
12.07.2026 à 10:00
IA et éducation (2/2) : du dilemme moral au malaise social
Texte intégral (10018 mots)
Cet article est une republication, avec l’accord de l’auteur, Hubert Guillaud. Il a été publié en premier le 01 juillet 2025 sur le site Dans Les Algorithmes sous licence CC BY-NC-SA.
Tout l’été, profitez de republications de « Dans Les Algorithmes » ! Rendez-vous tous les dimanches de juillet et d’août pour réfléchir, ensemble, sur les enjeux de l’Intelligence Artificielle.

Encourager les élèves à un usage responsable de l’IA semble plus facile à dire qu’à faire. Notamment parce que l’IA place la déqualification au coeur même de l’apprentissage. Derrière la question morale de la triche, il faut surtout observer le malaise social à l’oeuvre. L’IA n’est certainement pas le grand égalisateur qu’on pense.
Suite de notre dossier sur IA et éducation (voir la première partie).
La bataille éducative est-elle perdue ?
Une grande enquête de 404 media montre qu’à l’arrivée de ChatGPT, les écoles publiques américaines étaient totalement démunies face à l’adoption généralisée de ChatGPT par les élèves. Le problème est d’ailleurs loin d’être résolu. Le New York Mag a récemment publié un article qui se désole de la triche généralisée qu’ont introduit les IA génératives à l’école. De partout, les élèves utilisent les chatbots pour prendre des notes pendant les cours, pour concevoir des tests, résumer des livres ou des articles, planifier et rédiger leurs essais, résoudre les exercices qui leur sont demandés. Le plafond de la triche a été pulvérisé, explique un étudiant. “Un nombre considérable d’étudiants sortiront diplômés de l’université et entreront sur le marché du travail en étant essentiellement analphabètes”, se désole un professeur qui constate le court-circuitage du processus même d’apprentissage. La triche semblait pourtant déjà avoir atteint son apogée, avant l’arrivée de ChatGPT, notamment avec les plateformes d’aides au devoir en ligne comme Chegg et Course Hero. “Pour 15,95 $ par mois, Chegg promettait des réponses à toutes les questions de devoirs en seulement 30 minutes, 24h/24 et 7j/7, grâce aux 150 000 experts diplômés de l’enseignement supérieur qu’elle employait, principalement en Inde”.
Chaque école a proposé sa politique face à ces nouveaux outils, certains prônant l’interdiction, d’autres non. Depuis, les politiques se sont plus souvent assouplies, qu’endurcies. Nombre de profs autorisent l’IA, à condition de la citer, ou ne l’autorisent que pour aide conceptuelle et en demandant aux élèves de détailler la manière dont ils l’ont utilisé. Mais cela ne dessine pas nécessairement de limites claires à leurs usages. L’article souligne que si les professeurs se croient doués pour détecter les écrits générés par l’IA, des études ont démontré qu’ils ne le sont pas. L’une d’elles, publiée en juin 2024, utilisait de faux profils d’étudiants pour glisser des travaux entièrement générés par l’IA dans les piles de correction des professeurs d’une université britannique. Les professeurs n’ont pas signalé 97 % des essais génératifs. En fait, souligne l’article, les professeurs ont plutôt abandonné l’idée de pouvoir détecter le fait que les devoirs soient rédigés par des IA. “De nombreux enseignants semblent désormais désespérés”. “Ce n’est pas ce pour quoi nous nous sommes engagés”, explique l’un d’entre eux. La prise de contrôle de l’enseignement par l’IA tient d’une crise existentielle de l’éducation. Désormais, les élèves ne tentent même plus de se battre contre eux-mêmes. Ils se replient sur la facilité. “Toute tentative de responsabilisation reste vaine”, constatent les professeurs.
L’IA a mis à jour les défaillances du système éducatif. Bien sûr, l’idéal de l’université et de l’école comme lieu de développement intellectuel, où les étudiants abordent des idées profondes a disparu depuis longtemps. La perspective que les IA des professeurs évaluent désormais les travaux produits par les IA des élèves, finit de réduire l’absurdité de la situation, en laissant chacun sans plus rien à apprendre. Plusieurs études (comme celle de chercheurs de Microsoft) ont établi un lien entre l’utilisation de l’IA et une détérioration de l’esprit critique. Pour le psychologue, Robert Sternberg, l’IA générative compromet déjà la créativité et l’intelligence. “La bataille est perdue”, se désole un autre professeur.
Reste à savoir si l’usage “raisonnable” de l’IA est possible. Dans une longue enquête pour le New Yorker, le journaliste Hua Hsu constate que tous les étudiants qu’il a interrogés pour comprendre leur usage de l’IA ont commencé par l’utiliser pour se donner des idées, en promettant de veiller à un usage responsable et ont très vite basculé vers des usages peu modérés, au détriment de leur réflexion. L’utilisation judicieuse de l’IA ne tient pas longtemps. Dans un rapport sur l’usage de Claude par des étudiants, Anthropic a montré que la moitié des interactions des étudiants avec son outil serait extractive, c’est-à-dire servent à produire des contenus. 404 media est allé discuter avec les participants de groupes de soutien en ligne de gens qui se déclarent comme “dépendants à l’IA”. Rien n’est plus simple que de devenir accro à un chatbot, confient des utilisateurs de tout âge. OpenAI en est conscient, comme le pointait une étude du MIT sur les utilisateurs les plus assidus, sans proposer pourtant de remèdes.
Comment apprendre aux enfants à faire des choses difficiles ? Le journaliste Clay Shirky, devenu responsable de l’IA en éducation à la New York University, dans le Chronicle of Higher Education, s’interroge : l’IA améliore-t-elle l’éducation ou la remplace-t-elle ? “Chaque année, environ 15 millions d’étudiants de premier cycle aux États-Unis produisent des travaux et des examens de plusieurs milliards de mots. Si le résultat d’un cours est constitué de travaux d’étudiants (travaux, examens, projets de recherche, etc.), le produit de ce cours est l’expérience étudiante”. Un devoir n’a de valeur que « pour stimuler l’effort et la réflexion de l’élève ». “L’utilité des devoirs écrits repose sur deux hypothèses : la première est que pour écrire sur un sujet, l’élève doit comprendre le sujet et organiser ses pensées. La seconde est que noter les écrits d’un élève revient à évaluer l’effort et la réflexion qui y ont été consacrés”. Avec l’IA générative, la logique de cette proposition, qui semblait pourtant à jamais inébranlable, s’est complètement effondrée.
Pour Shirky, il ne fait pas de doute que l’IA générative peut être utile à l’apprentissage. “Ces outils sont efficaces pour expliquer des concepts complexes, proposer des quiz pratiques, des guides d’étude, etc. Les étudiants peuvent rédiger un devoir et demander des commentaires, voir à quoi ressemble une réécriture à différents niveaux de lecture, ou encore demander un résumé pour vérifier la clarté”… “Mais le fait que l’IA puisse aider les étudiants à apprendre ne garantit pas qu’elle le fera”. Pour le grand théoricien de l’éducation, Herbert Simon, “l’enseignant ne peut faire progresser l’apprentissage qu’en incitant l’étudiant à apprendre”. “Face à l’IA générative dans nos salles de classe, la réponse évidente est d’inciter les étudiants à adopter les utilisations utiles de l’IA tout en les persuadant d’éviter les utilisations néfastes. Notre problème est que nous ne savons pas comment y parvenir”, souligne pertinemment Shirky. Pour lui aussi, aujourd’hui, les professeurs sont en passe d’abandonner. Mettre l’accent sur le lien entre effort et apprentissage ne fonctionne pas, se désole-t-il. Les étudiants eux aussi sont déboussolés et finissent par se demander où l’utilisation de l’IA les mène. Shirky fait son mea culpa. L’utilisation engagée de l’IA conduit à son utilisation paresseuse. Nous ne savons pas composer avec les difficultés. Mais c’était déjà le cas avant ChatGPT. Les étudiants déclarent régulièrement apprendre davantage grâce à des cours magistraux bien présentés qu’avec un apprentissage plus actif, alors que de nombreuses études démontrent l’inverse. “Un outil qui améliore le rendement mais dégrade l’expérience est un mauvais compromis”.
C’est le sens même de l’éducation qui est en train d’être perdu. Le New York Times revenait récemment sur le fait que certaines écoles interdisent aux élèves d’utiliser ces outils, alors que les professeurs, eux, les sur-utilisent. Selon une étude auprès de 1800 enseignants de l’enseignement supérieur, 18 % déclaraient utiliser fréquemment ces outils pour faire leur cours, l’année dernière – un chiffre qui aurait doublé depuis. Les étudiants ne lisent plus ce qu’ils écrivent et les professeurs non plus. Si les profs sont prompts à critiquer l’usage de l’IA par leurs élèves, nombre d’entre eux l’apprécient pour eux-mêmes, remarque un autre article du New York Times. A PhotoMath ou Google Lens qui viennent aider les élèves, répondent MagicSchool et Brisk Teaching qui proposent déjà des produits d’IA qui fournissent un retour instantané sur les écrits des élèves. L’État du Texas a signé un contrat de 5 ans avec l’entreprise Cambium Assessment pour fournir aux professeurs un outil de notation automatisée des écrits des élèves.
Pour Jason Koebler de 404 media : “la société dans son ensemble n’a pas très bien résisté à l’IA générative, car les grandes entreprises technologiques s’obstinent à nous l’imposer. Il est donc très difficile pour un système scolaire public sous-financé de contrôler son utilisation”. Pourtant, peu après le lancement public de ChatGPT, certains districts scolaires locaux et d’État ont fait appel à des consultants pro-IA pour produire des formations et des présentations “encourageant largement les enseignants à utiliser l’IA générative en classe”, mais “aucun n’anticipait des situations aussi extrêmes que celles décrites dans l’article du New York Mag, ni aussi problématiques que celles que j’ai entendues de mes amis enseignants, qui affirment que certains élèves désormais sont totalement dépendants de ChatGPT”. Les documents rassemblés par 404media montrent surtout que les services d’éducation américains ont tardé à réagir et à proposer des perspectives aux enseignants sur le terrain.
Dans un autre article de 404 media, Koebler a demandé à des professeurs américains d’expliquer ce que l’IA a changé à leur travail. Les innombrables témoignages recueillis montrent que les professeurs ne sont pas restés les bras ballants, même s’ils se sentent très dépourvus face à l’intrusion d’une technologie qu’ils n’ont pas voulue. Tous expliquent qu’ils passent des heures à corriger des devoirs que les élèves mettent quelques secondes à produire. Tous dressent un constat similaire fait d’incohérences, de confusions, de démoralisations, entre préoccupations et exaspérations. Quelles limites mettre en place ? Comment s’assurer qu’elles soient respectées ? “Je ne veux pas que les étudiants qui n’utilisent pas de LLM soient désavantagés. Et je ne veux pas donner de bonnes notes à des étudiants qui ne font pratiquement rien”, témoigne un prof. Beaucoup ont désormais recours à l’écriture en classe, au papier. Quelques-uns disent qu’ils sont passés de la curiosité au rejet catégorique de ces outils. Beaucoup pointent que leur métier est plus difficile que jamais. “ChatGPT n’est pas un problème isolé. C’est le symptôme d’un paradigme culturel totalitaire où la consommation passive et la régurgitation de contenu deviennent le statu quo.”
L’IA place la déqualification au coeur de l’apprentissage
Nicholas Carr, qui vient de faire paraître Superbloom : How Technologies of Connection Tear Us Apart (Norton, 2025, non traduit) rappelle dans sa newsletter que “la véritable menace que représente l’IA pour l’éducation n’est pas qu’elle encourage la triche, mais qu’elle décourage l’apprentissage”. Pour Carr, lorsque les gens utilisent une machine pour réaliser une tâche, soit leurs compétences augmentent, soit elles s’atrophient, soit elles ne se développent jamais. C’est la piste qu’il avait d’ailleurs explorée dans Remplacer l’humain (L’échappée, 2017, traduction de The Glass Cage) en montrant comment les logiciels transforment concrètement les métiers, des architectes aux pilotes d’avions). “Si un travailleur maîtrise déjà l’activité à automatiser, la machine peut l’aider à développer ses compétences” et relever des défis plus complexes. Dans les mains d’un mathématicien, une calculatrice devient un “amplificateur d’intelligence”. À l’inverse, si le maintien d’une compétence exige une pratique fréquente, combinant dextérité manuelle et mentale, alors l’automatisation peut menacer le talent même de l’expert. C’est le cas des pilotes d’avion confrontés aux systèmes de pilotage automatique qui connaissent un “affaissement des compétences” face aux situations difficiles. Mais l’automatisation est plus pernicieuse encore lorsqu’une machine prend les commandes d’une tâche avant que la personne qui l’utilise n’ait acquis l’expérience de la tâche en question. “C’est l’histoire du phénomène de « déqualification » du début de la révolution industrielle. Les artisans qualifiés ont été remplacés par des opérateurs de machines non qualifiés. Le travail s’est accéléré, mais la seule compétence acquise par ces opérateurs était celle de faire fonctionner la machine, ce qui, dans la plupart des cas, n’était quasiment pas une compétence. Supprimez la machine, et le travail s’arrête”.
Bien évidemment que les élèves qui utilisent des chatbots pour faire leurs devoirs font moins d’effort mental que ceux qui ne les utilisent pas, comme le pointait une très épaisse étude du MIT (synthétisée par Le Grand Continent), tout comme ceux qui utilisent une calculatrice plutôt que le calcul mental vont moins se souvenir des opérations qu’ils ont effectuées. Mais le problème est surtout que ceux qui les utilisent sont moins méfiants de leurs résultats (comme le pointait l’étude des chercheurs de Microsoft), alors que contrairement à ceux d’une calculatrice, ils sont beaucoup moins fiables. Le problème de l’usage des LLM à l’école, c’est à la fois qu’il empêche d’apprendre à faire, mais plus encore que leur usage nécessite des compétences pour les évaluer.
L’IA générative étant une technologie polyvalente permettant d’automatiser toutes sortes de tâches et d’emplois, nous verrons probablement de nombreux exemples de chacun des trois scénarios de compétences dans les années à venir, estime Carr. Mais l’utilisation de l’IA par les lycéens et les étudiants pour réaliser des travaux écrits, pour faciliter ou éviter le travail de lecture et d’écriture, constitue un cas particulier. “Elle place le processus de déqualification au cœur de l’éducation. Automatiser l’apprentissage revient à le subvertir”.
En éducation, plus vous effectuez de recherches, plus vous vous améliorez en recherche, et plus vous rédigez d’articles, plus vous améliorez votre rédaction. “Cependant, la valeur pédagogique d’un devoir d’écriture ne réside pas dans le produit tangible du travail – le devoir rendu à la fin du devoir. Elle réside dans le travail lui-même : la lecture critique des sources, la synthèse des preuves et des idées, la formulation d’une thèse et d’un argument, et l’expression de la pensée dans un texte cohérent. Le devoir est un indicateur que l’enseignant utilise pour évaluer la réussite du travail de l’étudiant – le travail d’apprentissage. Une fois noté et rendu à l’étudiant, le devoir peut être jeté”.
L’IA générative permet aux étudiants de produire le produit sans effectuer le travail. Le travail remis par un étudiant ne témoigne plus du travail d’apprentissage qu’il a nécessité. “Il s’y substitue ». Le travail d’apprentissage est ardu par nature : sans remise en question, l’esprit n’apprend rien. Les étudiants ont toujours cherché des raccourcis bien sûr, mais l’IA générative est différente, pas son ampleur, par sa nature. “Sa rapidité, sa simplicité d’utilisation, sa flexibilité et, surtout, sa large adoption dans la société rendent normal, voire nécessaire, l’automatisation de la lecture et de l’écriture, et l’évitement du travail d’apprentissage”. Grâce à l’IA générative, un élève médiocre peut produire un travail remarquable tout en se retrouvant en situation de faiblesse. Or, pointe très justement Carr, “la conséquence ironique de cette perte d’apprentissage est qu’elle empêche les élèves d’utiliser l’IA avec habileté. Rédiger une bonne consigne, un prompt efficace, nécessite une compréhension du sujet abordé. Le dispensateur doit connaître le contexte de la consigne. Le développement de cette compréhension est précisément ce que la dépendance à l’IA entrave”. “L’effet de déqualification de l’outil s’étend à son utilisation”. Pour Carr, “nous sommes obnubilés par la façon dont les étudiants utilisent l’IA pour tricher. Alors que ce qui devrait nous préoccuper davantage, c’est la façon dont l’IA trompe les étudiants”.
Nous sommes d’accord. Mais cette conclusion n’aide pas pour autant à avancer !
Passer du malaise moral au malaise social !
Utiliser ou non l’IA semble surtout relever d’un malaise moral (qui en rappelle un autre), révélateur, comme le souligne l’obsession sur la « triche » des élèves. Mais plus qu’un dilemme moral, peut-être faut-il inverser notre regard, et le poser autrement : comme un malaise social. C’est la proposition que fait le sociologue Bilel Benbouzid dans un remarquable article pour AOC (première et seconde partie).
Pour Benbouzid, l’IA générative à l’université ébranle les fondements de « l’auctorialité », c’est-à-dire qu’elle modifie la position d’auteur et ses repères normatifs et déontologiques. Dans le monde de l’enseignement supérieur, depuis le lancement de ChatGPT, tout le monde s’interroge pour savoir que faire de ces outils, souvent dans un choix un peu binaire, entre leur autorisation et leur interdiction. Or, pointe justement Benbouzid, l’usage de l’IA a été « perçu » très tôt comme une transgression morale. Très tôt, les utiliser a été associé à de la triche, d’autant qu’on ne peut pas les citer, contrairement à tout autre matériel écrit.
Face à leur statut ambigu, Benbouzid pose une question de fond : quelle est la nature de l’effort intellectuel légitime à fournir pour ses études ? Comment distinguer un usage « passif » de l’IA d’un usage « actif », comme l’évoquait Ethan Mollick dans la première partie de ce dossier ? Comment contrôler et s’assurer d’une utilisation active et éthique et non pas passive et moralement condamnable ?
Pour Benbouzid, il se joue une réflexion éthique sur le rapport à soi qui nécessite d’être authentique. Mais peut-on être authentique lorsqu’on se construit, interroge le sociologue, en évoquant le fait que les étudiants doivent d’abord acquérir des compétences avant de s’individualiser. Or l’outil n’est pas qu’une machine pour résumer ou copier. Pour Benbouzid, comme pour Mollick, bien employée, elle peut-être un vecteur de stimulation intellectuelle, tout en exerçant une influence diffuse mais réelle. « Face aux influences tacites des IAG, il est difficile de discerner les lignes de partage entre l’expression authentique de soi et les effets normatifs induits par la machine. » L’enjeu ici est bien celui de la capacité de persuasion de ces machines sur ceux qui les utilisent.
Pour les professeurs de philosophie et d’éthique Mark Coeckelbergh et David Gunkel, comme ils l’expliquent dans un article (qui a depuis donné lieu à un livre, Communicative AI, Polity, 2025), l’enjeu n’est pourtant plus de savoir qui est l’auteur d’un texte (même si, comme le remarque Antoine Compagnon, sans cette figure, la lecture devient indéchiffrable, puisque nul ne sait plus qui parle, ni depuis quels savoirs), mais bien plus de comprendre les effets que les textes produisent. Pourtant, ce déplacement, s’il est intéressant (et peut-être peu adapté à l’IA générative, tant les textes produits sont rarement pertinents), il ne permet pas de cadrer les usages des IA génératives qui bousculent le cadre ancien de régulation des textes académiques. Reste que l’auteur d’un texte doit toujours en répondre, rappelle Benbouzid, et c’est désormais bien plus le cas des étudiants qui utilisent l’IA que de ceux qui déploient ces systèmes d’IA. L’autonomie qu’on attend d’eux est à la fois un idéal éducatif et une obligation morale envers soi-même, permettant de développer ses propres capacités de réflexion. « L’acte d’écriture n’est pas un simple exercice technique ou une compétence instrumentale. Il devient un acte de formation éthique ». Le problème, estiment les professeurs de philosophie Timothy Aylsworth et Clinton Castro, dans un article qui s’interroge sur l’usage de ChatGPT, c’est que l’autonomie comme finalité morale de l’éducation n’est pas la même que celle qui permet à un étudiant de décider des moyens qu’il souhaite mobiliser pour atteindre son but. Pour Aylsworth et Castro, les étudiants ont donc obligation morale de ne pas utiliser ChatGPT, car écrire soi-même ses textes est essentiel à la construction de son autonomie. Pour eux, l’école doit imposer une morale de la responsabilité envers soi-même où écrire par soi-même n’est pas seulement une tâche scolaire, mais également un moyen d’assurer sa dignité morale. « Écrire, c’est penser. Penser, c’est se construire. Et se construire, c’est honorer l’humanité en soi. »
Pour Benbouzid, les contradictions de ces deux dilemmes résument bien le choix cornélien des étudiants et des enseignants. Elle leur impose une liberté de ne pas utiliser. Mais cette liberté de ne pas utiliser, elle, ne relève-t-elle pas d’abord et avant tout d’un jugement social ?
L’IA générative ne sera pas le grand égalisateur social !
C’est la piste fructueuse qu’explore Bilel Benbouzid dans la seconde partie de son article. En explorant qui à recours à l’IA et pourquoi, le sociologue permet d’entrouvrir une autre réponse que la réponse morale. Ceux qui promeuvent l’usage de l’IA pour les étudiants, comme Ethan Mollick, estiment que l’IA pourrait agir comme une égaliseuse de chances, permettant de réduire les différences cognitives entre les élèves. C’est là une référence aux travaux d’Erik Brynjolfsson, Generative AI at work, qui souligne que l’IA diminue le besoin d’expérience, permet la montée en compétence accélérée des travailleurs et réduit les écarts de compétence des travailleurs (une théorie qui a été en partie critiquée, notamment parce que ces avantages sont compensés par l’uniformisation des pratiques et leur surveillance – voir ce que nous en disions en mobilisant les travaux de David Autor). Mais sommes-nous confrontés à une homogénéisation des performances d’écritures ? N’assiste-t-on pas plutôt à un renforcement des inégalités entre les meilleurs qui sauront mieux que d’autres tirer parti de l’IA générative et les moins pourvus socialement ?
Pour John Danaher, l’IA générative pourrait redéfinir pas moins que l’égalité, puisque les compétences traditionnelles (rédaction, programmation, analyses…) permettraient aux moins dotés d’égaler les meilleurs. Pour Danaher, le risque, c’est que l’égalité soit alors reléguée au second plan : « d’autres valeurs comme l’efficacité économique ou la liberté individuelle prendraient le dessus, entraînant une acceptation accrue des inégalités. L’efficacité économique pourrait être mise en avant si l’IA permet une forte augmentation de la productivité et de la richesse globale, même si cette richesse est inégalement répartie. Dans ce scénario, plutôt que de chercher à garantir une répartition équitable des ressources, la société pourrait accepter des écarts grandissants de richesse et de statut, tant que l’ensemble progresse. Ce serait une forme d’acceptation de l’inégalité sous prétexte que la technologie génère globalement des bénéfices pour tous, même si ces bénéfices ne sont pas partagés de manière égale. De la même manière, la liberté individuelle pourrait être privilégiée si l’IA permet à chacun d’accéder à des outils puissants qui augmentent ses capacités, mais sans garantir que tout le monde en bénéficie de manière équivalente. Certains pourraient considérer qu’il est plus important de laisser les individus utiliser ces technologies comme ils le souhaitent, même si cela crée de nouvelles hiérarchies basées sur l’usage différencié de l’IA ». Pour Danaher comme pour Benbouzid, l’intégration de l’IA dans l’enseignement doit poser la question de ses conséquences sociales !
Les LLM ne produisent pas un langage neutre mais tendent à reproduire les « les normes linguistiques dominantes des groupes sociaux les plus favorisés », rappelle Bilel Benbouzid. Une étude comparant les lettres de motivation d’étudiants avec des textes produits par des IA génératives montre que ces dernières correspondent surtout à des productions de CSP+. Pour Benbouzid, le risque est que la délégation de l’écriture à ces machines renforce les hiérarchies existantes plus qu’elle ne les distribue. D’où l’enjeu d’une enquête en cours pour comprendre l’usage de l’IA générative des étudiants et leur rapport social au langage.
Les premiers résultats de cette enquête montrent par exemple que les étudiants rechignent à copier-coller directement le texte créé par les IA, non seulement par peur de sanctions, mais plus encore parce qu’ils comprennent que le ton et le style ne leur correspondent pas. « Les étudiants comparent souvent ChatGPT à l’aide parentale. On comprend que la légitimité ne réside pas tant dans la nature de l’assistance que dans la relation sociale qui la sous-tend. Une aide humaine, surtout familiale, est investie d’une proximité culturelle qui la rend acceptable, voire valorisante, là où l’assistance algorithmique est perçue comme une rupture avec le niveau académique et leur propre maîtrise de la langue ». Et effectivement, la perception de l’apport des LLM dépend du capital culturel des étudiants. Pour les plus dotés, ChatGPT est un outil utilitaire, limité voire vulgaire, qui standardise le langage. Pour les moins dotés, il leur permet d’accéder à des éléments de langages valorisés et valorisants, tout en l’adaptant pour qu’elle leur corresponde socialement.
Dans ce rapport aux outils de génération, pointe un rapport social à la langue, à l’écriture, à l’éducation. Pour Benbouzid, l’utilisation de l’IA devient alors moins un problème moral qu’un dilemme social. « Ces pratiques, loin d’être homogènes, traduisent une appropriation différenciée de l’outil en fonction des trajectoires sociales et des attentes symboliques qui structurent le rapport social à l’éducation. Ce qui est en jeu, finalement, c’est une remise en question de la manière dont les étudiants se positionnent socialement, lorsqu’ils utilisent les robots conversationnels, dans les hiérarchies culturelles et sociales de l’université. » En fait, les étudiants utilisent les outils non pas pour se dépasser, comme l’estime Mollick, mais pour produire un contenu socialement légitime. « En déléguant systématiquement leurs compétences de lecture, d’analyse et d’écriture à ces modèles, les étudiants peuvent contourner les processus essentiels d’intériorisation et d’adaptation aux normes discursives et épistémologiques propres à chaque domaine. En d’autres termes, l’étudiant pourrait perdre l’occasion de développer authentiquement son propre capital culturel académique, substitué par un habitus dominant produit artificiellement par l’IA. »
L’apparence d’égalité instrumentale que permettent les LLM pourrait donc paradoxalement renforcer une inégalité structurelle accrue. Les outils creusant l’écart entre des étudiants qui ont déjà internalisé les normes dominantes et ceux qui les singent. Le fait que les textes générés manquent d’originalité et de profondeur critique, que les IA produisent des textes superficiels, ne rend pas tous les étudiants égaux face à ces outils. D’un côté, les grandes écoles renforcent les compétences orales et renforcent leurs exigences d’originalité face à ces outils. De l’autre, d’autres devront y avoir recours par nécessité. « Pour les mieux établis, l’IA représentera un outil optionnel d’optimisation ; pour les plus précaires, elle deviendra une condition de survie dans un univers concurrentiel. Par ailleurs, même si l’IA profitera relativement davantage aux moins qualifiés, cette amélioration pourrait simultanément accentuer une forme de dépendance technologique parmi les populations les plus défavorisées, creusant encore le fossé avec les élites, mieux armées pour exercer un discernement critique face aux contenus générés par les machines ».
Bref, loin de l’égalisation culturelle que les outils permettraient, le risque est fort que tous n’en profitent pas d’une manière égale. On le constate très bien ailleurs. Le fait d’être capable de rédiger un courrier administratif est loin d’être partagé. Si ces outils améliorent les courriers des moins dotés socialement, ils ne renversent en rien les différences sociales. C’est le même constat qu’on peut faire entre ceux qui subliment ces outils parce qu’ils les maîtrisent finement, et tous les autres qui ne font que les utiliser, comme l’évoquait Gregory Chatonsky, en distinguant les utilisateurs mémétiques et les utilisateurs productifs. Ces outils, qui se présentent comme des outils qui seraient capables de dépasser les inégalités sociales, risquent avant tout de mieux les amplifier. Plus que de permettre de personnaliser l’apprentissage, pour s’adapter à chacun, il semble que l’IA donne des superpouvoirs d’apprentissage à ceux qui maîtrisent leurs apprentissages, plus qu’aux autres.
L’IApocalypse scolaire, coincée dans le droit
Les questions de l’usage de l’IA à l’école que nous avons tenté de dérouler dans ce dossier montrent l’enjeu à débattre d’une politique publique d’usage de l’IA générative à l’école, du primaire au supérieur. Mais, comme le montre notre enquête, toute la communauté éducative est en attente d’un cadre. En France, on attend les recommandations de la mission confiée à François Taddéi et Sarah Cohen-Boulakia sur les pratiques pédagogiques de l’IA dans l’enseignement supérieur, rapportait le Monde.
Un premier cadre d’usage de l’IA à l’école vient pourtant d’être publié par le ministère de l’Education nationale. Autant dire que ce cadrage processuel n’est pas du tout à la hauteur des enjeux. Le document consiste surtout en un rappel des règles et, pour l’essentiel, elles expliquent d’abord que l’usage de l’IA générative est contraint si ce n’est impossible, de fait. « Aucun membre du personnel ne doit demander aux élèves d’utiliser des services d’IA grand public impliquant la création d’un compte personnel » rappelle le document. La note recommande également de ne pas utiliser l’IA générative avec les élèves avant la 4e et souligne que « l’utilisation d’une intelligence artificielle générative pour réaliser tout ou partie d’un devoir scolaire, sans autorisation explicite de l’enseignant et sans qu’elle soit suivie d’un travail personnel d’appropriation à partir des contenus produits, constitue une fraude ». Autant dire que ce cadre d’usage ne permet rien, sinon l’interdiction. Loin d’être un cadre de développement ouvert à l’envahissement de l’IA, comme s’en plaint le SNES-FSU, le document semble surtout continuer à produire du déni, tentant de rappeler des règles sur des usages qui les débordent déjà très largement.
Sur Linked-in, Yann Houry, prof dans un Institut privé suisse, était très heureux de partager sa recette pour permettre aux profs de corriger des copies avec une IA en local, rappelant que pour des questions de légalité et de confidentialité, les professeurs ne devraient pas utiliser les services d’IA génératives en ligne pour corriger les copies. Dans les commentaires, nombreux sont pourtant venus lui signaler que cela ne suffit pas, rappelant qu’utiliser l’IA pour corriger les copies, donner des notes et classer les élèves peut être classée comme un usage à haut-risque selon l’IA Act, ou encore qu’un formateur qui utiliserait l’IA en ce sens devrait en informer les apprenants afin qu’ils exercent un droit de recours en cas de désaccord sur une évaluation, sans compter que le professeur doit également être transparent sur ce qu’il utilise pour rester en conformité et l’inscrire au registre des traitements. Bref, d’un côté comme de l’autre, tant du côté des élèves qui sont renvoyés à la fraude quel que soit la façon dont ils l’utilisent, que des professeurs, qui ne doivent l’utiliser qu’en pleine transparence, on se rend vite compte que l’usage de l’IA dans l’éducation reste, formellement, très contraint, pour ne pas dire impossible.
D’autres cadres et rapports ont été publiés. Comme celui de l’inspection générale, du Sénat ou de la Commission européenne et de l’OCDE, mais qui se concentrent surtout sur ce qu’un enseignement à l’IA devrait être, plus que de donner un cadre aux débordements des usages actuels. Bref, pour l’instant, le cadrage de l’IApocalypse scolaire reste à construire, avec les professeurs… et avec les élèves.
Hubert Guillaud
MAJ du 02/09/2025 : Le rapport de François Taddei sur l’IA dans l’Enseignement supérieur a été publié. Et, contrairement à ce qu’on aurait pu en attendre, il ne répond pas à la question des limites de l’usage de l’IA dans l’enseignement supérieur.
Le rapport est pourtant disert. Il recommande de mutualiser les capacités de calculs, les contenus et les bonnes pratiques, notamment via une plateforme de mutualisation. Il recommande de développer la formation des étudiants comme des personnels et bien sûr de repenser les modalités d’évaluation, mais sans proposer de pistes concrètes. « L’IA doit notamment contribuer à rendre les établissements plus inclusifs, renforcer la démocratie universitaire, et développer un nouveau modèle d’enseignement qui redéfinisse le rôle de l’enseignant et des étudiants », rappelle l’auteur d‘Apprendre au XXIe siècle (Calmann-Levy, 2018) qui militait déjà pour transformer l’institution. Il recommande enfin de développer des data centers dédiés, orientés enseignement et des solutions techniques souveraines et invite le ministère de l’enseignement supérieur à se doter d’une politique nationale d’adoption de l’IA autour d’un Institut national IA, éducation et société.
Le rapport embarque une enquête quantitative sur l’usage de l’IA par les étudiants, les professeurs et les personnels administratifs. Si le rapport estime que l’usage de l’IA doit être encouragé, il souligne néanmoins que son développement « doit être accompagné de réflexions collectives sur les usages et ses effets sur l’organisation du travail, les processus et l’évolution des compétences », mais sans vraiment faire de propositions spécifiques autres que citer certaines déjà mises en place nombre de professeurs. Ainsi, sur l’évolution des pratiques, le rapport recense les évolutions, notamment le développement d’examens oraux, mais en pointe les limites en termes de coûts et d’organisation, sans compter, bien sûr, qu’ils ne permettent pas d’évaluer les capacités d’écriture des élèves. « La mission considère que l’IA pourrait donner l’opportunité de redéfinir les modèles d’enseignement, en réinterrogeant le rôle de chacun. Plusieurs pistes sont possibles : associer les étudiants à la définition des objectifs des enseignements, responsabiliser les étudiants sur les apprentissages, mettre en situation professionnelle, développer davantage les modes projet, développer la résolution de problèmes complexes, associer les étudiants à l’organisation d’événements ou de travaux de recherche, etc. Le principal avantage de cette évolution est qu’elle peut permettre de renforcer l’engagement des étudiants dans les apprentissages, car ils sont plus impliqués quand ils peuvent contribuer aux choix des sujets abordés. Ils prendront aussi conscience des enjeux pour leur vie professionnelle des matières enseignées. Une telle évolution pourrait renforcer de ce fait la qualité des apprentissages. Elle permettrait aussi de proposer davantage d’horizontalité dans les échanges, ce qui est attendu par les étudiants et qui reflète aussi davantage le fonctionnement par projet, mode d’organisation auquel ils seront fréquemment confrontés ». Pour répondre au défi de l’IA, la mission Taddeï propose donc de « sortir d’une transmission descendante » au profit d’un apprentissage plus collaboratif, comme François Taddéi l’a toujours proposé, mais sans proposer de norme pour structurer les rapports à l’IA.
Le rapport recommande d’ailleurs de favoriser l’usage de l’IA dans l’administration scolaire et d’utiliser le « broad listening » , l’écoute et la consultation des jeunes pour améliorer la démocratie universitaire… Une proposition qui pourrait être stimulante si nous n’étions pas plutôt confrontés à son exact inverse : le broad listening semble plutôt mobilisé pour réprimer les propos étudiants que le contraire… Enfin, le rapport insiste particulièrement sur l’usage de l’IA pour personnaliser l’orientation et être un tuteur d’études. La dernière partie du rapport constate les besoins de formation et les besoins d’outils mutualisés, libres et ouverts : deux aspects qui nécessiteront des financements et projets adaptés.
Ce rapport très pro-IA ne répond pas vraiment à la difficulté de l’évaluation et de l’enseignement à l’heure où les élèves peuvent utiliser l’IA pour leurs écrits.
Signalons qu’un autre rapport a été publié concomitamment, celui de l’Inspection générale de l’éducation, du sport et de la recherche (IGERS) qui insiste également sur le besoin de coordination et de mutualisation.
Pour l’instant, l’une des propositions la plus pratico-pratique que l’on a vu passer sont assurément les résultats de la convention « citoyenne » de Sciences-Po Aix sur l’usage de l’IA générative, formulant 7 propositions. La convention recommande que les étudiants déclarent l’usage de l’IA, pour préciser le niveau d’intervention qui a été fait, le modèle utilisé et les instructions données, sur le modèle de celles utilisées par l’université de Sherbrooke. L’avis recommande aussi la coordination des équipes pédagogiques afin d’harmoniser les pratiques, pour donner un cadre cohérent aux étudiants et bâtir une réflexion collective. La 3e proposition consiste à améliorer l’enquête sur les pratiques via des formulaires réguliers pour mieux saisir les niveaux d’usages des élèves. La 4e proposition propose de ne pas autoriser l’IA générative pour les étudiants en première et seconde année, afin de leur permettre d’acquérir un socle de connaissances. La 5e proposition propose que les enseignants indiquent clairement si l’usage est autorisé ou non et selon quelles modalités, sur le modèle que propose, là encore, l’université de Sherbrooke. La 6e proposition propose d’améliorer la formation aux outils d’IA. La 7e propose d’organiser des ateliers de sensibilisation aux dimensions environnementales et sociales des IA génératives, intégrés à la formation. Comme le montrent nombre de chartes de l’IA dans l’éducation, celle-ci propose surtout un plus fort cadrage des usages que le contraire.
En tout cas, le sujet agite la réflexion. Dans une tribune pour le Monde, le sociologue Manuel Cervera-Marzal estime que plutôt que d’ériger des interdits inapplicables en matière d’intelligence artificielle, les enseignants doivent réinventer les manières d’enseigner et d’évaluer, explique-t-il en explicitant ses propres pratiques. Même constat dans une autre tribune pour le professeur et écrivain Maxime Abolgassemi.
Dans une tribune pour le Club de Mediapart, Céline Cael et Laurent Reynaud, auteurs de Et si on imaginait l’école de demain ? (Retz, 2025) reviennent sur les annonces toutes récentes de la ministre de l’Éducation, Elisabeth Borne, de mettre en place une IA pour les professeurs “pour les accompagner dans leurs métiers et les aider à préparer leurs cours” (un appel d’offres a d’ailleurs été publié en janvier 2025 pour sélectionner un candidat). Des modules de formation seront proposés aux élèves du secondaire et un chatbot sera mis en place pour répondre aux questions administratives et réglementaires des personnels de l’Éducation nationale, a-t-elle également annoncé. Pour les deux enseignants, “l’introduction massive du numérique, et de l’IA par extension, dans le quotidien du métier d’enseignant semble bien plus souvent conduire à un appauvrissement du métier d’enseignant plutôt qu’à son optimisation”. “L’IA ne saurait être la solution miracle à tous les défis de l’éducation”, rappellent-ils. Les urgences ne sont pas là.
Selon le bulletin officiel de l’éducation nationale qui a publié en juillet un cadre pour un usage raisonné du numérique à l’école, la question de l’IA « doit être conduite au sein des instances de démocratie scolaire », afin de nourrir le projet d’établissement. Bref, la question du cadrage des pratiques est pour l’instant renvoyée à un nécessaire débat de société à mener.
MAJ du 01/10/2025 : A la suite d’Anthropic, OpenAI vient de publier une version de son chatbot pour étudiants. Ce “mode étude” consiste à doter ChatGPT “d’un nouveau filtre de conversation qui régule simplement la manière dont il répond aux élèves, encourageant moins de réponses et plus d’explications”. Plutôt que de donner des réponses, le robot tente d’expliquer le sujet et de renvoyer les étudiants à leurs propres efforts. Pourtant, rappelle la Technology Review, cela ne signifie pas que le système ne produise pas d’erreurs, au contraire. Il peut finalement apprendre à aborder des problèmes de manière erronée et produire des explications totalement fausses. Enfin, il n’empêchera pas les étudiants d’exiger du moteur de produire des réponses plutôt que de simplement les accompagner dans leur compréhension. Le mode tutorat lancé par les grandes entreprises de l’IA vise surtout à décrocher des marchés avec le secteur éducatif et fait la promesse que le tutorat personnalisé serait finalement un secteur où l’on pourrait considérablement réduire le coût humain.
MAJ du 13/10/2025 : Lundi matin revient sur l’injonction à déployer l’IA à l’école… et rappelle, fort à propos, les échecs du numérique à l’école. Déjà en 2015, un rapport de l’OCDE concluait à « l’absence d’effets – voir même à des effets négatifs –, des investissements consacrés à l’équipement des établissements scolaires en technologies numériques, sur les résultats aux épreuves PISA », souligne une méta-analyse. Le rapport de synthèse de 2020 du CNESCO parle de « révolution manquée » et reconnaît que « s’il n’y a pas eu de révolution numérique à l’école, c’est parce que les outils numériques n’améliorent pas les apprentissages ».
« Les promesses des prophètes de l’IA ressemblent comme deux gouttes d’eau à celles des années 2000 et 2010, au prix d’une petite mise à jour, un peu comme les publicités pour les aspirateurs robots ressemblent à s’y méprendre à celles pour les aspirateurs classiques, l’autotune en plus. Votre enfant a du mal à mettre un « s » au pluriel ? Pas de souci ! Il suffit de demander à l’IA de faire une petite chanson, du genre : « t’as pas mis de S… SOS » ! « Le résultat est bluffant ». […] Comme l’écrivait le rapport du Sénat, il importe de « faire la démonstration scientifique de la capacité de l’IA (…) à favoriser la montée en compétence des apprenants et de transformer efficacement les façons d’enseigner ». Même s’il est parfois difficile de distinguer la démonstration scientifique du publireportage. »
MAJ du 24/11/2025 : Sur Gizmodo, AJ Dellinger ironise sur l’annonce par OpenAI du lancement d’un chatGPT pour les profs. « Les enseignants pourront faire noter le travail des chatbots de leurs élèves par leurs propres chatbots ». Le problème de l’abrutissement des jeunes est en passe d’être résolu !, grince-t-il. « Les établissements scolaires sont devenus un champ de bataille pour les entreprises d’IA qui cherchent désespérément à implanter leurs produits dans un maximum d’institutions ». « On ignore pour l’instant si la présence de ces chatbots dans ces espaces profite réellement à qui que ce soit d’autre qu’à l’entreprise qui les conçoit », raille le journaliste. À défaut de s’inquiéter en amont des risques possibles, il est probable que nous puissions bientôt en voir les résultats.
MAJ du 25/11/2025 : Dans une tribune pour le New York Times, le professeur d’anglais, Carlo Rotella, explique comment, confrontée à l’IA, il a humanisé ses cours. “Un cours d’anglais résistant à l’IA repose sur trois piliers : l’évaluation écrite et orale, l’enseignement du processus d’écriture plutôt que la simple attribution de dissertations, et une plus grande importance accordée aux interactions en classe.“ Quizz pointilleux, tests pour observer le processus d’écriture plutôt que le résultat final, des entretiens pour que les étudiants expliquent comment ils ont conçu et rédigé leur travail, rendre les travaux écrits plus personnels (« êtes-vous proustien ? ») plutôt que de demander une dissertation factuelle. ”Je perçois la voix individuelle des étudiants dans leurs travaux, qui se développent de manière crédible à partir d’exercices et de brouillons, la plupart du temps sans dérive robotique”. Et surtout développer des discussions en classe et y participer, en interdisant les ordinateurs pour améliorer les interactions… Autant d’éléments qui demandent de s’extraire soi-même du cours magistral. “Ne perdez pas votre temps à vous entraîner à être remplaçables par une IA. Utilisez vos facultés ou vous les perdrez.” Mais tout cela n’est possible que parce que le professeur a peu d’élèves, concède-t-il. “Je ne peux pas être sûr que ce qui fonctionne aujourd’hui continuera de fonctionner face aux progrès inexorables de l’IA”, prévient-il.
MAJ du 05/01/2026 : Pour le New York Times, la journaliste Natasha Singer fait le point sur le déploiement de l’IA dans les écoles au niveau mondial, via des partenariats entre les grandes entreprises de la tech et le secteur scolaire. Sur les campus, les cours et spécialisations en IA se multiplient, alors que les cours en informatique sont désertés du fait des difficultés d’employabilité.
MAJ du 15/01/2026 : « À ce stade de son développement, les risques liés à l’utilisation de l’IA générative dans l’éducation des enfants l’emportent sur ses avantages », estime un rapport de Brookings. Qui recommande notamment de créer des outils d’IA éducatifs avec les enseignants, les élèves, les parents et la communauté.
06.07.2026 à 09:03
UPLOAD dans un recueil de nouvelles solarpunk
Texte intégral (565 mots)
Cela fait plusieurs années que Framasoft participe à des ateliers d’écriture solarpunk dans le cadre d’une Activité Pédagogique d’Intersemestre à l’Université de Technologie de Compiègne (voir l’annonce originelle publiée en 2024).
À chaque fin de session, les étudiantes et étudiants rendent public leur travail en ligne et en lisent un extrait en direct à la radio (sur Graf’Hit : captures en ligne ). Et comme les textes sont généralement publiés sous licence libre (CC BY-SA le plus souvent), il a été possible de se baser sur certaines propositions pour les unifier en un recueil sous le nom collectif Camilles Picard.
Une nouvelle étape est franchie désormais, car les éditions C&F ont accepté d’en faire un livre papier, disponible en librairie et sur leur site : cfeditions.com/upload/

Le recueil UPLOAD, par Camilles Picard chez C&F éditions
Vous pourrez y retrouver huit textes conçus à l’origine par un étudiant ou une étudiante, ainsi qu’un complément écrit par Stéphane Crozat, l’enseignant-chercheur initiateur du projet à l’UTC (également auteur de romans et… membre de Framasoft).
Les participants et participantes à la conférence Archipel auront la chance de découvrir l’ouvrage lors de la semaine du colloque.
Souhaitons que diffuser ces textes sous ce nouveau format donnera lieu à d’autres récits solarpunk à l’avenir, bien évidemment sous licence libre…
Le déroulé du cours qui a permis la création de ces textes : librecours.net/courses/api0075/
Crédits de l’image de fond : https://storyseedlibrary.org/art/the-lemonaut/hackerspace/ · A prosthesis maintenance day at the hackerspace, 2024, CC BY SA The Lemonaut
06.07.2026 à 07:42
Khrys’presso du lundi 6 juillet 2026
Texte intégral (10125 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- 21 °C à la surface des océans : un record absolu pour la saison (reporterre.net)
- Les astronomes tirent la sonnette d’alarme : l’humanité risque de perdre le ciel étoilé pour toujours (futura-sciences.com)

- En floutant ses bases militaires sur ses cartes, la Russie a révélé leur position aux forces ukrainiennes (slate.fr)
- A year with zero deaths on its streets : How Helsinki became a world reference for road safety (euronews.com)
- Pax Silica : l’Europe s’aligne-t-elle sur Washington dans la guerre technologique avec Pékin ? (legrandcontinent.eu)
En fin de semaine dernière, l’Union a rejoint aux côtés de 9 pays – dont 3 États membres : l’Allemagne, les Pays-Bas et la Grèce – la Pax Silica, une initiative lancée par l’administration Trump en décembre qui vise à renforcer la coopération dans les chaînes d’approvisionnement de l’IA et des technologies de pointe.
- Le Data Privacy Framework remis en question par la fin de l’indépendance de la FTC (next.ink)
La Cour suprême américaine vient de statuer que Donald Trump peut révoquer les dirigeants des agences états-uniennes comme la FTC quand il le veut. L’association noyb et le député Philippe Latombe y voient une incompatibilité avec l’accord Data Privacy Framework qui repose sur l’indépendance de l’agence.
- ChatControl : nouvelle tentative de prolonger la surveillance des messageries (next.ink)
- Politician who investigated spyware abuses had his phone hacked with Pegasus spyware (techcrunch.com)
Security researchers have confirmed that a European politician had his phone hacked with the Pegasus spyware while serving on an investigatory committee probing abuses of the notorious surveillance tool. This has reignited fresh controversy over governments abusing spyware to collect information about their critics.
- Top EU judges financial holdings raise troubling questions (investigate-europe.eu)
More than 40 per cent of jurists at the Court of Justice have declared private financial interests, with some working on cases concerning industries where they hold stakes. A new Investigate Europe investigation reveals the transparency concerns and possible conflict of interest risks at the bloc’s most powerful court.
- Expulsions et enfermement : le durcissement sans précédent de la politique migratoire européenne (inkyfada.com)
Le Parlement européen a adopté un règlement qui réorganise l’expulsion des étrangers en situation irrégulière. Ses promoteurs saluent la fin de l’impuissance européenne face à l’immigration non contrôlée. L’ONU et les associations de défense des droits y voient un “risque élevé de violations des droits humains”.
- Quand l’Andalousie s’enrichit grâce aux immigré·es tout en votant pour un parti xénophobe (basta.media)
En Espagne, les zones de cultures intensives sous serre sont le lieu d’un miracle économique fondé sur le recours massif à la main-d’œuvre immigrée. Ces territoires votent aussi pour Vox, le parti d’extrême droite qui refuse toute régularisation.
- Alerte rouge canicule, 44 °C attendus localement, 1 200 pompiers mobilisés contre les incendies… Le Portugal s’embrase à son tour (humanite.fr)
Le pays est en train d’affronter « une chaleur intense (…) des niveaux d’humidité extrêmement bas et des vents pouvant atteindre 70 kilomètres par heure ou plus »
- “Des pics à 50 degrés à Genève sont tout à fait possibles dans 20 ans” (rts.ch)

- Les manifestations anti-migrant·es en Afrique du Sud pourraient provoquer le pire épisode de violences depuis 2021 (legrandcontinent.eu)
Des manifestants anti-immigration ont fixé un ultimatum : tous les migrants en situation irrégulière doivent quitter le pays d’ici 30 juin.
- « Mal élu, Keir Starmer n’a fait qu’une politique de droite agressive » (politis.fr)
- Palantir : How a US spy-tech firm with links to Israel’s genocide infiltrated the British state (middleeasteye.net)
- Que deviennent les fûts de déchets radioactifs immergés dans l’Atlantique dans les années 1970 et 1980 ? Les débuts de réponse d’une expédition scientifique (theconversation.com)
Entre 1971 et 1982, plus de 200 000 fûts de déchets radioactifs furent immergés par plusieurs pays européens dans l’Atlantique Nord-Est, à des profondeurs atteignant plus de 4 700 mètres.
- L’OMS a une très bonne nouvelle au sujet de la contagion au hantavirus (huffingtonpost.fr)
« Aujourd’hui, la dernière personne ayant été en contact avec une personne exposée à l’hantavirus à bord du navire de croisière MV Hondius a terminé sa période de quarantaine, a été testée négative et est rentrée chez elle »
- PlayStation va supprimer chez ses client·es des films qu’iels ont pourtant achetés (next.ink)
PlayStation a prévenu ses client·es que les films et séries TV distribués par Studio Canal ne seront plus visibles à compter du 1er septembre. Pire : les contenus seront tout simplement supprimés des bibliothèques des utilisateurices. Malgré un achat en bonne et due forme…
Voir aussi Sony is deleting over 550 purchased movies from PS5 users’ digital libraries (videogameschronicle.com)
- Imprimantes en panne : le fabricant Epson en procès pour obsolescence programmée (reporterre.net)
Pour la première fois de l’histoire, le fabricant d’imprimantes Epson va être jugé pour délit d’obsolescence programmée et risque 300 000 euros d’amende.
- A New Lawsuit Claims the Memory Crisis Was Manufactured on Purpose (androidheadlines.com)
Samsung, SK Hynix, and Micron have been slapped with a class action lawsuit for price fixing and market manipulation of RAM. This is a big deal because these three companies together manufacture around 89 % of the entire global DRAM market. The suit says that “the DRAM oligopolists have simultaneously cut production, coordinated a pivot to HBM and exit from DDR3 and DDR4, and otherwise decreased and locked up conventional DRAM supply while prices charged up with mind-blowing scale and rapidity. Samsung, SK Hynix, and Micron continue to squeeze conventional DRAM supply, simultaneously and publicly directing their resources towards less profitable-per-die HBDM – or in some cases, simply junking conventional DRAM supply channels together.”
- Les data centers sont devenus la nouvelle mine d’or des cambrioleurs (slate.fr)
La ruée vers l’intelligence artificielle fait exploser la valeur des composants informatiques, au point de transformer les livraisons destinées aux centres de données en cibles privilégiées du crime organisé.
- Jusqu’à 46 °C ressentis : la Coupe du monde en alerte canicule (reporterre.net)
« Une vague de chaleur record et dangereuse va s’étendre cette semaine sur les deux tiers est du pays », ont prévenu les services météorologiques américains […] Au plus fort de l’épisode, la chaleur ressentie pourrait atteindre entre 40 et 46 °C à cause du très fort taux d’humidité.
- Gamblers Are Betting Millions of Dollars on California Wildfires (slate.com)
As prediction markets boom and a new wildfire season begins, fire survivors and ethicists say that the betting encourages and rewards callous thinking—and dangerous behavior, too.
- Les festivités ont à peine commencé pour les 250 ans des États-Unis qu’un morceau de la scène s’effondre (huffingtonpost.fr)
Par chance personne n’a été blessé, mais cet incident vient s’ajouter au flop des festivités organisées dans la capitale. Car à quelques mètres de là, se trouve la grande foire patriotique de Donald Trump. Et comme l’ont relevé plusieurs médias américains, elle n’a pas vraiment trouvé son public.
- Les États-Unis fêtent-ils aujourd’hui leur pire anniversaire ? (legrandcontinent.eu)
Violence politique, polarisation extrême, effondrement de la confiance : pour son 250e anniversaire, la plus ancienne démocratie constitutionnelle du monde se met elle-même en scène et le spectacle est celui d’un pays qui va jusqu’à douter de sa propre continuité.

- 250 ans des États-Unis : Trump impose sa vision, les entreprises françaises suivent (multinationales.org)
Donald Trump tente de s’approprier la célébration du 250e anniversaire de l’indépendance des États-Unis à travers une organisation à sa botte qui organise des journées de prières et des spectacles de combat. Des travaux d’« embellissement » ont été lancés dans la capitale Washington, comme la construction d’un arc de triomphe et d’une immense salle de bal à la Maison Blanche.
- Lawmakers Must Act Now to Prevent Armed Police Drones (eff.org)
This is not science fiction. It’s not premature. If towns, cities, states, or the federal government want to act to reign in the emergence of armed police drones and robots, we have precious little time.
- ICE Flouting Federal Judge’s Order to Stop Arresting Immigrants at New York Courts (theintercept.com)
“ICE continues to flagrantly violate the law by arresting immigrants who are attending their mandatory court hearings”
- Le Pérou bascule à l’extrême droite avec l’élection de Keiko Fujimori (reporterre.net)
À la suite d’un mois de dépouillement, la fille de l’ancien autocrate Alberto Fujimori, Keiko Fujimori, a été élue présidente du pays. La dirigeante du parti Fuerza Popular (FP, Force populaire), mouvement politique brassant de la droite conservatrice à l’extrême droite autoritaire, devrait prendre ses fonctions le 28 juillet, pour un mandat de cinq ans.
- L’État chilien va condamner quatre jeunes guerriers mapuche à des dizaines d’années de prison (nantes.indymedia.org)
Spécial IA
- IA : les centres de données émettent bien plus de CO2 qu’estimé, selon Allianz Trade (france24.com)

- Women Who Use AI Seen As Incompetent ; Men Who Use AI Seen As Pragmatic (forbes.com)
the AI use penalty may be even larger for older women, women of color, or other women who face intersectional sources of bias.
- Claude : la politique de confidentialité a changé, et utiliser le chatbot “éthique” d’Anthropic n’a plus rien d’anodin (lesnumeriques.com)
Reconnaissance faciale, données partagées avec la police, droit d’opposition réduit : la nouvelle réalité des abonné·es Claude
- How a seemingly harmless image can jailbreak AI (nerds.xyz)
- The Linux Foundation Uses DNS to Give AI Agents a Trusted Identity (linuxinsider.com)
- Open source game engine Godot will no longer accept AI-authored code contributions : ‘We can’t trust heavy users of AI to understand their code enough to fix it’ (pcgamer.com)
- Cheap PCs being priced out of existence as memory cost bites (theregister.com)
AI server gold rush leaves budget laptops starving for chips as sub-$500 machines down nearly a fifth stateside
- Ford rehires human engineers after AI fails to match quality checks (bbc.com)
the firm has rehired more than 300 “veteran” quality inspectors in recent years to make up for the pitfalls of automated systems.

- Bosses Horrified as “AI Native” College Graduates Hit the Workplace (futurism.com)
Massive numbers of students are going to emerge from university with degrees, and into the workforce, who are essentially illiterate.
- The AI Industry Is Losing (wheresyoured.at)
I’m sorry man, you have an addiction, and I worry it’s ruining your life. What is this producing ? What are you actually doing with this time ? Because if you’re allegedly 100 times more productive, wouldn’t that, y’know, produce something fairly incredible ? I have no idea — and don’t want to put this man on blast — how significant his commitments on GitHub may or may not be, but the return on investment of “obsessively checking your laptop at all times in case you might not be productive” should be something on the order of curing a disease.
- The EU spends billions on AI, but can anyone track the money ? (edri.org)
The European Union has pledged billions to establish itself as a global leader in artificial intelligence (AI). However, there is a significant transparency gap between the political announcements and the actual flow of money. ‘From Frameworks to Factories’, a new report by Open Future , maps the EU’s AI investment architecture and asks a simple question : Can the money be followed ?
- IA krach ? (blog.mondediplo.net)
Qu’est-ce qu’une bulle ? C’est une croyance collective. Qu’est-ce qu’un krach ? C’est l’effondrement de la croyance qui fit la bulle. Avec l’Intelligence artificielle (IA), nous sommes servis : nous avons deux bulles pour le prix d’une.

Spécial guerre(s) au Moyen-Orient
- Violences sexuelles sur les Palestinien·nes : une arme de la colonisation israélienne (humanite.fr)
Viols, tortures, humiliations : dans un rapport rendu public ce 1ᵉʳ juillet, deux ONG documentent les violences sexuelles dont sont systématiquement victimes Palestiniens et Palestiniennes, dans la logique coloniale et génocidaire du gouvernement israélien.
- “Si nous refusions de partir, ils allaient nous tuer” : en Cisjordanie, la hausse des attaques par les colons israéliens (radiofrance.fr)
- Israel Installs Cranes Equipped With Unmanned Machine Guns to Kill Gazans (novaramedia.com)
- Gaza : tirez sur les enfants d’abord (la-bas.org)
Ciblage délibéré des enfants par l’armée israélienne dans la bande de Gaza. C’est la conclusion d’un important rapport d’une commission de l’ONU publié ce 18 juin, repris à travers le monde et qui confirme qu’Israël commet un génocide à Gaza.
Spécial femmes dans le monde
- Trafficked, beaten and raped : raids reveal scale of abuse of women in Asia’s cyberscam centres (theguardian.com)
- Non à la normalisation et à la reconnaissance des talibans ! Oui à a reconnaissance des droits et de la liberté des femmes, des filles et des familles d’Afghanistan ! (humanite.fr)
Présidente de Negar-Soutien aux femmes d’Afghanistan, Shoukria Haidar, interpelle les parlementaires européens et la Commission européenne sur la normalisation des relations avec les talibans.
- Prendre davantage en compte les femmes dans les essais cliniques et le développement des innovations thérapeutiques (theconversation.com)
- « Mère et ministre » : la suédoise Romina Pourmokhtari bouscule l’Union européenne avec son bébé (lesnouvellesnews.fr)
- « Vous êtes plus sensible qu’un clitoris » : une députée recadre un élu d’extrême droite (ledauphine.com)
Interrompue à plusieurs reprises par un élu d’extrême droite lors d’un débat au Bundestag sur les violences faites aux femmes fin mars, la députée allemande Kathi Gebel a rétorqué qu’il était « plus sensible qu’un clitoris ». Trois mois plus tard, la scène fait le tour des réseaux.
- Un réseau international qui rappelle l’affaire Pelicot découvert au Royaume-Uni, huit personnes arrêtées (huffingtonpost.fr)
Un réseau international d’agressions sexuelles facilitées par l’usage de drogues a été découvert au Royaume-Uni. Plus de 270 personnes ont été identifiées.
- Les sportives américaines transgenres bannies de compétitions féminines (france24.com)
La Cour suprême américaine a validé, mardi, les lois de plusieurs États interdisant aux sportives transgenres de participer aux compétitions féminines scolaires et universitaires. Donald Trump a salué une “grande victoire” pour les républicains.
- Maximum Lethality. Women in the Army Are More Likely to Be Killed by Fellow Soldiers Than Enemy Combatants (theintercept.com)
In many cases, women in the Army are killed by current or former romantic partners. Over 70 percent of victims had an intimate relationship with the perpetrator at one point
Spécial France
- La date de l’élection présidentielle 2027 est connue (huffingtonpost.fr)
L’élection présidentielle 2027 aura lieu les dimanches 18 avril et 2 mai, respectivement pour le premier et le second tour.
- Manifestations syndicales ou réserve électorale ? Le casse-tête du 1er-Mai 2027, veille de second tour présidentiel (lcp.fr)
- Philippe Poutou et le NPA renoncent à la présidentielle et se rangent derrière Jean-Luc Mélenchon (huffingtonpost.fr)
- Bernard Arnault soumis à un redressement fiscal de 22,5 millions d’euros (franceinfo.fr)
Le patron de LVMH a déposé un recours devant le Conseil d’État

- Notre-Dame a encore besoin de plus de 100 millions d’euros pour finir sa restauration (huffingtonpost.fr)
Si les dégâts de l’incendie de 2019 ont été entièrement réparés, il reste encore 130 millions d’euros à réunir pour financer des travaux complémentaires programmés jusqu’en 2033.
- Coupe du monde : face à l’omniprésence des paris sportifs, Addictions France alerte (addictions-france.org)
À l’occasion de la Coupe du monde, Addictions France lance une campagne d’interpellation pour dénoncer l’omniprésence du marketing des paris sportifs et ses conséquences néfastes sur la population. Dans un contexte où les incitations à parier sont partout, à la télévision, sur les réseaux sociaux, dans l’espace public, Addictions France alerte sur l’urgence de protéger les publics.
- Cet été à Paris, vous pourrez vous baigner dans la Seine, au bras Marie, à Grenelle, à Bercy (et toujours) au canal Saint-Martin (huffingtonpost.fr)
- 1 700 rivières contaminées en partie : la carte inédite de la pollution chimique des cours d’eau en France (reporterre.net)
- Jean-Luc Mélenchon propose de refaire la carte des régions (huffingtonpost.fr)
Le candidat de La France insoumise propose de supprimer les régions actuelles pour en créer de nouvelles, imaginées autour des fleuves et des rivières.
- À Wissous, la démocratie confisquée pour un data center dédié à Amazon (fne-idf.fr)
- Canicule : Les Écologistes déposent leur motion de censure contre le gouvernement (reporterre.net)
- Appel aux dons après l’annulation de Solidays : “L’avenir de Solidarité Sida est clairement en suspens” (telerama.fr)
Annulé en raison de la canicule ce week-end, le festival parisien estime ses pertes à 3 millions d’euros. Son directeur appelle à renflouer l’association Solidarité Sida, ainsi privée de 70 % de ses ressources.
- Près de 7 000 départs de feu : la saison des incendies commence violemment en France (reporterre.net)
- « Si on n’a pas de pluie, on va être très, très mal » : une sécheresse intense assèche la France (reporterre.net)
La sécheresse est là et elle est massive. Au 2 juillet, 30 départements français étaient placés en niveau de crise sécheresse. Au total, 96 départements avaient franchi des seuils de vigilance ou d’alerte sécheresse. C’est plus que les 85 départements concernés à la même période en 2022, année d’une sécheresse estivale historique.

- Pourquoi les retards de train se multiplient pendant la canicule ? (reporterre.net)
- Jusqu’à 38°C ce week-end : la vague de chaleur démarre fort (meteo-paris.com)
les scénarios les plus alarmants envisagent une extension de la chaleur vers le nord de la France durant la deuxième semaine de juillet, avec un risque de températures supérieures à 35°C sur de nombreuses régions et, dans les hypothèses les plus extrêmes, des pointes pouvant dépasser 40°C jusque sur certaines régions du nord.
- L’AMOC, courant marin chaud de l’Atlantique, ralentit (et ce n’est pas une bonne nouvelle pour le climat de la France) (20minutes.fr)
Spécial femmes en France
- « Elles bougent » : les rôles modèles changent l’avenir des filles (lesnouvellesnews.fr)
En rencontrant des femmes ingénieures, techniciennes ou expertes du numérique, avec l’association Elles bougent les filles modifient leur regard sur les métiers scientifiques et osent davantage s’y projeter.
- Des budgets d’hommes, « Des hordes de Brad Pitt » : ces députées qui ne laissent rien passer (lesnouvellesnews.fr)
Entre injonctions sexistes au sourire et répartition très genrée du pouvoir à l’Assemblée nationale, les députées Ayda Hadizadeh et Gabrielle Cathala ont dénoncé le patriarcat parlementaire.
- « Qu’est ce qui autorise les hommes ? », par Maïtena Biraben, Laura Smet, Caroline Roux et Gisèle Pélicot (latribune.fr)
- La mère de la petite Rosa a porté plainte contre Gérald Darmanin pour non-assistance à personne en danger et mise en danger de la vie d’autrui. (huffingtonpost.fr)
Jérôme Barella est le principal suspect dans le viol et la mort de Lyhanna, 11 ans […] Il n’avait jamais été inquiété jusque-là, alors qu’il était notamment visé par une plainte déposée en août 2025 par la mère de Rosa, une enfant également âgée de 11 ans l’accusant de viols.

- Bruel visé par trois nouvelles plaintes, dont une pour agression sexuelle sur mineure (huffingtonpost.fr)
Spécial médias et pouvoir
- Marc Bloch au Panthéon : l’éditocratie gâche la fête (acrimed.org)
Marc Bloch et son épouse Simonne Vidal sont entrés au Panthéon mardi 23 juin, sous un cortège de commentaires dépolitisants et de falsifications de la mémoire de l’historien résistant.
- Le contrat qui prouve qu’Erik Tegnér agissait comme un agent d’influence du pouvoir hongrois (streetpress.com)
StreetPress a obtenu le contrat d’Erik Tegnér, directeur du média d’extrême droite Frontières, avec le Danube Institute. Pour 4.200 euros par mois, il devait aider à promouvoir les discours d’Orbán en France, en parallèle du lancement de son média.
- Canicule : quand médias et politiques rejouent les pires répliques des films catastrophe (politis.fr)
Politiques, journalistes et chroniqueurs ont excellé dans le pire, du déni au mépris des scientifiques. […] Dans cette catégorie, la palme revient à Luc Ferry […] : « Mon père s‘est évadé quatre fois des camps nazis. Il faisait très chaud aussi, surtout dans le four qu’on avait préparé pour lui. C’est invraisemblable. On est quand même capable de supporter ça ! »
- CNews : QuotaClimat en appelle au Conseil d’État pour faire condamner le climatoscepticisme de la chaîne (reporterre.net)
- Guillaume Erner sanctionné mais maintenu à l’antenne de France Culture après des extraits fallacieux sur Mélenchon (telerama.fr)
L’animateur de la matinale de France Culture a écopé d’une “sanction disciplinaire” qu’il n’a pas contestée “au vu de [ses] responsabilités et de la gravité de [sa] faute”.
- Les magasins Relay, ligne de front dans la croisade politique de Vincent Bolloré (multinationales.org)
Contrôlée par Vincent Bolloré, l’enseigne détient le quasi-monopole de la vente de presse et de livres dans les gares françaises, grâce à un contrat avec la SNCF renouvelé en 2023. La forte visibilité des titres d’extrême droite et le récent refus de distribuer un livre-enquête sur Bernard Arnault nourrissent les soupçons d’instrumentalisation politique.
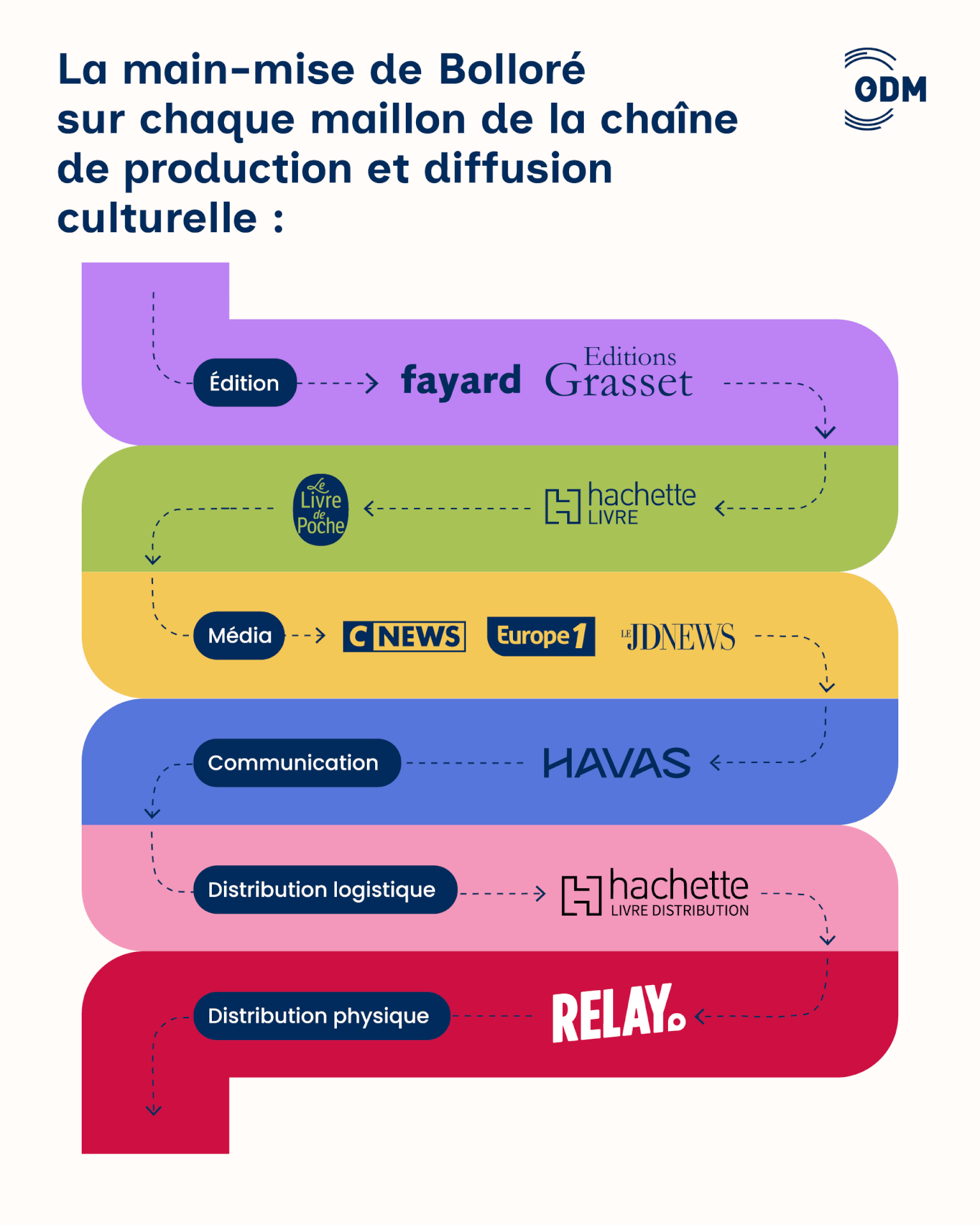
- Édition : il faut sauver les indés (blogs.mediapart.fr)
L’offensive menée par Vincent Bolloré tend à focaliser l’attention sur sa personne, au risque d’occulter le phénomène qui la rend possible : la concentration progressive et de plus en plus hégémonique du monde de l’édition. Alors qu’un distributeur fait face à un risque de faillite, plusieurs dizaines de maisons d’édition indépendantes alertent sur un possible effondrement de tout leur écosystème et appellent à un sursaut collectif pour sauver la pluralité éditoriale.
Soutenir
- Il reste 20 jours et il manque encore 1000€ de contributions pour que le prochain numéro de Curseurs soit financé ! (fr.ulule.com)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Nouvelle dissolution avant la présidentielle 2027 ? Une « instrumentalisation » de la Constitution que rien n’interdit (publicsenat.fr)
Un scénario peu envisagé jusque-là pourrait bousculer la campagne : la tenue d’élections législatives anticipées suite à une dissolution de l’Assemblée nationale. C’est la folle rumeur qui circule dans le camp d’Emmanuel Macron, relayée par Le Figaro et L’Opinion. Le Président songerait de nouveau à actionner l’arme de la dissolution, comme un ultime coup de poker pour contrecarrer les plans des oppositions, RN et LFI en tête
- Au salon de l’armement Eurosatory, la France cherche son « Palantir européen » (synthmedia.fr)
- Financement des armées : le Parlement adopte définitivement un budget porté à 436 milliards pour la période 2024-2030 (franceinfo.fr)
- [La France compte 35 000 millionnaires de plus en un an, selon le dernier rapport d’UBS (https://www.franceinfo.fr/replay-radio/le-decryptage-eco/la-france-compte-35-000-millionnaires-de-plus-en-un-an-selon-le-dernier-rapport-d-ubs_8061521.html) (franceinfo.fr)
- Loi d’urgence agricole : le Sénat approuve la réintroduction de deux pesticides interdits (huffingtonpost.fr)
Le Sénat a voté la réintroduction dérogatoire et encadrée de deux insecticides interdits en France.
Voir aussi Loi d’urgence agricole : pesticides, eau, élevages… le Sénat adopte le texte en version Duplomb (humanite.fr)
Une version du projet de loi d’urgence agricole qui pousse encore plus loin la déréglementation environnementale a été adoptée au palais du Luxembourg vendredi 3 juillet dans la nuit. Malgré l’opposition de la gauche, le texte a été voté à 219 voix contre 111.

- Retour en avion, traiteur de luxe… un déplacement de la ministre de la Transition écologique fait polémique (ledauphine.com)
- Attaqué sur la canicule, Lecornu « sort de ses gonds » à l’Assemblée : « c’est scandaleux et indigne ! » (huffingtonpost.fr)
- Crise du logement : il est temps de regarder du bon côté de la chaîne de responsabilité (politis.fr)
Alors que la France traverse un épisode de canicule dramatique, avec des températures records et déjà plusieurs morts au compteur, le gouvernement va étudier en conseil des ministres un projet de loi visant notamment à reculer de 5 ans l’obligation de rénovation des passoires thermiques pour leur mise en location.
- MaPrimeRénov’, la prime qui ne chauffait personne (frustrationmagazine.fr)
MaPrimeRénov’ ressemble à ça : une aide publique qui se revendique ambitieuse, qui occupe le terrain médiatique, qui permet à n’importe quel ministre de sortir un chiffre impressionnant en conférence de presse, et qui, à y regarder de près, a surtout permis à l’État de se féliciter pendant que les logements continuaient de cramer.
- Exclusion des étudiant·es hors Union européenne non boursier·es : le gouvernement passe en force (gisti.org)
Le décret visant à exclure des aides au logement les étudiants hors Union européenne non boursiers a été publié le dimanche 28 juin, malgré l’opposition, fin mai, de l’ensemble des membres du conseil national de l’habitat. Les étudiant·es qui perdront près de 200 € par mois sont, contrairement à ce qu’affirme le Ministre du logement, très largement des étudiant·es pauvres.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Quatre questions sur la nouvelle affaire qui éclabousse le RN au Parlement européen, autour de soupçons de détournement de fonds par un groupe de partis d’extrême droite (franceinfo.fr)
La justice européenne soupçonne l’ex-groupe Identité et démocratie, où siégeait le RN, d’avoir “indûment dépensé” plusieurs millions d’euros entre 2019 et 2024. Une enquête est ouverte depuis l’an dernier, mais des perquisitions ont eu lieu dans des entreprises proches du parti.

- Justice : l’Assemblée nationale approuve la consultation de bases génétiques privées pour résoudre certaines enquêtes criminelles (lemonde.fr)
La gauche s’est vivement opposée à cette mesure. Ces dispositions portent « une atteinte disproportionnée au respect de la vie privée »
- Le droit d’association : un fondement de notre démocratie aujourd’hui fragilisé (theconversation.com) – voir aussi Associations : l’engagement résiste, les financements s’érodent (theconversation.com)
- Claire Hédon, Défenseure des droits : « On maltraite notre jeunesse » (politis.fr)
À un mois de quitter ses fonctions, […], Claire Hédon dresse un bilan sévère de six années en tant que Défenseure des droits […] elle alerte surtout sur une jeunesse « malmenée » : jeunes des quartiers populaires visés par les contrôles au faciès, multiverbalisations qui peuvent conduire au surendettement, mineurs en attente de scolarisation ou enfants handicapés privés d’un accompagnement adapté.
- « La justice n’existe plus » : le Conseil d’État valide définitivement la poursuite du chantier de l’autoroute A69 (vert.eco)
La plus haute juridiction administrative française a donné son feu vert définitif à ce projet contesté d’autoroute entre Toulouse et Castres, ce lundi. Elle considère qu’il répond bien à une « raison impérative d’intérêt public majeur », condition nécessaire à la destruction d’espèces protégées sur le tracé.
Voir aussi « C’est officiel » : l’autoroute A69 définitivement validée par le Conseil d’État (reporterre.net) et A69 : Un tiers du prix du péage de l’autoroute sera pris en charge par les contribuables (france3-regions.franceinfo.fr)
Spécial résistances
- Militant·es des mouvements sociaux, artistes, citoyen·nes : organisons-nous pour soutenir la campagne de Jean-Luc Mélenchon ! (politis.fr)
Des militant·es des mouvements sociaux et citoyens, non-membres de La France insoumise, appellent à soutenir la candidature de Jean-Luc Mélenchon, seule candidature crédible de rupture avec le système, et à s’organiser pour permettre une implication collective, autonome et populaire dans la campagne.
- Numérique : l’ère du soin (lab.noesya.coop)
Nous refusons la colonisation de nos imaginaires par une bande de vieux adolescents mégalomanes. Nous avons vécu d’autres mutations techniques : l’informatique personnelle, la publication assistée par ordinateur (PAO), la photographie numérique, le web, le commerce en ligne… Nous saurons intégrer les larges modèles de langages dans nos diverses pratiques, avec calme et responsabilité, en mesurant à la fois les bénéfices réels (pas le récit publicitaire) et les risques réels (cognitifs, écologiques, sociaux, politiques…). Nous ne sommes pas en retard dans une course absurde vers la destruction du vivant, nous sommes en avance dans une nécessaire et inéluctable désescalade numérique.
- « Pas de volets, pas de loyer ! » : la fronde des locataires face aux canicules mortelles (lareleveetlapeste.fr)
- Victoire dans l’affaire Geneviève Legay : la Cour d’appel de Lyon confirme la sanction contre le commissaire Souchi (france.attac.org)
Ce lundi 29 juin 2026, la Cour d’appel de Lyon a rendu son délibéré dans l’affaire Geneviève Legay : le commissaire Rabah Souchi a été condamné à 6 mois de prison avec sursis, comme en première instance. Il s’agit d’une condamnation historique. Toutefois, cette peine n’étant pas inscrite à son casier judiciaire, Rabah Souchi pourra continuer d’exercer dans le maintien de l’ordre.
- Entretien avec Assa Traoré : 10 ans de combat pour Adama (histoirescrepues.fr)
- « C’était David contre Goliath » : récit d’une victoire contre un méga entrepôt (reporterre.net)
Grâce à une alliance entre militant·es, associatifs et politiques, des collectifs ont réussi à faire reculer le grand projet d’entrepôts Green Dock qui aurait menacé une réserve en Île-de-France.
- Chlordécone : 500 parties civiles se pourvoient en cassation (reporterre.net)
Énième rebondissement dans l’affaire qui oppose l’État aux victimes de la chlordécone. Plus d’un demi-millier de parties civiles se pourvoient en cassation, a déclaré le 30 juin l’un de leurs avocats, Me Christophe Lèguevaques. Objectif : contester la confirmation du non-lieu dans ce scandale sanitaire secouant la Martinique et la Guadeloupe depuis plus de trois décennies.
- Face à un « système qui les broie », des agriculteurices soutenu·es par des bénévoles (reporterre.net)
En Gironde, une association vient en aide aux agriculteurices en grande difficulté, parfois au bord du suicide. Sa poignée de bénévoles leur offre une aide juridique, administrative, et surtout un soutien psychologique.
Spécial outils de résistance
- Rapport du World Inequality Lab : 50 ans après, le nouveau rapport Meadows ? (bonpote.com)
si l’intégralité des gains de productivité horaire engrangés en Europe depuis les années 1960 avait été convertie en temps libre plutôt qu’en production supplémentaire, nous travaillerions aujourd’hui autour de 450 à 500 heures par an – une dizaine d’heures par semaine. Dans les faits, le temps de travail n’a reculé que d’un quart depuis les années 1960, parce que les trois quarts de ces gains ont servi à produire et à consommer davantage. En ce sens, la semaine de 25 heures du WIL ne fait que rattraper une partie du temps libre que nous aurions pu nous offrir depuis un demi-siècle.
- Plus de 100 000 signatures contre une proposition de loi sur l’usage des armes par les forces de l’ordre (huffingtonpost.fr)
Cette pétition s’oppose à la proposition de loi « visant à reconnaître une présomption de légitime défense pour les forces de l’ordre ».
La pétition à signer : Contre la présomption de légitime défense pour les forces de l’ordre (petitions.assemblee-nationale.fr)

Spécial MAGAM et cie
- Google’s New reCAPTCHA Wants Your Camera Access and 21 Points of Your Hand (reclaimthenet.org)
The same company that monetizes everything you do online would like to switch on your camera.
- European digital ID wallets are a gift to Google and Apple (osnews.com)
European governments are rolling out digital identity wallets, which are to be used by citizens to access services, and to verify their age online. As reported by Follow the Money and Android Authority, there is a serious problem with this : these wallets rely on safety services of Google and Apple. These are known as Google Play Integrity API, and Apple’s Managed Device Attestation. Such safety services (known as “remote attestation”) are used to ensure that wallet apps run on hardware that is not tampered with […] by embedding these safety services in public infrastructure, Europe risks making society dependent on private companies while serving their corporate interests.
- Google va lancer ses résumés par IA en France (france24.com)
Faire une recherche sur Google et avoir en réponse un résumé grâce à l’intelligence artificielle : le géant américain s’apprête à lancer en France cette fonctionnalité, qui fait planer sur les médias une lourde menace de baisse de trafic.
- Google perd son recours européen, amende record de plus de 4 milliards d’euros confirmée (france24.com)
La Cour de Justice de l’Union européenne a confirmé, jeudi, l’amende de 4,1 milliards d’euros à l’encontre de Google pour abus de position dominante dans l’écosystème des téléphones mobile. Bruxelles avait infligé cette amende à l’entreprise américaine en 2018, la plus lourde qui ait été imposée par l’UE à ce jour.
- Amazon has enough satellites to launch its Starlink competitor (theverge.com)
Amazon says it now has enough satellites operating in low-Earth orbit to light up its Starlink internet competitor. With last night’s launch, Amazon Leo has 396 satellites deployed, which is “enough to support continuous service across initial latitudes,” according to Chris Weber, VP heading up business and product for Amazon Leo.
- Microsoft worker emails thousands of colleagues about company’s support for genocidal Israel (thecanary.co)
On his final day at the company, a Microsoft worker in Italy has sent out an email to thousands of colleagues informing them of how the corporation operates as the technological backbone of the Gaza holocaust perpetrated by Israel.
Les autres lectures de la semaine
- Palantir et l’illusion de la souveraineté (legrandcontinent.eu)
- Ne leur donnez jamais votre visage (danslesalgorithmes.net)
- What happened to the fight for the internet ? (dustycloud.org)
- Le fantasme de l’efficacité fasciste (legrandcontinent.eu)
De Madrid à Buenos Aires, les droites populistes ressuscitent les mythes des dictatures et imposent un récit où le chaos de la démocratie serait l’obstacle à la prospérité économique.
- « La transition écologique n’a pas lieu car elle est piégée dans la logique du capitalisme » (politis.fr)
Nous sommes collectivement en train de comprendre que le capitalisme ne peut pas fonctionner sans croissance. Une économie capitaliste qui produit et consomme moins entre forcément en crise, avec toutes les conséquences néfastes que l’on connaît. Il va donc falloir imaginer une autre architecture économique qui puisse « prospérer sans croissance »
- « Notre travail gratuit est le secret le mieux gardé de la société de marché » (la-croix.com)
Aidant·es familiales, bénévoles, client·es mis·es à contribution pour installer un appareil, renseigner des données : l’économie moderne se nourrit d’activités contributives non rémunérées qui représenteraient 28 000 € par an et par Français·e selon l’experte Carole Lipsyc. Un angle mort dans la réflexion sur la création de valeur.
- Le 4‑Juillet : une date inventée, un mythe construit, un récit disputé (theconversation.com)
L’indépendance des États-Unis n’a pas été déclarée le 4 juillet 1776. Elle l’a été le 2 juillet. Que s’est-il passé le 4 ? Le Congrès a adopté un texte. Un texte qui allait devenir, en deux siècles et demi, le document le plus sacré d’une nation qui ne se réclame d’aucune religion d’État. Le 4-Juillet est moins une date qu’un récit.
- « Quand les femmes écrivaient l’Histoire » : Cécile Michel rehabilite les femmes libres d’il y a 4000 ans (lesnouvellesnews.fr)
À travers une étude minutieuse d’archives, Cécile Michel corrige une Histoire patriarcale. Dans « Quand les femmes écrivaient l’Histoire », l’historienne dresse 24 portraits de Mésopotamiennes indépendantes afin de rompre avec un récit qui minimise le rôle des femmes.
- Misogynie et botanique : comment le patriarcat s’est infiltré dans nos jardins (reporterre.net)
Des savoirs effacés et des noms de plantes sexistes : une balade organisée par l’association Les Mutines indigènes, dans le Gard, a permis de mesurer les biais qui parcourent encore le monde de la botanique.
- « Petite Casbah », une histoire (post)coloniale entravée (orientxxi.info)
Le projet éditorial Petite Casbah édité par les éditions Bayard Jeunesse, tiré du dessin animé éponyme, a subi de nombreuses interventions en cours d’écriture. La doctorante Laura Orban, un temps coautrice, explique pourquoi elle a décidé de retirer sa signature, et analyse en quoi cette expérience est un révélateur de logiques plus générales à l’œuvre dans l’écriture et dans la transmission de l’histoire coloniale
- Les dettes de la colonisation (cadtm.org) Comment la Banque mondiale a transféré aux États indépendants les dettes des puissances coloniales
- « Juneteenth Independence Day » : le long combat des Afro‑Américain·es pour l’accès à l’éducation après l’abolition de l’esclavage (theconversation.com)
Contraction des mots « June » (juin) et « nineteenth » (dix-neuvième), le Juneteenth, qui marque l’émancipation des esclaves aux États-Unis, est devenu un jour férié en 2021.
Les BDs/graphiques/photos de la semaine
- Actions
- Mirage
- Enseignements
- Piscine
- Police
- Rappel
- Avant-Après
- Tests
- Bolloré
- Tutrice
- Arnault
- Duplomb
- Why
- King
- Extinction
- Global warming
- Deep down
- Easy
- Meaningless
- Crash
- Reverse
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Honest Government Ad : Palantir (tube.fdn.fr)
- Les médias contre Mélenchon et LFI : 15 ans de diabolisation (acrimed.org)
- Inventer de faux antisémites, légitimer de vrais racistes (video.blast-info.fr)
- Extrême droite et féminisme d’État : aux origines du fémonationalisme (spectremedia.org)
- La France devient-elle plus dangereuse pour les personnes LGBT ? (humanite.fr)
- « La guerre la plus meurtrière après la seconde guerre mondiale est en cours » – et personne n’en parle (reporterre.net)
derrière chaque téléphone, chaque ordinateur, chaque voiture électrique il y a des parcelles de métaux, du cobalt, du coltan du cuivre, et derrière les métaux, il y a du sang, la guerre, les morts, la misère. C’est ce que nous explique David Maenda Kithoko dans cet entretien
Les trucs chouettes de la semaine
- Des chercheureuses ont trouvé comment rajeunir votre cerveau… grâce à une transplantation de selles (slate.fr)
Et si la clé de la jeunesse du cerveau se trouvait dans les intestins ? C’est la piste que suit une nouvelle étude menée par des chercheureuses américain·es et italien·nes […] Transplanter des matières fécales de jeunes souris dans des souris âgées permettrait en effet de restaurer la capacité de leur cerveau à former de nouvelles connexions.
- Santé au travail dans les collectifs horizontaux (santeautravail.enliberte.fr)
Collectifs “à plat”, “horizontaux”, “sans chef·fes”, “sans lien de subordination”… Nombreux sont les exemples de structures qui se réclament de ces modèles, rendant ainsi la fonction employeuse floue et peu assumée. Pour autant, ces associations ou coopératives restent des organisations de travail, qui exposent leurs salarié·es à des risques pour leur santé mentale et physique, qu’on appelle “risques professionnels”. Ce site propose quelques outils qui peuvent être utiles aux travailleur·euses de ces collectifs pour verbaliser les risques auxquels iels sont exposé·es, en discuter collectivement et réfléchir à des mesures de prévention.
- “La mutualisation, ça marche à fond !” L’Adullact, le logiciel libre au service des collectivités (zdnet.fr)
- La mairie de la Croix-en-Touraine a pris une décision rare : abandonner Microsoft pour migrer vers Linux et les logiciels libres (developpez.com)
« Linux est beaucoup moins attaqué que Windows et demande moins de ressources. L’intérêt pour nous était de concilier tout ca pour faire pérenniser nos postes informatiques et qu’on soit mieux protégés sur nos données. C’est donc pour sécuriser les données confidentielles des 2000 habitants du village que ce choix a été fait »
- Logiciels libres, Linux : comment sortir de la dépendance à Google, Microsoft et Apple ? (telescopemag.fr)
Tous les premiers samedis du mois à la Cité des Sciences de Paris, des bénévoles proposent des ateliers pour aider à installer des logiciels libres. Une solution pour s’opposer au monopole des GAFAM dans le numérique, tout en prolongeant la durée de vie des ordinateurs et des smartphones face à l’obsolescence programmée.
- Open-source Krita hits 90 % of Photoshop’s capability as creators abandon Adobe subscriptions (blazetrends.com)
Krita just proved it isn’t just a toy for sketching. The team over at XDA Developers recently put the open-source painting app through a brutal benchmark test against Adobe Photoshop. The result ? Krita is matching about 90 % of Photoshop’s raw power for everyday digital art tasks. It handled heavy photo manipulation, complex layer masks, and detailed edits without breaking a sweat.
- Domaine Public : une histoire belge du Web indépendant (curseurs.be)
Créé au début des années 2000, Domaine Public héberge aujourd’hui plus de 400 collectifs, associations et acteurs du non-marchand en Belgique francophone. Aurélie et Denis nous racontent la genèse de ce projet, au carrefour de luttes bruxelloises et de celles pour le logiciel libre et le web indépendant.
- Les sans pagEs et le Wiktionnaire : féminisme et dictionnaire dans la galaxie Wikimédia (zdnet.fr)
Les sans pagEs, qui œuvrent à diminuer les biais de genre dans Wikipédia et les projets associés, fêtent leurs 10 ans

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).