
02.07.2026 à 10:12
Ce que l’on sait des récents séismes au Venezuela, et des risques qui subsistent
Texte intégral (2484 mots)
Le Venezuela et sa capitale, Caracas, ont été frappés par deux puissantes secousses sismiques le 24 juin 2026, à seulement quelques secondes d’intervalle. Les deux séismes, de magnitude 7,2 et 7,5, ont provoqué l’effondrement de bâtiments dans plusieurs villes du nord du pays, faisant plus de 2 200 morts et piégeant de nombreuses autres personnes, selon les autorités.
Le géophysicien Sylvain Barbot explique ce que l’on sait à ce stade de cette double secousse et les risques qui subsistent. Chercheur à l’Université de Californie du Sud, il dresse également un parallèle avec la faille de San Andreas, aux États-Unis.
Les séismes sont des phénomènes naturels qui se produisent généralement aux limites des plaques tectoniques de la Terre. Ces plaques, qui constituent la croûte terrestre, ont une épaisseur de plusieurs dizaines de kilomètres et portent les océans comme les continents. Elles sont en mouvement permanent, mais pas de manière fluide ni régulière.
Le Venezuela se situe à la frontière entre deux de ces plaques : la plaque sud-américaine et la plaque caraïbe. En glissant l’une contre l’autre, elles peuvent se bloquer, accumulant des contraintes jusqu’à ce qu’elles cèdent brutalement, provoquant un séisme.

Le 24 juin 2026, deux fortes secousses sismiques se sont produites à 39 secondes d’intervalle, toutes deux d’une magnitude supérieure à 7. Il pourrait s’agir de deux séismes distincts ou d’un seul séisme comportant deux phases de rupture. Les scientifiques ne le savent pas encore, car les données sont toujours en cours d’analyse.
L’hypothèse de deux séismes distincts est tout à fait plausible. En 2023, la Turquie a connu un « doublet » sismique, avec deux séismes de magnitude supérieure à 7 survenus à huit heures d’intervalle. Dans ce cas, il s’agissait clairement de deux événements distincts.
À lire aussi : Pourquoi il y a des séismes en cascade en Turquie et en Syrie
Au Venezuela, les deux secousses n’étaient espacées que de quelques secondes. Par le passé, de très longues failles ont subi des déplacements sur différents segments lors de séismes de cette ampleur, donnant l’impression qu’il s’agissait de deux séismes distincts alors qu’ils correspondaient en réalité à deux ruptures d’un même événement sismique.
Qu’est-ce qui déclenche des séismes aussi destructeurs ?
Les séismes sont déterminés par la manière dont les roches résistent aux contraintes de cisaillement et de pression. Ces contraintes peuvent s’accumuler pendant des années, voire des décennies, jusqu’à dépasser la résistance des roches, qui finissent alors par se rompre. À partir de ce moment, la contrainte se propage et la rupture s’étend.
Il ne s’agit pas d’un mouvement progressif. En quelques secondes, les plaques se déplacent brutalement, provoquant un séisme. Ce phénomène se produit à plusieurs kilomètres sous la surface, où la température et la pression sont très élevées.
Ce phénomène est difficile à reproduire en laboratoire et met en jeu de nombreux processus, relevant aussi bien de la mécanique que de la chimie ou de la circulation des fluides. Son résultat est toutefois simple : une rupture se produit, au cours de laquelle des masses rocheuses glissent les unes contre les autres, créant une fracture qui brise tout sur son passage et provoque d’importants dégâts.
Le système de failles du Venezuela est-il comparable à celui de la faille de San Andreas, en Californie ?
Les failles impliquées dans le séisme au Venezuela et la faille de San Andreas, en Californie, sont très similaires. Il s’agit de failles transformantes, où les plaques glissent horizontalement l’une par rapport à l’autre selon un mouvement en décrochement.
Même les vitesses de déplacement sont assez proches. Au Venezuela, les deux plaques glissent l’une par rapport à l’autre à une vitesse moyenne d’environ 20 millimètres par an. Le long de la faille de San Andreas, ce mouvement est légèrement plus rapide, de l’ordre de 30 millimètres par an.
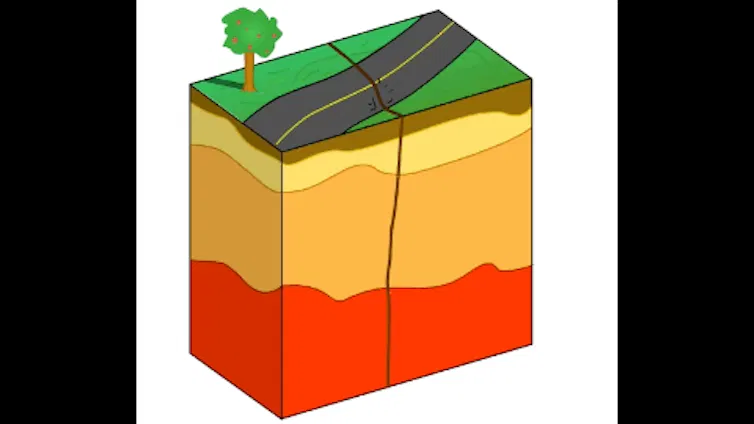
Ces failles produisent également des séismes de forte magnitude à des fréquences comparables. Sur la faille de San Andreas, les scientifiques estiment qu’un séisme de magnitude 7 ou plus se produit en moyenne tous les 170 ans environ, même si cet intervalle varie selon les segments de la faille. Il ne s’agit toutefois pas d’un mécanisme d’horlogerie : ces séismes peuvent survenir beaucoup plus fréquemment… ou beaucoup plus rarement.
Le dernier « Big One » du sud de la Californie remonte au séisme de Fort Tejon, en 1857, un puissant tremblement de terre de magnitude 7,9. Une étude récente suggère que les contraintes accumulées le long de la partie sud de la faille de San Andreas sont aujourd’hui plus importantes qu’à n’importe quel moment au cours des mille dernières années. Si les hypothèses de cette étude sont correctes, la faille pourrait être proche de rompre. Mais la fréquence des grands séismes est très variable : le prochain pourrait survenir dans cent ans… ou demain. Personne ne peut le prédire.
Ces failles ont déjà produit de nombreux séismes par le passé. C’est à lui seul un argument en faveur de normes parasismiques strictes pour les bâtiments et les infrastructures, comme les ponts ou les hôpitaux, ainsi que de plans de préparation aux situations d’urgence.
Les scientifiques ont-ils identifié des signes annonciateurs permettant de prévoir un séisme imminent ?
Les scientifiques cherchent activement à identifier des précurseurs fiables qui permettraient d’alerter avant une rupture sismique, mais aucun signal suffisamment fiable n’a encore été mis en évidence.
Il existe des cas anecdotiques où des essaims de petits séismes ont précédé une rupture majeure et qui, rétrospectivement, auraient pu constituer des indices précoces d’un grand séisme à venir. Mais ce n’est pas systématique.
L’apprentissage automatique a permis de mettre en évidence des modifications régulières de la microsismicité précédant les ruptures majeures, et certaines études sur la physique des séismes ont commencé à expliquer pourquoi ce phénomène se produit.
À lire aussi : Une IA pour détecter les signes avant-coureurs des séismes lents
Il y a donc de bonnes raisons d’espérer qu’à l’avenir, nous serons capables de relier ces différents indices et de mieux comprendre les mécanismes en jeu. Mais nous n’en sommes pas encore là.
En revanche, il est possible d’émettre des alertes à très court terme. Lorsqu’un séisme débute, il génère plusieurs types d’ondes sismiques qui se propagent à des vitesses différentes. Les plus rapides arrivent en premier et peuvent être détectées, ce qui permet aux scientifiques de prévoir l’arrivée des deuxième et troisième trains d’ondes, plus lents et généralement plus destructeurs.
Après les premières ondes, appelées ondes P, arrivent les ondes S, ou ondes de cisaillement, qui sont un peu plus puissantes. Viennent ensuite les ondes de surface. Les premières ondes P peuvent déclencher les systèmes d’alerte précoce, offrant seulement quelques secondes de réaction, mais cela suffit pour interrompre le trafic, fermer les gazoducs, arrêter les trains à grande vitesse et sécuriser les infrastructures sensibles aux secousses. Cela peut également laisser juste assez de temps pour se mettre à l’abri et éviter d’être tué par l’effondrement d’un bâtiment, au bureau comme à la maison.
Quels sont désormais les risques pour le Venezuela ?
Les géologues connaissent bien la tectonique de cette région, car ils cartographient ces failles et étudient leur comportement depuis des décennies. Mais pour comprendre précisément cet événement, les scientifiques doivent se rendre sur le terrain afin d’évaluer l’ampleur des dégâts et de mesurer l’étendue de la rupture.
Par ailleurs, les séismes entraînent d’autres risques. Après les secousses, la région reste pendant plusieurs mois, voire plusieurs années, plus exposée aux glissements de terrain, car les roches ont été déstabilisées.
Cela signifie que les prochaines fortes pluies risquent de déclencher des glissements de terrain. Le Venezuela doit donc s’attendre à de nouveaux dégâts, à d’autres dangers et, malheureusement, à de nouvelles pertes humaines.
Sylvain Barbot ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
02.07.2026 à 08:23
Que deviennent les fûts de déchets radioactifs immergés dans l’Atlantique dans les années 1970 et 1980 ? Les débuts de réponse d’une expédition scientifique
Texte intégral (2245 mots)

Entre 1971 et 1982, plus de 200 000 fûts de déchets radioactifs furent immergés par plusieurs pays européens dans l’Atlantique Nord-Est, à des profondeurs atteignant plus de 4 700 mètres. La localisation exacte de ces barils et surtout leurs impacts possibles sur l’environnement des grands fonds restaient à ce jour largement inconnus depuis des études des années 1980.
Les campagnes à la mer NODSSUM 2025 et 2026, portées par le CNRS et réalisées avec les moyens de la Flotte océanographique française, ont permis d’identifier plusieurs milliers de ces barils.
À l’aide du sous-marin Nautile, nous avons inspecté visuellement plusieurs dizaines de ces fûts, documenté leur degré avancé de dégradation et observé des containers particulièrement corrodés.
Le contenu de certains d’entre eux se répand sur le fond marin environnant. Ces fûts sont colonisés par différents organismes, notamment des anémones, des éponges et des crabes.

Sur cinq sites d’étude retenus, à proximité immédiate et au contact des fûts, le Nautile a réalisé des prélèvements détaillés de sédiments, d’eau, d’organismes et de communautés microbiennes. Les habitats rocheux voisins ont également été explorés par le sous-marin, afin de les comparer avec les écosystèmes présents sur et autour des fûts.
Des instruments de mesure de radioactivité de terrain embarqués ont détecté des signaux significatifs de radionucléides spécifiquement liés à ces déchets, le cobalt 60 et le niobium 94, en plus du césium 137 et de l’américium 241 (ces derniers sont également des marqueurs des essais aériens d’armes et accidents nucléaires, mais présents ici dans des quantités bien supérieures à ce marquage classique).
Ces mesures et contrôles radiologiques ont permis de confirmer l’absence de contamination des instruments déployés (y compris le Nautile) et de s’assurer que les niveaux d’activité n’induisaient pas de problèmes majeurs de radioprotection pour les scientifiques de la campagne à la mer.
Comment ces observations ont-elles été réalisées ?
La zone de déversement couvre une surface d’environ 14 500 kilomètres carrés. Pour identifier les fûts et définir les cibles de notre étude, le robot autonome Ulyx de la Flotte océanographique française a été déployé lors de la campagne 2025.
Capable de plonger jusqu’à 6 000 mètres et survolant les fonds marins d’environ 70 mètres, il acquiert des données sonar haute résolution avec une précision de 5 centimètres. Ulyx a permis de cartographier environ 165 kilomètres carrés, soit moins de 2 % de toute la zone de déversement. Plus de 3 500 fûts ont été localisés, alignés selon les trajectoires des navires ayant effectué les déversements.

Ulyx a également pu s’approcher et survoler le plafond océanique à environ 8-10 mètres au-dessus du fond marin pour se procurer des images. Nous avons prospecté cinq zones et photographié environ 50 fûts, montrant l’épanchement de matière hors des fûts. Ces données ont été combinées à un échantillonnage de sédiments réalisé en 2025 à distance des fûts depuis le navire, dont l’analyse a révélé la présence de radionucléides artificiels probablement associés à ce déversement, supérieure à celle attendue dans les grands fonds.
Les images de fûts dégradés prises par Ulyx, associées aux analyses de sédiments montrant les niveaux d’activité les plus élevés, ont fourni les cibles des plongées du Nautile lors de la campagne 2026.
Pourquoi est-ce important ?
Tout d’abord, ce site constitue un laboratoire unique pour comprendre le devenir des radionucléides dans les grands fonds et leurs interactions avec les écosystèmes de l’océan profond.
Les fûts modifient l’environnement en offrant un substrat dur qui se trouve colonisé, facilitant potentiellement ces transferts de radionucléides vers les organismes vivants, avec des conséquences encore inconnues, qui vont être évaluées par le projet NODSSUM. Les résultats de l’analyse des échantillons fourniront, dans les mois à venir, des indices sur l’impact de ces écosystèmes, y compris les microorganismes, ainsi que sur leur rôle dans le transfert et la mobilisation de ces radionucléides, permettant d’évaluer leurs impacts.
Enfin, il s’agit de l’une des premières études radioécologiques en grands fonds marins, ayant nécessité la mise en place et le développement de nouvelles procédures et méthodologies allant de la définition de la stratégie d’échantillonnage jusqu’à la radioprotection à bord.
Quelles vont être les suites ?
Les campagnes de 2025 et de 2026 ont permis de collecter un ensemble riche et vaste de données et d’échantillons : cartes sonar, images de fûts et des zones adjacentes, des centaines d’échantillons de sédiments, plusieurs dizaines de poissons, des milliers de litres d’eau filtrés et de nombreux organismes, dont des anémones et des concombres de mer.

Les images seront analysées afin de caractériser la composition et la structure des écosystèmes associés aux fûts et de ceux des zones avoisinantes. Les échantillons (sédiments, eau, faune) seront analysés dans les mois à venir par un groupe français et international de chercheurs (Norvège, Allemagne, Espagne) afin d’identifier et de quantifier différents radionucléides artificiels et d’étudier leur dispersion depuis les fûts vers l’environnement des grands fonds.
L’ensemble de ces données constituera l’une des études radioécologiques des grands fonds les plus complètes à ce jour et permettra de mieux comprendre le cycle biogéochimique des radionucléides dans ces environnements.
Pour aller plus loin et suivre l’actualité du projet NODSSUM, retrouvez-le sur Bluesky et LinkedIn, #NODSSUM.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Javier Escartin a reçu des financements de l'ANR pour autres projets et sans lien a la campagne NODSSUM.
Patrick Chardon a reçu des financements de ANR sans lien avec le projet NODSSUM
01.07.2026 à 17:25
Décapitaliser le savoir scientifique et le rendre accessible à tous : des solutions existent
Texte intégral (2762 mots)

Publier et accéder à des articles scientifiques coûte très cher aux organismes de recherche. L’accès ouvert est-il la solution parfaite ? Découvrez des exemples concrets de publications qui allient gratuité, exigence et rigueur.
L’édition scientifique est une industrie particulièrement rentable. Les estimations les plus récentes suggèrent qu’elle génère environ 19 milliards de dollars US (soit 16,67 milliards d’euros) de chiffre d’affaires par an, avec des marges qui avoisinent les 40 %. Ces chiffres vertigineux reflètent en grande partie le fait que des maisons d’édition privées, telles qu’Elsevier, Springer Nature, Wiley, Taylor & Francis ou SAGE, capitalisent sur un travail largement financé par des fonds publics.
Cette monétisation se fait soit conditionnant l’accès à un article scientifique au paiement d’un droit ou d’un abonnement, soit en faisant payer les auteurs pour publier en libre accès pour le lecteur. Pourtant, la majeure partie du travail nécessaire à la publication, notamment la rédaction, l’évaluation par les pairs et une grande partie du travail éditorial, est fournie gratuitement par les chercheurs. La conséquence directe est que la richesse d’un institut ou d’un pays dicte encore en partie l’accès au savoir scientifique.
Les barrières payantes
Pendant des décennies, la vaste majorité de la recherche a été publiée derrière des barrières payantes (paywalls). Cela signifie que les scientifiques, leurs institutions et le grand public doivent payer pour accéder aux découvertes scientifiques. Une personne peut acheter l’accès à un article spécifique pour quelques dizaines ou parfois une centaine d’euros. Les instituts de recherche, quant à eux, paient des abonnements qui se chiffrent souvent en millions d’euros à des milliers de revues scientifiques afin que leurs chercheurs puissent accéder à ces articles.
Rétrospectivement, avant l’avènement d’Internet et la diffusion massive de revues au format électronique, il était compréhensible que la production d’articles scientifiques engendre des coûts très importants, notamment en raison de l’impression et de la distribution physique des revues dans les bibliothèques universitaires. Aujourd’hui, cette justification n’est plus fondée.
Alors même que les coûts de production ont fortement diminué grâce à la diffusion numérique des articles, les frais de publication ont drastiquement augmenté. En réponse à cette privatisation du savoir, Aaron Swartz a publié en 2008 le Guerilla Open Access Manifesto, qui a eu pour but d’alerter et d’insister sur le manque d’accès pour les pays du Sud global.
Dans ce contexte, Alexandra Elbakyan a créé Sci-Hub en 2011, une plateforme, qui permet de donner accès à un grand nombre de publications scientifiques, devenue l’une des plus grandes fuites de connaissances scientifiques de notre époque. Bien que cette initiative repose sur une revendication éthique d’accès universel au savoir, elle demeure illégale et condamnée dans de nombreux pays, et ne saurait être une solution pérenne au problème de l’accès à la connaissance scientifique.
L’accès ouvert est-il une solution ?
Face à la frustration croissante suscitée par le verrouillage des résultats de la recherche derrière des barrières payantes, et aux fortes inégalités d’accès à la science qui en découlent, l’Open Access (OA), ou accès ouvert, est de plus en plus souvent exigé par les agences de financement de la recherche, et parfois par les gouvernements eux-mêmes. L’objectif est simple : faire en sorte que la recherche, en particulier lorsqu’elle est financée par des fonds publics, soit accessible comme un bien commun.

Aujourd’hui, si l’Open Access est devenu la norme, plusieurs modèles coexistent et ne répondent pas tous au problème de la même manière. Les trois principales voies sont l’OA verte, l’OA dorée et l’OA diamant.
L’OA verte consiste à publier dans une revue classique, souvent commerciale, puis à déposer une version acceptée mais non formatée du manuscrit dans une archive ouverte ou un dépôt institutionnel. L’OA dorée rend l’article final immédiatement accessible à tous, mais repose sur des frais de publication s’élevant à plusieurs milliers d’euros, payés par les auteurs ou leurs institutions. L’OA diamant, enfin, permet une publication gratuite pour les auteurs et une lecture gratuite pour les lecteurs, grâce à des revues portées par des communautés scientifiques, des bibliothèques universitaires ou des institutions sans but lucratif.
Les modèles d’OA verte et dorée restent dépendants des éditeurs commerciaux et entraînent souvent des coûts cachés pour les chercheurs, les institutions ou les financeurs. À l’inverse, l’OA diamant est porté par la communauté, gratuit à la fois pour les auteurs et pour les lecteurs, et maintient la recherche comme un bien public plutôt qu’une source de profit privé. Si l’OA verte améliore l’accès à court terme, elle peut aussi retarder des changements structurels plus profonds en préservant le système existant.
Des exemples d’accès diamant
Grâce aux avancées techniques récentes, il est facile de partager du code informatique, et la communauté scientifique, soutenue par les financeurs publics, s’est organisée pour créer Open Journal System, qui est un logiciel clé en main permettant de gérer l’ensemble du processus éditorial d’une revue scientifique (de la soumission des manuscrits à l’évaluation par les pairs, l’édition, la publication et la diffusion).
Aujourd’hui le système est utilisé dans 148 pays dans le monde et permet la gestion éditoriale gratuite de journaux par les scientifiques eux-mêmes. Parmi ces journaux, Sedimentologika, créé en novembre 2022, qui va bientôt publier son cinquantième article dans le domaine de la sédimentologie, ou Planetary Research, qui va publier son premier article dans le domaine de la planétologie en juillet 2026, sont deux revues que nous avons contribué à fonder.
D’autres initiatives, structurées en plateforme, comme Sci|Post, historiquement ancré dans le domaine de la physique, ou Episciences, proposent désormais des modèles étendus à l’ensemble des domaines de la science, y compris les sciences humaines et sociales. À l’échelle plus locale des établissements et universités, de nouveaux projets de presse académique émergent, tel que POPS à l’Université Paris-Saclay.
Les scientifiques ont aussi proposé d’autres façons de publier, s’affranchissant des codes de conduites les plus courants. Par exemple, la publication dans arXiv de l’Université Cornell, un gigantesque dépôt gratuit de 2,4 millions d’articles, ou sur son équivalent français HAL, permettent le partage de manuscrit sans validation par les pairs (article de type « preprint »). Le seul critère d’accès est que le déposant doit avoir un e-mail institutionnel ou être coopté par ses pairs (critère récent, nécessaire pour filtrer les faux articles créés par intelligence artificielle). La garantie de qualité scientifique y reste donc relativement limitée, mais l’avantage réside dans l’immédiateté de la diffusion à tous. De nombreux travaux très influents et largement cités, par exemple dans le domaine de l’intelligence artificielle, sont ainsi accessibles sans n’avoir jamais été évalués par les pairs. Cependant, la plupart des articles déposés sur arXiv sont également publiés par la suite dans des revues scientifiques après processus d’évaluation. Dans ce cas, arXiv sert principalement de plateforme de diffusion rapide et d’échange scientifique venant compléter plutôt que remplacer le processus éditorial traditionnel.
Certaines sociétés savantes proposent depuis longtemps des revues en accès diamant, comme les Comptes Rendus de l’Académie des sciences ou certaines communications de la Société américaine de mathématique. Malheureusement, le modèle économique en accès diamant est parfois difficile à établir, mais des solutions innovantes sont proposées. Par exemple, le Bulletin de la Société mathématique de France propose un modèle d’inscription-pour-ouverture (Subscribe-to-Open, S2O). Il s’agit ici chaque année de payer un abonnement pour la lecture, mais lorsque le seuil de rentabilité est atteint, tous les articles publiés dans cette revue deviennent accessibles librement ad vitam aeternam. Chaque année, le compteur est remis à zéro.
Une autre façon de publier consiste à proposer une discussion libre à propos de l’article après publication. Ce type de solution a l’avantage d’évaluer l’article, mais, pour l’instant, aucune solution pérenne et de grande ampleur n’a émergé. Il existe néanmoins des solutions intéressantes. Par exemple, Peer Community In comporte aujourd’hui 21 journaux thématiques avec relecture, publie gratuitement à la fin de l’évaluation et laisse le choix aux auteurs de soumettre de nouveau dans un journal traditionnel ou non.
Des dangers futurs, mais aussi des opportunités
L’édition scientifique est, aujourd’hui, mise en péril par les logiques capitalistes des grands éditeurs privés, qui s’enrichissent grâce à une aura et une respectabilité pourtant produite par les scientifiques eux-mêmes. Briser ce système reste difficile, car les scientifiques les plus réputés sont sollicités par les journaux les plus en vue, contribuant à reproduire ce modèle. D’autre part, les grands groupes éditoriaux contrôlent une part importante des outils de recherche, d’indexation et de mise en relation des articles scientifiques, renforçant encore la visibilité de leurs propres revues.
Par ailleurs, ces acteurs participent activement à la production d’une pseudoscience scientométrique, en proposant des évaluations quantitatives, comme les nombres de citations, les facteurs d’impacts, etc. Bien que les limites et les dérives de ces métriques aient été largement documentées, et malgré l’existence d’initiatives, comme DORA, appelant à une réforme de l’évaluation de la recherche, de nombreuses politiques publiques restent cantonnées à ces indicateurs pour évaluer la science (on privilégie la quantité d’articles à la qualité). Les carrières des chercheurs restent ainsi largement évaluées à travers le prestige supposé des revues dans lesquelles ils publient.
À l’heure où les grandes puissances mondiales sont tentées par des virages autoritaires et la promotion des faits « alternatifs », la science doit plus que jamais préserver son indépendance et maintenir la confiance du grand public. Dans un contexte de disette budgétaire, reprendre collectivement la maîtrise des infrastructures de publication scientifique de manière plus efficiente, moins onéreuse et plus durable apparaît comme un enjeu majeur pour la communauté scientifique.
Au-delà du monde académique, l’ouverture des connaissances bénéficie également au grand public, aux enseignants, aux associations, aux décideurs et au secteur privé, en facilitant l’accès aux avancées scientifiques les plus récentes. Enfin, rendre la science plus accessible ne signifie pas seulement diffuser davantage de savoirs : cela contribue aussi à renforcer la transparence, l’esprit critique et la capacité collective à débattre et à répondre aux défis actuels de manière informée et raisonnée.
Frédéric Schmidt est Professeur à l'Université Paris-Saclay, membre de l'Institut Universitaire de France (IUF). Il a obtenu divers financements publics (Université Paris-Saclay, CNRS, CNES, ANR, UE, ESA, France 2030) ainsi que des financements privés (Airbus) pour ses recherches. Il est éditeur scientifique du journal Planetary Research et membre fondateur de l'association Planetary Research Cooperative, l'association loi 1901 qui détient le journal.
Camille Thomas est co-fondateur et membre du comité de direction de Sedimentologika. Il a reçu des financements du fonds pour la recherche scientifique Suisse. Il travaille bénévolement comme manager éditorial pour Sedimentologika et est co-président de l'association loi 1901 qui détient le journal.
Romain Vaucher est co-fondateur et membre du comité de direction de Sedimentologika. Il travaille bénévolement comme manager éditorial pour Sedimentologika et est vice-président de l'association loi 1901 qui détient le journal.