Pourquoi un modèle entraîné météorologique qui serait uniquement fondé sur des données passées pourrait avoir des difficultés à prévoir correctement la quantité de pluie de demain, dans le contexte du changement climatique.
Le temps est l’ennemi des statisticiens. Même à l’ère des systèmes d’IA, un modèle météorologique qui serait uniquement fondé sur des données passées et des principes statistiques peut avoir des difficultés à prévoir correctement les quantités de pluie futures, dans le contexte du changement climatique – tout simplement parce que la situation évolue.
Nous avons toutes et tous vu passer les images terribles des inondations espagnoles d’octobre 2024. Avec plus de 200 morts, cet évènement est passé directement au statut d’incident le plus meurtrier survenu en Espagne depuis les inondations de 1962.
D’aucuns pourraient s’étonner du manque de préparation alors que les méthodes d’intelligence artificielle (IA) se répandent. À titre d’exemple, le modèle européen ECMFW, utilisé par Météo France, a récemment intégré un modèle d’IA (nommé AIFS) pour améliorer ses performances.
Avec toutes les méthodes récentes en météorologie et en climatologie, liées au déploiement de l’IA, pourquoi les inondations de Valence n’ont-elles pas pu être anticipées ?
Les statistiques au service de la climatologie
Avant d’entrer dans le vif du sujet, je voudrais clarifier un point crucial : je ne suis pas climatologue et ne me revendique pas tel. Je ne vais donc pas m’étendre en détail sur des phénomènes météorologiques que je ne maîtrise pas assez.
Par contre, je connais bien l’étude des données temporelles. Et la question de la prédictibilité de ce phénomène météorologique va me permettre de vous expliquer un problème de statistiques sur lequel la recherche travaille toujours : la dérive des données (en anglais, data drift).
Tout d’abord, il faut formaliser un peu cet évènement climatique.
Premièrement, ce n’est pas un événement qui arrive tous les quatre matins. Ce genre d’occurrence reste statistiquement rare : on utilisera donc l’appellation « événement rare » ou « événement extrême ».
Deuxièmement, les inondations espagnoles de 2024 sont un événement rare parmi des événements rares. Explication : les habitants des Cévennes connaissent bien ces fortes pluies sous le nom d’« épisodes cévenols ». Ces épisodes cévenols font partie de ce que l’on appelle les épisodes méditerranéens. La « DANA » espagnole de 2024 est un exemple typique d’épisode méditerranéen : c’est exactement le même phénomène que les épisodes cévenols, et donc aussi « rare », mais non localisé aux Cévennes.
Finalement, parlons un peu de ce que nous appelons la « distribution des données ». La distribution des données, tout du moins dans ce cas-ci, c’est la probabilité qu’un évènement (un épisode pluvieux en ce qui nous concerne) arrive, qu’il soit d’une intensité donnée, qu’il ait une durée donnée, etc. Par exemple :
Si nous sommes le 15 septembre, il est beaucoup plus probable que, demain, il pleuve à Brest (Finistère) qu’à Nice (Alpes-Maritimes) : la probabilité de l’événement « pluie » à Brest est bien plus élevée que celle du même événement à Nice.
Si toutefois il pleut demain à Brest, il est fort peu probable que cette pluie soit d’intensité très élevée. En parallèle, s’il pleut demain à Nice, la possibilité que ce soit un épisode méditerranéen est plus élevée qu’à Brest. Il est donc plus probable d’avoir de fortes pluies à Nice, « sachant qu’il pleuvra demain », qu’à Brest.
Il est impossible de connaître parfaitement cette distribution, c’est-à-dire la probabilité qu’il pleuve une quantité donnée à tel endroit donnée à tel instant précis. Par contre, les scientifiques disposent d’un certain nombre d’outils permettant d’apprendre à prédire les évènements.
Un exemple de distribution des précipitations : il s’agit de la probabilité qu’il pleuve une quantité donnée lors d’un jour de pluie. Dans cet exemple, il y 5 % de chance qu’il pleuve 12 millimètres dans la journée et, s’il pleut 40 millimètres ou plus, on fait face à un événement extrême et rare.Rémi Vaucher, Fourni par l'auteur
Apprendre à prédire les évènements
Ces outils, ce sont majoritairement les statisticiens qui les inventent. Ils vont regarder les données passées et tenter d’en reproduire le comportement pour pouvoir prédire les données futures.
Par exemple, pour le sujet qui nous intéresse : les villes du pourtour méditerranéen ont besoin de pouvoir prédire les épisodes extrêmes et notamment la quantité d’eau (en millimètres) pour prévoir la mise en place de dispositifs exceptionnels (par exemple, des SMS alertant les habitants d’un risque de pluie ou d’inondation).
Pour cela, on va disposer de tous les relevés météorologiques (température, pression atmosphérique, vitesse du vent, orientation du vent, etc.) en plusieurs points géographiques autour de la zone concernée.
En apprenant à un algorithme à utiliser les données de la journée actuelle pour prédire la probabilité d’occurrence d’un épisode méditerranéen pour les deux ou trois jours à venir – et, si un épisode est envisagé, la quantité de précipitation prévue –, l’administration peut utiliser d’autres modèles (physique, statistique) pour prévoir les risques d’inondation dans telle ou telle zone de la localité.
Glissement de distribution et changement climatique
Malheureusement, avec le changement climatique, le climat change. Pour un statisticien, cette phrase signifie : « Un modèle entraîné sur le passé peut-il encore prévoir correctement la quantité de pluie de demain ? »
La figure ci-dessous nous montre mois par mois, depuis 2008, comment évolue le maximum de pluie dans une station météorologique proche de Valence (Espagne). Nous pouvons observer des valeurs maximales fluctuantes, mais dont les maximums restent sous 200 millimètres cumulés pendant deux jours.
Maintenant, admettons que nous entraînons un modèle à prédire les précipitations cumulées des deux prochains jours en utilisant ces données : nous lui donnons plein d’indicateurs au jour J, et nous souhaitons les précipitations cumulées des jours J+1 et J+2. Il est intuitif de penser que le modèle ne dépassera jamais la valeur de 200 millimètres, et cette intuition est réaliste : après tout, pourquoi le ferait-il ? Les modèles statistiques ne sont pas faits pour réfléchir à de nouvelles choses, ils sont faits pour reproduire un comportement appris, présent dans les données, qui aurait déjà pu (statistiquement) survenir dans le passé.
Analysons maintenant la suite des données.
Si nous avions utilisé notre modèle entraîné sur les données 2007-2023 pour prédire les précipitations des 16 et 17 octobre 2024, nous nous serions… certainement lamentablement plantés. Plus précisément, le modèle aurait sous-estimé la quantité de pluie (ce qui peut conduire des communes à avoir un faux sentiment de sécurité).
Ces dernières figures montrent bien que les inondations de Valence en 2024 étaient un évènement tellement extrême qu’il en devenait imprévisible. Pour mieux illustrer ce propos, la figure suivante montre, autour d’une ville où les épisodes cévenols sont plus fréquents, l’augmentation progressive de l’intensité de ces évènements. C’est ce que l’on appelle un « glissement de la distribution ».
Illustration du glissement de la distribution des précipitations (invisibles sur les données de Valence). On voit que, en 1960, les précipitations sont majoritairement entre 200 millimètres et 300 millimètres alors qu’elles se situent, en 2020, entre 250 millimètres et 400 millimètres.Rémi Vaucher, Fourni par l'auteur
Le temps : l’ennemi ancestral du statisticien
Ce phénomène de glissement dans le temps ne s’applique pas qu’en climatologie, mais il y est particulièrement crucial au vu des victimes causées ces dernières années. En santé, beaucoup de facteurs influencent les données. Sont susceptibles d’évoluer dans le temps par exemple : les sources de pollution, le nombre de personnes vaccinées, le nombre de fumeurs, etc. Dans le numérique, les systèmes de recommandations sur les plateformes de contenus doivent réussir à s’adapter aux phénomènes de mode.
Enfin, le glissement de distribution ne concerne pas que les évolutions temporelles. Par exemple, les résultats d’une étude neuroscientifique sur des étudiants aux États-Unis restent-ils valides lorsqu’on l’applique à des quadragénaires en Inde ?
En somme, l’évolution (temporelle) de certains facteurs, comme les populations ou le climat, représente de vrais défis pour les statisticiens. Pour ce qui est de la météorologie, il existe des systèmes dits « hybrides », c’est-à-dire qui combinent une compréhension de la physique du système et des statistiques sur les données passées. Cette hybridation améliore les performances de prévision, mais les modèles restent encore, pour l’instant, en difficulté sur les évènements climatiques extrêmes.
Rémi Vaucher ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
Données fragmentaires, arbitrages complexes, conflits d’usage : si les jumeaux numériques ne peuvent pas tout résoudre, ils offrent au moins une centralisation de l’information pour mieux gérer en temps réel et mieux planifier.
Texte intégral (2301 mots)
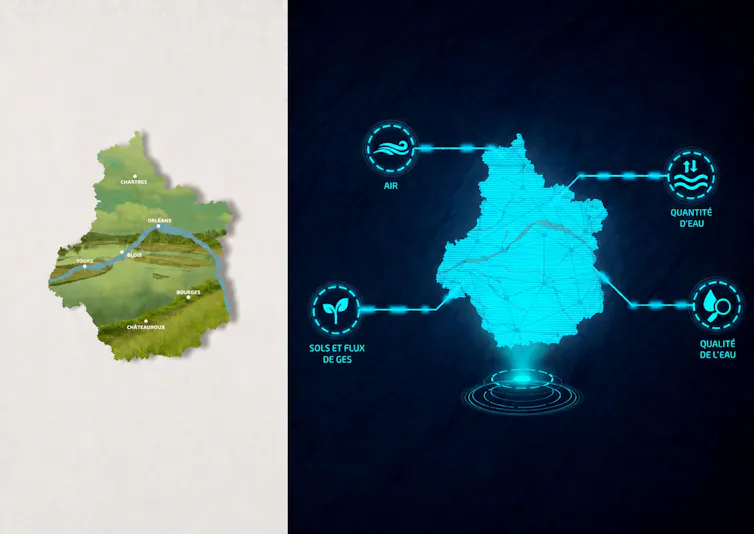
Les jumeaux numériques environnementaux permettent de mieux comprendre les ressources naturelles, un objectif au cœur du programme ARD JUNON, soutenu par la Région Centre-Val de Loire. Ces outils centralisent des données de terrain, des modèles et des analyses.Didier Depoorter/BRGM, Fourni par l'auteur
Faut-il adapter les pratiques agricoles face à des ressources en eau de plus en plus incertaines ? Peut-on renforcer la résilience des territoires face aux risques d’inondation ou de pollution de l’air ? Comment anticiper les effets d’aménagements sur les sols, l’eau ou la biodiversité ?
Les réponses à ces questions reposent aujourd’hui sur des données fragmentaires et des arbitrages complexes entre acteurs du territoire. Mais une nouvelle approche émerge : l’usage de jumeaux numériques environnementaux, qui permet de représenter numériquement et automatiquement la réalité physique sur de longues périodes. Déjà utilisés dans l’industrie pour les véhicules ou les machines, ces formes de modélisation sont désormais appliquées à de nombreux autres objets : bâtiments, villes, organes humains, processus de fabrication… Elles assurent leur suivi de façon intégrée et continue, tout au long de leur cycle de vie, avec une promesse : mieux comprendre pour mieux décider.
Dans l’environnement au sens large (urbain, agricole, naturel, industriel) et dans un contexte de changement climatique où la gestion des ressources naturelles et énergétiques est devenue critique, ces approches suscitent un intérêt croissant auprès des acteurs publics et industriels.
En France, par exemple, l’État a annoncé mi-avril 2026 un investissement de 25 millions d’euros dans le cadre du plan France 2030 pour développer des jumeaux numériques des territoires, destinés à mieux anticiper leurs évolutions et éclairer les décisions des collectivités. Mais leur déploiement soulève encore plusieurs défis, techniques comme sociaux.
Décider au quotidien et sur le long terme
Une fois déployés sur un territoire, les jumeaux numériques permettent d’adapter les flux et les pratiques en fonction de la disponibilité des ressources et des risques.
Le programme JUNON vise à fournir un jumeau numérique à la Région Centre-Val de Loire, qui permettra de concevoir des services numériques pour améliorer le suivi et la compréhension de l’environnement ainsi que la gestion des ressources naturelles.Néologis, Fourni par l'auteur
Mais leur intérêt ne se limite pas au suivi en temps réel. Les jumeaux numériques permettent aussi de tester différents scénarios et de planifier de futurs aménagements selon différentes problématiques. Les projets d’urbanisation, de paysagisme et de restauration environnementale peuvent ainsi se décliner afin d’estimer leurs impacts respectifs et de rationaliser les choix des collectivités.
Il devient par exemple possible de comparer l’impact de la création d’un bois ou d’une zone agricole, à l’aménagement d’une rive, à la création d’un parking, d’une autoroute ou bien d’un parc photovoltaïque. Quels seront leurs impacts respectifs par rapport aux émissions de CO₂, aux dépenses énergétiques, à la disponibilité de la ressource eau et à la qualité de l’air ? Ces impacts varient-ils selon les localisations ? Actuellement, plusieurs villes européennes et dans le monde construisent déjà leur plan d’urbanisme en fonction de ces paramètres grâce aux jumeaux numériques.
En objectivant ces effets, les jumeaux numériques contribuent à éclairer les décisions. Ils peuvent aider à apaiser des débats souvent sensibles entre acteurs du territoire, afin d’améliorer le dialogue social et le partage des ressources et des espaces communs. Mais si cette capacité à mieux comprendre et anticiper suscite un fort intérêt, elle se heurte encore à plusieurs obstacles.
Des outils encore difficiles à s’approprier
Le développement des jumeaux numériques repose en grande partie sur les progrès récents de l’intelligence artificielle (IA). Les techniques de machine learning permettent désormais de suivre et d’analyser en continu de grandes quantités de données et d’en tirer des capacités de prédiction inédites.
Cependant, pour de nombreux acteurs (personnels techniques, élus ou grand public), cette impulsion technologique constitue une rupture qui reste difficile à appréhender, tant dans sa mise en œuvre que dans l’interprétation des résultats. Peut-on se fier à un modèle pour orienter des décisions concrètes ? Comment comprendre les hypothèses et les calculs derrière les simulations ? L’enjeu ne se limite pas à un simple rejet : un manque de compréhension partagée peut conduire à des visions divergentes entre acteurs, et fragiliser des projets de jumeaux souvent longs et coûteux.
Dans ce contexte, l’accompagnement est essentiel. Retours d’expérience sur d’autres jumeaux numériques territoriaux, formations et démarches de médiation facilitent l’appropriation progressive de ces outils.
Gourmands en données
Les jumeaux numériques dépendent des données auxquelles ils ont accès. Pour représenter et suivre en temps réel des environnements complexes et étendus, ils ont besoin de volumes d’informations très importants et de dispositifs de mesure souvent onéreux. C’est le cas par exemple de certaines sondes de mesure sur la qualité des eaux, à la fois coûteuses à l’achat et à l’entretien, qui doit être régulier.
Certaines variables sont difficiles à mesurer de façon automatique, comme la biodiversité qui repose encore largement sur des observations de terrain. La fréquence et l’étendue des mesures sont limitées car elles doivent être réalisées par des spécialistes pour faire le décompte long et laborieux des différentes espèces présentes. De même, certains polluants émergents, comme les PFAS ou certains pesticides, ne sont toujours pas mesurables en dehors des laboratoires.
D’autres proxys reposent sur des observations indirectes dans le temps. L’analyse d’images satellitaires permet ainsi d’identifier les périodes de développement des cultures (levées végétales), et donc de déduire la nature des semis. Cette information est essentielle pour estimer les besoins en eau, anticiper les périodes d’irrigation ou évaluer les pressions exercées sur la ressource.
Bien que ces technologies soient encore en développement à l’échelle des territoires, de nombreux projets émergent déjà, portés par des acteurs variés : collectivités, agences publiques, entreprises, bureaux d’études…
Or, ces initiatives sont souvent développées de manière indépendante. Il n’est pas rare que plusieurs jumeaux numériques mobilisent des flux de données similaires ou proposent des fonctionnalités proches, sans véritable mutualisation. Par exemple, un jumeau numérique régional simulant une crue centennale du Danube ne peut pas anticiper correctement les risques s’il est isolé : il nécessite les données du jumeau climatique global (précipitations en amont, fonte des neiges alpines) pour produire des simulations fiables. Sans cette interconnexion, les systèmes d’alerte des villes seraient basés sur des scénarios incomplets, sous-estimant potentiellement les risques. Le silotage des jumeaux territoriaux peut entraîner des redondances, des coûts supplémentaires et un usage moins efficient des ressources. Pour aller vers plus de frugalité, des initiatives telles que les projets LDT4SSC (Local Digital Twins for Smart and Sustainable Communities) visent à créer une fédération européenne de jumeaux numériques locaux interconnectés. L’un des enjeux majeurs consiste donc à rendre ces systèmes interopérables, c’est-à-dire capables de communiquer entre eux et de partager des données et des résultats.
Cette interopérabilité s’exerce à deux niveaux. D’une part, celui des données utilisées et générées : celles-ci doivent être accessibles, compréhensibles et réutilisables par différents acteurs. L’utilisation de principes comme les standards FAIR (Findable, Accessible, Interoperable, Reusable) permet de faciliter leur partage.
D’autre part, celui des méthodes et des outils. Aujourd’hui, les solutions sont encore largement hétérogènes. Le développement de standards communs (définir par exemple des procédures de communication ou protocoles d’échange, des architectures et des formats) qui permettraient de faciliter leur articulation et leur évolution est au cœur de nombreuses études. Une standardisation des jumeaux numériques pourrait rendre ces structures plus compatibles.
Les jumeaux numériques apparaissent désormais comme des outils de plus en plus omniprésents dans la gestion de nos territoires. Ils sont porteurs de solutions innovantes, mais supposent de nombreux défis qui devront être abordés collectivement.
Sébastien Dupraz a reçu des financements de la Région Centre-Val de Loire, de l'Etat Français et de l'Europe dans le cadre de ses activités liées aux Jumeaux Numériques Environnementaux.
Dominik Koll, Honorary Lecturer, Nuclear Physics, Australian National University
En analysant de la poussière d’étoiles piégée dans la glace de l’Antarctique, des chercheurs ont mis au jour un indice inédit sur le déplacement du Système solaire à travers la galaxie. Une découverte qui pourrait éclairer l’origine de mystérieux nuages interstellaires.
Texte intégral (1812 mots)
L'Antarctique offre un terrain d'observation précieux où la neige s’accumule lentement et reste en grande partie préservée des perturbations.Derek Oyen/Unsplash, CC BY
Des atomes de fer 60, produits lors d’explosions stellaires, permettent de remonter le fil de l’histoire de notre environnement galactique. Leur présence dans la glace antarctique révèle une variation inattendue de la poussière interstellaire atteignant la Terre.
Quand vous pensez à l’espace, vous imaginez sans doute des étoiles, des planètes et des satellites. Pourtant, une grande partie de l’espace est remplie de nuages de gaz, de plasma et de poussières d’étoiles, appelés nuages interstellaires.
Rien que dans les régions proches de notre galaxie, on recense environ 15 nuages interstellaires distincts. Le Système solaire traverse actuellement l’un d’entre eux, baptisé de façon évocatrice le Nuage interstellaire local. On pense que l’origine et l’histoire de ces nuages sont étroitement liées à la naissance et à la mort des étoiles. Mais leurs traces sont également visibles ici même sur Terre, dans un endroit où l’on ne s’attendrait pas forcément à les trouver : la glace de l’Antarctique.
Mes collègues et moi étudions depuis plusieurs années la poussière d’étoiles piégée dans d’anciennes couches de neige et de glace antarctiques afin de retracer l’histoire de notre voisinage cosmique, y compris celle du Système solaire lui-même.
Dans une nouvelle étude publiée dans Physical Review Letters (https://doi.org/10.1103/nxjq-jwgp), nous avons mis en évidence un indice subtil qui révèle le déplacement de notre Système solaire à travers son environnement interstellaire local au cours des 80 000 dernières années.
Regarder le ciel en regardant vers le bas
L’astronomie consiste généralement à lever les yeux au ciel. Les télescopes collectent la lumière provenant d’étoiles et de galaxies lointaines, ce qui nous permet d’observer des événements sur d’immenses distances dans l’espace et le temps. À partir de ces observations, nous déduisons comment les étoiles naissent et meurent, comment les éléments chimiques se forment et comment l’Univers évolue.
Au lieu d’étudier la lumière qui nous parvient, nous examinons les débris d’étoiles ayant explosé, directement ici sur Terre. Véritables fournaises cosmiques, les étoiles fabriquent dans leur cœur de nombreux éléments chimiques, du carbone et de l’oxygène jusqu’au calcium et au fer. Elles produisent également des isotopes rares (des variantes d’un même élément chimique), comme le fer 60.
Lorsque des étoiles massives explosent en supernovæ à la fin de leur existence, ces éléments sont projetés dans l’espace et deviennent de la poussière interstellaire.
De minuscules grains de cette poussière dérivent ensuite à travers la galaxie et finissent parfois par atteindre la surface de la Terre. Du fer 60 radioactif, véritable signature des explosions stellaires, est piégé à l’intérieur de ces grains. En recherchant ces atomes dans les archives géologiques terrestres (https://doi.org/10.1140/epja/s10050-025-01554-0), nous pouvons étudier des événements astrophysiques tels que les supernovæ, longtemps après que leur lumière s’est éteinte.
C’est ce qui rend l’Antarctique si précieux. Sa neige s’accumule lentement et reste en grande partie préservée des perturbations, formant une sorte d'enregistrement stratifié qui remonte sur des dizaines de milliers d’années. Chaque couche conserve une photographie du matériau présent dans notre voisinage cosmique à l’époque où elle s’est formée.
À la recherche de poussière d’étoiles dans la glace antarctique
Alors que nous étudions 500 kg de neige récente en Antarctique, nous avons découvert de manière inattendue cet isotope radioactif rare. D’où provenait-il ? Aucune supernova proche de la Terre ne s’était produite récemment.
Mais notre voisinage cosmique est rempli de 15 nuages interstellaires, et le Système solaire en traverse actuellement au moins un. La poussière d’étoiles serait-elle présente dans ces nuages avant d’être captée par la Terre ? Si c’est le cas, alors la quantité de poussière d’étoiles recueillie par notre planète devrait être liée à leur structure : plus ces nuages sont denses, plus ils contiennent de fer 60. C’était notre hypothèse en 2019 (https://doi.org/10.1103/PhysRevLett.123.072701).
Très vite, d’autres explications ont été avancées. Il y a plusieurs millions d’années, la Terre a reçu d’importantes pluies de fer 60 provenant de supernovæ massives (https://doi.org/10.1038/nature17196). Le fer 60 retrouvé dans la neige antarctique serait-il le dernier vestige, ou l’écho affaibli, de ce signal ancien ? Une pluie devenue simple bruine ?
Pour le vérifier, nous avons analysé une section de 300 kg de glace antarctique datant de 40 000 à 80 000 ans. Le processus est extrêmement minutieux. La glace doit être fondue puis traitée chimiquement afin d’isoler d’infimes quantités de fer, y compris le fer 60 contenu dans la poussière d’étoiles.
Nous avons ensuite utilisé la spectrométrie de masse par accélérateur, une technique extrêmement sensible permettant de compter les atomes individuellement, au sein du Heavy-Ion Accelerator Facility de l’Australian National University. Nos analyses ont consisté à dénombrer un à un les atomes de fer 60. Sur la base des mesures précédemment réalisées dans la neige de surface antarctique et dans des sédiments océaniques vieux de plusieurs milliers d’années, nous nous attendions à observer un niveau relativement stable de dépôt de fer 60.
Or, nous en avons trouvé moins. Pas zéro, mais une quantité nettement inférieure à celle que nous attendions.
Ce résultat suggère qu’une moindre quantité de poussière interstellaire atteignait la Terre à cette époque. Cette variation est remarquable, car elle s’est produite sur une période relativement courte à l’échelle de l’astrophysique. Elle ne correspond pas au scénario des dépôts de fer 60 issus des supernovæ qui ont atteint la Terre il y a plusieurs millions d’années, un phénomène qui s’inscrit, lui, sur des durées bien plus longues. Nous avons donc dû chercher une source plus modeste et plus locale pour expliquer la présence de cet isotope.
Le complexe moléculaire d’Orion est l’un des grands nuages interstellaires de notre galaxie.NASA/JPL-Caltech
Une histoire qui tombe à point nommé
Naturellement, les astronomes s’intéressent aussi de près aux nuages qui entourent le Système solaire. L’an dernier, une étude reconstituant l’histoire de ces nuages a conclu qu’ils provenaient très probablement d’une explosion stellaire (https://iopscience.iop.org/article/10.3847/1538-4357/adc920). Les chercheurs ont également estimé que le Système solaire traverse le Nuage interstellaire local depuis une période comprise entre 40 000 et 124 000 ans (https://iopscience.iop.org/article/10.3847/1538-4357/adb033).
Si cette hypothèse est correcte, alors la quantité de fer 60 recueillie sur Terre aurait dû varier au cours de cette même période, c’est-à-dire entre 40 000 et 124 000 ans avant aujourd’hui.
C’est ce que montrent nos résultats obtenus en Antarctique.
L’histoire ne s’emboîte toutefois pas parfaitement. Si ces nuages provenaient directement d’une étoile ayant explosé, nous devrions observer dans la glace antarctique des quantités de fer 60 bien plus importantes que celles que nous mesurons réellement.
Malgré cela, la trace de ces nuages est bien inscrite dans les archives géologiques terrestres. En remontant plus loin dans le temps et en analysant des glaces encore plus anciennes, nous pourrions bientôt percer le mystère de ces nuages interstellaires locaux et reconstituer plus complètement leur histoire ainsi que leurs origines encore incertaines.
Dominik Koll a reçu des financements de l'Australian Institute of Nuclear Science and Engineering (AINSE).