
12.07.2026 à 11:35
Peut-on cartographier l'Odyssée ? Comment géographes antiques et chercheurs d'aujourd'hui ont retracé le voyage d'Ulysse
Texte intégral (2333 mots)
L'Odyssée, le très attendu film de Christopher Nolan, sort en salles le 15 juillet. L'occasion de revenir sur une question qui fascine historiens et archéologues depuis des siècles : les lieux traversés par Ulysse ont-ils réellement existé ?
L’Odyssée d’Homère est une quête, celle du roi Ulysse, qui met dix ans à regagner son royaume d’Ithaque après la guerre de Troie. C’est un récit aux dimensions géographiques, spatiales et temporelles très marquées. Il n’est donc pas surprenant que, depuis des siècles, les lieux évoqués dans ce récit fascinent les lecteurs, qui se demandent combien d’entre eux ont réellement existé.
Quelques historiens et spécialistes de l’Antiquité estiment toutefois que l’Odyssée n’est qu’une œuvre poétique. Selon eux, en tant que création littéraire et récit mythologique, il est vain de chercher à situer ces lieux sur une carte.
Le savant grec de l’Antiquité Ératosthène, premier à avoir mesuré la circonférence de la Terre, contestait tout lien entre l’Odyssée et la géographie. Il affirmait : « Vous trouverez le théâtre des errances d’Ulysse lorsque vous aurez trouvé le cordonnier qui a cousu le sac des vents. »
J’étudie l’histoire de la cartographie et des représentations mentales de l’espace depuis plus de vingt ans. À mes yeux, ce sont précisément les dimensions géographiques du récit qui lui donnent tout son ancrage. Le désir d’Ulysse de retrouver le chemin de son foyer est au cœur même du poème. Et c’est au fil de sa traversée de ces différents lieux et espaces que le héros se transforme.
Cartographier le mythe
L'historien grec de l'Antiquité Polybe, qui vécut environ six siècles après Homère, estimait que l’Odyssée relatait un récit réel agrémenté de quelques éléments mythologiques, et non l’inverse. Il soulignait par exemple que certaines techniques de pêche décrites près de Scylla étaient semblables à celles pratiquées autour de la Sicile. Selon lui, Scylla devait donc se trouver au large des côtes siciliennes.
Strabon était un philosophe et géographe grec qui écrivait près de sept siècles après Homère. Sa Géographie, vaste œuvre en 17 livres, constitue à la fois un atlas et une encyclopédie du monde grec à l'époque de l'empereur Auguste. On y trouve également le récit d'îles peuplées uniquement d'hommes ou de femmes dans l'océan Indien, un motif qui rappelle ceux décrits par Homère dans l’Odyssée :
« Dans l'océan se trouve une petite île, située non loin du large, en face de l'embouchure du fleuve Liger ; elle est habitée par des femmes du peuple des Samnites, possédées par Dionysos, qu'elles cherchent à rendre favorable en l'apaisant par leurs rites. »
Les légendes et les mythes de l'époque regorgent de récits de femmes séduisant les hommes pour les entraîner à leur perte. C'est le cas de Circé, que Homère décrit comme « une redoutable déesse aux beaux cheveux ». Elle vit seule sur l'île d'Aiaié, entourée de loups et de lions apprivoisés, et attire Ulysse et ses compagnons dans son domaine pour les transformer en porcs.
Homère évoque également Calypso, qui retient Ulysse sur son île d'Ogygie pendant sept ans dans ce que certains traduisent comme une « captivité sexuelle ». D'autres traductions suggèrent toutefois qu'Ulysse y demeure de son plein gré, jusqu'au moment où il décide qu'il est temps de repartir.
Sur les cartes et les globes de l'Antiquité, le monde réel et les mythes se superposent et s'entremêlent. Le mathématicien et astronome romain Ptolémée, qui a cartographié le monde connu au IIᵉ siècle après J.-C., fait figurer sur ses cartes plusieurs lieux issus de l'univers homérique, comme la Lotophagitis (le pays des Lotophages), le Circaeum Promontorium (Aiaié, le royaume de Circé) ou encore les Sirenusae Insulae (les îles des Sirènes).

{kind=link}
Les tentatives visant à reporter précisément ces lieux sur des cartes modernes se sont révélées difficiles. Les calculs de latitude et de longitude de Ptolémée reposaient sur une projection très différente de la nôtre ainsi que sur une estimation erronée de la circonférence de la Terre. Une correspondance approximative entre ces lieux et les cartes actuelles laisse penser que la Lotophagitis se situerait en Afrique.
À la fin du XVIᵉ siècle, le cartographe néerlandais Abraham Ortelius fut le premier à représenter l'intégralité du voyage d'Ulysse dans son Theatrum Orbis Terrarum. Cette carte, intitulée Map of the Wanderings of Ulysses (« Carte des errances d'Ulysse »), utilise le nom latin Ulysses et non le grec Odysseus pour désigner le héros.
Ortelius représente à la fois les mondes mythique et fictif d'Ulysse comme s'il s'agissait de réalités scientifiques, et affirme qu'Ithaque correspond à l'actuelle Corfou. Homère situait l'île de Calypso au large de Schérie, un havre mythique constituant la dernière étape du voyage d'Ulysse avant son retour à Ithaque.
Or, aucune île ne se trouve à l'ouest de Corfou. Ortelius en a donc inventé une sur sa carte. Cette île fictive est ensuite devenue une référence pour les cartographes, au point de continuer à figurer sur les cartes jusque dans les XIXᵉ et XXᵉ siècles.

{kind=link}
En 1912, le politicien et voyageur français Victor Bérard entreprit de reconstituer l'itinéraire d'Ulysse en parcourant lui-même la Méditerranée. Il situait l'île de Calypso près de Gibraltar, le pays des Lotophages sur l'île de Djerba, au large du sud de la Tunisie, et le pays des Cyclopes à Posillipo, près de Naples.
Selon la théorie de Bérard, l’Odyssée d'Homère aurait été influencée par les voyages et les cartes des Phéniciens, notamment par leurs instructions de navigation côtière, qui s'appuyaient sur les étoiles pour s'orienter. Mais nombre de ces « cartes » relevaient davantage de l'imaginaire et de la tradition orale que d'objets cartographiques réels.
À la recherche d'Ithaque
L'un des grands débats autour de la géographie de l’Odyssée consiste à déterminer où se trouvait réellement Ithaque. Pendant longtemps, les spécialistes ont soutenu qu'il s'agissait de l'actuelle île d'Ithaki, dans la mer Ionienne. Le problème est qu'Ithaki est une île montagneuse, alors que l'Ithaque décrite par Homère est « basse ».
Des chercheurs des universités de Cambridge et d'Aberdeen ont récemment avancé qu'Homère ne décrit en réalité jamais Ithaque comme une île. Selon eux, il la présente plutôt comme une terre ou un territoire appartenant à une île plus vaste.
Cette interprétation ferait de Paliki, située sur la côte ouest de Céphalonie, une candidate plus crédible. Des études géoscientifiques et des fouilles archéologiques ont en effet montré que Paliki constituait un important site de l'âge du bronze, ce qui renforce l'hypothèse qu'elle puisse correspondre à l'Ithaque d'Homère.
Les étapes du voyage d'Ulysse correspondent peut-être à des lieux bien réels, ou relèvent peut-être entièrement du mythe. Dans les deux cas, les liens qu'elles entretiennent les unes avec les autres racontent une même histoire : celle du désir profond de retrouver son foyer et de la quête d'appartenance. Ils éclairent aussi la manière dont les Anciens percevaient le monde, comme un espace peuplé de mystères et de dangers.
La géographie de l’Odyssée offre ainsi une clé de lecture des vulnérabilités et des peurs des hommes de la Grèce antique. Les cartes retraçant le voyage d'Ulysse ne sont peut-être pas fidèles à la réalité, mais après tout, aucune carte ne l'est totalement. Les cartes ne sont au fond que des récits que nous nous racontons : des voyages vers l'inconnu, bien au-delà des frontières de notre imagination. Dans l’Odyssée, Homère ne se contente pas de cartographier le monde ; il en crée un.
Pragya Agarwal ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.07.2026 à 10:39
Opération de la cataracte, prothèse de hanche… quand les dépassements d’honoraires des médecins se généralisent pour des actes fréquents
Texte intégral (2933 mots)
L’essentiel
- Les dépassements d’honoraires des médecins spécialistes se généralisent, voire deviennent majoritaires pour certains soins et dans certains territoires.
- Des études récentes de l’Institut de recherche et documentation en économie de la santé (Irdes) montrent que certains actes sont particulièrement concernés, comme l’opération de la cataracte, la reconstruction du ligament croisé, la « sleeve gastrectomy » ou encore la pose de prothèse de hanche.
- Ce constat pose question quant à l’accès aux soins pour tous, notamment pour les ménages dont les ressources se situent juste au-dessus des seuils pour bénéficier des dispositifs de prise en charge destinés aux foyers les plus modestes.
Les dépassements d’honoraires sont devenus une réalité pour un nombre croissant de Français. Ce terme un peu technique renvoie au supplément de prix facturé par certains médecins libéraux au-delà du tarif conventionnel de la Sécurité sociale – et donc souvent à la charge du patient. Car la règle est simple : la Sécurité sociale ne rembourse pas ces dépassements.
Ils restent donc à la charge des patients… sauf si leur complémentaire santé (souvent appelée « mutuelle », même quand elle ne relève pas du Code de la mutualité) prend le relais. Or, ce relais est fortement inégal et souvent incomplet, quand il n’est pas inexistant : au total, seuls 40 % de ces frais sont effectivement pris en charge par les complémentaires santé en moyenne.
Une part importante des dépenses reste donc directement supportée par les ménages. À travers cette réalité, c’est l’accessibilité financière aux soins qui se trouve directement interrogée.
Un phénomène qui ne date pas d’hier
Ce constat n’est pas récent. Au début des années 1980, lors de la négociation d’un nouvel accord entre l’Assurance-maladie et les médecins, ces derniers demandent une hausse de leurs tarifs. Mais cette requête se heurte aux difficultés financières de l’Assurance-maladie.
Pour faire face à cette situation, le gouvernement décide de créer deux secteurs conventionnels :
dans le secteur 1, les médecins s’engagent à respecter les tarifs fixés par l’Assurance-maladie…
dans le secteur 2, les médecins peuvent fixer des tarifs plus élevés en demandant des compléments d’honoraires aux patients.
Dans les années 1990, la forte augmentation des médecins optant pour le secteur 2 fait craindre un basculement massif vers ce mode d’exercice. Pour freiner ce mouvement, l’accès au secteur 2 est restreint aux seuls médecins disposant de certains titres hospitaliers – notamment anciens chefs de clinique et assistants des hôpitaux. Ces parcours étant propres aux médecins spécialistes, les médecins généralistes ont, de fait, été exclus en pratique du dispositif. Ceux qui exercent encore aujourd’hui en secteur 2 y ont donc accédé avant ce « gel », ce qui explique leur très faible proportion.
Dans les années 2010, dans un contexte d’augmentation préoccupante des niveaux de dépassements, la régulation s’oriente vers des mécanismes d’incitation à la modération des dépassements : d’abord le contrat d’accès aux soins (CAS) en 2012, remplacé en 2016 par l’option de pratique tarifaire maîtrisée (Optam). Les médecins qui y souscrivent s’engagent pour trois ans à ne pas augmenter leurs tarifs, à stabiliser leur taux de dépassement d’honoraires et la part des actes qu’ils réalisent sans dépassement.
Dans les faits, ces mécanismes de régulation des tarifs et les modalités de prise en charge des dépassements d’honoraires par les complémentaires santé sont complexes. S’y ajoute bien souvent un manque de visibilité pour le patient sur le niveau du dépassement qui va lui être appliqué. Dans ces conditions, difficile pour lui d’estimer le montant qui va rester à sa charge.
Aujourd’hui, des pratiques largement répandues chez les médecins
En 2024, selon le Haut Conseil pour l’avenir de l’Assurance-maladie (Hcaam), 56 % des spécialistes libéraux (qui consultent en médecine libérale) exercent en secteur 2, contre 37 % en 2000. Sur les vingt dernières années, la proportion de médecins libéraux en secteur 2 a fortement progressé dans l’ensemble des spécialités.
Elle atteint, par exemple, 86 % chez les chirurgiens et 72 % chez les ophtalmologues. Chez les dermatologues, la proportion est d’environ 50 %. Au contraire, pour certaines spécialités comme la cardiologie ou la radiologie, elle est plus proche d’un tiers (31 % en cardiologie, 35 % en radiologie en 2024).
En 2024, le taux moyen de dépassement des médecins de secteur 2 s’élève à 50 %. Cela signifie que, en moyenne, un acte dont le tarif de l’assurance-maladie est de 100 euros est facturé 150 euros (toutefois, en se limitant uniquement aux actes qui ont fait l’objet d’un dépassement, ce montant s’élève en réalité à 189 euros.
Mais ce taux moyen de 50 % varie largement selon les spécialités et selon les praticiens : par exemple, il était, en 2024, de 60 % chez les chirurgiens, mais de 20 % environ chez les cardiologues ou les pneumologues.
À lire aussi : Médecins spécialistes et déserts médicaux : leur présence sur un territoire ne suffit pas à garantir l’accès aux soins
Même à l’intérieur d’une même spécialité, les pratiques de dépassements d’honoraires sont très variables d’un praticien à l’autre et peuvent atteindre des niveaux élevés : ainsi, chez les chirurgiens libéraux de secteur 2 par exemple, le taux de dépassement excédait 184 % pour les 10 % de chirurgiens ayant les plus forts dépassements, en 2023.
Exemples à l’appui : des dépassements loin d’être marginaux pour les patients
L’Institut de recherche et documentation en économie de la santé (Irdes) a réalisé plusieurs études afin d’alimenter les travaux du Haut Conseil pour l’avenir de l’Assurance-maladie (Hcaam). Certaines visent à objectiver la fréquence et les montants que les dépassements d’honoraires représentent concrètement pour les patients dans l’accès à certaines spécialités, certains actes ou épisodes de soins et selon les territoires.
L’Irdes a ainsi analysé les tarifs pratiqués pour une sélection de 14 actes techniques fréquents, à partir des données du Système national des données de santé (SNDS). Les résultats montrent que, pour certains actes, la proportion de patients s’étant vu facturer un dépassement est élevée.
Par exemple, en 2021, sept reconstructions du ligament croisé antérieur du genou par autogreffe sur dix ont donné lieu à un dépassement d’un montant de 535 euros en moyenne.
Pour la gastrectomie longitudinale (sleeve gastrectomy) pour obésité morbide par coelioscopie, 58 % des patients ont dû acquitter un dépassement d’honoraires d’un montant de 880 euros en moyenne, mais supérieur à 1 500 euros dans 10 % des cas.
Mais un acte de soins est rarement isolé : à une intervention chirurgicale sont le plus souvent associés une consultation et un acte d’anesthésie, des actes d’imagerie pré et/ou postopératoire… Dans ce cas, les dépassements d’honoraires peuvent relever de différents médecins et se cumuler tout le long de l’épisode de soins.
Dans une deuxième étude, l’Irdes a analysé ces phénomènes de cumul pour quatre épisodes de soins fréquents, liés à quatre actes hospitaliers : l’accouchement, la chirurgie du cristallin, la prothèse totale de hanche et la coloscopie.
En 2021, un peu plus d’une patiente sur deux ayant eu un accouchement par voie basse sans complication a été exposée à des dépassements au cours de son épisode de soins, pour un montant de 300 euros en moyenne.
Mais pour une prothèse de hanche, 79 % des patients (soit près de huit sur dix) ont été exposés à des dépassements, pour un montant de 700 euros en moyenne, la facture dépassant les 1 400 euros dans 10 % des cas.
Ainsi, pour bon nombre de soins ou épisodes de soins, avoir à régler un dépassement est aujourd’hui devenu la situation la plus courante pour le patient.
Quasiment pas de dépassements en cardiologie de ville ou pour un accouchement par voie basse
Pour certains soins, l’offre dite à tarif opposable (notamment celle assurée par les hôpitaux publics ou les médecins libéraux de secteur 1) demeure majoritaire et globalement accessible dans la plupart des territoires.
C’est, par exemple, le cas des actes d’accouchements par voie naturelle qui, dans 59 départements, ne donnent quasiment jamais lieu (dans plus de 95 % des cas) à un dépassement d’honoraires de la part du gynécologue-obstétricien qui l’a réalisé.
Il en va de même pour les cardiologues de ville qui exercent aux trois quarts en secteur 1, ce qui permet aux patients d’accéder à une offre sans dépassement dans la plupart des territoires, sauf dans certains départements ou régions très urbanisés, comme l’Île-de-France ou la Gironde.
Niveaux d’accessibilité (APL) aux cardiologues selon le périmètre de l’offre
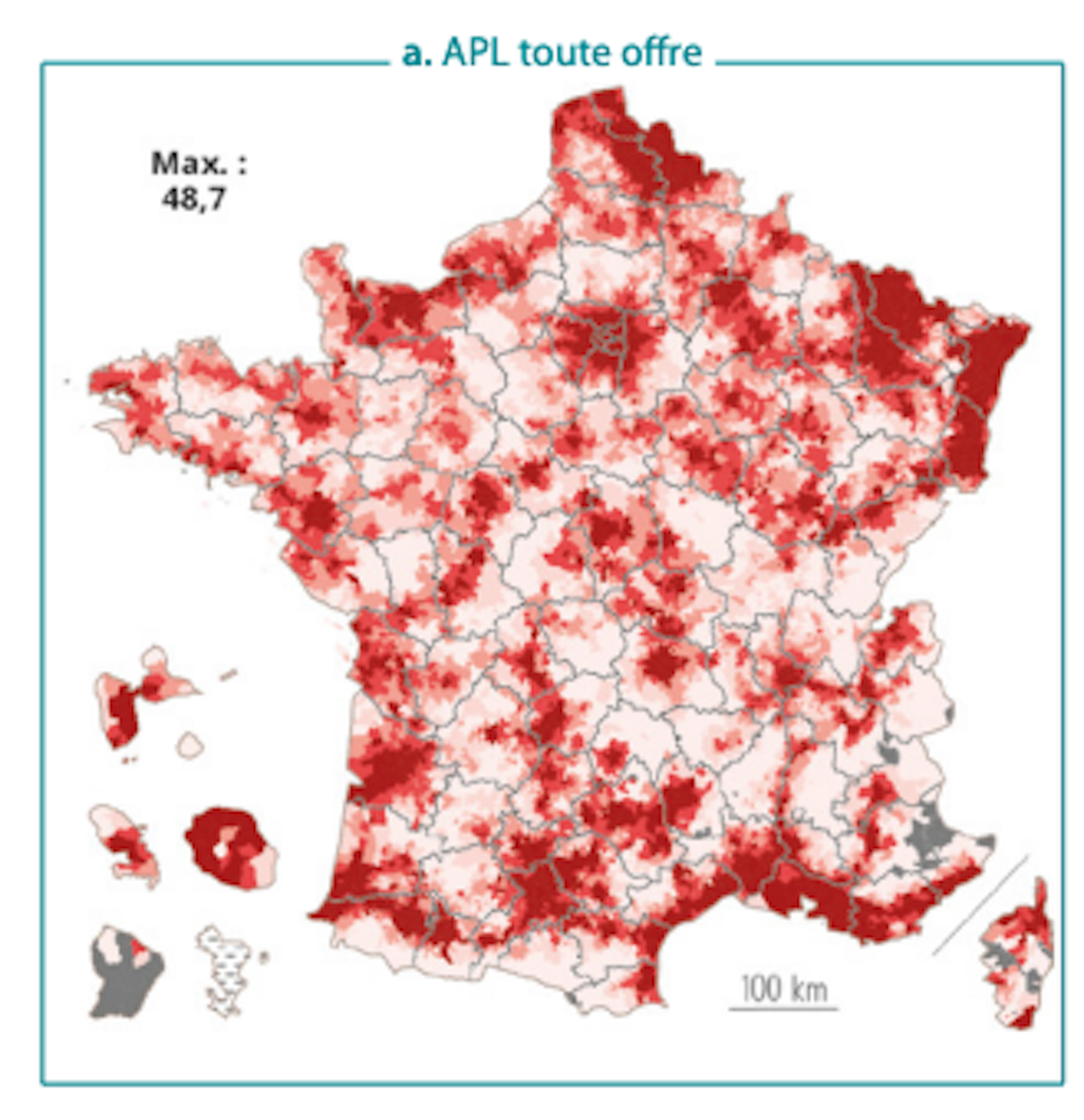
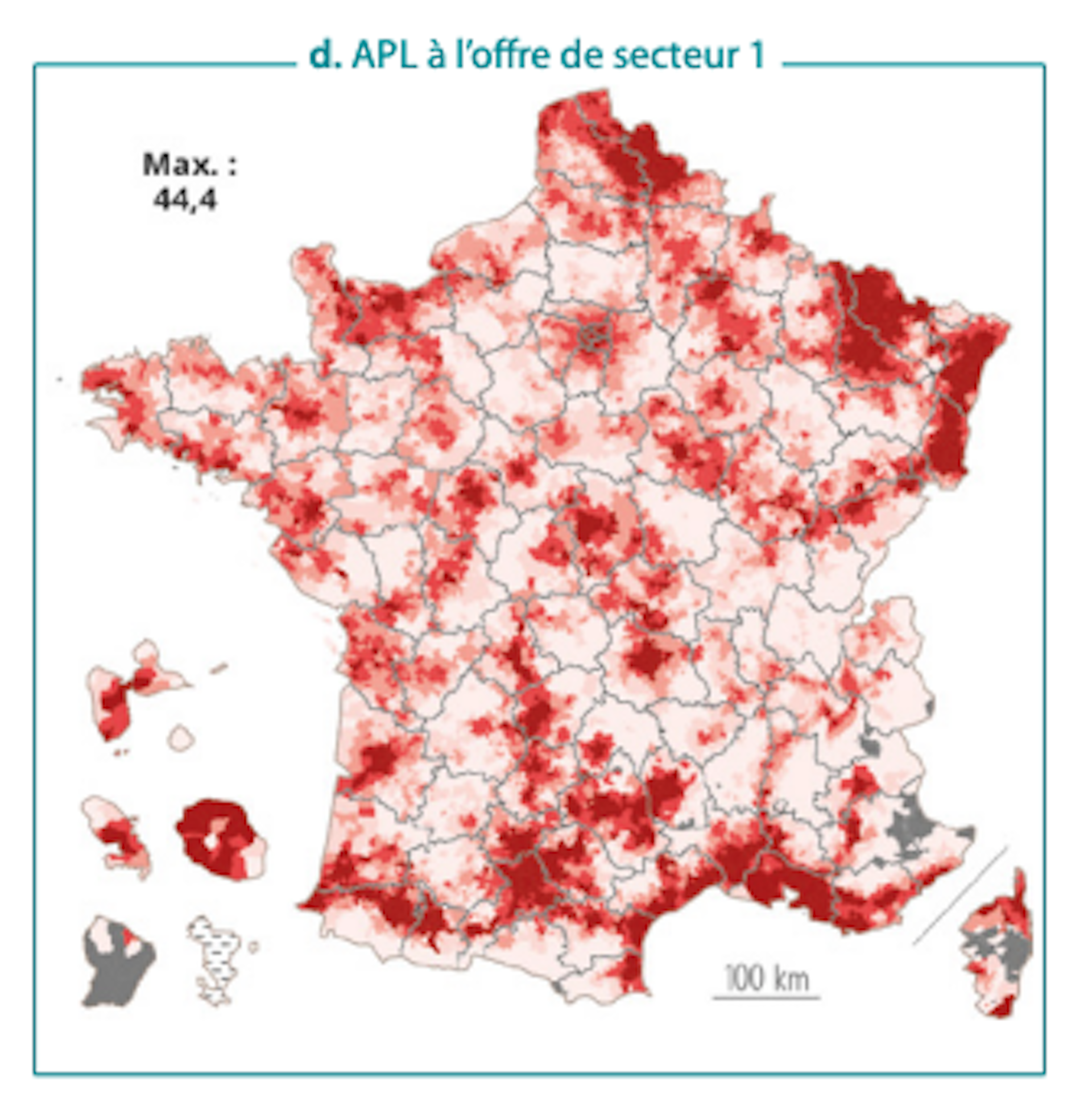
Ces territoires où l’offre de soins sans dépassement a disparu
À l’inverse, pour d’autres soins, le secteur 2 s’est fortement diffusé. Dans la plupart des territoires, l’accessibilité géographique repose alors largement sur ces praticiens, rendant parfois les dépassements difficiles à éviter.
C’est notamment le cas en ophtalmologie et en dermatologie de ville.
Niveaux d’accessibilité (APL) aux ophtalmologistes selon le périmètre de l’offre
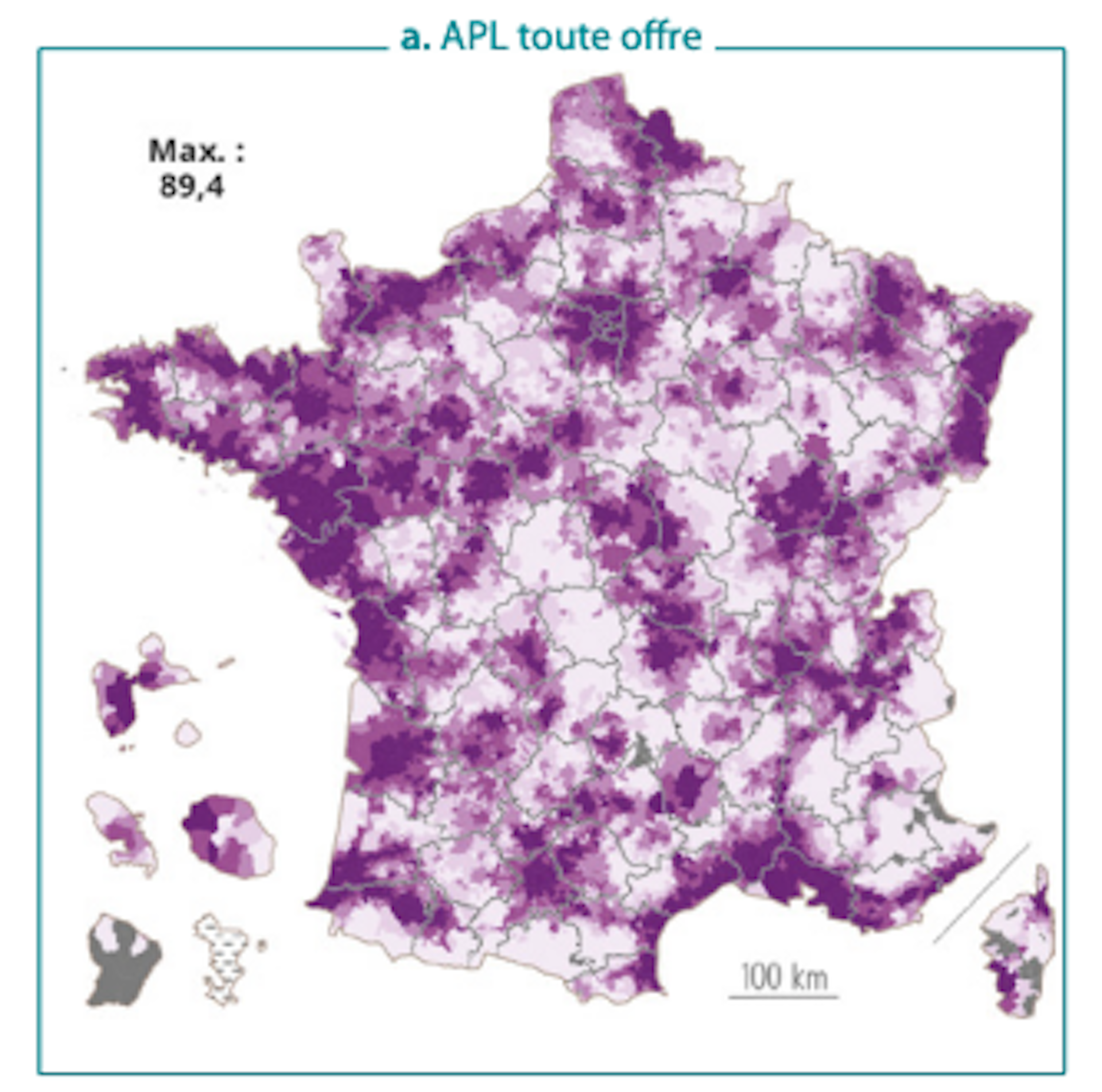
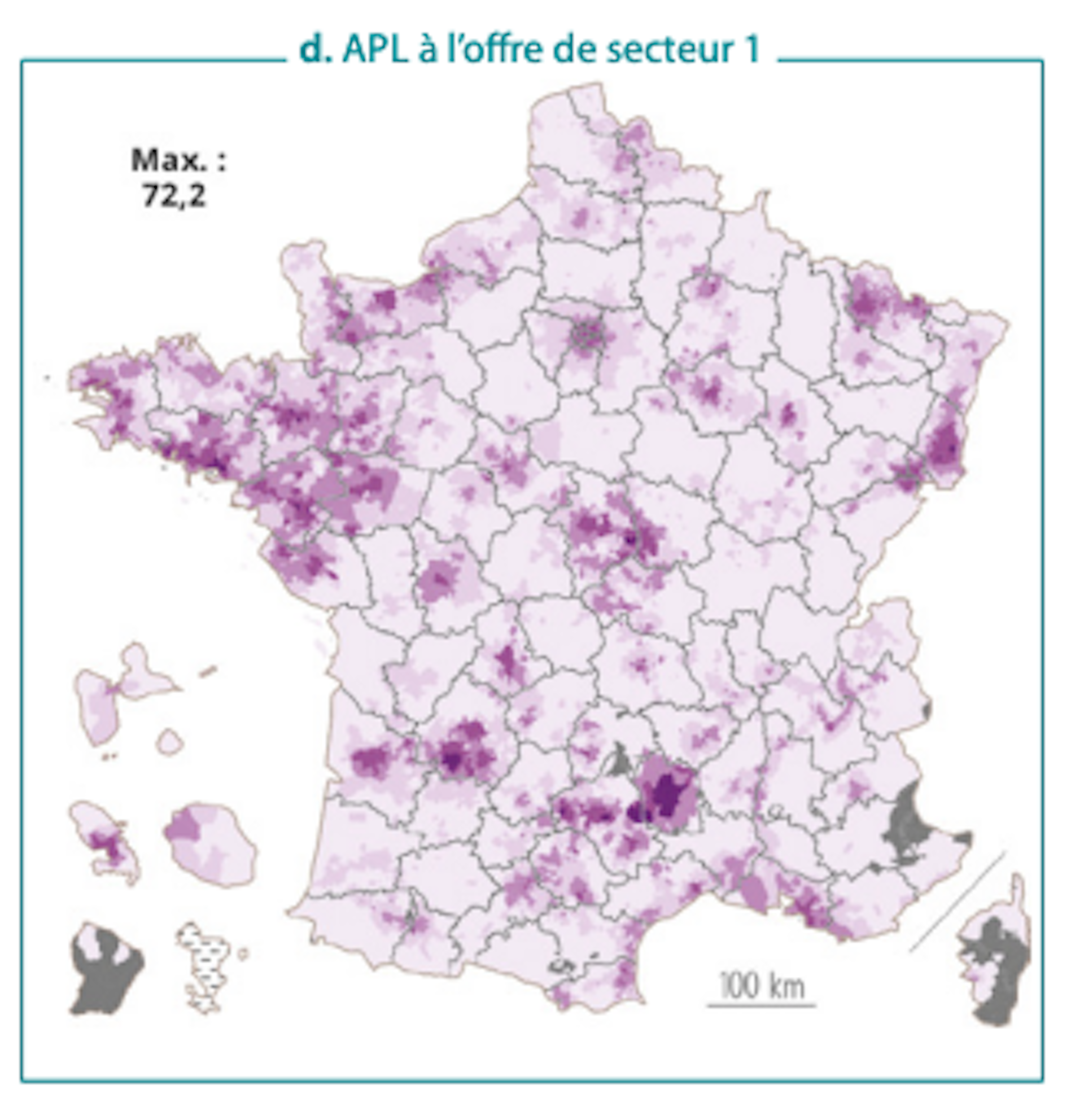
On observe également ce phénomène pour la sleeve gastrectomy : dans 61 départements, plus d’un acte sur deux donne lieu à un dépassement et, dans 16 départements, plus de trois sur quatre.
Or, le profil des patients qui acquittent ces dépassements dépend directement de l’accessibilité à une offre sans dépassement, laquelle varie fortement selon les soins. Les travaux de l’Irdes montrent ainsi que lorsque l’offre à tarif opposable (hôpitaux publics, établissements privés à but non lucratif et libéraux de secteur 1) est majoritaire et bien répartie sur le territoire – comme pour les accouchements – les dépassements concernent principalement les patients issus des communes les plus favorisées.
À l’inverse, lorsque le secteur 2 est prédominant, comme pour la reconstruction du ligament croisé, les dépassements tendent à se répartir entre tous les profils de patients, y compris ceux des communes les plus défavorisées.
L’accès universel aux soins est-il menacé ?
Loin de constituer des situations marginales, ces configurations tendent à devenir la norme dans un nombre croissant de territoires et de spécialités. À mesure que l’offre à tarif opposable recule, l’accès à des soins sans dépassement cesse d’être garanti et dépend du lieu de résidence, du type de soins, et in fine des ressources des patients.
Cette question ne se pose pas, en droit, pour les assurés les plus précaires : près de 8 millions de personnes bénéficient aujourd’hui de la complémentaire santé solidaire (C2S), un dispositif destiné aux personnes à faibles ressources, pour lesquelles la facturation de dépassements d’honoraires est interdite par la loi.
En revanche, pour l’ensemble des autres assurés, aucune protection équivalente n’existe. Dans les territoires et spécialités où l’offre à tarif opposable (sans dépassement) s’est amenuisée, les dépassements deviennent de fait difficilement évitables, y compris pour des patients aux ressources modestes mais situées au‑dessus des seuils d’éligibilité à la complémentaire santé solidaire.
Au rythme actuel des installations en secteur 2 (qui autorise les dépassements d’honoraires), la dynamique apparaît difficilement soutenable. À l’horizon 2040, le secteur 2 pourrait représenter près de 89 % des médecins spécialistes exerçant en libéral, tandis que le montant total des dépassements d’honoraires dépasserait 10 milliards d’euros, contre 4,7 milliards en 2025.
Une telle trajectoire pose de manière aiguë la question de l’accès équitable aux soins, comme l’illustrent les travaux récents du Haut Conseil pour l’avenir de l’Assurance-maladie, qui explorent plusieurs scénarios de réforme des dépassements d’honoraires des médecins.
La question devient centrale : le système de santé français restera-t-il fondé sur un accès universel aux soins, indépendant des ressources des patients et de leur lieu de résidence, ou évoluera-t-il vers un modèle où le niveau de couverture par la complémentaire santé et la capacité à payer conditionneront de plus en plus l’accès effectif aux médecins spécialistes ?
Ces travaux ont bénéficié du soutien financier du Haut conseil pour l’avenir de l’assurance maladie (Hcaam).
12.07.2026 à 10:39
Quand la Légion d’honneur fait monter les cours de Bourse : les décorations d’État, signaux de proximité politique ?
Texte intégral (2138 mots)
Instituée en 1802, la Légion d’honneur est la plus haute distinction nationale décernée à des citoyens français ou à des personnes étrangères pour leurs mérites au service de la nation, à titre civil ou sous les armes. Symbolique, serait-elle dénuée de toute valeur économique ? Une étude montre que, au contraire, son attribution peut agir comme un signal positif sur les marchés financiers. Explications à l’occasion de la promotion du 14-Juillet.
De la Légion d’honneur française à la Presidential Medal of Freedom américaine et à l’Ordre de la République chinois, les décorations civiles d’État existent dans plus de neuf pays sur dix. Sans récompense matérielle directe, elles sont souvent perçues essentiellement comme une reconnaissance symbolique, des « hochets avec lesquels on mène les hommes », selon une formule attribuée à Napoléon Bonaparte. Sont-elles pour autant dénuées de valeur économique ?
Nous avons étudié la réaction des marchés lorsqu’un administrateur d’entreprise cotée reçoit la Légion d’honneur (Journal of Law, Economics, and Organization, à paraître). La valeur boursière de son entreprise augmente alors significativement.
Cette réaction financière est concentrée sur les administrateurs pour lesquels la distinction semble révéler une proximité politique auparavant invisible aux investisseurs. Une décoration d’État peut ainsi agir comme le signal public d’un accès privilégié aux décideurs publics.
Une distinction prestigieuse mais discrétionnaire
Créée en 1802 par Napoléon Bonaparte, la Légion d’honneur demeure très prestigieuse. Elle est attribuée chaque année à plusieurs centaines de civils, issus de la fonction publique, du monde associatif, des arts, de la recherche ou des entreprises. Les personnes proposées doivent justifier de « mérites éminents », mais sans critère précis et directement observable. Les ministres constituent et transmettent des dossiers de proposition de décoration.
Après instruction et examen, les nominations et promotions sont officialisées par décret signé par le président de la République. Le processus comporte ainsi une dimension largement discrétionnaire.
Pour en mesurer la valeur économique, nous avons relié l’ensemble des décorations civiles attribuées entre 1995 et 2019 aux membres des conseils d’administration d’entreprises françaises cotées. Notre base ainsi constituée rassemble 1 240 décorations reçues par 1 074 administrateurs alors qu’ils siégeaient dans ces entreprises. À partir d’un corpus de vingt-cinq ans d’articles de presse tirés des cinq principaux quotidiens nationaux, nous montrons que les noms des récipiendaires ne sont pas publics avant la publication des décrets. Ceux-ci apportent donc aux investisseurs une information publique nouvelle.
Un « hochet » à 7 millions d’euros
Nous comparons, autour du décret, le rendement de chaque titre à celui attendu d’après l’évolution du marché. L’écart entre les deux, appelé « rendement anormal », mesure la réaction propre à l’annonce. Cette réaction est positive : en moyenne, le cours des entreprises concernées enregistre une surperformance de 0,21 % dans les deux jours suivant l’annonce, puis de 0,43 % après cinq jours, sans que cette surperformance ne soit ensuite effacée. Si ces chiffres peuvent sembler modestes, pour l’entreprise médiane de notre échantillon, dont la capitalisation boursière s’élève à environ 3,5 milliards d’euros, cela représente, deux jours après l’annonce, 7 millions d’euros de valeur supplémentaire (euros constants de 2000).
Cet effet reste inférieur à ceux mis en évidence pour d’autres formes de connexions politiques des dirigeants d’entreprise : les liens avec un président nouvellement élu, observés en France lors de l’élection de Nicolas Sarkozy, ou les passages entre les sphères des affaires et de la politique (« pantouflage »), étudiés dans 47 pays.
Mais les décorations d’État sont bien plus fréquentes et sont peu coûteuses à attribuer : leur portée est ainsi substantielle. Selon l’hypothèse d’efficience des marchés, une telle réaction traduit une information nouvelle et jugée pertinente par les investisseurs. Mais elle ne dit pas, à elle seule, ce qu’ils apprennent.
Les décorations d’État comme un signal de connexions politiques
Une première explication est celle du mérite : la reconnaissance publique pourrait conduire les investisseurs à réviser leur jugement sur les compétences, la réputation ou l’effort futur d’un administrateur. Une seconde est celle de la proximité politique. L’accès aux décideurs est précieux pour les entreprises, notamment celles pour lesquelles la réglementation, les licences, les subventions ou les marchés publics jouent un rôle déterminant dans les perspectives économiques. La dimension discrétionnaire de la Légion d’honneur ouvre la voie à cette seconde interprétation.
Pour les départager, nous exploitons une caractéristique des élites françaises : une part importante des responsables économiques et politiques est issue d’un nombre restreint de grandes écoles. Leurs promotions, de taille réduite, favorisent des réseaux d’anciens élèves identifiables et durables. Ainsi, nous avons apparié les dirigeants d’entreprises et les membres des gouvernements successifs à des registres historiques d’anciens élèves d’une quinzaine de grandes écoles.
À lire aussi : Grandes écoles : 80 fois plus de chances d’admission quand on est enfant d’ancien diplômé
Un administrateur est considéré comme ayant, avant sa décoration, un lien identifiable avec le gouvernement lorsqu’il a fréquenté le même établissement, dans la même promotion (ou dans la promotion voisine) qu’un membre du gouvernement impliqué dans le processus d’attribution. Cette mesure saisit une proximité institutionnelle qu’un investisseur peut plausiblement identifier à partir des biographies publiques ou des interactions qu’elle a pu engendrer.

{kind=link}
Lorsqu’un tel lien est déjà identifiable, la décoration devrait apporter peu d’information supplémentaire et générer peu ou pas de réaction boursière. Dans le cas contraire, les investisseurs peuvent y voir la révélation d’un accès aux décideurs publics jusque-là inobservable. C’est précisément ce que montrent nos résultats. Aucune réaction boursière n’est observée lorsqu’un administrateur décoré apparaît déjà connecté à un responsable politique impliqué dans le processus d’attribution. À l’inverse, la réaction est positive et significative lorsque l’on n’observe pas de lien préalable. La Légion d’honneur semble alors révéler des liens nouveaux, ou jusque-là inconnus, avec les décideurs publics.
D’autres résultats vont dans le même sens. Les réactions boursières sont plus fortes lorsque la décoration est attribuée tôt dans le cycle politique, tandis qu’on ne mesure plus de réaction en fin de mandat. Ce calendrier semble indiquer que les investisseurs valorisent la durée anticipée de l’accès politique que la distinction peut révéler. Elles sont aussi plus marquées pour les entreprises les plus exposées aux décisions de l’État (commandes publiques, réglementation ou présence de l’État au capital).
Enfin, elles ne se propagent pas aux autres entreprises du même secteur : les investisseurs y voient une information propre à l’entreprise, et non l’annonce d’un changement plus général de politique publique.
Que nous disent les décorations d’État ?
Nos résultats ne montrent pas que certaines décorations auraient été attribuées de manière indue ni que des récipiendaires auraient bénéficié d’un traitement préférentiel. Ils mettent plutôt en évidence un mécanisme souvent négligé dans les interactions entre les États et les marchés : en distribuant du prestige public, un État peut aussi diffuser une information ayant une valeur économique, notamment sur l’accès potentiel aux décideurs publics.
Cette conclusion dépasse le seul cas français, puisque les systèmes de décorations civiles existent dans la plupart des pays et types de régimes politiques. Ces distinctions peuvent légitimement récompenser le service rendu, entretenir des normes civiques et reconnaître des contributions que les marchés valorisent imparfaitement. Il ne s’ensuit donc pas nécessairement qu’il faudrait en attribuer moins.
Mais lorsque leur attribution implique des procédures discrétionnaires et des acteurs politiques, elles peuvent aussi modifier les anticipations sur l’influence future de leurs récipiendaires.
Des critères plus explicites, un examen indépendant des dossiers et une plus grande transparence sur les voies institutionnelles de nomination pourraient réduire le risque qu’elles soient d’abord interprétées comme des signaux de proximité politique. De telles évolutions auraient toutefois un coût : elles réduiraient la souplesse qui peut favoriser la reconnaissance de formes diverses de mérite et, surtout, qui contribue à préserver les fonctions symboliques et d’influence des distinctions d’État.
Le projet ayant conduit à cette publication a bénéficié d’un financement de l’État français dans le cadre du plan d’investissement « France 2030 », géré par l’Agence nationale de la recherche (référence : ANR-17-EURE-0020), de l’Initiative d’excellence de l’université d’Aix-Marseille — A*MIDEX, du Fonds Wetenschappelijk Onderzoek—Vlaanderen (FWO) et du Fonds de la recherche scientifique — FNRS, dans le cadre du projet EOS O020918F (EOS ID 30784531).
Le projet ayant conduit à cette publication a bénéficié d’un financement de l’État français dans le cadre du plan d’investissement « France 2030 », géré par l’Agence nationale de la recherche (référence : ANR-17-EURE-0020), de l’Initiative d’excellence de l’université d’Aix-Marseille — A*MIDEX, du Fonds Wetenschappelijk Onderzoek—Vlaanderen (FWO) et du Fonds de la recherche scientifique — FNRS, dans le cadre du projet EOS O020918F (EOS ID 30784531).