
22.06.2026 à 07:42
Khrys’presso du lundi 22 juin 2026
Texte intégral (8749 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Les jets privés ont toujours le vent en poupe : flambée du prix du pétrole ou pas, une poignée d’ultra-riches continuent de prendre l’avion sans compter (lindependant.fr)
Les vols en jet ont progressé de 4 % dans le monde, dopés par Cannes, Monaco et les grands événements sportifs, symbole d’une économie toujours plus inégalitaire.
- Un tiers de l’humanité doit s’endetter pour vivre (theconversation.com)
L’endettement des ménages est surtout évoqué à travers le prisme du pouvoir d’achat, du paiement fractionné ou du surendettement, mais il reste rarement analysé comme un phénomène social massif et structurel. Une recherche récente s’efforce de quantifier cette « dette du quotidien » à l’échelle mondiale.

- Not just books – how renting a sewing machine from the library can improve democracy (bbc.com)
Finland’s libraries are increasingly being valued not by how many books they lend, but how they help societies function.
- Autorisation illimitée de pesticides : l’Europe recule pour le moment (basta.media)
Omnibus, c’est le nom d’un projet de règlement poussé par la Commission européenne, qui déroule le tapis rouge aux fabricants de pesticides. Aucun accord n’a finalement été trouvé par les États membres de l’UE. On vous raconte cette bonne nouvelle.
- Le Parlement européen donne son feu vert à une nouvelle génération d’OGM (basta.media)
Des eurodéputés du centre, de la droite et de l’extrême-droite ont voté ce 17 juin en faveur des nouvelles techniques génomiques. Aucun étiquetage n’est prévu sur les aliments. Les mouvements paysans annoncent saisir la Cour de justice européenne.
- EU to soon classify AWS and Azure as gatekeepers under DSA (heise.de)
As gatekeepers, AWS and Azure would be obliged to ensure interoperability and data portability. This would, for example, simplify switching cloud providers and allow customers to link other services with AWS or Azure clouds, instead of being limited to AWS and Azure offerings. Significant fines could also be imposed if the cloud services are found to be in violation of existing regulations.
- L’Europe veut libérer le potentiel des données de santé (theconversation.com)
Avec son Espace européen des données de santé (EEDS), l’Union européenne (UE) est confrontée à un défi de taille : comment exploiter la valeur scientifique et économique des données de santé, tout en garantissant la sécurité de l’infrastructure qui les héberge et son alignement sur les intérêts et les valeurs européennes ?
- Immigration : le Parlement européen adopte le règlement qui autorise les « centres de retour » en dehors de l’Union (publicsenat.fr)
Les eurodéputé·es ont adopté mercredi le règlement controversé qui autorise la rétention de migrant·es expulsé·es, et les débouté·es du droit d’asile dans des centres situés dans des pays hors de l’Union européenne. Ce vote est l’aboutissement d’une alliance inédite à Bruxelles entre la droite et l’extrême droite
- L’Europe dépense des milliards pour renvoyer les migrant·es : pourquoi cette stratégie ne fonctionne pas (theconversation.com)
- Le chêne légendaire de Robin des Bois est mort, victime de la chaleur et du tourisme (reporterre.net)
- Scan your eyeballs, think of the children : how Britain sells surveillance as safety (thenerve.news)
Keir Starmer’s under-16 social media ban can only work if everyone proves who they are. It is the natural conclusion of the Online Safety Act – and of a Brexit that was always about control, says digital rights advocate Heather Burns
- ICE plans to give local police facial recognition app for immigration enforcement (biometricupdate.com)
- Facial Recognition on Public Buses ? Kansas City Says Yes (yro.slashdot.org)
- États-Unis : moins d’un an après son ouverture, le centre de détention pour migrant·es « Alligator Alcatraz » ferme ses portes (rfi.fr)
Inauguré en juillet 2025 à l’initiative du gouverneur républicain Ron DeSantis dans le parc naturel des Everglades, en Floride, le centre […] était devenu l’un des symboles de la politique anti-migrant·es menée aux États-Unis. Jusqu’à 1 400 personnes y ont été retenues dans des conditions de détention particulièrement difficiles.
- Trump a trouvé le coupable du fiasco de la coûteuse rénovation de ce bassin à Washington (huffingtonpost.fr)
Alors que la peinture tout juste appliquée se décolle sur le miroir d’eau, le président des États-Unis pointe du doigt « les extrémistes de gauche ».

- Leak Exposes Members of Peter Thiel’s Secretive ‘Dialog’ Society (wired.com)
A trove of internal records from a secret society for powerful figures in US politics, finance, and tech was left exposed online […] naming participants in its events and revealing sensitive personal details they were assured would stay private.The group, called Dialog, is a private, invitation-only organization cofounded in 2006 by the billionaire tech investor Peter Thiel.
- Océans : Trump renonce à démanteler un système de surveillance crucial pour le climat (reporterre.net)
- Ce satellite va s’écraser sur Terre, la NASA veut envoyer un robot pour le sauver (slate.fr)
L’agence spatiale prépare une opération sans précédent pour tenter de prolonger la vie de l’observatoire spatial Swift, qui subit une dégradation progressive de son altitude qui le rapproche inévitablement d’une rentrée atmosphérique.
- Un séisme catastrophique semble « dangereusement proche » en Californie, alerte une étude (slate.fr)
Les failles géologiques de San Andreas et San Jacinto ont atteint leur niveau de contrainte tectonique le plus élevé depuis 1.000 ans.
- Un cimetière de baleines vieux de 5,3 millions d’années découvert au fond de l’océan Indien (theconversation.com)
Spécial IA
- WA police launch real-time AI camera surveillance “to catch criminals” (nine.com.au)
- Le fonds IA de Bernie Sanders ? Une idée plus courante qu’on le croit (next.ink)
Bernie Sanders propose de créer un fonds souverain qui permettrait à la population des États-Unis de participer aux profits générés par l’intelligence artificielle.
- IA : blocage d’Anthropic aux étrangers, son patron Dario Amodei, “pompier pyromane” pris à son propre jeu (radiofrance.fr)
Donald Trump a forcé Anthropic à bloquer ses meilleurs modèles aux ressortissants étrangers, un acte inédit révélant notre dépendance technologique aux produits américains . Dario Amodei est pris à son propre piège de “pompier pyromane” de l’IA.
- “Mythos” at Home, and It’s Called AISLE (aisle.com)
A startup out of Europe built an AI system that matches Mythos on zero-day discovery, using widely available models, even air-gapped. You’ve probably never heard of it.
- IA et Open Source : la fin du pillage de code grâce au copyleft de Yale ? (goodtech.info)
Vous en avez (vous aussi) assez de voir vos dépôts GitHub pillés par des modèles d’IA fermés ? Des chercheurs de Yale proposent la licence CCAI […] Son but ? Contraindre les développeurs d’IA à rendre publiques l’architecture et les données d’entraînement de leurs modèles dès lors qu’ils se nourrissent de code open source.
- Recommendations When Using LLM-backed Generative AI Systems for FOSS Contributions (sfconservancy.org)
The FOSS community should support, not just tolerate, those who outright reject LLM-gen-AI systems. There are many intersecting ethical and moral issues regarding these systems, many of which are not currently fully understood. Anyone who chooses to avoid them deserves our support and assistance.
- The Community is the Achievement ; the Achievement is the Community (linguacelta.com)
The distributed technology community is an absolute marvel. It knows more than any individual could ever hope to know. It is generous in sharing knowledge. At its best, it is patient and encouraging and collaborative. It wants to invite you in and tell you everything it knows. Your biggest problem may be getting it to stop when your brain is full. […] By asking LLMs to provide (often confidently incorrect) answers to their tech questions, developers are not only destabilizing professional communities of practice, but also neglecting to maintain the rich technological commons which has previously been built up from public discussions of questions and answers.[…] it isn’t possible to separate the professional from the political, or the technological from the ethical. When we try to do that, we end up with tech projects that discriminate against minoritized people, not because their creators particularly intended to discriminate, but because bias is endemic in every culture, and the community had no ethical guardrails requiring creators to check for that bias.
- Le coût caché de l’IA en entreprise : 6,4 heures par semaine à surveiller des robots (cio-online.com)
- Tension de la productivité : le goulot de la diffusion (danslesalgorithmes.net)
- OpenAI just exposed how bad AI still is at real science (nerds.xyz)
Artificial intelligence companies love to talk about how their models are transforming science. Depending on who you ask, AI is either on the verge of curing diseases, discovering new drugs, or completely reinventing research itself. OpenAI’s newly announced LifeSciBench benchmark, however, offers a much more grounded reality check.
- Is AI ruining our skills ? Early results are in — and they’re not good (nature.com)
Reliance on artificial-intelligence tools degrades the abilities of physicians and software engineers, studies show.

- 13 mots suffisent pour manipuler un résultat de recherche par IA (next.ink)
- On AI in research and astrophysics (lookingup.francois-rincon.org)
- Europe must choose between AI and climate goals, data center lobby says (politico.eu) Tech sector says only carbon-emitting gas plants are reliable enough today to power the EU’s AI goals.
- Exclusive : Conservatives plan nationwide protest against AI data centers (axios.com)
- Alors, pour vous en dessert, ce sera data centers ou transition énergétique ? (open.substack.com)
Spécial guerre(s) au Moyen-Orient
- C’est finalement depuis le palais de Versailles que Trump a signé l’accord avec l’Iran (huffingtonpost.fr)
Attendue vendredi en Suisse, la signature de l’accord entre Washington et Téhéran a finalement eu lieu plus tôt que prévu.
- Iran : une défaite pour Trump, un désastre pour Netanyahou (politis.fr)
L’accord de cessez-le feu avec l’Iran est bien fragile alors que les dirigeants israéliens ne rêvent que de le torpiller.
- Netanyahu Finally Learns the Truth About Trump (theatlantic.com)
An alliance with the president was the Israeli prime minister’s selling point. Now it may be his downfall.
- Le cessez-le-feu entre Hezbollah et Israël déjà violé, l’Iran réplique et ferme le détroit d’Ormuz (huffingtonpost.fr)
Des frappes israéliennes ont fait une quinzaine de morts au lendemain de l’annonce d’une trêve.[…] L’Iran n’a pas tardé à répondre aux frappes en annonçant la fermeture du détroit d’Ormuz
- US-Iran Talks Delayed as ‘Renewed Israeli Aggression’ in Lebanon Kills at Least 18 (commondreams.org)
One Lebanese writer reported that Israeli forces were “committing massacres” in residential areas across southern Lebanon, threatening to derail progress toward a US-Iran peace deal.
- « Ma peau a été complètement brûlée » : au Liban, les ravages du phosphore blanc, largué illégalement par l’armée israélienne (vert.eco)
Depuis le début de la guerre au Liban en 2023, l’armée israélienne a, selon plusieurs cas documentés par les ONG, utilisé du phosphore blanc. Cette arme incendiaire illégale quand elle est employée dans des zones civiles ravage la terre et entraîne de lourdes conséquences sanitaires.
Spécial femmes dans le monde
- Son of Norway’s crown princess convicted of rape and sentenced to four years in prison (theguardian.com)
- Italy PM Meloni ‘stunned’ by Trump’s claims she begged him for a photo (theguardian.com)
Trump said : “She’s probably happy I talked to her. I didn’t have to talk to her. She begged me to take a picture with her. She wanted a picture with me so badly. I wouldn’t have taken it, but I felt sorry for her.” The remarks provoked fury in Italy and words of solidarity for Meloni from across the political spectrum, with Italy’s foreign minister, Antonio Tajani, saying he had cancelled a trip to the US next week.
- Des agents d’OnlyFans menacent des créatrices de contenu et prélèvent jusqu’à 50 % de leurs revenus (slate.fr)
Critiques sur leur apparence, pressions pour produire des contenus plus explicites, menaces : certaines créatrices d’OnlyFans vivent une réalité bien éloignée du fantasme de l’entrepreneuriat numérique.
- Canada makes femicide first-degree murder as all three major Criminal Code reforms become law (canada.ca)
- Young women now have ‘close to zero’ risk of cervical cancer death after HPV jab (bbc.com)
Children vaccinated at age 12–13 against HPV (human papillomavirus) have close to zero risk of dying from cervical cancer before the age of 30, landmark new research reveals.
Spécial France
- Le groupe Bernard Hayot : aux origines coloniales de la vie chère (frustrationmagazine.fr)
Les années 2024-2025 ont marqué un tournant dans la mobilisation des militants caribéens contre la vie chère. Au cours des manifestations, une entreprise martiniquaise familiale a été désignée responsable de la vie chère : le Groupe Bernard Hayot (GBH). Pendant six ans, le groupe a imposé le mystère sur ses chiffres d’affaires et ses bénéfices, ne les révélant qu’au cours de l’année 2025.
- « La France interdit chez elle les pesticides qu’elle vend aux pays du Sud » (reporterre.net)
Les luttes contre le chlordécone et l’agent orange manifesteront ensemble à Paris le 20 juin contre le « colonialisme chimique ». La géographe brésilienne Larissa Mies Bombardi, qui a forgé ce concept, décrypte cette « asymétrie » entre le Nord et le Sud global.
- Cybersécurité : la transposition de NIS2 continue de traîner des pieds (next.ink)
17 octobre 2024 : c’était la date limite pour transposer le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité, plus connu sous le nom NIS2.
- Protection des mineur·es en ligne : la CJUE valide l’obligation de vérification de l’âge sur les sites pornographiques (leclubdesjuristes.com)
Après le renvoi préjudiciel du Conseil d’État, la Cour de justice de l’Union européenne (CJUE) a rendu, mardi 16 juin, un arrêt validant la possibilité pour la France d’imposer aux sites pornographiques la vérification de l’âge de leurs utilisateurs.
- Violences sexuelles sur mineur·es en Martinique : plus de 700 procédures en cours et une “libération de la parole” confirmée par le procureur général (la1ere.franceinfo.fr)
- Le nombre de victimes de violences à Bétharram pourrait être beaucoup plus élevé qu’attendu (huffingtonpost.fr)
Le rapport de la commission d’enquête indépendante sur les violences à Bétharram estime qu’il pourrait y avoir jusqu’à 1 500 victimes de violences sexuelles et physiques.
Voir aussi Affaire Bétharram : entre 700 et 1500 élèves potentiellement victimes, selon les projections d’une ONG (rfi.fr)
« Crimes de masse », « sadisme », « torture »… Entre 700 et 1 500 élèves scolarisés de 1950 à la fin des années 1990 ont potentiellement été victimes « de violences d’une exceptionnelle gravité » à Notre-Dame-De-Bétharram, près de Lourdes dans le sud-ouest de la France, et dans d’autres établissements de la congrégation religieuse, selon le rapport d’une ONG spécialisée dévoilé samedi 20 juin.
- La Cnaf fait le pari de l’open source pour reprendre la main sur le calcul des allocations (acteurspublics.fr)
- Les renseignements intérieurs français débranchent Palantir (synthmedia.fr)
Le Premier ministre Sébastien Lecornu a annoncé le divorce entre la DGSI et Palantir, la sulfureuse entreprise de logiciels américaine choyée par Donald Trump. Après dix ans de dépendance technologique, les services secrets français coupent le cordon pour confier leurs données ultra-sensibles au champion tricolore ChapsVision.
Voir aussi Qu’est-ce que ChapsVision, l’entreprise française retenue par Paris pour remplacer Palantir ? (legrandcontinent.eu)
- Chaleur, inondations… Un quart des futurs data centers français vulnérable aux risques climatiques (reporterre.net)
- La SNCF annule 71 trains à cause de la canicule (reporterre.net)
La SNCF a annoncé jeudi 18 juin la suppression de 71 trains censés circuler entre jeudi et lundi, pour « prévenir les pannes potentielles de climatisation liées aux très hautes températures », a indiqué à l’Agence France-Presse l’entreprise ferroviaire.
- Canicule : avec 44 °C ressentis, il fera dimanche plus chaud à Paris qu’à Bangkok et à la Mecque (franceinfo.fr)
La canicule s’installe, avec 60 départements en vigilance orange si bien que la température ressentie, comprenant l’humidité et l’ensoleillement, sera plus élevée dimanche en France que dans plusieurs villes tropicales ou désertiques.

- Quel climat futur dans votre région ? (meteofrance.com)
- “La fête de la musique est la plus grosse soirée de l’année” : stupeur et colère des bars, sidérés par l’interdiction d’alcool en terrasse ce week-end à Strasbourg (france3-regions.franceinfo.fr)
“Nous n’avons eu aucun communiqué de la préfecture ni même de l’UMIH (Union des métiers et des industries hôtelières). Juste un post Facebook sur le compte de la préfecture”.
- Déshydratation, efficacité diminuée, réactions cutanées… Pourquoi médicaments et canicule ne font pas forcément bon ménage (franceinfo.fr)
- Psychiatrie : Benzodiazépines ou l’addiction sur prescription (journal-labreche.fr)
9 millions. C’est le nombre de Français·es traité·es par benzodiazépines au cours de l’année 2024. Ces sédatifs prescrits pour l’anxiété et l’insomnie sont aussi très addictifs, et sont souvent prescrits au-delà des 12 semaines préconisées. De nombreux professionnels dénoncent un problème de santé publique.
Spécial femmes en France
- Ces jeunes pères qui prennent leur congé de paternité pendant la Coupe du monde de Foot (lesnouvellesnews.fr)
Sur l’indispensable compte de « T’as pensé à ?, l’association qui rend visible la charge mentale des femmes », des agentes de la CPAM disent s’attendre à une hausse des demandes de congé paternité pendant la Coupe du monde 2026.
- Thomas Lilti, le réalisateur d’« Hippocrate », épinglé dans une enquête de « Mediapart » (huffingtonpost.fr)
Le médecin et cinéaste est notamment accusé d’avoir pillé le travail de plusieurs femmes scénaristes pour ses films.[…] Dans son enquête, Mediapart révèle également que Thomas Lilti a été radié de l’Ordre des médecins […] Malgré sa radiation en 2012, il aurait « abusé à de multiples reprises de son autorité de médecin sur des femmes placées sous son autorité »
Voir aussi Vols de scénarios et voyeurisme : le réalisateur Thomas Lilti (“Hippocrate”) visé par deux enquêtes (lesinrocks.com)
une proche de Thomas Lilti, qui a résidé chez lui, a découvert des images d’elle nue dans son propre ordinateur. Elle y a trouvé un logiciel de caméra espion dont elle ne savait rien. “On voit le réalisateur face à l’écran, faire des manipulations pour lancer et éteindre les vidéos. Sur l’un, on le voit clairement tester le cadre”
- À Mayotte, le combat des associations contre les violences sexuelles sur mineur·es (histoirescrepues.fr)
Depuis 2018, l’association Haki za Wanatsa (“les droits des enfants” en shimaoré) recueille les témoignages de victimes et mène des actions de terrain, en dépit des tabous culturels et de la faiblesse des services de l’État.
- Un an après #MeTooPolice, où en est-on ? (rembobine.info)
Entre 2012 et 2025, 429 personnes ont été victimes de violences sexuelles commises par 215 policiers et gendarmes – tous grades confondus et dans plus d’une centaine de villes en France. Ces violences, aux modes opératoires multiples, vont du harcèlement sexuel aux agressions sexuelles aux viols. Systémiques, elles n’ont pourtant fait l’objet d’aucune prise en charge sérieuse du ministère de l’Intérieur.
- Lyhanna : pourquoi il faudra rester mobilisé·es longtemps (lesnouvellesnews.fr)
« Tant qu’une loi intégrale et des moyens ne seront pas adoptés » : partout en France, des rassemblements sont appelés chaque lundi. Derrière l’émotion suscitée par l’affaire Lyhanna, la coalition féministe pour une loi-cadre contre les violences sexuelles redoute, une fois encore, l’inaction des pouvoirs publics.
- Affaire Lyhanna : l’autopsie de la collégienne confirme qu’elle a été violée (humanite.fr)
- La Ciivise passe les (in)actions du Gouvernement à la loupe (lesnouvellesnews.fr)
Les appels répétés de la Ciivise à agir contre les violences faites aux enfants n’ont pas été entendus. Dans un rapport publié ce lundi 15 juin, la Commission épluche les actions du Gouvernement et le presse de « passer à la vitesse supérieure », notamment après le meurtre de Lyhanna.
- « Urgence sanitaire » : seize familles portent plainte contre TikTok (lesnouvellesnews.fr)
Anorexie, dépression et idées suicidaires. Après le suicide de cinq adolescentes, le collectif « Algos Victima » porte plainte contre TikTok pour « abus de faiblesse ».
Spécial médias et pouvoir
- Enquêter sur Bernard Arnault, un exercice sous pression (larevuedesmedias.ina.fr)
Ces dernières semaines, plusieurs enquêtes sur Bernard Arnault, dont un livre biographique publié le 10 juin, agitent les services de communication du géant du luxe LVMH. Pour les journalistes qui tentent de percer le mystère de l’homme le plus riche de France, la tâche est souvent périlleuse.
- Qui est vraiment Matthieu Pigasse ? (frustrationmagazine.fr)
- Le 13h d’Inter : anesthésier le réel, mode d’emploi (acrimed.org)
- Liberté de la presse : ce qui est arrivé à un de nos journalistes est extrêmement grave (politis.fr)
Lors de l’audience devant la juge des référés, le représentant du ministère de l’Intérieur a dû préciser les raisons qui l’ont poussé à interdire à notre journaliste Maxime Sirvins d’entrer au salon de l’armement Eurosatory. Des motivations particulièrement inquiétantes qui ont toutes été balayées par le tribunal administratif.
- CNews mise en demeure de respecter le pluralisme des courants de pensée et d’opinion (telerama.fr)
Saisie en janvier par Reporters sans frontières, l’Arcom a épluché les programmes de la chaîne phare de Vincent Bolloré en mars 2025. Et constaté que non, tous les courants de pensée ne sont pas représentés dans les infos et les débats.
- Face à l’extrême droite, défendre la liberté des médias (politis.fr)
La menace contre la liberté de la presse en France n’a plus rien d’hypothétique. Pour Reporters sans frontières, l’absence de réformes ambitieuses favorise la précarisation des métiers, la concentration des médias et les stratégies d’influence politique. Thibaut Bruttin, son directeur général, appelle à la vigilance.
- Ebra et Le Dauphiné Libéré : l’événementiel au détriment de l’information ? (acrimed.org)
Quotidien régional dominant à Grenoble, Le Dauphiné Libéré ne lésine pas sur les moyens pour se mettre au service du secteur de la Tech et de l’IA dans la « Silicon Valley française ».
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- G7 d’Évian : Emmanuel Macron efface le climat de l’agenda pour « ne pas fâcher » Donald Trump (reporterre.net)

- Climat : la France cuit, et le gouvernement se félicite (reporterre.net)
En pleine vague de chaleur, le ministère de la Transition écologique s’est félicité, le 17 juin, de l’avancée de son plan d’adaptation au changement climatique. Une stratégie mal financée et largement insuffisante, rétorquent les associatifs.
- Les vagues de chaleur ont un terrible coût sanitaire, estimé à plus de 5 000 morts par an par Oxfam (huffingtonpost.fr)
- Urgences saturées, manque de soignant·es : la chaleur extrême révèle la déroute du système de santé face au changement climatique (vert.eco)
À l’aube d’une nouvelle vague de chaleur précoce, l’ONG Oxfam documente dans un rapport l’explosion des besoins en soins due au réchauffement climatique, alors que le système de santé français s’enfonce déjà dans la crise.
- Le gouvernement détourne les aides de l’Ademe pour financer l’un des plus gros pollueurs de France (disclose.ngo)
Matignon et Bercy ont truqué deux appels à projets de l’Agence de la transition écologique (Ademe) pour financer le géant de la pétrochimie Ineos, révèle Disclose. La multinationale va toucher plus de 300 millions d’euros d’argent public pour soutenir l’activité d’une usine parmi les plus émettrices de CO2 en France.
- « Silence vaut acceptation » : quand le gouvernement invite les multinationales à lui dicter sa politique (multinationales.org)
derrière tous les discours du pouvoir exécutif sur la « souveraineté numérique », c’est bien l’attractivité vis-à-vis des grands acteurs économiques internationaux qui reste la priorité, au détriment du droit de l’environnement et des citoyen·nes.
- Derrière la loi « simplification », l’offensive des Big Tech et du lobby des datacenters (multinationales.org)
L’article 35 de la loi de simplification […] crée le statut de « projet national d’intérêt majeur » qui vise à faciliter la construction rapide de nouveaux data centers. Des gros acteurs économiques ont pesé de tout leur poids pour faire adopter cette mesure stratégique, à commencer par les Big Tech qui ont démontré une nouvelle fois l’étendue de leurs réseaux d’influence.
- Bercy crée la Direction de l’intelligence artificielle et du numérique (presse.economie.gouv.fr)
La DIAN sera chargée de définir et mettre en œuvre la stratégie numérique et IA des ministères économiques et financiers.
- Matignon bloque la diffusion d’un rapport sur l’impact de l’IA sur les effectifs de la fonction publique (acteurspublics.fr)
Une mission menée par plusieurs inspections générales a tenté, depuis quelques mois, de quantifier les effets du déploiement de l’IA dans la fonction publique. Son rapport, désormais dans les mains du Premier ministre, Sébastien Lecornu, pourrait toutefois ne jamais être rendu public
- Lecornu donne une date pour introduire les cours d’IA au lycée (huffingtonpost.fr)
Le Premier ministre a annoncé qu’une heure de cours par semaine serait dispensée aux classes de seconde pour apprendre à maîtriser l’intelligence artificielle.
- Pronote, Parcoursup, ENT : pourquoi l’interdiction du smartphone pose problème (lenouveauparadigme.fr)
- Gabriel Attal : « Il faut l’équivalent de la politique agricole commune pour l’IA » (lesechos.fr)
- Mort de Lyhanna : « Plutôt que de punir les magistrat·es, il faut augmenter leur nombre, les encourager, les former » (basta.media)
- L’Unédic appelle l’État à ne plus ponctionner les comptes de l’assurance-chômage pour lui permettre de réduire sa dette (franceinfo.fr)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- La préfecture de police de Paris interdit un grand rassemblement contre les violences du régime iranien (franceinfo.fr)
- Fête de la musique : ni « violences », ni « dégradations », Laurent Nuñez prévient qu’« aucun débordement ne saura être toléré » (leparisien.fr)
Dans une lettre aux préfets, Laurent Nuñez demande de mettre en œuvre un dispositif de sécurité renforcé pour la Fête de la musique 2026, afin de prévenir le terrorisme, les violences urbaines et tout débordement.
- La préfecture de police interdit le concert de LFI prévu pour la Fête de la musique. (huffingtonpost.fr) – voir aussi Concert de LFI à Paris : les insoumis·es déposent un recours en référé après l’interdiction par la préfecture de police (liberation.fr) et Le concert de LFI pour la Fête de la musique finalement autorisé à Paris (huffingtonpost.fr)
La France insoumise, qui a annoncé l’organisation de ce concert dimanche sur la place de la République, a gagné son bras de fer face à la préfecture de police.
- Loi RIPOST, quand Nuñez attaque : les « LAPI » ou la surveillance massive des déplacements (laquadrature.net)
Les lecteurs automatiques de plaques d’immatriculation, plus fréquemment dénommés par l’acronyme « LAPI », sont encore peu connus en France. Pourtant, derrière ces quatre lettres se cache un dispositif ancien qui permet d’identifier et de localiser des véhicules en France à grande échelle.
- Sophie Djigo : un jugement qui met toustes les enseignant·es et chercheureuses en danger (politis.fr)
Le jugement rendu dans l’affaire de la professeure de philosophie harcelée par l’extrême droite marque un tournant préoccupant pour la liberté pédagogique et académique.
- « Nous ne sommes pas dupes de ce pinkwashing » : comment les maires RN du nord instrumentalisent les luttes LGBT (basta.media)
Annuler des événements LGBT tout en se drapant des couleurs arc-en-ciel : dans les Hauts de France, les mairies RN instrumentalisent le mois des fiertés. Et ce alors qu’au parlement européen, le parti refuse de voter contre les « thérapies de conversion ».
- Erik Tegnér, le directeur du magazine d’extrême droite « Frontières », condamné à six mois de prison avec sursis pour divulgation de données personnelles d’avocat·es (lemonde.fr)
Dans un hors-série publié en 2025, ces avocat·es étaient présenté·es avec leur nom, leur prénom et la ville où ils exercent comme des « militants idéologiques », désignés comme les « coupables » de la crise migratoire.
- Des militant·es « humilié·es et frappé·es » par le GIGN lors d’une action antimilitariste en Haute-Savoie (reporterre.net)
- Jordan, éborgné après la victoire du PSG : la télé aveugle aux violences policières ? (politis.fr)
Le témoignage de l’homme, blessé par un tir de LBD, n’a connu aucun écho médiatique. Un silence aussi peu surprenant que désespérant.
- « Je veux la vérité sur la mort de mon fils » : le combat de la mère d’Adam, tué par un policier (basta.media)
Fatiha est la mère d’Adam, un jeune tué en 2022, à vingt ans, lors d’une intervention policière. Elle tente depuis de lever les zones d’ombre qui entourent le récit des policiers. Quatre ans après les faits, la reconstitution va enfin avoir lieu.
- 49 personnes tuées au cours d’une intervention policière en 2025 (basta.media)
Spécial résistances
- « On a toujours été là » : avec les prides rurales, les fiertés LGBT s’assument à la campagne (basta.media)
- Les quatre activistes antipub relaxé·es : une victoire contre l’État répressif (antipub.org) – voir aussi Victoire : les quatre activistes ayant dénoncé le génocide de Gaza n’iront pas en prison (lareleveetlapeste.fr)
Pour le collectif Résistance à l’Agression Publicitaire, c’est « une victoire contre l’État répressif ». Le Tribunal Correctionnel de Lyon a relaxé les quatre activistes antipub et pour la lutte de libération palestinienne qui avaient participé à un détournement publicitaire en septembre 2025.
- Blinding the Cyclops—Wrecking the Panopticon – Camera Hunting in the Metropolis (crimethinc.com)
“Big Brother is watching you.” Once a threat from a dystopian future, today this is a universal reality that we all participate in with our smartphones and Instagram accounts. Yet for years, a rebel undercurrent has pushed back against surveillance, seizing the prevalence of surveillance cameras as yet another vulnerability in the system of control. In the following narrative, an anonymous researcher wages a personal war against surveillance infrastructure, testing some of the same tactics that social movements have recently employed from Greece and Slovenia to Chile and Hong Kong.

Spécial outils de résistance
- Pétition : Dégageons les capitalistes des médias ! (acrimed.org)
- « Il est temps de choisir son camp » : et si on créait un label « sans-IA générative » ? (reporterre.net)
- Dans votre quartier aussi c’est un four ? Témoignez ! (blogs.mediapart.fr)
Un nouvel épisode caniculaire s’étend à nouveau en France où au moins 53 départements sont en vigilance orange ce 19 juin 2026. Et les températures risquent de continuer à grimper. Pour un article en préparation, nous vous donnons la parole à ce sujet. Racontez-nous votre quotidien.
- Fiche 36 : il fait trop chaud au boulot ! en 8 questions (solidaires.org)
Spécial MAGAM et cie
- Google referme la dernière faille qui permettait aux vrais bloqueurs de pub de survivre sur Chrome (clubic.com)

- À partir du 3 août 2026, Google va utiliser votre adresse IP pour le ciblage publicitaire ! (it-connect.fr)
Exploiter votre adresse IP pour vous proposer des publicités personnalisées, c’est la nouvelle idée de Google. À compter du 3 août 2026, Google va la mettre en place dans l’Espace économique européen, au Royaume-Uni et en Suisse. L’adresse IP, qui est une donnée personnelle au sens du RGPD, va donc être utilisée pour le ciblage publicitaire.
- Dans un discours optimiste, Jeff Bezos expose son plan pour sauver la Terre (huffingtonpost.fr)
Son plan en détail ? Rendre la Terre à son état d’avant l’ère industrielle en envoyant toutes les activités polluantes sur la Lune ou des astéroïdes.
Les autres lectures de la semaine
- From PGP to Mythos : a brief history of export controls that didn’t stop anyone (techcrunch.com)
- Recherche désespérément trous béants : enquête sur les terres excavées du Grand Paris Express (lechiffon.fr)
- “Racisé”, le mot qui dérange la République (komunemedia.substack.com)
Apparu dans les universités en 1972, le terme “racisé” cristallise les tensions françaises entre universalisme républicain et reconnaissance des discriminations raciales.
- L’histoire des femmes américaines qui ont aidé la France et ses orphelins à se relever de la Première Guerre mondiale (slate.fr)
Pendant et après la Grande Guerre, des milliers d’Américaines ont mené des missions humanitaires en France, en participant à la reconstruction du pays et en jouant le rôle de mères auprès des orphelins français. Une facette méconnue de l’histoire transatlantique.
- Comment le génie de George Sand a été minimisé par l’histoire littéraire (theconversation.com)
L’année 2026 marque le cent cinquantième anniversaire de la mort de George Sand. La relire, c’est redécouvrir son apport artistique et intellectuel, mais aussi comprendre comment le génie féminin a été systématiquement dénié par un canon littéraire reléguant les femmes à la portion congrue.
- Meet Héloïse, the Medieval Woman Philosopher Who Turned a Doomed Love Affair into a Meditation on Ethics (openculture.com)
- Pourquoi de plus en plus de médecins reconnaissent‑ils la validité des expériences de mort imminente ? (theconversation.com)
Les BDs/graphiques/photos de la semaine
- G7
- Pantone
- Remember
- Scandale
- Philo
- Futur
- Mondial
- Sun
- Hot
- Normal
- Numéro
- Elon
- 18 juin
- Quand est-ce qu’on interdit les lunettes connectées ? (framablog.org)
- Réalité
- Medium
- Pride
- Trans
- Petits gestes
- Higher
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Démocratie en danger : journalistes supprimé·es, information menacée (basta.media)
Ce 18 juin, les journalistes étaient en grève à travers la France. Ils et elles dénoncent la dégradation de leurs conditions de travail, la concentration des médias entre les mains des milliardaires et demandent l’encadrement de l’usage de l’intelligence artificielle dans les médias.
- The Map of Physics : Animation Shows How All the Different Fields in Physics Fit Together (openculture.com)
Les trucs chouettes de la semaine
- Marie Muzard, l’ange gardienne des poulpes en Méditerranée (humanite.fr)
À Cannes, elle a créé une association pour attirer l’attention sur la disparition en Méditerranée de ce céphalopode. En cause : le réchauffement de l’eau et… les cartes des restaurants.
- Black Women Farmers Are Reclaiming the Land (reasonstobecheerful.world)
From sharecroppers to herbalists to healers, Black women farmers have been nourishing the world for generations — and continue to today.
- Shaking up the coffee world : Entirely new way of making espresso unveiled (unsw.edu.au)
Researchers at UNSW Sydney have harnessed the power of ultrasonic sound waves to make espresso-strength coffee with room temperature water, cutting energy use by up to 75 %.
- Mastodon looks to newsletters to help revive the open social web (techcrunch.com)
- Pages not found (404s.design)
404 pages worth finding

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
18.06.2026 à 18:20
Table ronde « Logiciels libres », avec Framasoft, à l’Assemblée Nationale
Texte intégral (525 mots)
Depuis février 2026, la commission d’enquête « sur les dépendances structurelles et les vulnérabilités systémiques dans le secteur du numérique et les risques pour l’indépendance de la France » est conduite, à l’Assemblée nationale par Cyrielle Chatelain (rapporteure) et Philippe Latombe (président). De nombreuses auditions ont été tenues, le logiciel libre y étant souvent évoqué comme alternative aux situations de dépendance. Framasoft a été auditionnée mercredi 6 mai 2026 dans le cadre d’une table ronde sur le logiciel libre.
Pierre-Yves Gosset, coordinateur des services numériques de l’association Framasoft, est intervenu au côté d’Étienne Gonnu et Loïc Dayot, respectivement chargé de plaidoyer et administrateur de l’association April, de Renaud Chaput, directeur technique de Mastodon, et de Nicolas Vivant, fondateur de France Numérique Libre, directeur de la stratégie et de la culture numériques de la commune d’Échirolles.
- La vidéo est disponible ci-dessus sur PeerTube, ou directement sur le site de l’Assemblée Nationale.
- La transcription de l’audition a été réalisée par le groupe de travail Transcription de l’April (merci à elles et eux !).
- Le compte-rendu officiel est aussi disponible sur le site de l’Assemblée Nationale (ou la copie archivée par nos soins).
Les auditions se sont achevées courant mai et le rapport devrait être publié en juillet 2026.
16.06.2026 à 15:20
LaSuite.coop : interview d’une coopérative qui veut (elle aussi !) dégoogliser internet
Texte intégral (3388 mots)
Ce n’est pas tous les jours qu’on a de belles perspectives à partager. Alors ne boudons pas notre plaisir !
En mars dernier, nous vous partagions un (long) article sur La suite numérique de l’État, les critiques qui en étaient faites, et plus généralement la stratégie « Make or Buy » de l’État.
Nous évoquions alors une interview de l’équipe de LaSuite.coop, une coopérative dont l’objectif est de proposer des outils numériques libres et éthiques (en partie basés sur les outils de LaSuite de l’État).
Nous avons enfin trouvé le temps de les interroger sur leur projet, et ça tombe bien, puisqu’elles et ils ouvrent leur sociétariat à toute personne souhaitant participer à l’aventure.
Hello l’équipe de LaSuite.coop ! On est ravi⋅es de vous accueillir pour cette nouvelle interview sur le Framablog. Commençons par le début : qui êtes-vous ?
Bonjour à toute la communauté Framasoft ! Ici LaSuite.coop, une coopérative née de la rencontre entre plusieurs structures qui avaient chacune la même conviction : les organisations qui défendent des valeurs progressistes méritent des outils numériques qui leur ressemblent.
Derrière le projet, on trouve cinq structures fondatrices : IndieHosters, coopérative qui héberge des services libres depuis plus de dix ans ; Open Source Politics, spécialiste des plateformes de démocratie participative pour les collectivités ; Yaal Coop, coopérative de développement logiciel ; Algoo, éditeur de Galaé, notre solution de messagerie email libre et Le Bureau.coop coopérative qui accompagne dans la gestion de noms de domaine.. Ensemble, nous avons constitué une SCIC, une Société Coopérative d’Intérêt Collectif, pour porter collectivement ce projet.
Ce qui nous rassemble, ce n’est pas simplement le logiciel libre. C’est l’idée que la manière dont on produit et gouverne les outils numériques a des conséquences politiques concrètes. On se doute que vous le savez déjà, mais utiliser Google Workspace ou Microsoft 365, ce n’est pas un choix neutre : c’est confier ses données, ses communications et son autonomie à des entreprises dont le modèle économique repose sur l’extraction et la centralisation. Nous pensons qu’il existe une autre voie, et nous essayons de la rendre accessible.

Alors, dites nous en plus maintenant sur le projet « LaSuite.coop ». Quelle est son histoire ?
L’idée vient d’IndieHosters. Depuis 2015, Timothée, Pierre et leur collectif expérimentent des outils libres avec une conviction simple : il devrait être possible de s’émanciper des GAFAM sans sacrifier le confort ni la fiabilité. En 2020, pendant le confinement, ils lancent Liiibre, une suite collaborative complète, avec un modèle économique basé sur les communs, sans clients ni prestataires, mais avec des contributeurs et contributrices d’une ressource partagée. L’utopie concrète, comme ils disaient.
C’est à cette même période qu’IndieHosters et Open Source Politics commencent à travailler ensemble sur des projets de civic tech comme la mise en place d’outils de documentation pour Numérique En Commun(s) et la migration de la pétition du Sénat sur Decidim. En parallèle, IndieHosters est sollicité pour contribuer à l’infrastructure de La Suite numérique de l’État portée par la DINUM. Deux chemins qui s’alimentent mutuellement : d’un côté des expertises techniques qui se renforcent au contact de déploiements à grande échelle, de l’autre des relations de confiance qui se construisent avec des personnes d’horizons différents venant de l’État, de l’ESS et de la civic tech.
C’est là qu’IndieHosters propose à OSP de commercialiser Liiibre. IndieHosters (« IH ») avait les outils et l’infrastructure, Open Source Politics (« OSP ») avait les clients et les relations commerciales. Une complémentarité évidente. Et du côté d’OSP, le contexte accélère la décision : quand Musk rachète Twitter pour en faire une machine à désinformation, quand Trump récompense les Big Tech qui l’ont soutenu, quand Meta supprime ses équipes de fact-checking, on réalise que proposer seulement des outils de participation citoyenne à nos clients n’est plus suffisant. La souveraineté numérique ne peut pas s’arrêter à la plateforme de consultation. On embrasse donc la vision d’IndieHosters.
C’est de là que naît l’idée de LaSuite.coop. Ensemble, on a regardé de près les outils de La Suite numérique de l’État et ils nous ont grandement séduit. Comme ils étaient réservés aux agents publics nous y avons vu une opportunité d’en faire profiter le plus grand nombre. Mais pour aller plus loin, il fallait s’entourer.
Pour le développement IndieHosters a pensé à Yaal Coop qu’ils connaissent via le réseau Libre Entreprise, un réseau d’entreprise du numérique libre qui applique les valeurs du libre à sa gouvernance (horizontalité, transparence, égalité salariale, …), ainsi que par le collectif CHATONS.
Et suite au rachat de Gandi on a vu émerger deux initiatives qui nous on plu, Galae un service email professionnel commercialisé par Algoo et LeBureau.coop pour les noms de domaines. On leur a alors présenté notre projet et proposé de nous rejoindre.
OK. Alors maintenant, creusons un peu votre offre de services : vous proposez quoi ? Et à qui ?
À qui s’adresse-t-on ? À toute organisation qui cherche une alternative crédible aux suites de Google ou Microsoft : associations, syndicats, coopératives, mutuelles, structures de l’ESS, collectivités, communes de plus de 1 500 habitants, établissements d’enseignement supérieur, médias indépendants, partis politiques… Si vous partagez nos valeurs et avez besoin d’outils fiables sans sacrifier votre indépendance numérique, LaSuite.coop s’adresse à vous.
Un mot sur notre modèle : on parle de cotisation, pas d’abonnement, et ce n’est pas qu’une question de sémantique. En cotisant, une organisation ne paie pas simplement un prestataire pour un service, elle contribue à un commun, elle participe à le faire vivre et à le développer. C’est une relation fondamentalement différente de celle qu’on entretient avec un éditeur SaaS classique. Le montant est calculé en fonction de la taille de l’organisation et des outils déployés il nous paraît logique de ne pas faire payer une petite asso au même tarif qu’une fédération nationale.
Concrètement, on propose aujourd’hui une suite complète accessible via un portail de connexion unique : visio, chat, mail, agenda, prise de notes collaborative, stockage et partage de fichiers (avec la suite Collabora intégrée pour créer vos documents textes, tableurs et présentations), un gestionnaire de mots de passe et Grist, un outil no-code super puissant pour gérer vos données. Notre offre actuelle s’adresse aux organisations d’au moins dix personnes, mais on travaille à ouvrir le service aux particuliers et aux petits collectifs d’ici la fin de l’année. La souveraineté numérique ne devrait pas être réservée aux structures déjà bien installées.
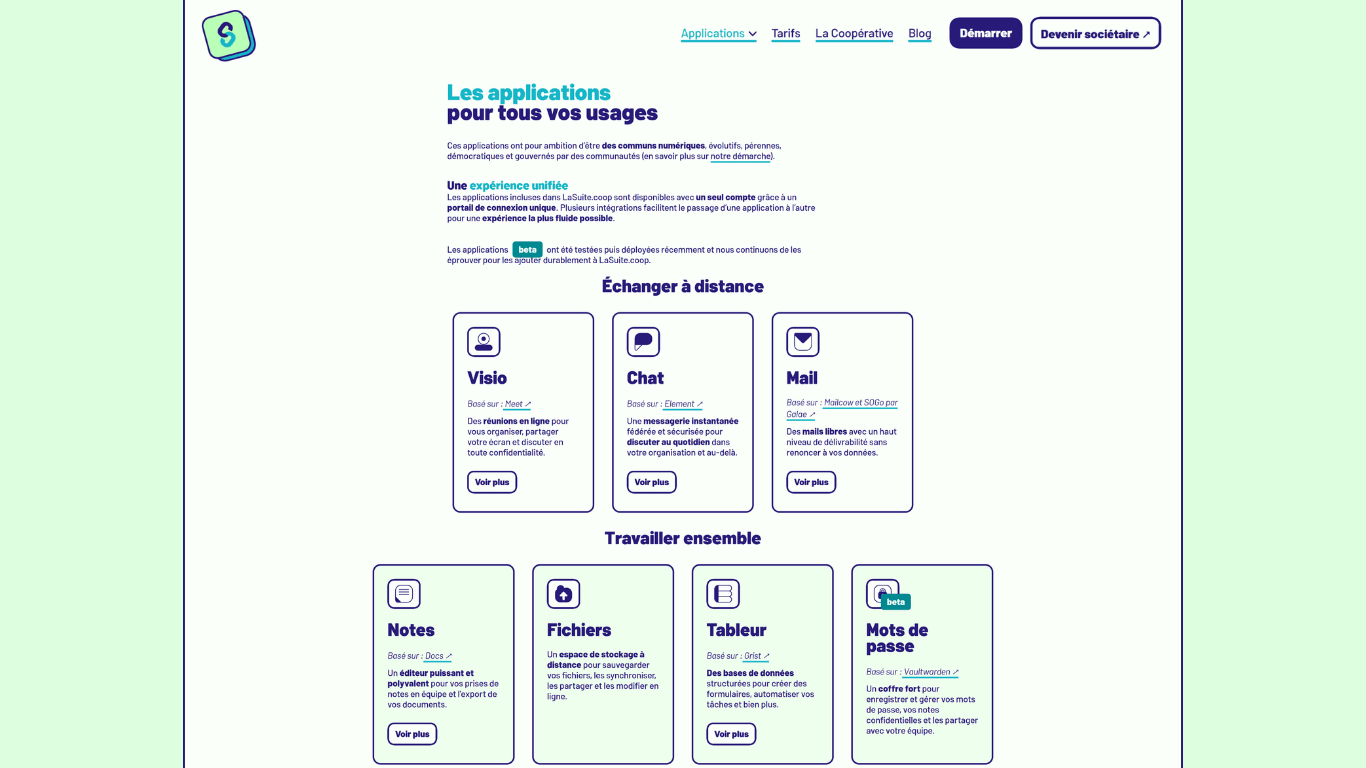
Capture du site LaSuite.coop
Votre offre propose essentiellement les logiciels portés par La Suite Numérique de l’État, pourquoi ? Quel est votre rapport avec les équipes de la Dinum ?
Notre offre comporte en partie des logiciels portés par la DINUM parce que ce sont de très bons outils, tout simplement. Docs, Fichiers, Grist, Visio, ces logiciels ont été développés (ou amélioré pour le cas de Grist) pour répondre aux exigences d’une administration qui gère des données sensibles et des millions d’utilisatrices et d’utilisateurs. Ils sont robustes, open source, maintenus par des communautés actives. Quand on a regardé ce qui existait pour construire LaSuite.coop, la réponse s’est imposée assez naturellement.
D’autant plus que les membres d’IndieHosters ont contribué en partie à l’infrastructure de La Suite numérique de l’État. Cette relation de travail a créé une vraie proximité. Aujourd’hui on remonte des bugs, on participe aux discussions sur la feuille de route, et on s’implique dans les réflexions pour pérenniser le code de ces outils dans la durée. Il n’y a pas de contrat qui nous lie, juste une communauté qui s’articule dans le même sens. On avance ensemble, chacun de son côté, vers le même horizon.
C’est d’ailleurs ce que Timothée est allé défendre plus tôt cette année au FOSDEM : un modèle public-coopératif pour les communs numériques. L’idée est simple et puissante, la DINUM crée et garantit les communs, LaSuite.coop les maintient, les déploie et les rend accessibles au-delà de l’administration, et la communauté en oriente l’évolution. Chacun son rôle, dans le même sens. Un modèle qui n’a pas besoin de capital-risque ni de logique extractive pour tenir, juste des acteurs alignés sur l’intérêt général.
Avez-vous d’autres envies d’ouverture de services en perspective ?
Oui en effet ! D’abord ouvrir le service aux structures de moins de dix personnes et aux particuliers, ensuite, développer un outil de migration pour faciliter la transition vers LaSuite.coop pour le plus grand nombre. Parce qu’on sait que le frein principal ce n’est pas la volonté, c’est la complexité perçue du passage d’un outil à un autre. Un bon outil de migration, c’est ce qui transforme une bonne intention en vrai changement.
Nous avons également des liens étroits avec d’autres éditeurs d’applications qu’on prévoit de faire rentrer dans la gouvernance et dans l’offre prochainement : Biru (avec l’app Tenzu), tiBillet, kaihuri (pour Mobilizon) et peut être vous Framasoft (pour PeerTube).
Super ! Vous êtes actuellement en période de pré-ouverture de levée de fonds, car vous ouvrez votre sociétariat. Qu’est-ce que cela signifie, concrètement ?
Devenir sociétaire de LaSuite.coop, c’est acquérir au moins une part sociale à 100 euros et avec elle, une voix dans la coopérative. Droit de vote, accès aux assemblées générales, possibilité de peser sur les futurs développements des outils. On ne devient pas client, on devient copropriétaire d’une infrastructure numérique souveraine.
C’est rare, et c’est ce qui nous tient à cœur, que les personnes qui utilisent ces outils puissent aussi décider de leur direction. Une coopérative sans sociétaires, c’est une coquille vide. Avec eux, c’est un projet qui s’ancre dans le temps.
Pour l’instant, vous pouvez manifester votre intérêt sur notre site, la campagne ouvrira très prochainement. Ces pré-inscriptions comptent beaucoup pour nous car c’est une façon concrète de mesurer l’intérêt pour le projet et de nous donner la confiance nécessaire pour avancer sereinement vers nos objectifs. Inscrivez-vous dès maintenant sur https://societariat.lasuite.coop/ pour être averti·e en avant-première.

Capture écran site LaSuite.coop
Vous êtes-vous fixé des objectifs financiers à atteindre ? Lesquels et pourquoi ?
Nous nous sommes fixé un objectif minimum de 200 000 € pour avoir les reins solides et franchir un premier cap : augmenter significativement le nombre d’organisations auxquelles nous proposons nos services, en commençant par les coopératives.
Au-delà, nous espérons rencontrer un écho le plus large possible, pour avoir les moyens d’outiller rapidement les petites entreprises et le grand public.
Enfin, à partir d’un seuil de quelques millions d’euros, nous considérons qu’il sera préférable de créer un fonds de dotation pour accompagner l’essaimage de structures comme la nôtre sur le territoire, plutôt que de devenir une méga-structure. Nous avons à cœur de privilégier la mise en réseau de structures à taille humaine comme le font des coopératives telles que Biocoop ou Enercoop, plutôt que de former un monolithe. Sur ce point aussi, on pense différemment des GAFAM !
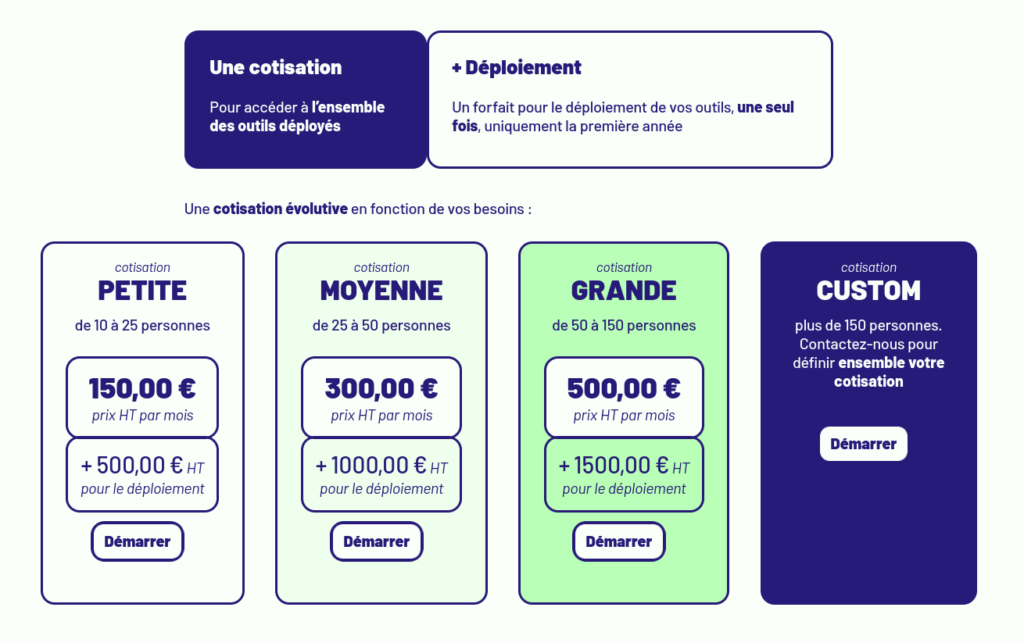
Les tarifs de LaSuite.coop (au 11/06/2026)
Allongez-vous sur le divan, fermez les yeux… Pour vous, dans 5 ans, LaSuite.coop, c’est quoi ?
Dans cinq ans, on aimerait avoir prouvé qu’un modèle coopératif peut tenir face aux géants, pas en les imitant, mais en faisant mieux sur ce qui compte vraiment. Des outils aussi fluides que Google Workspace, avec un contact humain en plus et des données qui restent les vôtres.
Concrètement, on veut avoir ouvert le service au grand public, développé un outil de migration en un clic depuis Microsoft et Google et commencé à reverser une part de notre chiffre d’affaires aux communs numériques que nous faisons vivre.
On veut aussi avoir les moyens de financer deux postes qui nous tiennent particulièrement à cœur. Le premier : une personne dédiée à la qualité du code que l’on repartage à la communauté open source avec documentation rigoureuse, code lisible, pour que n’importe qui puisse venir étudier ce qu’on fait et s’en emparer. Le deuxième, une personne à temps complet sur l’animation de l’écosystème des communs numériques, en interne ou via une structure partenaire. Parce qu’un commun sans communauté active, ça ne dure pas.
Il y a aussi l’ambition plus large de contribuer à faire migrer une partie significative de la population française vers des outils libres (on a le droit de rêver) et de porter un plaidoyer au niveau européen pour que ce modèle public-coopératif essaime au-delà de nos frontières. Nous sommes convaincus que la souveraineté numérique ne se construira pas pays par pays, chacun dans son coin. En cinq ans, on veut avoir démontré que l’utopie concrète, ça fonctionne.
On espère aussi que dans 5 ans (et même bien avant) on fasse parti des membres bien identifiés des Licoornes et qu’on participe avec eux à promouvoir le modèle coopératif, comme ils le font avec leur campagne ALT au capitalisme en cours.

Question relativement récurrente dans les interviews du Framablog : y a-t-il une question que vous auriez aimé qu’on vous pose ?
La question qu’on redoute un peu mais qu’il faut poser : « Qu’est-ce qui pourrait faire échouer LaSuite.coop ? »
L’indifférence. Pas l’hostilité, ça, ça mobilise, mais l’indifférence… Le sentiment que le problème n’est pas si urgent, qu’on verra ça plus tard. On peut construire les meilleurs outils du monde, porter le modèle le plus juste qui soit, si personne ne se sent concerné, ça ne suffit pas. C’est pour ça que le sociétariat compte autant pour nous. Chaque personne qui rejoint la coopérative, c’est une personne de plus qui a décidé que plus tard c’est maintenant.