
ACCÈS LIBRE
23.09.2025 à 09:00
Sarah qui ? Ça raccroche !
Frédéric Urbain
Texte intégral (1615 mots)
Marre des appels indésirables ? Un développeur français vous propose de bloquer plus de 16 millions de numéros sur iOS et Android.
Salut Camille !
Peux-tu nous dire qui tu es ?
Je m’appelle Camille Bouvat, je suis développeur depuis bientôt 18 ans et freelance depuis 13 ans, spécialisé dans le PHP avec Laravel. Je travaille avec différents types de clients, petites et grandes entreprises. J’aime diversifier mes compétences avec de l’administration système, de l’UX/UI, de l’accessibilité et aussi dernièrement du développement mobile natif. J’ai eu beaucoup d’expériences différentes que ce soit en entreprise, en tant qu’indépendant et entrepreneur ou même en tant que formateur.
Pour bloquer les appels indésirables, nous avons l’habitude de recommander Yet Another Spam Blocker (voir sur Framalibre ou chez Grisebouille), qui est sous licence AGPL et plutôt efficace. Pourquoi avoir créé une autre application de ton côté ?
Étant utilisateur iOS, cette application n’est pas disponible sur cette plateforme et je ne connaissais pas cette application. J’ai cherché simplement sur l’App Store et j’ai trouvé quelques applications que j’ai testées et utilisées. Mais souvent soit elle était payante, soit gratuite mais avec une liste de blocage assez limité ou encore une interface pas très intuitive.
Donc un dimanche après-midi, je me suis dit « tiens, code un prototype pour bloquer les appels », vers 20h j’avais le prototype fonctionnel. Après quelques peaufinements, je publie l’application sur l’App Store le lundi suivant. Puis, j’ai voulu pousser le bouchon plus loin en allant chercher des informations dans les données open-data de l’ARCEP, pour commencer à bloquer tous les préfixes des opérateurs sources de SPAM. La majorité des applications ne bloque que 12,5 millions de numéros qui correspondent aux numéros dédié au démarchage.
Actuellement, Saracroche bloque plus de 16 millions de numéros et et la liste va encore grossir au fur et à mesure des signalements faits dans l’application.
Copie d’écran de la version Android
Je voulais aussi une application qui respecte au maximum la vie privée, en demandant le minimum de permissions, et qui limite au maximum les échanges avec un serveur.
T’as l’air d’un bon gars sur ta photo de profil, qu’est-ce qui t’a pris de t’agacer comme ça ?
Merci ☺️, mais comme tout le monde, je reçois des appels indésirables à titre personnel et encore plus quand on est indépendant. Donc je me suis lancé dans ce projet et c’était un défi pour moi, étant développeur web et pas mobile. J’ai voulu faire du natif avec Swift et Swift UI, pour faire une application légère et performante.
Au départ, je ne voulais faire l’application que pour iPhone mais j’ai reçu beaucoup de demandes pour la porter sur Android, ce que j’ai finit par faire au début du mois d’août. Cela m’a pris un peu plus de deux jours et demi de travail, tout en sachant que l’application Android est écrite dans un autre langage (Kotlin et Jetpack Compose). Après la publication le 15 août, elle a rencontré un succès assez rapide, avec déjà 5 000 installations.
Il y a très peu de paramètres, dans Saracroche. C’est limite frustrant pour des geeks. Il n’y a rien à ajouter ?
Mon but aussi est de proposer une application simple, pour le plus grand nombre avec peu de réglages en apparence. Je souhaite rajouter des fonctionnalités plus avancées, mais elles ne seront pas accessibles directement.

Logo de Saracroche
Je veux une UX réussie pour le plus grand nombre d’entre nous pas uniquement pour les geeks, car les appels et SMS indésirables sont un fléau et tout le monde doit pouvoir un moyen de s’en protéger. Proposer une interface de qualité par expérience, c’est du travail. Quand on est développeur, on a tendance à mettre toutes les fonctionnalités au même niveau mais il faut savoir hiérarchiser, avoir une vraie réflexion sur l’interface, se poser les bonnes questions, et se montrer empathique sur les besoins premiers des utilisateurs.
Ce que je souhaiterais rajouter :
- Une liste participative qui permettra de bloquer ou indiquer les appels indésirables de façon plus réactive.
- Bloquer les SMS.
- Proposer différentes listes avancés.
- L’adapter à l’étranger.
- Des options avancées (j’ai reçu des mails et tickets sur GitHub)
- Peut-être une version pour entreprise qui pourrait m’aider à rendre viable le projet sur long terme.
Il y a des choses que je vais pouvoir faire sur Android que je ne pourrais pas proposer sur iOS. Les deux plateformes sont très différentes sur leur gestion d’appels et SMS.
Je souhaite collaborer avec le service 33700. Je les ai contactés, mais malheureusement, je n’ai encore reçu aucune réponse.
L’app est disponible directement dans les magasins d’applications, pour iOS et Android, c’est bien ça ?
Oui, elle est disponible sur les plus gros stores. Elle est aussi disponible pour ceux sur Android via Obtainium et un jour sur F-Droid. Cela demande de faire une build reproductible. Je me suis penché dessus, mais cela va demander du temps.
Est-ce que tu as besoin d’un coup de main ? Pour traduire, soutenir, tester, c’est le moment de demander, on a un petit lectorat de libristes.
J’aurais besoin d’aide pour tester. Par exemple, en ce moment, je travaille sur une version iOS qui se met à jour en arrière-plan et iOS a un certain nombre de limitations, donc je souhaiterais avoir des retours sur le fonctionnement.
J’ai toujours besoin des signalements pour faire grossir la base de données et améliorer le blocage.
L’application est jeune, elle n’a que 5 mois sur iOS et même pas 1 mois sur Android, donc il y a encore beaucoup de travail, ne serait-ce que pour la traduire, rajouter des fonctionnalités… je n’en suis qu’au début !
Tu as prévu de développer d’autres applis d’utilité publique, ou bien ?
J’ai plusieurs idées, une application de recette couplée avec la base de données du Ciqual de l’ANSES pour aider à manger plus équilibré, moins de viande, et avoir le décompte des macronutriments. Une application pour aider les associations à gérer leurs membres avec un accent particulier sur l’expérience utilisateur.
J’ai toujours des idées, voire trop ! Mais Saracroche m’a donné encore plus envie de créer et d’être un contributeur open source.
Pour aller plus loin
Nous vous invitons à tester Saracroche, une app encore jeune, et à nous faire des retours dans les commentaires ou directement auprès de Camille via son site.
Saracroche n’a pas encore de notice dans Framalibre, notre annuaire de logiciels libres contributifs, je dis ça je dis rien.
22.09.2025 à 07:42
Khrys’presso du lundi 22 septembre 2025
Khrys
Texte intégral (10200 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- TikTok : les États-Unis et la Chine s’entendent sur « un cadre pour un accord » (lemonde.fr)
- Là où la jeunesse fait vaciller le vieux monde (basta.media)
Dans plusieurs pays d’Asie, les jeunes se soulèvent. Après la révolution au Bangladesh l’an dernier, des mouvements ont lieu au Népal et en Indonésie. Des médias indépendants du monde entier s’intéressent à ces mobilisations.
- Israel killed 31 journalists in Yemen strike, press freedom group says (washingtonpost.com)
Last week’s attack was “the deadliest strike on journalists in the Middle East” documented by the Committee to Protect Journalists.
- When Africa’s internet breaks, this ship answers the call (restofworld.org)
Undersea internet cables are critical in today’s hyperconnected world. The crew of the Léon Thévenin maintains one stretch of this global network.
- COP30 : la trajectoire climatique européenne s’embourbe, la faute à la France qui trouble le jeu (humanite.fr)
À moins de deux mois du prochain sommet onusien sur le climat, les États membres de l’Union européenne sont incapables de se mettre d’accord sur un objectif clair de décarbonation, au risque de mettre en péril l’accord de Paris. Une situation provoquée par la France, qui cherche à remodeler l’objectif climatique 2040 de l’UE à sa guise.
- « L’Espagne compte aujourd’hui, 2,3 millions d’emplois de plus qu’avant la pandémie » : comment le gouvernement de gauche a redressé l’économie nationale (humanite.fr)
La nouvelle politique économique – fondée sur une importante expansion keynésienne, des augmentations salariales pour compenser l’inflation et la mise en place de nouveaux programmes de revenus minimums pour réduire les inégalités – a jeté les bases d’une croissance assez remarquable.
- Scammers using QR code stickers on parking meters to get at people’s bank accounts (nltimes.nl)
Paying with your smartphone has become commonplace, and scammers are finding new ways to exploit this. A new method on the rise in the Netherlands is sticking QR codes on parking meters, taking users to a spoofed website of the popular parking app EasyPark, where they have to enter their bank or credit card information.
- ProtectNotSurveil coalition raises alarm about EU’s Frontex expansion plans (edri.org)
The European Commission is set to reform Frontex’s mandate again in 2026. Frontex is the European Border and Coast Guard agency. […] the ProtectNotSurveil coalition highlights how reckless the expansion of Frontex’s surveillance capacities would be and how the Commission’s foreseen plans go in the opposite direction of what migrants and affected communities are calling for.
- Massive Attack Turns Concert Into Facial Recognition Surveillance Experiment (gadgetreview.com)
During their latest tour stop, Massive Attack shocked fans by integrating facial recognition into the show itself. Live video feeds captured audience faces, processing them through recognition software and projecting the results as part of the visual experience. […] This stunt aligns with the band’s decades-long critique of surveillance culture and digital control systems.
- Le logiciel, talon d’Achille du numérique « responsable » vaudois (https-vd.ch)
Le Conseil d’État vaudois a récemment répondu à une interpellation sur la durée de vie des équipements numériques utilisés par l’administration cantonale. Si cette réponse témoigne d’une volonté réelle de limiter l’empreinte environnementale du numérique public, elle laisse apparaître un angle mort préoccupant : le rôle central du logiciel dans l’obsolescence. […] Cette absence de critères empêche toute transition vers des systèmes d’exploitation libres, qui pourraient prolonger de plusieurs années la vie utile d’un appareil, et faciliter sa réutilisation par des tiers.

- Why Europe’s new tech laws have the world on edge (edri.org)
Trump and the global far-right are trying to discredit Europe’s tech laws with misinformation and political pressure, fearing that these regulations might disrupt their ability to undermine democracy. If Europe wants to safeguard its democracy and its credibility as a global regulatory leader in tech, the European Commission needs to enforce these laws swiftly and decisively.
- L’Irlande nomme une ancienne lobbyiste de Meta en tant que commissaire de sa CNIL (next.ink)
- Ballons JD Vance, sosies… Les manifestant·es anti Trump à Londres n’ont pas manqué de créativité (huffingtonpost.fr)
- Four arrested after photo of Trump and Jeffrey Epstein projected onto Windsor Castle (independent.co.uk)

- Channel 4 to mark Trump’s UK visit with ‘longest uninterrupted reel of untruths’ (theguardian.com)
More than 100 of Donald Trump’s inaccurate statements are to be dissected by Channel 4 to coincide with his state visit, in what it described as “the longest uninterrupted reel of untruths, falsehoods and distortions ever broadcast on television”.
- 170 milliards de dollars de pertes en six décennies : le coût du blocus étasunien pour Cuba (humanite.fr)
Lors de la présentation de son rapport annuel, le ministre des Affaires étrangères de l’île a fustigé une hausse de près de 50 % des dommages et préjudices subis par La Havane.
Voir aussi Cuba : comment Donald Trump a intensifié le blocus contre l’île (humanite.fr)
Avec leur politique « criminelle et inhumaine » de blocus visant Cuba basée sur « la misère, la faim et le désespoir », les États-Unis seraient responsables d’« une violation massive et systématique des droits humains », selon un dernier rapport diffusé par La Havane.
- Trump announces skilled worker visas will now cost $100,000 (theverge.com)
- Jimmy Kimmel viré, un signal de plus de l’effondrement de la liberté d’expression aux États-Unis (telerama.fr)
La star des talk-shows américains a été suspendue d’antenne par ABC après avoir critiqué la récupération de la mort de l’influenceur Charlie Kirk par le camp trumpiste. Après la fin du “Late Show” de Stephen Colbert, qui sera le prochain sur la liste ?
- The Scary Truth Behind Stephen Colbert’s Cancellation and Jimmy Kimmel’s Silencing (collider.com)
With Paramount, who owns CBS, wanting to merge with Skydance (which is led by Trump ally David Ellison), and the Federal Trade Commission (led by Trump appointee Brendan Carr) needing to sign off on the merger, many wondered if this would lead to Colbert, also a frequent critic of the former reality star-turned-President during his entire 10-year stint leading The Late Show, being fired.
- Donald Trump se dit « attaché à la liberté d’expression »… mais juge « illégal » que trop de médias le critiquent (huffingtonpost.fr)
Le président américain était interrogé sur l’éviction de Jimmy Kimmel sous la pression de son administration. Il a donné une définition très personnelle du « free speech ».

- Le Pentagone veut imposer aux journalistes son autorisation avant la publication d’une information (lemonde.fr)
Dans un message envoyé aux médias, le département de la défense américain menace de révoquer les accès au Pentagone si les correspondants ne se plient pas à cette règle.
- Aux États-Unis, le Sénat instaure une journée nationale de commémoration de Charlie Kirk (franceinfo.fr)
- DOJ Quietly Deletes Study on Politics of Domestic Terrorists (newrepublic.com)
Trump’s Justice Department deleted a study from its website stating that right-wing violence “continues to outpace all other types of terrorism and domestic violent extremism” in the United States. This comes as the Trump administration and Republicans generally blame political violence solely on the left.
- Les purges menées par l’administration Trump et le mouvement MAGA après l’assassinat de Charlie Kirk : un premier bilan (legrandcontinent.eu)
- U.S. Press Freedom in Sharp Decline as Economic Pressures and Political Attacks Mount (mediabiasfactcheck.com)
The United States has fallen to 57th place in the 2025 RSF World Press Freedom Index, its lowest ranking in recent history, reflecting a deepening crisis for journalism in the country. Press freedom in the U.S. now faces unprecedented challenges—not only from political pressure but also from economic collapse within the media industry.
- Aux États-Unis, la police de l’immigration jette une candidate démocrate au sol… et est félicitée sur Fox News (huffingtonpost.fr)
Laura Ingraham, une présentatrice vedette de la chaîne, a salué le travail des agents de l’ICE après que l’un d’eux a poussé violemment la démocrate Kat Abughazaleh.
- Le président américain a désigné le mouvement « Antifa » comme organisation terroriste. (huffingtonpost.fr)
- After cuts to food stamps, Trump administration ends government’s annual report on hunger in America (mainichi.jp)
- RFK Jr.’s anti-vaccine panel realizes it has no idea what it’s doing, skips vote (arstechnica.com)
- Samsung brings ads to US fridges (theverge.com)
Samsung’s ‘screens everywhere’ initiative is morphing into ads everywhere.
- Countries are struggling to meet the rising energy demands of data centers (restofworld.org)
Mexico’s lagging energy grid is forcing companies, including Microsoft, to use generators.
- Après la condamnation de Bolsonaro, le Brésil face aux forces réactionnaires (politis.fr)
L’ex-président a écopé de 27 ans de prison pour tentative de coup d’État. Un jugement historique pour le pays. Il ne met cependant pas fin aux assauts de l’extrême droite, qui compte notamment sur Trump pour sauver leur leader.
- « Un cas de racisme environnemental » : à l’approche de la COP30 à Belém, une favéla lutte pour accéder à l’eau potable (vert.eco)
- Chili : la Patagonie asphyxiée par ses saumons (politis.fr)
Le Chili est le deuxième producteur de ce poisson d’élevage au monde, après la Norvège, et la société civile exige une régulation de cette industrie jugée « écocidaire ». En juillet, l’ONG Oceana a alerté sur les risques pour l’environnement et l’humain que représente l’usage massif d’antibiotiques.
Spécial IA
- China’s DeepSeek says its hit AI model cost just $294,000 to train (reuters.com)
- DeepSeek AI’s code quality depends on who it’s for (and China’s opinion of them) (techspot.com)
- ChatGPT consomme autant d’énergie qu’une ville entière pendant trois jours (science-et-vie.com)
- Mark Zuckerberg n’a pas pu cacher son désarroi devant la présentation erratique de ses lunettes IA (huffingtonpost.fr) – voir aussi Quand l’IA ne veut pas (gros fail de Zuckerberg) (tube.fdn.fr)
- Microsoft, Nvidia, other tech giants plan over $40 billion of new AI investments in UK (cnbc.com)
- Microsoft is filling Teams with AI agents (theverge.com)
Dedicated Copilot agents will join meetings and answer questions in channels.
- Google stuffs Chrome full of AI features whether you like it or not (theregister.com)

- ChatGPT Will Guess Your Age and Might Require ID For Age Verification (yro.slashdot.org)
- OpenAI says models are programmed to make stuff up instead of admitting ignorance (go.theregister.com)
- Librarians Are Being Asked to Find AI-Hallucinated Books (404media.co)
patrons are growing more trusting of their preferred generative AI tool or product, and the veracity of the outputs they receive. […] librarians report being treated like robots over library reference chat, and patrons getting defensive over the veracity of recommendations they’ve received from an AI-powered chatbot. Essentially, like more people trust their preferred LLM over their human librarian.
- Science journalists find ChatGPT is bad at summarizing scientific papers (arstechnica.com)
LLM “tended to sacrifice accuracy for simplicity” when writing news briefs.
- Un rapport sur l’éducation appelant à une utilisation éthique de l’IA contient plus de 15 sources fictives (developpez.com)
- AI medical tools found to downplay symptoms of women, ethnic minorities (arstechnica.com)
Bias-reflecting LLMs lead to inferior medical advice for female, Black, and Asian patients.
- Épinglée pour la diffusion d’un visuel jugé raciste, la police nationale du Doubs le retire en catimini (lechni.info)
Une dame blanche, âgée, chic mais modeste, devant un distributeur, le regard perdu et qui semble supplier tout témoin de l’aider face à un danger imminent qu’elle ressent mais ne perçoit pas ; à un pas derrière elle, dans l’ombre, la fixant tel un charognard sur sa proie, surgit un homme, plus grand, jeune, cheveux crépus, le teint légèrement halé, portant un sweat à capuche. Cette scène n’est pas issue du dernier blockbuster identitaire, mais des réseaux sociaux de la « Police Nationale du Doubs ». Souhaitant alerter sur les dangers du « vol par ruse », l’institution n’a pas hésité à avoir recours à l’intelligence artificielle pour générer une iconographie qu’elle jugeait appropriée.
- Massive Attack remove music from Spotify to protest against CEO Daniel Ek’s investment in AI military (theguardian.com)
The band cited a ‘moral and ethical burden’ placed on artists by revenue from their work ultimately funding lethal technologies
- The Organic Academic Pledge (organicacademic.online)
We, the undersigned, pledge to never use generative AI for any part of our academic research.
- The Useful Idiots of AI Doomsaying (theatlantic.com)
Those who predict that superintelligence will destroy humanity serve the same interests as those who believe that it will solve all of our problems.
- Large Language Muddle (nplusonemag.com)
- Against the protection of stocking frames. (ethanmarcotte.com)
I think it’s long past time I start discussing “artificial intelligence” (“AI”) as a failed technology. Specifically, that large language models (LLMs) have repeatedly and consistently failed to demonstrate value to anyone other than their investors and shareholders. The technology is a failure, and I’d like to invite you to join me in treating it as such.
- About AI and Unlikelihood (superrr.net)
AI systems can by design only learn from the past – a past which is shaped by structures of colonialism, white supremacy and patriarchy. If AI is a machine of the past, then it is our craft to dream up futures not yet imagined. Artificial intelligence cannot, by design, do this ; what we need is the joy, wisdom and solidarity of real, messy, creative people.
Spécial Palestine et Israël
- Israeli tanks push into major Gaza City residential area (bbc.co.uk)
- The frantic race to protect historic treasures from Israeli bombs (bbc.co.uk)
- Ces Israélien·nes manifestent à la frontière avec Gaza pour dénoncer leur « pays qui tue tant de gens » (huffingtonpost.fr)
Des militant·es israélien·nes ont manifesté à la frontière avec la bande de Gaza alors que l’armée israélienne a prévenu qu’elle allait frapper Gaza-ville avec « une force sans précédent ».
- Israël, Eric Cantona prend position (football.fr)
« Quatre jours après le début de la guerre en Ukraine, la Fifa et l’UEFA ont suspendu la Russie. Nous en sommes maintenant à 716 jours de ce qu’Amnesty International a qualifié de génocide. Et pourtant, Israël continue d’être autorisé à participer. Pourquoi ces doubles standards ? »
- Aux Emmy Awards, Javier Bardem lance « Free Palestine » vêtu d’un keffieh (huffingtonpost.fr)
L’acteur espagnol a dénoncé « le génocide à Gaza » lors de la 77e édition des « Oscars de la télévision américaine » à Los Angeles.
- Massive Attack interdit la diffusion de sa musique en Israël et claque la porte de Spotify (liberation.fr)
Le légendaire groupe britannique a annoncé rejoindre l’initiative No Music for Genocide et bloque sa diffusion sur le territoire hébreu.
- “Pas de musique pour le génocide” : plus de 400 artistes et labels ne sont plus écoutables en Israël (telerama.fr)
Plusieurs centaines d’artistes internationaux dont Massive Attack, Fontaines D.C., Kneecap… ont rejoint le collectif No Music for Genocide, et appellent au boycott culturel de l’État hébreu.
- Comment les accusations de génocide à Gaza visant Israël ont pris une nouvelle dimension (huffingtonpost.fr)
Alors que les accusations de génocide à Gaza se multiplient ces derniers mois, une commission d’enquête de l’ONU a pour la première fois elle aussi qualifié la situation dans l’enclave palestinienne de génocide.
- Reconnaissance de la Palestine : le très politique revirement d’Emmanuel Macron (politis.fr)
Face à l’opinion publique et au génocide en cours à Gaza, le président se résout à prendre cette décision symbolique. À rebours de ses propres positions et de celles de ses ministres successifs.
- Drapeaux palestiniens sur les mairies : Retailleau veut les interdire, mais que dit vraiment la loi (huffingtonpost.fr) – voir aussi Drapeaux palestiniens : la nouvelle charge de Bruno Retailleau contre la solidarité avec Gaza (humanite.fr)
Le ministère de l’Intérieur a demandé aux préfets, dans un télégramme consulté vendredi 19 septembre par l’AFP, de s’opposer à la pose de drapeaux palestiniens sur des mairies et autres édifices publics lundi 22 septembre. Même le jour de la reconnaissance officielle par Emmanuel Macron de l’État de Palestine, la solidarité avec son peuple victime d’un génocide doit être interdite aux yeux de Bruno Retailleau.
- Marine Le Pen, Bruno Retailleau… En France, les derniers soutiens « inconditionnels » à Israël (humanite.fr)
De Marine Le Pen à Bruno Retailleau en passant par quelques élus macronistes, plusieurs responsables politiques continuent de fermer les yeux sur le génocide à Gaza et s’opposent fermement à la reconnaissance par la France d’un État palestinien.
- Depuis Gaza et Ramallah : « Macron parle de deux États tout en continuant d’armer Israël » (politis.fr)
La reconnaissance de leur État est un combat pour les Palestiniens depuis 77 ans. Lundi 22 septembre, à la tribune de l’ONU, la France, suivie par 17 autres pays dont le Royaume-Uni, va enfin franchir le pas.
- Nouveau veto américain pour protéger Israël, colère des 14 autres membres du Conseil de sécurité (france24.com)
- L’Espagne va coopérer activement avec la justice internationale pour enquêter sur des « violations des droits humains à Gaza » (humanite.fr)
La justice espagnole va collaborer avec la Cour internationale de justice et la Cour pénale internationale pour enquêter sur les crimes de guerre commis par Israël dans l’enclave palestinienne.
- Le Royaume-Uni, le Canada et l’Australie reconnaissent officiellement l’État de Palestine (huffingtonpost.fr)
Ces annonces interviennent à la veille d’un sommet important à New York, coprésidé par la France et l’Arabie saoudite, au sujet de l’avenir de la solution à deux États.
Spécial femmes dans le monde
- Tribune féministe internationale pour le boycott du Forum mondial des femmes pour la paix (contretemps.eu)
Les 19 et 20 septembre, un « Forum mondial des femmes pour la paix » se tenait à Essaouira (Maroc). En instrumentalisant le féminisme, il met sur le même plan la résistance palestinienne et l’armée coloniale, soit colonisé et colonisateur, participant ce faisant à normaliser l’État colonial d’Israël.
- Early dropoff in girls’ school sports linked to new gender confirmation forms (edmontonjournal.com)
‘Girls are taking a hard hit, while nothing is happening with the boys’
- ‘The New Age of Sexism’ explores how misogyny is replicated in AI and emerging tech (pbs.org)

- Marlène, millionnaire en quête de justice (radiofrance.fr)
Marlène Engelhorn a grandi dans une famille multimillionnaire à Vienne, en Autriche. Elle apprend à dissimuler le patrimoine que possède sa famille. Quand elle apprend qu’elle va hériter de plusieurs dizaines de millions d’euros, elle décide de redistribuer cet héritage via une assemblée citoyenne.
Spécial France
- Le gouverneur de la Banque de France favorable à des mesures sur les hauts patrimoines (lemonde.fr)
François Villeroy de Galhau en appelle […] à résoudre d’urgence un problème budgétaire « aggravé » par la crise politique. « On ne peut plus attendre, a-t-il déclaré, déplorant les querelles politiciennes ».« Pour citer un exemple, des mesures antioptimisation fiscale sur les hauts patrimoines seraient justifiées » afin que l’effort de redressement soit « ressenti comme juste »
- Thomas Piketty : « Le combat pour la taxation des plus riches ne fait que commencer » (politis.fr)
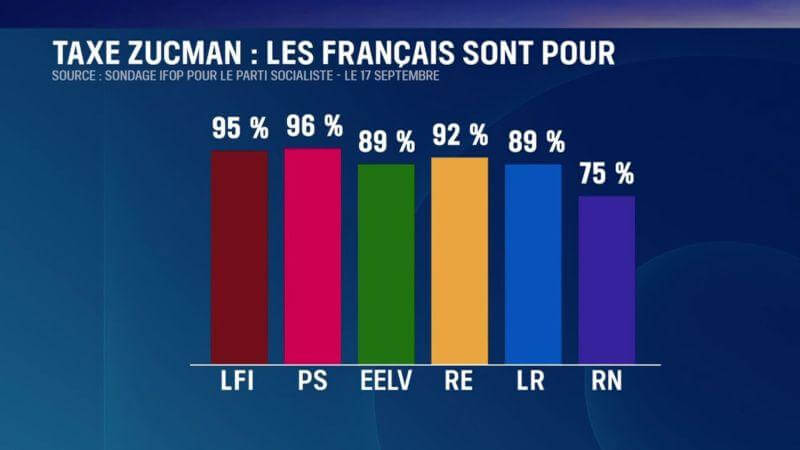
- Taxe Zucman : panique à bord au Medef (politis.fr)
Alors que la taxe qui vise à taxer les patrimoines des ultra-riches, s’impose dans le débat public, le patronat monte de plus en plus violemment au front pour s’indigner de cette proposition. Signe d’une panique croissante.
- Stérin, visé par une enquête après son refus de comparaître devant les députés (projetarcadie.com)
- Pour Bernard Arnault, Gabriel Zucman est un « militant d’extrême gauche » qui vise « la destruction de l’économie libérale » (liberation.fr)
Chez ceux que sa taxe horrifie, certains disent qu’il invoque les sept plaies d’Egypte, d’autres que son pangolin domestique serait à l’origine du Covid-19, et certains prétendent même qu’il est l’architecte de l’Etoile de la mort. Gabriel Zucman est, aux yeux de Bernard Arnault, rien de moins qu’un « militant d’extrême gauche » dont l’objectif est « la destruction de l’économie libérale »
- Les tours de Notre-Dame de Paris rouvrent au public (france24.com)
Les tours de Notre-Dame de Paris seront de nouveau accessibles au public à partir de samedi dans le cadre des journées du patrimoine. Suspendu après l’incendie du 15 avril 2019, le parcours de la visite des tours a été totalement réorganisé et repensé avec à la clé l’une des plus belles vues de la capitale.
- Marche blanche pour rendre visibles les quatre victimes de meurtres homophobes retrouvées dans la Seine (humanite.fr)
Des centaines de personnes se sont réunies à Choisy-le-Roi (Val-de-Marne), ce 19 septembre, à l’appel de l’association Stop Homophobie, pour une marche blanche en hommage aux quatre victimes retrouvées dans la Seine le 13 août.
- La quasi-totalité de l’autorité environnementale d’Île-de-France démissionne (reporterre.net)
- Polytechnique, une école d’État sous emprise (multinationales.org)
Organes de gouvernance, chaires, partenariats, start-ups, associations d’élèves et d’anciens élèves… La place croissante des grandes entreprises à tous les niveaux de l’École polytechnique et leur influence sur le contenu de la recherche et de l’enseignement posent question dans un contexte d’urgence climatique.
- Cocktails et petits fours : quand Total, Nestlé et Danone financent les soirées étudiantes d’AgroParisTech (reporterre.net)
- PestiRiv : résultats de l’étude nationale sur l’exposition aux pesticides des riverains de zones viticoles (anses.fr)
Les résultats de l’étude montrent que les riverains des zones viticoles sont plus exposés aux produits phytopharmaceutiques appliqués sur ces cultures que les personnes éloignées de toute culture. Ces expositions sont par ailleurs plus importantes en période de traitement.
Voir aussi “Cette agriculture tue les gens” : l’étude PestiRiv révèle ses résultats, les riverains des vignes surexposés aux pesticides (france3-regions.franceinfo.fr)
Ce lundi 15 septembre étaient publiés les résultats très attendus de l’étude PestiRiv, portant sur l’exposition aux pesticides des populations situées à proximité des zones viticoles. Sans surprise, les riverains y sont fortement imprégnés de produits phytosanitaires et pose ainsi des questions de santé publique.
- A69 : des travaux assourdissants 18 heures par jour (reporterre.net)
Explosions, poussières… Depuis la reprise du chantier de l’A69, les riverains du tracé sont accablés par les nuisances. Le concessionnaire met les bouchées doubles pour combler son retard avant une audience décisive au tribunal.
- Le projet touristique porté par Tony Parker dans le Vercors est rejeté au motif des incertitudes sur l’impact environnemental (lemonde.fr)
Spécial femmes en France
- L’austérité budgétaire est sexiste (solidaires.org)
- Le cyberharcèlement frappe de plus en plus tôt et surtout les femmes (politis.fr)
Insultes, menaces, humiliations… Les études révèlent l’ampleur du cyberharcèlement en France qui débute dès l’école primaire et dont les conséquences psychologiques peuvent être dramatiques, allant jusqu’au suicide.
- « Pour lutter contre les cyberviolences, il faut combattre le sexisme hors-ligne » (politis.fr)
Comment lutter contre les violences sexistes en ligne ? Présidente du Collectif féministe contre le cyberharcèlement, Laure Salmona esquisse plusieurs pistes.
- Typhaine D : quand la justice décortique la violence masculine en ligne (politis.fr)
Neuf hommes ont été jugés, ce 17 septembre, par la 17e chambre du tribunal correctionnel de Paris, après une vague de cyberharcèlement subie par l’artiste Typhaine D. […] Qui aurait pu penser que l’écriture inclusive pouvait mener au tribunal ? Sûrement pas l’artiste Typhaine D. « Au bucher ! Sorcière ! », « Il faut la piquer », « Je déboiterai bien une bonne féministe », « Sale pute de Femen, le seul mot féminin que tu dois connaitre c’est ‘cuisine’ » (sic)… Des messages comme ceux-là, Typhaine D en a reçu des milliers en juillet 2022, après avoir participé à une émission du Crayon.
- Après le suicide de Caroline Grandjean, sa veuve Christine porte plainte contre l’Éducation nationale (huffingtonpost.fr)
Victime de harcèlement homophobe répété, l’institutrice à bout s’était donné la mort après avoir répertorié tout ce qu’elle subissait dans son village du Cantal.
- 83 % des affaires de violences sexuelles classées sans suite : le Conseil de l’Europe alarmé par l’impunité en France (nouvelobs.com)
- Après le féminicide d’Inès Mecellem à Poitiers, Gérald Darmanin a saisi l’Inspection générale de la justice (huffingtonpost.fr)
« Toute la lumière doit être faite sur cette horrible affaire », a déclaré le ministre de l’Intérieur, alors que la victime avait déposé plusieurs plaintes contre son ex-compagnon.
- Plaidoyer pour une médiatisation féministe pour contrer la propagande christofasciste (blogs.mediapart.fr)
Spécial médias et pouvoir
- Charlie Kirk et Charlie Hebdo : émoi à France Culture après un billet “du malaise et de la confusion” (telerama.fr)
Dans ce billet initialement titré « Je suis Charlie Kirk » et diffusé le 12 septembre, Guillaume Erner estimait qu’« il y a (vait) désormais au moins deux Charlie : le “Je suis Charlie” de Charlie Hebdo et puis “Je suis Charlie” de Charlie Kirk ».
- Delphine Ernotte monte au créneau contre CNews : “Qu’ils assument d’être une chaîne d’extrême droite !” (telerama.fr)
Dans un entretien au “Monde” ce jeudi 18 septembre, la présidente de France Télévisions défend vigoureusement l’audiovisuel public contre les offensives répétées des médias de l’empire Bolloré.

- « Bloquons tout » : un journalisme sous escorte policière (acrimed.org)
L’angle sécuritaire a largement dominé le traitement médiatique du mouvement social « Bloquons-tout », organisé partout en France le 10 septembre. Défilé de policiers sur les plateaux télé, focalisation sur les « violences », décompte en direct sur les chaînes d’information en continu du nombre d’interpellations : retour sur un cas d’école de journalisme de préfecture.
- « Bloquons tout » du 10 septembre sur CNews : haine, désinformation et carton d’audience (politis.fr)
Le 10 septembre, comme d’habitude, le moindre feu de poubelle a tenu en haleine tous les éditorialistes de chaînes d’info. Sur l’extrême droitière CNews, les grévistes n’étaient plus des Français·es lambda aux revendications légitimes, mais des gauchistes-LFIstes « palestinistes ».
- Pourquoi on ne voit que des gens aisés à la télé (frustrationmagazine.fr)
ce n’est pas seulement quand il s’agit d’information : en fait, tous les programmes télévisés sur-représentent les catégories aisées et diplômés. Et c’est… de pire en pire, nous confirme le rapport annuel de l’Arcom (ex-CSA)
- Prétention à l’objectivité du journalisme français : ça suffit ! (frustrationmagazine.fr)
Le journalisme français s’est bâti sur ce mythe : celui d’une objectivité quasi scientifique. Le journaliste, dit-on, « relate les faits », sans parti pris. Cette fiction, héritée de l’universalisme républicain, est brandie comme un étendard de professionnalisme. Mais comme l’ont montré par exemple les sociologues Pierre Bourdieu et Patrick Champagne, cette neutralité est un masque. Les journalistes politiques évoluent dans les mêmes cercles que les élus, fréquentent les mêmes grandes écoles, partagent les mêmes habitus bourgeois et parisiens. Ce n’est pas de l’objectivité : c’est un point de vue situé, celui d’une classe sociale dominante qui a réussi à imposer son regard comme « neutre ».
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- La main dans le sac. Sébastien Lecornu n’est pas diplômé d’un master de droit, contrairement à ce qu’il prétendait (liberation.fr)
« Mediapart » révèle ce vendredi 19 septembre que le Premier ministre a « manipulé la réalité » en se présentant comme titulaire d’un diplôme qu’il n’a jamais obtenu.
Voir aussi Sébastien Lecornu : Le Premier ministre reconnaît ne pas avoir fini le cursus mentionné sur son CV (20minutes.fr)
Le journal [Mediapart] rappelle que ce genre de mensonge a poussé à la démission Noelia Núñez, députée espagnole. Elle avait assuré être diplômée en droit, en administration publique et en philologie anglaise avant d’admettre avoir entamé des études sans jamais les avoir finies. « Un diplôme en droit n’est pas indispensable pour représenter les citoyens ; l’honnêteté l’est », affirmait un édito d’El Pais, cité par le journal d’investigation français.
- “Mission État efficace” : Sébastien Lecornu nomme deux fonctionnaires chargés de supprimer des structures publiques (franceinfo.fr)
- Sébastien Lecornu supprime la délégation en charge du SNU en attendant « la création prochaine » d’un « service militaire volontaire » (liberation.fr)
Le nouveau Premier ministre a annoncé vendredi 19 septembre, qu’il entendait supprimer, au nom d’un Etat « efficace », plusieurs structures et délégations interministérielles, dont celle en charge du service national universel (SNU).
- Brevet 2026 : “les 2011 on est vraiment maudits”, les élèves de collège perdus face à la réforme qui les touche (france3-regions.franceinfo.fr)
Les collégiens multiplient les messages d’incompréhension et d’inquiétude face aux changements du diplôme national du brevet. Entre nouvelle notation, poids renforcé des épreuves finales et épreuves de mathématiques sans calculatrice, la réforme fait réagir aussi bien les élèves que les parents.
- Qui est Thierry Breton, le patron le plus incompétent de France ? (frustrationmagazine.fr)
- Pourquoi la Cour des comptes s’oppose à la gratuité des trams, métros et bus (lefigaro.fr)
- Inaction écologique : même la Cour des comptes tacle l’État (reporterre.net)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- De la dette publique à la lutte contre la démocratie : une stratégie néolibérale (politis.fr)
Pour les néolibéraux – qu’ils soient globalistes comme Emmanuel Macron ou nationalistes comme le RN –, la démocratie comme régime fondé sur le principe d’égalité doit être nécessairement limitée.
- Une étude d’ampleur sur l’islamophobie révèle l’angoisse des musulman·es en France (politis.fr)
Mené par l’Ifop et la Grande mosquée de Paris, ce travail montre l’étendue du racisme subi par les musulman·es en France au quotidien, au travail, dans l’Éducation, par les forces de l’ordre ou dans les services publics.
- Éric Zemmour définitivement condamné pour des propos racistes en 2019 (franceinfo.fr) – voir aussi Racisme : Éric Zemmour condamné pour la deuxième fois en deux semaines (humanite.fr)
La cour de cassation a rejeté, mardi, le pourvoi d’Éric Zemmour qui est donc définitivement condamné pour provocation à la haine raciale et injure à caractère raciste. En cause, des propos tenus en 2019 à la Convention de la droite.
- Un journaliste blessé dans une manif à Lyon, ses collègues de France TV mettent en cause les « forces de l’ordre » (huffingtonpost.fr)
Deux policiers ont par ailleurs été blessés, dont l’un a « perdu une dent » à la suite d’un jet de projectile, selon la préfecture.
- À Marseille, une enquête ouverte après la vidéo d’une femme violentée par la police le 18 septembre (huffingtonpost.fr)
- 10 septembre : taser et coups de pied servis par la Brav dans un restaurant parisien (streetpress.com)
Le 10 septembre, au soir du mouvement « Bloquons tout », des policiers ont débarqué dans l’enseigne « Chez Papa » dans le 19e arrondissement de Paris. Six personnes témoignent de la violence de leur intervention, où des coups de taser ont été donnés.« C’était en mode Gestapo, ça frappait à gauche et à droite des gens, aléatoirement »
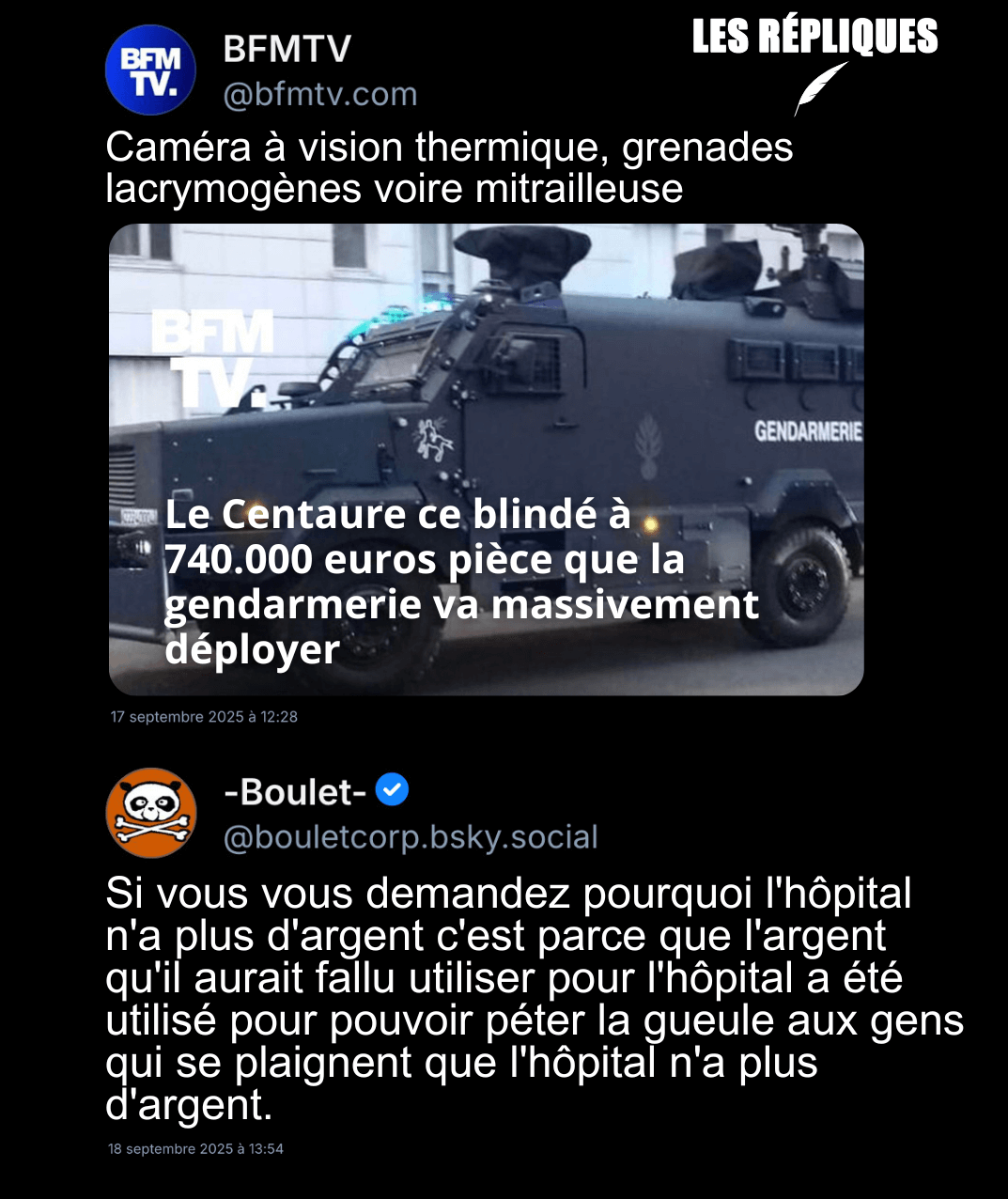
- Grève du 18 septembre : qu’est-ce que le Centaure, le véhicule blindé de la gendarmerie déployé pour faire face aux manifestations ? (franceinfo.fr)

Spécial résistances
- Sous les lacrymos, une soif de justice sociale (politis.fr)
Alors que ce 18 septembre marque la seconde étape d’un mouvement social qui grossit, le pouvoir politique comme économique pèse de tout son poids pour tenter d’éteindre une colère qui ne demande qu’à le déborder.

- Politis en direct des manifestations (politis.fr)
1 million de manifestant·es, selon la CGT. Tous les signaux étaient au vert, ce matin, pour une journée de mobilisation massivement suivie. Les promesses ont été tenues. Et le message envoyé à Emmanuel Macron, explicite : la fin de sa politique et du monde d’ultrariches dont elle sert les intérêts. Quelle sera la suite ?
- Pour la manifestation du 18 septembre, des cheminots en grève envahissent le ministère de l’Économie (huffingtonpost.fr)
L’action s’est tenue après une Assemblée générale organisée à la Gare de Lyon, située à quelques minutes.
- “Bloquons Tout” : c’est quoi “l’opération canard” qui a semé le bazar sur les boulevards à Toulouse ? (actu.fr)
“Opération canard”. C’est le nom de code d’une action menée ce samedi 13 septembre 2025 à Toulouse, dans le cadre du mouvement “Bloquons tout”. Et cela a semé une belle pagaille.[…]Le principe de ladite opération ? « Marcher à l’infini sur les passages piétons pour bloquer de fait la circulation »
- « Opération canard », « cortège vélorutionnaire » : c’est quoi ces actions vues aux mobilisations du 10 et du 18 septembre ? (leparisien.fr)
Des actions non violentes ont eu lieu lors des mobilisations du 10 et 18 septembre. Elles consistaient principalement à ralentir la circulation dans plusieurs villes françaises.
- « Ni ultimatum, ni pause » : organisons des AGs partout pour préparer la suite ! Billet d’Anasse Kazib (revolutionpermanente.fr)
Le mouvement doit se poursuivre et se doter d’un véritable plan de bataille pour faire tomber Lecornu et Macron.
- 24 septembre : l’intersyndicale lance un ultimatum au Premier ministre (rapportsdeforce.fr) – voir aussi Sébastien Lecornu répond à l’ultimatum des syndicats et leur propose une date de rencontre à Matignon (huffingtonpost.fr)
Le Premier ministre, arrivé en poste depuis peu, est attendu au tournant par l’intersyndicale, qui le menace d’une « nouvelle journée de grève ».
- Grêver est une joie pure ! (rogueesr.fr)
- À Bure, « la manif du futur » dénonce le projet Cigéo d’enfouissement de déchets nucléaires (huffingtonpost.fr)
Des centaines de personnes ont manifesté dans la Meuse, sous haute surveillance policière, contre le projet Cigéo d’enfouissement des déchets nucléaires hautement radioactifs.
Spécial outils de résistance
- Signer les pétitions : Pour une fiscalité juste : soutenons la taxe Zucman ! (petitions.assemblee-nationale.fr) et Pour une contribution équitable des ultra-riches et des grandes entreprises au financement des services publics (petitions.assemblee-nationale.fr)
- Imposition des ultrariches : au secours, les riches vont partir ! (basta.media)
Les gouvernements successifs agitent la peur de l’exil des ultra-riches pour ne pas trop les imposer. En s’appuyant sur des études, l’organisation Attac montre que les départs sont peu nombreux et défend une réforme de l’imposition des plus fortunés.
- 3 applis pour le 18 septembre et après (laquadrature.net)
- Vous avez été victime ou témoin de violences policières ? Partagez-nous votre témoignage (soscisurvey.de)
Ce questionnaire ANONYME et confidentiel a pour objectif de recenser les violences policières perpétrées pendant les journées de mobilisation. Il s’agit d’une initiative citoyenne menée par un collectif formé lors du mouvement “Bloquons tout”.

Spécial GAFAM et cie
- La taxe sur le numérique dans les clous de la Constitution (zdnet.fr)
La taxe GAFA française agace les États-Unis de Trump, mais aussi l’Européen Axel Springer qui l’attaquait devant le Conseil constitutionnel via sa filiale Digital Classifieds France. Le recours est écarté par les Sages.
- Google Secretly Handed ICE Data About Pro-Palestine Student Activist (theintercept.com)
Google handed over Gmail account information to ICE before notifying the student or giving him an opportunity to challenge the subpoena.
- This Microsoft Entra ID Vulnerability Could Have Been Catastrophic (wired.com)
A pair of flaws in Microsoft’s Entra ID identity and access management system could have allowed an attacker to gain access to virtually all Azure customer accounts.
- Boycott Microsoft (bdsmovement.net)
Microsoft is perhaps the most complicit tech company in Israel’s illegal apartheid regime and ongoing genocide against 2.3 million Palestinians in Gaza. Microsoft’s complicity in Israel’s apartheid and genocide is well documented, exposing its strong ties to the Israeli military, its collaboration with Israeli government ministries, and its involvement in the Israeli prison system, which is notorious for systematic torture and abuse of Palestinians. Microsoft knowingly provides Israel with technology, including artificial intelligence (AI), that is deployed to facilitate grave human rights violations, war crimes, crimes against humanity (including apartheid), as well as genocide.
- Un ancien fonctionnaire devient lobbyiste pour TikTok (projetarcadie.com)
Les autres lectures de la semaine
- Qui est responsable si un bot enregistre une réunion sans consentement ? (frenchweb.fr)
- « Les sciences sociales se sont construites comme un système de pouvoir ». Entretien avec Sonia Dayan-Herzbrun (contretemps.eu)
- 1st vs. 118th : On Gender Equality, Japan and Iceland Took Different Roads (unseen-japan.com)
Earlier this year, Japan’s Emperor Naruhito asked Iceland’s president why Iceland leads the world in gender equality. The question highlighted a striking contrast between the two nations. Iceland has held the top spot in the Global Gender Gap Report for years, while Japan ranks near the bottom.
- Depuis les soulèvements Indonésiens (lundi.am)
- L’incroyable histoire de la révolution haïtienne (frustrationmagazine.fr)
Alors qu’une guerre génocidaire à Gaza fait rage, et qu’en France un mouvement populaire renoue avec des aspirations révolutionnaires, certaines histoires trouvent un écho particulier. C’est le cas de la révolution haïtienne (1791-1804), la première révolution d’esclaves à avoir abouti, et qui, pour se faire, a tenu en respect, pendant plus de dix ans, des ennemis bien supérieurs en nombre et en armements
- Les chimpanzés consomment l’équivalent d’une « pinte de bière » par jour dans la nature, révèle une étude (huffingtonpost.fr)
- Ces livres qui brisent le « silence nucléaire » (reporterre.net)
RIP
- Robert Redford, icône du cinéma américain, est mort à 89 ans (france24.com)
Les BDs/graphiques/photos de la semaine
- Coups de fil

- Centaure
- Canadair
- Bollore
- Taxe
- Pognon
- Espagne
- Allocs
- Liberté d’expression
- Grok
- Trump
- Antifa
- Antifascists
- Nazis
- No
- Rage
- Origen
- Plaisir
- Password
- Swiss
- Stop
- Pratique
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Aides aux entreprises : quand Michelin envoie à l’étranger des machines achetées avec l’argent public (franceinfo.fr)
- Une élite incompétente méprisant profondément son peuple, voilà le néolibéralisme ! Barbara Stiegler (indymotion.fr)
- La démocratie ne meurt que si on la laisse mourir – Salomé Saqué (bee-tube.fr)
- Abir Al-Sahlani au parlement Européen (tube.fdn.fr)
- Manifestation du 18 septembre : la promenade de Villiers rebaptisée Philippe Poutou (ouest-france.fr)
Aux Sables-d’Olonne, la promenade Philippe de Villiers a été rebaptisée “promenade Philippe Poutou” par une quinzaine de membre de “Bloquons tout”, ce jeudi 18 septembre. Une inauguration dans les règles de l’art, avec un couper de ruban.
- Ça Crame – Planète Boum Boum (clip officiel) [La Lutte est Belle! – L’album des 130 ans de la CGT ] (videos.globenet.org)
- Un cheval chie en passant devant Trump (tube.fdn.fr)
- L’Actu des Oublié.e.s • S VI • EP 1 • USA : L’âge de glace s’achève (lenumerozero.info)
Les trucs chouettes de la semaine
- Les Mains Invisibles n°1 est sorti et librement téléchargeable (lesmainsinvisibles.wordpress.com)
Cette revue naît de la nécessité de redonner aux créatrices de la période moderne (qu’elles soient écrivaines, traductrices, éditrices, philosophes, artistes, architectes, scientifiques, compositrices, musiciennes, comédiennes…) la visibilité qu’elles avaient à leur époque, et ont perdu au fil des siècles en raison d’un processus, aujourd’hui bien connu, d’invisibilisation historiographique.
- Île de Man : comment des élèves d’une école primaire veulent sauver leur langue (france24.com)
Après la mort de son dernier locuteur natif en 1974, le gaélique mannois – aussi appelé le manx – n’avait plus grand espoir de revivre. Surtout quand l’Unesco officialise son extinction, en 2009. Mais les habitants de l’île de Man ont réussi à prouver le contraire.
- MaKING Printed Circuit Boards with Wild Clay (feministhackerspaces.cargo.site)
- Hosting a Website on a Disposable Vape (hackaday.com)
- Une chauve-souris pourrait bloquer un projet d’autoroute (reporterre.net)
- Chaussures odorantes, vaches zébrées et lézards croqueurs de pizzas… Voici les 10 lauréats des Ig-Nobel, récompensés pour leurs recherches des plus farfelues (franceinfo.fr)
La cérémonie s’est déroulée jeudi à Boston, un mois avant la remise des véritables prix Nobel. La 35e cuvée a été une nouvelle fois très riche.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
15.09.2025 à 07:42
Khrys’presso du lundi 15 septembre 2025
Khrys
Texte intégral (9469 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- How Vietnam’s military built one of the hottest tech companies in Southeast Asia (restofworld.org)
Over two decades, Viettel grew from a state telco into a tech powerhouse that makes everything from 5G chips to robots to affordable mobile phones.
- Kathmandu burns despite PM resignation (nepalitimes.com) – voir aussi How a movement against corruption on Nepali social media triggered unrest and death (restofworld.org)
In what has come to be known as the “Gen Z protest,” thousands of demonstrators took to the streets and 19 were reportedly killed.
Et From Discord to Bitchat, tech at the heart of Nepal protests (france24.com)
- Plus de 80 mortEs dans des inondations en Inde et au Pakistan (reporterre.net)
- L’Iran au bord de la crise de nerfs (orientxxi.info)
En Iran, le faible niveau des réserves en eau inquiète. Associé à l’augmentation des températures, provoquant des coupures d’électricité, il annonce une crise énergétique sans précédent, dans un contexte de tensions géopolitiques maximales.
- Les pays pétroliers annoncent une forte hausse de la production (reporterre.net)
La stratégie du « Drill, baby, drill ! » (« Fore, chérie, fore ! »), chère à Donald Trump, contamine les pays concurrents des États-Unis.Dimanche 7 septembre, l’Arabie saoudite, la Russie et six autres membres de l’Organisation des pays exportateurs de pétrole (Opep) ont annoncé une augmentation de leur production, pour répondre à la hausse de production aux États-Unis, au Canada et au Brésil.
- Solar power is growing exponentially in Africa (futuretimeline.ne)
- Les États membres figurent parmi les pays qui décarbonent le plus rapidement leur mix électrique (legrandcontinent.eu)
Sur les 10 pays ayant le plus augmenté la part de l’éolien et du solaire dans leur mix électrique entre 2021 et 2024, 9 sont des membres de l’Union européenne. En Lituanie, la part du renouvelable dans la production totale d’électricité a ainsi bondi de près de 30 points en l’espace de trois ans, passant de 36 à 65 %.
- Au centre du jeu bruxellois, l’extrême droite sonne la charge contre l’écologie et le climat (multinationales.org)
Au Parlement européen, les députés RN et leurs alliés ont noué une alliance de fait avec la droite pour saborder les régulations et les objectifs du Pacte vert. Et ne rechignent pas – à rebours de leurs discours en France – à faire les yeux doux aux industriels et aux lobbys patronaux.
- Dutch parliament votes to criminalize gay conversion therapy (nltimes.nl)
Therapy practices meant to “cure” homosexuality are set to become punishable by law. A majority in the Tweede Kamer, the lower house of the Dutch parliament, voted in favor of a bill by D66 and the VVD that ensures this. In a debate last week, it became clear that the proposers had, with a few adjustments, persuaded some opponents to reconsider.
- Ursula von der Leyen désormais visée par deux motions de censure au Parlement (huffingtonpost.fr)
Relations avec Israël, accord douanier avec Trump… Autant de raisons pour le groupe de Manon Aubry (LFI, groupe The Left à Bruxelles) de déposer une motion de censure.
- ‘Danger to Democracy’ : 500+ Top Scientists Urge EU Governments to Reject ‘Technically Infeasible’ Chat Control (patrick-breyer.de)
Over 500 of the world’s leading cryptographers, security researchers, and scientists from 34 countries have today delivered a devastating verdict on the EU’s proposed “Chat Control” regulation.
- Proton Mail Suspended Journalist Accounts at Request of Cybersecurity Agency (theintercept.com)
- Misinformation and myth : the UK’s phoney war over human rights (observer.co.uk)
- À Londres, 110 000 manifestants en l’honneur de l’influenceur trumpiste Charlie Kirk… Et avec eux Éric Zemmour et Steve Bannon (humanite.fr)
- Elon Musk accused of ‘inciting violence’ in UK, as four police officers seriously injured during protests (thelondoneconomic.com) Oh well, at least we locked up all those grannies and sign-holders the other week. Not a peep from Elon Musk about their free speech, mind.
- The shadow war on libraries (cbc.ca)
Some Canadian politicians and influencers, inspired by an American-born movement, are trying to roll back 2SLGBTQ+ rights in Canada — one book at a time.
- Abdulkader Sinno : Why I left IU, Indiana and the United States (idsnews.com)
I left IU because IU President Pamela Whitten’s administration and the IU Board of Trustees, backed by Indiana’s state government and collaborating with ideological organizations, are waging war on IU’s faculty, mistreating IU’s staff and attacking IU’s students if they dare to express views the administrators and politicians do not agree with.
- Domestic Workers in New York Face Low Pay, Exploitation — and Fear of Deportation (documentedny.com)
Immigrant domestic workers in New York are facing increasing fear of deportation as immigration enforcement intensifies under the new Trump administration.
- La Cour suprême des États-Unis légitime le contrôle au faciès (politis.fr)
« Nous n’employons pas le profilage racial », affirme le responsable de la politique d’expulsions aux États-Unis. Pourtant, les restrictions qui viennent d’être levées par la Cour suprême – ce dont il se félicite – visaient à éviter les dérives de la police de l’immigration (ICE), telles que le contrôle au faciès.
- Vance Blasted After Saying He Doesn’t ’Give A Sh*t’ If Bombing Venezuelan Boat Is A War Crime (comicsands.com)
- Shooter dead, 2 other students hospitalized after shooting at Colorado high school (abcnews.go.com)

- Assassinat de Charlie Kirk : qui était ce soutien majeur de Trump auprès de la jeunesse tué dans l’Utah ? (huffingtonpost.fr)
Défenseur du port d’armes à feu et anti-avortement, ce porte-parole du trumpisme pilotait l’un des podcasts les plus écoutés aux États-Unis. L’influence de Charlie Kirk […] avait largement servi Donald Trump pour séduire les jeunes hommes américains en promouvant une conception ultra-traditionnelle de la famille.
- Charlie Kirk’s Legacy Deserves No Mourning (thenation.com)
There is no requirement to take part in this whitewashing campaign, and refusing to join in doesn’t make anyone a bad person. It’s a choice to write an obituary that begins “Joseph Goebbels was a gifted marketer and loving father to six children.”
- Charlie Kirk was killed by a meme (garbageday.email)
- After Charlie Kirk’s death, teachers and professors nationwide fired or disciplined over social media posts (nbcnews.com)
- Elon Musk n’est plus l’homme le plus riche du monde, qui est Larry Ellison qui le détrône (huffingtonpost.fr)
Le patron du géant technologique Oracle a profité d’un énorme coup de pouce boursier ce mercredi pour ravir la première place au patron de X et de Tesla.
- Climat : Donald Trump supprime l’obligation pour les industries polluantes de calculer leur impact carbone (humanite.fr)
« Une fois de plus, cette administration tente de dissimuler les données afin de masquer les dommages », a fustigé Julie McNamara, de l’association Union of Concerned Scientists auprès de l’AFP. « Si nous ne pouvons pas dire ce que fait une entreprise, nous ne pouvons pas la tenir pour responsable »
- Attaques de Trump : les climatologues étasuniens ripostent (reporterre.net)
« Ils cachent la vérité. Nous ripostons. » Les mots claquent à la une du site Climate.us. Cette plateforme en cours de construction vise à remplacer le site Climate.gov. Un portail anglophone d’information et de vulgarisation sur le changement climatique qui était extrêmement réputé et fréquenté aux États-Unis, avant d’être fermé en juin par le gouvernement de Donald Trump.
- Brésil : Jair Bolsonaro condamné à 27 ans de prison pour tentative de coup d’État (humanite.fr) – voir aussi L’ancien président brésilien Jair Bolsonaro condamné à vingt-sept ans de prison pour tentative de coup d’Etat (lemonde.fr)
L’ex-dirigeant d’extrême droite a été reconnu coupable d’avoir été le chef d’une « organisation criminelle » ayant conspiré pour assurer son « maintien autoritaire au pouvoir » malgré sa défaite en 2022. Sa défense va déposer des recours, « y compris au niveau international ».
- How Big Tech Killed Brazil’s “Fake News Bill” (elclip.org)
Bill 2630 changed the relationship between tech companies and the far right and revealed the menu of lobbying strategies against regulation
- Comment les faussaires de Tenu.pro inondent les revues scientifiques (france24.com)
Des chercheureuses ont mis à jour un réseau d’ampleur de publication de “faux” articles scientifiques baptisé Tenu.pro qui a réussi à placer plus de 1 500 études “biaisées” dans des revues scientifiques.
- The cold truth about EVs : Freezing weather slashes battery mileage (restofworld.org)
Innovation in China and Norway makes strides, but in most markets EVs can lose almost half their driving distance when temperatures drop.
- Disposable face masks used during Covid have left chemical timebomb (theguardian.com)
The surge in the use of disposable face masks during the Covid pandemic has left a chemical timebomb that could harm humans, animals and the environment, research suggests.Billions of tonnes of plastic face masks created to protect people from the spread of the virus are now breaking down, releasing microplastics and chemical additives including endocrine disruptors, the research found.
- Heart attacks may actually be infectious (sciencedaily.com)
Heart attacks may not just be caused by cholesterol, they could be sparked by hidden bacterial biofilms that awaken after viral infections. This discovery could transform prevention and treatment, even leading to vaccines against heart disease.
- What the NHS can learn from the European country that boosted cancer survival rates (bbc.com)
- This Teen Scientist Turned a $0.50 Bar of Soap Into a Cancer-Fighting Breakthrough and Became ‘America’s Top Young Scientist’ (zmescience.com)
Heman’s inspiration for his invention came from his childhood in Ethiopia, where he witnessed the dangers of prolonged sun exposure.
Spécial IA
- The myth of sovereign AI : Countries rely on U.S. and Chinese tech (restofworld.org)
As countries pursue self-sufficiency in AI, they risk depending on foreign companies, undermining their independence and their goals.
- L’Albanie nomme pour la première fois un ministre généré par intelligence artificielle (rfi.fr)
C’est une première dans le monde, l’Albanie vient de faire entrer dans son gouvernement un ministre généré par intelligence artificielle. L’annonce en a été faite par le Premier ministre, Edi Rama, qui a présenté l’innovation comme un moyen de lutter contre la corruption.
- CEOs Are Obsessed With AI, But Their Pushes to Use It Keep Ending in Disaster (futurism.com) They recognize it’s less about the technology, and more about the willingness to truly reinvent the work, the workforce.
- This Year’s Finest Examples of AI Misadventure (aidarwinawards.org)

- Mathematicians Find GPT-5 Makes Critical Errors in Original Proof Generation (yro.slashdot.org)
The researchers compared the experience to working with a junior assistant needing careful verification. They warned AI reliance during doctoral training risks students losing opportunities to develop fundamental mathematical skills through mistakes and exploration.
- Des codeureuses sont embauché·es pour réparer les erreurs commises par l’IA qui provoque leurs licenciements (developpez.com)
Spécialiste en nettoyage de code généré par l’IA est le nouveau titre d’emploi en vogue sur les CV
- Mojeek is Not an Answer Engine (blog.mojeek.com)
Almost all companies in search are rushing to embed AI answers into search results pages. Google has rolled out AI Overviews. Microsoft has fused Bing with CoPilot. And others are moving quickly in the same direction. The intent is clear. Instead of connecting you to the web, these so-called search engines are keeping you away from it.
- Peut-il y avoir un « bon usage de l’IA » à l’université ? (blogs.mediapart.fr)
Il est indéniable que l’IA fait dorénavant partie de notre époque. Faut-il pour autant automatiquement accepter tout ce qui en découle, comme anesthésiés au regard de toutes les facettes du « progrès technologique » ? Il est ainsi bien étrange de la part d’un sociologue de considérer qu’il est des évolutions sociales et technologiques qu’il ne serait pas possible de contester, comme si celles-ci étaient inéluctables et naturelles – en dirait-on tout autant des inégalités de genres, de races ou de classes ?
Spécial Palestine et Israël
- Attaque israélienne à Doha : pour la première fois, un pays médiateur touché (rfi.fr)
Les bombardements de l’aviation israélienne ce mardi 9 septembre à Doha sont une première. Ces dernières années, des frappes israéliennes ont tué des responsables du Hamas palestinien dans plusieurs pays de la région. Cette fois, c’est sur le sol du Qatar, monarchie du golfe Persique qui héberge de longue date les dirigeants du Hamas en exil tout en œuvrant à la médiation avec Israël.
- Le Yémen, nouvelle frontière israélienne (orientxxi.info)
Le jeudi 28 août, à la suite de multiples menaces proférées ces derniers mois, une frappe aérienne israélienne décime le gouvernement nommé par les houthistes à Sanaa. Au moins douze dignitaires sont assassinés, notamment le premier ministre, Ahmed Al-Rahawi, le ministre des affaires étrangères, Jamal Ahmed Amer, et huit autres ministres. Le ministre de la défense, Mohammed Al-Atifi, est également annoncé comme blessé.
- Israël impose une punition collective aux Palestiniens de Cisjordanie (agencemediapalestine.fr)
Après une fusillade meurtrière dans Jérusalem-Est occupée, Israël ordonne la démolition des maisons des suspects en Cisjordanie occupée et la révocation des permis de travail de leurs voisins.
- À Gaza-ville, Benjamin Netanyahu donne un ultimatum aux habitant·es et promet d’encore intensifier l’offensive (huffingtonpost.fr)
« Vous avez été prévenus, partez maintenant ! », a déclaré le Premier ministre israélien, affirmant que l’intensification des opérations à Gaza-ville n’en était qu’à leur « début ».
- « Il n’y aura pas d’État palestinien, cet endroit nous appartient » : Benyamin Netanyahou assume son projet d’annexion (humanite.fr)
Benyamin Netanyahou a ouvertement assumé, jeudi 11 septembre, sa volonté d’annexer la Palestine, lors d’une cérémonie de signature d’un important projet de colonisation en Cisjordanie occupée
- 64 700 mort·es et de 164 000 blessé·es à Gaza : l’ex-chef d’état-major de l’armée israélienne reconnaît le bilan du ministère de la Santé du Hamas (humanite.fr)
- US senators say ‘America complicit’ in ethnic cleansing of Palestinians after Israel visit (middleeasteye.net) Two US lawmakers filed a report saying Israel is committing ethnic cleansing in Gaza and the occupied West Bank
- La flottille vers Gaza attaquée cette nuit ? La garde nationale tunisienne enquête (huffingtonpost.fr)
Un bateau de la « Global Sumud Flotilla » a été la cible d’une « attaque de drone », affirment les militant·es qui se dirigent vers l’enclave palestinienne.
- L’Espagne interdit l’entrée de son territoire à deux ministres israéliens d’extrême droite (franceinfo.fr)
- Après l’Espagne, un autre pays menace de se retirer de l’Eurovision si Israël participe (huffingtonpost.fr)
La présence de l’État hébreu est contestée alors que l’offensive à Gaza se poursuit, faisant des dizaines de milliers de morts.
Spécial femmes dans le monde
- Au Kenya, les féminicides sont devenus un fléau (afriquexxi.info)
L’absence de statistiques fiables et de stratégie cohérente pour lutter contre les féminicides au Kenya a laissé place à une culture d’insécurité quotidienne pour les femmes dans le pays.
- En Autriche, trois nonnes fuient un Ehpad (france24.com)
En Autriche, trois sœurs octogénaires se sont évadées d’un Ehpad et ont regagné le couvent qu’elles occupaient pendant quelques années près de Salzbourg. Les religieuses ont reçu l’aide d’anciens élèves du pensionnat et de villageois sensibilisés à leur cause.
- Le contenu de la lettre attribuée à Donald Trump à l’attention de Jeffrey Epstein dévoilé (huffingtonpost.fr)
Le président américain avait démenti l’existence de cette lettre en juillet, en pleine polémique sur ses liens avec le délinquant sexuel.
- Donald Trump va devoir verser une somme astronomique à E. Jean Carroll (huffingtonpost.fr)
Une cour d’appel de New York confirme la condamnation du président des États-Unis à verser plus de 80 millions de dollars à l’autrice pour diffamation.
- Dans « The Vampire Diaries », l’actrice principale n’a jamais reçu le même salaire que ses co-stars masculines (huffingtonpost.fr)
- Women’s suffrage is apparently up for debate again in America (theguardian.com) You’d be forgiven for assuming this particular issue was sorted out quite a long time ago. But, because we live in hell, it seems the question is once again up for debate.Not by women, though ; the fairer sex is obviously too emotional for such muscular discussion. So please sit this one out, ladies, and listen to what America’s finest male intellectuals have to say.
- Sur TikTok, le masculinisme à portée de scroll : jusqu’où l’algorithme peut-il emmener les ados ? (rtbf.be)
- A single bout of resistance or high-intensity interval training increases anti-cancer myokines and suppresses cancer cell growth in vitro in survivors of breast cancer (pubmed.ncbi.nlm.nih.gov)
This highlights the importance of exercise as a treatment with promising anti-cancer effects.
Spécial France
- Eramet : pourquoi le fonds souverain norvégien exclut l’entreprise française de son portefeuille ? (humanite.fr)
Le fonds souverain norvégien a décidé vendredi d’exclure le groupe minier français Eramet de son portefeuille, invoquant des risques de violations des droits des populations autochtones et des dommages environnementaux liés aux activités d’une mine de nickel en Indonésie.
- Mégabassines : la France recadrée par un rapporteur de l’ONU (reporterre.net)
Un rapporteur de l’ONU qui prend la plume pour défendre une petite association du Poitou, voilà un soutien que les adeptes de l’agro-industrie n’ont sûrement pas vu venir. L’Association de protection d’information et d’étude de l’eau et de son environnement (Apieee) pourrait ainsi être reconnue victime de discriminations en infraction avec le droit international.
- Dette publique : l’agence de notation Fitch dégrade la note de la France (humanite.fr)
L’agence de notation sanctionne l’instabilité politique et le déficit budgétaire, en faisant passer la note française de AA- à A +.
- À l’Assemblée, Bayrou victime d’obsolescence programmée (politis.fr)
Le premier ministre a perdu très logiquement le vote de confiance qu’il avait lui-même sollicité. Il tombe après s’être défendu sans conviction devant une Assemblée nationale qui pensait déjà à la suite.
Voir aussi Vote de confiance : “le score est inattendu”, vos députés ont-ils voté la chute de François Bayrou ? (france3-regions.franceinfo.fr) et Chute du gouvernement Bayrou : ce qu’ont voté les députés, groupe par groupe (lemonde.fr)

- Loi Duplomb : enfin un débat à l’Assemblée nationale (reporterre.net)
- « On a bouffé des terres » : les résidences secondaires, un gouffre écologique et social (reporterre.net)
De plus en plus de villes touristiques interdisent la construction de résidences secondaires.
- Un écoscore sur les vêtements instauré dès le 1er octobre, malgré plusieurs années de pression de l’industrie du textile (humanite.fr)
Le coût environnemental de nos vêtements pourra être affiché de façon claire et lisible dès le 1er octobre. Le décret a été publié au Journal Officiel le 9 septembre, après le feu vert de la Commission européenne en mai et l’aval du Conseil d’Etat.[…] Comme le nutriscore, il reste pour le moment facultatif.
- “Quand on a trouvé cette piste, on l’a gardée”, en mal de logement, ces étudiants ont choisi de vivre au camping (france3-regions.franceinfo.fr)
- Un·e salarié·e tombant malade pendant ses vacances pourra désormais reporter ses congés payés, tranche la Cour de cassation (franceinfo.fr)
À condition que “l’arrêt-maladie soit notifié par le salarié à son employeur”, le travailleur peut demander un tel report “puisque la maladie l’empêche de se reposer”, selon la Cour de cassation.
- Congés reportés lors d’un arrêt maladie : la CPME demande à Sébastien Lecornu de “défendre” les entreprises françaises (franceinfo.fr)
Face à la réglementation européenne, la Confédération des petites et moyennes entreprises demande au nouveau Premier ministre de prendre des mesures afin d’éviter une situation critique pour les employeurs.
- Trains de nuit : “on se dit qu’on est invisible”, les personnes en fauteuil roulant restent à quai (france3-regions.franceinfo.fr)
Alors que le retour du train de nuit est plébicité en France, les personnes à mobilités réduites regrettent d’en être exclus. Avec un fauteuil roulant, impossible de monter dans l’un des wagons qui permet de voyager de dormir en voyageant.
Spécial femmes en France
- Les mémoires de Gisèle Pelicot seront publiées début 2026 (telerama.fr)
Gisèle Pelicot publiera ses mémoires en février 2026 sous le titre “Et la joie de vivre” aux éditions Flammarion, qui précisent qu’elle racontera “son histoire avec ses propres mots”.
- Judith Godrèche, désabusée après sa mise en examen, a hâte d’affronter Jacques Doillon (huffingtonpost.fr)
« D’un côté, ma plainte contre lui se heurte à la prescription. De l’autre, pour sa plainte contre moi, la justice ne perd pas de temps », affirme-t-elle sur Instagram, avant de lancer : « À votre avis, ça encouragera les victimes à dénoncer les violences qu’elles ont subies, ou ça les dissuadera ? ».
Voir aussi Judith Godrèche dit son incompréhension après sa mise en examen pour diffamation envers Jacques Doillon (telerama.fr)
Si cette mise en examen résulte d’une procédure automatique, comme dans toute affaire de diffamation, la comédienne s’est émue ce mercredi, sur Instagram, que ce mécanisme judiciaire puisse dissuader les victimes de témoigner.
- « S’aimer n’est pas un crime ! » le déchirant hommage de Christine, la compagne de Caroline Grandjean (actu.fr)
- Féminicide. “Tout ce que ma fille a pu dire n’a pas été pris au sérieux” : après le meurtre d’Inès, sa famille dénonce l’inaction des autorités (france3-regions.franceinfo.fr)
“Elle a toujours donné toute sa vie pour l’associatif. Elle faisait partie d’une association qui s’appelle Buddy System, c’est là qu’elle a rencontré ce monsieur. Elle donnait des cours de français, elle aidait à l’insertion, pour les papiers… Vraiment, elle se donnait corps et âme pour ces associations” […] “Dès qu’il faisait quelque chose, dans la foulée, elle portait plainte. Entre le 10 juillet et le 28 août 2025, elle a déposé 6 plaintes pour viol et agression, pour violence physique, pour harcèlement, menaces de mort, dégradations… Elle était quasiment toutes les semaines au commissariat pour déposer plainte” […] Il l’a pistée samedi 6 septembre toute l’après-midi. Elle a eu peur et s’est réfugié dans les magasins. Là, elle a pu appeler les secours. La police est venue et ont embarqué l’homme, mais trente minutes après elle l’a recroisé dans la rue, il était déjà sorti !
Spécial médias et pouvoir
- « Le 20h de France 2, en passe de gagner le concours du journal le plus réactionnaire » (acrimed.org)
- Affaire Thomas Legrand : le journalisme politique malade de son corporatisme (acrimed.org)
- Le Parisien bientôt vendu à Vincent Bolloré ? Les journalistes du groupe s’y opposent fermement (huffingtonpost.fr)
Les journalistes du Parisien ont écrit une lettre ouverte à Bernard Arnault, propriétaire du journal depuis 2015, l’appelant à « renoncer » à une possible vente du quotidien à Vincent Bolloré.
- Pierre-Édouard Stérin restructure son empire et cible au passage le journaliste qui a révélé ses visées politiques (multinationales.org)
Durant l’été, le milliardaire Pierre-Édouard Stérin a créé une holding baptisée du nom du journaliste qui a révélé l’existence du projet Périclès, Thomas Lemahieu, où il a placé l’essentiel de sa fortune. Provocation, étalage de son sentiment d’impunité, ou hommage du vice à la vertu ?
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Sébastien Lecornu Premier ministre : Macron en défense (liberation.fr)
Son arrivée à Matignon révèle qu’Emmanuel Macron manque décidément d’oxygène. Face à la crise, il se recroqueville dans un espace politique qui, chaque jour, ressemble de plus en plus à une cabine téléphonique.

- Chasse, ZAD, nucléaire : qui est Sébastien Lecornu, le nouveau Premier ministre ? (reporterre.net)
- Qui est Sébastien Lecornu, nouveau pantin fade de Macron ? (frustrationmagazine.fr)
Terrifié par l’approche du 10 septembre, Bayrou a préféré se suicider politiquement. Sa longue et pitoyable carrière politique se termine donc, comme il en avait toujours rêvé, par une entrée dans l’Histoire : il est le premier Premier ministre de la Ve République à perdre son vote de confiance.
- Sébastien Lecornu : les souvenirs amers des Outre-mer (politis.fr)
Entre 2020 et 2022, le nouveau premier ministre était chargé du portefeuille des territoires ultramarins. Son passage rue Oudinot a nourri griefs et amertumes, notamment en Kanaky-Nouvelle-Calédonie.
- Le gouvernement bloque au dernier moment un plan pour réduire la consommation de viande des Français (lavoixdunord.fr)
La Stratégie nationale pour l’alimentation a été bloquée par les services du Premier ministre juste avant le vote de confiance de ce lundi. Sa publication était pourtant prête, après des mois de négociations.
- Juste avant de partir, François Bayrou a enchaîné les décisions anti-écologiques (reporterre.net)
- Avec la chute de François Bayrou, tous ces dossiers législatifs qui vont tomber à l’eau (huffingtonpost.fr)
Même sans dissolution de l’Assemblée nationale, la chute du gouvernement Bayrou a des conséquences sur certains textes législatifs, sur le plan calendaire mais pas uniquement.
- Indemnité, garde du corps, chauffeur… ces avantages que vont conserver Bayrou et ses ministres (ledauphine.com)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- « Pour Macron, les manifestations ne sont plus une expression de la démocratie » (politis.fr)
- Chute de Bayrou : « Un épisode de plus dans la dérive antidémocratique du macronisme » (reporterre.net)
- Laurent Mauduit : « Entre les patrons et l’extrême droite, ce ne sont plus des passerelles, mais de la porosité » (alternatives-economiques.fr)
- Après la chute de Bayrou, les plans du Rassemblement national (streetpress.com)
- Les images impressionnantes d’un immeuble en feu au cœur de Paris pendant le 10-septembre (huffingtonpost.fr)
Des manifestants ont scandé « bravo la police ! », selon des images filmées par l’AFP, et ont accusé les forces de l’ordre d’avoir lancé une grenade de gaz lacrymogène en direction du restaurant après une charge policière.
- « J’ai le droit de prendre un café ! » : Danielle Simonnet expulsée d’un café par la Brav-M (huffingtonpost.fr)
La députée du NFP Danielle Simonnet a été sortie d’un café ce mercredi 10 septembre à Paris, après s’y être réfugiée dans le cadre des mobilisations.
- Extinction Rebellion : « On nous réprime alors qu’on est juste des personnes lambda » (politis.fr)
Pour avoir participé à une action en 2023 qui visait à dénoncer l’implication de la BNP Paribas dans l’énergie fossile, plusieurs militant·es d’Extinction Rebellion passent en procès ce vendredi 12 septembre. Une procédure judiciaire qui s’inscrit dans une vague de répression toujours plus importante.
- Gabriel Pontonnier, mutilé par une grenade du maintien de l’ordre (index.ngo)
Le 24 novembre 2018, lors de l’acte II des gilets jaunes à Paris, Gabriel Pontonnier a été grièvement blessé à la main par l’explosion d’une grenade GLI-F4. Près de sept ans après les faits, le procès du policier qui a lancé la grenade s’ouvrira le 11 septembre 2025.

- 10 septembre : l’extrême droite radicale en embuscade (streetpress.com)
Alors que l’extrême droite radicale a vécu comme un traumatisme son expulsion du mouvement des Gilets jaunes, ils ont été peu visibles lors du 10 septembre. À Paris, Némésis a fait un de leurs habituels happenings. À Lyon, des lycéen·nes ont été attaqué·es.
- Attaque au couteau à Antibes : l’agresseur donnait des signes de radicalisation et avait été signalé à la préfecture (francebleu.fr)
La PJJ avait signalé récemment son cas au comité de prévention de radicalisation de la préfecture, à cause de signes de radicalisation et de sa fascination pour les tueries de masse et l’extrême droite. […] L’adolescent avait déjà été mis en examen et placé en détention en avril 2024 pour “participation à une association de malfaiteurs en vue de la préparation d’un crime, en l’espèce des assassinats, et d’apologie publique de crime ou délit”
- Un ex-policier de la brigade des mineurs de Marseille condamné à quinze ans pour viols d’enfants et détention de fichiers pédopornographiques (lemonde.fr)
La peine prononcée par la cour criminelle des Bouches-du-Rhône est assortie d’une période de sûreté de dix ans, d’un suivi sociojudiciaire de dix ans avec obligation de soins et d’une interdiction d’exercer en tant que policier ou de faire tout métier ou action bénévole au contact de mineurs.
- Surpopulation carcérale : les proches toujours plus inaccessibles (blogs.mediapart.fr)
Spécial résistances
- Le mouvement du 10 septembre a déjà gagné (frustrationmagazine.fr)
“J’ai fait ça parce qu’il était en train de se passer dans le pays quelque chose dont j’ai conclu que ce mouvement m’empêcherait à coup sûr de conduire la politique nécessaire pour le pays”. Voici la “vérité” que l’éphémère premier ministre François Bayrou est venu apporter aux journalistes de l’émission C à vous le samedi 6 septembre.
- Bye bye Bayrou, Macron, et leur monde (contretemps.eu)
- 11 000 personnes ont fêté le départ de Bayrou partout en France (reporterre.net)
- Au « pot de départ » de François Bayrou, on réclame déjà celui d’Emmanuel Macron (huffingtonpost.fr)
À Paris, Lyon, Marseille ou encore Rennes, des centaines de manifestant·es ont festoyé dans les rues après l’annonce de la chute du gouvernement.
- « Bloquons tout » : de Lille à Toulouse, une journée de colère (reporterre.net)
« Bloquons tout ». Ce mot d’ordre lancé pour le 10 septembre a rassemblé 175 000 participants pour 812 actions partout en France, selon le ministère de l’Intérieur. La CGT évoque de son côté 250 000 personnes pour 200 rassemblements et manifestations.

- Campus mobilisés, lycées bloqués : la jeunesse en première ligne du mouvement du 10 septembre (basta.media)
- « J’en ai marre de galérer » : avec les travailleurs et étudiants précaires réunis pour « tout bloquer » (streetpress.com)
- Antivalidistes contre la politique d’austérité et la violence d’État (blogs.mediapart.fr)
Les Dévalideuses soutiennent la mobilisation sociale de septembre 2025 (grèves, manifestations, actions locales) contre la cure d’austérité en cours et annoncée. La société que l’on nous dessine est toujours plus violente, toujours plus à la charge des plus vulnérables. La destruction des services publics crée des classes segmentées dans la société.
- Trans pédés gouines dans la rue le 10 septembre ! Construire un mouvement autonome, unifier la classe (contretemps.eu)
- Manifestant·es, interpellations : ce que l’on sait (ou non) du bilan du 10-septembre (huffingtonpost.fr)
- « Militant LGBT, je retire ma plainte contre le policier qui m’a éborgné » (mouais.org)
Non, la police n’est pas l’alliée des personnes LGBT et, non, la Justice ne peut rien lorsqu’un flic a décidé de « casser du pédé ». Ici, comme en Hongrie ou ailleurs, nous devrons nous battre en connaissance de ce fait. Refusant de persévérer dans l’illusion d’une procédure utile et équitable, je retire ma plainte.
Spécial outils de résistance
- Un autre budget est vital : l’argumentaire d’Attac (france.attac.org)
- « Bloquons tout » : cinq chiffres qui montrent l’explosion des inégalités en France (vert.eco)
- Pour en finir avec les exagérations sur la dette de l’État, avec ou sans Bayrou (basta.media)
Décryptage du débat sur la dette, entre comparaison erronée avec l’endettement des ménages, discours fallacieux sur l’ardoise laissée aux générations futures et dépenses publiques rendues injustement responsables du déficit.
- Tout comprendre à la taxe Zucman en trois minutes (alternatives-economiques.fr)
Le gouvernement Bayrou est tombé avec son budget. La taxation des ultrariches, à laquelle il se refusait, va immanquablement être portée par la gauche et revenir dans le débat. En quoi consisterait-elle ?
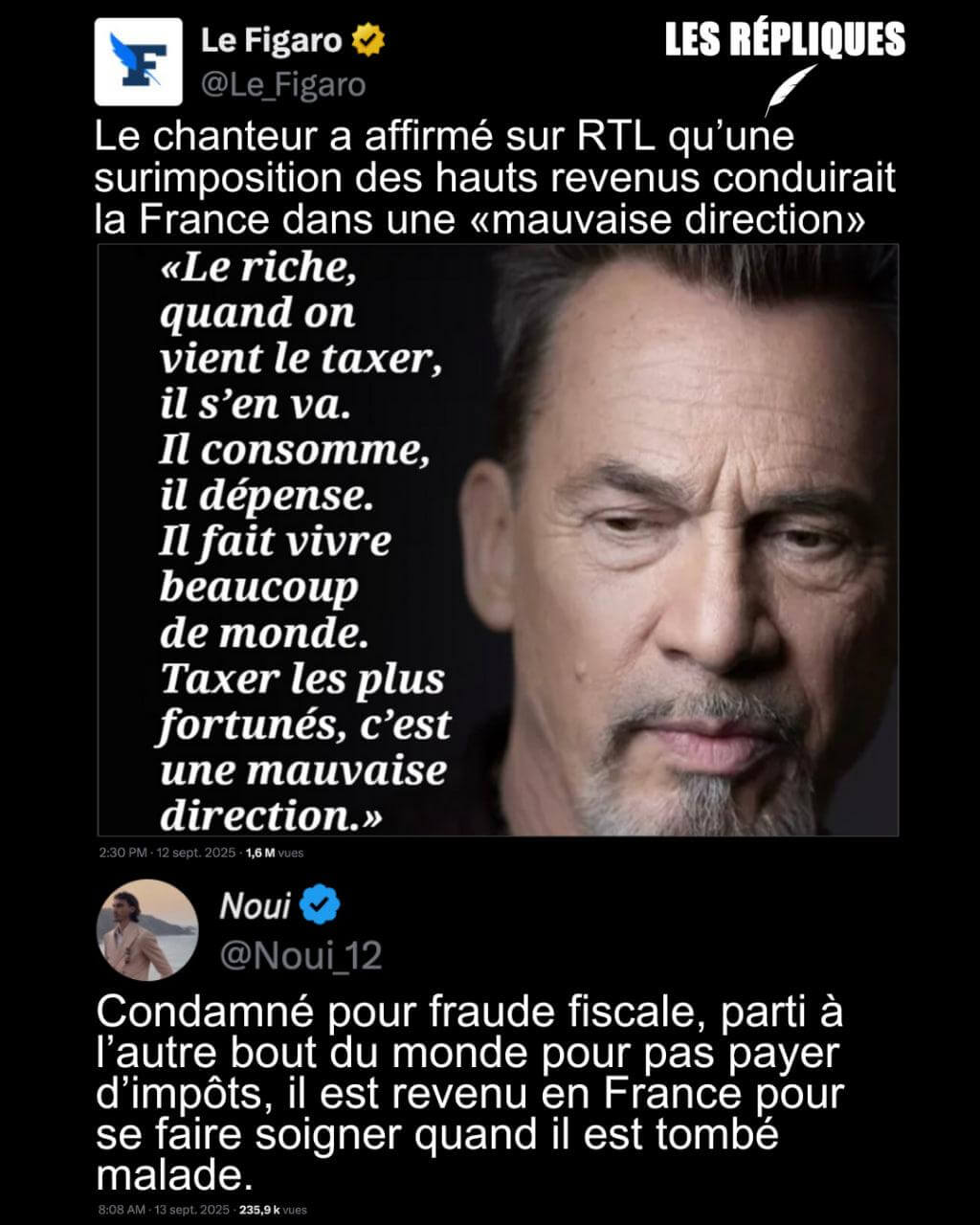
- Comment démonter les mensonges du pouvoir sur la dette (frustrationmagazine.fr)
- Du retour du « pognon de dingue » (humanite.fr)
Les transferts de la Sécurité sociale sont purement assimilés à des versements de l’État, en contradiction totale avec l’esprit de la Sécu voulue par Laroque et Croizat. […] une bonne part du « pognon de dingue » d’Emmanuel Macron est notre pognon et nous ne serions des dingues que si nous renoncions à le voir reconnaître comme tel.
- La révolution sera culturelle ou ne sera pas (politis.fr)
Dans un essai dessiné, Blanche Sabbah analyse la progression des idées réactionnaires dans les médias. Loin de souscrire à la thèse de la fatalité, l’autrice invite la gauche à réinvestir le champ des idées.
- Nourrir les grèves, mode d’emploi (reporterre.net)
Spécial GAFAM et cie
- Defending an open web : What the Google search ruling means for the future (blog.mozilla.org)
- Whistle-Blower Sues Meta Over Claims of WhatsApp Security Flaws (yro.slashdot.org)
The former head of security for WhatsApp filed a lawsuit on Monday accusing Meta of ignoring major security and privacy flaws that put billions of the messaging app’s users at risk, the latest in a string of whistle-blower allegations against the social media giant.
- Microsoft, OpenAI reach non-binding deal to allow OpenAI to restructure (reuters.com)
- Indigenous group in Brazil takes TikTok to court over planned data center (restofworld.org)
The Anacé Indigenous community is going to court to stop a planned TikTok data center they say is being built on their land.
- David Chavalarias, spécialiste des réseaux sociaux : « X continue de contaminer la société » (vert.eco)
l’augmentation de la part de personnes qui ne croient pas à un réchauffement climatique d’origine humaine (+5 % entre 2019 et 2023) s’est accompagnée « d’une [hausse] très significative de l’activisme climatosceptique sur Twitter/X depuis l’été 2022, et d’une hostilité accrue envers les climatologues ». Entre 2019 et 2023, la France est même le pays où le nombre de personnes qui nient le consensus scientifique sur le climat a le plus augmenté (de 63 % à 71 %) parmi les 30 États étudiés sur les cinq continents.
Les autres lectures de la semaine
- Atlas « Cartographier l’anthropocène » (ign.fr) – Édition 2025 : Inondations : des data pour faire barrage (ign.fr)
- L’écologie de la carte bleue (blogs.mediapart.fr)
La « naissance » du consommateur a servi à deux choses : écouler le surplus de marchandises produites par le capitalisme, et réintégrer les gens dans les rapports marchands sur leur temps de loisir, fraîchement arraché par des luttes sociales […] la « consommation » a étendu le travail sur le temps de loisir, de sorte que nous continuons à travailler au bon fonctionnement de l’économie une fois sorti du bureau ou de l’usine.
- Wallet voting (pluralistic.net) You cannot vote with your wallet. Or rather, you can, but you will lose that vote. Wallet-votes always go to the people with the thickest wallets, and statistically, that is not you.
- Ces blocages qui ont fait trembler le pouvoir (reporterre.net)
- Pourquoi notre voix change-t-elle quand on parle une langue étrangère ? (ouest-france.fr)
- L’expression « culture du viol » est-elle exagérée ? (theconversation.com)
Les BDs/graphiques/photos de la semaine
- Trempe
- Déguisement
- Nouveautés
- Clarifier
- Message
- Fraude
- Récit
- Falloir
- Tout bloquer
- Shooter
- ED
- Quotes
- Bansky
- Remember
- Alt text
- Alone
{kind=link}
{kind=link}
{kind=link}
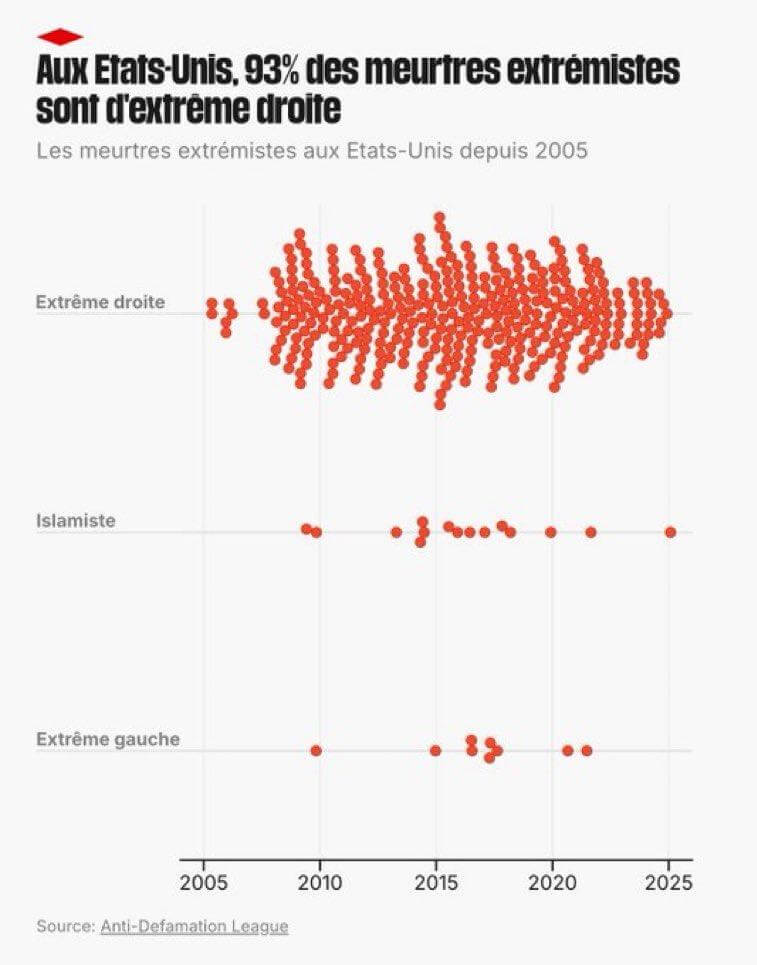{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- “Les milliardaires français paient peu, voire pas du tout, d’impôt sur le revenu”, démontre l’économiste Gabriel Zucman, invité du “20 heures” de France 2 (franceinfo.fr)

- Chapoutot sur la midinale de regards.fr (tube.fdn.fr)
- Manon Bril : ça veut dire quoi, “Français de souche” ? (à propos des salades de fruits) (tube.fdn.fr)
- Minuit dans le siècle : Militer contre le fascisme : pourquoi et comment ? (minuit-dans-le-siecle.castos.com)
- The Daily Show : Climate Change for Dummies (tube.fdn.fr)
- Every company with AI (Eleanor Morton) (tube.fdn.fr)
- Humain·es vs oiseaux (tube.fdn.fr)
- Mères isolées sous surveillance (radiofrance.fr)
Marion et Sarah, toutes deux mères isolées, dévoilent, à partir de leur expérience, un vaste système de surveillance et de contrôle des plus précaires.
- H24 – 24 heures dans la vie d’une femme (arte.tv – disponible jusqu’au 21/10/2026)
- Dans La Chair est triste hélas, Ovidie raconte comment, il y a quelques années, par dégoût et lassitude, elle en est venue à arrêter de coucher avec les hommes. (radiofrance.fr)
Arrêter le sexe avec les hommes, ce n’est pas juste arrêter le coït, c’est arrêter tout ce que cela implique d’être une femme et de constamment lutter pour rester désirable. C’est un boulot à temps plein que d’être un sexe à convoiter
- « Avoir raison avec… bell hooks » – série en 5 épisodes (radiofrance.fr)
- Au-delà de l’atome (radiofrance.fr)
LSD plonge dans l’infiniment petit. Si le mot “infini” nous stoppe dans un vertige, du plus profond de nous aux confins de l’espace, quelque chose se touche.
Les trucs chouettes de la semaine
- Jean-Marie Séguret, DSI de Lyon : « se soustraire de Microsoft impose un travail de fond » (cio-online.com)
Dans la lignée d’une politique municipale faisant la part belle à la sobriété et à la souveraineté, la DSI de la ville de Lyon déploie une stratégie visant à renforcer son indépendance. Avec un projet phare : le remplacement de Microsoft Office sur 80 % des postes d’ici mars 2026.
- L’Open Source pour rééquilibrer les relations transatlantiques dans le numérique ? (io-online.com)
La Linux Foundation Europe souligne les atouts de l’Open Source pour un continent cherchant à gagner en indépendance par rapport à la technologie américaine. À condition toutefois d’investir pour ne plus seulement être des consommateurs passifs de logiciels libres.
- Une ferme collective cultivée par trois couples : une riche idée face à la solitude des agriculteurices (france3-regions.franceinfo.fr)
- La RH envoie un refus commun à 340 candidates, iels en rient et se donnent rendez-vous au bar (ouest-france.fr)
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
08.09.2025 à 07:42
Khrys’presso du lundi 8 septembre 2025
Khrys
Texte intégral (9190 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Poutine, Xi, Modi et le pacte de Tianjin. Texte intégral de la déclaration des pays de l’OCS (legrandcontinent.eu)
La Chine est en train de redessiner la carte de l’Asie. Face à Trump et à l’Europe, elle appelle à « réformer l’ONU ».

- « Il pourrait être possible de vivre jusqu’à 150 ans », quand Xi et Poutine échangent sur l’immortalité (nouvelobs.com)
Les dirigeants chinois et russe, tous deux âgés de 72 ans, sont à la tête de leur pays depuis respectivement environ 12 et 20 ans, cumulés. Aucun n’a manifesté son intention de quitter le pouvoir ou signaler un potentiel successeur politique.
- La Chine concentre plus des deux-tiers des caméras de surveillance installées dans le monde (legrandcontinent.eu)
Avec 700 millions de caméras de surveillance, la Chine compte près d’une caméra pour deux habitant·es. En plus de subvenir aux besoins de leur marché domestique, les entreprises chinoises spécialisées dans la sécurité dominent le marché global, et équipent désormais des sites sensibles dans plusieurs pays européens.
- China’s chip startups are racing to replace Nvidia (restofworld.org)
Tapping investor interest and ex-Nvidia talent, China’s AI chipmakers are seizing openings created by U.S. export controls.
- Comment le visage de Luigi Mangione s’est retrouvé sur le site de Shein (huffingtonpost.fr)
Le visuel a été rapidement supprimé par l’entreprise chinoise de fast-fashion. Difficile de savoir qui en est à l’origine.
- L’Indonésie en révolte face aux violences policières (theconversation.com)
La mort d’Affan Kurniawan, jeune chauffeur de moto-taxi écrasé le 28 août par un véhicule de police, lors d’une manifestation à Jakarta, a enflammé la contestation déjà virulente en Indonésie. Dans la rue comme sur les réseaux sociaux, la colère vise une institution policière, accusée de corruption et de violence, qui apparaît comme un outil destiné à protéger les élites plutôt que les simples citoyen·nes.
- Deadly M6 earthquake strikes northeastern Afghanistan (open.substack.com)
Thirteen minutes before midnight on August 31, 2025, a magnitude 6 earthquake struck northeastern Afghanistan. Damage to nearby villages was severe, and many houses collapsed into piles of debris that trapped sleeping residents. News reports indicate that more than 800 people have been killed, a number that is expected to rise. Making matters worse, the earthquake triggered landslides that blocked roads, hindering rescue efforts.
- Soudan : plus d’un millier de morts dans un glissement de terrain qui a décimé un village du Darfour (lemonde.fr)
L’éboulement, qui a eu lieu dimanche, a frappé le village de Tarasin et « a complètement détruit » la zone située dans le djebel Marra, d’après un groupe armé contrôlant la région.
- Burkina Faso’s parliament votes to outlaw homosexual acts (bbc.com)
Burkina Faso’s unelected transitional parliament has passed a bill banning homosexual acts, a little over a year after a draft of an amended family code that criminalised homosexuality was adopted by the country’s cabinet.
- En plein vol, l’avion de Von der Leyen privé de ses systèmes de navigation par une attaque attribuée à la Russie (liberation.fr)
- Malgré les retards, la Suisse ne renoncera pas aux drones israéliens ADS15 (rts.ch)
Le Département fédéral de la défense renonce ainsi à trois fonctionnalités initialement garanties par le fabricant. Les drones ne sont pas équipés du système d’évitement automatique, du système de dégivrage, ni du système de décollage et d’atterrissage indépendant du GPS. Concrètement, les drones voleront accompagnés d’une escorte dans l’espace aérien non contrôlé. Et ce jusqu’à 3000 mètres d’altitude au-dessus du Plateau et jusqu’à 4000 mètres au-dessus des régions alpines. Ils pourront naviguer sans restriction dans l’espace aérien contrôlé. La nuit, les drones pourront être utilisés partout sans escorte.
- Le Portugal est en deuil. (huffingtonpost.fr)
L’un des funiculaires emblématiques de Lisbonne a déraillé et s’est encastré dans un immeuble au bas d’une pente, ce mercredi 3 septembre au soir, dans un quartier très touristique du centre-ville. L’accident a fait au moins quinze morts et une dizaine de blessés, dont une Française, d’après le premier bilan provisoire des autorités.
- VIH : un nouveau traitement préventif autorisé en Europe (politis.fr)
Un nouveau traitement préventif contre le VIH, le Yeytuo, est autorisé depuis fin août par la Commission européenne. Pour les personnes qui ne sont pas infectées mais exposées, le médicament est efficace à plus de 99 % contre le développement de la maladie. Le laboratoire a promis deux millions de doses génériques à prix coûtant pour une centaine de pays en développement.
- Le nouveau parti de gauche britannique pourrait s’avérer dévastateur pour le Labour (contretemps.eu)
Jeremy Corbyn et Zarah Sultana ont annoncé cet été la création d’un nouveau parti de gauche, qui a suscité immédiatement un énorme enthousiasme parmi toutes celles et ceux qui, en Grande-Bretagne, aspirent à une rupture avec le statu quo néolibéral, impérialiste et raciste.
- Comment l’accord avec les États-Unis sape les avancées environnementales européennes (basta.media)
L’accord sur les droits de douane conclu cet été entre l’Europe et les États-Unis remet en cause les mesures environnementales mises en place par l’UE ces dernières années, alerte Stéphanie Kpenou, de l’Institut Veblen.
- États-Unis : quand la lutte antimigrant·es s’arme de logiciels espions (france24.com)
Un contrat de deux millions de dollars a été conclu entre l’ICE […] et Paragon, éditeur sulfureux de logiciels espions ultraperfectionnés. Le bras armé de la politique antimigrants de Donald Trump aura ainsi accès à des outils similaires au célèbre Pegasus, logiciel au cœur d’un scandale impliquant la surveillance par onze États de journalistes et d’opposant·es politiques.
- Donald Trump va redonner au Pentagone son nom d’il y a 80 ans, et c’est tout un symbole (huffingtonpost.fr)
Le président des États-Unis va signer un décret pour changer le nom du « ministère de la Défense » en « ministère de la Guerre », qui existait jusqu’en 1947.
- Donald Trump se fait couvrir de louanges par tous les géants de la tech à la Maison Blanche, sauf Elon Musk (huffingtonpost.fr)
Le gratin de la tech continue de courtiser le président américain, prêt à tout pour échapper aux régulations et obtenir la protection du républicain.
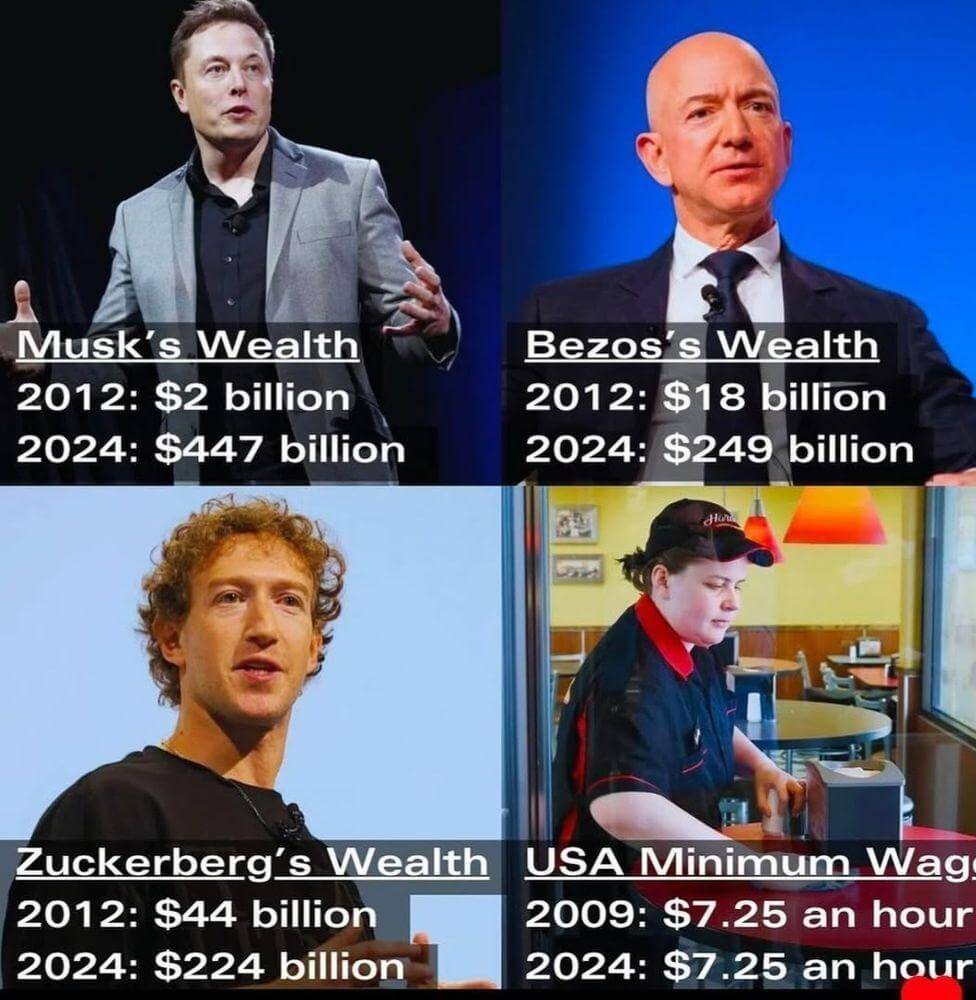
- Republican Says Radioactive Shrimp May Turn You Into Xenomorph (newsweek.com)
Louisiana Senator John Kennedy, a Republican, compared radioactive shrimp to the deadly extraterrestrial creatures from the Alien film franchise. His remarks came during a Senate hearing on water contamination, where he suggested that consuming tainted seafood could leave people resembling a Xenomorph.
- Chicago has the most lead pipes in the nation. We mapped them all. (grist.org)
- Limogé·es par l’administration Trump, des scientifiques lancent leur propre site d’information sur le climat (franceinfo.fr)
- 20 years after Katrina, New Orleans’ levees are sinking and short on money (grist.org)
The city’s $14 billion flood system faces new threats from climate change, land subsidence, and Trump budget cuts.
- The Great Hoax Against Venezuela : Oil Geopolitics Disguised As ‘War On Drugs’ (popularresistance.org)
Former UN anti-drugs agency director Pino Arlacchi dismantles the Venezuela “narco-state” narrative with 30 years of reliable data.
- Au Brésil, le procès de Bolsonaro fait déjà date (humanite.fr)
Quelle que soit la sentence – qui devrait tomber d’ici au 12 septembre –, ce procès est déjà historique. Jamais auparavant, les auteurs de putsch contre l’ordre démocratique et institutionnel n’avaient été traduits en justice. Pas même les dignitaires de la dictature militaire.
- L’effondrement de ce mégacourant océanique est beaucoup plus probable que prévu (usbeketrica.com)
Affaibli par le dérèglement climatique, l’AMOC aurait bien plus de chances de s’arrêter que prévu, avertit une nouvelle étude. Un événement littéralement glaçant puisqu’il pourrait faire chuter les températures en Europe jusqu’à –30 °C.
Spécial IA
- L’Europe inaugure Jupiter, son premier supercalculateur pour booster l’“IA” (france24.com)
L’Europe a inauguré vendredi son premier ordinateur géant et ultra-rapide nommé Jupiter, conçu par le groupe français Atos. Doté d’un budget de 500 millions d’euros partagé entre l’UE et Berlin, il vise à rattraper le retard pour l’entraînement de modèles d’“IA” et à soutenir la recherche scientifique, notamment sur le climat.
- New Jersey’s AI data centers face new water usage bill (newsbreak.com)
A single AI data center could consume 5 million gallons of water daily. New Jersey wants to make them report water consumption.

- AI web crawlers are destroying websites in their never-ending hunger for any and all content (theregister.com)
Yes, of course, we can try to fend them off with logins, paywalls, CAPTCHA challenges, and sophisticated anti-bot technologies. You know one thing AI is good at ? It’s getting around those walls.As for robots.txt files, the old-school way of blocking crawlers ? Many – most ? – AI crawlers simply ignore them.
- Les géants de la tech accusés du vol de millions de chansons pour entraîner leurs IA (telerama.fr)
- “First of its kind” AI settlement : Anthropic to pay authors $1.5 billion (arstechnica.com)
Anthropic agreed to pay $1.5 billion and destroy all copies of the books the AI company pirated to train its artificial intelligence models.
Voir aussi La start-up américaine d’intelligence artificielle Anthropic va verser 1,5 milliard de dollars pour avoir téléchargé illégalement des millions de livres (franceinfo.fr)
Cette transaction permet à Anthropic d’éviter un procès, qui devait démarrer début décembre pour déterminer le montant des dommages et intérêts. La start-up risquait d’être condamnée à débourser une somme bien supérieure à celle décidée avec les détenteurs de droit, au point de mettre en péril son existence même.
- AI Generated ‘Boring History’ Videos Are Flooding YouTube, Drowning Out Real History (news.slashdot.org)
- Humans are being hired to make AI slop look less sloppy (nbcnews.com)
In the age of automation, human workers are being brought in to fix what artificial intelligence gets wrong.
- Behind Every “Smart” AI Tool Lies a Human Cleaning Up Its Chaos (economictimes.indiatimes.com)
As artificial intelligence platforms flood the internet with “sloppy” output, a growing number of human workers are being called upon to fix AI’s errors, from clunky code to cringe-worthy art. Once viewed as targets for automation, creative professionals and freelancers now find their livelihoods unexpectedly dependent on cleaning up after the very machines once poised to replace them. This emerging economy reveals not only the limits of current AI, but also the hidden labour underpinning the polished digital Behind Every “Smart” AI Tool Lies a Human Cleaning Up Its Chaos, products we take for granted.
- Les IA spécialisées en revue de la littérature scientifique : des promesses douteuses (academia.hypotheses.org)
- Why AI Isn’t Ready to Be a Real Coder (spectrum.ieee.org)
The reason we have a programming language is because we need to be unambiguous. But right now, we’re trying to adjust the prompt [in a way] that the tool will be able to understand. We’re adapting to the tool, so instead of the tool serving us, we’re serving the tool. And it is sometimes more work than just writing the code.
- ChatGPT-5 menace de faire imploser la bulle de l’IA générative (faketech.fr)
La sortie ratée de ChatGPT-5 pointe les limites de l’IA générative, qui serait devenue une bulle financière, selon la propre admission du PDG d’OpenAI.

- « Moins vous en savez sur l’IA, plus vous êtes susceptible de l’utiliser », d’après une étude selon laquelle l’IA peut sembler magique aux yeux de ceux qui ont peu de connaissances en la matière (developpez.com)
- Derrière les « émotions » des chatbots, l’inquiétant phénomène de « sycophantie » (huffingtonpost.fr)
La flatterie excessive des chatbots cache un dangereux engrenage, allant de l’addiction jusqu’à la « psychose » – et pour certaines entreprises, c’est une aubaine.
- OpenAI announces parental controls for ChatGPT after teen suicide lawsuit (arstechnica.com)
Spécial Palestine et Israël
- L’évacuation de Gaza-Ville, prélude aux « portes de l’enfer » (humanite.fr)
Ce 6 septembre, les habitants de la cité se sont vu imposer un énième ordre d’évacuation par Israël. Tel-Aviv tente de percer ce qu’elle présente comme la dernière poche de résistance du Hamas au moment où des négociations sont menées entre l’organisation islamiste et les États-Unis pour la libération des otages.
- La guerre à Gaza, un “génocide” pour Teresa Ribera : l’UE se désolidarise de sa commissaire (fr.euronews.com)
- Une couverture noire pour briser le silence (politis.fr)
Face à l’hécatombe de journalistes à Gaza et au silence qui l’entoure, des dizaines de rédactions à travers le monde – de Mediapart à Al Jazeera en passant par The Independent et Politis – s’unissent pour alerter : le droit d’informer est attaqué.
- De Marseille à Tunis, des flottilles pour briser le siège de Gaza (orientxxi.info)
Depuis le dimanche 31 août, plusieurs dizaines de bateaux sont partis des ports de Marseille, Barcelone, Gênes et enfin Tunis dans le cadre de la Global Sumud Flotilla. Cet élan massif vise à briser le blocus autour de l’enclave palestinienne qui subit famine et génocide. Il suscite un soutien international croissant.
- Des dizaines de bateaux voguent vers Gaza pour briser le blocus israélien illégal (lareleveetlapeste.fr)
Le 31 août, plus de 300 personnes ont pris la mer, depuis différents ports européens, pour rejoindre Gaza. A nouveau, la « Global Sumud Flotilla » va tenter de rompre le blocus imposé par Israël et apporter de l’aide humanitaire à la population gazaouie.
- L’actrice française Adèle Haenel rejoint la flottille Global Sumud pour Gaza depuis Tunis (fr.euronews.com)
- Besançon. Polémique liée à Gaza : annulation de la venue de Raphaël Enthoven au festival Livres dans la Boucle (estrepublicain.fr)
En cause : […] les propos tenus par le « philosophe’’ sur le réseau social X le 15 août dernier : « Il n’y a aucun journaliste à Gaza. Uniquement des tueurs, des combattants ou des preneurs d’otages avec une carte de presse ».
- Vuelta 2025 : la formation Israël-Premier Tech, doit-elle continuer la course ? (humanite.fr)
La Vuelta 2025 est perturbée depuis son retour en Espagne par de nombreuses actions menées par des manifestants pro-Palestine. Les plus marquantes sont survenues à Bilbao, mercredi dernier, et ont poussé les organisateurs à neutraliser l’étape. Face à cela est-il encore raisonnable de laisser courir l’équipe israélienne ?
- Conférence sur la solution à deux États à l’ONU : un nouveau pays va reconnaître la Palestine (humanite.fr)
À moins de trois semaines de la conférence à l’ONU où la France reconnaitra l’État de Palestine, la Finlande s’ajoute à la liste des pays se joignant au processus. Le gouvernement israélien et le secrétaire d’État américain Marco Rubio tentent de les en dissuader.
- « Reconnaître l’État de Palestine et surtout appliquer des sanctions pour que cesse le génocide » (humanite.fr)
Spécial femmes dans le monde
- À Taïwan,les femmes écrivent l’histoire (politis.fr)
Un mouvement politique taïwanais a appelé à destituer des élus considérés comme trop proches de la Chine. Une mobilisation majoritairement féminine, avec des volontaires s’engageant parfois politiquement pour la première fois.
- Séisme en Afghanistan : les secouristes ont aidé les hommes… mais pas les femmes (slate.fr)
Les normes culturelles afghanes, qui interdisent tout contact physique entre les hommes et les femmes qui n’appartiennent pas à la même famille, ont poussé les secouristes majoritairement masculins à ne pas venir en aide aux femmes.
- États-Unis : les femmes quittent massivement le marché du travail (lesnouvellesnews.fr)
Une étude pointe un « exode silencieux » des femmes qui renoncent à l’emploi outre-Atlantique. Baisse des salaires et coûts de garde des enfants élevés, fin de la flexibilité instaurée pendant la pandémie, IA supprimant des métiers féminisés, « bro-culture »…
- Affaire Epstein : plus de 30 000 pages liées au délinquant sexuel rendues publiques, mais il y a un hic (huffingtonpost.fr)
« 97 % des documents reçus du ministère de la Justice étaient déjà publics. Il n’y a aucune mention d’une liste de clients ou de quoi que ce soit qui améliore la transparence ou la justice pour les victimes. »
Voir aussi GOP Rep. Thomas Massie takes first step to force a vote on releasing the Epstein files (nbcnews.com)
- L’autrice de « La Servante écarlate » Margaret Atwood tacle la censure dans les écoles canadiennes, celle-ci est mise en pause (huffingtonpost.fr)
Au Canada, le ministère de l’Éducation de la province de l’Alberta avait annoncé le retrait d’œuvres littéraires des bibliothèques scolaires en raison de leur contenu sexuellement explicite. La Servante écarlate, roman culte adapté en série, fait partie du lot.
- À la ménopause, le risque cardiovasculaire pour les femmes augmente (theconversation.com)
les femmes restent encore aujourd’hui sous-représentées dans les études cliniques portant sur les maladies cardiovasculaires et cérébrovasculaires […] elles ne représentent qu’un tiers des participants dans les essais cliniques sur les AVC, ce qui limite la compréhension de cette pathologie chez elles et l’efficacité des stratégies de prévention et de traitement.
- Ils ont joué à la place des footballeuses et n’en reviennent pas de leur état (ma-grande-taille.com)
des footballeurs ont accepté de relever un défi inédit : jouer dans les mêmes conditions que celles imposées aux femmes footballeuses, avec un terrain adapté pour neutraliser les différences physiques. L’expérience a bouleversé leurs certitudes sur l’intensité et la difficulté du football dit féminin.
- Pour Sabrina Carpenter, Colman Domingo danse en drag-queen et fait taire les critiques (huffingtonpost.fr)
Il a même cité la célèbre drag-queen américaine RuPaul : « On naît nu et tout le reste, c’est du drag », en précisant que cette phrase vaut pour « les costumes, les t-shirts, les robes. Tout est du drag ».
- Golshifteh Faharani : « Le cinéma indépendant représente mieux les États-Unis que Trump » (humanite.fr)
Golshifteh Farahani préside cette semaine le jury du 51e festival du film américain de Deauville.[…]« Le mot « président » me fait trembler quand on voit ce que sont de nombreux présidents dans le monde : des fous. »
Spécial France
- Impôts : la nouvelle étude qui mesure les effets d’un retour de l’ISF (lesechos.fr)
En cas de hausse des impôts sur le patrimoine, l’expatriation des plus fortunés resterait faible et aurait un effet modeste sur l’économie nationale, conclut une étude du Conseil d’analyse économique. L’optimisation fiscale réduit davantage les recettes que les départs à l’étranger.
- Fuite de données massive : les informations médicales et privées de 2 millions de Français·es dans la nature (generation-nt.com)
Des bases de données contenant les informations de près de deux millions de Français·es sont actuellement en vente ou en accès libre sur un forum du dark web. Les entreprises Alain Afflelou, Syma Mobile et même le Service National Universel (SNU) seraient concernés. Ces fuites exposent des données parfois très sensibles, comme des informations médicales ou des pièces d’identité.
- La mode des tétines pour adultes inquiète la Fédération Française d’Orthodontie, qui se dit « abasourdie » (huffingtonpost.fr)
- « On nous prend pour des jambons » : dans les Pyrénées-Orientales, les oublié·es d’internet sont à bout (madeinperpignan.com)
- À Paris, la verbalisation dans la zone à trafic limité de l’hypercentre reportée à 2026 (lemonde.fr)
Dix mois après le lancement, sur un mode « pédagogique », de ce dispositif, la Mairie de Paris a signalé, jeudi, que ces « mois d’expérimentation » avaient « vu une baisse de 8 % du trafic routier dans la ZTL ».
- Dans les Bouches-du-Rhône et le Var, la rentrée décalée met les enfants en joie et les parents en stress (huffingtonpost.fr)
- « Le système s’effondre déjà » : l’échec de l’assurance privée pour les récoltes (reporterre.net)
Le nouveau système d’assurance-récolte « est déjà en train de s’effondrer », alerte le porte-parole de la Confédération paysanne. Censé aider les agriculteurices face aux risques climatiques, il ne couvre pas les incendies.
- À Toulouse, l’été sans accès à l’eau des oubliés de l’État (streetpress.com)
À Toulouse, où l’invisibilisation croissante des publics à la rue complique leur accès aux droits, de nombreux occupants de lieux de vie informels ont dû affronter les fortes chaleurs avec un accès à l’eau fortement restreint.
- « La montée des eaux ? Je n’ai pas le temps, je déjeune » : Au Cap-Ferret, les riches propriétaires en plein déni climatique (reporterre.net)
la canopée fond à vue d’œil. Les pins sont abattus pour éradiquer leurs épines si embêtantes. Le sable est remplacé par du gazon, pour ne plus en avoir plein les pieds. » À ses yeux, la commune s’est « disneylandisée » jusqu’à devenir une caricature : « Nous avions une presqu’île à vivre, ils en ont fait une presqu’île à vendre.
- De nouvelles centrales nucléaires ne sauveront pas le climat, dit un rapport (reporterre.net)
- Nucléaire : Greenpeace doit payer 30 000 euros pour être entrée dans une centrale (reporterre.net)
- Dans le Doubs, 27 agriculteurs ont arrêté les pesticides sur 4 000 ha pour protéger l’eau (lareleveetlapeste.fr)
Pour l’essentiel, les pratiques mises en place comprenaient la réimplantation de linéaires de haies, la rotation des cultures et l’allongement des rotations, ainsi que la réduction des intrants.
- Pour manger sans pesticides pendant la grossesse, des paniers bio prescrits aux femmes enceintes (basta.media)
Distribuer des paniers d’aliments garantis sans pesticides ni perturbateurs endocriniens pour les femmes enceintes. L’initiative de l’« ordonnance verte » née à Strasbourg a déjà convaincu une vingtaine de villes en France.
Spécial femmes en France
- Baccalauréat : ce que l’on sait de l’élève qui a eu son diplôme à 9 ans, un record de précocité (huffingtonpost.fr)
Une jeune fille née en 2015 a largement dépassé le précédent record d’obtention du bac cette année. Avant elle, le record de précocité revenait à un élève de 11 ans et 11 mois.
- Tests de féminité : les boxeuses françaises privées de championnats du monde, une situation « inadmissible » selon la ministre des sports (lemonde.fr)
Il n’y aura aucune concurrente tricolore pendant la compétition, qui se tiendra du 4 au 14 septembre à Liverpool. Les résultats des tests de féminité exigés par la fédération internationale n’ayant pas été transmis à temps.
- “Élue Miss France, je suis violée quelques heures plus tard” : les révélations chocs sur la “face cachée” du prestigieux concours de beauté (midilibre.fr)
- Violences sexistes et sexuelles : Marie Portolano mise en examen pour diffamation à la suite d’une plainte de Pierre Ménès (humanite.fr)
il faisait ce qui lui plaisait, sans jamais être réprimandé. Outre l’humiliation, tous genres confondus, il se permettait de faire ce que bon lui semblait aux femmes qui l’entouraient. De toucher qui il voulait où il voulait, avec le consentement non des personnes concernées évidemment, mais de celles qui auraient tout à fait pu l’arrêter.
- Affaire Gérard Depardieu : l’acteur est renvoyé devant la cour criminelle de Paris pour viols sur la comédienne Charlotte Arnould (franceinfo.fr)
- Homme sage-femme jugé pour viols : l’ex soignant condamné à quatorze ans de réclusion criminelle (humanite.fr)
Un maïeuticien déjà condamné pour 11 viols sur des patientes a contesté jeudi avoir « masturbé » deux des six autres femmes qu’il est accusé d’avoir violées, évoquant des gestes « médicaux » devant la cour criminelle de l’Hérault. Le verdict est tombé ce vendredi 5 septembre. Lionel Charvin est condamné à quatorze ans de prison.
- Homosexuelle et harcelée, une directrice d’école se suicide le jour de la rentrée (leparisien.fr)
D’abord le classement sans suite de sa plainte, et puis la promotion de l’inspectrice de l’éducation nationale qui, selon elle, ne l’avait pas vraiment soutenue tout au long de cette affaire. Il y a un message dans le fait qu’elle ait choisi cette date de la rentrée pour se donner la mort.
Voir aussi Cas d’école – L’histoire de Caroline (blogs.mediapart.fr)
Parce qu’elle est mariée à une femme, Caroline a subi les attaques d’un corbeau qui l’a menacée de mort et a tagué des insultes homophobes sur le mur de son école. On aurait pu croire que sa hiérarchie et les parents d’élèves auraient fait bloc pour la soutenir. Il n’en a rien été.
Et Suicide d’une directrice d’école : “L’institution ne prend pas en charge l’humain” (telerama.fr)
- Féminicide d’Amanda Glain : l’ex-policier Arnaud Bonnefoy condamné à 22 ans de réclusion criminelle (huffingtonpost.fr)
En janvier 2022, l’ancien gardien de la paix avait étranglé à mort sa compagne Amanda Glain qui voulait le quitter, décrivant lui-même un acte « monstrueux ».
Spécial médias et pouvoir
- Macron en guerre informationnelle… depuis le JDNews (politis.fr)
Le président a convoqué, pour le 10 septembre, un « conseil de défense sur la guerre informationnelle ». Et « en même temps », accorde son entretien de rentrée à l’hebdomadaire d’extrême droite JDNews… pour lequel travaillent pléthore de journalistes pro russes.
- Bayrou : quatre chaînes d’info, une seule ligne édito (acrimed.org)

- L’affaire Thomas Legrand et le mythe de la neutralité journalistique (politis.fr)
L’affaire Thomas Legrand relance un vieux débat : un journaliste engagé est-il forcément un journaliste suspect ? Et si le problème n’était pas l’engagement, mais l’hypocrisie de ceux qui prétendent ne pas en avoir ?
- Le journalisme politique vit son « moment socialiste » (acrimed.org)
Depuis que la chute de François Bayrou et de son gouvernement est annoncée, le landerneau du journalisme politique s’agite et tente d’imaginer « l’après ». De nombreux éditorialistes en sont désormais convaincus : c’est le « moment socialiste », après que le PS a consommé sa rupture avec LFI et le programme du NFP.
- Université d’été de LFI : retour sur l’« affaire Olivier Pérou » (acrimed.org)
En août 2025, l’université d’été de La France insoumise (LFI), les Amfis, a été le théâtre d’une nouvelle polémique médiatique : le refus d’accréditer Olivier Pérou, journaliste du Monde et co-auteur du livre La Meute […] Cette décision, assumée par LFI, a déclenché une vague d’indignation dans les rédactions qui y ont vu une atteinte grave à la liberté de la presse.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Budget 2026 : en catimini, François Bayrou et Emmanuel Macron s’apprêtent à publier trois décrets pour doubler les franchises médicales (humanite.fr)
Sans attendre le vote de confiance des députés, le gouvernement veut imposer ses mesures austéritaires dans le dos du Parlement et s’apprête à alourdir le reste à charge des assurés pour faire des économies sur l’assurance-maladie.
- Rentrée 2025 : les syndicats s’inquiètent du budget alloué à l’éducation (letudiant.fr)
- 20 à 30 % des bâtiments scolaires sont « vétustes » et « inadaptés » : syndicats et ONG exigent un plan à 50 milliards pour rénover le bâti scolaire (humanite.fr)

- Rentrée scolaire 2025 : Il manque « l’équivalent de 2.500 professeurs », selon Élisabeth Borne (20minutes.fr)
- Une décision de Pécresse sur la fin progressive des manuels scolaires dans les lycées suscite l’inquiétude (huffingtonpost.fr)
- Elisabeth Borne veut un « droit à la déconnexion » pour les espaces numériques de travail des élèves (lemonde.fr)
En déplacement dans un établissement à Bondy, la ministre de l’éducation a déclaré vouloir mettre en place une pause numérique pour tous les élèves entre 20 heures et 7 heures. Elle souhaite également interdire l’utilisation des téléphones portables dans tous les collèges à la rentrée prochaine.
- Porte-Parole du Parti socialiste et « en même temps » Gobal Data Protection officer chez Palantir (reflets.info)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- En s’attaquant à l’AME, François Bayrou tente de se sauver grâce au RN (politis.fr)
Le gouvernement travaille sur des projets de décrets réformant l’aide médicale d’État. À quelques jours d’un vote de confiance qui s’annonce plus que défavorable pour le Premier ministre, il tente de manoeuvrer en douce pour séduire l’extrême droite.
- « Violences urbaines » : en douce, le ministère de l’Intérieur interdit les journalistes en manifestation (humanite.fr) – voir aussi Avant le 10 septembre, Retailleau a-t-il vraiment interdit les journalistes en manifestation ? (huffingtonpost.fr)
la prise en compte du statut des journalistes telle que consacrée par le schéma national du maintien de l’ordre, ne trouve pas à s’appliquer dans un contexte de violences urbaines

- Bruno Retailleau veut s’inspirer de l’Italie qui « criminalise » l’organisation des rave parties (huffingtonpost.fr)
Le ministre de l’Intérieur réagissait sur TF1 à l’organisation d’une rave-party dans les Corbières, touchés par le grand incendie d’août dans l’Aude.
- À Vitré, des syndicalistes du centre d’appel Concentrix, poussés à bout (splann.org)
Des syndicalistes du centre d’appel de la multinationale Concentrix, à Etrelles près de Vitré en Ille-et-Vilaine, attaquent leur employeur en justice. Ils dénoncent un management délétère conduisant à des tentatives de suicide, des burn-out et un turn-over très important. Ils regrettent que leurs alertes auprès de leur direction et des élus locaux n’aient pas amélioré la situation
- Faux média local, vrai site facho Breizhinfo s’est créé une place dans la fachosphère (larevuedesmedias.ina.fr)
- Les tribunes de Rennes et Guingamp, autrefois antiracistes, basculent-elles à l’extrême droite ? (basta.media)
Les supporters ultra de Rennes et Guingamp sont-ils en train de perdre leur ADN antiraciste ? Comment des tribunes plutôt à gauche deviennent-elles poreuses aux idées d’extrême droite ?
Voir aussi : Quand le hooliganisme d’extrême droite s’incruste dans les tribunes du foot breton (basta.media)
Des groupes de hooligans d’extrême droite se rendent de plus en plus visibles lors des matchs de Rennes et Guingamp (Côtes-d’Armor). Ces tribunes deviennent un vivier pour des groupuscules identitaires qui participent aussi à des actions violentes dans la rue.
- Une enquête ouverte après l’agression de quatre militants LFI par deux individus « nationalistes » à Brest (humanite.fr)
- À La plaine Saint-Denis, un policier gifle un jeune puis lui crache au visage (streetpress.com)
Selon Salim Dabo, le fonctionnaire de police ferait partie de l’unité N26. Le président de l’association Univers Project explique avoir lui-même déjà eu à faire à eux. En janvier dernier, il aurait été violemment interpellé pendant qu’il organisait une maraude dans le quartier de la Plaine. Salim, placé en garde à vue, accuse ensuite les policiers de l’avoir frappé au sein de sa cellule.
Spécial résistances
- 2 septembre : la CGT initie une grève reconductible dans l’énergie (rapportsdeforce.fr)
Alors que la rentrée sociale s’annonce chaude, la FNME-CGT appelle à une grève reconductible dans l’énergie dès le 2 septembre. Objectif : obtenir une augmentation des salaires et une baisse de la TVA sur l’abonnement énergétique.
- Grève illimitée : les syndicats de l’AP-HP se mobilisent pour défendre la Sécurité Sociale de 1945 (humanite.fr)
Alors que le « Plan Bayrou » demande plus d’« efficience » à l’Hôpital Public, les organisations syndicales ont déposé un préavis de grève illimitée, dès ce 5 septembre, pour dénoncer les coupes austéritaires dans les budgets de la santé, conduisant à des conditions de travail toujours plus dures
- 10 septembre : ce que les assemblées générales révèlent du mouvement (rapportsdeforce.fr)
Mouvement nébuleux d’extrême droite, renouveau des gilets jaunes ou réunion de militants de gauche ? Depuis le début du mois d’août, des assemblées générales préparent le mouvement de blocage du 10 septembre dans plus de 60 villes. Elles révèlent un visage du mouvement bien différent de certaines caricatures médiatiques.
- « On peut mettre à l’arrêt la Loire-Atlantique » : 500 personnes en AG à Nantes pour le 10 septembre (revolutionpermanente.fr)
- “Ils sont en train de nous casser”, “Ce sont nos conquis sociaux” : la mobilisation “Bloquons Tout” expliquée par deux militant·es (france3-regions.franceinfo.fr)
- Avant les blocages du 10 septembre, cette note des renseignements témoigne de leur inquiétude. (huffingtonpost.fr)
Si les renseignements prévoient une mobilisation importante, ils s’inquiètent surtout du « caractère diffus et imprévisible » du mouvement et des conséquences que cela pourrait avoir.

- Une grève se prépare à la SNCF une semaine après les blocages du 10 septembre (huffingtonpost.fr)
Contre les projets d’économies budgétaires du gouvernement, trois syndicats majoritaires de la SNCF appellent à la grève le 18 septembre.
- Riverain·es exposé·es aux pesticides : le bras de fer commence (reporterre.net)
Spécial outils de résistance
Spécial GAFAM et cie
- Google doit partager ses données de recherche mais échappe à la vente de Chrome (france24.com)
- Google stock jumps 8 % after search giant avoids worst-case penalties in antitrust case (cnbc.com)
Google will not be required to divest Chrome ; nor will the court include a contingent divestiture of the Android operating system in the final judgment
- Google et Shein écopent d’une amende record en France pour non-respect des règles sur les cookies (huffingtonpost.fr)
La Cnil a infligé 325 millions d’euros d’amende à Google et 150 millions d’euros d’amende à Shein pour d’importants manquements en matière de publicité en ligne.
- Flo app controversy : Jury rules Meta stole users’ menstrual data (tuta.com)
Millions of women entrusted their menstrual data in the period cycle app, Flo. Now the court ruled Meta was eavesdropping on users’ in-app communications. But why would Meta want your menstrual data, and what does it mean for your privacy ?
Les autres lectures de la semaine
- Pouvoir, technologie et phénoménologie des conventions (journals.openedition.org)
- Les bactéries miroirs pourraient conquérir la vie sur Terre : et si ce fantasme de scientifiques devenait une dangereuse réalité (theconversation.com)
À l’avenir, si des cellules synthétiques (dites « cellules miroirs »), correspondant à la version chimiquement inversée de cellules naturelles, se développaient sur Terre, quelles pourraient être les conséquences pour la santé humaine et l’environnement ?
- No suffering, no death, no limits : the nanobots pipe dream (aeon.co)
Thirty years ago, nanotech was about to change everything. Let’s not get tricked again by Silicon Valley’s magical thinking
- Open Source is one person (opensourcesecurity.io)
- « Au potager, contrôler ou laisser faire ? L’exemple du liseron » (reporterre.net)
- ‘People Are So Proud of This’ : How River and Lake Water Is Cooling Buildings (wired.com)
Networks of pipes and heat exchangers can transfer excess heat from buildings into nearby bodies of water—but as the world warms, the cooling potential of some water courses is now diminishing.
- Transformer Washington en théocratie : Trump et les racines de la guerre chrétienne en Amérique (legrandcontinent.eu)
- Comprendre l’autodissolution du PKK (lundi.am)
- On ne naît pas blanc, on le devient : explorer « La pensée blanche » avec Lilian Thuram (theconversation.com)
- Trouveresses, ménestrelles et jongleresses (laviedesidees.fr)
Au Moyen Âge, les femmes ne se contentent pas d’écouter la musique : elles la chantent, la composent, la copient et la transmettent. Derrière le silence des sources, entre cloîtres et cours affleure une vie musicale insoupçonnée. Un foisonnement de pratiques aujourd’hui rendu à la lumière […] de toute évidence, les femmes apparaissent partout où l’on se met en peine de chercher leurs traces.
- Babybel on a dit. (klaire.blog)
Le truc s’appelle « i drink safe », et vas-y on a bien compris, i drink safe, c’est i dépense encore du pognon à cause de ÇA, c’est i pay un taxi parce que le dernier rer les boules, i prend sur moi, ma gestion et mes finances la charge mentale du viol – vous étiez habillée comment ? vous aviez consommé de l’alcool ? vous aviez vérifié qu’il y avait pas de GHB dans votre verre ? NON ? Vous aviez pas de bracelet ? ? Ben enfin mademoiselle.
Les BDs/graphiques/photos de la semaine
- Pot de départ

- Remember
- Saturation
- Tapisserie
- Rentrée
- Violences
- Alliance
- Balance
- ChatGPT
- Dave
- Why
- Bro
- Taxes
- Wealth
- Corporate
- Astuce
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- La libération de la Palestine : un combat anticolonial et antifasciste (contretemps.eu)
- De “Matrix” à “Sense8”, la révolution Wachowski (france.tv – disponible jusqu’au 29/09/2025)
- Les compositrices… empêchées, effacées, oubliées (radiofrance.fr – série de podcasts de 2009)
- Où sont les femmes dans la musique classique ? (radiofrance.fr – émission de 2014)
Les trucs chouettes de la semaine
- “Notre solution coûte trois fois moins cher qu’Office 365” : comment Lyon a tourné le dos à Microsoft (lesnumeriques.com)
- Bye-bye Microsoft ! Comment les organisations se mettent (enfin) au logiciel libre (incyber.org)
Un pays tout entier, le Danemark, un länder allemand, des dizaines de communes, comme Lyon, la troisième ville de France… Lentement mais sûrement, les collectivités basculent vers Linux, LibreOffice et autres NextCloud. Le but est économique, mais aussi d’asseoir sa souveraineté numérique et d’en finir avec la dictature des GAFAM.
- Des scientifiques aident les ibis chauves à migrer grâce à de petits avions ULM (lareleveetlapeste.fr)
Fait remarquable : même plusieurs années après, les ibis reconnaissent encore les humains qui les ont guidés lors de leur premier voyage.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
01.09.2025 à 07:42
Khrys’presso du lundi 1er septembre 2025
Khrys
Texte intégral (7482 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Rare Snail Has a 1-in-40,000 Chance of Finding a Mate. New Zealand Begins the Search (slashdot.org)
Ned’s shell spirals left, while almost all other snails have right spiraling shells […] this snail’s reproductive organs “don’t line up” with those of snails with right-spiraling shells […]“If 40,000 people read this,” the campaign explains, “chances are, Ned’s dreams will come true.”
- Tokyo enregistre 35 °C pendant 10 jours, un record historique (reporterre.net)
- Japan launches its first homegrown quantum computer (livescience.com)
Japan’s first entirely homegrown quantum computer uses superconducting qubits and components made entirely domestically.
- Why China has a tech manufacturing advantage over the U.S. (restofworld.org)
- Nucléaire iranien : Paris, Londres et Berlin menacent Téhéran de sanctions (humanite.fr)
L’Allemagne, la France et le Royaume-Uni ont indiqué lancer le mécanisme de « snapback » à l’encontre de l’Iran, dans une lettre adressée au Conseil de sécurité de l’Onu. Dans trente jours, le régime islamiste pourrait subir de nouvelles sanctions.
- “On en manque déjà pour la consommation humaine” : en Espagne, les datacenters épuisent les ressources en eau (tf1info.fr)

- Denmark to give people copyright over their own face, voice, and body to fight deepfakes (business-humanrights.org) – voir aussi Denmark’s New Digital Identity Rights Law Could Redefine Privacy and AI Rights for its citizens (thisisn0tareview.wordpress.com)
Denmark is on the verge of becoming the first country in Europe to legally recognize a citizen’s face, voice, and likeness as protected intellectual property. In a landmark move, the Danish government has introduced a legislative proposal aimed at giving individuals full legal control over their digital selves, an unprecedented step in the age of artificial intelligence.
- Des proches de Donald Trump sont en train de préparer une campagne subversive pour annexer le Groenland (legrandcontinent.eu)
Le chargé d’affaires américain à Copenhague a été convoqué aujourd’hui, mercredi 27 août, par le ministre des Affaires étrangères danois suite à des informations ayant révélé une opération d’influence menée par des citoyens américains au Groenland.
- Sur les droits de douane, Donald Trump essuie un nouveau revers majeur, le président américain fulmine (huffingtonpost.fr)
Une cour d’appel fédérale américaine a statué vendredi 29 août que la plupart des droits de douane imposés par Donald Trump sont illégaux. Un revers majeur le président et sa politique qui ébranle l’économie mondiale, avant que la Cour suprême ne se prononce à son tour.
- Donald Trump mort ? Comment la folle rumeur a enflammé Internet après cette phrase de JD Vance (huffingtonpost.fr)
Spéculations sur sa santé, agenda vide, étrange sortie de son vice-président… Il n’en fallait pas plus pour que certains internautes américains lancent la rumeur.

- 2 men impersonating officers fatally shot by Texas homeowners after firing shots through door (police1.com)
- CDC Director Susan Monarez fired by Trump administration after refusing to resign, citing ‘reckless directives’ (nbcnews.com) – voir aussi L’administration Trump fait imploser la principale agence sanitaire américaine (huffingtonpost.fr)
Robert Kennedy Jr, le ministre de la Santé de Donald Trump, a licencié la responsable de la principale agence de santé publique américaine. Sa faute : refuser la dérive antivax du gouvernement.
- L’obsession trans (laviedesidees.fr)
La question trans est devenue l’un des points de clivages centraux du débat public aux États-Unis, jusqu’à la récente tuerie de Minneapolis et l’accusation de “transterrorisme”.
- Mississippi’s Broken Age Verification Law Forces Bluesky To Block All State Users (techdirt.com)
- Mastodon says it doesn’t ‘have the means’ to comply with age verification laws (techcrunch.com)
Decentralized social network Mastodon says it can’t comply with Mississippi’s age verification law — the same law that saw rival Bluesky pull out of the state — because it doesn’t have the means to do so.The social nonprofit explains that Mastodon doesn’t track its users, which makes it difficult to enforce such legislation. Nor does it want to use IP address-based blocks
- Au festival Burning Man, la folle histoire de cet accouchement surprise en plein désert (huffingtonpost.fr)
Un couple de festivalier·es a vécu une surprise incroyable : la naissance de leur premier enfant dans leur camping-car… alors qu’iels n’avaient pas la moindre idée de cette grossesse.
- Florida deploys robot rabbits to control invasive Burmese python population (cbsnews.com)
They look, move and even smell like the kind of furry Everglades marsh rabbit a Burmese python would love to eat. But these bunnies are robots meant to lure the giant invasive snakes out of their hiding spots.
- Tesla denied having fatal crash data until a hacker found it (arstechnica.com)
The data was key evidence in the death of a pedestrian in 2019.
Voir aussi En procès, Tesla a affirmé ne pas avoir de données sur un accident mortel… avant qu’un pirate informatique ne les retrouve (humanite.fr)
La vitrine technologique du multimilliardaire Elon Musk aurait tenté de cacher des preuves essentielles lors d’un procès s’étant déroulé en juillet 2025, révèle le « Washington Post ». Attaquée en justice pour avoir participé à la mort d’une civile, percutée par une voiture Tesla en pilote automatique, l’entreprise a été condamnée à 243 millions de dollars de dommages et intérêts.
- An inner-speech decoder reveals some mental privacy issues (arstechnica.com)
researchers at the Stanford University built a BCI that could decode inner speech—the kind we engage in silent reading and use for all our internal monologues. The problem is that those inner monologues often involve stuff we don’t want others to hear.
Voir aussi L’implant cérébral qui lit les pensées : miracle médical et nouvelles questions éthiques (france24.com)
Des chercheureuses ont réussi, pour la première fois, à traduire en temps réel les pensées silencieuses grâce à un implant cérébral couplé à une intelligence artificielle. Cette technologie promet d’offrir une nouvelle forme de communication aux personnes paralysées. Elle soulève néanmoins des questions cruciales sur la vie privée, le consentement et la sécurité mentale.
- Trump administration halts construction of nearly finished offshore wind farm (grist.org)
Ørsted’s Revolution Wind project off the coast of Massachusetts and Rhode Island is hit with a stop-work order over vague “national security” concerns.
- The Tyre Poison Nobody Talks About (weareoceanrising.substack.com)
When rain hits city streets, salmon die within hours. Scientists have traced the killer to a chemical hidden in every car tyre, one that turns stormwater into poison. New research shows this dust doesn’t just wipe out fish, it rides the air, lodges in our lungs, and is already reshaping ecosystems worldwide.
- Déforestation : la justice brésilienne limite l’expansion du soja en Amazonie (humanite.fr)
La décision d’une juge fédérale rendue ce lundi permet le rétablissement du moratoire interdisant l’exportation de soja issu de zones de l’Amazonie en proie à la déforestation.
Spécial IA
- Anthropic will start training its AI models on chat transcripts (theverge.com)

- OpenAI annonce que certaines de vos conversations avec ChatGPT pourront être transmises à la police (rtbf.be)
- Wikipedia Editors Reject Founder’s AI Review Proposal After ChatGPT Fails Basic Policy Test (news.slashdot.org)
Wikipedia’s volunteer editors have rejected founder Jimmy Wales’ proposal to use ChatGPT for article review guidance after the AI tool produced error-filled feedback when Wales tested it on a draft submission. The ChatGPT response misidentified Wikipedia policies, suggested citing non-existent sources and recommended using press releases despite explicit policy prohibitions.
- YouTube secretly tested AI video enhancement without notifying creators (arstechnica.com)
Google says this isn’t technically “GenAI,” but it is altering videos without warning.
- Meta created flirty chatbots of Taylor Swift, other celebrities without permission (reuters.com)
- Elon Musk sues Apple and OpenAI, revealing his panic over OpenAI dominance (arstechnica.com)
- Imgur’s Community Is In Full Revolt Against Its Owner (404media.co)
The front page of Imgur, a popular image hosting and social media site, is full of pictures of John Oliver raising his middle finger and telling MediaLab AI, the site’s parent company, “fuck you.” Imgurians, as the site’s users call themselves, telling their business daddy to go to hell is the end result of a years-long degradation of the website. The Imgur story is one a classic case of enshitification
- One long sentence is all it takes to make LLMs misbehave (theregister.com)
Chatbots ignore their guardrails when your grammar sucks, researchers find. […] You just have to ensure that your prompt uses terrible grammar and is one massive run-on sentence like this one which includes all the information before any full stop which would give the guardrails a chance to kick in before the jailbreak can take effect and guide the model into providing a “toxic” or otherwise verboten response the developers had hoped would be filtered out.
- The personhood trap : How AI fakes human personality (arstechnica.com)
AI assistants don’t have fixed personalities—just patterns of output guided by humans.
- AI robots are helping South Korea’s seniors feel less alone (restofworld.org)
A ChatGPT-powered robotic companion called Hyodol is taking over some work from overburdened caregivers, much to the delight of seniors who treat them like grandchildren.
- “ChatGPT killed my son” : Parents’ lawsuit describes suicide notes in chat logs (arstechnica.com)
ChatGPT taught teen jailbreak so bot could assist in his suicide, lawsuit says.
- Meta changes teen AI chatbot responses as Senate begins probe into ‘romantic’ conversations (cnbc.com)
The social media giant is now training its AI chatbots so that they do not generate responses to teenagers about subjects like self-harm, suicide, disordered eating and avoid potentially inappropriate romantic conversations
Spécial Palestine et Israël
- Palestine : « Le degré de déshumanisation et d’invisibilisation est sidérant » (acrimed.org)
- « J’ai vu des enfants qui meurent de faim » : à Gaza, la famine atteint un « point de rupture », alerte l’ONU (humanite.fr)
Alors que l’Onu estime à plus d’un demi-million le nombre de Gazaouis en situation de détresse alimentaire maximale, son secrétaire général a dénoncé « un catalogue sans fin d’horreurs ».
- Gaza : l’effacement planifié d’un peuple (politis.fr)
Depuis l’offensive terrestre déclenchée au lendemain de l’attaque menée par le Hamas le 7 octobre 2023, Israël a lentement mais méthodiquement broyé le territoire palestinien.

- « Jamais je n’aurais imaginé vivre une scène de guerre sur un navire humanitaire » (politis.fr)
Le 24 août, le navire humanitaire Ocean Viking a été attaqué dans les eaux internationales par les tirs des garde-côtes libyens, alors qu’il naviguait vers une embarcation en détresse. Lucille Guenier, coordinatrice de la communication de SOS Méditerranée, était à bord.
- Les États-Unis refusent d’octroyer des visas à des membres de l’Autorité palestinienne avant l’Assemblée générale de l’ONU (rtbf.be)
- Microsoft licencie quatre employé·es, accusé·es d’avoir dénoncé la complicité du géant de la tech dans le génocide à Gaza (humanite.fr)
Microsoft a licencié deux employé·es mercredi 27 août, et deux autres jeudi 28 août. Leur faute ? Avoir occupé le bureau du président de la multinationale pour dénoncer ses liens avec l’armée israélienne génocidaire.
- Palestinian Activists Urge Oakland to Stop Military Shipments to Israel (kqed.org)
Palestinian activists are calling on Oakland officials to halt military cargo shipments through the city’s airport to Israel, saying the shipments have supported Israeli airstrikes on Gaza.
- Le Royaume-Uni interdit aux responsables israéliens de participer à un salon de l’armement (humanite.fr)
Le Royaume-Uni a interdit aux responsables israéliens de participer au Defence and Security Equipment International, un important salon de l’armement se tenant tous les deux ans à Londres au début du mois de septembre. Des entreprises israéliennes seront toutefois présentes.
- Des salarié·es de Météo-France exigent la fin des partenariats avec Israël (reporterre.net)
Depuis plusieurs mois, le syndicat CGT de Météo-France demande l’arrêt des partenariats avec Israël pour dénoncer la guerre en Palestine. L’État hébreu se servirait de données météorologiques européennes à des fins militaires.
- Insaf Rezagui : « La France pourrait être poursuivie pour complicité si elle continue de soutenir Israël » (politis.fr)
Alors que l’Assemblée générale de l’ONU se réunit en septembre et que le génocide perpétré par Israël à Gaza se poursuit, la docteure en droit international public Inzaf Rezagui rappelle la faiblesse des décisions juridiques des instances internationales, faute de mécanisme contraignant et en l’absence de volonté politique.
Spécial femmes dans le monde
- Aux Pays-Bas, les femmes revendiquent un « droit à la nuit » après le meurtre d’une adolescente (huffingtonpost.fr)
La mort de Lisa, 17 ans, tuée alors qu’elle rentrait de soirée à Amsterdam, a créé une onde de choc chez les Néerlandaises. Elles réclament de pouvoir sortir la nuit en toute sécurité.
- Giorgia Meloni « écœurée » par l’utilisation de son image (et celle d’autres femmes) sur un forum sexiste (huffingtonpost.fr)
Le site « Phica » a ciblé plusieurs personnalités italiennes, détournant des images d’elles prises dans le cadre privé.
- My ex stalked me, so I joined a ‘dating safety’ app. Then my address was leaked (bbc.com)
The leak was seized on by misogynist groups online, and within hours, several websites had been created to humiliate the women who’d signed up.Two maps were published on social media, showing 33,000 pins spread across the United States.
- Santé des femmes : pourquoi la recherche sur l’endométriose n’avance pas ? (rfi.fr)
Maladie gynécologique toujours stigmatisée, l’endométriose touche environ 190 millions de personnes dans le monde. Même s’il existe des traitements relativement efficaces, la recherche se poursuit pour développer des tests de dépistage. Aux États-Unis, la recherche est mise à mal par l’administration Trump qui n’en finit pas avec des coupes budgétaires drastiques.
Spécial France
- À Paris, l’hommage aux républicains espagnols de la « Nueve », premiers libérateurs de la capitale (politis.fr)
Comme chaque année depuis 2004, une cérémonie organisée par la Mairie de Paris a célébré les républicains espagnols de la 9e Compagnie de la 2e DB de Leclerc, qui furent les premiers soldats alliés à entrer pour libérer Paris le 24 août 1944.
- Nouveautés de la rentrée scolaire 2025 : éducation à la sexualité, tests de forme physique, mathématiques… Quels sont les changements au programme ? (franceinfo.fr)
- Dans les Bouches-du-Rhône, la pluie et les orages décalent à mardi la rentrée prévue lundi 1er septembre (huffingtonpost.fr)
De très fortes précipitations et de violents orages sont attendus sur le département en soirée ce dimanche et jusqu’en fin de matinée lundi.
- Investie par les LR à Paris pour les municipales, Rachida Dati lâche les législatives au profit de Michel Barnier (humanite.fr)
La ministre de la Culture, tout juste de retour dans son parti après une année de césure en Macronie, s’est sans surprise vue investie pour concourir à la mairie de Paris. Une source de joie pour Rachida Dati à qui la pugnacité ne fait jamais défaut, trop heureuse de la bataille qui s’annonce pour arracher la capitale aux socialistes
- Attention à ce faux courrier de l’Assurance Maladie déposé dans votre boîte aux lettres, c’est une arnaque (huffingtonpost.fr)
Très réaliste, ce courrier déposé directement dans votre boîte aux lettres vous invite à flasher un QR code pour confirmer vos droits. […] les fraudeurs utilisent une technique bien connue : faire craindre aux assurés la perte d’accès imminente à leur compte Ameli ou l’expiration de leur carte Vitale pour les empêcher de vérifier la véracité des informations.
- Après Bétharram, 5 prêtres mis en cause dans un établissement catholique près de Nantes (huffingtonpost.fr)
Les faits survenus au collège-lycée Saint-Stanislas ont eu lieu entre les années 1950 et 1990. Les victimes sont neuf hommes et une femme.
- Un réseau d’esclavage moderne découvert dans des vignobles de la région Champagne (ldh-france.org)
- Mercure dans le thon : des communes bannissent les boîtes de leurs cantines (reporterre.net)
- Feuilles mortes, arbres jaunis… La chaleur provoque un automne précoce (reporterre.net)
- Les mégabassines du Poitou sont au point mort, révèle un document interne (reporterre.net)
- À Paris, la baignade dans la Seine va durer plus longtemps que prévu sur deux des trois sites (huffingtonpost.fr)
Anne Hidalgo s’est félicitée de la réussite de ce projet et en a donc profité pour sonner l’heure des prolongations jusqu’à la mi-septembre.
Spécial femmes en France
- « En 10 secondes, le client est fixé » : un restaurateur de La Rochelle investit dans des bracelets de dépistage du GHB (leparisien.fr)
- Violences sexuelles : et si le « oui » ne valait rien ? (politis.fr)
L’inscription de la notion de consentement dans la définition pénale du viol a fait débat l’hiver dernier à la suite du vote d’une proposition de loi. Clara Serra, philosophe féministe espagnole, revient sur ce qu’elle considère comme un risque de recul pour les droits des femmes.
- Plus de 70 % des associations féministes voient leur santé financière dégradée par rapport à 2024, majoritairement à cause des baisses de subventions (franceinfo.fr)
Spécial médias et pouvoir
- L’Empaillé au tribunal de Perpignan le 16 octobre (lempaille.fr)
Louis Aliot a été condamné à six mois ferme pour détournement de fonds publics, mais il continue à gérer Perpignan avec ses copains néo-fascistes et son directeur de la police… qui nous attaque en justice.
- Tapisserie de Bayeux : la préfecture du Calvados retire en catimini une vidéo qui contredit l’Élysée (france3-regions.franceinfo.fr)
En janvier 2025, la préfecture du Calvados publiait sur ses réseaux sociaux une vidéo sur le dépoussiérage de la tapisserie de Bayeux. Des experts y soulignaient son extrême fragilité et l’impossibilité de la déplacer sur une longue distance. Alors que le chef de l’État a annoncé le prêt de l’œuvre aux Britanniques, la vidéo n’est plus accessible.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Le crépuscule de Jupiter ou l’impasse présidentielle (politis.fr)
À bout de souffle, Emmanuel Macron se retrouve isolé, sans majorité et contesté à la fois dans la rue et sur la scène internationale. Entre menace de pleins pouvoirs et incapacité à ouvrir une issue politique, la présidence vacille, révélant l’impasse d’une Ve République en crise.
- Pour se sauver, François Bayrou choisit sa chute (politis.fr)
À la surprise générale, le premier ministre demandera un vote de confiance à l’Assemblée nationale le 8 septembre. Tentative de reprendre la main face au mouvement du 10 septembre ou manœuvre pour préparer sa sortie ?

- Loi Duplomb, A69 : Comment le gouvernement Bayrou a contourné l’Assemblée nationale pour faire passer ses projets. La démocratie malmenée ? (theconversation.com)
La loi Duplomb ou la proposition de loi sur l’autoroute A69 ont été adoptées en contournant l’Assemblée nationale à travers des tactiques gouvernementales, faussant la logique parlementaire.
- Elisabeth Borne veut réformer le contrôle continu du baccalauréat, afin que certaines notes ne comptent plus pour l’examen et pour Parcoursup (franceinfo.fr)
La ministre de l’Education nationale l’a annoncé, mercredi, lors de sa conférence de presse de rentrée alors que le contrôle continu compte pour 40 % de la note finale du baccalauréat depuis la réforme Blanquer.
- Allocation de rentrée scolaire : « On laisse penser que les pauvres méritent leur pauvreté » (politis.fr)
Comme chaque année, des politiques et des éditorialistes utilisent l’allocation de rentrée scolaire pour relancer le débat sur « l’assistanat ».
- 230 milliards d’économies : le Medef présente un plan de guerre pour « redresser le pays » (revolutionpermanente.fr)

- « Complètement dingue » : Bayrou répond à la polémique sur la rénovation de son bureau (huffingtonpost.fr)
François Bayrou ne décolère par contre Mediapart qui a consacré cette semaine un article aux travaux de rénovation du bureau du maire de Pau.
- Un préfet part en vacances en voiture de fonction, la CGT lui rappelle le contexte d’économie budgétaire (huffingtonpost.fr)
Le préfet de la Haute-Loire est critiqué par la CGT pour être allé en vacances en Italie avec sa voiture de fonction et d’avoir sollicité un chauffeur de son administration.
- Des candidats RN épinglés pour des frais kilométriques équivalents à trois fois le tour de la Terre (huffingtonpost.fr)
Le site « Les Jours » révèle que des candidats d’extrême droite aux dernières élections législatives ont explosé le compteur des frais kilométriques remboursables.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Des militant·es d’Extinction-Rébellion poursuivi·es pour une infraction imaginaire (radiofrance.fr)
Sept militant·es d’Extinction-Rébellion comparaissent devant le tribunal correctionnel de Paris pour une action menée le 14 juin dernier, Place de la République, lors d’une manifestation de soutien au peuple palestinien. Pour une infraction hasardeuse : la mise en danger de la vie d’autrui.
- La LDH interdite de forum associatif par le maire de Chalon, le tribunal administratif de Dijon rendra sa décision mardi (francebleu.fr)
- Kneecap à Rock en Seine : « Ce que redoutent certains élus, ce n’est pas le désordre, c’est la liberté », dénonce Matthieu Pigasse (humanite.fr)
- Une enquête ouverte sur le groupe Facebook “La France avec Jordan Bardella” après la publication de messages racistes (franceinfo.fr)
- L’UNI : malgré les dérives néonazies du pseudo-syndicat étudiant, le soutien indéfectible de Bruno Retailleau (humanite.fr)
Saluts nazis, propos racistes et antisémites… Les preuves contre des membres de l’UNI s’accumulent sans réaction du ministre de l’Intérieur. Interrogé plusieurs fois par « Mediapart », il maintient, à quelques heures de la rentrée universitaire, son soutien au pseudo-syndicat étudiant.
- À quelques jours de la rentrée, faisons le point sur les attaques fascistes contre l’Allier (fsu03.fsu.fr)
depuis maintenant près de trois mois, la FSU et nommément son secrétaire départemental Vincent Présumey sont la cible des attaques de l’extrême droite, déclenchées en raison de notre rôle dans la mobilisation laïque contre les subventions publiques déversées sur le « spectacle » de Murmures de la Cité et, à travers cette association, à l’extrême droite racialiste et intégriste.
- L’avocate des victimes de l’agression raciste dans la Creuse menacée (politis.fr)
Les violences se poursuivent à Royère-de-Vassivière. Après la « chasse aux nègres » menée le 15 août, pour laquelle sept personnes ont porté plainte, leur avocate, Me Coline Bouillon, a été la cible de menaces de mort et de viol en ligne, d’après nos informations. Elle a déposé plainte.
- Extrême droite, comment en est-on arrivés là ? (frustrationmagazine.fr)
Alors que le spectre d’un départ du gouvernement Bayrou avant le 10 septembre se fait de plus en plus fort, celui d’une cohabitation avec le Rassemblement National, possiblement souhaité par Macron lui-même ré-émerge aussi.
Spécial résistances
- Bataille contre le budget Bayrou : l’intersyndicale appelle à la mobilisation le 18 septembre sur l’ensemble du territoire (humanite.fr)
L’intersyndicale (CFDT, CGT, FO, CFE-CGC, CFTC, Unsa, Solidaires, FSU) s’est réunie dans la matinée du vendredi 29 août.
- Grève du 18 septembre : les augmentations de salaires, l’autre moteur du mouvement social (humanite.fr)
Après deux années de rattrapage sur l’inflation, la modération salariale ressentie fin 2024 se confirme en 2025 et devrait s’accentuer en 2026. L’intersyndicale appelle ce vendredi à manifester et faire grève le 18 septembre contre la rigueur budgétaire, mais aussi pour obtenir des augmentations.
- La CGT soutient la mobilisation du 10 septembre et appelle à “construire la grève partout où c’est possible” (franceinfo.fr)
- La CGT et Solidaires décident de mobiliser dès le 10 septembre, avant la rencontre intersyndicale de vendredi (rapportsdeforce.fr)

- « La lutte a rendu visibles les sans-papiers qui rasaient les murs » (politis.fr)
Alors que le ministère de l’Intérieur s’acharne à enfermer les personnes sans-papiers pour les renvoyer de force dans leur pays d’origine, Alassane Dicko, de l’Association malienne des expulsés, revient sur l’histoire de la lutte des personnes expulsées et de leurs soutiens.
- « Il y avait urgence, on a foncé » : les opposants à l’A69 de retour dans les platanes (reporterre.net)
Spécial outils de résistance
- Pétition unitaire (CFDT, CGT, FO, CFE-CGC, CFTC, UNSA, FSU, Solidaires) contre le budget Bayrou (stopbudgetbayrou.fr)
- Libres d’obéir, de Johann Chapoutot, sort en B.D ! (souffrance-et-travail.com)
- À Karlsruhe, un artiste entraîne les oiseaux à chanter des mélodies antifascistes (courrierinternational.com)
Spécial GAFAM et cie
- Lois extraterritoriales : Les DSI face aux coupures des fournisseurs cloud (lemondeinformatique.fr)
De nouvelles sanctions américaines, mais aussi européennes illustrent les risques qu’embarquent les contrats cloud, les fournisseurs se trouvant contraints de se plier aux injonctions des États dont ils dépendent.
- Google will require developer verification for Android apps outside the Play Store (techcrunch.com)
- Your Word documents will be saved to the cloud automatically on Windows going forward (ghacks.net)
Microsoft announced that it is changing the default save location for Word documents on Windows. “Anything new you create will be saved automatically to OneDrive or your preferred cloud destination”
- Angry, confused and worried about police – behind Instagram bans (bbc.com)
Instagram users have told the BBC of their confusion, fear and anger after having their accounts suspended, often for being wrongly accused by parent company Meta of breaching the platform’s child sex abuse rules.
- Indonésie : TikTok suspend ses directs après des manifestations d’une rare violence (lemonde.fr)
Face à la colère qui embrase l’Indonésie, TikTok choisit la prudence et coupe temporairement son direct, privant plus de 100 millions d’utilisateurices de cette fonctionnalité très populaire.
Le rapport de la semaine
- Breaking up with Big Tech:a human rights-based argument for tackling Big Tech’s market power (amnesty.org)
In today’s digital age, a small group of technology giants – Alphabet (Google), Meta, Microsoft, Amazon, and Apple – wield extraordinary influence over the infrastructure, services, and norms that shape our online lives. These companies dominate key sectors of the internet : from search and social media to cloud computing, e-commerce, and mobile operating systems. While not all their market positions constitute illegal monopolies, their collective market power enables them to set the terms of digital engagement for billions of people worldwide. Their reach is so extensive that some experts have even likened them to utility providers. This concentration of power has profound implications for human rights, particularly the rights to privacy, non-discrimination, and access to information
Les autres lectures de la semaine
- 20 ans après, retours sur le référendum de 2005 (5/5) (acrimed.org)
- Les milliardaires de la tech et Trump : ce qu’ils ont obtenu (multinationales.org)
- By all means, tread on those people (pluralistic.net)
Just as Martin Niemöller’s “First They Came” has become our framework for understanding the rise of fascism in Nazi Germany, so, too is Wilhoit’s Law the best way to understand America’s decline into fascism […] : Conservatism consists of exactly one proposition, to wit : There must be in-groups whom the law protects but does not bind, alongside out-groups whom the law binds but does not protect.
- Les « Panama playlists » illustrent la facilité avec laquelle nous partageons nos données (next.ink)
- Why Do Students Give Teachers Apples and More from the Fruit’s Juicy Past (smithsonianmag.com)
The perfect back-to-school treat has a colorful past that once brought the wrath of an axe-wielding reformer
- « Élisée Reclus ne faisait pas de hiérarchie entre les luttes » (reporterre.net)
- A universal rhythm guides how we speak : Global analysis reveals 1.6-second ‘intonation units’ (phys.org)
Have you ever noticed that a natural conversation flows like a dance—pauses, emphases, and turns arriving just in time ? A new study has discovered that this isn’t just intuition ; there is a biological rhythm embedded in our speech.
- La longue histoire des tests de grossesse : de l’Égypte antique à Margaret Crane, l’inventrice du test à domicile (theconversation.com)
Depuis la pandémie de Covid-19, nous connaissons tous très bien les tests antigéniques, mais saviez-vous que le principe de l’autotest a été imaginé, dans les années 1960, par une jeune designer pour rendre le test accessible à toutes les femmes en le pratiquant à domicile ?
- Les discrètes (laviedesidees.fr)
Reléguées au second plan de la scène diplomatique, les épouses d’ambassadeurs demeurent pourtant les architectes invisibles du prestige français à l’étranger.
- La Culture du féminicide (laviedesidees.fr)
Les féminicides s’affichent partout. De la Bible à Netflix, tous les arts – mythologie, peinture, théâtre, cinéma, chanson – ont mis en scène le massacre des femmes. En retraçant l’histoire de cette structure de pensée, on comprend comment les sociétés légitiment l’élimination des femmes.
Les BDs/graphiques/photos de la semaine
{kind=link}
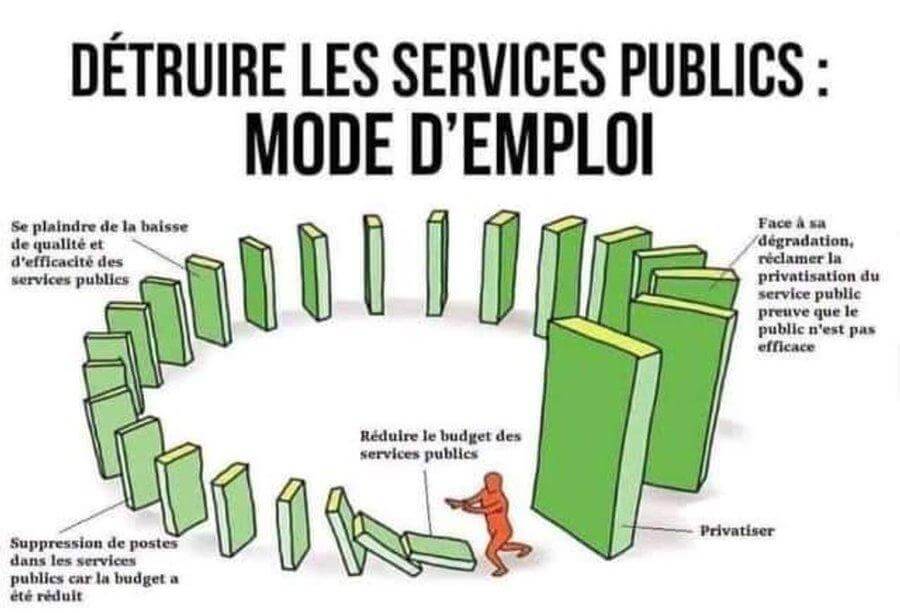{kind=link}
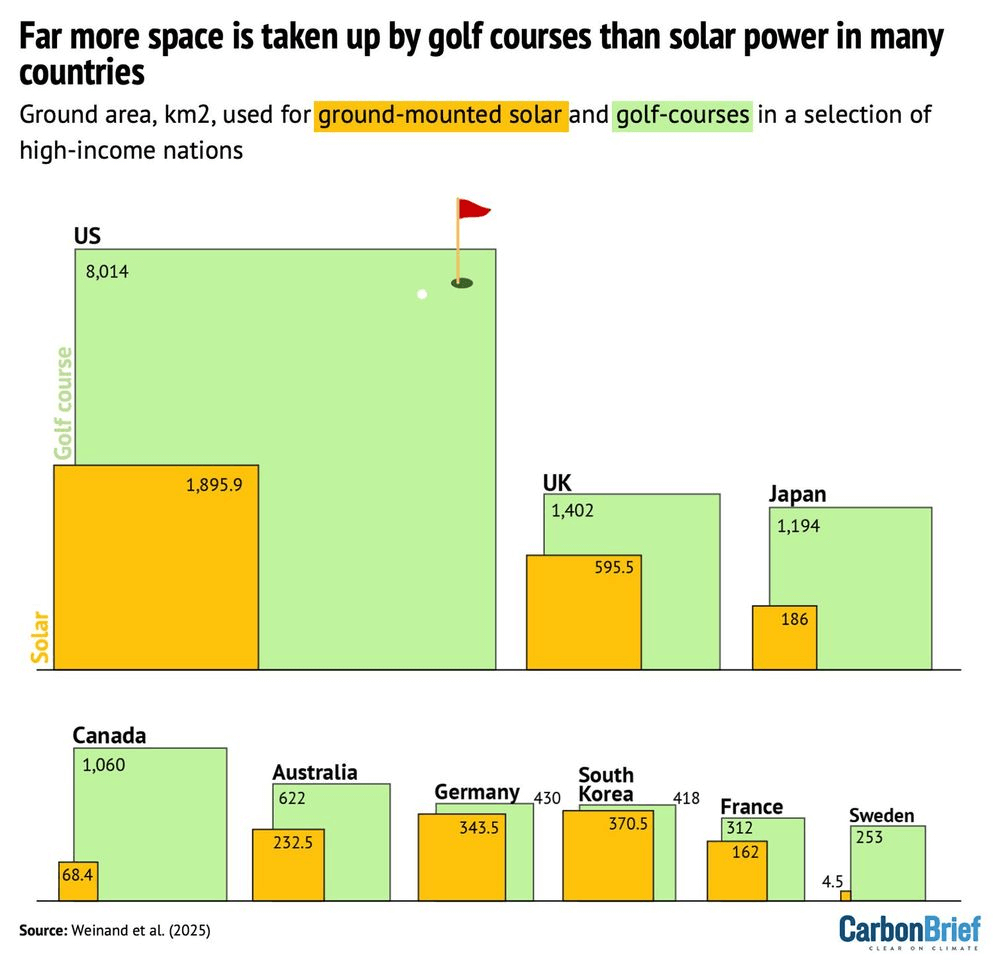{kind=link}
Les vidéos/podcasts de la semaine
- Pourquoi la France laisse Israël piétiner le droit international (video.blast-info.fr)
- Comment les élites allemandes livrèrent le pouvoir aux nazis (spectremedia.org)
- Commission d’enquête commande publique sénat : Logiciels Libres (tube-numerique-educatif.apps.education.fr)
Les trucs chouettes de la semaine
- The Ancient Woodland Practice Boosting British Biodiversity (reasonstobecheerful.world)
Coppicing — cutting trees back — to support nature may seem counterintuitive. But it can help make the most of a limited landscape.
- Underserved Communities Are Reaping the Benefits of London’s Solar Microgrids (reasonstobecheerful.world)
Thanks to a change in regulations, residents in social housing can now access the clean, affordable energy coming from their own roofs.
- Contre le monopole des Big Tech, « de nouvelles formes de communs numériques » (basta.media)
- Spécial informaticien·nes : deux tests, l’un sur le mail et l’autre sur javascript. Cadeau bonus : Wat – un lightning talk par Gary Bernhardt à CodeMash 2012 (destroyallsoftware.com)
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
25.08.2025 à 07:42
Khrys’presso du lundi 25 août 2025
Khrys
Texte intégral (7960 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Dramatic slowdown in melting of Arctic sea ice surprises scientists (theguardian.com)
They said natural variations in ocean currents that limit ice melting had probably balanced out the continuing rise in global temperatures. However, they said this was only a temporary reprieve and melting was highly likely to start again at about double the long-term rate at some point in the next five to 10 years.
- 120 000 visiteureuses par an : le surtourisme accable l’Antarctique (reporterre.net)
- Selon les expert·es, les océans auraient subi un changement capital et critique (fr.euronews.com)
Les vagues de chaleur marine pourraient avoir conduit les océans de la planète à un point de basculement critique. Les scientifiques craignent que le réchauffement prolongé des océans ne devienne la “nouvelle normalité”.

- Most air cleaning devices have not been tested on people − and little is known about their potential harms, new study finds (theconversation.com)
The gap between marketing claims and evidence of effectiveness might not be surprising, but there is more at stake here. Some of these technologies generate chemicals such as ozone, formaldehyde and hydroxyl radicals to kill microbes – substances that can potentially harm people if inhaled.
- Le « no man’s land » entre les deux Corées est devenu un sanctuaire écologique pour la faune et la flore locales (slate.fr)
Créée pour séparer les deux Corées, la zone démilitarisée abrite aujourd’hui près de 6.000 espèces animales et végétales. Un paradoxe rendu possible par l’absence d’activité humaine depuis 1953.
- La Russie serait en train d’aider indirectement la Chine à envahir Taïwan (legrandcontinent.eu)
Selon des documents publiés fin juillet par le groupe BlackMoon puis authentifiés par The Insider, l’agence russe Rosoboronexport aurait signé en juin 2024 un contrat d’un montant de 4,3 millions d’euros avec l’entreprise chinoise CETC International pour la livraison d’un système de commandement automatisé susceptible d’être utilisé par Pékin afin d’envahir Taïwan
- China’s biggest delivery app brings its disruptive playbook to Brazil (restofworld.org)
Meituan’s arrival is likely to transform the delivery industry — which has already seen the unlikely partnership between rivals Uber and iFood.
- Nationwide internet outage slashes Pakistan’s connectivity to 20 % (profit.pakistantoday.com.pk)
NetBlocks reports major disruption affecting PTCL backbone ; millions of users left offline as authorities remain silent
- Ukraine : autour des champs de mines, l’agriculture s’adapte (journal-labreche.fr)
- Greta Thunberg et 200 personnes bloquent la plus grande raffinerie de Norvège (lareleveetlapeste.fr)
Depuis lundi 18 août, plus de 200 militants écologistes, accompagnés de Greta Thunberg, bloquent la plus importante raffinerie de Norvège. Ils exigent que le pays entame une transition pour sortir de l’industrie pétrolière et gazière.
- Vagues de chaleur : un coût économique majeur pour l’Europe et le monde (argusdelassurance.com)
Selon une étude publiée par Allianz Trade, les vagues de chaleur extrêmes pourraient amputer le produit intérieur brut (PIB) européen de 0,5 point en 2025. L’impact, déjà sensible en Chine et aux États-Unis, illustre la vulnérabilité croissante des économies face aux risques climatiques.
- La canicule et les incendies ne laissent aucun répit à l’Europe du Sud (larepubliquedespyrenees.fr) – voir aussi Incendies : plus d’1 million d’hectares calcinés sur le territoire de l’UE en 2025, un triste record depuis 20 ans (humanite.fr)
L’année 2025 a surpassé les vingt précédentes avec plus de 10 000 kilomètres carrés sinistrés par des incendies dévastateurs dans l’Union européenne selon les données de l’Effis, analysées par l’AFP ce jeudi 21 août.
- Incendies meurtriers dans la péninsule ibérique : déjà 343 000 hectares ravagés en 2025 en Espagne, un nouveau record (vert.eco)
- Incendies en Espagne : Pedro Sanchez réclame un pacte sur l’urgence climatique (humanite.fr)
L’objectif : fournir les « ressources aux agents publics, aux fonctionnaires, non seulement lorsque l’incendie a lieu, mais aussi en amont, afin qu’ils puissent répondre de manière beaucoup plus efficace ».
- « Un incendie sous-marin » : à Nice, les plongeurs catastrophés par la canicule marine (reporterre.net) – voir aussi « C’est comme une forêt qui brûle sous l’eau » : ce que cache la vague de chaleur marine en Méditerranée (vert.eco)

- Au Portugal, le combat acharné de villages contre une mine de lithium (reporterre.net)
- L’avion est jusqu’à 26 fois moins cher que le train en Europe (reporterre.net)
- Miel, prunes… Les seuils autorisés d’acétamipride relevés par l’UE (reporterre.net)
Alors qu’en France, le Conseil constitutionnel a retoqué le 7 août la réintroduction de l’acétamipride dans la loi Duplomb, la Commission européenne, elle, relève les seuils des limites maximales autorisées de résidus de ce néonicotinoïde controversé sur différents produits comme les graines de moutarde, le miel et les prunes.
- Zadistes, écologistes et antifascistes allemands unis pour « faire l’histoire » (reporterre.net)
Zadistes, écologistes et antifascistes sont réunis en Allemagne pour tirer les leçons des luttes passées. Alors que le mouvement Ende Gelände fête ses 10 ans, chacun·e tente de planifier les combats futurs.
- Mozilla warns Germany could soon declare ad blockers illegal (bleepingcomputer.com) – voir aussi Comment Axel Springer a relancé sa bataille contre Adblock Plus via le droit d’auteur (next.ink)
- How can England possibly be running out of water ? (theguardian.com)
- VW introduces monthly subscription to increase car power (bbc.co.uk)
German car making giant Volkswagen (VW) has introduced a subscription for UK customers wanting to increase the power of some of its electric cars. Those who buy an eligible car in its ID.3 range can choose to pay extra if they want to unlock the full power of the engine inside the vehicle. VW says the “optional power upgrade” will cost £16.50 per month or £165 annually – or people can choose to pay £649 for a lifetime subscription.
- “Airports Feel Like Ghost Towns” : US Tourism Reels as European Boycott Slashes Visitor Numbers and Drains Billions From the Economy (rudebaguette.com) – voir aussi “America first” : le tourisme étranger recule aux États-Unis sous l’effet de Donald Trump (france24.com)
En marge d’une conférence de presse avec Volodymyr Zelensky, lundi 18 août, Donald Trump s’est vanté qu’aucun étranger en situation irrégulière n’ait franchi les frontières américaines ces derniers mois. Mais ce qu’il oublie de dire, c’est que ce sont aussi les touristes étranger·es qui désertent désormais les États-Unis.
- Palantir profite à fond de l’élection de Donald Trump (next.ink)
- SpaceX says states should dump fiber plans, give all grant money to Starlink (arstechnica.com)
- Deeply divided Supreme Court lets NIH grant terminations continue (arstechnica.com)
The result was a decisive win for the scientists. As the ruling explained, the government’s termination efforts violated a statute against “arbitrary and capricious” policies, resulting in a stay that both blocked implementation of the policy and restored the flow of research funding.
- Library receives donations to replace books church leaders targeted for LGBTQ+ themes (kentuckylantern.com)
The Kentucky Lantern reported Aug. 18 that three leaders of the Reformation Church of Shelbyville urged its members to remove books from the Shelby County Public Library by checking them out and never returning them. The books portray gay characters and historical figures or explore LGBTQ+ themes.
- From Book Bans to Internet Bans : Wyoming Lets Parents Control the Whole State’s Access to The Internet (eff.org)
If you’ve read about the sudden appearance of age verification across the internet in the UK and thought it would never happen in the U.S., take note : many politicians want the same or even more strict laws. As of July 1st, South Dakota and Wyoming enacted laws requiring any website that hosts any sexual content to implement age verification measures.
- Columbia Tries to Undermine Its Unions, Hire Scab Instructors (labornotes.org)
Imagine you get a letter from your manager a week before you are set to teach classes, removing you from teaching duties but saying you’ll get paid anyway. […] Getting paid to not teach might sound pretty good, but in fact the university is hiring adjuncts with no union contract to do the work of union members.
- Ugly Laws : The Blueprint For Trump’s Anti-Homeless Crusade (motherjones.com)
DC’s crackdown is just the latest in a long war on being poor and disabled in public.
- Trump Administration Helped Netanyahu’s Cyber Chief After His Las Vegas Arrest for Child Sex Crimes (thenorthstar.com)
Caught in a U.S. child predator sting, Netanyahu’s cyber chief was charged and jailed — until Trump’s White House intervened to make sure he got back to Israel safely.
- Trump Confesses that the United States Is a Client of Russia (emptywheel.net)

- « Je suis sans voix, c’est incroyable ! » : Poutine offre une moto à un Américain qui ne pouvait réparer la sienne, faute de pièces détachées russes (liberation.fr)
Ce citoyen d’Alaska avait été interviewé par des journalistes de la chaîne d’Etat russe, en amont du sommet du 15 août. Il leur avait montré son deux-roues, d’une marque initialement russe, qu’il ne pouvait pas réparer à cause de pièces difficiles à obtenir depuis la guerre en Ukraine.
- OpenExo dévoile un incroyable exosquelette open source, complet et gratuit (neozone.org)
À une époque où les subventions fédérales diminuent, les systèmes open source sont devenus de plus en plus essentiels pour faciliter la recherche de pointe sur la rééducation assistée par robot et l’augmentation de la mobilité
- Venezuela mobilizes its militia after US says it’s deploying military forces to waters around Latin America (edition.cnn.com)
Spécial IA
- AI giants race to scoop up elusive real-world data (restofworld.org)
OpenAI, Google, and Perplexity create partnerships and free offers for a steady stream of consumer data that can’t be scraped from the internet.
- US Tech Stocks Hit By Concerns Over Future of AI Boom (tech.slashdot.org)
- “AI” skepticism went mainstream this week (buttondown.com)
After years of non-stop hype and bloviation, a flood of recent news stories suggest the tide may be turning on “AI”. Headlines this week announced AI is a “mass delusion event,” “a big nothing,” and even warned readers to “get ready for the crash.”
- GPT-5 Pro impressionne mais demeure très éloigné de la véritable intelligence artificielle générale (fredzone.org)
L’expert insiste sur l’importance de distinguer performance spectaculaire et compréhension véritable. GPT-5 Pro peut éblouir par ses démonstrations, mais l’inférence statistique sous-jacente reste fondamentalement superficielle. Tout en reconnaissant l’utilité pratique indéniable de l’outil, Goertzel met en garde contre la confusion conceptuelle entre capacités mimétiques avancées et intelligence générale authentique.
- Humans intervened every 9 minutes in AAA test of driver assists (arstechnica.com)
- Microsoft Warns Excel’s New AI Function ‘Can Give Incorrect Responses’ in High-Stakes Scenarios (slashdot.org)
- Mark Zuckerberg Shakes Up Meta’s A.I. Efforts, Again (nytimes.com)
Meta internally announced a new restructuring of its artificial intelligence division amid internal tensions over the technology
- AI Website Builder Lovable Abused for Phishing and Malware Scams (hackread.com)
- Google’s AI could lead you into scam support numbers on Search (digitaltrends.com)
Beware the next time Google’s AI saves you a few clicks and directly serves customer support helplines.
- Google says a typical AI text prompt only uses 5 drops of water — experts say that’s misleading (theverge.com)
Google shared a study of Gemini’s environmental impact, but it omits some key data.
- IA : ChatGPT-5 consommerait autant d’électricité que 3 millions de foyers français (humanite.fr)
La dernière version de l’intelligence artificielle générative d’OpenAI, la plus utilisée au monde, est vendue comme plus efficace, avec toujours plus de paramètres, mais elle est aussi toujours plus gourmande en énergie et en eau.
- Big Tech’s “AI for good” spending increases in Africa. So does skepticism (restofworld.org)
While Google, Microsoft, and Meta provide AI for social good, some advocates say projects exploit the continent for data, erode local control.
- The Mongolian startup defying Big Tech with its own LLM (restofworld.org)
Egune is one of several linguistically and culturally aware AI models built by smaller nations to reduce reliance on American and Chinese tech giants.
- L’IA Siri a-t-elle été créée par Luc Julia ? Itinéraire d’une approximation médiatique (next.ink)
- Friends Don’t Let Friends Prompt (buttondown.com)
- Fiches d’Auto-défense contre l’IA générative (pigeongratuit.wordpress.com)
Spécial Palestine et Israël
- Enfer ininterrompu : Les détenus de Gaza confrontés à de graves tortures et à la terreur israéliennes derrière les barreaux – Point de presse de la Commission des affaires des détenus et de l’Association des prisonniers palestiniens (infolibertaire.net)
- Gaza : l’ONU déclare officiellement la famine dans le territoire palestinien, 500 000 personnes touchées (huffingtonpost.fr)
Le rapport d’un organisme des Nations Unies pointe l’état « catastrophique » de centaines de milliers de Gazaouis, victimes de l’« obstruction systématique d’Israël ».
- La famine à Gaza officiellement déclarée par l’ONU : Israël préfère dénoncer « les mensonges du Hamas » (humanite.fr)
Ce vendredi 22 août, les Nations unies ont reconnu la famine dans la bande de Gaza. Une première au Moyen-Orient, alors que 500 000 personnes se trouvent dans un état « catastrophique », rapporte ses experts.
- Israeli army database suggests at least 83 % of Gaza dead were civilians (972mag.com)
Classified intelligence from May reveals Israel believed it had killed some 8,900 militants in its attacks on Gaza, indicating a proportion of civilian slaughter with few parallels in modern warfare, a joint investigation finds.

- Cisjordanie : le nouveau projet de colonie du gouvernement israélien sera voté demain (carte exclusive) (legrandcontinent.eu)
Alors que le commandement de Tsahal a approuvé la semaine dernière de nouveaux plans visant à intensifier l’offensive armée israélienne à Gaza, le ministre d’extrême-droite Bezalel Smotrich veut faire approuver un nouveau projet de colonie qui couperait de facto en deux la Cisjordanie, en menaçant à terme la création d’un État palestinien.
- La colonie E1, le vaste projet d’Israël en Cisjordanie pour « enterrer » tout possible État palestinien (huffingtonpost.fr)
Validé par Israël, ce projet massif de colonisation prévoit de couper en deux la Cisjordanie, avec la volonté assumée d’empêcher la reconnaissance d’un État palestinien.
- Plan israélien pour Gaza : “Nous nous préparons bel et bien à lancer la conquête de Gaza”, confirme l’ambassadeur d’Israël en France (franceinfo.fr)
- Projet E1 : 21 pays, dont le Royaume-Uni et la France condamnent le plan israélien de colonisation en Cisjordanie (humanite.fr)
- Face aux accusations en antisémitisme de Netanyahou, la France et l’Australie répliquent (humanite.fr)
Canberra a fustigé […] le « déchaînement » de critiques de Tel-Aviv, dont le dirigeant a aussi accusé Anthony Albanese d’être un « politicien faible » qui a « trahi » Israël. « La force ne se mesure pas au nombre de personnes que vous pouvez faire exploser ou d’enfants que vous pouvez laisser affamés », a rétorqué le ministre des Affaires intérieures australien Tony Burke
- Accusé d’attiser l’antisémitisme par Netanyahou, Macron pris au piège de la propagande israélienne (humanite.fr)
Dans un courrier officiel adressé à l’Élysée, le premier ministre israélien accuse le président français « d’alimenter le feu antisémite » en reconnaissant l’État de Palestine. L’ironie est amère : c’est exactement la rhétorique employée par les macronistes depuis presque deux ans contre les défenseurs de Gaza.
- Après la lettre de Netanyahu sur l’antisémitisme, la réponse cinglante de l’Élysée (huffingtonpost.fr)
Le Premier ministre israélien a estimé que la volonté d’Emmanuel Macron de reconnaître l’État palestinien nourrissait l’antisémitisme.
- Censure de Kneecap : face au maintien du groupe à Rock en Seine, la région Île-de-France retire ses 500 000 euros de subvention (humanite.fr)
Le groupe de rap originaire de Belfast, fervent soutien du peuple palestinien, est la cible de la région Île-de-France. Sa présidente Valérie Pécresse a décidé, jeudi 21 août, de retirer la subvention jusqu’ici reversée chaque année au festival Rock en Seine, où doit se produire le trio.
- Des alpinistes ont accroché un drapeau palestinien de 145 m2 sur le pic du Petit Dru afin de dénoncer « l’inaction des gouvernements face au génocide en cours à Gaza ». (huffingtonpost.fr)
Ce drapeau devait être initialement suspendu « pendant trois jours », précise le collectif. Mais il a été retiré dès le 17 août par hélicoptère par les unités de montagne de la gendarmerie nationale sur demande de la préfecture et de la mairie, justifiant que le site est classé […] « Les autorités ont déployé de grands moyens pour tenter de le décrocher par hélicoptère, dans cette face raide et difficile d’accès. La mobilisation disproportionnée de la gendarmerie pour enlever ce drapeau, comme la répression des drapeaux palestiniens sur le Tour de France, nous interroge : un symbole d’espoir pour un peuple opprimé est-il devenu une offense ? »
- L’ULB veut-elle empêcher que la promotion de droit ne porte le nom de Rima Hassan, eurodéputée française ? (rtbf.be)
- Aux États généraux du film documentaire, à Lussas, la nécessaire diffusion des images parvenues de Gaza (humanite.fr)
Le rendez-vous estival du cinéma documentaire projette quatre longs métrages sur le sort des Palestiniens, dont le film de Sepideh Farsi, Put Your Soul in Your Hand and Walk, en plein air. Toutes ces œuvres donnent accès à la parole tue des Gazaouis.
- Gaza : le devoir de nommer et d’agir (humanite.fr)
La Convention pour la prévention et la répression du crime de génocide, adoptée en 1948, expressément applicable devant la Cour internationale de Justice (CIJ) n’a pas été conçue pour constater un crime une fois qu’il est trop tard, mais pour l’empêcher. Elle impose d’agir dès qu’un risque plausible est établi, bien avant la certitude judiciaire.

- Témoignage de Zahra* : Quand un collectif pour la paix invisibilise des voix palestiniennes (humanite.fr)
- Appel syndical à mettre fin au génocide contre le peuple palestinien. (laboursolidarity.org)
Spécial femmes dans le monde
- Préservatifs écolos : les options éthiques, véganes et naturelles (reporterre.net)
l’utilisation du préservatif est en baisse chez les jeunes Européens : entre 2014 et 2022, elle est passée de 70 à 61 % chez les garçons de 15 ans et de 63 à 57 % chez les filles du même âge, et un tiers des jeunes hommes refuse catégoriquement de mettre une capote.
Le résultat d’étude pas bien étonnant de la semaine
Spécial France
- Le groupe La Poste a annoncé ce vendredi 22 août à l’AFP qu’il allait suspendre dès le 25 août les envois de colis vers les États-Unis. (huffingtonpost.fr)
Seule exception préservée par le groupe public français à ce stade : les envois de cadeaux entre particuliers, d’une valeur de moins de 100 euros.
- Cyclotourisme : « Le train est un obstacle à l’utilisation du vélo en vacances ! » (capital.fr)
- La FDSEA menace de vider les rayons des produits avec des pesticides interdits (rue89strasbourg.com)
La FDSEA et les Jeunes Agriculteurs ont annoncé se mobiliser contre la censure de la loi Duplomb à partir du 20 août dans les supermarchés. Ils estiment avoir le droit d’utiliser les mêmes pesticides que leurs voisins européens.
- Des métaux lourds dans le chocolat : l’UFC-Que choisir met en garde contre la présence de cadmium, cancérigène et toxique (humanite.fr)
En France, 47 % des adultes et près d’un enfant sur cinq affichent des niveaux de cadmium supérieurs à ceux recommandés par les autorités sanitaires, en faisant un des pays les plus touchés au monde. L’Anses recommande aussi de baisser la concentration maximale de cadmium autorisée dans les engrais phosphatés à 20 mg/kg, contre 60 mg/kg actuellement.
- « C’est une lente agonie » : 8 000 oiseaux « crèvent » du botulisme dans les marais de Loire-Atlantique (vert.eco)
« Le botulisme, j’en vois chaque année en Brière, mais à ce point, c’est inédit depuis les années 1990 […] Les fortes chaleur de juin, le faible niveau d’eau et le manque d’oxygène qui lui est dû, ont permis à la bactérie de se développer. » Le « lien avec le réchauffement climatique est certain »
- Aux municipales 2026, Marine Tondelier veut faire « polliniser » l’écologie (humanite.fr)
Après leur succès de 2020, les Écologistes ne cachent pas leurs ambitions. Outre la conservation des villes qu’ils dirigent déjà comme Lyon, Strasbourg ou Bordeaux, les Verts veulent conquérir Caen et Lorient tout en participant à faire basculer d’autres communes grâce à l’union de la gauche.
Spécial femmes en France
- La légalisation de la GPA, prochain débat que Gabriel Attal veut lancer à Renaissance (huffingtonpost.fr)
Le secrétaire général du parti présidentiel souhaite remettre dans le débat la question de la gestation pour autrui, aujourd’hui interdite en France.
- Alexandra Rosenfeld dénonce l’emprise de Jean Imbert quatre mois après avoir témoigné anonymement (huffingtonpost.fr)
Sur Instagram, l’ex-Miss France a pris la parole en son nom pour accuser le chef de violences, et revenir sur le témoignage qu’elle avait livré anonymement à « ELLE » en avril.
- Huit familles portent plainte dans l’affaire des abus sexuels sur des bébés à l’hôpital de Montreuil (huffingtonpost.fr)
Juliette S. et Redouane E. ont été mis en examen début août pour agressions sexuelles sur mineur·es et captation d’images à caractère pédopornographique.[…] Début août Juliette S. s’est rendue au commissariat pour reconnaître les faits, tout en affirmant que son compagnon Redouane E. était l’instigateur.
Spécial médias et pouvoir
- Journalistes assassinés à Gaza : cessons le “version contre version” (arretsurimages.net)
- La France Insoumise bannit de ses universités d’été un journaliste du Monde, co-auteur d’un livre-enquête à succès (lefigaro.fr)
- Comment vont les 500 familles les plus riches de France ? (frustrationmagazine.fr)
Chaque été, le magazine patronal Challenges publie son classement des 500 familles les plus riches de France. Ce numéro est une petite bible de la lutte des classes : car malgré les efforts, de plus en plus pathétiques, qu’ont les journalistes à légitimer le niveau d’enrichissement de la grande bourgeoisie, les mécanismes de sa domination apparaissent de façon de plus en plus criante.
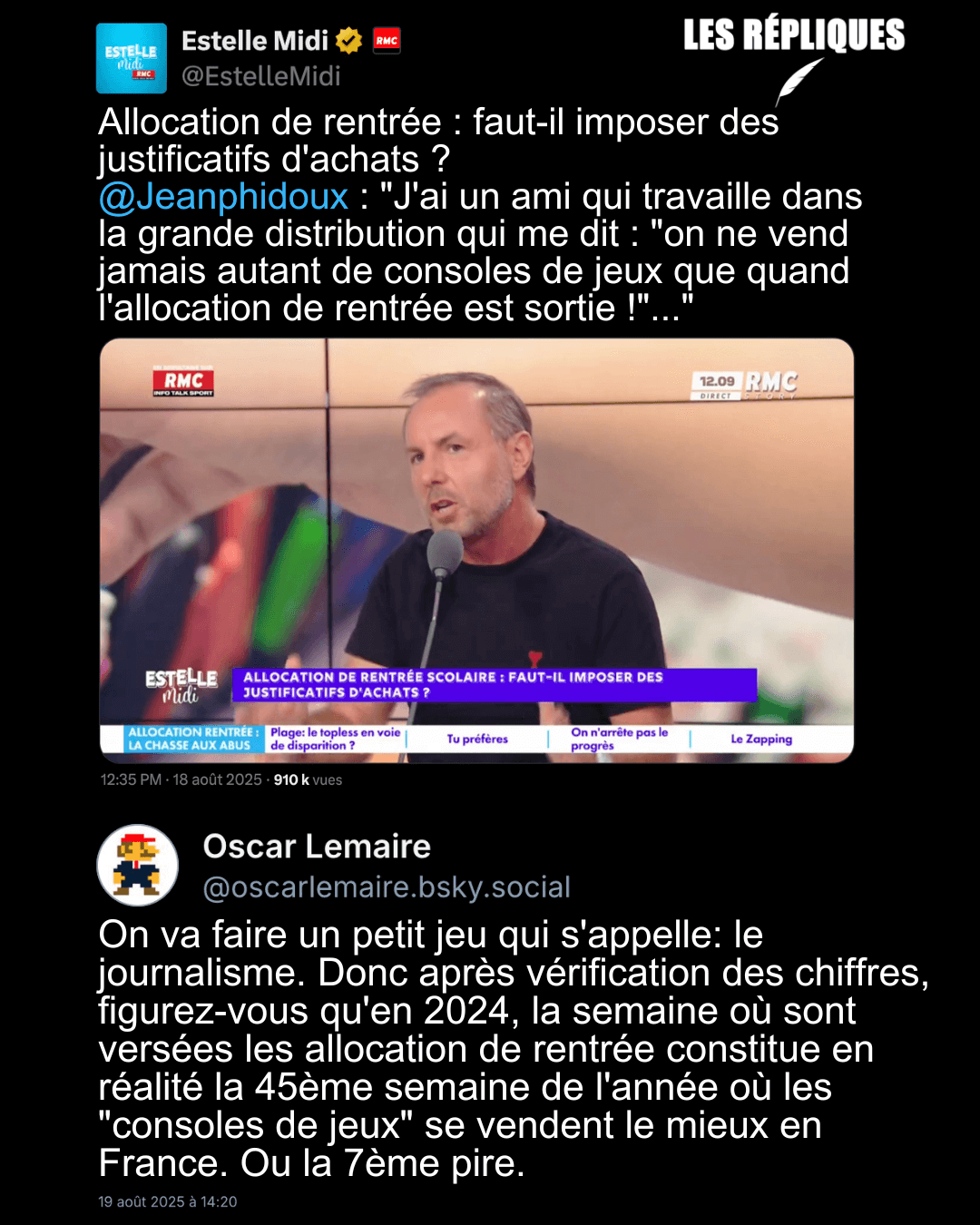
- Le streamer Jean Pormanove meurt en direct vidéo sur la plateforme Kick, une enquête ouverte (lavoixdunord.fr)
Kick est connue pour ne pas réglementer ses contenus, ce qui permet de diffuser des événements en direct parfois très violents et humiliants […] Jean Pormanove aurait participé à une vidéo en direct très éprouvante récemment, avec « dix jours et nuits de torture », avec des violences physiques « extrêmes » et l’ingestion supposée « de produits toxiques ». Derrière son écran, le public peut verser des dons pour les encourager. Mediapart indique que deux hommes lui infligeaient ces sévices : « Safine » et… « Naruto ». Dans un article paru fin 2024, nos confrères révélaient les dérives de Kick et le calvaire subi notamment par Jean Pormanove.
Voir aussi Jean Pormanove : pour Kick, la violence est un business (frustrationmagazine.fr)
Et Handicide : quand le validisme tue (blogs.mediapart.fr)La mort de Raphaël Graven, dit Jean Pormanove, a suscité de nombreuses réactions. Pourtant, le validisme est omis des analyses. La discrimination sur le handicap, quand elle est mentionnée, n’est pas considérée dans sa dimension systémique, mais comme des torts individuels.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Emmanuel Macron juge que François Bayrou a “les capacités” pour tenir jusqu’en 2027 et répète qu’il ne veut pas de nouvelle dissolution (franceinfo.fr)
On a un Parlement qui reflète les fractures du pays. C’est aux responsables politiques de savoir travailler ensemble

- Bayrou envisage de réduire les aides aux personnes âgées et handicapées (lessentieldeleco.fr)
- La mort de Jean Pormanove est « comme la chronique d’une mort annoncée » selon la LDH (huffingtonpost.fr)
Nathalie Tehio, la présidente de la Ligue des droits de l’Homme, regrette l’inaction de l’Arcom et de la ministre Clara Chappaz, pourtant alertées à propos du streamer JP
- La fin de la 2G sera “une rupture dramatique” : ascenseurs, téléassistance, rien n’est prêt (lesnumeriques.com)
Derrière la disparition programmée des réseaux 2G et 3G se cache une réalité bien plus inquiétante que celle des vieux téléphones. Des dispositifs vitaux, encore dépendants de ces anciennes technologies, risquent tout simplement de tomber en panne.
- Centre de tri brûlé à Marseille : l’« hallucinant silence » des autorités (reporterre.net)
Quel cocktail toxique les Marseillais ont-ils respiré lors du spectaculaire incendie du 8 juillet ? Car les 750 hectares de garrigue des Pennes-Mirabeau, commune de la banlieue nord, ne sont pas les seuls à avoir brûlé : le centre de tri des déchets de la métropole Aix-Marseille-Provence, géré par Suez, a, lui aussi, été touché.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Enfermée 6 jours à cause d’une OQTF injustifiée : le cauchemar de cette étudiante de retour du Maroc (lemediatv.fr)
De retour du Maroc, Sarah, installée en France depuis 7 ans, a été enfermée 6 jours à l’aéroport. Malgré ses papiers en règle, elle a subi harcèlement et conditions inhumaines. La justice a annulé son expulsion et ordonné un titre de séjour.
- “Je dors deux heures par nuit” : la vie dans un campement parisien ciblé par des expulsions sans mise à l’abri (infomigrants.net)
Une trentaine de personnes exilées survivent dans un campement du quartier de la Chapelle, au nord de Paris, ciblé durant l’été par une série d’opérations policières “sans base légale”, selon Médecins du Monde. Un an après les Jeux olympiques, les pratiques d’évacuation sans mise à l’abri se multiplient selon l’ONG. Les exilés témoignent, eux, d’un quotidien difficile entre le bruit du métro, la précarité et le harcèlement policier.
- « L’offensive anticommuniste, une réhabilitation de l’extrême droite au service du capital » (humanite.fr)
En inaugurant une stèle « aux victimes du communisme », le maire de Saint-Raphaël (Var), soutien de Marine Le Pen, cherche à faire oublier le passé collaborationniste de l’extrême droite française et à faire taire toute contestation du capitalisme.
Spécial résistances
- 10 septembre : « Ce mouvement appelle à des actions qui débordent le répertoire syndical habituel » (humanite.fr)
- 10 septembre : qui sont les Français·es qui soutiennent l’appel « bloquons tout » ? (humanite.fr)
Près de 2 Français·es sur 3 ont exprimé leur soutien au mouvement du 10 septembre
- « Tout bloquer » le 10 septembre ? LFI appelle à y participer, les autres partis politiques embarrassés (huffingtonpost.fr)
- « Tout bloquer » le 10 septembre ? Marine Tondelier soutient le mouvement, le PS plus prudent (huffingtonpost.fr)
- SUD-Rail appelle à la grève le 10 septembre (sudrail.fr)
- CHAT CONTROL est de retour : nous avons deux mois pour agir ! (fdn.fr)
- Université d’été des mouvements sociaux et des solidarités 2025 (blogs.mediapart.fr)
Pour sa quatrième édition, l’UEMSS rassemblera environ 2000 personnes pour 4 jours de rencontres, de partage, de formations et de fête au service des luttes sociales, écologiques et solidaires !
Spécial outils de résistance
- Financement de la protection sociale : cotiser plus pour socialiser plus (alternatives-economiques.fr)
Spécial GAFAM et cie
- Panique après la dernière mise à jour Windows 11 : des SSD deviennent illisibles, voire irrécupérables (lesnumeriques.com)
Une récente mise à jour de Windows 11 pourrait littéralement mettre en péril vos données : certains utilisateurs signalent la disparition pure et simple de leurs disques après installation. Un bug que Microsoft n’avait pas prévu… mais qui pourrait coûter cher.
- Bluesky silenced trans voices over J.K. Rowling (pride.com)
Trans creators on Bluesky are raising the alarm after multiple users were suspended for posts expressing negative sentiments about J.K. Rowling—including ones that didn’t mention violence or threats.
- BlueSky Blocks Mississippi IPs, Citing State’s Age Verification Law, Free Speech and Privacy Concerns (mississippifreepress.org)
The social media platform BlueSky announced Friday afternoon that it had made “the difficult decision to block access from Mississippi IP addresses,” after the State’s new social media age-verification law forced its hand. The company cited both the prohibitive costs of complying with the law as well as concerns over privacy and free expression.
Les autres lectures de la semaine
- How the Personal Computer Took Over the World (ifixit.com)
- La toile d’araignée : merveille d’ingénierie naturelle depuis 400 millions d’années (theconversation.com)
- 20 ans après, retours sur le référendum de 2005 (4/5) (acrimed.org)
- Le Nouveau Moment Grotius (legrandcontinent.eu)
Né à Delft en 1582 et mort à Rostock en 1645, Hugo de Groot — dit Grotius — a traversé une période historique de transformations vertigineuses qui n’est pas sans rappeler celle dans laquelle nous nous trouvons.
- Casser le nouvel ordre cannibale (humanite.fr)
La rencontre entre Donald Trump et Vladimir Poutine en Alaska, suivie des discussions à la Maison-Blanche avec Volodymyr Zelensky auxquelles ont accouru, essoufflés, des dirigeants européens, constitue une accélération de la roue entraînant les actuelles bascules d’un monde violemment secoué par les polycrises du capitalisme mondialisé.
- Nouvelle-Calédonie : une première analyse géopolitique de l’Accord de Bougival (legrandcontinent.eu)
- RD Congo. Le Parc des Virunga, un siècle de colonialisme vert et de rébellions armées (afriquexxi.info)
Le Parc national des Virunga, dans l’est de la RD Congo, a 100 ans. Plus vieille réserve d’Afrique, créée durant la colonisation belge au détriment des populations locales, elle est l’une des causes anciennes de la déstabilisation, toujours en cours, de la région.
- Marie Tharp, la cartographe qui a changé la face des fonds marins (theconversation.com)
- « On sous-estime grandement le pouvoir de la fiction. En touchant le cœur, on invite à l’action » (socialter.fr)
- Travail du sexe, entre prohibition et féminisme libéral (lundi.am)
- Envie de plus d’orgasmes ? Optez pour une partenaire féminine (theconversation.com)
Le simple fait de donner la priorité à l’orgasme des femmes — en adoptant des phrases simples comme « elle passe en premier » — pourrait suffire à réduire considérablement l’écart entre les sexes en matière d’orgasme.
Les BDs/graphiques/photos de la semaine
- Résistance
- Bayrou
- Journalisme
- Canicule
- Seuil
- Vagues
- Ventilo
- Mars

- Cycle
- Mirage
- Accessibilité
- Stroke
- Évolution du réseau de chemin de fer français (histoire-itinerante.fr)
- Si seulement
- Emergency
- FAFs
- Plan
{kind=link}
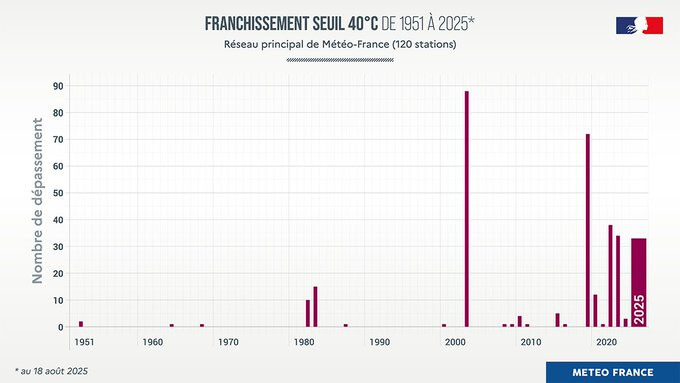{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
Les trucs chouettes de la semaine
- Tous les élèves des Pyrénées-Orientales pourront bientôt apprendre le catalan, de la maternelle à l’université (francebleu.fr)
L’Etat, la région Occitanie et le département des Pyrénées-Orientales signent ce mercredi un accord historique, sous l’égide de l’Office de la langue catalane. Il s’agit, d’ici dix ans, de permettre à tous les élèves du département de pouvoir apprendre le catalan dans les établissements scolaires.
- Surdité et UX Design – avec Emmanuelle Aboaf (iamtamara.design)

- Comment rendre une conférence ou une présentation accessible ? Bonnes pratiques et outils (access42.net)
L’accessibilité numérique est souvent la grande oubliée des conférences et des présentations. Pourtant, il y a des éléments importants à prendre en compte pour que les personnes handicapées puissent accéder aux mêmes informations que les personnes valides tout en ayant une expérience agréable.
- Internet Artifacts : une frise chronologique des principaux moments des débuts de l’internet (neal.fun)
- Oubliez Excel ! Le gouvernement français a sa propre version gratuite et libre (clubic.com)
Grist réunit tableur, base de données et automatisation dans un outil gratuit, libre et sécurisé.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Lava
- La revue des médias
- Le Grand Continent
- Le Diplo
- Le Nouvel Obs
- Lundi Matin
- Mouais
- Multitudes
- Politis
- Regards
- Smolny
- Socialter
- The Conversation
- UPMagazine
- Usbek & Rica
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- Contretemps
- A Contretemps
- Alter-éditions
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- Philo Mag
- Terrestres
- Vie des Idées
- ARTS
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- INTERNATIONAL
- Alencontre
- Alterinfos
- CETRI
- ESSF
- Inprecor
- Journal des Alternatives
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview
- Fiabilité 3/5
- Slate
- Ulyces
- Fiabilité 1/5
- Contre-Attaque
- Issues
- Korii
- Positivr
- Regain