
30.06.2026 à 16:49
Savoir nager est essentiel, mais ne suffit pas à prévenir les noyades
Emmanuel Auvray, Enseignant à l'UFR STAPS, Chercheur associé à l'équipe Histemé, Université de Caen Normandie
Texte intégral (1950 mots)
Durant l’épisode caniculaire que vient de traverser la France, le regain de baignades dans les espaces naturels, mais aussi en ville s’est accompagné d’une hausse marquée des noyades. Si la maîtrise des techniques de natation ne protège donc pas de tous les risques en milieu naturel, comment développer concrètement les réflexes de prévention nécessaires à tous les âges ?
Depuis le 18 juin 2026 en France, le ministre l’intérieur Laurent Nuñez a annoncé le décès par noyade de 74 personnes durant une période marquée par un épisode caniculaire. Comme le montrent les données de la surveillance épidémiologique des noyades menée par Santé publique France (2025), les épisodes de fortes chaleurs s’accompagnent d’une augmentation du nombre de noyades, dans la mesure où un plus grand nombre de personnes se baignent pour se rafraîchir.
Pour autant, une fois encore, d’aucuns attribuent ces noyades au fait que les Français ne sauraient pas nager du fait du manque de piscines permettant d’enseigner la natation.
Cette explication, souvent avancée dans le débat public, est-elle, à elle seule, suffisante pour comprendre et endiguer cette hécatombe ?
Différencier cause et corrélation
Entre le 1er juin et le 30 septembre 2025, 1 418 noyades ont eu lieu en France, dont 409 ont été suivies de décès. Ces chiffres pour l’été 2025 sont en hausse par rapport à la même période en 2024, où il y avait eu 1 246 noyades et 350 décès.
Les décès par noyade en cours d’eau ou plans d’eau ont représenté environ la moitié de ces décès, quel que soit l’âge. Pour les autres lieux, les décès par noyade ont davantage eu lieu en piscine privée en ce qui concerne les mineurs et en mer en ce qui concerne les adultes.
Bien que nous ne disposions pas encore de données précises sur les noyades de juin 2026, il semble qu’il s’agit principalement d’adolescents et de jeunes adultes masculins dans des lieux de baignade non surveillés, voire interdits. Si l’on se réfère aux bilans des années précédentes, nous savons que le fait de ne pas savoir nager était en cause dans 10 % des décès par noyade.
Dès lors, l’idée selon laquelle il existerait une forte corrélation entre le fait de ne pas savoir nager et se noyer mérite d’être nuancée. Dans la grande majorité des cas, les gens se noient dans des contextes où la maîtrise des techniques de nage ne prémunit ni contre les dangers propres à l’environnement (courants, vagues, variations de profondeur, température de l’eau, obstacles, etc.), ni contre les erreurs d’appréciation ou les comportements à risque.
Si le fait de ne pas savoir nager représente indéniablement un facteur de risque, il ne saurait, à lui seul, expliquer la survenue des noyades. Celles-ci résultent le plus souvent d’une combinaison de facteurs individuels, environnementaux et comportementaux.
L’apprentissage et la question des équipements
Face à un parc de piscines publiques vieillissant et particulièrement énergivore, l’État et les collectivités territoriales doivent poursuivre la mobilisation engagée par la ministre des Sports Roxana Maracineanu (2019-2022) en faveur de l’apprentissage de la natation et du développement des équipements. L’objectif est de permettre au plus grand nombre d’apprendre à nager dans le cadre scolaire, au sein du milieu associatif et à l’échelle des communes.
Or, la situation n’est pas homogène d’un territoire à un autre. Par exemple, entre la Seine-Saint-Denis et le reste de la France, malgré une hausse des ressources publiques consacrées au savoir-nager et aux équipements, l’écart par rapport à la moyenne nationale (86 %) continue de croître. Entre 2012 et 2023, on relève une baisse de 20 points de la maîtrise du savoir nager en dix ans (66 %) qui interroge l’organisation d’une éducation aquatique de qualité.
D’un autre côté, on ne compte plus les fermetures de piscines en raison de leur état de délabrement. Selon les estimations, il manque environ 400 piscines pour permettre un apprentissage plus massif de la natation et réduire ainsi les inégalités d’accès sur le territoire national.
Le développement de centres aquatiques et parcs de loisirs ne doit pas masquer une réalité préoccupante : la France manque aujourd’hui de piscines « basiques », c’est-à-dire d’équipements prioritairement pensés pour l’apprentissage de la natation et l’entraînement. Sans compter l’augmentation des dépenses, à la charge des collectivités, que supposent le déplacement des scolaires sur des piscines de plus en plus éloignées des établissements et sous tension pour obtenir des créneaux.
Comme le réclame le champion olympique Alain Bernard, il faudrait déployer « un plan Marshall » pour équiper de manière plus homogène la France de ce type de bassins. À l’heure où, face au réchauffement climatique, nous observons un regain d’intérêt pour la baignade urbaine et l’apprentissage de la natation en milieu naturel.
Bien que limitées dans l’espace et le temps et à rebours de l’histoire de l’enseignement de la natation scolaire, ces tendances sont légitimes et intéressantes. En miroir de ce qui se fait à l’étranger depuis déjà de nombreuses années (Danemark, Allemagne), elles offrent l’occasion, en plus des piscines, de pouvoir se baigner au cœur des villes, comme à Nantes et Paris, et d’apprendre à nager en analysant son environnement de nage naturel et tenir en conséquence les bonnes conduites face aux risques et vicissitudes d’un espace ouvert, en étant surveillés par des professionnels qualifiés.
Mettre l’accent sur la prévention
Inscrit, depuis 2006, dans le socle commun de connaissances et de compétences du collège, le savoir-nager est une priorité nationale qui s’inscrit dans le prolongement de l’aisance aquatique développée à l’école primaire. Or, selon les résultats fournis par le projet européen « Aquatic Literacy For All Children » (ALFAC), les enfants français ont un retard significatif par rapport aux standards européens. S’ils présentent un niveau inférieur dans les habiletés motrices aquatiques de base, ils progressent avec l’âge, sans toutefois combler l’écart avec les autres pays.
Comme le soulignent les travaux en matière de littératie aquatique, c’est-à-dire la capacité à évoluer en sécurité, avec confiance et plaisir dans le milieu aquatique, la prévention de la noyade fait encore souvent défaut dans les programmes de formation chez les 4 à 12 ans tant du côté des parents que des apprenants.
Les jeunes sont sensibles à un discours préventif même dès leur plus jeune âge. Du côté de l’attestation du savoir-nager en sécurité (ASNS), il repose sur l’enchainement, sans lunettes de natation, de 9 actions. Sa validation atteste de la maîtrise des compétences permettant d’évoluer en sécurité dans un milieu surveillé et fermé. En outre, il comprend l’enseignement d’un ensemble de connaissances et d’attitudes qui relève de la prévention :
savoir identifier la personne responsable de la surveillance à alerter en cas de problème ;
connaître et respecter les règles de base liées à l’hygiène et la sécurité dans un établissement de bains ou un espace surveillé ;
savoir identifier les environnements et les circonstances pour lesquels l’ASNS permet d’évoluer en sécurité.
Selon nos observations, ces dimensions ne sont pas suffisamment prises en compte et certifiées pour apprendre à l’élève à en faire un bon usage en fonction des lieux : piscine publique, piscine privative, espaces naturels surveillés ou non, etc. Pourtant, nous disposons aujourd’hui d’un ensemble d’outils pédagogiques qui permettent de prévenir et éduquer aux dangers de la baignade.
Adapter les baignades selon les âges de la vie
En ce qui concerne les noyades chez les adultes en 2025, par rapport à 2024, le nombre de noyades suivies de décès en mer a augmenté de 20 % et avec l’âge. En matière de prévention, il faut les sensibiliser au fait de faire évoluer leur manière de se baigner aux différents âges de leur vie. Par exemple, au lieu de nager en mer en s’éloignant de la plage pour aller rejoindre la bouée des 300 m, il devient plus raisonnable de nager parallèlement à la plage.
En vieillissant, il faut pas hésiter à demander l’avis d’un professionnel pour adapter sa nage à son état de santé et à sa condition physique avant de s’aventurer trop loin et trop longuement.
Réduire les noyades à une seule question de savoir-nager ou de déficit d’infrastructures revient à occulter la complexité du phénomène. Les circonstances de survenue des noyades mettent également en jeu d’autres facteurs : la surestimation de ses propres capacités, la méconnaissance des risques liés aux milieux aquatiques, les comportements à risque, la consommation d’alcool, les conditions environnementales, ou encore l’absence d’une véritable culture de la prévention en fonction des âges de la vie.
Dès lors, la lutte contre les noyades ne peut se limiter au seul apprentissage des techniques de nage ; elle suppose également le développement d’une véritable éducation à l’aisance aquatique, à la gestion du risque et à la prise de décision dans des espaces surveillés ou non par des professionnels qualifiés. Également exposée aux conséquences des épisodes caniculaires, cette profession est sous tension et mérite la plus grande attention de la part des pouvoirs publics et le respect des baigneurs/nageurs.
Emmanuel Auvray ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
30.06.2026 à 16:48
Le retour de la 2CV – en version électrique : nostalgie ou solution pour une mobilité plus sobre ?
Marc Prieto, Professeur-HDR, directeur de l'Institut ESSCA "Transports & Mobilités Durables", ESSCA School of Management
Texte intégral (1612 mots)

.jpg){kind=link}
La 2CV électrique illustre une recomposition des stratégies automobiles : mobiliser l’héritage pour accompagner la décarbonation. Un cas révélateur des tensions entre innovation, coût et usages.
L’industrie automobile est-elle à ce point en difficulté qu’elle doive puiser dans ses modèles mythiques pour soutenir une électrification encore hésitante ? En 2026, le rétro marketing appliqué aux véhicules électriques connaît un véritable essor, notamment autour d’icônes populaires : Fiat 500, Mini, Renault 5 ou encore Renault 4L.
Plutôt qu’un manque d’inspiration des designers, cette tendance traduit surtout un choix stratégique assumé : capitaliser sur des modèles familiers pour rassurer les consommateurs face à une transition technologique encore incertaine.
Parmi ces icônes, l’une manquait encore à l’appel : la Citroën 2CV (deux chevaux-vapeur). Le groupe Stellantis a levé le voile en annonçant son retour à l’horizon de 2028 dans le cadre de son plan « FaSTLAne 2030 ».
Quand le passé éclaire le futur
Ce recours au passé n’est pas inédit chez Citroën. Dès les années 2010, la DS3 avait déjà mobilisé l’héritage de la mythique DS. Dans nos travaux de 2014, nous montrions qu’il ne s’agissait pas d’un simple exercice nostalgique, mais d’une variante stratégique du rétro marketing reposant sur l’utilisation d’un nom iconique, sans reprise du design d’origine, afin de projeter le nouveau modèle, qui deviendra par la suite une marque à part entière, vers le segment premium.
À lire aussi : La voiture électrique accessible à tous ? Les marges de manœuvre limitées des constructeurs européens
Aujourd’hui, avec la future 2CV, Citroën adopte une logique presque inverse. L’objectif n’est plus de monter en gamme, mais au contraire de rendre accessible la mobilité électrique, avec un véhicule annoncé autour de 15 000 €.
Autrement dit, là où la DS3 utilisait le passé pour justifier un positionnement haut de gamme, la 2CV pourrait l’utiliser pour légitimer une offre frugale.
L’émergence des « e-cars »
Le projet dépasse toutefois le simple cadre du marketing. Il s’inscrit dans une évolution réglementaire européenne avec l’apparition des « e-cars » (catégorie M1E). Cette nouvelle catégorie permet de concevoir des véhicules compacts, plus légers et moins coûteux, tout en autorisant des dérogations à certaines obligations de sécurité, notamment celles liées à la réglementation GSR2, particulièrement onéreuses.
L’objectif – accélérer la démocratisation de la voiture électrique – est clair. Mais cette simplification a une contrepartie. Les performances restent limitées, avec une autonomie souvent inférieure à 200 kilomètres et des capacités de recharge réduites. Ces véhicules sont donc avant tout conçus pour un usage urbain ou des déplacements de portée limitée.
Dès lors, la future 2CV pourra‑t‑elle rester fidèle à l’esprit de polyvalence de l’originale, pensée pour la France rurale ?
Basculement stratégique
Le contraste avec la DS3 est particulièrement éclairant.

.jpg){kind=link}
La DS3 reposait sur une forme d’« authenticité symbolique » : le client acceptait un prix élevé parce qu’il achetait un produit moderne adossé à un héritage prestigieux. Avec la 2CV, le défi est différent. Il s’agit de maintenir un prix bas, ce qui implique des choix industriels forts, notamment le recours à une plateforme technique issue du partenaire chinois Leapmotor.
Tableau comparatif des stratégies DS3 et 2CV (2028)
Le principal risque tient au fait qu’un décalage peut apparaître entre l’image iconique et la réalité technique, tandis que les usages pourraient se retrouver contraints. Le succès ne dépendra donc pas seulement du design ou du nom, mais de la cohérence entre le produit et la promesse historique de la 2CV.
La nostalgie, une fenêtre stratégique de court terme
Au fond, la nostalgie n’est qu’un point d’entrée. Si elle semble en effet servir de « pont » entre le passé et la transition écologique, elle s’apparente plutôt à une phase ayant vocation à se refermer à l’instar de Renault dont le directeur marketing a récemment indiqué vouloir clôturer ce cycle. La 2CV pourrait ainsi jouer un rôle clé en rendant acceptable une technologie électrique contraignante, caractérisée par une autonomie limitée et des usages plus ciblés, grâce à son ancrage dans un imaginaire collectif positif.
Ce que révèle le retour de la 2CV, c’est une mutation plus profonde. La contrainte budgétaire devient un argument de marketing, la simplicité retrouve ses lettres de noblesse tandis que la sobriété, sans encore s’imposer pleinement, gagne en légitimité et pourrait, à certaines conditions, séduire un public plus large.
L’enjeu est donc moins de faire revivre le passé que de redéfinir la valeur automobile à l’ère de la décarbonation. Cependant, une fois l’effet nostalgique dissipé, la réussite dépendra d’un critère simple : le véhicule répond‑il réellement aux besoins des usagers ? Sur ce point, rien n’est moins sûr. Plusieurs constructeurs s’y sont déjà essayés avec des succès mitigés, à l’instar du groupe Renault avec la Dacia Spring. Ce véhicule électrique urbain fut lancé en Europe en 2021 par le groupe Renault à travers sa marque Dacia, positionné comme l’une des offres les plus abordables du marché, avec une batterie d’environ 26,8 kilowattheures (kWh) offrant une autonomie autour des 220 kilomètres (cycle WLTP). En matière de diffusion, elle totalise en Europe environ 200 000 unités vendues depuis son lancement (près de cinq fois plus pour la Renault Clio sur la même période).
Si les progrès technologiques permettent d’étendre significativement l’autonomie des batteries et d’améliorer les conditions de recharge, ces petites voitures sont appelées à s’imposer bien au‑delà des usages urbains, des ménages multi-équipés et des flottes d’entreprise. Elles constituent ainsi un levier crédible et structurant de la transition vers une mobilité décarbonée.
Marc Prieto ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
30.06.2026 à 16:44
Le droit d’association : un fondement de notre démocratie, aujourd’hui fragilisé
Timothée Duverger, Responsable de la Chaire TerrESS de Sciences Po Bordeaux, Sciences Po Bordeaux
Texte intégral (1996 mots)
Pendant une grande partie du XIXe siècle, s’associer pour défendre des intérêts communs a suscité la méfiance du pouvoir. De la répression des coalitions ouvrières à la consécration de la fameuse loi de 1901, le droit d’association est le produit d’une histoire politique mouvementée, où se jouent les rapports entre État, société et libertés collectives. Retour sur cette longue conquête à l’occasion du 125ᵉ anniversaire de la loi relative au contrat d’association.
Pour parvenir à l’adoption de cette loi de liberté, il aura fallu à la IIIᵉ République trente ans et 34 projets, propositions de loi ou rapports au Parlement. Et surtout plus d’un siècle de luttes sociales depuis le décret d’Allarde et les lois Le Chapelier. Ceux-ci ont aboli le système des corporations et interdit toute association de personnes d’un même métier en 1791, à la fois pour libérer l’individu des anciennes structures collectives et pour limiter les contre-pouvoirs, ce qui a durablement marqué la culture politique française.
Très rapidement après, des municipalités ont cependant encouragé les accords collectifs entre maîtres et compagnons d’un même métier. Et, au niveau réglementaire, l’article 291 du Code pénal de 1810 a aménagé la loi en laissant libres les associations de moins de 20 membres et en soumettant les autres à l’agrément pour leur création et l’autorisation pour leurs réunions.
C’est, ainsi, à la fois en continuité avec les formes de solidarités traditionnelles, incarnées par le compagnonnage ou les confréries issues de l’Ancien Régime, et en rupture avec celles-ci, puisqu’elles les modernisent avec la liberté d’adhésion, que les associations se décantent progressivement au début du XIᵉ siècle.
La notion elle-même d’association apparaît dans les années 1830, avec une certaine polysémie. Elle peut recouvrir une fonction de défense professionnelle pour réguler le travail et notamment négocier les tarifs vis-à-vis des maîtres. Elle se cache alors souvent sous les dehors plus respectables de sociétés de secours mutuel qui lui servent de paravent. Mais l’association peut aussi fournir du travail aux ouvriers désœuvrés, en particulier lors de grèves, pour prendre la forme d’une association de producteurs. L’association peut enfin viser le rassemblement des ouvriers de toutes les professions, dont se fait l’écho en 1833 le cordonnier parisien Efrahem dans son pamphlet De l’association des ouvriers de tous les corps d’État.
Si la révolution de 1848 a reconnu par le décret du 25 février le droit d’association, celui-ci a fait long feu après les répressions de juin et le coup d’État du 2 décembre 1851 suivi de la restauration de l’Empire. Il faut attendre le tournant libéral des années 1860 et, surtout, le retour de la République en 1870 pour que les libertés associatives puissent de nouveau être considérées.
La loi de 1901
Le droit d’association est finalement consacré par la loi de 1901 dans un contexte anticlérical marqué par le débat sur la séparation de l’Église et de l’État. Comme avec la loi de 1884 sur les syndicats, il s’agit pour les républicains de reconnaître une liberté publique tout en évitant que celle-ci ne serve de support à la constitution de contre-pouvoirs aux mains de leurs adversaires. Or, la loi de 1901 est adoptée en opposition aux congrégations religieuses, accusées, d’une part, d’aliéner la liberté de l’individu qui forme des vœux perpétuels et, d’autre part, d’entraver la circulation des richesses à travers les biens de mainmorte.
C’est ce qui explique non seulement que la loi vise d’abord la formation d’associations non déclarées (son article 1), mais aussi qu’elle crée la reconnaissance d’utilité publique, qui s’accompagne de l’obligation d’adopter des statuts types. S’il s’agit, d’un côté, de fonder une liberté – celle de s’associer sans avoir à le déclarer –, de l’autre, cette liberté tend à se réduire à mesure que les associations augmentent leurs capacités juridiques et matérielles. L’État libère autant qu’il contrôle pour éviter que ne se reconstituent les organisations de l’Ancien Régime telles que les corporations.
Il existe ainsi depuis 1901 trois types d’association en fonction de leur capacité juridique :
les associations non déclarées, sans personnalité juridique ni biens propres ;
les associations déclarées, auxquelles n’est accordée que la « petite personnalité », c’est-à-dire d’une capacité juridique limitée ;
les associations reconnues d’utilité publique, qui peuvent recevoir des dons et des legs, mais sont soumises au contrôle de l’État.
L’association est définie, dans l’article 1er de la loi de 1901, comme une
« convention par laquelle deux ou plusieurs personnes mettent en commun, d’une façon permanente, leurs connaissances ou leur activité dans un but autre que de partager des bénéfices ».
On retrouve à son fondement une logique d’action collective, reposant sur les principes de mutualisation et de coopération ainsi qu’un but non lucratif.
Alors que l’association est souvent rattachée à la démocratie libérale, comme l’a établi Alexis de Tocqueville dans son œuvre classique De la démocratie en Amérique, la loi reste peu prescriptive sur ses modalités d’organisation. L’inscription de principes démocratiques dans les associations est dépendant de statuts types largement diffusés et, surtout, de contraintes juridiques et administratives liées à l’octroi de subventions et à la reconnaissance d’utilité publique.
Les associations dans les cycles d’action publique
Cette reconnaissance du droit d’association est, par ailleurs, concomitante de la mise en place de l’assistance publique, marquée notamment par la loi de 1905 sur l’assistance aux vieillards, aux infirmes et aux incurables. Les politiques sociales étant encore embryonnaires, l’État choisit le contrôle plutôt que l’interdiction des congrégations qui gèrent la plupart des œuvres. À la différence du conflit autour de l’école, il ne s’agit pas d’exclure, mais bien d’inclure les œuvres charitables à la nouvelle assistance publique dans une « volonté de concordat social », selon les termes de l’historienne Colette Bec.
Les associations ont ainsi accompagné l’essor de l’État social, particulièrement après-guerre dans les domaines du social, de la santé, de la culture, du sport ou de l’éducation. Les associations sont ainsi devenues des auxiliaires des politiques publiques. Si cela a pu aller jusqu’à des formes de corporatisme, à l’instar de la création par ordonnance de l’Union nationale des associations familiales (Unaf) en 1945, la période a surtout consisté en un mode de régulation tutélaire, reposant sur le déploiement d’instruments tels que les agréments, les subventions ou les délégations de service public. L’État s’est ainsi retrouvé à fixer les règles, à octroyer les financements et à professionnaliser les associations, au sein desquelles le développement des emplois a eu pour corollaire l’apparition de la figure de l’association gestionnaire.
Le tournant néolibéral des politiques publiques dans les années 1980 s’est accompagné d’une managérialisation des associations. On a ainsi assisté à la conjonction entre, d’une part, l’externalisation de missions de services publics, en lien notamment avec la décentralisation, et, d’autre part, le développement des politiques de l’emploi. De nouveaux instruments reposant sur la contractualisation, le financement au résultat et la mise en concurrence des opérateurs sont apparus. Cette nouvelle régulation repose moins sur les subventions que sur les marchés publics ou des financements indirects consistants à rendre solvables les bénéficiaires des services (crédits d’impôt, défiscalisation des dons, allocations individuelles de solidarité, etc.).
Réinventer les associations et leur relation à l’État
Les associations se retrouvent aujourd’hui face à un triple défi. D’abord, elles doivent renforcer leur fonction employeur. Les spécificités et le caractère atypique du travail associatif ont été largement documentés, de même que l’on a vu apparaître un patronat associatif auquel l’Union des employeurs de l’économie sociale et solidaire (UDES) s’efforce d’offrir un débouché dans le dialogue social. Ensuite, elles doivent consolider leurs modèles économiques, ce qui passe par la diversification de leurs ressources et de leurs activités. Enfin, si depuis la loi de 1901 la dimension socioéconomique des associations a pris de l’importance, au point qu’elles comptent aujourd’hui autour de 1,8 million d’emplois, elles doivent également revitaliser leur dimension sociopolitique, alors que l’on constate une baisse des participations bénévoles dans les secteurs les plus professionnalisés.
Cela plaide en faveur d’un nouveau cycle d’action publique reposant sur la co-construction des politiques entre les pouvoirs publics et les associations. Plutôt que d’alimenter la défiance à travers les coupes budgétaires ou un contrat d’engagement républicain qui fait craindre des sanctions administratives, l’État gagnerait à reconnaître pleinement la contribution à l’intérêt général des associations ainsi que leurs libertés démocratiques, dans l’esprit de la Charte des engagements réciproques, signée en 2014, et de la circulaire Valls qui l’a suivie.
Tout l’enjeu réside donc dans la capacité de la République à retrouver le souffle initial de la loi de 1901 tout en tenant compte de ce que les associations sont devenues.
Timothée Duverger ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
30.06.2026 à 16:44
Associations : l’engagement résiste, les financements s’érodent
Guillaume Plaisance, Maître de conférences en sciences de gestion, Université de Bordeaux; IAE Bordeaux - Université de Bordeaux
Texte intégral (1188 mots)
Il y a 125 ans, la loi de 1901 fondait le statut des associations. Avec 1,6 million de structures, 13 millions de bénévoles et près de 2 millions de salariés, les associations irriguent tous les domaines de la vie sociale. Pourtant, derrière ce poids considérable se dessine une réalité plus fragile, marquée par la précarité financière, les mutations du bénévolat et le recul du soutien public.
Définie comme « la convention par laquelle deux ou plusieurs personnes mettent en commun, d’une façon permanente, leurs connaissances ou leur activité dans un but autre que de partager des bénéfices » par la loi de 1901, l’association est une organisation à but non lucratif qui appartient, depuis la loi Hamon de 2014, à l’économie sociale et solidaire. Les associations sont pourtant bien plus que des organisations réduites à leur non-lucrativité : elles relèvent du tiers secteur et de la société civile et sont bien plus hétérogènes que l’on ne peut l’imaginer.
Les associations françaises aujourd’hui : quelle structure ?
La France compte environ 1 600 000 associations, une statistique qu’il est difficile d’affiner dans la mesure où de très nombreuses associations demeurent enregistrées par les services de l’État alors qu’elles ne sont plus réellement actives.
Chaque année, ce sont entre 65 000 et 75 000 associations qui sont créées, et ce de manière relativement équitable entre les milieux ruraux et urbains. Ramenées à la densité démographique la plupart des créations d’associations se situent dans le sud de la France.
Le salariat demeure l’exception dans le monde associatif : en 2024, moins d’une association sur dix emploie du personnel, soit un total de près de 2 millions de salariés. En outre, ces emplois sont très inégalement répartis : près de la moitié des associations employeuses comptent moins de trois salariés, tandis que 70 % des effectifs travaillent dans des structures de plus de 20 salariés. Le paysage associatif est ainsi marqué par de fortes disparités de taille, d’emploi et de ressources.
Les associations comptent donc essentiellement sur leurs bénévoles pour parvenir à fonctionner. On en compte entre 13 millions et 13,5 millions : 3 millions d’entre eux s’engagent plutôt ponctuellement et 10 millions tout au long de l’année.
Le bénévolat : indispensable, en pleine mutation
Les dernières études permettent de constater que 25 % des Français sont bénévoles dans au moins une association (contre 22,5 % en 2010). Ce sont 28 % des hommes et 22 % des femmes qui sont concernés.
Néanmoins, les engagements réguliers ont tendance à régresser pour peu à peu devenir des participations plus ponctuelles. La « colonne vertébrale » des associations, à savoir les bénévoles qui s’engagent quelques heures par semaine tout au long de l’année, repose sur les retraités, essentiellement des hommes. Il s’agit de 10 % des Français.
Contrairement aux idées reçues, l’âge des bénévoles est de moins en moins un facteur explicatif de l’engagement. Les 15-34 ans s’engagent plus, se rapprochant du niveau d’engagement des plus de 65 ans qui, de son côté, diminue.
Les différentiels générationnels se sont donc estompés et le désengagement progressif des seniors interroge vivement.
La fracture réelle est plutôt à regarder du côté du niveau de diplôme : les personnes peu diplômées ou ayant un CAP ou BEP sont deux fois moins engagées que les diplômés au-delà du bac+2 (32 %).
Des organisations en proie à des difficultés financières
Les associations sont 78 % à disposer d’un budget annuel inférieur à 10 000 euros. Et 32 % d’entre elles ont même un budget inférieur à 1 000 euros par an.
Le budget cumulé des associations françaises culmine quant à lui à 113 milliards d’euros. Plus de la moitié se retrouvent au sein des associations employeuses qui ont un budget moyen par association de 728 000 euros (celui d’une association sans salarié est proche de 7 000 euros). Les associations salariées s’appuient seulement sur 19 % de subventions.
L’idée reçue selon laquelle les associations sont construites en dépendance des autorités publiques en termes financiers est erronée. En revanche, leur absence empêche les associations de se développer, car il existe une relation forte entre les associations et l’État qui a longtemps délégué ses missions et attendu des associations qu’elles jouent un rôle majeur de cohésion et de structuration dans la société.
Pourtant, l’État se désengage : alors qu’en 2005, 34 % des ressources des associations étaient des subventions, cette proportion est tombée à 20 % en 2020. Les dons et mécénats, si souvent mentionnés comme un substitut aux subventions ne représentent que 5 % des ressources et restent encore peu accessibles à l’immense majorité des associations : leur activité appartient à des secteurs qui mobilisent habituellement moins de financements privés que le sport ou la culture.
En 2025, 29 % des associations sans salariés et 53 % de celles employeuses jugeaient leur situation financière difficile, voire très difficile. En conséquence, plus de soixante mille associations envisageaient de réduire leurs activités.
En somme, l’accumulation de nouvelles contraintes administratives, les signes croissants de défiance des partenaires publics (comme en témoigne le renforcement des contrôles – moins subis par les entreprises) et la raréfaction des financements mettent sous tension un secteur qui joue pourtant un rôle essentiel dans le maintien du lien social.
Guillaume Plaisance est Vice-président de Recherches & Solidarités.
30.06.2026 à 12:50
Maladie des petits vaisseaux cérébraux : nouvelles pistes pour traiter cette affection méconnue qui touche des millions de personnes
Claire Peghaire, Docteur en pharmacie et enseignant chercheur en physiologie vasculaire, Université de Bordeaux
Texte intégral (2202 mots)
La maladie des petits vaisseaux cérébraux, qui accroît notamment le risque d’AVC et de troubles cognitifs, concernerait plus de 5 millions de personnes en France. En l’absence de traitement curatif, la prévention des facteurs de risque cardiovasculaire reste aujourd’hui la stratégie la plus efficace. Cependant, de nouvelles pistes thérapeutiques prometteuses sont explorées.
La maladie des petits vaisseaux cérébraux est une pathologie chronique qui affecte les plus fines artères du cerveau, celles qui irriguent en continu les zones profondes indispensables à la mémoire, à l’attention et à la coordination.
Avec le temps, ces vaisseaux se rigidifient, s’épaississent ou deviennent plus fragiles et perméables. Les conséquences de cette situation sont loin d’être anodines, puisque la maladie des petits vaisseaux cérébraux favorise les accidents vasculaires cérébraux (AVC), les troubles cognitifs, les difficultés en matière de marche ainsi que la perte d’autonomie.
En France, la maladie des petits vaisseaux cérébraux concernerait plus de 5 millions de personnes de 65 ans et plus. À ce jour, aucun traitement ne permet de la traiter.
À Bordeaux, au sein du laboratoire de biologie des maladies cardiovasculaires, dirigé par Thierry Couffinhal, et du Vascular Brain Health Institute (fondé par Stéphanie Debette, désormais directrice de l’Institut du cerveau et de la moelle épinière), nous essayons de mieux comprendre l’origine de la maladie. Voici ce que nous en savons à l’heure actuelle.
Une maladie difficile à repérer
Lorsque les fines artères qui l’irriguent sont affectées par la maladie des petits vaisseaux cérébraux, le cerveau reçoit moins bien l’oxygène et les nutriments dont il a besoin.
En outre, les cellules qui tapissent ces vaisseaux sanguins participent à la formation de la barrière hémato-encéphalique, une structure essentielle à la bonne santé du cerveau. Cette barrière agit normalement comme un filtre très sélectif entre le sang et le cerveau. Lorsqu’elle devient plus perméable, des substances indésirables peuvent pénétrer dans le tissu cérébral et contribuer à son altération progressive.
À lire aussi : Alzheimer, Parkinson, dépression… La santé du cerveau, en tête de nos préoccupations
La maladie des petits vaisseaux cérébraux est souvent silencieuse à ses débuts. Il n’est pas rare qu’elle progresse pendant des années sans signe spectaculaire, et les premiers indices de sa présence peuvent être discrets : ralentissement intellectuel, troubles de l’équilibre, fatigue cognitive, petits oublis inhabituels. Elle peut également entraîner des AVC.
Pour la détecter, l’imagerie par résonance magnétique (IRM) cérébrale reste aujourd’hui l’outil de référence. Elle permet d’observer des lésions caractéristiques, parfois présentes avant même les premiers symptômes, telles que des microsaignements, des lacunes (petites cavités témoignant d’anciennes lésions des petits vaisseaux), et surtout des « hypersignaux de la substance blanche », autrement dit des anomalies qui traduisent une souffrance chronique du tissu cérébral.
Pour mémoire, la substance blanche, qui constitue près de la moitié du volume du cerveau, est la partie qui correspond au réseau des fibres nerveuses. Ces dernières peuvent être vues comme des « autoroutes » qui permettent la propagation des signaux électriques entre les différentes régions du cerveau.
Des traitements encore trop limités
À ce jour, il n’existe pas encore de médicament spécifiquement conçu pour guérir la maladie des petits vaisseaux cérébraux. Les lésions peuvent toutefois être détectables plusieurs années avant l’apparition des symptômes, et leur progression peut être ralentie grâce à une prise en charge précoce des facteurs de risque cardiovasculaire.
On sait que certaines maladies, comme le diabète, les maladies cardiovasculaires ou l’insuffisance rénale chronique, semblent favoriser l’aggravation des lésions des petits vaisseaux cérébraux.
À lire aussi : La maladie rénale est aussi une maladie du cerveau
Aucun dépistage systématique n’est actuellement envisagé, notamment parce que le diagnostic repose essentiellement sur l’IRM, un examen coûteux difficile à généraliser à l’ensemble de la population.
Les médecins agissent surtout sur les facteurs dont la recherche scientifique a montré qu’ils peuvent influer sur le risque de développer la maladie (hypertension artérielle, diabète, cholestérol) ainsi que sur la consommation de tabac ou la sédentarité.
Si la prévention est essentielle, elle ne cible pas directement les mécanismes biologiques qui endommagent les petits vaisseaux du cerveau.
Ceux-ci sont encore mal connus, mais parmi les principales hypothèses formulées pour expliquer le développement de la maladie figurent le dysfonctionnement des cellules qui tapissent l’intérieur des vaisseaux sanguins (les cellules endothéliales), l’altération de la barrière hémato-encéphalique, l’inflammation chronique ou encore le stress oxydatif. Ce dernier phénomène, que l’on pourrait comparer à une « rouille biologique », abîme progressivement les vaisseaux sanguins.
C’est précisément à ce niveau que se situent nos recherches. Nos travaux récents apportent un nouvel éclairage sur les mécanismes de la maladie, ouvrant de nouvelles perspectives thérapeutiques.
Une nouvelle piste : protéger les vaisseaux de l’intérieur
Pour mieux comprendre la maladie des petits vaisseaux cérébraux, nous avons entrepris d’en disséquer les mécanismes au niveau cellulaire et moléculaire. Notre ambition est de passer d’une médecine de prévention à une médecine capable de réparer et protéger directement les microvaisseaux cérébraux.
Nos recherches ont conduit à l’identification d’une cible prometteuse, appelée TRIM47 (pour TRIpartite Motif containing 47). Nous avons démontré que cette protéine joue un rôle protecteur dans les cellules endothéliales en contribuant au maintien de l’intégrité vasculaire et en limitant les effets du stress oxydatif.
L’action protectrice de TRIM47 semble passer par l’un des principaux systèmes de défense antioxydante de notre organisme, la voie de signalisation NRF2. Lorsque cette voie fonctionne correctement, la cellule active ses propres mécanismes de réparation et de détoxification.
Divers résultats de recherche suggèrent toutefois que l’efficacité de cette réponse protectrice diminue à mesure que l’on vieillit, ce qui rend les cellules plus vulnérables au stress oxydatif.
Nous cherchons aujourd’hui à déterminer dans quelle mesure cette altération contribue au développement de la maladie des petits vaisseaux cérébraux et quels facteurs, génétiques ou environnementaux, pourraient l’influencer.
L’objectif n’est plus seulement de traiter les symptômes, comme faire baisser la tension artérielle, mais de renforcer les capacités naturelles de défense du vaisseau sanguin cérébral. Il s’agirait de traiter la maladie à sa source, avant la survenue d’AVC ou l’installation de troubles cognitifs.
Pour cela, il est notamment envisagé d’augmenter l’activité du couple TRIM47/NRF2, et donc de la voie antioxydante, dans l’espoir de préserver la barrière hémato-encéphalique et de protéger les neurones.
Deux stratégies complémentaires sont actuellement envisagées : développer de nouvelles molécules ciblant cette voie de protection ou réévaluer des médicaments déjà disponibles susceptibles d’agir sur ces mécanismes.
Cibler l’ARN messager pour traiter la maladie
Notre première stratégie thérapeutique consiste à cibler l’ARN messager (une molécule qui joue en quelque sorte le rôle de « plan de montage » des protéines dans les cellules) afin de diminuer la production d’une protéine appelée KEAP1.
En effet, cette dernière freine l’activité du système de protection cellulaire TRIM47/NRF2. En levant ce frein, nous espérons renforcer les défenses naturelles des vaisseaux sanguins cérébraux contre les mécanismes de vieillissement et de dégradation.
Pour atteindre cet objectif, nous développons des molécules appelées « oligonucléotides antisens » (ASO), conçues pour reconnaître spécifiquement l’ARN messager de KEAP1 et en réduire l’expression. Ces ASO sont chimiquement modifiés afin d’améliorer leur stabilité dans l’organisme et de favoriser leur distribution vers les vaisseaux cérébraux et les cellules du cerveau.
Ce travail de précision nécessite d’identifier la meilleure séquence thérapeutique, d’optimiser ses propriétés chimiques et son mode d’administration, puis de vérifier qu’elle atteint efficacement sa cible dans le cerveau avant d’évaluer sa capacité à préserver la santé vasculaire et les fonctions cérébrales.
Pour transformer cette découverte biologique en traitement potentiel, nous travaillons avec des équipes de chimistes bordelais de l’Institut européen de chimie et de biologie et du laboratoire « Acides nucléiques : Régulations naturelles et artificielles », experts dans la conception et la synthèse de molécules ciblant les ARN.
Ces collaborations étroites entre biologistes et chimistes sont essentielles pour passer de la compréhension d’un mécanisme fondamental à la conception de candidats médicaments innovants, plus ciblés, plus efficaces et potentiellement mieux tolérés.
Repositionner des médicaments déjà connus
Autre piste prometteuse : tester des médicaments déjà commercialisés pour d’autres indications, comme pour la sclérose en plaques, dont on sait qu’ils sont capables de passer la barrière hémato-encéphalique et d’activer la voie NRF2, un mécanisme associé à des effets protecteurs antioxydants et anti-inflammatoires.
Cette stratégie, appelée repositionnement thérapeutique, présente un avantage majeur : elle permet de gagner plusieurs années de recherche, car ces molécules disposent déjà de données de sécurité chez l’humain.
De ce fait, si les résultats précliniques en laboratoire de recherche s’avéraient positifs, des essais cliniques (donc menés chez les patients) pourraient être envisagés plus rapidement que pour un médicament entièrement nouveau.
Ceci permettrait ainsi de proposer plus rapidement une nouvelle solution thérapeutique aux patients, tout en diminuant les coûts de recherche et développement.
Un espoir face au vieillissement cérébral
Pour la première fois, de nouvelles stratégies thérapeutiques pourraient permettre, à terme, d’agir directement sur certains mécanismes impliqués dans la maladie des petits vaisseaux cérébraux, l’une des principales causes du déclin cognitif lié à l’âge.
Ces travaux en sont encore au stade préclinique, et plusieurs étapes de validation seront encore nécessaires avant d’envisager une application chez l’être humain.
La conviction qui guide nos recherches est qu’en protégeant les vaisseaux du cerveau, on protège aussi la mémoire, l’autonomie et la qualité de vie. Mieux traiter la maladie des petits vaisseaux cérébraux pourrait signifier demain moins d’AVC, moins de dépendance et davantage d’années de vie en bonne santé.
En attendant l’arrivée de traitements ciblés, certaines mesures ont déjà démontré leur efficacité pour préserver la santé cérébrale : contrôler sa tension artérielle, pratiquer une activité physique régulière, éviter le tabac, adopter une alimentation équilibrée et maintenir une vie sociale et intellectuelle active.
Des recommandations simples, mais qui restent aujourd’hui parmi les moyens les plus efficaces de protéger durablement son cerveau…
Claire Peghaire a reçu des financements de l'Agence nationale de la recherche (projet TheraVasc 2025-2028, ANR-25-CE14-3415-01), du VBHI (projet NAT-VAD 2025-2028, initiative IHU3 France 2030) et un prix associé à un mentorat du programme Spark Bordeaux 2024.
30.06.2026 à 12:50
Maladie d’Alzheimer et démence : comment préserver la dignité de ceux que les médicaments ne peuvent pas aider
Kate Irving, Professor of Clinical Nursing, Dublin City University
Texte intégral (1882 mots)

Bien que l’espoir de voir émerger des médicaments capables de ralentir la progression de la maladie d’Alzheimer commence à poindre timidement, la question de la prise en charge de la démence demeurera selon toute vraisemblance encore longtemps d’actualité. Comment préserver la dignité, l’identité et l’histoire d’une personne, lorsque sa parole s’estompe ?
En matière de maladie d’Alzheimer, les personnes que la démence effraie commencent à voir briller une lueur d’espoir, à mesure que des pistes pour mettre au point des médicaments capables d’agir sur cette affection se dessinent.
Contrairement aux médicaments plus anciens, destinés à agir sur les symptômes sans modifier la maladie sous-jacente, ce type de traitement vise à ralentir le processus pathologique lui-même.
Rappelons que, si la maladie d’Alzheimer est la cause la plus fréquente de démence, ce terme recouvre des symptômes (pertes de mémoire, confusion et modifications de la pensée) qui ne lui sont pas exclusifs et concernent aussi d’autres pathologies.
Jusqu’à présent, les médicaments visant à infléchir l’évolution de la maladie d’Alzheimer ne sont pas encore capables de retarder la progression des symptômes de plusieurs années ; tout au plus permettent-ils de la ralentir de quelques mois. En outre, leur administration s’accompagne d’un risque, faible, mais sérieux, d’effets indésirables, parmi lesquels figurent des œdèmes et des saignements cérébraux.
Pour l’heure, ces traitements ne conviennent qu’à des patients chez qui la maladie d’Alzheimer n’en est encore qu’aux premiers stades. Pour les nombreuses autres personnes qui ne sont pas dans ce cas, aucun traitement curatif ne se profile à l’horizon : seule demeure la perspective de la démence. Toutefois, le fait que les scientifiques parviennent désormais à modifier, dans une certaine mesure, le cours de la maladie a suscité un immense intérêt pour les travaux de recherche sur la démence. Cette attention est indispensable si l’on veut que ces progrès se poursuivent.
Mais l’engouement du public peut aussi restreindre le champ de la discussion, en focalisant tous les regards sur la biologie de la démence, au détriment de l’attention portée à la vie des personnes qui en font l’expérience.
Se souvenir des belles choses
Depuis de nombreuses années, les chercheurs en sciences sociales plaident pour une compréhension plus large de la nature de la démence. En effet, si celle-ci commence par des modifications cérébrales, elle affecte la personne tout entière. Elle peut transformer la manière dont quelqu’un se souvient, communique, entre en relation avec autrui et donne du sens au monde.
Pour le formuler autrement, l’accompagnement des personnes atteintes de démence ne saurait se limiter à ralentir le déclin biologique. Il faut aussi s’interroger sur ce qui fait qu’une personne se sent reconnue, en relation avec les autres et fidèle à elle-même.
Même lorsque la médecine ne peut offrir de guérison, le soin peut encore apaiser la détresse, préserver l’identité et créer des moments qui ont du sens. La musique, la poésie, le conte, le théâtre, les arts visuels, la danse et la médiation muséale offrent aux personnes atteintes de démence des possibilités de réagir et de se reconnecter aux autres, surtout lorsque la conversation ordinaire devient difficile.
La valeur de ce travail est parfois difficile à mesurer. En effet, les protocoles utilisés pour rendre compte de l’efficacité des médicaments ne peuvent être aisément employés pour évaluer ce qu’apporte à un patient le fait de fredonner une chanson qui lui est familière, de reconnaître une image, de rire d’une plaisanterie ou de brièvement redevenir plus présent aux autres…
Cependant, à mesure que ce type d’interventions se généralise, et que leur pratique perdure au-delà des premiers stades de la maladie, ces approches agissent comme des révélateurs, mettant en lumière l’humanité de personnes chez qui la démence est déjà très avancée.
Un tel travail peut remettre en question les stéréotypes nuisibles véhiculés par la presse et les réseaux sociaux. En effet, la démence est souvent assimilée à une sorte de « vivante mort », et les personnes qu’elle frappe sont vues comme des « zombies » ou des « coquilles vides ». Cette conception entretient l’idée qu’une personne atteinte de démence a déjà disparu, alors même qu’elle est encore en vie, réceptive, et capable de tisser des liens.
Il faut également faire attention de ne pas tomber dans un autre piège : si l’attention se concentre surtout sur celles et ceux qui peuvent encore parler, chanter, peindre, se produire ou réagir d’une façon qui nous est familière, le risque est que les personnes atteintes de démence très avancée soient considérées comme inatteignables. Or, ces patients sont déjà fréquemment jugés inaptes à participer à la recherche scientifique, voire, parfois, à s’engager dans toute démarche créative ou relationnelle.
Une telle vision des choses peut creuser un fossé délétère dans le champ même de la démence, entre celles et ceux qui parviennent encore à échanger d’une façon que nous pouvons appréhender facilement et celles et ceux dont la communication est devenue plus difficile à déchiffrer.
Dépossession narrative et fabulation critique
Dans une publication récente, nous avons exploré les possibilités et les limites des interactions avec des personnes parvenues aux derniers stades de la démence. Notre article examinait deux notions pouvant aider à penser ce problème : la dépossession narrative et la fabulation critique.
La dépossession narrative désigne le fait d’être privé de la maîtrise de sa propre histoire. À mesure que la démence progresse, les personnes peuvent devenir moins capables de s’expliquer, de relater leurs souvenirs, de rectifier des malentendus ou de dire à autrui ce qui compte pour elles. Leur vie ne cesse pas pour autant d’avoir un sens, mais leur aptitude à la raconter selon les codes habituels peut s’en trouver diminué.
Cela soulève un grave problème éthique. Comment les soignants, les chercheurs, les artistes ou les proches doivent-ils réagir lorsqu’une personne ne peut plus raconter clairement sa propre histoire ? Que faire des fragments qui subsistent : un geste, un regard, un contact, un son, une expression du visage, voire une absence de réaction ?
La fabulation critique peut être une approche envisageable. Ce terme est issu de travaux menés sur l’histoire, les archives et le silence. Il décrit une forme de reconstruction imaginative prudente, à laquelle on peut recourir lorsque les preuves directes sont partielles, manquantes ou impossibles à retrouver. Dans le périmètre de la prise en charge de la démence, ou des recherches y ayant trait, la fabulation critique peut aider à réfléchir à la manière d’entrer en relation, de façon éthique, avec la vie intérieure de personnes dont la communication se trouve très limitée.
Idéalement, la fabulation critique doit se faire tout en retenue. Cette approche nous autorise à nous demander ce qu’une personne pourrait ressentir, se remémorer ou chercher à exprimer, tout en restant lucides sur les limites de notre interprétation.
L’importance de la retenue
Il s’agit de faire preuve d’humilité. Certes, il se peut qu’un soignant qui s’occupe d’une personne depuis longtemps connaisse peut-être mieux que quiconque son histoire, ses habitudes, ses préférences et ses angoisses. Si une telle familiarité permet de mieux comprendre le patient, mais elle ne garantit pas l’exactitude des interprétations. Même les proches d’une personne atteinte de démence doivent rester attentifs aux risques de projection ou de surinterprétation, et se retenir de plaquer leurs propres présupposés sur son expérience, au risque de s’approprier entièrement l’histoire de l’autre.
La fabulation critique doit rester ancrée dans la retenue, et la question de la relation doit être au centre des préoccupations. Cette approche suppose d’examiner nos propres présupposés, nos motivations et de réfléchir au pouvoir dont nous disposons ; il s’agit de nous interroger sur ce que vit la personne atteinte de démence ainsi que sur la mesure dans laquelle nous avons le droit de rendre compte de cette expérience.
À l’inverse, si nous refusons tout engagement imaginatif, nous risquons de laisser les personnes vivant les derniers stades de la démence murées dans le silence. Un silence qui peut devenir synonyme d’effacement…
De nouveaux médicaments aideront peut-être à ralentir le développement de la maladie d’Alzheimer chez certaines personnes, faisant perdurer les stades les plus précoces. Mais pour les autres, sur lesquelles ces médicaments n’auront que peu ou pas d’effet, ou pour celles dont la démence est déjà trop avancée pour leur permettre de raconter leur histoire d’une façon qui nous soit immédiatement compréhensible, la question de l’accompagnement restera d’actualité. Les vies de ces personnes méritent encore notre attention, et leur silence ne doit pas être confondu avec l’absence.
Kate Irving a bénéficié d'un financement COST (Coopération européenne en science et technologie). Financé par l'Union européenne, ce programme octroie des subventions pour la mise en place de réseaux de recherche collaboratifs et interdisciplinaires. Elle siège au conseil d'administration de l'Association irlandaise contre la maladie d'Alzheimer.
29.06.2026 à 16:05
Is the Pope’s AI encyclical a warning on Tech Messianism?
Francisco De Abreu Duarte, Full-time Assistant Professor, European University Institute
Texte intégral (1729 mots)
In May 2026, in his first encyclical Magnifica Humanitas – signed on the 135th anniversary of Pope Leo XIII’s Rerum Novarum – Pope Leo XIV warned the world about the dangers of the promise of Artificial Intelligence (AI), categorically calling machine learning “a form of statistical adaptation based on data and feedback, which can be very effective, but does not imply inner growth”. Critical of an AI that replaces religious pluralism with a technological monolith, Pope Leo XIV addresses one of the most interesting dynamics of our contemporary societies: what role can religion play in a world in which technology seems to have a spiritual project of its own?
This “spiritual” AI is, in many ways, the Tower of Babel that the Pope fears. It comes with one concrete future and a defined goal, and has taken different names and ideologies, ranging from Peter Thiel’s doomsday scenario with the coming of the Antichrist, to transhumanist and techno-optimistic visions in which society is materially satisfied and markets run free.
These ideologies share one thing in common, which connects AI to some forms of organised religion in remarkable ways: messianism.
To be very clear, many other social projects have borrowed certain aspects of the same religious dimension to foster legitimacy and large-scale adoption, often with good intentions.
As Joseph Weiler well observed, Robert Schuman’s project for a “Europe of many peoples” was in itself a messianic promise, the dream of a ‘European Promised Land’. The same could be said of American Constitutionalism and its ‘constitutional faith’, as Levinson would put it, and the quasi-religious role of the founding fathers, the Constitution, or the Declaration of Independence.
Political messianism has the potential to unite a people around a particular goal, focusing our attention more on the end goal and less on the journey, especially when that journey is fraught with peril and suffering. However, there seems to be something entirely new about AI messianism.
First, the entire project of general AI is, in itself, ultimately that of achieving human intelligence. Unlike other technological advancements of the past – such as harvesting electricity or fire – AI seeks, at the core of its scientific foundations, to replicate Humankind and, perhaps one day, to surpass it.
Tests like the famous Turing Test were precisely designed to see how far a machine could go in convincing humans that it was one of them. Leonardo Da Vinci painfully discovered how such an imitation game could trigger a negative reaction from humans themselves, namely when he (allegedly) presented humanity’s first “robot” before the Sforza’s court, much to the horror and wonder of the guests. This is not so different from the reaction we have today, almost instinctively, when we gasp at how Claude writes a poem or Python code.
Secondly, technology brings about a particular Messiah. There is a concept in AI studies that once belonged solely to sci-fi books and is now making its way into everyday news. The concept of Artificial General Intelligence or AGI, or even Superintelligence, is ultimately that of Kurzweil’s “Singularity”, a moment in which human intelligence is no longer the most capable on Earth. This AGI is the Messiah who shall cure Earth from all illness (as Google DeepMind CEO Demis Hassabis tells us again and again). To follow this Messiah becomes then our mission, our religious quest, no matter what the cost is to the environment or to ourselves. When Andreessen says that “our enemy is the Precautionary Principle, which would have prevented virtually all progress since man first harnessed fire”, it’s a call for action to push quicker and farther, as far as we can, to follow it. The Singularity is ultimately God, with AI as its Son, and this new machine-led Earth as our Promised Land.
Now, one could ask: Is it not a bit bizarre to frame technology in this way? Who is to gain from such a messianic view of technology?
In political messianism, it is fairly easy to understand its appeal. It provides a guiding goal, it unites a people, and rallies the masses to fight for a common ideal or cause. It can also manipulate them to do terrible things. People die for a country because they wish to contribute to something long-lasting, bigger than themselves, to achieve some ultimate goal. But they also do it to follow a leader, often to the destruction of minorities. Likewise, religious messianism serves a purpose for the faithful: orienting behaviour, providing solace in a difficult life, promising that the future will be better than the present once in eternal life.
To some extent, the Catholic Church itself largely benefited from such an idea and so did early Christianity during its infancy, in appealing to the poor of the Roman Empire. It also led to enormous suffering when it justified atrocities in the name of God.
But technology should not really be about that, especially when most tech-optimists advocate for the wonders of technology neutrality as a value of the project itself.
The answer lies perhaps in the Pope’s acknowledgment that “When it comes to decisions regarding economic flows and digital platforms, as well as the governance of data and algorithms, we cannot allow a handful of actors to dictate these processes on their own.” The point is then a matter of power and control, positions in which messianism can be used for the same political ends of manipulation and exploitation (e.g. you will not be replaced by AI, but by someone who uses AI). These, in turn, lead to further uncritical adoption and a continuous race toward the unknown end. This monocultural race, in which we assume the path to be one and the final destination to be certain, is precisely one of the known dangers of messianism.
In fact, this might be the ultimate hidden goal of AI messianism, which has long strayed from its counterculture goals to now present a monocultural ideology of technology, led by the US and China, to which the rest of the world should bow or face oblivion.
Like any good old messianic project, it is never the entire story. There are alternatives to the path – multiple in fact – from alternative clouds to alternative social media solutions, from alternative Large Language Models (LLMs) to alternative cyber communities, each following its own path, sometimes agreeing and sometimes disagreeing, but never submitting to one singular religious vision of what the world should be.
Today is perhaps the moment to exercise some caution, take some time to reflect, and engage in some critical thinking.
AI is, no doubt, an enormous and potentially civilisation-changing achievement, but we cannot let it lead us on a cultish journey toward our own demise – not because it takes over, but because we destroy ourselves and our humanity in the process.
What is needed is what Michael Walzer called the “art of separation” in Liberalism: keeping technology one sphere among many, rather than a totalising one that colonises politics, faith, and meaning itself.
Perhaps pluralism, more than one single vision of technological advancement, is the counter-theology we need today.

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Francisco De Abreu Duarte ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 16:04
Peut-on faire du sport en été quand il fait chaud ? Oui, mais pas n’importe comment
Alejandro J. Almenar Arasanz, Profesor área de Fisioterapia, Universidad San Jorge
Marta Diarte Oliva, Docente e investigadora, Universidad San Jorge
Texte intégral (1521 mots)

Il est possible de s’entraîner par temps chaud en prenant certaines précautions. L’essentiel n’est pas de prouver ce dont on est capable, mais de progresser, d’être à l’écoute de son corps et d’adapter son programme.
Quand l’été arrive, les mêmes recommandations se répètent : éviter les heures les plus chaudes de la journée, rechercher l’ombre et boire de l’eau. Ce sont des conseils judicieux, surtout en période de canicule, mais ils ne correspondent pas toujours à la réalité. Certaines personnes aiment s’entraîner, transpirer, courir ou faire du vélo en plein air.
(En France, pendant les fortes chaleurs, le ministère de la santé invite à limiter au maximum l’activité physique et à privilégier les activités douces. Des gestes simples permettent d’éviter les accidents, insistent ses services. Retrouver ses conseils consacrés à la pratique sportive au moment des pics de chaleur, ndlr.)
Est-ce possible ? Oui, mais la chaleur ajoute une charge supplémentaire et oblige à adapter l’effort. Ce n’est pas la même chose de sortir pour marcher une demi-heure que de faire des séries de course à pied, un long parcours à vélo ou une séance de musculation intense. Le risque et les adaptations nécessaires dépendent de la personne, du type d’exercice pratiqué et de la durée d’exposition à la chaleur.
Un même entraînement n’est plus tout à fait le même
Pendant l’exercice, les muscles génèrent de la chaleur. Pour la dissiper, l’organisme envoie davantage de sang vers la peau et active la transpiration, tout en continuant à alimenter les muscles. C’est pourquoi un rythme habituel peut s’avérer plus exigeant en été : la perception de l’effort augmente, la fatigue survient plus tôt et les performances peuvent diminuer.
Adapter son entraînement ne signifie pas être moins en forme. Courir plus lentement, réduire le nombre de séries ou allonger les temps de repos peut demander un effort similaire à celui d’une séance plus intense par temps frais. Lors des journées de forte chaleur, le chronomètre ou la charge d’entraînement ne reflètent pas toujours tout : il convient également de prêter attention à ses sensations, à sa respiration, à sa fréquence cardiaque et à sa capacité à récupérer entre les efforts.
Transpirer aide, mais ce n’est pas une fin en soi
La transpiration est l’un des principaux mécanismes utilisés par le corps pour évacuer la chaleur, mais ce qui nous rafraîchit réellement, c’est l’évaporation de la sueur sur la peau. Lorsque l’humidité est élevée, on peut se retrouver trempé et, malgré cela, moins bien se rafraîchir.
De plus, transpirer davantage ne signifie pas s’entraîner mieux, brûler plus de graisses, ni éliminer davantage de « toxines ». Cela dépend de la température, de l’humidité, des vêtements que l’on porte, de l’intensité et de l’adaptation individuelle. C’est pourquoi il n’est pas très pertinent d’évaluer une séance en fonction du degré d’humidité du t-shirt à la fin de l’exercice : cela peut être un indicateur de l’effort fourni, mais aussi simplement de la chaleur, de l’humidité ou d’un mauvais choix de vêtements.
Un autre aspect à prendre en compte est que la tolérance à la chaleur s’acquiert à l’entraînement : une exposition progressive améliore la capacité à transpirer et à réguler la température corporelle. Un débutant ou une débutante devra donc privilégier des séances plus courtes, à intensité modérée, et les moments où il fait moins chaud. Une personne entraînée et acclimatée, en revanche, dispose d’une plus grande marge de manœuvre, mais elle n’est pas pour autant invulnérable : elle peut réduire le rythme lors des exercices d’endurance et diminuer le volume ou allonger les temps de repos lors des séances de musculation.
Manger et boire de manière raisonnable
Faire de l’exercice intense immédiatement après un repas copieux peut favoriser l’apparition d’une sensation de lourdeur, de nausées ou de troubles digestifs. Il est conseillé de laisser un délai suffisant ou, si le temps est compté, d’opter pour des aliments légers et faciles à digérer, comme un fruit, une tartine au miel ou à la confiture, un yaourt ou un petit sandwich simple. La quantité et le moment doivent être adaptés au type d’entraînement et à la tolérance de chacun.
Il est également utile de commencer la séance en étant bien hydraté. Pour une séance courte, l’eau suffit généralement, mais si l’effort se prolonge ou si la transpiration est abondante, il peut être utile de reconstituer également ses réserves en sels minéraux et en glucides.
Dans tous les cas, boire en excès (« au cas où ») n’est pas une bonne idée : l’hydratation doit être adaptée à la durée et à l’intensité de l’effort, ainsi qu’aux pertes individuelles. Une bonne règle pratique consiste à arriver à l’entraînement sans avoir très soif et à observer comment le corps réagit après : une fatigue excessive, un mal de tête ou une récupération anormalement lente peuvent être des signes indiquant que la séance, la chaleur ou l’hydratation n’ont pas été bien gérées.
S’entraîner en plein soleil ajoute une contrainte supplémentaire
Certaines personnes aiment sentir le soleil pendant leur entraînement. Il ne faut pas diaboliser cette préférence, mais il faut comprendre que le rayonnement solaire augmente la charge thermique et entraîne une exposition supplémentaire aux rayons ultraviolets.
Si vous choisissez de vous entraîner sous les rayons du soleil, il est conseillé de protéger votre peau, de porter des vêtements légers, d’avoir de l’eau à portée de main et d’accepter que certains jours, il faille réduire la durée ou l’intensité de l’exercice. L’Organisation mondiale de la santé (OMS) recommande de limiter l’exposition pendant les heures où le rayonnement est le plus intense et de recourir à l’ombre, à des vêtements protecteurs et à une protection solaire.
Certains symptômes ne doivent pas être ignorés : en cas de vertiges, de maux de tête intenses, de nausées, de faiblesse inhabituelle, de perte de coordination, de confusion ou de sensation d’évanouissement, il faudra s’arrêter, trouver un endroit frais et rafraîchir son corps.
Il est donc possible de s’entraîner par temps chaud. L’essentiel n’est pas de prouver ce dont on est capable, mais de progresser, d’être à l’écoute de son corps et d’adapter son programme. Commençons par la colline ; ensuite, si tout se passe bien, l’Everest viendra tout seul.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 16:03
Sahel : pourquoi les massacres de civils par les forces officielles sont en recul
Marc-Antoine Pérouse de Montclos, directeur de recherches, Institut de recherche pour le développement (IRD)
Texte intégral (2074 mots)
Dans les trois pays de l’Alliance des États du Sahel (Mali, Niger, Burkina Faso) et au Nigeria voisin, les armées sont depuis longtemps en butte à des rébellions djihadistes – rébellions qu’elles alimentent régulièrement en massacrant des civils soupçonnés de déloyauté, ou simplement en commettant des « bavures » sanglantes. Ces derniers temps, toutefois, on semble constater une légère amélioration en la matière : apparemment, les armées tuent moins de civils qu’auparavant. Il convient toutefois de bien comprendre que les chiffres dont on dispose ne sont que des estimations et, surtout, que cette amélioration s’explique par le fait que les populations ont souvent fui les zones des combats…
On sait depuis longtemps que les massacres de civils sont contreproductifs pour les stratégies de guerre contre-insurrectionnelle qui visent à isoler les éléments rebelles en gagnant les esprits et les cœurs de la population.
Au Sahel, l’une des raisons de la résilience des groupes djihadistes tient justement aux nombreuses violations des droits de l’homme commises par les forces de défense et de sécurité. Ces brutalités n’ont pas seulement poussé des jeunes à chercher refuge dans les bras des insurgés pour échapper à l’arrestation arbitraire, à l’exécution extra-judiciaire ou à la torture en prison. En pratique, elles ont aussi légitimé le discours de djihadistes se présentant comme les défenseurs de la communauté des musulmans face à des pouvoirs impies et prédateurs.
Des abus multiples
Du Burkina Faso au Nigeria en passant par le Mali et le Niger, on ne compte plus les massacres perpétrés par des militaires, leurs supplétifs miliciens et, dans certains cas, leurs partenaires russes. Un rapport de Human Rights Watch, rendu public le 2 avril dernier, a ainsi montré que, entre janvier 2023 et août 2025, les troupes de Ouagadougou et de Bamako avaient tué trois à quatre fois plus de civils que les groupes djihadistes qu’elles étaient censées combattre : sur cette période, 1 800 personnes ont été tuées au total, dont 1 200 par les forces gouvernementales.
Ce n’est pas nouveau : en 2023, le Sénat français avait fini par reconnaître que, sur les années 2020-2021, du temps où les soldats de l’opération Barkhane (2014-2022) étaient encore déployés sur le terrain, les militaires et miliciens maliens, burkinabè et nigériens avaient éliminé autant de civils que les djihadistes.
Au Nigeria, des bases de données ont également révélé que les forces gouvernementales étaient à l’origine de la mort de plus de 55 % des victimes des affrontements recensés avec Boko Haram entre 2007 et 2019.
Il est évidemment difficile de tenir un décompte précis des hostilités. Mais la tendance générale est confirmée par les témoignages recueillis sur place. À Bama, dans le nord-est du Nigeria, un paysan se plaignait par exemple des exactions de la mouvance Boko Haram tout comme de celles de l’armée. « Mais les soldats sont pires », concluait-il après la mort de deux de ses enfants abattus par des militaires alors qu’ils étaient partis travailler aux champs. Un réfugié de Baga Kawa, un petit port de pêche du côté nigérian du lac Tchad, estimait de son côté que « la plus grande menace pour les populations, c’est l’armée, car c’est elle qui nous tue ».
Les abus contre des civils prennent diverses formes, de l’exécution extra-judiciaire au viol en passant par l’extorsion, les mauvais traitements ou la détention illégale. Au Nigeria, c’est aujourd’hui l’armée de l’air qui est à la manœuvre en bombardant des marchés et des villages entiers. Officiellement, l’objectif est de s’en prendre à des camps de Boko Haram. Chaque fois, la hiérarchie parle d’erreurs qui, en l’occurrence, tuent des dizaines de paysans ayant eu pour tort de se trouver au mauvais endroit au mauvais moment.
Au Burkina Faso, ces bavures sont plutôt le fait des escortes qui tirent à vue sur tout ce qui bouge lorsqu’elles encadrent les convois chargés de ravitailler les villes de province assiégées par des djihadistes. À l’occasion, les bataillons d’intervention rapide, créés fin 2022 par le capitaine Ibrahim Traoré quelques mois après son arrivée au pouvoir à l’issue d’un putsch militaire, opèrent aussi des raids meurtriers dans les campagnes, sans même prévenir les troupes régulières stationnées à proximité.
Le rôle des milices
Assurément, l’arrivée au pouvoir de juntes militaires et la « milicianisation » de la réponse à la menace djihadiste ont beaucoup joué contre le respect des droits de l’homme en temps de guerre. Dans la région, les autorités ont en effet cherché à pallier le manque d’effectifs de leurs troupes en confiant à des supplétifs le soin d’assumer les tâches les plus sales de la lutte contre le terrorisme. Selon le rapport précité de Human Rights Watch à propos du Burkina Faso, les pires abus ont ainsi été enregistrés quand l’armée est intervenue aux côtés des miliciens koglweogo, les VDP (Volontaires pour la défense de la patrie).
Le Niger pourrait à présent connaître le même sort : la junte y a formalisé en mars 2026 des organisations territoriales d’autodéfense appelées à être équipées en armes pour repérer, dénoncer et arrêter les suspects. En pratique, ces milices peuvent tuer des civils en toute impunité car elles rendent peu de comptes à des militaires qui bénéficient eux-mêmes de l’immunité du secret-défense.
Ces dernières années, cependant, les forces gouvernementales de pays comme le Burkina Faso (depuis 2025) ou le Nigeria (depuis 2020) semblent moins directement impliquées dans des massacres à grande échelle. Faut-il y voir une professionnalisation des pratiques militaires ? Se pourrait-il donc que les officiers nigérians et burkinabè soient davantage conscients des effets pervers de ces tueries qui légitiment et renforcent les groupes djihadistes ?
Des militaires et des djihadistes plus « aimables » ?
L’hypothèse selon laquelle les militaires auraient amélioré leur comportement est évidemment avancée par les premiers intéressés. Elle est également favorisée par certains coopérants occidentaux qui, au Nigeria, veulent continuer de croire aux mérites de formations censées apprendre le respect des droits de l’homme aux soldats africains. Dans le cas de la France, par exemple, une telle perspective correspond bien à la volonté de faire oublier les échecs de l’opération Barkhane au Sahel en se repositionnant vers les pays du golfe de Guinée et en renouant le dialogue avec le Tchad, dont le président Mahamat Idriss Déby a officiellement été reçu à l’Élysée en janvier 2026.
D’ordre tactique et non humanitaire, le souci d’épargner des vies humaines pourrait aussi répondre à l’évolution de certains groupes djihadistes, qui ont dû apprendre à composer avec la population à mesure qu’ils s’enracinaient dans les campagnes. Au Nigeria, la branche ralliée à l’organisation État islamique, ISWAP (Islamic State West Africa Province), a ainsi la réputation d’être plus respectueuse des civils que les autres factions de la mouvance Boko Haram.
Au Burkina Faso, le JNIM (Jamāʿat nuṣrat al-islām wal-muslimīn) d’Iyad ag-Ghali et la Katiba Macina d’Amadou Kouffa ont également adouci leur position. Depuis 2021, ils ne communiquent plus de vidéos d’exécutions de femmes adultères. En 2025, l’adjoint d’Amadou Kouffa, Mahmoud Barry, dit « Abou Yehiya », a pour sa part commencé à diffuser des prêches invitant ses combattants à éviter les bavures et à épargner les civils. L’objectif est, tout à la fois, d’obtenir le soutien de la population et de recruter des jeunes en les conviant à participer à la protection de leurs communautés contre les exactions des forces burkinabè et des katibas rivales de l’État islamique au Sahel.
De l’invisibilisation des massacres
Plusieurs éléments invitent cependant à relativiser l’éventualité d’une « humanisation » des belligérants de la zone. Tout d’abord, il semble peu probable que les armées de la région aient pu soudainement améliorer leur comportement quand on connaît leurs fragilités structurelles, la faiblesse de leurs chaînes de commandement, la récurrence de leurs mutineries, leur indiscipline notoire, la rapidité de leurs recrutements, la réduction des temps de formation et le temps long que requiert un véritable reformatage des appareils sécuritaires.
L’hypothèse d’un adoucissement des stratégies de répression ne correspond pas non plus au durcissement des juntes au pouvoir dans les trois pays qui composent l’Alliance des États du Sahel, à savoir le Burkina Faso, le Mali et le Niger, qui se sont tous retirés de la Cour pénale internationale.
En réalité, les abus sont moins visibles parce que les médias ont été verrouillés par les dictatures en place. Les journalistes occidentaux comme africains n’ont quasiment plus accès aux zones de conflit, ou bien doivent être « embarqués » dans des unités militaires, comme au Nigeria. La tendance est d’autant plus marquée que les forces gouvernementales ont elles-mêmes perdu du terrain. Dans la région nigériane du Borno, par exemple, l’armée s’est retranchée à l’intérieur de grosses casernes, les supercamps, qui laissent le champ libre aux insurgés dans les campagnes. Dans le nord et l’est du Burkina Faso, les soldats se sont repliés dans les villes et sont avérés incapables de protéger les VDP actifs dans les campagnes, qui ont commencé à déserter et qui sont en conséquence moins à même de commettre des atrocités contre les villageois suspectés de sympathies djihadistes.
La politique de la terre brûlée, à cet égard, explique pour beaucoup la réduction des massacres. Dans les zones de conflit, les populations rurales ont, en effet, été évacuées manu militari vers des camps de déplacés, ou bien sont parties d’elles-mêmes vers les villes. Dans les campagnes, il y a tout simplement moins de gens à tuer pour les belligérants. Mais une telle situation ne laisse guère présager une sortie de crise.
Marc-Antoine Pérouse de Montclos ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 16:02
Loi de finances 2026 : quels risques autour des prévisions de dette publique ?
Fabien Tripier, Professeur d'économie, Université Paris Dauphine – PSL
François Langot, Professeur d'économie, Directeur adjoint de l'i-MIP (PSE-CEPREMAP), Le Mans Université
Jean-Olivier Hairault, Professeur d'économie et Directeur Scientifique de l'Observatoire Macro du Cepremap, Paris School of Economics – École d'économie de Paris
Jocelyn Maillard, Economiste à l’Observatoire de Macroéconomie, Cepremap
Texte intégral (2508 mots)
Le programme d’ajustement budgétaire pour 2026 repose sur des hypothèses économiques fortes. Que se passera-t-il si la réalité s’en écarte défavorablement ? L’objectif étant de réduire la dette, que risque-t-il alors de se passer ? La question est d’autant plus importante que la discussion parlementaire sur le budget 2027, qui commencera en septembre, sera sans doute d’autant plus difficile que l’élection présidentielle approche.
La loi de finances pour 2026 présente un programme d’ajustement budgétaire pour stabiliser la dette à 118 % du PIB en 2029. Un quart de cet ajustement repose sur un scénario conjoncturel plutôt favorable. S’il ne se réalisait pas, il y aurait plus d’une chance sur deux que la dette publique ne soit pas stabilisée, même si le programme était appliqué.
À l’inverse, si ce programme n’était pas mis en place alors que le scénario conjoncturel favorable se réalisait, la dette publique augmenterait de plus de 11 points de PIB en quatre années, soulignant ainsi le risque de dérive de la dette en cas de statu quo budgétaire.
À lire aussi : Et si la dette publique servait d’abord à rendre les citoyens plus heureux ?
Une procédure de déficit excessif
La trajectoire de la dette publique française est au cœur du débat budgétaire depuis plusieurs décennies. Le ratio dette/PIB a augmenté régulièrement sous l’impulsion d’un déficit budgétaire persistant qui ne se résorbe pas spontanément en période de croissance (voir la figure ci-dessous). En outre, la remontée des taux d’intérêt depuis 2022 a renchéri le coût de l’endettement public, alourdissant la charge de la dette. Cette situation a conduit la France à être sous procédure de déficit excessif. Cela l’engage vis-à-vis de ses partenaires européens à présenter une trajectoire crédible de réduction de sa dette publique.

Dans ce contexte budgétaire, la loi de finances pour 2026 présente un nouveau programme d’ajustement, avec pour objectif de stabiliser la dette à 118 % du PIB en 2029. La note de l’i-MIP 2026-12 (« Loi de finances 2026 : quels risques autour des prévisions de dette publique ? ») présente une évaluation des risques autour de cette prévision. Annoncer un niveau de dette publique ne suffit pas, mieux vaut connaître la probabilité de dépasser cette cible, ou encore identifier le niveau de la dette qui ne sera pas dépassée avec une certaine probabilité. Cette approche probabiliste répond à une demande d’informations sur les risques de dérapages budgétaires, aujourd’hui manquantes dans le débat public.
Comment évaluer le risque ?
La nouvelle loi de finances repose sur deux piliers :
d’une part, la trajectoire budgétaire annoncée par le gouvernement sur la période 2026-2029,
d’autre part, une prévision de conjoncture macroéconomique avec laquelle ce programme budgétaire interagira.
Évaluer ce programme consiste donc à identifier séparément le scénario conjoncturel et le scénario budgétaire qui lui sont sous-jacents. Comme la réalisation simultanée de ces deux scénarios n’est pas certaine, la prévision du gouvernement est risquée. Pour quantifier ce risque, nous comparons les prévisions du gouvernement, conditionnées par la réalisation des scénarios budgétaire et conjoncturel particuliers qu’il propose, à celles qui résulteraient de scénarios tirés au sort dans les distributions historiques des chocs conjoncturels et budgétaires estimées sur les données observées sur la période 2003–2025.
Cet exercice permet de révéler où se situent dans les distributions des probabilités historiques les scénarios du gouvernement, et ainsi le risque associé à son programme de stabilisation de la dette. Cette évaluation des risques considère que la distribution des scénarios conjoncturels passés est la référence pertinente parce que les estimations de ces scénarios ne sont pas affectées par le programme budgétaire grâce à l’utilisation de notre modélisation structurelle.
Un risque conjoncturel
Avant d’évaluer ces risques, il est utile de décomposer les sources de réduction de la dette dans le scénario du gouvernement. Cette décomposition permet d’isoler ce qui relève de la politique budgétaire et ce qui relève du contexte conjoncturel. Sur une réduction totale de 192 milliards d’euros de dette publique entre 2025 et 2029, nous estimons que 142 milliards – soit 74 % – sont attribuables au scénario budgétaire, c’est-à-dire à la consolidation annoncée dans le projet de loi de finances (PLF) 2026. Les 49 milliards restants – soit 26 % – proviennent du scénario conjoncturel tel que projeté par le scénario du gouvernement.
Comme près d’un quart de la baisse de la dette repose sur le scénario conjoncturel envisagé, il est important d’évaluer où se situe ce scénario dans la distribution des réalisations historiques, c’est-à-dire mesurer le risque conjoncturel.
Une prévision probablement dépassée ?
Ce risque est mesuré par la probabilité que la cible de dette soit dépassée si le scénario conjoncturel retenu par le gouvernement est remplacé par la conjoncture « médiane » de ce qui a été observé dans le passé, alors que le programme budgétaire est intégralement mis en œuvre (l’incertitude venant donc uniquement de la conjoncture). Cette mesure du risque conjoncturel répond à la question : que devient la dette si le budget est appliqué, mais que l’environnement macroéconomique n’est pas celui retenu dans la prévision gouvernementale ?
Le tableau 1 donne la réponse à cette question. En 2029, la médiane de la distribution simulée s’établit à 119,5 % du PIB, soit 1,5 point au-dessus de la cible officielle de 118 %. Cela signifie que la prévision du gouvernement se situe en dessous de la médiane des scénarios basés sur une conjoncture à l’image de l’historique : il y a 55 % de chances que la dette dépasse 118 % du PIB, même si le programme budgétaire est pleinement appliqué. La probabilité de dépasser 125 % est de 30 % et celle de dépasser 126,2 % est de 25 %.

L’autre risque
Symétriquement, le risque budgétaire mesure la probabilité que la cible de dette soit dépassée si le scénario budgétaire du gouvernement n’est pas exécuté, alors que son scénario conjoncturel se réalise. Ce risque semble, à première vue, davantage sous le contrôle du gouvernement, puisque l’implémentation de sa politique dépend a priori de sa volonté. Mais ce serait une lecture trop optimiste, voire naïve.
L’expérience passée montre que les plans d’ajustement budgétaire sont très rarement mis en œuvre comme prévu. Ainsi, la figure 1 montre qu’il existe un décalage systématique entre les politiques annoncées et celles effectivement implémentées. Le risque budgétaire ne doit donc pas être interprété comme une hypothèse extrême ou secondaire, mais comme un risque central d’exécution de la trajectoire annoncée.
Que deviendrait la dette si la conjoncture prévue se réalise, mais que le budget annoncé n’est pas mis en œuvre ? Le tableau 2 donne la réponse à cette question. En 2029, la médiane de la distribution atteint 129,5 % du PIB, soit 11,5 points au-dessus de la cible. La probabilité de dépasser 118 % est de 99 % et celle de dépasser 125 % est de 89 %. Cette situation correspond à un statu quo budgétaire complet : le gouvernement et le parlement ne modifient pas leurs comportements par rapport à ceux observés dans le passé.
Un programme trop peu ambitieux ?
Elle constitue donc une borne haute du risque budgétaire, qui mesure à quel point la trajectoire de dette dépend de la réalisation effective du programme de consolidation budgétaire. Sans elle, la dette serait orientée structurellement à la hausse, avec un accroissement de 3,5 points en moyenne par an (de 115,6 % en 2025 à 129,5 % en 2029).

Ces résultats soulignent, une fois de plus, l’importance d’implémenter le programme budgétaire annoncé. Ils indiquent également que, même avec ces restrictions budgétaires, la probabilité de stabiliser la dette à 118 % du PIB en 2029 est d’un peu moins d’une chance sur deux. Jouer à pile ou face sur la stabilisation de la dette dans un contexte de finances publiques dégradées et d’environnement international incertain est un pari risqué qui soulève deux questions.
La première est celle de l’intensité de la consolidation. Un objectif plus ambitieux de réduction du déficit permettrait, à risque conjoncturel donné, de réduire le niveau de dette médian et reviendrait alors à se fixer l’objectif que 70 % des simulations permettraient d’être en dessous de 118 %. La seconde est celle de la mise en place de règles budgétaires pluriannuelles prévoyant des ajustements automatiques des dépenses et/ou des recettes tant que la dette publique reste au-dessus d’une certaine cible.
Ces deux orientations ne sont pas exclusives. Elles invitent à ouvrir un débat plus large sur la crédibilité et la robustesse de la stratégie budgétaire française, qui dépasse le seul horizon de la loi de finances 2026.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 16:00
Maximiser les bénéfices ou minimiser le gaspillage ? Le vrai casse-tête de vos commerçants pendant les soldes
Arvind Sainathan, Associate Professor of Operations Management, Neoma Business School
Fang Liu, Professor of Operations Management, Durham University
Texte intégral (1642 mots)
Casser les prix ou jeter des produits invendus ? Tel est le dilemme des commerçants tandis que débutent les soldes d’été. Pour inciter à consommer davantage, les vendeurs mobilisent différents types de promotion. Notre étude se penche sur ces mécanismes commerciaux et offre des pistes pour réconcilier recherche de rentabilité et durabilité.
Des soldes d’été aux offres exceptionnelles du Black Friday, les promotions sont devenues incontournables dans le paysage commercial. Les consommateurs considèrent souvent qu’une remise n’est qu’une remise, qu’il s’agisse d’une baisse de prix ou d’offres de produits gratuits, telles qu’« un acheté, un offert » (une pratique aussi appelée BOGOF pour « Buy One Get One Free »).
Pourtant, de nouvelles recherches suggèrent que les promotions peuvent remplir des objectifs différents, avec des conséquences importantes non seulement pour les acheteurs, mais aussi pour les vendeurs confrontés à une augmentation des déchets et à une compression des marges.
Notre étude récente propose une approche plus claire pour appréhender les promotions dans le commerce de détail. Nous expliquons pourquoi les baisses de prix et les offres fondées sur la quantité peuvent générer des résultats étonnamment différents en distinguant deux objectifs chez les enseignes : la maximisation des bénéfices et la minimisation du gaspillage.
Ces travaux font écho à des préoccupations plus larges concernant la surproduction dans le secteur de la mode, le gaspillage alimentaire et l’empreinte environnementale des chaînes d’approvisionnement du commerce de détail au niveau mondial.
À lire aussi : Le bonheur s’achète-t-il en solde ?
Psychologie de l’achat devant les promotions
De nombreux consommateurs estiment qu’une remise de 50 % et une offre BOGOF reviennent pratiquement au même. Certes, les deux réduisent le prix unitaire effectif. Cependant, les recherches montrent que chaque méthode de promotion a un impact distinct sur les choix des acheteurs.
Une remise sur le prix réduit le coût de chaque unité. À l’inverse, une promotion de type BxGy, « achetez x, obtenez y gratuit », introduit un seuil, les consommateurs doivent acheter une quantité minimale pour obtenir la récompense. Ce seuil modifie la psychologie de l’achat, car la valeur que les consommateurs attribuent à un article diminue à chaque unité supplémentaire qu’ils achètent, selon le principe de l’utilité marginale décroissante.
Des consommateurs tentés d’acheter plus
Derrière ces promotions, deux mécanismes sont à l’œuvre. Lorsque les stocks sont élevés, les offres telles que « un acheté, un offert » exploitent un effet de regroupement pour encourager les consommateurs à acheter en plus grande quantité.
Cela concorde avec des études antérieures qui montrent comment les détaillants utilisent des incitations comportementales pour augmenter les dépenses des consommateurs, en particulier dans des contextes hautement concurrentiels comme les soldes de fin d’année.
L’effet de différenciation, quant à lui, apparaît lorsque les consommateurs accordent une valeur différente aux unités supplémentaires, comme c’est le cas pour la mode, les accessoires et les cadeaux. Dans le cas de promotions fondées sur des seuils, cet effet permet aux détaillants d’attirer à la fois des acheteurs ayant une forte disposition à payer et des chasseurs de bonnes affaires. Cette tendance fait écho à des études sur la manière dont les consommateurs de mode utilisent les promotions pour tester des articles qu’ils n’achèteraient peut-être pas au prix fort.
Ces mécanismes aident à expliquer pourquoi les promotions du Black Friday incitent souvent les consommateurs à opter pour des lots de plusieurs articles plutôt que pour de simples remises.
À lire aussi : Soldes : les commerçants sont-ils d’honnêtes manipulateurs ?
Profit ou planète ? Le dilemme derrière le déstockage
Les soldes saisonniers (Cyber Monday, soldes de janvier, soldes de fin de saison dans la mode…) mettent en évidence un dilemme persistant chez les commerçants : soit maximiser leur bénéfice restant, soit écouler les stocks pour éviter le gaspillage. Notre étude définit deux politiques de promotion optimales (OPP) distinctes : l’une maximise le bénéfice attendu, quitte à ce qu’il reste des invendus ; l’autre est axée sur l’écoulement des stocks.
Nos recherches montrent que ces deux objectifs – maximiser les bénéfices et minimiser le gaspillage – sont souvent contradictoires. Une baisse de prix modérée peut, par exemple, préserver les marges, mais laisser des marchandises invendues. De la même manière, les offres promotionnelles plus importantes de type « deux achetés, un offert » (« Buy Two Get One [Free] », BTGO) peuvent vider les rayons, mais réduire la rentabilité.
Cette tension se retrouve dans des rapports documentant les conséquences des stocks invendus. Parmi ces conséquences : les déchets textiles, lorsque les détaillants jettent ou détruisent les produits de fast-fashion invendus. Ce difficile équilibre entre profits et durabilité apparaît également de façon évidente avec le gaspillage alimentaire, lié à des cycles de fraîcheur stricts et à des erreurs de prévision. Devant ces phénomènes, les autorités européennes renforcent les obligations environnementales, les consommateurs s’interrogeant de plus en plus sur le coût de la surproduction induite par les démarques.
Nos recherches montrent que trouver des moyens d’optimiser la politique promotionnelle aide à atténuer les tensions entre ces deux objectifs. Dans de nombreux scénarios, les OPP axées sur le profit permettent d’atteindre un profit maximal avec un gaspillage limité, tandis que les OPP axées sur la liquidation aident à écouler les stocks avec un sacrifice limité en matière de profit.
Ce que les détaillants et les consommateurs peuvent en retenir
Notre étude met en évidence deux facteurs qui déterminent quelle promotion fonctionne le mieux.
Le premier est le niveau des stocks. Lorsque les stocks sont bas, des remises de prix modestes maximisent les bénéfices sans encourager les achats excessifs. Lorsque les stocks sont élevés, les promotions « un acheté, un offert » ou « deux achetés, un offert » accélèrent la rotation des stocks en tirant parti de l’effet de regroupement. Cela explique pourquoi les soldes du lendemain de Noël s’appuient souvent sur des offres d’achat multiple : les détaillants tentent de réduire les coûts de stockage et le gaspillage.
Le deuxième facteur est le type de produit. Les produits de base, tels que le pain, le dentifrice et les boissons gazeuses – qui ont à l’unité une valeur similaire –, réagissent bien aux promotions « un acheté, un offert ». En parallèle, les produits à valeur hétérogène, tels que les accessoires de mode et les cadeaux de Noël, tirent plutôt profit des promotions « deux achetés, un offert », qui correspondent mieux aux diverses perceptions de valeur des consommateurs.
Pour les consommateurs, cela signifie que les promotions sont rarement arbitraires. Elles révèlent la façon dont les détaillants appréhendent la valeur de leurs articles et comment ils gèrent la pression sur les stocks.
Vers des promotions plus intelligentes et plus durables
Les promotions dans le commerce de détail influencent les choix des consommateurs et le volume des consommations. Comprendre les mécanismes de ces offres peut aider les détaillants à réduire les démarques inutiles et à diminuer le gaspillage, pour concevoir des promotions qui profitent à la fois à l’entreprise et à l’environnement.
Quant aux consommateurs, ils se soucient de plus en plus de la durabilité, de la réparabilité et de la réduction des déchets. Comprendre le fonctionnement des promotions, que ce soit pendant la frénésie du Black Friday ou lors d’une vente discrète en milieu de saison, peut les aider à faire des choix plus éclairés.
Fang Liu a reçu des financements de Major Program of National Natural Science Foundation of China (72192843).
Arvind Sainathan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 15:59
Produire de grandes cultures en agroécologie de manière rentable, c’est possible
Lucie Zgainski, Ingénieur de recherche, Inrae
Marie-Noël Mistou, Ingénieur de Recherche, Inrae
Michel Bertrand, Ingénieur de Recherche, Inrae
Muriel Valantin Morison, Directrice de recherche - agroécologue, Inrae
Texte intégral (2790 mots)

Depuis vingt-cinq ans, l’Inrae teste en conditions réelles des alternatives à l’agriculture conventionnelle sur huit hectares à Versailles, dans les Yvelines. Une expérience riche en enseignements.
Peut-on nourrir la France en réduisant notre utilisation de pesticides et d’engrais azotés ? Pour répondre à cette question, les chercheurs peuvent utiliser plusieurs méthodes. L’une d’entre elles consiste à tester différentes techniques agricoles en conditions réelles sur de grandes cultures et à étudier leurs évolutions sur le temps long.
C’est ce qu’il se passe dans l’une des stations expérimentales de l’Inrae depuis vingt-cinq ans, et les résultats agronomiques et économiques de cette expérimentation donnent de nombreuses raisons de se réjouir.
Un essai système d’une durée de vingt-cinq ans
Le dispositif expérimental La Cage, mis en place en 1998 à Versailles (Yvelines) sur une parcelle de huit hectares, compare ainsi sur le long terme quatre systèmes de culture cohérents et représentatifs des grandes cultures sans élevage :
un système productif conduit en agriculture conventionnelle ;
un système à bas niveau d’intrants (faible utilisation de produits phytosanitaires et d’engrais azotés) ;
un système en agriculture biologique ;
un système sous couvert végétal.
Dans ce dernier cas de figure, des plantes sont semées entre deux cultures afin de protéger le sol lorsqu’il resterait nu. Ces couverts végétaux sont utilisés pour tâcher de limiter l’érosion, d’améliorer la fertilité et la structure des sols, de favoriser la biodiversité et de réduire le développement des mauvaises herbes.
Cette façon de faire de l’agriculture implique une réduction du travail du sol notamment des opérations mécaniques réalisées pour préparer la terre avant les cultures. Cette réduction permettrait notamment de préserver la structure et la biodiversité des sols, de limiter l’érosion, de diminuer les émissions liées à l’usage des machines agricoles et de favoriser la séquestration du carbone dans les sols.
Conçu pour anticiper des enjeux comme la réduction des pesticides ou l’amélioration du bilan carbone, ce dispositif de La Cage permet de tester et d’ajuster des pratiques innovantes en fonction des objectifs et de l’évolution des connaissances.
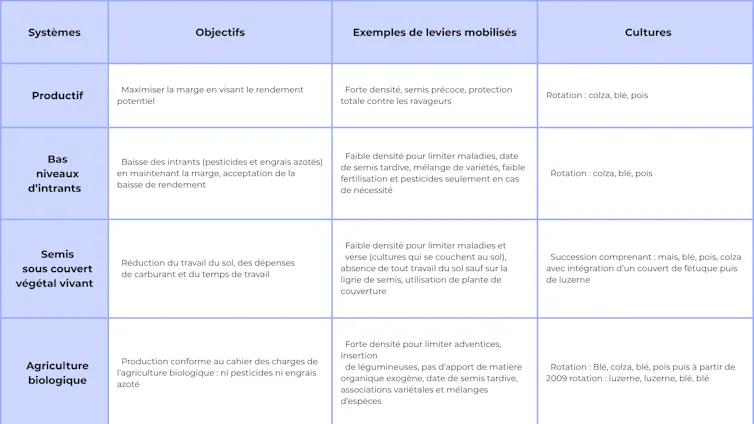
Chaque système combine différents leviers techniques (rotation des cultures, travail du sol, fertilisation, etc.) qui interagissent entre eux : par exemple, la stratégie de fertilisation dépend de la densité de semis choisie, car une densité plus élevée entraîne une compétition accrue entre plantes et modifie leurs besoins en nutriments.
L’agriculture biologique mise, elle, sur les légumineuses pour compenser l’absence d’engrais azotés, car celles-ci (pois, trèfle, luzerne, féverole, etc.) fixent naturellement l’azote de l’air ce qui permet d’enrichir les sols en azote pour les cultures suivantes.
Quelles performances agronomiques des systèmes expérimentaux de La Cage ?
Les rendements des principales espèces cultivées, notamment blé, maïs, colza et pois, ont ainsi été mesurés chaque année, offrant une série temporelle robuste pour comparer la productivité des systèmes contrastés.
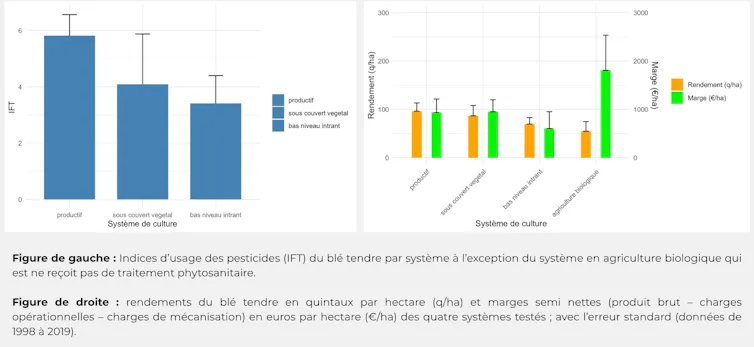
Dans les systèmes avec bas niveau d’intrants, sous couvert végétal et en agriculture biologique, les séries de rendements montrent généralement une variabilité plus élevée et des niveaux moyens de rendement inférieurs au système productif (Cf. Figure 1). Par contre, les marges peuvent être importantes et surpasser nettement le système productif. C’est notamment le cas avec l’agriculture biologique, car le prix de vente du blé bio est en règle générale nettement plus élevé que le conventionnel.
Dans le système sous couvert végétal, la restitution au sol des résidus de culture (tiges, feuilles mortes, racines) et des couverts végétaux contribue à la fertilité des sols. Cependant, ces restitutions influencent également la disponibilité des éléments nutritifs pour les cultures suivantes, ce qui peut entraîner des variations interannuelles des rendements.
Dans les systèmes biologiques et sous couvert végétal, l’introduction de légumineuses permet de capter l’azote atmosphérique, un élément essentiel à la croissance des plantes, modérant ainsi partiellement les déficits d’apport d’engrais azotés.
Par ailleurs, les systèmes sous couvert permanent sans travail du sol montrent des effets positifs sur la structure du sol, notamment par l’amélioration de la stabilité des agrégats et l’augmentation de la porosité, favorisant ainsi l’infiltration de l’eau et l’activité biologique du sol. Ces bénéfices doivent être mis en balance avec des défis techniques comme la gestion des couverts, qui sont en compétition pour l’eau et les nutriments avec les cultures principales et le défaut de maîtrise des mauvaises herbes.
Globalement, l’analyse agronomique et économique de La Cage confirme que certains systèmes de culture diversifiés peuvent atteindre des niveaux de rentabilité équivalents au système productif, sur la culture du blé et à l’échelle de la rotation, tout en améliorant certains aspects de durabilité. Ces résultats illustrent aussi l’importance de considérer des séries longues de données pour intégrer la variabilité climatique et les effets cumulatifs des pratiques de gestion, la restitution des résidus de culture au sol et la dynamique des cultures successives.
Mais qu’en est-il de ces maladies qui peuvent ravager les cultures et qui restent encore souvent les bêtes noires des agriculteurs ? Considérant, par exemple, la septoriose du blé, nos résultats montrent les limites des systèmes productifs très vulnérables dès que l’on n’utilise plus de pesticides.
La gestion des maladies
La septoriose du blé est une maladie fréquente qui dépend fortement du climat. Sa gestion repose sur différents leviers (choix variétal, pratiques culturales, fongicides). Les systèmes productifs très dépendants des traitements sont les plus touchés lorsque l’on retire l’usage des pesticides. Des systèmes, comme le semis sous couvert, limitent mieux la maladie, car il permet aux microorganismes (bactéries, champignons, faune du sol) de rentrer en compétition avec les agents pathogènes ou de limiter leur développement. Ainsi, réduire les pesticides n’entraîne pas forcément plus de maladies, à condition d’adapter les pratiques. Globalement, c’est la cohérence du système agricole dans son ensemble qui permet une gestion durable des maladies.
Notre étude confirme également d’autres bénéfices aux pratiques agroécologiques. Le premier concerne le carbone qui est stocké dans les sols agricoles et qui représente aujourd’hui un enjeu majeur pour l’atténuation du changement climatique.
Quel bilan carbone ?
De fait, une partie non négligeable du carbone séquestré par les plantes lors de la photosynthèse finit dans le sol par l’intermédiaire des racines. Les résidus de culture aériens (tiges, feuilles mortes…) constituent un autre apport en carbone dans les sols. Mais selon les techniques agricoles utilisées, la pérennité de ce stock de carbone peut fluctuer.
Le carbone stocké dans le sol est un des déterminants majeurs de sa fertilité, qu’elle soit physique (maintien de la structure), chimique (fourniture de nutriments) ou biologique (ressource pour les organismes vivants).
En l’absence d’apports d’effluents organiques issus de l’élevage, le bilan carbone d’un système de culture découle seulement du niveau des entrées et des pertes à l’échelle de la parcelle. Les entrées correspondent donc aux résidus (aériens et souterrains) des cultures et des couverts végétaux. Les pertes correspondent à la minéralisation des matières organiques du sol sous l’action des microorganismes qui peuplent la terre, la décomposent et la transforment en éléments minéraux.
Les systèmes de culture de La Cage présentent des dynamiques contrastées d’apports de carbone au sol, étroitement liées à la productivité des cultures, à la place des légumineuses et des couverts végétaux.
Plus les rendements sont élevés, plus il y a des résidus de culture restitués au sol. C’est donc le système productif qui produit le plus de résidus riches en carbone. Toutefois, cette réalité est compensée dans les systèmes ayant des couverts végétaux. Dans le système sous couvert, les apports totaux de carbone sont au final estimés à un niveau supérieur à celui des autres systèmes, grâce à l’apport de ces couverts. Au final, le stock de carbone augmente dans le temps dans le système en agriculture biologique et encore plus dans le système sous couvert végétal, alors qu’il reste stable dans les deux autres systèmes.
Quels effets sur la biodiversité du sol ?
Au-delà de la gestion des maladies et de l’apport en carbone des sols, notre étude met également en évidence un autre bénéfice majeur des pratiques agroécologiques : leur effet positif sur la biodiversité du sol.
La biodiversité du sol comprend une multitude de taxons de taille extrêmement variable et qui remplisse des fonctions diverses. Les vers de terre qui constituent l’essentiel de la macrofaune du sol sont les plus souvent étudiés et sont considérés comme des acteurs majeurs du fonctionnement du sol compte tenu de leur rôle de fouisseur et transformateur de la matière organique. Les pratiques agricoles, en particulier le travail du sol, l’apport de matière organique et l’usage de pesticides, sont de longue date reconnues comme ayant un impact majeur dans le maintien de ces populations.
Le système sous couvert végétal, sans travail du sol, se distingue par des abondances et biomasses nettement plus élevées de vers de terre anéciques et épigés, de trois à sept fois supérieures à celles observées dans les systèmes productif et biologique avec du travail du sol, et ce, seulement une dizaine d’années après l’implantation de l’essai. Cette augmentation s’accompagne également d’une diversité en espèces de vers de terre.
En agriculture biologique, l’augmentation des populations de vers de terre est plus lente. Mais après plus de quinze ans de conduite, ce système peut héberger entre 1,5 et 2,3 fois plus de vers de terre que le système productif, selon les variations interannuelles liées au climat.
Par ailleurs, les changements de pratiques agricoles mettent souvent plusieurs années à se traduire par des modifications significatives des communautés de vers de terre. Ces résultats soulignent l’importance des dispositifs expérimentaux de long terme pour évaluer de manière robuste l’impact des systèmes de culture sur la biodiversité des sols.
Que retenir ?
Les essais systèmes sont des outils clés pour tester et évaluer des solutions agroécologiques. Sur le long terme, ils montrent qu’il est possible de produire avec moins de pesticides, d’azote et d’énergie, tout en assurant une marge économique pour l’agriculteur, un stockage de carbone et l’accroissement de la biodiversité dans les sols.
Le dispositif évolue pour répondre à ces enjeux qui se posent aujourd’hui à l’agriculture et en lien avec la demande sociétale : produire sans apport d’azote, sans travail du sol, aller vers une agriculture sans pesticides, concilier production et biodiversité. Des nouveaux systèmes abordant ces thématiques sont en cours de conception avec la profession agricole.
Lucie Zgainski a reçu des financements de l'ANR.
Michel Bertrand a reçu des financements de l'ANR
Muriel Valantin Morison a reçu des financements de l'ANR et du programme Ecophyto pour réaliser ses recherches
Marie-Noël Mistou ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 15:57
Petits-enfants d’immigrés : du diplôme à l’emploi, le modèle républicain tient-il ses promesses ?
Mathieu Ichou, Chargé de recherche à l’Ined, co-responsable de l’unité Migrations Internationales et Minorités (MIM), Ined (Institut national d'études démographiques)
Texte intégral (1621 mots)
Si, dans les familles immigrées, l’ascension scolaire est réelle, la génération des petits-enfants se heurte sur le terrain de l’emploi à des inégalités persistantes et à certaines formes de déclassement. C’est ce que montrent les résultats d’un projet de recherche inédit, mené à l’Institut national d’études démographiques.
En France, environ une personne de moins de 60 ans sur trois a un lien généalogique avec la migration : soit parce qu’elle est elle-même immigrée (« première génération »), soit parce qu’elle est l’enfant d’un ou de deux parents immigrés (« deuxième génération »), soit parce qu’elle est le petit-enfant d’au moins un grand-parent immigré (« troisième génération »).
Cette troisième génération reste méconnue, car les enquêtes de la statistique publique ne permettent pas de l’identifier. Les recherches sur les enfants d’immigrés ont déjà montré que leurs trajectoires scolaires et professionnelles sont très diverses : certains groupes atteignent des positions proches de celles de la population majoritaire sans ascendance migratoire, tandis que d’autres – notamment au sein des minorités racisées – restent plus exposés au chômage, à la ségrégation résidentielle ou aux discriminations.
Mais l’étude de cette deuxième génération ne permet pas toujours de savoir si ces écarts tiennent surtout à l’expérience migratoire des parents ou à des mécanismes plus durables, produits dans la société française elle-même. Les petits-enfants d’immigrés, nés en France de parents eux-mêmes nés en France, permettent de trancher : si des écarts subsistent encore à cette génération, ils signalent des mécanismes d’exclusion durables (ségrégation, discrimination, racisme), et non les seuls effets de la migration initiale.
Que deviennent ces petits-enfants d’immigrés en matière de diplômes et d’emploi ? Le modèle républicain tient-il ses promesses d’égalité, quelle que soit l’origine ?
Ce sont précisément les questions que nous nous sommes posées à travers le projet 3GEN, mené à l’Institut national d’études démographiques (Ined) et financé par l’ANR. Grâce à l’enquête Trajectoires et Origines 2 (TeO2), qui permet pour la première fois d’identifier directement les petits-enfants d’immigrés à grande échelle, les chercheurs et chercheuses impliqués dans le projet ont pu comparer les parcours de trois générations : les immigrés eux-mêmes, leurs enfants, et leurs petits-enfants.
Les analyses, que nous avons publiées avec Milan Bouchet-Valat, Louise Caron, Lucas Drouhot, Mathieu Ferry, Ognjen Obućina, Ariane Pailhé, Paul Siarry et Rosa Weber dans plusieurs revues scientifiques de premier plan (Revue française de sociologie, European Sociological Review, Demography et American Sociological Review) apportent des résultats inédits.
L’ascension scolaire sur trois générations
Le premier constat est celui d’une progression éducative importante. Les grands-parents immigrés arrivés en France dans l’après-guerre étaient, pour la grande majorité, sans diplôme : 72 % des grands-parents d’origine nord-africaine (Algérie, Maroc, Tunisie) et 55 % des grands-parents d’Europe du Sud (Portugal, Espagne, Italie) n’avaient aucun titre scolaire, contre 23 % pour les grands-parents nés en France de parents eux-mêmes français.
Leurs enfants et petits-enfants ont bénéficié de l’expansion du système scolaire français. Entre grands-parents et parents, la mobilité ascendante est frappante dans les familles immigrées : 67 % des trajectoires intergénérationnelles sont ascendantes dans les familles d’origine nord-africaine, et même 72 % dans les familles d’Europe du Sud, contre 54 % dans les familles de la population majoritaire.
Au final, les petits-enfants d’immigrés, pris dans leur ensemble, ont des trajectoires scolaires très proches de celles des personnes sans ascendance migratoire, notamment pour les petits-enfants d’immigrés sud européens.
Des inégalités qui persistent pour les descendants d’Afrique du Nord
La réalité est plus contrastée pour les petits-enfants d’immigrés nord-africains. Certes, ils progressent eux aussi nettement par rapport à leurs grands-parents et leurs parents. Mais des pénalités demeurent, tant dans l’accès à l’enseignement supérieur que dans la sortie du système scolaire sans aucun diplôme.
La situation n’est pas la même pour les filles et les garçons. Les petites-filles d’immigrés nord-africains connaissent des trajectoires scolaires favorables : elles sont même surreprésentées en haut de la distribution des diplômes. Ce sont principalement les petits-fils d’immigrés maghrébins qui concentrent les difficultés. Ils sont nettement plus représentés parmi les sortants sans diplôme, et nettement moins dans les classes préparatoires aux grandes écoles.
Ce contraste entre hommes et femmes au sein d’un même groupe d’origine n’est pas nouveau, mais il ne s’estompe pas à la troisième génération. Il suggère que les mécanismes à l’œuvre vont au-delà du simple héritage social familial, d’autant que les petits-enfants d’immigrés ont souvent grandi dans des milieux sociaux assez proches de ceux de la population majoritaire.
Le diplôme ne suffit pas : le déclassement professionnel subsiste
Une autre dimension, moins souvent examinée, est celle du déclassement : le fait d’exercer un emploi qui ne correspond pas à la formation obtenue. Le déclassement vertical désigne la situation où l’on est plus diplômé que les autres personnes occupant le même type de poste. Le déclassement horizontal renvoie au fait de travailler dans un secteur sans rapport avec son domaine d’études.
Le déclassement vertical touche surtout les immigrés à la première génération et s’explique essentiellement par la non-reconnaissance des diplômes obtenus à l’étranger. Dès la deuxième génération, formée en France, ce problème disparaît presque entièrement.
En revanche, le déclassement horizontal persiste de façon significative pour les hommes d’origine non européenne, et ce, jusqu’à la troisième génération. Davantage orientés vers des filières généralistes ou peu professionnalisantes, ils se retrouvent plus souvent dans des emplois sans lien avec leurs études.
L’intégration républicaine : entre promesses tenues et inégalités persistantes
Que conclure de l’ensemble de ces travaux ? La situation de la troisième génération nous renseigne moins sur l’immigration que sur le fonctionnement de la société française elle-même. Elle montre à la fois la force des processus d’égalisation au fil des générations et la persistance de certaines inégalités liées à l’origine.
D’un côté, une dynamique puissante de rattrapage scolaire est à l’œuvre sur trois générations. La mobilité sociale ascendante des familles immigrées est réelle quelle que soit l’origine, et les petits-enfants d’immigrés européens connaissent une véritable égalisation avec la population majoritaire. Ce résultat donne du crédit à l’idée d’une intégration progressive permise par les institutions françaises, notamment par l’école publique.
De l’autre côté, des frontières ethnoraciales persistent dans la durée. Les petits-fils d’immigrés nord-africains font face à des désavantages scolaires durables que l’origine sociale de leurs parents n’explique pas complètement. Les données de l’enquête TeO2 montrent d’ailleurs que ces petits-enfants déclarent plus souvent que leurs camarades sans ascendance migratoire avoir subi au moins un traitement injuste dans le cadre scolaire.
La persistance des inégalités à la troisième génération ne peut pas être rapportée seulement aux origines sociales modestes des grands-parents immigrés. Elles renvoient aussi à des processus de ségrégation et de discrimination qui continuent d’affecter les trajectoires scolaires et professionnelles. La promesse républicaine d’égalité des chances semble donc largement tenue pour les familles originaires d’Europe du Sud, mais reste inachevée pour les familles originaires d’Afrique du Nord.
Le projet 3GEN est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Mathieu Ichou a reçu des financements de l'ANR.
29.06.2026 à 11:12
Peut-on mesurer l’invisible ? Comment naissent les indicateurs qui guident nos décisions ?
Florence Jeannot, Full Professor in Marketing, INSEEC Grande École
Guy Parmentier, Professeur des universités à Grenoble IAE, Grenoble IAE Graduate School of Management
Romain Rampa, Professeur Adjoint, École de technologie supérieure (ÉTS)
Texte intégral (1410 mots)
Cela devrait être un préalable à toute action. Bien construire un indicateur ne s’improvise pas. Comment procéder pour être certain de bien mesurer la variable voulue, sans effets de bord et autres biais ? C’est d’autant plus essentiel que la décision s’appuie sur ces indicateurs. Décryptage de la méthode et illustration avec le cas de la créativité, une « compétence » qui n’est pas immédiatement mesurable.
Créativité, engagement, confiance, bien-être : ces notions occupent aujourd’hui une place centrale, qu’il s’agisse d’entreprises, d’institutions publiques ou d’organisations éducatives. Elles orientent des décisions importantes, de l’innovation à l’évaluation des politiques publiques, jusqu’à l’amélioration des conditions de travail. Dans un contexte marqué par l’incertitude et les transformations rapides, elles sont de plus en plus mobilisées pour éclairer la manière dont les organisations s’adaptent et font face à ces changements.
Un point commun les relie : elles ne sont pas directement observables et doivent être appréhendées à travers des indicateurs. Dès lors, comment mesurer ce qui ne se voit pas ? Ces notions sont dites « intangibles » : elles correspondent à ce que les chercheurs appellent des construits latents, c’est-à-dire des réalités que l’on ne peut saisir qu’indirectement. Autrement dit, on ne mesure pas directement la créativité ou le bien-être, mais les éléments qui permettent de les approcher.
Derrière ces indicateurs se cache un processus de construction scientifique exigeant, souvent méconnu, qui conditionne la manière dont ces réalités sont évaluées et, in fine, les choix qui en résultent.
À lire aussi : L’impact invisible des outils de chantier sur la santé des travailleurs
Mesurer n’est jamais un acte neutre. C’est une manière de rendre certaines réalités visibles, et donc d’orienter les décisions. C’est aussi une manière de préciser ce qui compte pour une organisation et ce que l’on choisit d’observer et de suivre dans le temps.
Ce processus s’appuie sur une démarche méthodologique bien établie, notamment dans les travaux de Gilbert Churchill sur le développement d’échelles de mesure. À partir de nos travaux récents, il est possible d’en comprendre les étapes et les enjeux.
Clarifier l’objet de la recherche
La première étape consiste à clarifier ce que l’on cherche réellement à mesurer. En pratique, un même terme peut recouvrir des réalités différentes. Dans notre recherche, nous nous sommes intéressés à la créativité organisationnelle, non pas comme un simple résultat, mais comme une capacité. Une organisation devient créative lorsqu’elle met en place des pratiques, des dispositifs et des routines qui favorisent durablement la génération et le développement d’idées.
Pour préciser ce concept, nous avons analysé 417 articles scientifiques, ce qui nous a permis d’identifier cinq dimensions : l’ouverture vers l’extérieur, la socialisation des idées, l’équipement créatif, la gestion des idées et l’agilité organisationnelle.
Cette étape transforme une notion abstraite en un cadre clair, indispensable pour construire des indicateurs fiables. Elle permet aussi d’éviter de réduire des phénomènes complexes à des indicateurs trop simplistes.
Traduire le concept en indicateurs
Une fois les dimensions définies, il s’agit de les rendre mesurables. Concrètement, cela consiste à construire des « items », c’est-à-dire des questions permettant de capter chaque dimension à travers des pratiques observables. Par exemple, une organisation favorise-t-elle les échanges d’idées ? Dispose-t-elle d’outils pour les développer ? Est-elle ouverte à des sources d’inspiration extérieures ?
Cette phase correspond à la génération et à la sélection des items : il s’agit de créer puis de retenir les indicateurs les plus pertinents, en éliminant ceux qui sont redondants ou peu fiables. L’enjeu n’est pas d’accumuler les mesures, mais de retenir celles qui rendent le mieux compte de la réalité étudiée. Dans notre étude, cette étape a permis de construire un ensemble de 16 items traduisant les différentes dimensions des capacités créatives organisationnelles, avant de les soumettre aux étapes de validation.
Indispensable vérification
La dernière étape consiste à vérifier la qualité des indicateurs et la robustesse de l’échelle de mesure. Nous avons ainsi mené une enquête auprès de 900 répondants issus de différentes organisations, à l’échelle internationale, afin d’élargir la portée des résultats. Les données ont été analysées à l’aide de deux approches complémentaires :
l’analyse factorielle exploratoire permet d’identifier comment les réponses se regroupent entre elles, autrement dit les grandes dimensions qui émergent des données ;
l’analyse factorielle confirmatoire permet ensuite de vérifier que ces regroupements correspondent bien au modèle théorique proposé.
Ces méthodes permettent ainsi de vérifier que les résultats sont cohérents et qu’ils correspondent bien à la manière dont le phénomène a été modélisé. Elles constituent une première étape dans l’évaluation de la robustesse de l’échelle, en vérifiant la solidité de sa structure.
Plusieurs tests sont ensuite réalisés pour évaluer la qualité de l’échelle. Ils permettent notamment de vérifier sa fiabilité, ainsi que différentes formes de validité. En particulier, la validité convergente signifie que les items censés mesurer une même dimension donnent des résultats cohérents. La validité discriminante vérifie que les différentes dimensions de l’échelle sont bien distinctes.
Enfin, la validité prédictive permet de s’assurer que les indicateurs sont liés à des résultats concrets, comme la production d’innovations. Ainsi, les résultats de notre étude montrent que l’échelle développée est fiable et robuste, et qu’elle permet d’anticiper les résultats créatifs au sein des organisations.
De la mesure à l’action
Cette démarche a donné lieu à la mise en ligne d’un outil accessible gratuitement, permettant aux organisations d’évaluer leurs capacités créatives. À partir d’un questionnaire, il est possible d’obtenir un score global, ainsi qu’un diagnostic détaillé des différentes dimensions, accompagné de pistes d’amélioration concrètes.
L’intérêt est double : rendre visible une capacité souvent difficile à repérer pour les organisations et fournir des leviers d’action pour la développer dans le temps. Au-delà des résultats, il s’agit de mieux comprendre les équilibres internes et les marges d’adaptation d’une organisation.
Cette démarche s’applique tant aux entreprises qu’aux institutions publiques et aux organisations éducatives. Elle peut également être mobilisée pour analyser d’autres notions que la créativité, y compris des phénomènes sociétaux tels que le bien-être psychologique ou la cohésion sociale. Dans tous les cas, les indicateurs reposent sur des choix théoriques et méthodologiques qui influencent leur interprétation. Ils contribuent ainsi à orienter les façons de penser et d’agir face à des enjeux complexes.
Florence Jeannot a reçu des financements de l'Agence nationale de la recherche.
Guy Parmentier a reçu des financements de l'ANR
Romain Rampa ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 11:12
C’est qui le patron ?! : comment la co-création permet de convaincre les consommateurs de payer un « prix juste »
Faten Malek, Associate professor, ESSCA School of Management
Arabella David Ignatieff, Enseignante chercheuse marketing, ESC Amiens
Norchene Ben Dahmane Mouelhi, Marketing, ESCE International Business School
Olivier Braun, ICN Business School
Texte intégral (2023 mots)
L’histoire de la création de la marque équitable C’est qui le patron ? ! est un exemple éclairant de la façon dont le consommateur peut faire plus qu’acheter un produit. Ou comment faire de ses clients des partenaires dans la durée. Décryptage d’un cas exceptionnel.
L’engouement pour le bio, la transparence et les valeurs environnementales pousse de nombreuses entreprises à revendiquer des engagements responsables. Dans ce paysage concurrentiel, dominé par de grandes firmes disposant de ressources marketing considérables, la marque C’est qui le patron ? ! (CQLP) occupe une position singulière : elle revendique un ADN équitable, participatif et historiquement orienté vers le juste prix et la gouvernance citoyenne.
Cependant, alors que les stratégies de responsabilité se multiplient au travers des labels, des engagements socialement responsables, de la communication verte, de l’innovation durable, la question de l’attractivité de cette marque s’impose dans un contexte de transition écologique s’impose comme un enjeu incontournable. Cependant, à mesure que les stratégies de responsabilité se multiplient à travers les labels, les engagements socialement responsables, la communication verte ou encore l’innovation durable, la question de l’attractivité de la marque s’impose comme un enjeu incontournable dans le contexte de transition écologique.
La marque des consommateurs à un prix plus « juste »
Pour comprendre ces enjeux, il faut revenir aux origines de la marque. En 2015, une nouvelle crise du lait survenait. Les producteurs français ont alors décidé de se mettre en grève, car ils n’arrivaient plus à vivre de leurs exploitations de lait pour des raisons conjoncturelles et structurelles : la chute des cours, la fin des quotas laitiers, l’ouverture des marchés… Notons que, à ce jour, la filière laitière est toujours fragilisée par la surproduction de lait et l’épisode de dermatose nodulaire.
Afin d’améliorer la condition des producteurs de lait, en 2017, Nicolas Chabane a eu l’idée de lancer la société SCIC ainsi que la marque CQLP. Elle soutient les producteurs en les rémunérant à un prix plus acceptable pour eux mais aussi raisonnable pour ses clients : le « juste prix ».
La marque s’est appuyée sur les consommateurs pour supporter cette initiative, inscrite plus largement dans le soutien du secteur agricole. Depuis, elle attire et fidélise une base de clients engagés, en France comme dans plusieurs pays limitrophes.
Ce modèle de croissance se traduit par la diversification progressive de son offre et le maintien de sa promesse de justice sociale, économique et environnementale.
Toutefois, cette trajectoire questionne la pérennité de l’équilibre entre l’engagement des consommateurs, les contraintes économiques et les attentes des différents intervenants de la chaîne de valeur.
Un positionnement gagnant pour tout le monde ?
Ce juste prix est une source de différenciation forte pour la marque qui répond à la sensibilité accrue des consommateurs à un comportement dit responsable, voire militant. Nicolas Chabanne, un des fondateurs, exprime les raisons de la création de la marque et les caractéristiques de son ADN en ces termes évocateurs : « il faut apporter plus de considération à ceux qui nous nourrissent, les agriculteurs, et faire attention à ce que nous mangeons : nos corps ne sont pas des poubelles, et au fond nous aspirons tellement à autre chose ».
Au‑delà de la question du « juste prix », les valeurs mises en avant par le fondateur reposent sur une plus grande considération des producteurs et une attention accrue à la qualité de l’alimentation. Ces principes se prolongent par une recherche de proximité avec les consommateurs, qui ne sont plus seulement des acheteurs, mais des acteurs impliqués dans le fonctionnement de la marque. CQLP s’est très vite fait une belle place sur le marché.
Elle se positionne également en cultivant la proximité et la participation avec ses clients. CQLP est la première entreprise agroalimentaire. Les clients sont associés, s’ils le désirent, à la sélection des produits, de leurs caractéristiques, telles que le packaging et le prix de vente. Les clients peuvent suggérer, notamment, la production de nouveauté, demander à des enseignes de distribuer des produits estampillés CQLP. Ils contribuent de plus à la modification de la gamme de produits, sur un ensemble de critères, traditionnellement géré par les services marketing et commercial, par exemple. La marque sollicite alors l’avis des clients et des sociétaires grâce à leur vote en ligne. Les consommateurs deviennent alors des « consommacteurs ».
Ces multiples formes de participation contribuent à la pérennité des principes d’équité, de transparence et d’authenticité portés par la marque. Certaines enseignes de la grande distribution souscrivent également à ces principes et favorisent le développement de CQLP.
En définitive, toutes les parties prenantes bénéficient de ce positionnement soutenable : producteurs, clients et distributeurs.
Le soutien de la communauté paysanne
L’entreprise a ainsi réussi à créer une communauté dynamique et engagée de plus de 13 000 sociétaires. Pour devenir sociétaire, il suffit de verser un euro seulement. La marque vise à inclure les clients comme les sociétaires dans son circuit de décision marketing et commercial : le client est le patron !
Dans cette logique, clients et sociétaires participent concrètement à la mise sur le marché de produits agroalimentaires. Par exemple, récemment, près de 1 000 d’entre eux ont participé au vote concernant l’intégration dans la gamme des tomates concassées en boîte. L’engagement des clients et des sociétaires s’inscrit également dans la volonté de valoriser les producteurs locaux.
L’engagement citoyen de CQLP se concrétise par plusieurs actions. La marque a ainsi redistribué plus de 150 millions d’euros, principalement via l’achat de productions agricoles (146 millions d’euros), mais aussi par le biais d’aides directes (5 millions d’euros), notamment à travers un « fonds de solidarité des consommateurs et citoyens » lancé en avril 2020. Dans cette même logique d’accompagnement des filières, elle a également versé plus de 3,4 millions d’euros entre 2017 et 2021 afin de soutenir la transition des exploitations agricoles vers l’agriculture biologique.
Ces initiatives contribuent à renforcer la crédibilité et l’attractivité de la marque. En mai 2024, CQLP a ainsi atteint la première place du classement Nielsen des nouvelles marques. Par ailleurs, elle a enregistré une croissance de 16 % de ses ventes en janvier et février 2026.
Travailler gratuitement
Face à des consommateurs en quête de preuves concrètes, de traçabilité et de transparence, CQLP mise sur la visibilité de l’origine de ses produits et sur leur implication dans la définition des caractéristiques des offres, notamment via des questionnaires. Cette démarche favorise l’émergence de « consommacteurs », fortement attachés à la marque et prêts à la défendre.
L’anxiété écologique et la méfiance envers les discours traditionnels des marques contribuent également à ce succès, en particulier lorsque les produits proposés soutiennent les producteurs locaux et participent à la réduction de l’empreinte carbone.
Dans ce contexte, les consommateurs acceptent non seulement de contribuer gratuitement à certaines activités de la marque, mais aussi de payer un prix légèrement supérieur pour des produits jugés plus équitables.
Plus généralement, les entreprises qui recourent à la co‑création, à l’image de CQLP, voient leur mode de fonctionnement évoluer. Cette logique implique une gestion plus participative intégrant à la fois collaborateurs, producteurs et consommateurs dans les processus de création de valeur.
En rendant visible l’origine de ses produits et en intégrant les consommateurs dans un processus structuré de co‑création, CQLP ne se limite pas à répondre à leurs attentes ; elle redéfinit la relation client en une relation engageante et solidaire.
Un capital marque relationnel et communautaire
La co‑création de valeur se manifeste lorsque les marques et leurs clients s’accordent sur les caractéristiques des produits proposés et les modalités de leur mise sur le marché. Ce processus contribue à la construction d’un capital de marque relationnel, fondé sur la confiance, l’engagement communautaire et une forme d’appropriation collective. Il constitue ainsi une source d’avantage concurrentiel à la fois singulière, durable et difficilement imitable.
La co‑création cumule plusieurs avantages :
elle améliore l’expérience et la satisfaction des clients, renforce la perception de la marque, favorise le bouche‑à‑oreille et contribue à la fidélisation
elle permet aux consommateurs de gagner du temps, d’accéder à des produits mieux adaptés à leurs besoins et d’exprimer à la fois leur singularité et leur créativité, renforçant ainsi leur rôle d’ambassadeurs engagés de la marque.
La promesse de la marque, son ADN et les avantages de la co‑création constituent une source d’inspiration pour les entreprises et les créateurs.
Modèle inspirant ?
CQLP, qui fête ses dix ans, incarne une approche innovante en plaçant les consommateurs au cœur de son modèle d’affaires. Ce modèle est susceptible de susciter l’intérêt d’entrepreneurs en quête d’innovation et de relations plus authentiques avec leurs publics. Il s’adresse plus largement à celles et ceux souhaitant concilier performance économique et engagement social et environnemental.
Dans un contexte économique marqué par l’incertitude, les consommateurs tendent en effet à privilégier des marques porteuses de sens, proposant des prix équitables et des produits de qualité. Cet ADN de marque apparaît transférable à d’autres secteurs désireux de renforcer leur capital de marque tout en répondant aux attentes croissantes en matière de responsabilité et de transparence. Ce modèle d’affaires a permis à une équipe de chercheurs d’avoir en juin 2026 le prix CCMP FNEGE de la meilleure [étude de cas RSE.]
La marque CQLP illustre l’évolution des marques vers des approches plus relationnelles, fondées sur la participation et la confiance.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 11:12
Les sciences de gestion, une discipline « jouvence » ?
Jérôme Lamy, Directeur de recherche au CNRS (historien et sociologue des sciences), Observatoire de Paris
Philippe Schäfer, Professeur associé en sciences de gestion, Excelia
Vincent Helfrich, Professeur, ESSCA School of Management
Texte intégral (1163 mots)
Les sciences de gestion restent méconnues d’un public non initié. Voilà un prétexte pour étudier la diversité de ses investissements scientifiques.
Cet article est publié dans le cadre d’un partenariat avec la Revue française de gestion, qui a fêté ses 50 ans en 2025.
Les sciences de gestion, comme discipline scientifique, sont très peu connues du grand public. Il faut dire qu’à côté d’autres sciences plus anciennes et mieux ancrées, elles doivent constamment affirmer leur légitimité. Comment observer, de façon globale, l’évolution d’une discipline ? Nous avons fait le choix d’étudier les différentes façons dont les articles réflexifs publiés par la Revue française de gestion, rendaient compte des évolutions disciplinaires de la gestion. L’enjeu est de saisir la spécificité de cette discipline via la stratification fine des pratiques de recherche qu’elle investit.
Nous avons requis un outil d’analyse, les régimes de science, développé par le sociologue Terry Shinn. Les régimes de sciences caractérisent différentes formes d’investissements scientifiques en rendant compte des moyens mis en œuvre, des pratiques ordinaires de validation des savoirs et des audiences visées. Les sciences de gestion se distinguent par une implication forte et simultanée dans quatre de ces régimes, ce qui explique à la fois leur hétérogénéité et leur difficulté persistante à établir une identité unique capable de transcender l’enfermement induit par des logiques de spécialisation disciplinaire.
Le régime disciplinaire : une quête identitaire
Le régime disciplinaire est le socle de toute science, centré sur sa communauté, ses revues et la création de connaissances. Les sciences de gestion regroupent un ensemble hétérogène d’objets d’étude et de méthodologies, segmenté en sous-disciplines (stratégie, marketing, finance, management, logistique, etc.) qui se développent parfois de manière autonome. Ce trait composite conduit à une hétérogénéité persistante.
À lire aussi : Une brève histoire des méthodes managériales
Loin d’être un défaut, cette fragmentation est considérée comme un mode d’existence structurel d’une science dont l’objet d’étude est essentiellement multidimensionnel et en transformation permanente : l’action organisée. L’évolution des sciences de gestion est donc marquée par une posture de « prescience perpétuelle » car la discipline interroge en permanence ses fondements épistémiques.
Le régime transitaire : le point d’origine des sciences de gestion
Le régime transitaire décrit la circulation des acteurs, des concepts et des méthodes entre disciplines. Nées tardivement en France, les sciences de gestion ont émergé comme une « discipline-carrefour » à partir des années 1970. Elles se sont constituées en accueillant des économistes, des ingénieurs et des sociologues et ont donc naturellement emprunté à des sciences aussi diverses que l’économie, la sociologie, la psychologie, l’ingénierie, les mathématiques, pour se construire.
Néanmoins, ce mouvement n’est plus à sens unique. Depuis les années 2000 et surtout 2010, la discipline est devenue une source d’inspiration et de transfert pour d’autres domaines scientifiques (comme l’étude des dynamiques organisationnelles).
Le régime utilitaire : de l’efficacité opératoire à une utilité sociale
Le régime utilitaire est axé sur les débouchés commerciaux et la résolution de problèmes techniques. Contrairement aux sciences naturelles, les sciences de gestion sont peu concernées par le dépôt de brevets. Elles développent cependant de nombreux outils (instruments) pour tout type d’organisations. C’est principalement le rapport à l’action qui alimente, dans les années 1980, les débats internes à la discipline : quel équilibre trouver entre un utilitarisme trop dominant et une recherche « hors sol », trop éloignée du terrain ?
La tension entre rigueur académique et pertinence pratique demeure constante en sciences de gestion. Cependant, cette obsession d’utilité connaît aujourd’hui une inflexion notable. Les chercheurs interrogent aujourd’hui les effets des connaissances produites sur la société (avec, par exemple, l’intégration des exigences environnementales).
Le régime régulatoire : inspirer les politiques économiques et sociales pour transformer la société
Les sciences de gestion ont été moins visibles dans l’appareil d’État que d’autres disciplines. Le régime régulatoire concerne une forme de recherche qui répond aux besoins de l’action publique, notamment en matière de gouvernance et de régulation. Ces préoccupations sociales nourrissent le développement le plus récent, s’accentuant après la crise financière de 2008, la pandémie de Covid et les manifestations récurrentes des changements climatiques.
Ainsi, depuis le début des années 2000, des chercheurs en gestion ont fait une véritable « offre de service » pouvant contribuer aux politiques publiques, même si les articulations avec les institutions de gouvernement sont restées mineures dans les faits.
Notre analyse rend compte de la diversité des investissements scientifiques au sein des sciences de gestion qui se sont constituées en discipline, pour l’essentiel, à partir des années 1970. Les acteurs de la discipline, tels qu’ils se sont exprimés depuis cinquante ans dans la Revue française de gestion, ont tenté de défendre un modèle scientifique d’investissement maximal. C’est-à-dire que la gestion a été pensée comme une discipline modèle, capable de répondre à toutes les formes d’injonction épistémiques : disciplinairement efficace, opérationnelle d’un point de vue utilitaire, ouverte aux transferts de méthodes et prête à contribuer aux sciences de gouvernement.
En plus de son réexamen épistémique permanent, qui lui confère un statut de discipline « jouvence », la gestion est aussi marquée par une forme d’hypercorrection scientifique (pour reprendre une approche de Pierre Bourdieu et Luc Boltanski) qui lui fait s’astreindre à des exigences accrues de légitimité.
Jérôme Lamy a reçu des financements du CNES et du CNRS
Philippe Schäfer et Vincent Helfrich ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
29.06.2026 à 11:11
La science des passes en football nous apprend qu’au-delà de 60 % de stars dans l’équipe, la performance baisse
Mehdi Bagherzadeh, Professeur, Neoma Business School
Fabio Fonti, Professeur, Neoma Business School
Texte intégral (1543 mots)
Et si le succès dépendait moins de la présence des meilleurs joueurs que de la mise en place de conditions propices à un collectif fort ? C’est la leçon tirée d’une étude portant sur 1 750 matchs dans les cinq principales ligues masculines européennes de football lors de la saison 2017–2018. La Coupe du monde 2026 nous donnera peut-être une nouvelle occasion de le vérifier.
L’équipe de France avec un collectif composée de stars aura-t-elle moins de chance de remporter la Coupe du monde que des équipes avec un collectif plus fort organisées autour de joueurs moins célèbres ?
Car après des « années de galère et de combat », le Paris Saint-Germain (PSG) a remporté la Ligue des champions de l’UEFA lors de la saison 2024-2025, à la suite du départ de Lionel Messi, Neymar da Silva Santos Júnior et Kylian Mbappé, trois des meilleurs footballeurs du monde, avant de conserver le titre cette saison. À maintes reprises, le monde du football a démontré à quel point des équipes très talentueuses peuvent décevoir, tandis que des équipes moins bien dotées dépassent souvent les attentes.
Nos recherches récentes remettent en cause l’idée reçue selon laquelle, en matière de stars, « en compter plus, c’est toujours mieux ».
En croisant les données de 1 750 matchs de 91 équipes dans cinq ligues de football, nous avons montré que la relation entre la proportion de joueurs vedettes et la performance de l’équipe dessine un U inversé. Au-delà d’un certain seuil, chaque star supplémentaire réduit la probabilité de victoire. Notre point de basculement : 60 % de stars dans l’effectif. Au-delà, la performance commence à décliner.
Dans notre étude, un joueur est considéré comme « vedette » s’il obtient une note FIFA video game moyenne ≥ 80/100 sur trois saisons consécutives. Ce seuil correspond aux 1 % les plus élevés parmi les 29 869 joueurs répertoriés dans la base de données, et à seulement 10 % des joueurs des cinq ligues étudiées. En matière de coût, leur valeur médiane de marché atteint 17,4 millions d’euros, contre 2,1 millions pour un joueur ordinaire, soit près de huit fois plus.
Circuit de passe
Ce qui fait vraiment la différence entre une bonne et une mauvaise équipe, ce n’est pas tant qui la compose, mais comment elle travaille ensemble. Pour ce faire, nous avons modélisé les circuits de passes de chaque match sous forme de matrices. Alors qui transmet le ballon à qui ?
Deux paramètres ont été mesurés :
la densité du « circuit de passe », c’est-à-dire le degré auquel les joueurs sont connectés les uns aux autres par des passes. Plus ce réseau est dense, plus on compte de joueurs qui échangent directement le ballon entre eux ;
sa centralité, soit le degré auquel le jeu se concentre autour d’un ou de quelques joueurs.
Ces paramètres ont ensuite été croisés avec la proportion de joueurs vedettes dans chaque équipe et le résultat du match. Conclusion : les clubs comptabilisant plusieurs vedettes obtiennent de moins bons résultats lorsque leur jeu repose sur un petit nombre de ces stars, alors que le reste de son effectif reste à l’écart. À l’inverse, les équipes dont le ballon circule entre tous les joueurs, sans revenir systématiquement aux mêmes, tirent mieux parti de leurs vedettes.
Densifiée et décentralisée
Par exemple, lors de la saison 2017–2018 de Bundesliga, le Bayern Munich alignait 71 % de joueurs vedettes. Grâce à un circuit de passes à la fois dense – où de nombreux joueurs s’échangent le ballon directement entre eux – et décentralisé – aucun joueur ne monopolise le jeu –, le club a battu 6-1 le Borussia Dortmund qui compte 43 % de vedettes.
A contrario, l’AS Roma – 50 % de vedettes –, dont le circuit de passe était trop centralisé autour de ses stars, a subi une défaite 1-3 face à l’Inter Milan – 36 % de vedettes.
Pour gagner, les équipes composées de stars doivent créer des circuits de passe où davantage de joueurs sont connectés les uns aux autres par des passes. Les quelques stars ne doivent pas monopoliser le jeu ; les joueurs de l’équipe doivent se relayer pour gérer le jeu. Ce schéma allège la pression sur chaque joueur et garantit que l’ensemble de l’équipe contribue à la performance collective.
Tactique de passe efficace
Nous avons également constaté que les équipes composées de seulement 25 % de stars, mais avec des tactiques de passes mieux organisés – moins denses, mais décentralisés, différents joueurs prenant tour à tour une part active au jeu plutôt que quelques joueurs monopolisant le ballon – pouvaient surpasser des équipes dotées d’un vivier de talents bien plus solide. Les premières affichent une probabilité de victoire de 35 % supérieure à ce que leur seul niveau de talent laissait prévoir – et battent même en probabilité des équipes composées à plus de 60 % de vedettes mal organisées.
La performance ne dépend pas uniquement du talent individuel, mais de la qualité des modes de collaboration au sein de l’équipe.
Nos recherches déplacent le regard du manager de la question du « qui » vers celle du « comment ». Sans modes de collaboration adaptés au profil de l’équipe et relations appropriées, même les équipes les plus talentueuses peuvent échouer. Ce changement de paradigme commence à s’imposer dans les organisations avant-gardistes. En sciences du management, le leadership est d’ailleurs de moins en moins conçu comme un rôle individuel ; il devient un processus collectif dans lequel les membres collaborent pour produire des résultats qu’ils ne pourraient pas réaliser seuls.
Qu’est-ce que les managers devraient faire différemment ?
Le talent ne garantit pas la performance
Les managers qui dirigent des équipes avec de nombreux talents – équipes de recherche et développement (R&D), comités de direction, groupes de travail transervsaux – s’exposent à des rendements décroissants, voire négatifs. Dans notre étude, le point de basculement est de 60 % de stars. Au-delà, la performance décline.
Ces équipes partagent avec les équipes de football une caractéristique décisive : l’interdépendance de leurs tâches. C’est précisément cette interdépendance qui détermine si le talent individuel se transforme en performance collective. Les équipes moins talentueuses peuvent obtenir de bons résultats, en jouant sur la qualité de leur organisation interne.
Par ailleurs, un joueur vedette coûte près de huit fois plus qu’un joueur ordinaire. Les ressources consacrées au recrutement de stars peuvent parfois être mieux employées à structurer la collaboration au sein de l’équipe existante.
Accroître les rendements collectifs
Les managers doivent aller au-delà de la simple acquisition d'employés dotés de talent et plutôt réfléchir activement à la manière de structurer la collaboration de leurs équipes afin d’améliorer le rendement collectif.
Notre étude suggère trois leviers concrets à activer :
réorganiser les tâches et les flux d’information pour créer des modes de collaboration adaptés au profil des employés ayant le plus de potentiel ;
établir ces configurations dès le début. Les analyses intramatch montrent une forte inertie des schémas de collaboration – une fois installés, ils persistent ;
surveiller activement ces fonctionnements tout au long de la vie du projet, pour éviter que des événements imprévus – départ d’un membre clé, succès ou échecs précoces – ne déstabilisent les schémas optimaux.
Les grandes équipes ne sont pas un simple assemblage de talents ; elles sont conçues pour créer des liens. Le talent n’est qu’un potentiel ; ce sont des modes de collaboration bien pensés qui le transforment en performance. Plutôt que de se livrer à la « guerre des talents », les managers gagneraient à orchestrer ce qu’ils ont déjà.
Cet article a été corédigé avec Andrew C. Loignon, chercheur senior au Center for Creative Leadership (États-Unis).
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 11:10
La hausse des arrêts maladie est-elle la conséquence d’un problème de management ?
Gabriel Lomellini, Assistant Professor, HR and Organizational Behavior, ICN Business School
Texte intégral (1549 mots)
À partir du 1er septembre, la durée maximale d’une première prescription d’arrêt de travail sera plafonnée à un mois pour « contrer les abus et diminuer la facture » de 17,9 milliards d’euros de 2025. Ces absences pour raison de santé ne devraient-elles pas également être interprétées comme un signe de contestation d’un management ressenti comme vertical et contrôlées par les chiffres ?
Un récent baromètre Axa sur l’absentéisme a confirmé une tendance de fond : la hausse des arrêts maladie, en particulier de longue durée.
Si cette hausse concerne toutes les catégories sociales, elle touche principalement les jeunes de moins de 30 ans et les cadres. Plus généralement, parmi les arrêts longs, la première cause concerne les troubles psychologiques à 38 % en 2025, devant les troubles musculosquelettiques à 27 %.
Compte tenu du montant associé en 2025 aux arrêts maladie (environ 18 milliards d’euros), le gouvernement a annoncé une série de mesures se déployant selon un double volet : améliorer la qualité de vie au travail et contrôler les abus. Un décret fixe une durée maximale de 31 jours pour une première prescription et de 62 jours pour une prolongation.
Parmi ces mesures, on note un oubli majeur, celle de la question du management et de son rôle dans la santé au travail.
Au-delà de l’approche en termes de coûts, cette hausse doit interroger sur le rôle du management comme facteur de santé au travail, dans un contexte d’émergence de nouveaux risques liés à l’intelligence artificielle générative.
Pour ce faire, je m’appuie sur une approche transdisciplinaire, qui emprunte à la philosophie, la psychanalyse ou encore aux études critiques en management, ainsi que sur mes recherches sur l’expérience subjective du travail.
Tenir compte du travail réel
La santé au travail se situe à l’intersection de facteurs individuels et des pratiques de management. Dès les années 1960, le psychiatre et médecin du travail Claude Veil soulignait que l’absentéisme constitue un symptôme de l’état de l’organisation du travail. En matière d’absentéisme, écrit-il :
« Ce ne sont pas les données propres aux travailleurs qui jouent le plus grand rôle, mais bien des éléments qui dépendent de l’entreprise. »
Si le management joue un rôle si important dans la santé au travail, c’est qu’il détermine dans une large mesure les contraintes portant sur le travail réel, soit les tâches effectivement réalisées par un individu. Tenir compte du travail réel dans les pratiques de management est une condition indispensable pour effectuer un travail de qualité et préserver la santé des salariés.
Pour une infirmière, par exemple, un travail de qualité signifie plus que les conditions matérielles d’accueil et de soin. Écouter la personne à prendre en charge ou être en mesure de nouer un lien d’empathie contribue à un travail de qualité. Lorsque des pressions organisationnelles empêchent le travail réel – cadences impossibles ou objectifs trop élevés –, le risque est de basculer dans la souffrance.
Indicateur de l’état du management
L’arrêt maladie peut être interprété, sans toutefois s’y réduire, comme un certain indicateur de l’état du management. Depuis plusieurs années, un management encore très vertical et un contrôle par les chiffres fragilisent la santé sur les lieux de travail.
Le management reste en France particulièrement vertical et peu démocratique, ce qui restreint de fait l’autonomie individuelle et collective. Et si le recours massif au télétravail, au moment de la pandémie de Covid-19, a pu être vécu comme une prise d’autonomie de la part des salariés, le « retour au bureau », à l’inverse, a été ressenti comme une reprise du contrôle par le management.
Plus encore, les indicateurs chiffrés ont pris le pouvoir dans les organisations, évaluant le travail de manière individuelle. Bien que le management par les chiffres émerge à partir des années 1990 dans les entreprises privées, il ne s’y limite pas. Ce qu’on a appelé la New Public Management a étendu un ensemble d’outils de mesure de la performance dans les hôpitaux ou la fonction publique. Des mesures qui ont promu un « management désincarné », selon l’expression de la sociologue Marie-Anne Dujarier, à travers des indicateurs conçus à une très grande distance des réalités du métier et du vécu des salariés.
Réponse à l’exploitation ressentie
Par conséquent, la hausse des arrêts maladie interroge plus profondément sur l’affaiblissement des liens collectifs sur les lieux de travail. Comme le rappelle Pierre-Yves Gomez, chercheur en gestion :
« L’arrêt maladie illustre bien l’individualisation de la revendication sociale. Qu’il soit lié à la fatigue physique ou à la souffrance psychique, il traduit, comme toute forme de grève, le droit de suspendre son activité en réponse à l’exploitation ressentie par le travailleur. »
En sus de ces tendances de fond, le management se trouve percuté par le déploiement de l’intelligence artificielle. Un bouleversement qui implique d’être attentif à de nouveaux risques pour la santé.
Management par les algorithmes
En continuité d’un management par les chiffres, le « management algorithmique » s’est initialement déployé dans le cadre du capitalisme de plateforme, avec des entreprises comme Uber. Au sein de ces organisations, les algorithmes automatisent déjà une grande partie des tâches traditionnellement dévolues au management : évaluer, organiser ou distribuer le travail.
Les études soulignent que le management algorithmique peut contribuer à dégrader la santé des travailleurs. Les livreurs à vélo, ou encore les chauffeurs VTC, sont isolés face à la plateforme, coupés de leurs collègues, constamment évalués par des systèmes de notation, et sommés de s’adapter en temps réel à des algorithmes opaques et imprévisibles.
À lire aussi : Livreurs à domicile : comment le « management algorithmique » dégrade la santé des travailleurs
Des modalités de management qui se sont récemment étendues à des professions jusqu’ici protégées comme le journalisme ou encore des scénaristes hollywoodiens, ces derniers s’étant même mobilisés contre les risques qu’encourt leur profession.
Cerveau grillé
En dépit des promesses et espoirs suscités, ces technologies risquent non seulement de déqualifier le travail, certaines tâches devenant obsolètes, mais aussi de l’intensifier tant physiquement que mentalement. Certains cadres font état d’un sentiment de « brain fry », soit littéralement « cerveau grillé », du fait d’une utilisation intensive de l’IA au travail.
Face à cette combinaison de nouveaux risques, il est crucial d’adopter une approche holistique et préventive de la santé au travail. Dans une économie qui reste obsédée par la performance, les arrêts maladie doivent être interprétés comme un signe avant-coureur des tendances profondes du management et de notre rapport collectif au travail.
Gabriel Lomellini ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
28.06.2026 à 15:30
Clean beauty : comment une notion aussi floue est-elle devenue incontournable ?
Véronique Sadtler, Professeure, Université de Lorraine
Texte intégral (1663 mots)
Dans les rayons de cosmétiques, les promesses se multiplient : « naturel », « sans sulfate », « sans paraben », « 0 % silicone », « 95 % d’origine naturelle ». Ces mentions aujourd’hui omniprésentes sont devenues pour beaucoup de consommateurs des repères simples et rassurants face à des formulations souvent difficiles à décrypter. Mais que signifient-elles réellement ? Et comment une notion aussi floue que la « clean beauty » est-elle devenue en quelques années un argument majeur de l’industrie cosmétique ?
La question de l’exposition aux substances chimiques présentes dans les produits du quotidien fait régulièrement l’objet de travaux scientifiques. Une récente étude de l’Inserm a ainsi montré qu’une réduction temporaire de l’utilisation de certains produits cosmétiques et d’hygiène courants (shampooings, déodorants, dentifrices ou maquillage) pouvait entraîner une baisse mesurable de plusieurs polluants chimiques et perturbateurs endocriniens comme le bisphénol A.
Plus largement, les travaux consacrés aux perturbateurs endocriniens contribuent à alimenter les interrogations de la population sur les substances présentes dans les cosmétiques utilisés chaque jour. Les controverses régulièrement relayées dans les médias autour de certaines substances chimiques, ainsi que plusieurs procédures judiciaires récentes impliquant de grands groupes du secteur, entretiennent également ces débats dans l’espace public. Dans ce contexte, il n’est pas surprenant que la composition des produits soit devenue un critère de choix pour une part croissante des consommateurs.
C’est dans ce climat qu’a émergé la clean beauty. Apparue aux États-Unis dans les années 1990-2000 dans un contexte réglementaire beaucoup moins strict qu’en Europe, elle s’est progressivement diffusée à l’échelle mondiale. Les marques se sont à leur tour emparées de ces attentes, faisant de la clean beauty un argument central de communication. Cette tendance influence à présent l’ensemble du secteur cosmétique. Elle est souvent présentée comme l’une des grandes évolutions de l’industrie de la beauté au cours de la dernière décennie.
Cela témoigne d’un changement plus profond du rapport des consommateurs aux articles de soin et d’hygiène : au-delà de l’efficacité attendue, ils cherchent davantage à comprendre ce qu’ils utilisent au quotidien. Le succès de la clean beauty traduit ainsi un besoin croissant de réassurance. Face à des formulations complexes, beaucoup recherchent des repères plus simples pour guider leurs choix.
Une notion floue dans un secteur pourtant très réglementé
Mais derrière ce succès se cache un paradoxe. Contrairement aux labels ou certifications, la clean beauty ne repose sur aucune définition réglementaire harmonisée. Aucun texte européen ne définit ce qu’est une cosmétique « clean ». Chaque marque peut ainsi proposer sa propre interprétation : exclusion de certaines substances, limitation du nombre d’ingrédients, priorité donnée aux ingrédients d’origine naturelle ou encore mise en avant de procédés de fabrication particuliers.
Cette absence de définition contraste avec le niveau élevé de réglementation du secteur cosmétique européen. Les produits commercialisés en Europe font l’objet d’une évaluation de sécurité avant leur mise sur le marché. Plus de 1 300 substances y sont interdites et de nombreuses autres soumises à restriction.
On pourrait donc penser que ce cadre réglementaire répond déjà aux attentes d’un grand nombre de consommateurs. Malgré cela, les interrogations persistent. Les débats autour des perturbateurs endocriniens, des PFAS [13] ou de certaines substances classées CMR (cancérogènes, mutagènes ou toxiques pour la reproduction)) continuent d’alimenter les préoccupations de la population. Cette tension entre réglementation, perception du risque et attentes des utilisateurs apparaît également dans les débats récents autour du projet européen dit « Omnibus VI ». Présenté comme une simplification réglementaire, ce texte a suscité des inquiétudes chez plusieurs associations de consommateurs et organisations environnementales qui craignent un allongement des délais d’interdiction de certaines substances classées.
Quand la transparence ne suffit plus
On pourrait alors imaginer que la solution réside dans davantage d’informations. Après tout, la réglementation impose déjà une transparence importante. Tous les produits doivent afficher la liste complète de leurs ingrédients selon la nomenclature internationale INCI (International Nomenclature of Cosmetic Ingredients). La Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF) rappelle régulièrement l’importance de lire l’étiquetage complet des cosmétiques et souligne que les allégations doivent être vérifiables.
Cependant, transparence ne signifie pas nécessairement compréhension. Paradoxalement, les utilisateurs n’ont probablement jamais eu autant d’informations à leur disposition. Toutefois, entre les listes INCI, les allégations marketing, les labels et les différentes définitions de la naturalité, il reste souvent difficile de s’y retrouver.
Pour répondre à cette difficulté, certaines marques complètent désormais la liste INCI par des explications simplifiées indiquant l’origine ou la fonction des ingrédients (« agent nettoyant », « conservateur », « issu d’huiles végétales », etc.). Malgré cette abondance d’informations, de nombreux consommateurs peinent encore à interpréter des termes comme « clean », « naturel » ou « sans… », faute de définition harmonisée.
De plus, la liste INCI renseigne sur l’identité des ingrédients mais rarement sur leur origine ou leur mode d’obtention. Ainsi, certains composés parfumants, comme la vanilline, peuvent être obtenus par extraction végétale, biotechnologie ou synthèse chimique, sans que cette origine apparaisse dans leur nom. La notion de naturalité elle-même peut prêter à confusion : certains tensioactifs utilisés dans les shampooings et gels douche, comme les glucosides, sont fabriqués à partir de sucres et d’huiles végétales mais nécessitent plusieurs étapes de transformation chimique avant d’être incorporés dans une formule. Autrement dit, « naturel » ne signifie pas nécessairement « non transformé ».
Face à cette complexité, les applications, les labels et les mentions « sans… » jouent un rôle de simplification. Certaines bases de données et associations de consommateurs recensent désormais plusieurs milliers de cosmétiques contenant des ingrédients considérés comme indésirables ou controversés, contribuant à renforcer la vigilance du public vis-à-vis de la composition de ce qu’ils utilisent. Le « clean » devient alors autant un signal de confiance et de lisibilité qu’une caractéristique objective du produit lui-même.
Une promesse de simplicité face à la réalité des formulations
Reste une question essentielle : cette recherche de simplicité se traduit-elle réellement par des formulations plus simples ? Le shampooing illustre bien cette évolution, où les mentions « sans sulfates » ou « sans silicone » se sont largement diffusées ces dernières années. Or, concevoir un shampooing suppose de concilier nettoyage, stabilité, conservation, texture, mousse et sensorialité. La suppression d’un ingrédient nécessite de rééquilibrer l’ensemble de la formule et parfois de reprendre une partie du développement. La longueur d’une liste d’ingrédients ne constitue donc pas, à elle seule, un indicateur pertinent de qualité.
Au fond, les consommateurs ne recherchent pas uniquement des produits jugés plus naturels ou plus sûrs. Ils cherchent aussi à mieux comprendre ce qu’ils utilisent. C’est sans doute ce qui explique le succès de la clean beauty auprès d’un public confronté à des formulations de plus en plus complexes à décrypter.
Pourtant, derrière une liste d’ingrédients raccourcie ou une promesse de naturalité se cache souvent la même réalité : un cosmétique doit continuer à remplir les fonctions attendues par l’utilisateur. La clean beauty apparaît ainsi moins comme une catégorie scientifique clairement définie que comme une réponse à une demande de lisibilité, de transparence et de réassurance.
Véronique Sadtler ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
28.06.2026 à 15:30
Lutte contre les noyades : la sécurité de la baignade est une affaire de famille
Jeoffrey Dehez, Chargé de recherche en économie des loisirs et environnement, Inrae
Bruno Castelle, Directeur de Recherche CNRS, Université de Bordeaux
Sandrine Lyser, Ingénieure d’études en statistique, Inrae
Texte intégral (2005 mots)

En France, chaque année, les plus jeunes payent un lourd tribut à la noyade : celle-ci est la principale cause de mortalité par accident de la vie courante. Comment les adolescents appréhendent-ils ce risque ? Quel rôle leurs parents ont-ils à jouer ? Une nouvelle étude esquisse des pistes de réponses.
Les épisodes de canicule qui se succèdent mettent nos organismes à rude épreuve. Pour espérer en atténuer (un peu) les effets, la baignade apparaît comme une solution naturelle.
Pour tous ceux qui n’ont pas la possibilité de profiter d’une piscine (publique ou privée), la France regorge de plages, de rivières et de lacs susceptibles de répondre à cet impérieux besoin de fraîcheur.
Mais se baigner dans le milieu naturel n’est pas sans danger. Or, les adolescents semblent particulièrement exposés à ces risques, comme le révèle notre nouvelle enquête.
La vulnérabilité des adolescents face à la noyade
En France, la noyade est la première cause de mortalité par accident de la vie courante chez les moins de 25 ans : en 2016, elle comptait pour près d’un quart de ces décès (23 %, soit 135 décès sur 591 cette année-là. Pour les 13-25 ans, ces noyades ont principalement lieu en milieu naturel, autrement dit à la mer, dans des cours d’eau ou plans d’eau.
Plusieurs facteurs de risques sont généralement invoqués pour expliquer ce triste constat : des aléas mal connus par les adolescents (tels que les courants de baïne à l’océan), une appétence pour le risque, un excès de confiance en soi ou l’influence des pairs, particulièrement chez les garçons. Ce phénomène n’est pas propre à la France. On l’observe également en Australie, en Nouvelle-Zélande ou aux États-Unis.
Depuis plusieurs années, les adolescents sont ainsi devenus une priorité des politiques de prévention et de sensibilisation.
Or, si cette période de la vie s’accompagne effectivement d’une volonté de mise à distance des parents, il serait assez rapide de conclure à une totale autonomie des adolescents vis-à-vis de ces derniers. Face aux risques de baignade, les parents ont un rôle à jouer, à tous âges.
Une enquête auprès de collégiens
Pour tenter d’apprécier l’influence des parents dans la prévention des risques de baignade chez les adolescents, nous avons réalisé une enquête auprès d’un échantillon de collégiens, âgés de 11 à 15 ans, dans un établissement scolaire de la région bordelaise. Le collège en question et les zones d’habitation environnantes se situent à une heure de route environ des plages les plus proches de l’océan (soulignons qu’en l'état, les résultats peuvent difficilement être généralisés à une population plus large).
Nous avons demandé à 416 élèves de répondre à un questionnaire destiné à mieux connaître la nature de leurs activités à l’océan, ainsi que leur connaissance des règles de sécurité et des dangers. Ils ont également dû se projeter dans un scénario hypothétique décrivant une situation sur une plage non surveillée, en présence de camarades de leur âge, avec ou sans leurs parents présents sur place. Ils devaient indiquer, sur une échelle à cinq niveaux, la probabilité qu’ils se baignent, ainsi que le degré de risque perçu.
Une originalité du questionnaire est d’avoir été co-conçu avec un panel d’élèves du collège inscrits à l’option « sauvetage aquatique », afin d’améliorer sa compréhension par les autres enfants (ces élèves n’ont pas participé à l’enquête par la suite).
Une forte exposition au danger
En dépit de leur relatif éloignement géographique vis-à-vis de l’océan, plus de 9 adolescents sur 10 (92 %) ont déclaré s’y être rendus au moins une fois durant les douze derniers mois. Sur place, presque tous déclarent se baigner (98 %). Près des deux tiers (68 %) ont également indiqué s’être baignés au moins une fois hors des zones surveillées.
À peine plus de la moitié (52 %) des jeunes gens interrogés a été capable d’expliquer correctement la façon dont les zones de bain surveillées sont matérialisées (à l’aide de drapeaux rectangulaires jaunes et rouges).
Parmi les dangers de l’océan, les courants de baïne ont été cités par 64 % des collégiens interrogés, devant les vagues (36 %) et la marée (17 %). Sur les plages océanes du Sud-Ouest, cette dernière ne constitue pourtant généralement pas en elle-même un aléa. En effet, à l’exception du voisinage des embouchures, elle ne génère pas de courant important. Elle module en revanche l’activité des aléas : en moyenne, les courants de baïne sont plus intenses entre la marée basse et la mi-marée, et les vagues de bord sont plus violentes à marée haute.
Face à ces courants potentiellement dangereux, 34 % des jeunes ont répondu qu’il fallait faire la planche, tandis que 23 % seraient prêts à demander de l’aide aux surfeurs s’il y en a à proximité, et 20 % appelleraient à l’aide. Si chacune de ces réponses est pertinente, on peut toutefois regretter qu’elles ne soient pas citées par un plus grand nombre d’élèves…
L’avis des parents compte
Pour les jeunes adolescents interrogés, les parents demeurent un repère. Durant notre enquête, ils constituaient la principale source d’information vis-à-vis des dangers à l’océan, citée par 57 % des répondants, devant la télévision ou la radio (citées par 20 % des enquêtés), à égale position avec Internet et les réseaux sociaux (20 % de citations). L’école arrivait ensuite (avec 17 %). Les amis n’ont été mentionnés que par 8 % des répondants.
L’influence des parents se fait également sentir au travers des scénarios hypothétiques auxquels les collégiens ont été soumis. Ainsi, la probabilité de se baigner (hors d’une zone surveillée, rappelons-le) s’est révélée plus élevée – et le danger perçu, plus faible – lorsque nous indiquions que les parents étaient présents à la plage, par rapport à la situation où ils ne l’auraient pas été.
Cette influence des parents diminue au fur et à mesure que l’âge des répondants augmente. On constate par ailleurs que la propension à entrer dans l’eau est plus élevée chez les garçons.
Ces relations sont significatives sur un plan statistique, même si les raisons d’un tel résultat sont naturellement sujettes à discussions. Pour les adolescents, la présence des parents a pu être interprétée comme une autorisation de fait (« si les parents sont là, alors j’ai le droit d’y aller »).
En outre, au cours de nos précédentes études menées en Nouvelle-Aquitaine, une majorité d’adultes déclarait se baigner hors des zones ou des périodes surveillées. Il n’est donc pas impossible que les enfants aient eux aussi été influencés par ces comportements, s’ils accompagnaient leurs parents à ces occasions.
La sécurité, l’affaire de tous
Dans notre échantillon, une très large proportion de collégiens (66 %) ont déclaré avoir pris des cours de natation en dehors de l’école. Si l’acquisition de telles compétences est hautement recommandable, elle ne doit pas être perçue comme une assurance.
Une étude menée aux États-Unis a en effet mis en évidence que la vigilance des parents avait tendance à baisser dès lors qu’ils estimaient que leurs enfants savaient nager. Or, il faut bien comprendre que, dans le milieu naturel, la natation n’a plus vraiment de point commun avec ce qu’on l’on apprend en piscine. Le vent, les courants, les vagues ou l’absence de repères changent radicalement la donne.
En outre, si la confiance que les enfants ont en leurs parents est parfaitement légitime, d’autres travaux menés en Australie ont montré qu’au moins un quart des adultes présents sur la plage avaient leur attention monopolisée par autre chose que la surveillance des enfants.
Autre point essentiel : sauver quelqu’un de la noyade ne s’improvise pas. Chaque année, de nombreuses personnes décèdent en tentant d’en secourir une autre.
Pour cette raison, il reste impératif de se baigner dans des zones surveillées par des professionnels du sauvetage, y compris lorsque l’on est à la plage avec ses parents. La mise en place de ces zones en des lieux où la fréquentation est avérée est une mesure de santé publique, car interdire de se baigner est souvent vain.
Enfin, notre étude montre également que la sensibilisation aux risques de baignade ne doit pas se cantonner aux espaces côtiers : elle doit se déployer sur l’ensemble du territoire national. Il est important que la communication touche toute la sphère familiale, y compris les adultes.
L’environnement aquatique est une source immense de bien-être et de bienfaits pour tous, y compris les plus jeunes. Il est primordial de fournir aux adolescents d’aujourd’hui les meilleures clefs de compréhension pour en profiter en toute sécurité, afin que demain, ils se comportent en adultes responsables.
Les auteurs remercient Jean-François Téchené, enseignant et nageur-sauveteur, pour son soutien lors de la mise en place et la diffusion de l’enquête.
Jeoffrey Dehez est membre du groupe de recherche sur la sécurité de la baignade de l'Université de Nouvelles Galles du Sud, en Australie (University of New South Wales Beach Safety Research Group). Il a reçu des financements de la région Nouvelle Aquitaine.
Bruno Castelle et Sandrine Lyser ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview