
10.07.2026 à 11:01
3I/Atlas, une comète venue d’une autre étoile qui ne ressemble à rien de connu dans le Système solaire
Texte intégral (1829 mots)

Troisième objet interstellaire jamais détecté, 3I/Atlas ne ressemble à aucune comète du Système solaire. Sa composition et son âge exceptionnel en font un précieux témoin de la jeunesse de notre galaxie.
Des astronomes viennent de révéler de nouveaux détails sur la composition et l’âge d’une comète de passage, née autour d’une étoile lointaine. Ils concluent de leurs travaux que la composition de 3I/Atlas est radicalement différente de celle de tous les objets connus de notre Système solaire.
Trois études, publiées récemment et ici, apportent ainsi un nouvel éclairage sur les origines de cette comète hors du commun. 3I/Atlas semble s’être formée dans un environnement très froid, il y a environ 12 milliards d’années.
La comète est un objet interstellaire (interstellar object, ou ISO), c’est-à-dire un astéroïde ou une comète provenant de l’extérieur du Système solaire. Il s’agit du troisième objet de ce type jamais identifié, après 1I/ʻOumuamua et 2I/Borisov. Elle a été découverte il y a presque exactement un an, alors qu’elle arrivait de l’espace interstellaire sur une trajectoire traversant le Système solaire interne avant de s’en éloigner de nouveau.
Ces origines lointaines rendent les objets interstellaires particulièrement fascinants pour les astronomes, car ils constituent des fragments matériels d’autres systèmes planétaires, apportés jusqu’à nous par les courants gravitationnels de la galaxie et que nous pouvons étudier sans quitter le confort de notre propre Système solaire.
En tant que comète, 3I/Atlas contenait des glaces qui se sont sublimées, c’est-à-dire qu’elles sont passées directement de l’état solide à l’état gazeux. En se réchauffant sous l’effet du Soleil, ces gaz se sont échappés de la comète, donnant naissance à une spectaculaire chevelure (ou coma), l’enveloppe lumineuse qui entoure son noyau, ainsi qu’à une longue queue.
Une comète ne possède pas de source de lumière propre. La poussière présente dans sa chevelure réfléchit la lumière du Soleil, tandis que ses composés volatils (des substances qui se vaporisent ou se subliment facilement) émettent une fluorescence.
Mais il ne s’agit pas d’un simple spectacle lumineux : chaque molécule fluorescente laisse une empreinte spectrale dans la lumière qui parvient jusqu’à nos télescopes. Ces signatures permettent d’identifier les composés chimiques présents dans la comète.
Pour les révéler, les astronomes décomposent la lumière en ses différentes longueurs d’onde grâce à une technique appelée spectroscopie. Ils peuvent ainsi déterminer la composition chimique de la comète.
Un cocktail chimique inédit
Les observations ont révélé que 3I/Atlas renferme un mélange d’eau, de dioxyde et de monoxyde de carbone, de méthane, de cyanures, de sulfures, ainsi que d’atomes de fer et de nickel à l’état libre. Pris séparément, ces composés n’ont rien d’inhabituel : ils sont régulièrement détectés dans les comètes de notre propre Système solaire. En revanche, leurs proportions diffèrent nettement dans 3I/Atlas. Sa forte teneur en dioxyde de carbone (CO2) et sa faible abondance en ammoniac (NH3) trahissent son origine extérieure au Système solaire.
Les molécules constituées d’atomes appartenant à différents isotopes (des variantes d’un même élément chimique) présentent également des signatures spectrales légèrement différentes. Grâce à l’éclat de 3I/Atlas et à la puissance des plus grands télescopes, les astronomes ont pu distinguer ces signatures et mesurer les rapports isotopiques de la comète.
L’une des nouvelles études, publiée dans Nature, s’appuie sur les signatures spectrales de l’eau et du dioxyde de carbone mesurées par le télescope spatial James Webb pour déterminer le rapport entre les deux principaux isotopes du carbone, le 12C et le 13C, présents dans 3I/Atlas, ainsi que son rapport deutérium/hydrogène (D/H), le deutérium étant une forme lourde de l’hydrogène.
Ces résultats sont particulièrement enthousiasmants, car les rapports isotopiques d’un objet interstellaire comme 3I/Atlas sont censés refléter ceux du disque protoplanétaire dans lequel il s’est formé. Ils permettent donc de reconstituer avec une grande précision les conditions de sa formation, ainsi que les caractéristiques de l’étoile autour de laquelle il est né.
L’eau de 3I/Atlas présente un rapport deutérium/hydrogène (D/H) d’environ 1 %, soit une valeur nettement supérieure à celle mesurée dans toutes les comètes connues du Système solaire.
De telles concentrations en deutérium ne se rencontrent que dans des environnements extrêmement froids, où la température est inférieure à 30 kelvins (-243 °C). Dans ces conditions, les atomes d’hydrogène « ordinaires » sont progressivement remplacés par des atomes de deutérium, plus lourds, dans la glace d’eau qui recouvre de minuscules grains de poussière. Avec le temps, ces grains glacés s’agglomèrent pour former des comètes.
Une voyageuse venue des premiers âges de la galaxie
Le rapport 12C/13C de 3I/Atlas est lui aussi exceptionnel, bien supérieur à toutes les valeurs mesurées dans le Système solaire. Ce rapport isotopique fonctionne comme une véritable horloge cosmique. Au début de l’histoire de l’Univers, la première génération d’étoiles produisait un carbone très riche en 12C par rapport au 13C. Puis, au fil des cycles de naissance et de mort des étoiles, ce rapport a progressivement diminué. Si 3I/Atlas présente une valeur aussi élevée, c’est qu’elle s’est formée très tôt dans l’histoire de la Voie lactée, il y a environ 12 milliards d’années.
Des études menées peu après sa découverte avaient déjà suggéré que 3I/Atlas était probablement âgée d’au moins 7 milliards d’années, d’après sa vitesse. Son ancienneté est donc désormais étayée par plusieurs indices indépendants.
Si le ciel nocturne, au-delà des confins du Système solaire, peut sembler immuable, l’Univers comme notre galaxie évoluent bel et bien, à l’échelle de milliards d’années.

Lorsque 3I/Atlas s’est formée, l’Univers était encore dans sa prime jeunesse et la Voie lactée était encore en train de se construire, au gré de violentes collisions et fusions avec d’autres galaxies.
Si l’étoile autour de laquelle 3I/Atlas s’est formée avait une masse comparable à celle du Soleil, elle a probablement déjà achevé son existence. Les objets interstellaires qu’elle a éjectés peu après sa naissance, comme 3I/Atlas, lui ont ainsi survécu.
Au cours des dix prochaines années, de nouveaux télescopes de pointe dédiés à la découverte d’objets célestes, comme le NEO Surveyor de la NASA et l’observatoire Vera C. Rubin, au Chili, devraient multiplier par dix le nombre d’objets interstellaires connus. Cette moisson offrira aux astronomes une véritable archive fossile de l’évolution des systèmes planétaires tout au long de l’histoire de la Voie lactée.
Matthew Hopkins a reçu une bourse Elaine P. Snowden Fellow à l'université de Canterbury, en Nouvelle-Zélande.
10.07.2026 à 11:00
Les algues ne sont pas des plantes… et six autres faits surprenants sur la flore aquatique
Texte intégral (2750 mots)

Des plantes sans racines, d’autres carnivores, certaines capables de fleurir sous l’eau… Les plantes aquatiques ont développé des adaptations spectaculaires qui défient notre vision du monde végétal.
À l’abri des regards, sous la surface des eaux, se déploie un monde végétal d’une étonnante inventivité et parmi les plus importants sur le plan écologique.
Comme je le souligne dans une publication récente, les plantes aquatiques ont développé une extraordinaire diversité d’adaptations pour vivre sous l’eau. Certaines fleurissent sous la surface, d’autres capturent des animaux grâce à d’ingénieux pièges. Voici sept faits qui montrent à quel point ces organismes remarquables bousculent nos idées reçues sur ce qu’est une plante et sur les stratégies qu’elle déploie pour survivre.
1. Les plantes n’en finissent pas de retourner à l’eau
Quand on pense aux plantes, on imagine spontanément les forêts, les prairies ou les champs. Pourtant, au cours de leur histoire évolutive, les plantes sont retournées à de nombreuses reprises dans le milieu aquatique, là même où elles sont apparues. Il y a environ 500 millions d’années, elles ont conquis les terres émergées. Depuis, nombre d’entre elles ont fait le chemin inverse. Les scientifiques estiment que le mode de vie aquatique est apparu indépendamment plus de 100 fois au sein de différents groupes de plantes.
Les nénuphars font flotter leurs feuilles à la surface, les lentilles d’eau dérivent librement et les herbiers marins vivent entièrement immergés dans l’océan. Certains de ces groupes sont retournés à l’eau il y a plus de 100 millions d’années. Cette réapparition répétée des plantes aquatiques constitue l’un des exemples les plus spectaculaires de l’évolution convergente dans la nature.
2. Les plantes qui n’en sont pas
Parmi les organismes les plus visibles sous la surface de l’eau figurent les algues. Elles réalisent la photosynthèse et ressemblent souvent à des plantes sous-marines. Pourtant, malgré les apparences, les algues ne sont pas de véritables plantes.

Les algues marines appartiennent en réalité à plusieurs lignées d’algues distinctes dans l’arbre du vivant. Les laminaires géantes, qui forment de véritables forêts sous-marines, sont des algues brunes. Le nori et la dulse sont des algues rouges, tandis que la laitue de mer appartient aux algues vertes.
Contrairement aux plantes, elles ne possèdent ni véritables racines, ni tiges, ni feuilles, et ne produisent ni fleurs ni graines. Leur ressemblance avec les plantes rappelle toutefois que l’évolution peut conduire à des formes très similaires chez des organismes pourtant très éloignés, lorsqu’ils sont confrontés aux mêmes contraintes environnementales.
3. Des plantes qui vivent dans les profondeurs
Les plantes ont besoin de lumière pour réaliser la photosynthèse, ce qui les cantonne généralement aux milieux terrestres ou aux eaux peu profondes. Pourtant, certaines mousses aquatiques survivent à des profondeurs étonnantes. La faucillette courbée (Drepanocladus aduncus) a ainsi été observée à 140 mètres sous la surface dans les eaux exceptionnellement limpides de Crater Lake, dans l’État américain de l’Oregon. Il s’agit de la plante aquatique connue poussant aussi sur terre qui vit à la plus grande profondeur, environ la hauteur de la cathédrale de Strasbourg.
Des mousses de grande profondeur ont également été recensées dans des lacs de Nouvelle-Zélande, d’Antarctique et d’autres régions. Elles prospèrent dans des environnements si profonds qu’ils sont presque totalement privés de lumière et où très peu d’animaux peuvent survivre.
4. Des plantes sans racines
Les racines sont l’une des caractéristiques emblématiques des plantes. Elles les ancrent dans le sol et y puisent l’eau ainsi que les nutriments. Pourtant, de nombreuses plantes aquatiques ont considérablement réduit leur système racinaire, et certaines semblent même avoir complètement perdu leurs racines.

La vie sous l’eau change les règles du jeu. L’eau et les nutriments dissous entourent directement la plante, rendant les vastes systèmes racinaires beaucoup moins utiles que sur terre. De nombreuses espèces aquatiques absorbent ainsi les nutriments directement par leurs feuilles et leurs tiges.
Les lentilles d’eau en offrent l’un des exemples les plus extrêmes. Certaines espèces ne possèdent qu’une seule racine, contrairement à des parentes comme la grande lentille d’eau, qui en développe plusieurs. Quant aux espèces du genre Wolffia – les plus petites plantes à fleurs du monde –, elles n’ont plus aucune racine et flottent librement à la surface de l’eau. Un individu mesure à peine un millimètre de long et ses fleurs ne dépassent pas 0,3 millimètre.
5. Des plantes carnivores sous l’eau
Toutes les plantes aquatiques ne se contentent pas de la lumière du Soleil et des nutriments dissous dans l’eau. Certaines complètent leur alimentation en capturant et en digérant de petits animaux.
Les exemples les plus spectaculaires sont les utriculaires (Utricularia), un groupe de plantes aquatiques dépourvues de racines que l’on trouve dans les eaux douces du monde entier. Leurs feuilles se sont transformées en minuscules pièges en forme de vessie qui créent un vide en expulsant l’eau contenue dans leur cavité.

Lorsqu’un minuscule animal effleure les poils sensitifs situés à l’entrée du piège, une trappe s’ouvre brusquement et la proie est aspirée en moins d’une milliseconde. Les pièges des utriculaires figurent ainsi parmi les mouvements les plus rapides du règne végétal. S’ils capturent le plus souvent de petits invertébrés aquatiques, il leur arrive aussi de piéger des larves de poissons et des têtards.
Ce mode de vie carnivore permet aux utriculaires de prospérer dans des eaux pauvres en nutriments, où la plupart des autres plantes peinent à survivre.
6. Une pollinisation portée par les courants
Quand on pense à la pollinisation des plantes, on imagine volontiers des abeilles butinant de fleur en fleur par une belle journée ensoleillée. Mais sous l’eau, la pollinisation devient beaucoup plus compliquée. Au lieu de compter sur les insectes ou le vent, de nombreuses plantes aquatiques, comme les herbiers marins, utilisent directement les courants pour transporter leur pollen jusqu’à sa destination.
Sur terre, les plantes attirent leurs pollinisateurs en diffusant des parfums dans l’air. Sous l’eau, en revanche, ces signaux volatils sont inefficaces. Cette contrainte a conduit à un changement évolutif : les plantes entièrement aquatiques, comme les herbiers marins, ont perdu les gènes responsables de la production de ces composés odorants. Ne procurant plus d’avantage, ils ont progressivement disparu au cours de l’évolution.
7. Les herbiers marins et les mangroves, de puissants puits de carbone
Les herbiers marins et les mangroves capturent et stockent le carbone dans leurs tissus ainsi que dans les sédiments qui les entourent, ce qui les classe parmi les puits de carbone naturels les plus efficaces de la planète. Ensemble, ils emmagasinent ce que les scientifiques appellent le « carbone bleu » : le carbone piégé dans les écosystèmes côtiers, où il peut rester stocké pendant des siècles, voire des millénaires.

À l’échelle mondiale, ces écosystèmes – herbiers marins et mangroves – stockent 11,5 milliards de tonnes de carbone. Les mangroves représentent à elles seules le plus grand réservoir de carbone bleu, avec 6,5 milliards de tonnes.
Qu’elles capturent leurs proies en quelques fractions de milliseconde, poussent dans une quasi-obscurité ou stockent du carbone pendant des siècles, les plantes aquatiques témoignent de l’extraordinaire capacité du vivant à s’adapter.
Alexander Bowles a reçu une bourse « Glasstone Fellowship » à l'Université d'Oxford.
09.07.2026 à 17:26
Avec « The Mandalorian », comprendre les enjeux derrière les métaux rares
Texte intégral (2888 mots)

Armures étincelantes, forges ancestrales et batailles galactiques : dans l’univers de Star Wars, le « beskar » occupe une place à part. Ce métal légendaire, au cœur de l’identité mandalorienne, est réputé presque indestructible. Il résiste aux tirs de blaster et autres pistolasers, supporte des températures extrêmes et constitue un héritage transmis de génération en génération.
Avec la sortie en salle, le 20 mai dernier, de The Mandalorian and Grogu, premier film Star Wars à retrouver les écrans de cinéma depuis l’Ascension de Skywalker en 2019, le « beskar », matériau légendaire, revient au centre du récit. Présenté comme quasiment indestructible, capable de résister aux tirs de blaster et même aux sabres laser, le beskar appartient évidemment au domaine de la fiction.
Pourtant, derrière cette invention scénaristique se cache une réalité étonnamment familière : notre monde dépend lui aussi de matériaux rares, concentrés dans quelques régions du monde, convoités par les grandes puissances et devenus indispensables au fonctionnement des technologies modernes. La galaxie de Star Wars n’est peut-être pas aussi éloignée de nos préoccupations géologiques qu’elle en a l’air.
Un métal fictif qui ressemble à nos ressources stratégiques
Dans The Mandalorian, le beskar est bien davantage qu’un simple matériau. Il est rare, convoité, difficile à extraire et étroitement associé à une région unique de la galaxie : la planète Mandalore. Sa possession confère un avantage décisif, qu’il soit militaire, politique ou symbolique.
Cette situation n’est pas sans rappeler celle de certaines matières premières que géologues et économistes qualifient aujourd’hui de « critiques » ou de « stratégiques ». Ces ressources sont indispensables au fonctionnement de technologies essentielles, mais leur production demeure concentrée dans un nombre limité de pays, créant des dépendances parfois importantes.
Les terres rares en constituent sans doute l’exemple le plus connu. Derrière ce nom se cache un groupe de 17 éléments chimiques utilisés dans les aimants permanents des éoliennes, les moteurs de véhicules électriques, les smartphones ou encore certains équipements militaires. D’autres métaux, comme le cobalt, le gallium, le germanium ou l’indium, jouent également un rôle central dans les batteries, les semi-conducteurs ou les écrans tactiles.
Comme le beskar, ces ressources se distinguent moins par leur valeur marchande que par leur importance stratégique.
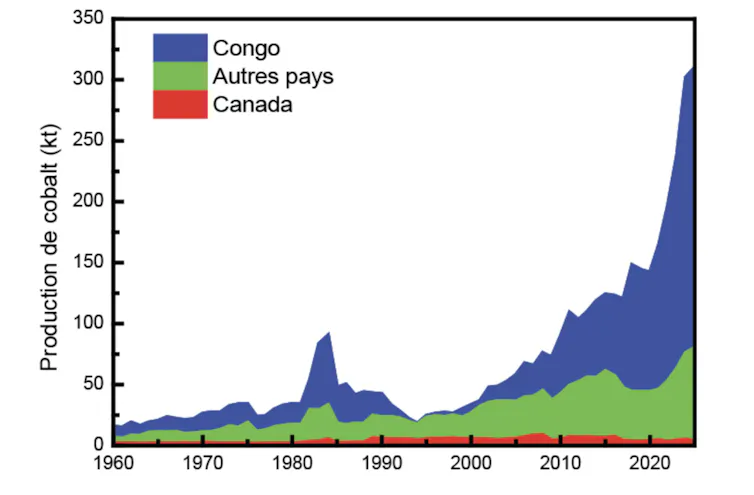
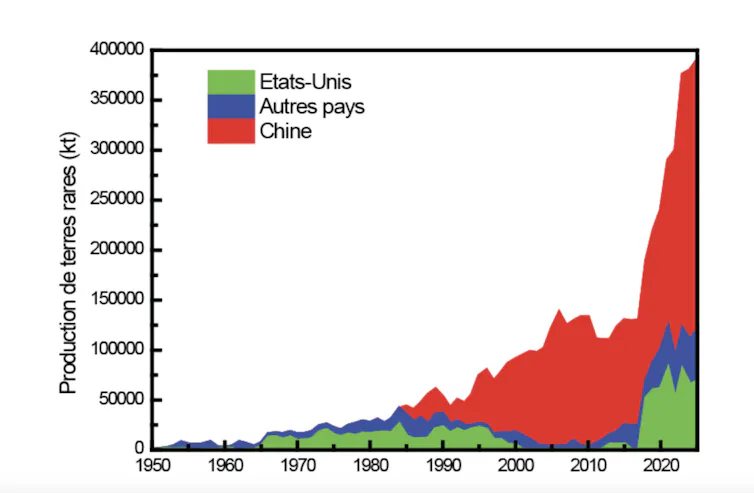
Leur répartition géographique est également très inégale. En 2025, la Chine assure près de 69 % de la production mondiale de terres rares et domine largement leur transformation industrielle. La République démocratique du Congo fournit quant à elle près des trois quarts du cobalt extrait dans le monde. Cette concentration crée une dépendance structurelle pour les grandes puissances industrielles, à l’image de celle que connaît la galaxie fictive de Star Wars vis-à-vis du beskar de Mandalore.
Quand la géologie rejoint la science-fiction
Les créateurs de Star Wars n’ont évidemment pas conçu le beskar comme un objet géologique. Pourtant, les propriétés qu’ils lui attribuent présentent une certaine cohérence avec ce que nous connaissons des matériaux les plus performants développés par l’industrie moderne.
Le beskar est présenté comme un alliage plutôt que comme un élément pur. Ce choix est particulièrement crédible. Dans le monde réel, les matériaux aux propriétés mécaniques exceptionnelles résultent presque toujours d’associations complexes entre plusieurs éléments chimiques.
L’acier inoxydable combine ainsi fer, chrome et nickel. Les alliages de titane utilisés dans l’aéronautique incorporent de l’aluminium et du vanadium. Les superalliages employés dans les turbines aéronautiques peuvent contenir une dizaine d’éléments différents afin de résister simultanément aux contraintes mécaniques, à l’oxydation et aux températures extrêmes.
La résistance thermique du beskar évoque également certains métaux réfractaires bien connus des géologues et des métallurgistes. Le tungstène, par exemple, possède la température de fusion la plus élevée parmi les métaux connus, atteignant 3 422 °C. Le rhénium, plus rare encore, est utilisé dans les composants soumis à des températures particulièrement élevées, notamment dans l’industrie aéronautique.

){kind=link}
Quant à sa capacité à absorber des impacts sans se rompre, elle rappelle les recherches menées depuis une vingtaine d’années sur les alliages à haute entropie. Ces matériaux de nouvelle génération associent plusieurs éléments en proportions voisines, produisant des combinaisons inédites de dureté, de résistance mécanique et de résistance à la corrosion.
Bien sûr, aucun de ces matériaux ne pourrait réellement arrêter un sabre laser. Mais la logique scientifique qui sous-tend le beskar apparaît moins fantaisiste qu’il n’y paraît au premier abord.
Des ressources au cœur des rapports de puissance
La comparaison devient encore plus frappante lorsqu’on s’intéresse à la géopolitique des ressources.
Dans l’univers du Mandalorian, le contrôle du beskar constitue un enjeu de pouvoir majeur. Les conflits qui entourent son extraction, sa circulation et sa réappropriation participent directement à l’équilibre politique de la galaxie. L’histoire récente fournit plusieurs exemples comparables.
En 2010, dans un contexte de tensions territoriales avec le Japon, la Chine a temporairement restreint ses exportations de terres rares. L’événement a provoqué une forte inquiétude parmi les industriels dépendants de ces matériaux et a accéléré les réflexions sur la diversification des approvisionnements.
Plus récemment, Pékin a instauré des restrictions à l’exportation concernant le gallium, le germanium, puis d’autres matériaux stratégiques utilisés dans les semi-conducteurs et les technologies de défense.
Ces épisodes rappellent que les matières premières critiques ne constituent pas seulement des ressources économiques. Elles représentent également des instruments d’influence et de souveraineté.
Face à ces enjeux, l’Union européenne a adopté en 2024 le Critical Raw Materials Act, destiné à renforcer la sécurité d’approvisionnement en matières premières critiques, à développer les capacités de recyclage et à diversifier les sources d’importation. Les États-Unis poursuivent des objectifs similaires à travers différents programmes de soutien à l’industrie minière et métallurgique.
Face à cette dépendance, deux grandes stratégies s’offrent aux pays importateurs : diversifier les sources d’extraction ou apprendre à récupérer ce que l’on a déjà consommé. C’est cette deuxième voie, celle du recyclage, que la série illustre, sans le savoir, avec une grande précision.
Le recyclage, ou l’art mandalorien appliqué à nos déchets
L’un des aspects les plus intéressants de la série réside peut-être dans la place accordée au recyclage du beskar. À plusieurs reprises, le personnage de l’armurière récupère d’anciens fragments de métal pour les fondre et leur donner une nouvelle forme. Dans la fiction, ce geste possède une dimension culturelle et spirituelle forte : il permet de préserver un héritage tout en l’adaptant aux besoins du présent.
Cette pratique fait écho à un défi bien réel. Aujourd’hui, moins de 1 % des terres rares contenues dans les produits en fin de vie sont effectivement recyclées. Les obstacles sont nombreux : faibles concentrations dans les objets, difficultés de démontage, coûts élevés des procédés de récupération ou encore insuffisance des filières de collecte.
Pourtant, les millions de véhicules électriques, d’éoliennes et d’équipements électroniques actuellement en circulation constituent déjà un immense gisement urbain de métaux stratégiques.
De nombreux programmes de recherche européens et asiatiques cherchent ainsi à développer de nouvelles méthodes permettant de récupérer le néodyme des aimants permanents ou le cobalt contenu dans les batteries. À leur manière, ces chercheurs pratiquent eux aussi une forme de forge moderne : ils transforment les déchets technologiques d’aujourd’hui en ressources stratégiques de demain.
Ce que le beskar révèle de notre monde
Au fond, The Mandalorian ne raconte pas une histoire de métallurgie. La série parle avant tout d’identité, de transmission, de mémoire collective et de résilience culturelle.
Mais si le beskar occupe une place aussi centrale dans cet univers, c’est précisément parce qu’il matérialise ces enjeux sous une forme immédiatement compréhensible. La rareté de la ressource, la dépendance qu’elle crée et les conflits qu’elle suscite donnent une profondeur supplémentaire aux thèmes explorés par la fiction.
Comme souvent, la science-fiction agit ici comme un miroir. Elle déplace les questions dans une galaxie imaginaire pour mieux éclairer celles qui traversent notre propre société.
Les terres rares, le cobalt ou le gallium ne bénéficient pas de l’aura mythique du beskar. Leurs noms sont moins évocateurs et leurs propriétés moins spectaculaires. Pourtant, ils jouent un rôle tout aussi déterminant dans les transformations technologiques, énergétiques et géopolitiques du XXIᵉ siècle.
La fiction n’invente donc pas tant qu’elle ne révèle. En imaginant un métal rare dont le contrôle influence le destin d’une galaxie entière, Star Wars nous invite à porter un regard nouveau sur les ressources dont dépend notre propre avenir.
Ignorer cette réalité, c’est avancer dans la galaxie sans armure : vulnérable, exposé, dépendant des autres.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.