
29.06.2026 à 16:03
Sahel : pourquoi les massacres de civils par les forces officielles sont en recul
Marc-Antoine Pérouse de Montclos, directeur de recherches, Institut de recherche pour le développement (IRD)
Texte intégral (2074 mots)
Dans les trois pays de l’Alliance des États du Sahel (Mali, Niger, Burkina Faso) et au Nigeria voisin, les armées sont depuis longtemps en butte à des rébellions djihadistes – rébellions qu’elles alimentent régulièrement en massacrant des civils soupçonnés de déloyauté, ou simplement en commettant des « bavures » sanglantes. Ces derniers temps, toutefois, on semble constater une légère amélioration en la matière : apparemment, les armées tuent moins de civils qu’auparavant. Il convient toutefois de bien comprendre que les chiffres dont on dispose ne sont que des estimations et, surtout, que cette amélioration s’explique par le fait que les populations ont souvent fui les zones des combats…
On sait depuis longtemps que les massacres de civils sont contreproductifs pour les stratégies de guerre contre-insurrectionnelle qui visent à isoler les éléments rebelles en gagnant les esprits et les cœurs de la population.
Au Sahel, l’une des raisons de la résilience des groupes djihadistes tient justement aux nombreuses violations des droits de l’homme commises par les forces de défense et de sécurité. Ces brutalités n’ont pas seulement poussé des jeunes à chercher refuge dans les bras des insurgés pour échapper à l’arrestation arbitraire, à l’exécution extra-judiciaire ou à la torture en prison. En pratique, elles ont aussi légitimé le discours de djihadistes se présentant comme les défenseurs de la communauté des musulmans face à des pouvoirs impies et prédateurs.
Des abus multiples
Du Burkina Faso au Nigeria en passant par le Mali et le Niger, on ne compte plus les massacres perpétrés par des militaires, leurs supplétifs miliciens et, dans certains cas, leurs partenaires russes. Un rapport de Human Rights Watch, rendu public le 2 avril dernier, a ainsi montré que, entre janvier 2023 et août 2025, les troupes de Ouagadougou et de Bamako avaient tué trois à quatre fois plus de civils que les groupes djihadistes qu’elles étaient censées combattre : sur cette période, 1 800 personnes ont été tuées au total, dont 1 200 par les forces gouvernementales.
Ce n’est pas nouveau : en 2023, le Sénat français avait fini par reconnaître que, sur les années 2020-2021, du temps où les soldats de l’opération Barkhane (2014-2022) étaient encore déployés sur le terrain, les militaires et miliciens maliens, burkinabè et nigériens avaient éliminé autant de civils que les djihadistes.
Au Nigeria, des bases de données ont également révélé que les forces gouvernementales étaient à l’origine de la mort de plus de 55 % des victimes des affrontements recensés avec Boko Haram entre 2007 et 2019.
Il est évidemment difficile de tenir un décompte précis des hostilités. Mais la tendance générale est confirmée par les témoignages recueillis sur place. À Bama, dans le nord-est du Nigeria, un paysan se plaignait par exemple des exactions de la mouvance Boko Haram tout comme de celles de l’armée. « Mais les soldats sont pires », concluait-il après la mort de deux de ses enfants abattus par des militaires alors qu’ils étaient partis travailler aux champs. Un réfugié de Baga Kawa, un petit port de pêche du côté nigérian du lac Tchad, estimait de son côté que « la plus grande menace pour les populations, c’est l’armée, car c’est elle qui nous tue ».
Les abus contre des civils prennent diverses formes, de l’exécution extra-judiciaire au viol en passant par l’extorsion, les mauvais traitements ou la détention illégale. Au Nigeria, c’est aujourd’hui l’armée de l’air qui est à la manœuvre en bombardant des marchés et des villages entiers. Officiellement, l’objectif est de s’en prendre à des camps de Boko Haram. Chaque fois, la hiérarchie parle d’erreurs qui, en l’occurrence, tuent des dizaines de paysans ayant eu pour tort de se trouver au mauvais endroit au mauvais moment.
Au Burkina Faso, ces bavures sont plutôt le fait des escortes qui tirent à vue sur tout ce qui bouge lorsqu’elles encadrent les convois chargés de ravitailler les villes de province assiégées par des djihadistes. À l’occasion, les bataillons d’intervention rapide, créés fin 2022 par le capitaine Ibrahim Traoré quelques mois après son arrivée au pouvoir à l’issue d’un putsch militaire, opèrent aussi des raids meurtriers dans les campagnes, sans même prévenir les troupes régulières stationnées à proximité.
Le rôle des milices
Assurément, l’arrivée au pouvoir de juntes militaires et la « milicianisation » de la réponse à la menace djihadiste ont beaucoup joué contre le respect des droits de l’homme en temps de guerre. Dans la région, les autorités ont en effet cherché à pallier le manque d’effectifs de leurs troupes en confiant à des supplétifs le soin d’assumer les tâches les plus sales de la lutte contre le terrorisme. Selon le rapport précité de Human Rights Watch à propos du Burkina Faso, les pires abus ont ainsi été enregistrés quand l’armée est intervenue aux côtés des miliciens koglweogo, les VDP (Volontaires pour la défense de la patrie).
Le Niger pourrait à présent connaître le même sort : la junte y a formalisé en mars 2026 des organisations territoriales d’autodéfense appelées à être équipées en armes pour repérer, dénoncer et arrêter les suspects. En pratique, ces milices peuvent tuer des civils en toute impunité car elles rendent peu de comptes à des militaires qui bénéficient eux-mêmes de l’immunité du secret-défense.
Ces dernières années, cependant, les forces gouvernementales de pays comme le Burkina Faso (depuis 2025) ou le Nigeria (depuis 2020) semblent moins directement impliquées dans des massacres à grande échelle. Faut-il y voir une professionnalisation des pratiques militaires ? Se pourrait-il donc que les officiers nigérians et burkinabè soient davantage conscients des effets pervers de ces tueries qui légitiment et renforcent les groupes djihadistes ?
Des militaires et des djihadistes plus « aimables » ?
L’hypothèse selon laquelle les militaires auraient amélioré leur comportement est évidemment avancée par les premiers intéressés. Elle est également favorisée par certains coopérants occidentaux qui, au Nigeria, veulent continuer de croire aux mérites de formations censées apprendre le respect des droits de l’homme aux soldats africains. Dans le cas de la France, par exemple, une telle perspective correspond bien à la volonté de faire oublier les échecs de l’opération Barkhane au Sahel en se repositionnant vers les pays du golfe de Guinée et en renouant le dialogue avec le Tchad, dont le président Mahamat Idriss Déby a officiellement été reçu à l’Élysée en janvier 2026.
D’ordre tactique et non humanitaire, le souci d’épargner des vies humaines pourrait aussi répondre à l’évolution de certains groupes djihadistes, qui ont dû apprendre à composer avec la population à mesure qu’ils s’enracinaient dans les campagnes. Au Nigeria, la branche ralliée à l’organisation État islamique, ISWAP (Islamic State West Africa Province), a ainsi la réputation d’être plus respectueuse des civils que les autres factions de la mouvance Boko Haram.
Au Burkina Faso, le JNIM (Jamāʿat nuṣrat al-islām wal-muslimīn) d’Iyad ag-Ghali et la Katiba Macina d’Amadou Kouffa ont également adouci leur position. Depuis 2021, ils ne communiquent plus de vidéos d’exécutions de femmes adultères. En 2025, l’adjoint d’Amadou Kouffa, Mahmoud Barry, dit « Abou Yehiya », a pour sa part commencé à diffuser des prêches invitant ses combattants à éviter les bavures et à épargner les civils. L’objectif est, tout à la fois, d’obtenir le soutien de la population et de recruter des jeunes en les conviant à participer à la protection de leurs communautés contre les exactions des forces burkinabè et des katibas rivales de l’État islamique au Sahel.
De l’invisibilisation des massacres
Plusieurs éléments invitent cependant à relativiser l’éventualité d’une « humanisation » des belligérants de la zone. Tout d’abord, il semble peu probable que les armées de la région aient pu soudainement améliorer leur comportement quand on connaît leurs fragilités structurelles, la faiblesse de leurs chaînes de commandement, la récurrence de leurs mutineries, leur indiscipline notoire, la rapidité de leurs recrutements, la réduction des temps de formation et le temps long que requiert un véritable reformatage des appareils sécuritaires.
L’hypothèse d’un adoucissement des stratégies de répression ne correspond pas non plus au durcissement des juntes au pouvoir dans les trois pays qui composent l’Alliance des États du Sahel, à savoir le Burkina Faso, le Mali et le Niger, qui se sont tous retirés de la Cour pénale internationale.
En réalité, les abus sont moins visibles parce que les médias ont été verrouillés par les dictatures en place. Les journalistes occidentaux comme africains n’ont quasiment plus accès aux zones de conflit, ou bien doivent être « embarqués » dans des unités militaires, comme au Nigeria. La tendance est d’autant plus marquée que les forces gouvernementales ont elles-mêmes perdu du terrain. Dans la région nigériane du Borno, par exemple, l’armée s’est retranchée à l’intérieur de grosses casernes, les supercamps, qui laissent le champ libre aux insurgés dans les campagnes. Dans le nord et l’est du Burkina Faso, les soldats se sont repliés dans les villes et sont avérés incapables de protéger les VDP actifs dans les campagnes, qui ont commencé à déserter et qui sont en conséquence moins à même de commettre des atrocités contre les villageois suspectés de sympathies djihadistes.
La politique de la terre brûlée, à cet égard, explique pour beaucoup la réduction des massacres. Dans les zones de conflit, les populations rurales ont, en effet, été évacuées manu militari vers des camps de déplacés, ou bien sont parties d’elles-mêmes vers les villes. Dans les campagnes, il y a tout simplement moins de gens à tuer pour les belligérants. Mais une telle situation ne laisse guère présager une sortie de crise.
Marc-Antoine Pérouse de Montclos ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 16:02
Loi de finances 2026 : quels risques autour des prévisions de dette publique ?
Fabien Tripier, Professeur d'économie, Université Paris Dauphine – PSL
François Langot, Professeur d'économie, Directeur adjoint de l'i-MIP (PSE-CEPREMAP), Le Mans Université
Jean-Olivier Hairault, Professeur d'économie et Directeur Scientifique de l'Observatoire Macro du Cepremap, Paris School of Economics – École d'économie de Paris
Jocelyn Maillard, Economiste à l’Observatoire de Macroéconomie, Cepremap
Texte intégral (2508 mots)
Le programme d’ajustement budgétaire pour 2026 repose sur des hypothèses économiques fortes. Que se passera-t-il si la réalité s’en écarte défavorablement ? L’objectif étant de réduire la dette, que risque-t-il alors de se passer ? La question est d’autant plus importante que la discussion parlementaire sur le budget 2027, qui commencera en septembre, sera sans doute d’autant plus difficile que l’élection présidentielle approche.
La loi de finances pour 2026 présente un programme d’ajustement budgétaire pour stabiliser la dette à 118 % du PIB en 2029. Un quart de cet ajustement repose sur un scénario conjoncturel plutôt favorable. S’il ne se réalisait pas, il y aurait plus d’une chance sur deux que la dette publique ne soit pas stabilisée, même si le programme était appliqué.
À l’inverse, si ce programme n’était pas mis en place alors que le scénario conjoncturel favorable se réalisait, la dette publique augmenterait de plus de 11 points de PIB en quatre années, soulignant ainsi le risque de dérive de la dette en cas de statu quo budgétaire.
À lire aussi : Et si la dette publique servait d’abord à rendre les citoyens plus heureux ?
Une procédure de déficit excessif
La trajectoire de la dette publique française est au cœur du débat budgétaire depuis plusieurs décennies. Le ratio dette/PIB a augmenté régulièrement sous l’impulsion d’un déficit budgétaire persistant qui ne se résorbe pas spontanément en période de croissance (voir la figure ci-dessous). En outre, la remontée des taux d’intérêt depuis 2022 a renchéri le coût de l’endettement public, alourdissant la charge de la dette. Cette situation a conduit la France à être sous procédure de déficit excessif. Cela l’engage vis-à-vis de ses partenaires européens à présenter une trajectoire crédible de réduction de sa dette publique.

Dans ce contexte budgétaire, la loi de finances pour 2026 présente un nouveau programme d’ajustement, avec pour objectif de stabiliser la dette à 118 % du PIB en 2029. La note de l’i-MIP 2026-12 (« Loi de finances 2026 : quels risques autour des prévisions de dette publique ? ») présente une évaluation des risques autour de cette prévision. Annoncer un niveau de dette publique ne suffit pas, mieux vaut connaître la probabilité de dépasser cette cible, ou encore identifier le niveau de la dette qui ne sera pas dépassée avec une certaine probabilité. Cette approche probabiliste répond à une demande d’informations sur les risques de dérapages budgétaires, aujourd’hui manquantes dans le débat public.
Comment évaluer le risque ?
La nouvelle loi de finances repose sur deux piliers :
d’une part, la trajectoire budgétaire annoncée par le gouvernement sur la période 2026-2029,
d’autre part, une prévision de conjoncture macroéconomique avec laquelle ce programme budgétaire interagira.
Évaluer ce programme consiste donc à identifier séparément le scénario conjoncturel et le scénario budgétaire qui lui sont sous-jacents. Comme la réalisation simultanée de ces deux scénarios n’est pas certaine, la prévision du gouvernement est risquée. Pour quantifier ce risque, nous comparons les prévisions du gouvernement, conditionnées par la réalisation des scénarios budgétaire et conjoncturel particuliers qu’il propose, à celles qui résulteraient de scénarios tirés au sort dans les distributions historiques des chocs conjoncturels et budgétaires estimées sur les données observées sur la période 2003–2025.
Cet exercice permet de révéler où se situent dans les distributions des probabilités historiques les scénarios du gouvernement, et ainsi le risque associé à son programme de stabilisation de la dette. Cette évaluation des risques considère que la distribution des scénarios conjoncturels passés est la référence pertinente parce que les estimations de ces scénarios ne sont pas affectées par le programme budgétaire grâce à l’utilisation de notre modélisation structurelle.
Un risque conjoncturel
Avant d’évaluer ces risques, il est utile de décomposer les sources de réduction de la dette dans le scénario du gouvernement. Cette décomposition permet d’isoler ce qui relève de la politique budgétaire et ce qui relève du contexte conjoncturel. Sur une réduction totale de 192 milliards d’euros de dette publique entre 2025 et 2029, nous estimons que 142 milliards – soit 74 % – sont attribuables au scénario budgétaire, c’est-à-dire à la consolidation annoncée dans le projet de loi de finances (PLF) 2026. Les 49 milliards restants – soit 26 % – proviennent du scénario conjoncturel tel que projeté par le scénario du gouvernement.
Comme près d’un quart de la baisse de la dette repose sur le scénario conjoncturel envisagé, il est important d’évaluer où se situe ce scénario dans la distribution des réalisations historiques, c’est-à-dire mesurer le risque conjoncturel.
Une prévision probablement dépassée ?
Ce risque est mesuré par la probabilité que la cible de dette soit dépassée si le scénario conjoncturel retenu par le gouvernement est remplacé par la conjoncture « médiane » de ce qui a été observé dans le passé, alors que le programme budgétaire est intégralement mis en œuvre (l’incertitude venant donc uniquement de la conjoncture). Cette mesure du risque conjoncturel répond à la question : que devient la dette si le budget est appliqué, mais que l’environnement macroéconomique n’est pas celui retenu dans la prévision gouvernementale ?
Le tableau 1 donne la réponse à cette question. En 2029, la médiane de la distribution simulée s’établit à 119,5 % du PIB, soit 1,5 point au-dessus de la cible officielle de 118 %. Cela signifie que la prévision du gouvernement se situe en dessous de la médiane des scénarios basés sur une conjoncture à l’image de l’historique : il y a 55 % de chances que la dette dépasse 118 % du PIB, même si le programme budgétaire est pleinement appliqué. La probabilité de dépasser 125 % est de 30 % et celle de dépasser 126,2 % est de 25 %.

L’autre risque
Symétriquement, le risque budgétaire mesure la probabilité que la cible de dette soit dépassée si le scénario budgétaire du gouvernement n’est pas exécuté, alors que son scénario conjoncturel se réalise. Ce risque semble, à première vue, davantage sous le contrôle du gouvernement, puisque l’implémentation de sa politique dépend a priori de sa volonté. Mais ce serait une lecture trop optimiste, voire naïve.
L’expérience passée montre que les plans d’ajustement budgétaire sont très rarement mis en œuvre comme prévu. Ainsi, la figure 1 montre qu’il existe un décalage systématique entre les politiques annoncées et celles effectivement implémentées. Le risque budgétaire ne doit donc pas être interprété comme une hypothèse extrême ou secondaire, mais comme un risque central d’exécution de la trajectoire annoncée.
Que deviendrait la dette si la conjoncture prévue se réalise, mais que le budget annoncé n’est pas mis en œuvre ? Le tableau 2 donne la réponse à cette question. En 2029, la médiane de la distribution atteint 129,5 % du PIB, soit 11,5 points au-dessus de la cible. La probabilité de dépasser 118 % est de 99 % et celle de dépasser 125 % est de 89 %. Cette situation correspond à un statu quo budgétaire complet : le gouvernement et le parlement ne modifient pas leurs comportements par rapport à ceux observés dans le passé.
Un programme trop peu ambitieux ?
Elle constitue donc une borne haute du risque budgétaire, qui mesure à quel point la trajectoire de dette dépend de la réalisation effective du programme de consolidation budgétaire. Sans elle, la dette serait orientée structurellement à la hausse, avec un accroissement de 3,5 points en moyenne par an (de 115,6 % en 2025 à 129,5 % en 2029).

Ces résultats soulignent, une fois de plus, l’importance d’implémenter le programme budgétaire annoncé. Ils indiquent également que, même avec ces restrictions budgétaires, la probabilité de stabiliser la dette à 118 % du PIB en 2029 est d’un peu moins d’une chance sur deux. Jouer à pile ou face sur la stabilisation de la dette dans un contexte de finances publiques dégradées et d’environnement international incertain est un pari risqué qui soulève deux questions.
La première est celle de l’intensité de la consolidation. Un objectif plus ambitieux de réduction du déficit permettrait, à risque conjoncturel donné, de réduire le niveau de dette médian et reviendrait alors à se fixer l’objectif que 70 % des simulations permettraient d’être en dessous de 118 %. La seconde est celle de la mise en place de règles budgétaires pluriannuelles prévoyant des ajustements automatiques des dépenses et/ou des recettes tant que la dette publique reste au-dessus d’une certaine cible.
Ces deux orientations ne sont pas exclusives. Elles invitent à ouvrir un débat plus large sur la crédibilité et la robustesse de la stratégie budgétaire française, qui dépasse le seul horizon de la loi de finances 2026.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 16:00
Maximiser les bénéfices ou minimiser le gaspillage ? Le vrai casse-tête de vos commerçants pendant les soldes
Arvind Sainathan, Associate Professor of Operations Management, Neoma Business School
Fang Liu, Professor of Operations Management, Durham University
Texte intégral (1642 mots)
Casser les prix ou jeter des produits invendus ? Tel est le dilemme des commerçants tandis que débutent les soldes d’été. Pour inciter à consommer davantage, les vendeurs mobilisent différents types de promotion. Notre étude se penche sur ces mécanismes commerciaux et offre des pistes pour réconcilier recherche de rentabilité et durabilité.
Des soldes d’été aux offres exceptionnelles du Black Friday, les promotions sont devenues incontournables dans le paysage commercial. Les consommateurs considèrent souvent qu’une remise n’est qu’une remise, qu’il s’agisse d’une baisse de prix ou d’offres de produits gratuits, telles qu’« un acheté, un offert » (une pratique aussi appelée BOGOF pour « Buy One Get One Free »).
Pourtant, de nouvelles recherches suggèrent que les promotions peuvent remplir des objectifs différents, avec des conséquences importantes non seulement pour les acheteurs, mais aussi pour les vendeurs confrontés à une augmentation des déchets et à une compression des marges.
Notre étude récente propose une approche plus claire pour appréhender les promotions dans le commerce de détail. Nous expliquons pourquoi les baisses de prix et les offres fondées sur la quantité peuvent générer des résultats étonnamment différents en distinguant deux objectifs chez les enseignes : la maximisation des bénéfices et la minimisation du gaspillage.
Ces travaux font écho à des préoccupations plus larges concernant la surproduction dans le secteur de la mode, le gaspillage alimentaire et l’empreinte environnementale des chaînes d’approvisionnement du commerce de détail au niveau mondial.
À lire aussi : Le bonheur s’achète-t-il en solde ?
Psychologie de l’achat devant les promotions
De nombreux consommateurs estiment qu’une remise de 50 % et une offre BOGOF reviennent pratiquement au même. Certes, les deux réduisent le prix unitaire effectif. Cependant, les recherches montrent que chaque méthode de promotion a un impact distinct sur les choix des acheteurs.
Une remise sur le prix réduit le coût de chaque unité. À l’inverse, une promotion de type BxGy, « achetez x, obtenez y gratuit », introduit un seuil, les consommateurs doivent acheter une quantité minimale pour obtenir la récompense. Ce seuil modifie la psychologie de l’achat, car la valeur que les consommateurs attribuent à un article diminue à chaque unité supplémentaire qu’ils achètent, selon le principe de l’utilité marginale décroissante.
Des consommateurs tentés d’acheter plus
Derrière ces promotions, deux mécanismes sont à l’œuvre. Lorsque les stocks sont élevés, les offres telles que « un acheté, un offert » exploitent un effet de regroupement pour encourager les consommateurs à acheter en plus grande quantité.
Cela concorde avec des études antérieures qui montrent comment les détaillants utilisent des incitations comportementales pour augmenter les dépenses des consommateurs, en particulier dans des contextes hautement concurrentiels comme les soldes de fin d’année.
L’effet de différenciation, quant à lui, apparaît lorsque les consommateurs accordent une valeur différente aux unités supplémentaires, comme c’est le cas pour la mode, les accessoires et les cadeaux. Dans le cas de promotions fondées sur des seuils, cet effet permet aux détaillants d’attirer à la fois des acheteurs ayant une forte disposition à payer et des chasseurs de bonnes affaires. Cette tendance fait écho à des études sur la manière dont les consommateurs de mode utilisent les promotions pour tester des articles qu’ils n’achèteraient peut-être pas au prix fort.
Ces mécanismes aident à expliquer pourquoi les promotions du Black Friday incitent souvent les consommateurs à opter pour des lots de plusieurs articles plutôt que pour de simples remises.
À lire aussi : Soldes : les commerçants sont-ils d’honnêtes manipulateurs ?
Profit ou planète ? Le dilemme derrière le déstockage
Les soldes saisonniers (Cyber Monday, soldes de janvier, soldes de fin de saison dans la mode…) mettent en évidence un dilemme persistant chez les commerçants : soit maximiser leur bénéfice restant, soit écouler les stocks pour éviter le gaspillage. Notre étude définit deux politiques de promotion optimales (OPP) distinctes : l’une maximise le bénéfice attendu, quitte à ce qu’il reste des invendus ; l’autre est axée sur l’écoulement des stocks.
Nos recherches montrent que ces deux objectifs – maximiser les bénéfices et minimiser le gaspillage – sont souvent contradictoires. Une baisse de prix modérée peut, par exemple, préserver les marges, mais laisser des marchandises invendues. De la même manière, les offres promotionnelles plus importantes de type « deux achetés, un offert » (« Buy Two Get One [Free] », BTGO) peuvent vider les rayons, mais réduire la rentabilité.
Cette tension se retrouve dans des rapports documentant les conséquences des stocks invendus. Parmi ces conséquences : les déchets textiles, lorsque les détaillants jettent ou détruisent les produits de fast-fashion invendus. Ce difficile équilibre entre profits et durabilité apparaît également de façon évidente avec le gaspillage alimentaire, lié à des cycles de fraîcheur stricts et à des erreurs de prévision. Devant ces phénomènes, les autorités européennes renforcent les obligations environnementales, les consommateurs s’interrogeant de plus en plus sur le coût de la surproduction induite par les démarques.
Nos recherches montrent que trouver des moyens d’optimiser la politique promotionnelle aide à atténuer les tensions entre ces deux objectifs. Dans de nombreux scénarios, les OPP axées sur le profit permettent d’atteindre un profit maximal avec un gaspillage limité, tandis que les OPP axées sur la liquidation aident à écouler les stocks avec un sacrifice limité en matière de profit.
Ce que les détaillants et les consommateurs peuvent en retenir
Notre étude met en évidence deux facteurs qui déterminent quelle promotion fonctionne le mieux.
Le premier est le niveau des stocks. Lorsque les stocks sont bas, des remises de prix modestes maximisent les bénéfices sans encourager les achats excessifs. Lorsque les stocks sont élevés, les promotions « un acheté, un offert » ou « deux achetés, un offert » accélèrent la rotation des stocks en tirant parti de l’effet de regroupement. Cela explique pourquoi les soldes du lendemain de Noël s’appuient souvent sur des offres d’achat multiple : les détaillants tentent de réduire les coûts de stockage et le gaspillage.
Le deuxième facteur est le type de produit. Les produits de base, tels que le pain, le dentifrice et les boissons gazeuses – qui ont à l’unité une valeur similaire –, réagissent bien aux promotions « un acheté, un offert ». En parallèle, les produits à valeur hétérogène, tels que les accessoires de mode et les cadeaux de Noël, tirent plutôt profit des promotions « deux achetés, un offert », qui correspondent mieux aux diverses perceptions de valeur des consommateurs.
Pour les consommateurs, cela signifie que les promotions sont rarement arbitraires. Elles révèlent la façon dont les détaillants appréhendent la valeur de leurs articles et comment ils gèrent la pression sur les stocks.
Vers des promotions plus intelligentes et plus durables
Les promotions dans le commerce de détail influencent les choix des consommateurs et le volume des consommations. Comprendre les mécanismes de ces offres peut aider les détaillants à réduire les démarques inutiles et à diminuer le gaspillage, pour concevoir des promotions qui profitent à la fois à l’entreprise et à l’environnement.
Quant aux consommateurs, ils se soucient de plus en plus de la durabilité, de la réparabilité et de la réduction des déchets. Comprendre le fonctionnement des promotions, que ce soit pendant la frénésie du Black Friday ou lors d’une vente discrète en milieu de saison, peut les aider à faire des choix plus éclairés.
Fang Liu a reçu des financements de Major Program of National Natural Science Foundation of China (72192843).
Arvind Sainathan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 15:59
Produire de grandes cultures en agroécologie de manière rentable, c’est possible
Lucie Zgainski, Ingénieur de recherche, Inrae
Marie-Noël Mistou, Ingénieur de Recherche, Inrae
Michel Bertrand, Ingénieur de Recherche, Inrae
Muriel Valantin Morison, Directrice de recherche - agroécologue, Inrae
Texte intégral (2790 mots)

Depuis vingt-cinq ans, l’Inrae teste en conditions réelles des alternatives à l’agriculture conventionnelle sur huit hectares à Versailles, dans les Yvelines. Une expérience riche en enseignements.
Peut-on nourrir la France en réduisant notre utilisation de pesticides et d’engrais azotés ? Pour répondre à cette question, les chercheurs peuvent utiliser plusieurs méthodes. L’une d’entre elles consiste à tester différentes techniques agricoles en conditions réelles sur de grandes cultures et à étudier leurs évolutions sur le temps long.
C’est ce qu’il se passe dans l’une des stations expérimentales de l’Inrae depuis vingt-cinq ans, et les résultats agronomiques et économiques de cette expérimentation donnent de nombreuses raisons de se réjouir.
Un essai système d’une durée de vingt-cinq ans
Le dispositif expérimental La Cage, mis en place en 1998 à Versailles (Yvelines) sur une parcelle de huit hectares, compare ainsi sur le long terme quatre systèmes de culture cohérents et représentatifs des grandes cultures sans élevage :
un système productif conduit en agriculture conventionnelle ;
un système à bas niveau d’intrants (faible utilisation de produits phytosanitaires et d’engrais azotés) ;
un système en agriculture biologique ;
un système sous couvert végétal.
Dans ce dernier cas de figure, des plantes sont semées entre deux cultures afin de protéger le sol lorsqu’il resterait nu. Ces couverts végétaux sont utilisés pour tâcher de limiter l’érosion, d’améliorer la fertilité et la structure des sols, de favoriser la biodiversité et de réduire le développement des mauvaises herbes.
Cette façon de faire de l’agriculture implique une réduction du travail du sol notamment des opérations mécaniques réalisées pour préparer la terre avant les cultures. Cette réduction permettrait notamment de préserver la structure et la biodiversité des sols, de limiter l’érosion, de diminuer les émissions liées à l’usage des machines agricoles et de favoriser la séquestration du carbone dans les sols.
Conçu pour anticiper des enjeux comme la réduction des pesticides ou l’amélioration du bilan carbone, ce dispositif de La Cage permet de tester et d’ajuster des pratiques innovantes en fonction des objectifs et de l’évolution des connaissances.
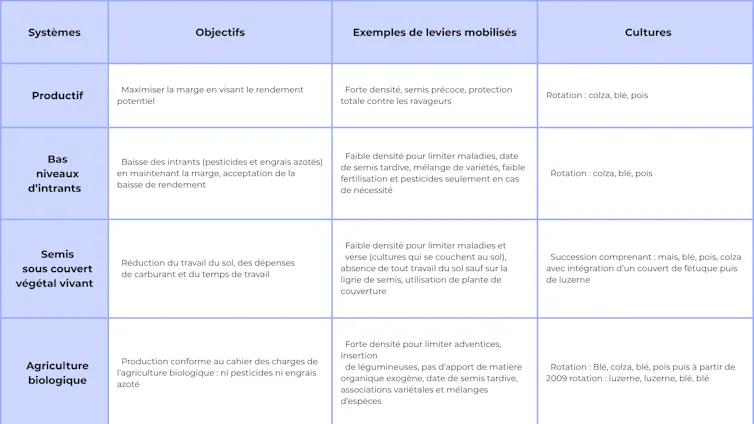
Chaque système combine différents leviers techniques (rotation des cultures, travail du sol, fertilisation, etc.) qui interagissent entre eux : par exemple, la stratégie de fertilisation dépend de la densité de semis choisie, car une densité plus élevée entraîne une compétition accrue entre plantes et modifie leurs besoins en nutriments.
L’agriculture biologique mise, elle, sur les légumineuses pour compenser l’absence d’engrais azotés, car celles-ci (pois, trèfle, luzerne, féverole, etc.) fixent naturellement l’azote de l’air ce qui permet d’enrichir les sols en azote pour les cultures suivantes.
Quelles performances agronomiques des systèmes expérimentaux de La Cage ?
Les rendements des principales espèces cultivées, notamment blé, maïs, colza et pois, ont ainsi été mesurés chaque année, offrant une série temporelle robuste pour comparer la productivité des systèmes contrastés.
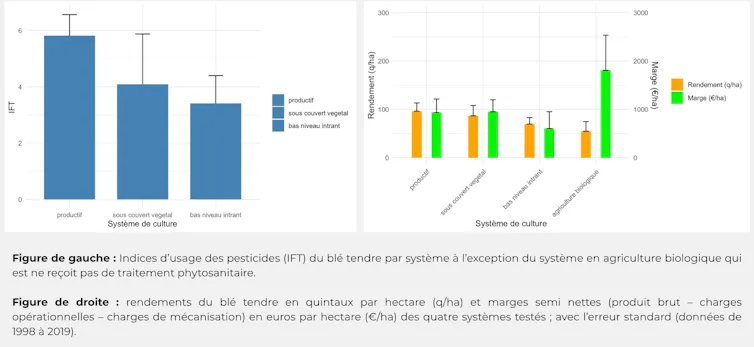
Dans les systèmes avec bas niveau d’intrants, sous couvert végétal et en agriculture biologique, les séries de rendements montrent généralement une variabilité plus élevée et des niveaux moyens de rendement inférieurs au système productif (Cf. Figure 1). Par contre, les marges peuvent être importantes et surpasser nettement le système productif. C’est notamment le cas avec l’agriculture biologique, car le prix de vente du blé bio est en règle générale nettement plus élevé que le conventionnel.
Dans le système sous couvert végétal, la restitution au sol des résidus de culture (tiges, feuilles mortes, racines) et des couverts végétaux contribue à la fertilité des sols. Cependant, ces restitutions influencent également la disponibilité des éléments nutritifs pour les cultures suivantes, ce qui peut entraîner des variations interannuelles des rendements.
Dans les systèmes biologiques et sous couvert végétal, l’introduction de légumineuses permet de capter l’azote atmosphérique, un élément essentiel à la croissance des plantes, modérant ainsi partiellement les déficits d’apport d’engrais azotés.
Par ailleurs, les systèmes sous couvert permanent sans travail du sol montrent des effets positifs sur la structure du sol, notamment par l’amélioration de la stabilité des agrégats et l’augmentation de la porosité, favorisant ainsi l’infiltration de l’eau et l’activité biologique du sol. Ces bénéfices doivent être mis en balance avec des défis techniques comme la gestion des couverts, qui sont en compétition pour l’eau et les nutriments avec les cultures principales et le défaut de maîtrise des mauvaises herbes.
Globalement, l’analyse agronomique et économique de La Cage confirme que certains systèmes de culture diversifiés peuvent atteindre des niveaux de rentabilité équivalents au système productif, sur la culture du blé et à l’échelle de la rotation, tout en améliorant certains aspects de durabilité. Ces résultats illustrent aussi l’importance de considérer des séries longues de données pour intégrer la variabilité climatique et les effets cumulatifs des pratiques de gestion, la restitution des résidus de culture au sol et la dynamique des cultures successives.
Mais qu’en est-il de ces maladies qui peuvent ravager les cultures et qui restent encore souvent les bêtes noires des agriculteurs ? Considérant, par exemple, la septoriose du blé, nos résultats montrent les limites des systèmes productifs très vulnérables dès que l’on n’utilise plus de pesticides.
La gestion des maladies
La septoriose du blé est une maladie fréquente qui dépend fortement du climat. Sa gestion repose sur différents leviers (choix variétal, pratiques culturales, fongicides). Les systèmes productifs très dépendants des traitements sont les plus touchés lorsque l’on retire l’usage des pesticides. Des systèmes, comme le semis sous couvert, limitent mieux la maladie, car il permet aux microorganismes (bactéries, champignons, faune du sol) de rentrer en compétition avec les agents pathogènes ou de limiter leur développement. Ainsi, réduire les pesticides n’entraîne pas forcément plus de maladies, à condition d’adapter les pratiques. Globalement, c’est la cohérence du système agricole dans son ensemble qui permet une gestion durable des maladies.
Notre étude confirme également d’autres bénéfices aux pratiques agroécologiques. Le premier concerne le carbone qui est stocké dans les sols agricoles et qui représente aujourd’hui un enjeu majeur pour l’atténuation du changement climatique.
Quel bilan carbone ?
De fait, une partie non négligeable du carbone séquestré par les plantes lors de la photosynthèse finit dans le sol par l’intermédiaire des racines. Les résidus de culture aériens (tiges, feuilles mortes…) constituent un autre apport en carbone dans les sols. Mais selon les techniques agricoles utilisées, la pérennité de ce stock de carbone peut fluctuer.
Le carbone stocké dans le sol est un des déterminants majeurs de sa fertilité, qu’elle soit physique (maintien de la structure), chimique (fourniture de nutriments) ou biologique (ressource pour les organismes vivants).
En l’absence d’apports d’effluents organiques issus de l’élevage, le bilan carbone d’un système de culture découle seulement du niveau des entrées et des pertes à l’échelle de la parcelle. Les entrées correspondent donc aux résidus (aériens et souterrains) des cultures et des couverts végétaux. Les pertes correspondent à la minéralisation des matières organiques du sol sous l’action des microorganismes qui peuplent la terre, la décomposent et la transforment en éléments minéraux.
Les systèmes de culture de La Cage présentent des dynamiques contrastées d’apports de carbone au sol, étroitement liées à la productivité des cultures, à la place des légumineuses et des couverts végétaux.
Plus les rendements sont élevés, plus il y a des résidus de culture restitués au sol. C’est donc le système productif qui produit le plus de résidus riches en carbone. Toutefois, cette réalité est compensée dans les systèmes ayant des couverts végétaux. Dans le système sous couvert, les apports totaux de carbone sont au final estimés à un niveau supérieur à celui des autres systèmes, grâce à l’apport de ces couverts. Au final, le stock de carbone augmente dans le temps dans le système en agriculture biologique et encore plus dans le système sous couvert végétal, alors qu’il reste stable dans les deux autres systèmes.
Quels effets sur la biodiversité du sol ?
Au-delà de la gestion des maladies et de l’apport en carbone des sols, notre étude met également en évidence un autre bénéfice majeur des pratiques agroécologiques : leur effet positif sur la biodiversité du sol.
La biodiversité du sol comprend une multitude de taxons de taille extrêmement variable et qui remplisse des fonctions diverses. Les vers de terre qui constituent l’essentiel de la macrofaune du sol sont les plus souvent étudiés et sont considérés comme des acteurs majeurs du fonctionnement du sol compte tenu de leur rôle de fouisseur et transformateur de la matière organique. Les pratiques agricoles, en particulier le travail du sol, l’apport de matière organique et l’usage de pesticides, sont de longue date reconnues comme ayant un impact majeur dans le maintien de ces populations.
Le système sous couvert végétal, sans travail du sol, se distingue par des abondances et biomasses nettement plus élevées de vers de terre anéciques et épigés, de trois à sept fois supérieures à celles observées dans les systèmes productif et biologique avec du travail du sol, et ce, seulement une dizaine d’années après l’implantation de l’essai. Cette augmentation s’accompagne également d’une diversité en espèces de vers de terre.
En agriculture biologique, l’augmentation des populations de vers de terre est plus lente. Mais après plus de quinze ans de conduite, ce système peut héberger entre 1,5 et 2,3 fois plus de vers de terre que le système productif, selon les variations interannuelles liées au climat.
Par ailleurs, les changements de pratiques agricoles mettent souvent plusieurs années à se traduire par des modifications significatives des communautés de vers de terre. Ces résultats soulignent l’importance des dispositifs expérimentaux de long terme pour évaluer de manière robuste l’impact des systèmes de culture sur la biodiversité des sols.
Que retenir ?
Les essais systèmes sont des outils clés pour tester et évaluer des solutions agroécologiques. Sur le long terme, ils montrent qu’il est possible de produire avec moins de pesticides, d’azote et d’énergie, tout en assurant une marge économique pour l’agriculteur, un stockage de carbone et l’accroissement de la biodiversité dans les sols.
Le dispositif évolue pour répondre à ces enjeux qui se posent aujourd’hui à l’agriculture et en lien avec la demande sociétale : produire sans apport d’azote, sans travail du sol, aller vers une agriculture sans pesticides, concilier production et biodiversité. Des nouveaux systèmes abordant ces thématiques sont en cours de conception avec la profession agricole.
Lucie Zgainski a reçu des financements de l'ANR.
Michel Bertrand a reçu des financements de l'ANR
Muriel Valantin Morison a reçu des financements de l'ANR et du programme Ecophyto pour réaliser ses recherches
Marie-Noël Mistou ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 15:57
Petits-enfants d’immigrés : du diplôme à l’emploi, le modèle républicain tient-il ses promesses ?
Mathieu Ichou, Chargé de recherche à l’Ined, co-responsable de l’unité Migrations Internationales et Minorités (MIM), Ined (Institut national d'études démographiques)
Texte intégral (1621 mots)
Si, dans les familles immigrées, l’ascension scolaire est réelle, la génération des petits-enfants se heurte sur le terrain de l’emploi à des inégalités persistantes et à certaines formes de déclassement. C’est ce que montrent les résultats d’un projet de recherche inédit, mené à l’Institut national d’études démographiques.
En France, environ une personne de moins de 60 ans sur trois a un lien généalogique avec la migration : soit parce qu’elle est elle-même immigrée (« première génération »), soit parce qu’elle est l’enfant d’un ou de deux parents immigrés (« deuxième génération »), soit parce qu’elle est le petit-enfant d’au moins un grand-parent immigré (« troisième génération »).
Cette troisième génération reste méconnue, car les enquêtes de la statistique publique ne permettent pas de l’identifier. Les recherches sur les enfants d’immigrés ont déjà montré que leurs trajectoires scolaires et professionnelles sont très diverses : certains groupes atteignent des positions proches de celles de la population majoritaire sans ascendance migratoire, tandis que d’autres – notamment au sein des minorités racisées – restent plus exposés au chômage, à la ségrégation résidentielle ou aux discriminations.
Mais l’étude de cette deuxième génération ne permet pas toujours de savoir si ces écarts tiennent surtout à l’expérience migratoire des parents ou à des mécanismes plus durables, produits dans la société française elle-même. Les petits-enfants d’immigrés, nés en France de parents eux-mêmes nés en France, permettent de trancher : si des écarts subsistent encore à cette génération, ils signalent des mécanismes d’exclusion durables (ségrégation, discrimination, racisme), et non les seuls effets de la migration initiale.
Que deviennent ces petits-enfants d’immigrés en matière de diplômes et d’emploi ? Le modèle républicain tient-il ses promesses d’égalité, quelle que soit l’origine ?
Ce sont précisément les questions que nous nous sommes posées à travers le projet 3GEN, mené à l’Institut national d’études démographiques (Ined) et financé par l’ANR. Grâce à l’enquête Trajectoires et Origines 2 (TeO2), qui permet pour la première fois d’identifier directement les petits-enfants d’immigrés à grande échelle, les chercheurs et chercheuses impliqués dans le projet ont pu comparer les parcours de trois générations : les immigrés eux-mêmes, leurs enfants, et leurs petits-enfants.
Les analyses, que nous avons publiées avec Milan Bouchet-Valat, Louise Caron, Lucas Drouhot, Mathieu Ferry, Ognjen Obućina, Ariane Pailhé, Paul Siarry et Rosa Weber dans plusieurs revues scientifiques de premier plan (Revue française de sociologie, European Sociological Review, Demography et American Sociological Review) apportent des résultats inédits.
L’ascension scolaire sur trois générations
Le premier constat est celui d’une progression éducative importante. Les grands-parents immigrés arrivés en France dans l’après-guerre étaient, pour la grande majorité, sans diplôme : 72 % des grands-parents d’origine nord-africaine (Algérie, Maroc, Tunisie) et 55 % des grands-parents d’Europe du Sud (Portugal, Espagne, Italie) n’avaient aucun titre scolaire, contre 23 % pour les grands-parents nés en France de parents eux-mêmes français.
Leurs enfants et petits-enfants ont bénéficié de l’expansion du système scolaire français. Entre grands-parents et parents, la mobilité ascendante est frappante dans les familles immigrées : 67 % des trajectoires intergénérationnelles sont ascendantes dans les familles d’origine nord-africaine, et même 72 % dans les familles d’Europe du Sud, contre 54 % dans les familles de la population majoritaire.
Au final, les petits-enfants d’immigrés, pris dans leur ensemble, ont des trajectoires scolaires très proches de celles des personnes sans ascendance migratoire, notamment pour les petits-enfants d’immigrés sud européens.
Des inégalités qui persistent pour les descendants d’Afrique du Nord
La réalité est plus contrastée pour les petits-enfants d’immigrés nord-africains. Certes, ils progressent eux aussi nettement par rapport à leurs grands-parents et leurs parents. Mais des pénalités demeurent, tant dans l’accès à l’enseignement supérieur que dans la sortie du système scolaire sans aucun diplôme.
La situation n’est pas la même pour les filles et les garçons. Les petites-filles d’immigrés nord-africains connaissent des trajectoires scolaires favorables : elles sont même surreprésentées en haut de la distribution des diplômes. Ce sont principalement les petits-fils d’immigrés maghrébins qui concentrent les difficultés. Ils sont nettement plus représentés parmi les sortants sans diplôme, et nettement moins dans les classes préparatoires aux grandes écoles.
Ce contraste entre hommes et femmes au sein d’un même groupe d’origine n’est pas nouveau, mais il ne s’estompe pas à la troisième génération. Il suggère que les mécanismes à l’œuvre vont au-delà du simple héritage social familial, d’autant que les petits-enfants d’immigrés ont souvent grandi dans des milieux sociaux assez proches de ceux de la population majoritaire.
Le diplôme ne suffit pas : le déclassement professionnel subsiste
Une autre dimension, moins souvent examinée, est celle du déclassement : le fait d’exercer un emploi qui ne correspond pas à la formation obtenue. Le déclassement vertical désigne la situation où l’on est plus diplômé que les autres personnes occupant le même type de poste. Le déclassement horizontal renvoie au fait de travailler dans un secteur sans rapport avec son domaine d’études.
Le déclassement vertical touche surtout les immigrés à la première génération et s’explique essentiellement par la non-reconnaissance des diplômes obtenus à l’étranger. Dès la deuxième génération, formée en France, ce problème disparaît presque entièrement.
En revanche, le déclassement horizontal persiste de façon significative pour les hommes d’origine non européenne, et ce, jusqu’à la troisième génération. Davantage orientés vers des filières généralistes ou peu professionnalisantes, ils se retrouvent plus souvent dans des emplois sans lien avec leurs études.
L’intégration républicaine : entre promesses tenues et inégalités persistantes
Que conclure de l’ensemble de ces travaux ? La situation de la troisième génération nous renseigne moins sur l’immigration que sur le fonctionnement de la société française elle-même. Elle montre à la fois la force des processus d’égalisation au fil des générations et la persistance de certaines inégalités liées à l’origine.
D’un côté, une dynamique puissante de rattrapage scolaire est à l’œuvre sur trois générations. La mobilité sociale ascendante des familles immigrées est réelle quelle que soit l’origine, et les petits-enfants d’immigrés européens connaissent une véritable égalisation avec la population majoritaire. Ce résultat donne du crédit à l’idée d’une intégration progressive permise par les institutions françaises, notamment par l’école publique.
De l’autre côté, des frontières ethnoraciales persistent dans la durée. Les petits-fils d’immigrés nord-africains font face à des désavantages scolaires durables que l’origine sociale de leurs parents n’explique pas complètement. Les données de l’enquête TeO2 montrent d’ailleurs que ces petits-enfants déclarent plus souvent que leurs camarades sans ascendance migratoire avoir subi au moins un traitement injuste dans le cadre scolaire.
La persistance des inégalités à la troisième génération ne peut pas être rapportée seulement aux origines sociales modestes des grands-parents immigrés. Elles renvoient aussi à des processus de ségrégation et de discrimination qui continuent d’affecter les trajectoires scolaires et professionnelles. La promesse républicaine d’égalité des chances semble donc largement tenue pour les familles originaires d’Europe du Sud, mais reste inachevée pour les familles originaires d’Afrique du Nord.
Le projet 3GEN est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Mathieu Ichou a reçu des financements de l'ANR.
29.06.2026 à 11:12
Peut-on mesurer l’invisible ? Comment naissent les indicateurs qui guident nos décisions ?
Florence Jeannot, Full Professor in Marketing, INSEEC Grande École
Guy Parmentier, Professeur des universités à Grenoble IAE, Grenoble IAE Graduate School of Management
Romain Rampa, Professeur Adjoint, École de technologie supérieure (ÉTS)
Texte intégral (1410 mots)
Cela devrait être un préalable à toute action. Bien construire un indicateur ne s’improvise pas. Comment procéder pour être certain de bien mesurer la variable voulue, sans effets de bord et autres biais ? C’est d’autant plus essentiel que la décision s’appuie sur ces indicateurs. Décryptage de la méthode et illustration avec le cas de la créativité, une « compétence » qui n’est pas immédiatement mesurable.
Créativité, engagement, confiance, bien-être : ces notions occupent aujourd’hui une place centrale, qu’il s’agisse d’entreprises, d’institutions publiques ou d’organisations éducatives. Elles orientent des décisions importantes, de l’innovation à l’évaluation des politiques publiques, jusqu’à l’amélioration des conditions de travail. Dans un contexte marqué par l’incertitude et les transformations rapides, elles sont de plus en plus mobilisées pour éclairer la manière dont les organisations s’adaptent et font face à ces changements.
Un point commun les relie : elles ne sont pas directement observables et doivent être appréhendées à travers des indicateurs. Dès lors, comment mesurer ce qui ne se voit pas ? Ces notions sont dites « intangibles » : elles correspondent à ce que les chercheurs appellent des construits latents, c’est-à-dire des réalités que l’on ne peut saisir qu’indirectement. Autrement dit, on ne mesure pas directement la créativité ou le bien-être, mais les éléments qui permettent de les approcher.
Derrière ces indicateurs se cache un processus de construction scientifique exigeant, souvent méconnu, qui conditionne la manière dont ces réalités sont évaluées et, in fine, les choix qui en résultent.
À lire aussi : L’impact invisible des outils de chantier sur la santé des travailleurs
Mesurer n’est jamais un acte neutre. C’est une manière de rendre certaines réalités visibles, et donc d’orienter les décisions. C’est aussi une manière de préciser ce qui compte pour une organisation et ce que l’on choisit d’observer et de suivre dans le temps.
Ce processus s’appuie sur une démarche méthodologique bien établie, notamment dans les travaux de Gilbert Churchill sur le développement d’échelles de mesure. À partir de nos travaux récents, il est possible d’en comprendre les étapes et les enjeux.
Clarifier l’objet de la recherche
La première étape consiste à clarifier ce que l’on cherche réellement à mesurer. En pratique, un même terme peut recouvrir des réalités différentes. Dans notre recherche, nous nous sommes intéressés à la créativité organisationnelle, non pas comme un simple résultat, mais comme une capacité. Une organisation devient créative lorsqu’elle met en place des pratiques, des dispositifs et des routines qui favorisent durablement la génération et le développement d’idées.
Pour préciser ce concept, nous avons analysé 417 articles scientifiques, ce qui nous a permis d’identifier cinq dimensions : l’ouverture vers l’extérieur, la socialisation des idées, l’équipement créatif, la gestion des idées et l’agilité organisationnelle.
Cette étape transforme une notion abstraite en un cadre clair, indispensable pour construire des indicateurs fiables. Elle permet aussi d’éviter de réduire des phénomènes complexes à des indicateurs trop simplistes.
Traduire le concept en indicateurs
Une fois les dimensions définies, il s’agit de les rendre mesurables. Concrètement, cela consiste à construire des « items », c’est-à-dire des questions permettant de capter chaque dimension à travers des pratiques observables. Par exemple, une organisation favorise-t-elle les échanges d’idées ? Dispose-t-elle d’outils pour les développer ? Est-elle ouverte à des sources d’inspiration extérieures ?
Cette phase correspond à la génération et à la sélection des items : il s’agit de créer puis de retenir les indicateurs les plus pertinents, en éliminant ceux qui sont redondants ou peu fiables. L’enjeu n’est pas d’accumuler les mesures, mais de retenir celles qui rendent le mieux compte de la réalité étudiée. Dans notre étude, cette étape a permis de construire un ensemble de 16 items traduisant les différentes dimensions des capacités créatives organisationnelles, avant de les soumettre aux étapes de validation.
Indispensable vérification
La dernière étape consiste à vérifier la qualité des indicateurs et la robustesse de l’échelle de mesure. Nous avons ainsi mené une enquête auprès de 900 répondants issus de différentes organisations, à l’échelle internationale, afin d’élargir la portée des résultats. Les données ont été analysées à l’aide de deux approches complémentaires :
l’analyse factorielle exploratoire permet d’identifier comment les réponses se regroupent entre elles, autrement dit les grandes dimensions qui émergent des données ;
l’analyse factorielle confirmatoire permet ensuite de vérifier que ces regroupements correspondent bien au modèle théorique proposé.
Ces méthodes permettent ainsi de vérifier que les résultats sont cohérents et qu’ils correspondent bien à la manière dont le phénomène a été modélisé. Elles constituent une première étape dans l’évaluation de la robustesse de l’échelle, en vérifiant la solidité de sa structure.
Plusieurs tests sont ensuite réalisés pour évaluer la qualité de l’échelle. Ils permettent notamment de vérifier sa fiabilité, ainsi que différentes formes de validité. En particulier, la validité convergente signifie que les items censés mesurer une même dimension donnent des résultats cohérents. La validité discriminante vérifie que les différentes dimensions de l’échelle sont bien distinctes.
Enfin, la validité prédictive permet de s’assurer que les indicateurs sont liés à des résultats concrets, comme la production d’innovations. Ainsi, les résultats de notre étude montrent que l’échelle développée est fiable et robuste, et qu’elle permet d’anticiper les résultats créatifs au sein des organisations.
De la mesure à l’action
Cette démarche a donné lieu à la mise en ligne d’un outil accessible gratuitement, permettant aux organisations d’évaluer leurs capacités créatives. À partir d’un questionnaire, il est possible d’obtenir un score global, ainsi qu’un diagnostic détaillé des différentes dimensions, accompagné de pistes d’amélioration concrètes.
L’intérêt est double : rendre visible une capacité souvent difficile à repérer pour les organisations et fournir des leviers d’action pour la développer dans le temps. Au-delà des résultats, il s’agit de mieux comprendre les équilibres internes et les marges d’adaptation d’une organisation.
Cette démarche s’applique tant aux entreprises qu’aux institutions publiques et aux organisations éducatives. Elle peut également être mobilisée pour analyser d’autres notions que la créativité, y compris des phénomènes sociétaux tels que le bien-être psychologique ou la cohésion sociale. Dans tous les cas, les indicateurs reposent sur des choix théoriques et méthodologiques qui influencent leur interprétation. Ils contribuent ainsi à orienter les façons de penser et d’agir face à des enjeux complexes.
Florence Jeannot a reçu des financements de l'Agence nationale de la recherche.
Guy Parmentier a reçu des financements de l'ANR
Romain Rampa ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
29.06.2026 à 11:12
C’est qui le patron ?! : comment la co-création permet de convaincre les consommateurs de payer un « prix juste »
Faten Malek, Associate professor, ESSCA School of Management
Arabella David Ignatieff, Enseignante chercheuse marketing, ESC Amiens
Norchene Ben Dahmane Mouelhi, Marketing, ESCE International Business School
Olivier Braun, ICN Business School
Texte intégral (2023 mots)
L’histoire de la création de la marque équitable C’est qui le patron ? ! est un exemple éclairant de la façon dont le consommateur peut faire plus qu’acheter un produit. Ou comment faire de ses clients des partenaires dans la durée. Décryptage d’un cas exceptionnel.
L’engouement pour le bio, la transparence et les valeurs environnementales pousse de nombreuses entreprises à revendiquer des engagements responsables. Dans ce paysage concurrentiel, dominé par de grandes firmes disposant de ressources marketing considérables, la marque C’est qui le patron ? ! (CQLP) occupe une position singulière : elle revendique un ADN équitable, participatif et historiquement orienté vers le juste prix et la gouvernance citoyenne.
Cependant, alors que les stratégies de responsabilité se multiplient au travers des labels, des engagements socialement responsables, de la communication verte, de l’innovation durable, la question de l’attractivité de cette marque s’impose dans un contexte de transition écologique s’impose comme un enjeu incontournable. Cependant, à mesure que les stratégies de responsabilité se multiplient à travers les labels, les engagements socialement responsables, la communication verte ou encore l’innovation durable, la question de l’attractivité de la marque s’impose comme un enjeu incontournable dans le contexte de transition écologique.
La marque des consommateurs à un prix plus « juste »
Pour comprendre ces enjeux, il faut revenir aux origines de la marque. En 2015, une nouvelle crise du lait survenait. Les producteurs français ont alors décidé de se mettre en grève, car ils n’arrivaient plus à vivre de leurs exploitations de lait pour des raisons conjoncturelles et structurelles : la chute des cours, la fin des quotas laitiers, l’ouverture des marchés… Notons que, à ce jour, la filière laitière est toujours fragilisée par la surproduction de lait et l’épisode de dermatose nodulaire.
Afin d’améliorer la condition des producteurs de lait, en 2017, Nicolas Chabane a eu l’idée de lancer la société SCIC ainsi que la marque CQLP. Elle soutient les producteurs en les rémunérant à un prix plus acceptable pour eux mais aussi raisonnable pour ses clients : le « juste prix ».
La marque s’est appuyée sur les consommateurs pour supporter cette initiative, inscrite plus largement dans le soutien du secteur agricole. Depuis, elle attire et fidélise une base de clients engagés, en France comme dans plusieurs pays limitrophes.
Ce modèle de croissance se traduit par la diversification progressive de son offre et le maintien de sa promesse de justice sociale, économique et environnementale.
Toutefois, cette trajectoire questionne la pérennité de l’équilibre entre l’engagement des consommateurs, les contraintes économiques et les attentes des différents intervenants de la chaîne de valeur.
Un positionnement gagnant pour tout le monde ?
Ce juste prix est une source de différenciation forte pour la marque qui répond à la sensibilité accrue des consommateurs à un comportement dit responsable, voire militant. Nicolas Chabanne, un des fondateurs, exprime les raisons de la création de la marque et les caractéristiques de son ADN en ces termes évocateurs : « il faut apporter plus de considération à ceux qui nous nourrissent, les agriculteurs, et faire attention à ce que nous mangeons : nos corps ne sont pas des poubelles, et au fond nous aspirons tellement à autre chose ».
Au‑delà de la question du « juste prix », les valeurs mises en avant par le fondateur reposent sur une plus grande considération des producteurs et une attention accrue à la qualité de l’alimentation. Ces principes se prolongent par une recherche de proximité avec les consommateurs, qui ne sont plus seulement des acheteurs, mais des acteurs impliqués dans le fonctionnement de la marque. CQLP s’est très vite fait une belle place sur le marché.
Elle se positionne également en cultivant la proximité et la participation avec ses clients. CQLP est la première entreprise agroalimentaire. Les clients sont associés, s’ils le désirent, à la sélection des produits, de leurs caractéristiques, telles que le packaging et le prix de vente. Les clients peuvent suggérer, notamment, la production de nouveauté, demander à des enseignes de distribuer des produits estampillés CQLP. Ils contribuent de plus à la modification de la gamme de produits, sur un ensemble de critères, traditionnellement géré par les services marketing et commercial, par exemple. La marque sollicite alors l’avis des clients et des sociétaires grâce à leur vote en ligne. Les consommateurs deviennent alors des « consommacteurs ».
Ces multiples formes de participation contribuent à la pérennité des principes d’équité, de transparence et d’authenticité portés par la marque. Certaines enseignes de la grande distribution souscrivent également à ces principes et favorisent le développement de CQLP.
En définitive, toutes les parties prenantes bénéficient de ce positionnement soutenable : producteurs, clients et distributeurs.
Le soutien de la communauté paysanne
L’entreprise a ainsi réussi à créer une communauté dynamique et engagée de plus de 13 000 sociétaires. Pour devenir sociétaire, il suffit de verser un euro seulement. La marque vise à inclure les clients comme les sociétaires dans son circuit de décision marketing et commercial : le client est le patron !
Dans cette logique, clients et sociétaires participent concrètement à la mise sur le marché de produits agroalimentaires. Par exemple, récemment, près de 1 000 d’entre eux ont participé au vote concernant l’intégration dans la gamme des tomates concassées en boîte. L’engagement des clients et des sociétaires s’inscrit également dans la volonté de valoriser les producteurs locaux.
L’engagement citoyen de CQLP se concrétise par plusieurs actions. La marque a ainsi redistribué plus de 150 millions d’euros, principalement via l’achat de productions agricoles (146 millions d’euros), mais aussi par le biais d’aides directes (5 millions d’euros), notamment à travers un « fonds de solidarité des consommateurs et citoyens » lancé en avril 2020. Dans cette même logique d’accompagnement des filières, elle a également versé plus de 3,4 millions d’euros entre 2017 et 2021 afin de soutenir la transition des exploitations agricoles vers l’agriculture biologique.
Ces initiatives contribuent à renforcer la crédibilité et l’attractivité de la marque. En mai 2024, CQLP a ainsi atteint la première place du classement Nielsen des nouvelles marques. Par ailleurs, elle a enregistré une croissance de 16 % de ses ventes en janvier et février 2026.
Travailler gratuitement
Face à des consommateurs en quête de preuves concrètes, de traçabilité et de transparence, CQLP mise sur la visibilité de l’origine de ses produits et sur leur implication dans la définition des caractéristiques des offres, notamment via des questionnaires. Cette démarche favorise l’émergence de « consommacteurs », fortement attachés à la marque et prêts à la défendre.
L’anxiété écologique et la méfiance envers les discours traditionnels des marques contribuent également à ce succès, en particulier lorsque les produits proposés soutiennent les producteurs locaux et participent à la réduction de l’empreinte carbone.
Dans ce contexte, les consommateurs acceptent non seulement de contribuer gratuitement à certaines activités de la marque, mais aussi de payer un prix légèrement supérieur pour des produits jugés plus équitables.
Plus généralement, les entreprises qui recourent à la co‑création, à l’image de CQLP, voient leur mode de fonctionnement évoluer. Cette logique implique une gestion plus participative intégrant à la fois collaborateurs, producteurs et consommateurs dans les processus de création de valeur.
En rendant visible l’origine de ses produits et en intégrant les consommateurs dans un processus structuré de co‑création, CQLP ne se limite pas à répondre à leurs attentes ; elle redéfinit la relation client en une relation engageante et solidaire.
Un capital marque relationnel et communautaire
La co‑création de valeur se manifeste lorsque les marques et leurs clients s’accordent sur les caractéristiques des produits proposés et les modalités de leur mise sur le marché. Ce processus contribue à la construction d’un capital de marque relationnel, fondé sur la confiance, l’engagement communautaire et une forme d’appropriation collective. Il constitue ainsi une source d’avantage concurrentiel à la fois singulière, durable et difficilement imitable.
La co‑création cumule plusieurs avantages :
elle améliore l’expérience et la satisfaction des clients, renforce la perception de la marque, favorise le bouche‑à‑oreille et contribue à la fidélisation
elle permet aux consommateurs de gagner du temps, d’accéder à des produits mieux adaptés à leurs besoins et d’exprimer à la fois leur singularité et leur créativité, renforçant ainsi leur rôle d’ambassadeurs engagés de la marque.
La promesse de la marque, son ADN et les avantages de la co‑création constituent une source d’inspiration pour les entreprises et les créateurs.
Modèle inspirant ?
CQLP, qui fête ses dix ans, incarne une approche innovante en plaçant les consommateurs au cœur de son modèle d’affaires. Ce modèle est susceptible de susciter l’intérêt d’entrepreneurs en quête d’innovation et de relations plus authentiques avec leurs publics. Il s’adresse plus largement à celles et ceux souhaitant concilier performance économique et engagement social et environnemental.
Dans un contexte économique marqué par l’incertitude, les consommateurs tendent en effet à privilégier des marques porteuses de sens, proposant des prix équitables et des produits de qualité. Cet ADN de marque apparaît transférable à d’autres secteurs désireux de renforcer leur capital de marque tout en répondant aux attentes croissantes en matière de responsabilité et de transparence. Ce modèle d’affaires a permis à une équipe de chercheurs d’avoir en juin 2026 le prix CCMP FNEGE de la meilleure [étude de cas RSE.]
La marque CQLP illustre l’évolution des marques vers des approches plus relationnelles, fondées sur la participation et la confiance.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 11:12
Les sciences de gestion, une discipline « jouvence » ?
Jérôme Lamy, Directeur de recherche au CNRS (historien et sociologue des sciences), Observatoire de Paris
Philippe Schäfer, Professeur associé en sciences de gestion, Excelia
Vincent Helfrich, Professeur, ESSCA School of Management
Texte intégral (1163 mots)
Les sciences de gestion restent méconnues d’un public non initié. Voilà un prétexte pour étudier la diversité de ses investissements scientifiques.
Cet article est publié dans le cadre d’un partenariat avec la Revue française de gestion, qui a fêté ses 50 ans en 2025.
Les sciences de gestion, comme discipline scientifique, sont très peu connues du grand public. Il faut dire qu’à côté d’autres sciences plus anciennes et mieux ancrées, elles doivent constamment affirmer leur légitimité. Comment observer, de façon globale, l’évolution d’une discipline ? Nous avons fait le choix d’étudier les différentes façons dont les articles réflexifs publiés par la Revue française de gestion, rendaient compte des évolutions disciplinaires de la gestion. L’enjeu est de saisir la spécificité de cette discipline via la stratification fine des pratiques de recherche qu’elle investit.
Nous avons requis un outil d’analyse, les régimes de science, développé par le sociologue Terry Shinn. Les régimes de sciences caractérisent différentes formes d’investissements scientifiques en rendant compte des moyens mis en œuvre, des pratiques ordinaires de validation des savoirs et des audiences visées. Les sciences de gestion se distinguent par une implication forte et simultanée dans quatre de ces régimes, ce qui explique à la fois leur hétérogénéité et leur difficulté persistante à établir une identité unique capable de transcender l’enfermement induit par des logiques de spécialisation disciplinaire.
Le régime disciplinaire : une quête identitaire
Le régime disciplinaire est le socle de toute science, centré sur sa communauté, ses revues et la création de connaissances. Les sciences de gestion regroupent un ensemble hétérogène d’objets d’étude et de méthodologies, segmenté en sous-disciplines (stratégie, marketing, finance, management, logistique, etc.) qui se développent parfois de manière autonome. Ce trait composite conduit à une hétérogénéité persistante.
À lire aussi : Une brève histoire des méthodes managériales
Loin d’être un défaut, cette fragmentation est considérée comme un mode d’existence structurel d’une science dont l’objet d’étude est essentiellement multidimensionnel et en transformation permanente : l’action organisée. L’évolution des sciences de gestion est donc marquée par une posture de « prescience perpétuelle » car la discipline interroge en permanence ses fondements épistémiques.
Le régime transitaire : le point d’origine des sciences de gestion
Le régime transitaire décrit la circulation des acteurs, des concepts et des méthodes entre disciplines. Nées tardivement en France, les sciences de gestion ont émergé comme une « discipline-carrefour » à partir des années 1970. Elles se sont constituées en accueillant des économistes, des ingénieurs et des sociologues et ont donc naturellement emprunté à des sciences aussi diverses que l’économie, la sociologie, la psychologie, l’ingénierie, les mathématiques, pour se construire.
Néanmoins, ce mouvement n’est plus à sens unique. Depuis les années 2000 et surtout 2010, la discipline est devenue une source d’inspiration et de transfert pour d’autres domaines scientifiques (comme l’étude des dynamiques organisationnelles).
Le régime utilitaire : de l’efficacité opératoire à une utilité sociale
Le régime utilitaire est axé sur les débouchés commerciaux et la résolution de problèmes techniques. Contrairement aux sciences naturelles, les sciences de gestion sont peu concernées par le dépôt de brevets. Elles développent cependant de nombreux outils (instruments) pour tout type d’organisations. C’est principalement le rapport à l’action qui alimente, dans les années 1980, les débats internes à la discipline : quel équilibre trouver entre un utilitarisme trop dominant et une recherche « hors sol », trop éloignée du terrain ?
La tension entre rigueur académique et pertinence pratique demeure constante en sciences de gestion. Cependant, cette obsession d’utilité connaît aujourd’hui une inflexion notable. Les chercheurs interrogent aujourd’hui les effets des connaissances produites sur la société (avec, par exemple, l’intégration des exigences environnementales).
Le régime régulatoire : inspirer les politiques économiques et sociales pour transformer la société
Les sciences de gestion ont été moins visibles dans l’appareil d’État que d’autres disciplines. Le régime régulatoire concerne une forme de recherche qui répond aux besoins de l’action publique, notamment en matière de gouvernance et de régulation. Ces préoccupations sociales nourrissent le développement le plus récent, s’accentuant après la crise financière de 2008, la pandémie de Covid et les manifestations récurrentes des changements climatiques.
Ainsi, depuis le début des années 2000, des chercheurs en gestion ont fait une véritable « offre de service » pouvant contribuer aux politiques publiques, même si les articulations avec les institutions de gouvernement sont restées mineures dans les faits.
Notre analyse rend compte de la diversité des investissements scientifiques au sein des sciences de gestion qui se sont constituées en discipline, pour l’essentiel, à partir des années 1970. Les acteurs de la discipline, tels qu’ils se sont exprimés depuis cinquante ans dans la Revue française de gestion, ont tenté de défendre un modèle scientifique d’investissement maximal. C’est-à-dire que la gestion a été pensée comme une discipline modèle, capable de répondre à toutes les formes d’injonction épistémiques : disciplinairement efficace, opérationnelle d’un point de vue utilitaire, ouverte aux transferts de méthodes et prête à contribuer aux sciences de gouvernement.
En plus de son réexamen épistémique permanent, qui lui confère un statut de discipline « jouvence », la gestion est aussi marquée par une forme d’hypercorrection scientifique (pour reprendre une approche de Pierre Bourdieu et Luc Boltanski) qui lui fait s’astreindre à des exigences accrues de légitimité.
Jérôme Lamy a reçu des financements du CNES et du CNRS
Philippe Schäfer et Vincent Helfrich ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
29.06.2026 à 11:11
La science des passes en football nous apprend qu’au-delà de 60 % de stars dans l’équipe, la performance baisse
Mehdi Bagherzadeh, Professeur, Neoma Business School
Fabio Fonti, Professeur, Neoma Business School
Texte intégral (1543 mots)
Et si le succès dépendait moins de la présence des meilleurs joueurs que de la mise en place de conditions propices à un collectif fort ? C’est la leçon tirée d’une étude portant sur 1 750 matchs dans les cinq principales ligues masculines européennes de football lors de la saison 2017–2018. La Coupe du monde 2026 nous donnera peut-être une nouvelle occasion de le vérifier.
L’équipe de France avec un collectif composée de stars aura-t-elle moins de chance de remporter la Coupe du monde que des équipes avec un collectif plus fort organisées autour de joueurs moins célèbres ?
Car après des « années de galère et de combat », le Paris Saint-Germain (PSG) a remporté la Ligue des champions de l’UEFA lors de la saison 2024-2025, à la suite du départ de Lionel Messi, Neymar da Silva Santos Júnior et Kylian Mbappé, trois des meilleurs footballeurs du monde, avant de conserver le titre cette saison. À maintes reprises, le monde du football a démontré à quel point des équipes très talentueuses peuvent décevoir, tandis que des équipes moins bien dotées dépassent souvent les attentes.
Nos recherches récentes remettent en cause l’idée reçue selon laquelle, en matière de stars, « en compter plus, c’est toujours mieux ».
En croisant les données de 1 750 matchs de 91 équipes dans cinq ligues de football, nous avons montré que la relation entre la proportion de joueurs vedettes et la performance de l’équipe dessine un U inversé. Au-delà d’un certain seuil, chaque star supplémentaire réduit la probabilité de victoire. Notre point de basculement : 60 % de stars dans l’effectif. Au-delà, la performance commence à décliner.
Dans notre étude, un joueur est considéré comme « vedette » s’il obtient une note FIFA video game moyenne ≥ 80/100 sur trois saisons consécutives. Ce seuil correspond aux 1 % les plus élevés parmi les 29 869 joueurs répertoriés dans la base de données, et à seulement 10 % des joueurs des cinq ligues étudiées. En matière de coût, leur valeur médiane de marché atteint 17,4 millions d’euros, contre 2,1 millions pour un joueur ordinaire, soit près de huit fois plus.
Circuit de passe
Ce qui fait vraiment la différence entre une bonne et une mauvaise équipe, ce n’est pas tant qui la compose, mais comment elle travaille ensemble. Pour ce faire, nous avons modélisé les circuits de passes de chaque match sous forme de matrices. Alors qui transmet le ballon à qui ?
Deux paramètres ont été mesurés :
la densité du « circuit de passe », c’est-à-dire le degré auquel les joueurs sont connectés les uns aux autres par des passes. Plus ce réseau est dense, plus on compte de joueurs qui échangent directement le ballon entre eux ;
sa centralité, soit le degré auquel le jeu se concentre autour d’un ou de quelques joueurs.
Ces paramètres ont ensuite été croisés avec la proportion de joueurs vedettes dans chaque équipe et le résultat du match. Conclusion : les clubs comptabilisant plusieurs vedettes obtiennent de moins bons résultats lorsque leur jeu repose sur un petit nombre de ces stars, alors que le reste de son effectif reste à l’écart. À l’inverse, les équipes dont le ballon circule entre tous les joueurs, sans revenir systématiquement aux mêmes, tirent mieux parti de leurs vedettes.
Densifiée et décentralisée
Par exemple, lors de la saison 2017–2018 de Bundesliga, le Bayern Munich alignait 71 % de joueurs vedettes. Grâce à un circuit de passes à la fois dense – où de nombreux joueurs s’échangent le ballon directement entre eux – et décentralisé – aucun joueur ne monopolise le jeu –, le club a battu 6-1 le Borussia Dortmund qui compte 43 % de vedettes.
A contrario, l’AS Roma – 50 % de vedettes –, dont le circuit de passe était trop centralisé autour de ses stars, a subi une défaite 1-3 face à l’Inter Milan – 36 % de vedettes.
Pour gagner, les équipes composées de stars doivent créer des circuits de passe où davantage de joueurs sont connectés les uns aux autres par des passes. Les quelques stars ne doivent pas monopoliser le jeu ; les joueurs de l’équipe doivent se relayer pour gérer le jeu. Ce schéma allège la pression sur chaque joueur et garantit que l’ensemble de l’équipe contribue à la performance collective.
Tactique de passe efficace
Nous avons également constaté que les équipes composées de seulement 25 % de stars, mais avec des tactiques de passes mieux organisés – moins denses, mais décentralisés, différents joueurs prenant tour à tour une part active au jeu plutôt que quelques joueurs monopolisant le ballon – pouvaient surpasser des équipes dotées d’un vivier de talents bien plus solide. Les premières affichent une probabilité de victoire de 35 % supérieure à ce que leur seul niveau de talent laissait prévoir – et battent même en probabilité des équipes composées à plus de 60 % de vedettes mal organisées.
La performance ne dépend pas uniquement du talent individuel, mais de la qualité des modes de collaboration au sein de l’équipe.
Nos recherches déplacent le regard du manager de la question du « qui » vers celle du « comment ». Sans modes de collaboration adaptés au profil de l’équipe et relations appropriées, même les équipes les plus talentueuses peuvent échouer. Ce changement de paradigme commence à s’imposer dans les organisations avant-gardistes. En sciences du management, le leadership est d’ailleurs de moins en moins conçu comme un rôle individuel ; il devient un processus collectif dans lequel les membres collaborent pour produire des résultats qu’ils ne pourraient pas réaliser seuls.
Qu’est-ce que les managers devraient faire différemment ?
Le talent ne garantit pas la performance
Les managers qui dirigent des équipes avec de nombreux talents – équipes de recherche et développement (R&D), comités de direction, groupes de travail transervsaux – s’exposent à des rendements décroissants, voire négatifs. Dans notre étude, le point de basculement est de 60 % de stars. Au-delà, la performance décline.
Ces équipes partagent avec les équipes de football une caractéristique décisive : l’interdépendance de leurs tâches. C’est précisément cette interdépendance qui détermine si le talent individuel se transforme en performance collective. Les équipes moins talentueuses peuvent obtenir de bons résultats, en jouant sur la qualité de leur organisation interne.
Par ailleurs, un joueur vedette coûte près de huit fois plus qu’un joueur ordinaire. Les ressources consacrées au recrutement de stars peuvent parfois être mieux employées à structurer la collaboration au sein de l’équipe existante.
Accroître les rendements collectifs
Les managers doivent aller au-delà de la simple acquisition d'employés dotés de talent et plutôt réfléchir activement à la manière de structurer la collaboration de leurs équipes afin d’améliorer le rendement collectif.
Notre étude suggère trois leviers concrets à activer :
réorganiser les tâches et les flux d’information pour créer des modes de collaboration adaptés au profil des employés ayant le plus de potentiel ;
établir ces configurations dès le début. Les analyses intramatch montrent une forte inertie des schémas de collaboration – une fois installés, ils persistent ;
surveiller activement ces fonctionnements tout au long de la vie du projet, pour éviter que des événements imprévus – départ d’un membre clé, succès ou échecs précoces – ne déstabilisent les schémas optimaux.
Les grandes équipes ne sont pas un simple assemblage de talents ; elles sont conçues pour créer des liens. Le talent n’est qu’un potentiel ; ce sont des modes de collaboration bien pensés qui le transforment en performance. Plutôt que de se livrer à la « guerre des talents », les managers gagneraient à orchestrer ce qu’ils ont déjà.
Cet article a été corédigé avec Andrew C. Loignon, chercheur senior au Center for Creative Leadership (États-Unis).
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
29.06.2026 à 11:10
La hausse des arrêts maladie est-elle la conséquence d’un problème de management ?
Gabriel Lomellini, Assistant Professor, HR and Organizational Behavior, ICN Business School
Texte intégral (1549 mots)
À partir du 1er septembre, la durée maximale d’une première prescription d’arrêt de travail sera plafonnée à un mois pour « contrer les abus et diminuer la facture » de 17,9 milliards d’euros de 2025. Ces absences pour raison de santé ne devraient-elles pas également être interprétées comme un signe de contestation d’un management ressenti comme vertical et contrôlées par les chiffres ?
Un récent baromètre Axa sur l’absentéisme a confirmé une tendance de fond : la hausse des arrêts maladie, en particulier de longue durée.
Si cette hausse concerne toutes les catégories sociales, elle touche principalement les jeunes de moins de 30 ans et les cadres. Plus généralement, parmi les arrêts longs, la première cause concerne les troubles psychologiques à 38 % en 2025, devant les troubles musculosquelettiques à 27 %.
Compte tenu du montant associé en 2025 aux arrêts maladie (environ 18 milliards d’euros), le gouvernement a annoncé une série de mesures se déployant selon un double volet : améliorer la qualité de vie au travail et contrôler les abus. Un décret fixe une durée maximale de 31 jours pour une première prescription et de 62 jours pour une prolongation.
Parmi ces mesures, on note un oubli majeur, celle de la question du management et de son rôle dans la santé au travail.
Au-delà de l’approche en termes de coûts, cette hausse doit interroger sur le rôle du management comme facteur de santé au travail, dans un contexte d’émergence de nouveaux risques liés à l’intelligence artificielle générative.
Pour ce faire, je m’appuie sur une approche transdisciplinaire, qui emprunte à la philosophie, la psychanalyse ou encore aux études critiques en management, ainsi que sur mes recherches sur l’expérience subjective du travail.
Tenir compte du travail réel
La santé au travail se situe à l’intersection de facteurs individuels et des pratiques de management. Dès les années 1960, le psychiatre et médecin du travail Claude Veil soulignait que l’absentéisme constitue un symptôme de l’état de l’organisation du travail. En matière d’absentéisme, écrit-il :
« Ce ne sont pas les données propres aux travailleurs qui jouent le plus grand rôle, mais bien des éléments qui dépendent de l’entreprise. »
Si le management joue un rôle si important dans la santé au travail, c’est qu’il détermine dans une large mesure les contraintes portant sur le travail réel, soit les tâches effectivement réalisées par un individu. Tenir compte du travail réel dans les pratiques de management est une condition indispensable pour effectuer un travail de qualité et préserver la santé des salariés.
Pour une infirmière, par exemple, un travail de qualité signifie plus que les conditions matérielles d’accueil et de soin. Écouter la personne à prendre en charge ou être en mesure de nouer un lien d’empathie contribue à un travail de qualité. Lorsque des pressions organisationnelles empêchent le travail réel – cadences impossibles ou objectifs trop élevés –, le risque est de basculer dans la souffrance.
Indicateur de l’état du management
L’arrêt maladie peut être interprété, sans toutefois s’y réduire, comme un certain indicateur de l’état du management. Depuis plusieurs années, un management encore très vertical et un contrôle par les chiffres fragilisent la santé sur les lieux de travail.
Le management reste en France particulièrement vertical et peu démocratique, ce qui restreint de fait l’autonomie individuelle et collective. Et si le recours massif au télétravail, au moment de la pandémie de Covid-19, a pu être vécu comme une prise d’autonomie de la part des salariés, le « retour au bureau », à l’inverse, a été ressenti comme une reprise du contrôle par le management.
Plus encore, les indicateurs chiffrés ont pris le pouvoir dans les organisations, évaluant le travail de manière individuelle. Bien que le management par les chiffres émerge à partir des années 1990 dans les entreprises privées, il ne s’y limite pas. Ce qu’on a appelé la New Public Management a étendu un ensemble d’outils de mesure de la performance dans les hôpitaux ou la fonction publique. Des mesures qui ont promu un « management désincarné », selon l’expression de la sociologue Marie-Anne Dujarier, à travers des indicateurs conçus à une très grande distance des réalités du métier et du vécu des salariés.
Réponse à l’exploitation ressentie
Par conséquent, la hausse des arrêts maladie interroge plus profondément sur l’affaiblissement des liens collectifs sur les lieux de travail. Comme le rappelle Pierre-Yves Gomez, chercheur en gestion :
« L’arrêt maladie illustre bien l’individualisation de la revendication sociale. Qu’il soit lié à la fatigue physique ou à la souffrance psychique, il traduit, comme toute forme de grève, le droit de suspendre son activité en réponse à l’exploitation ressentie par le travailleur. »
En sus de ces tendances de fond, le management se trouve percuté par le déploiement de l’intelligence artificielle. Un bouleversement qui implique d’être attentif à de nouveaux risques pour la santé.
Management par les algorithmes
En continuité d’un management par les chiffres, le « management algorithmique » s’est initialement déployé dans le cadre du capitalisme de plateforme, avec des entreprises comme Uber. Au sein de ces organisations, les algorithmes automatisent déjà une grande partie des tâches traditionnellement dévolues au management : évaluer, organiser ou distribuer le travail.
Les études soulignent que le management algorithmique peut contribuer à dégrader la santé des travailleurs. Les livreurs à vélo, ou encore les chauffeurs VTC, sont isolés face à la plateforme, coupés de leurs collègues, constamment évalués par des systèmes de notation, et sommés de s’adapter en temps réel à des algorithmes opaques et imprévisibles.
À lire aussi : Livreurs à domicile : comment le « management algorithmique » dégrade la santé des travailleurs
Des modalités de management qui se sont récemment étendues à des professions jusqu’ici protégées comme le journalisme ou encore des scénaristes hollywoodiens, ces derniers s’étant même mobilisés contre les risques qu’encourt leur profession.
Cerveau grillé
En dépit des promesses et espoirs suscités, ces technologies risquent non seulement de déqualifier le travail, certaines tâches devenant obsolètes, mais aussi de l’intensifier tant physiquement que mentalement. Certains cadres font état d’un sentiment de « brain fry », soit littéralement « cerveau grillé », du fait d’une utilisation intensive de l’IA au travail.
Face à cette combinaison de nouveaux risques, il est crucial d’adopter une approche holistique et préventive de la santé au travail. Dans une économie qui reste obsédée par la performance, les arrêts maladie doivent être interprétés comme un signe avant-coureur des tendances profondes du management et de notre rapport collectif au travail.
Gabriel Lomellini ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
28.06.2026 à 15:30
Clean beauty : comment une notion aussi floue est-elle devenue incontournable ?
Véronique Sadtler, Professeure, Université de Lorraine
Texte intégral (1663 mots)
Dans les rayons de cosmétiques, les promesses se multiplient : « naturel », « sans sulfate », « sans paraben », « 0 % silicone », « 95 % d’origine naturelle ». Ces mentions aujourd’hui omniprésentes sont devenues pour beaucoup de consommateurs des repères simples et rassurants face à des formulations souvent difficiles à décrypter. Mais que signifient-elles réellement ? Et comment une notion aussi floue que la « clean beauty » est-elle devenue en quelques années un argument majeur de l’industrie cosmétique ?
La question de l’exposition aux substances chimiques présentes dans les produits du quotidien fait régulièrement l’objet de travaux scientifiques. Une récente étude de l’Inserm a ainsi montré qu’une réduction temporaire de l’utilisation de certains produits cosmétiques et d’hygiène courants (shampooings, déodorants, dentifrices ou maquillage) pouvait entraîner une baisse mesurable de plusieurs polluants chimiques et perturbateurs endocriniens comme le bisphénol A.
Plus largement, les travaux consacrés aux perturbateurs endocriniens contribuent à alimenter les interrogations de la population sur les substances présentes dans les cosmétiques utilisés chaque jour. Les controverses régulièrement relayées dans les médias autour de certaines substances chimiques, ainsi que plusieurs procédures judiciaires récentes impliquant de grands groupes du secteur, entretiennent également ces débats dans l’espace public. Dans ce contexte, il n’est pas surprenant que la composition des produits soit devenue un critère de choix pour une part croissante des consommateurs.
C’est dans ce climat qu’a émergé la clean beauty. Apparue aux États-Unis dans les années 1990-2000 dans un contexte réglementaire beaucoup moins strict qu’en Europe, elle s’est progressivement diffusée à l’échelle mondiale. Les marques se sont à leur tour emparées de ces attentes, faisant de la clean beauty un argument central de communication. Cette tendance influence à présent l’ensemble du secteur cosmétique. Elle est souvent présentée comme l’une des grandes évolutions de l’industrie de la beauté au cours de la dernière décennie.
Cela témoigne d’un changement plus profond du rapport des consommateurs aux articles de soin et d’hygiène : au-delà de l’efficacité attendue, ils cherchent davantage à comprendre ce qu’ils utilisent au quotidien. Le succès de la clean beauty traduit ainsi un besoin croissant de réassurance. Face à des formulations complexes, beaucoup recherchent des repères plus simples pour guider leurs choix.
Une notion floue dans un secteur pourtant très réglementé
Mais derrière ce succès se cache un paradoxe. Contrairement aux labels ou certifications, la clean beauty ne repose sur aucune définition réglementaire harmonisée. Aucun texte européen ne définit ce qu’est une cosmétique « clean ». Chaque marque peut ainsi proposer sa propre interprétation : exclusion de certaines substances, limitation du nombre d’ingrédients, priorité donnée aux ingrédients d’origine naturelle ou encore mise en avant de procédés de fabrication particuliers.
Cette absence de définition contraste avec le niveau élevé de réglementation du secteur cosmétique européen. Les produits commercialisés en Europe font l’objet d’une évaluation de sécurité avant leur mise sur le marché. Plus de 1 300 substances y sont interdites et de nombreuses autres soumises à restriction.
On pourrait donc penser que ce cadre réglementaire répond déjà aux attentes d’un grand nombre de consommateurs. Malgré cela, les interrogations persistent. Les débats autour des perturbateurs endocriniens, des PFAS [13] ou de certaines substances classées CMR (cancérogènes, mutagènes ou toxiques pour la reproduction)) continuent d’alimenter les préoccupations de la population. Cette tension entre réglementation, perception du risque et attentes des utilisateurs apparaît également dans les débats récents autour du projet européen dit « Omnibus VI ». Présenté comme une simplification réglementaire, ce texte a suscité des inquiétudes chez plusieurs associations de consommateurs et organisations environnementales qui craignent un allongement des délais d’interdiction de certaines substances classées.
Quand la transparence ne suffit plus
On pourrait alors imaginer que la solution réside dans davantage d’informations. Après tout, la réglementation impose déjà une transparence importante. Tous les produits doivent afficher la liste complète de leurs ingrédients selon la nomenclature internationale INCI (International Nomenclature of Cosmetic Ingredients). La Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF) rappelle régulièrement l’importance de lire l’étiquetage complet des cosmétiques et souligne que les allégations doivent être vérifiables.
Cependant, transparence ne signifie pas nécessairement compréhension. Paradoxalement, les utilisateurs n’ont probablement jamais eu autant d’informations à leur disposition. Toutefois, entre les listes INCI, les allégations marketing, les labels et les différentes définitions de la naturalité, il reste souvent difficile de s’y retrouver.
Pour répondre à cette difficulté, certaines marques complètent désormais la liste INCI par des explications simplifiées indiquant l’origine ou la fonction des ingrédients (« agent nettoyant », « conservateur », « issu d’huiles végétales », etc.). Malgré cette abondance d’informations, de nombreux consommateurs peinent encore à interpréter des termes comme « clean », « naturel » ou « sans… », faute de définition harmonisée.
De plus, la liste INCI renseigne sur l’identité des ingrédients mais rarement sur leur origine ou leur mode d’obtention. Ainsi, certains composés parfumants, comme la vanilline, peuvent être obtenus par extraction végétale, biotechnologie ou synthèse chimique, sans que cette origine apparaisse dans leur nom. La notion de naturalité elle-même peut prêter à confusion : certains tensioactifs utilisés dans les shampooings et gels douche, comme les glucosides, sont fabriqués à partir de sucres et d’huiles végétales mais nécessitent plusieurs étapes de transformation chimique avant d’être incorporés dans une formule. Autrement dit, « naturel » ne signifie pas nécessairement « non transformé ».
Face à cette complexité, les applications, les labels et les mentions « sans… » jouent un rôle de simplification. Certaines bases de données et associations de consommateurs recensent désormais plusieurs milliers de cosmétiques contenant des ingrédients considérés comme indésirables ou controversés, contribuant à renforcer la vigilance du public vis-à-vis de la composition de ce qu’ils utilisent. Le « clean » devient alors autant un signal de confiance et de lisibilité qu’une caractéristique objective du produit lui-même.
Une promesse de simplicité face à la réalité des formulations
Reste une question essentielle : cette recherche de simplicité se traduit-elle réellement par des formulations plus simples ? Le shampooing illustre bien cette évolution, où les mentions « sans sulfates » ou « sans silicone » se sont largement diffusées ces dernières années. Or, concevoir un shampooing suppose de concilier nettoyage, stabilité, conservation, texture, mousse et sensorialité. La suppression d’un ingrédient nécessite de rééquilibrer l’ensemble de la formule et parfois de reprendre une partie du développement. La longueur d’une liste d’ingrédients ne constitue donc pas, à elle seule, un indicateur pertinent de qualité.
Au fond, les consommateurs ne recherchent pas uniquement des produits jugés plus naturels ou plus sûrs. Ils cherchent aussi à mieux comprendre ce qu’ils utilisent. C’est sans doute ce qui explique le succès de la clean beauty auprès d’un public confronté à des formulations de plus en plus complexes à décrypter.
Pourtant, derrière une liste d’ingrédients raccourcie ou une promesse de naturalité se cache souvent la même réalité : un cosmétique doit continuer à remplir les fonctions attendues par l’utilisateur. La clean beauty apparaît ainsi moins comme une catégorie scientifique clairement définie que comme une réponse à une demande de lisibilité, de transparence et de réassurance.
Véronique Sadtler ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
28.06.2026 à 15:30
Lutte contre les noyades : la sécurité de la baignade est une affaire de famille
Jeoffrey Dehez, Chargé de recherche en économie des loisirs et environnement, Inrae
Bruno Castelle, Directeur de Recherche CNRS, Université de Bordeaux
Sandrine Lyser, Ingénieure d’études en statistique, Inrae
Texte intégral (2005 mots)

En France, chaque année, les plus jeunes payent un lourd tribut à la noyade : celle-ci est la principale cause de mortalité par accident de la vie courante. Comment les adolescents appréhendent-ils ce risque ? Quel rôle leurs parents ont-ils à jouer ? Une nouvelle étude esquisse des pistes de réponses.
Les épisodes de canicule qui se succèdent mettent nos organismes à rude épreuve. Pour espérer en atténuer (un peu) les effets, la baignade apparaît comme une solution naturelle.
Pour tous ceux qui n’ont pas la possibilité de profiter d’une piscine (publique ou privée), la France regorge de plages, de rivières et de lacs susceptibles de répondre à cet impérieux besoin de fraîcheur.
Mais se baigner dans le milieu naturel n’est pas sans danger. Or, les adolescents semblent particulièrement exposés à ces risques, comme le révèle notre nouvelle enquête.
La vulnérabilité des adolescents face à la noyade
En France, la noyade est la première cause de mortalité par accident de la vie courante chez les moins de 25 ans : en 2016, elle comptait pour près d’un quart de ces décès (23 %, soit 135 décès sur 591 cette année-là. Pour les 13-25 ans, ces noyades ont principalement lieu en milieu naturel, autrement dit à la mer, dans des cours d’eau ou plans d’eau.
Plusieurs facteurs de risques sont généralement invoqués pour expliquer ce triste constat : des aléas mal connus par les adolescents (tels que les courants de baïne à l’océan), une appétence pour le risque, un excès de confiance en soi ou l’influence des pairs, particulièrement chez les garçons. Ce phénomène n’est pas propre à la France. On l’observe également en Australie, en Nouvelle-Zélande ou aux États-Unis.
Depuis plusieurs années, les adolescents sont ainsi devenus une priorité des politiques de prévention et de sensibilisation.
Or, si cette période de la vie s’accompagne effectivement d’une volonté de mise à distance des parents, il serait assez rapide de conclure à une totale autonomie des adolescents vis-à-vis de ces derniers. Face aux risques de baignade, les parents ont un rôle à jouer, à tous âges.
Une enquête auprès de collégiens
Pour tenter d’apprécier l’influence des parents dans la prévention des risques de baignade chez les adolescents, nous avons réalisé une enquête auprès d’un échantillon de collégiens, âgés de 11 à 15 ans, dans un établissement scolaire de la région bordelaise. Le collège en question et les zones d’habitation environnantes se situent à une heure de route environ des plages les plus proches de l’océan (soulignons qu’en l'état, les résultats peuvent difficilement être généralisés à une population plus large).
Nous avons demandé à 416 élèves de répondre à un questionnaire destiné à mieux connaître la nature de leurs activités à l’océan, ainsi que leur connaissance des règles de sécurité et des dangers. Ils ont également dû se projeter dans un scénario hypothétique décrivant une situation sur une plage non surveillée, en présence de camarades de leur âge, avec ou sans leurs parents présents sur place. Ils devaient indiquer, sur une échelle à cinq niveaux, la probabilité qu’ils se baignent, ainsi que le degré de risque perçu.
Une originalité du questionnaire est d’avoir été co-conçu avec un panel d’élèves du collège inscrits à l’option « sauvetage aquatique », afin d’améliorer sa compréhension par les autres enfants (ces élèves n’ont pas participé à l’enquête par la suite).
Une forte exposition au danger
En dépit de leur relatif éloignement géographique vis-à-vis de l’océan, plus de 9 adolescents sur 10 (92 %) ont déclaré s’y être rendus au moins une fois durant les douze derniers mois. Sur place, presque tous déclarent se baigner (98 %). Près des deux tiers (68 %) ont également indiqué s’être baignés au moins une fois hors des zones surveillées.
À peine plus de la moitié (52 %) des jeunes gens interrogés a été capable d’expliquer correctement la façon dont les zones de bain surveillées sont matérialisées (à l’aide de drapeaux rectangulaires jaunes et rouges).
Parmi les dangers de l’océan, les courants de baïne ont été cités par 64 % des collégiens interrogés, devant les vagues (36 %) et la marée (17 %). Sur les plages océanes du Sud-Ouest, cette dernière ne constitue pourtant généralement pas en elle-même un aléa. En effet, à l’exception du voisinage des embouchures, elle ne génère pas de courant important. Elle module en revanche l’activité des aléas : en moyenne, les courants de baïne sont plus intenses entre la marée basse et la mi-marée, et les vagues de bord sont plus violentes à marée haute.
Face à ces courants potentiellement dangereux, 34 % des jeunes ont répondu qu’il fallait faire la planche, tandis que 23 % seraient prêts à demander de l’aide aux surfeurs s’il y en a à proximité, et 20 % appelleraient à l’aide. Si chacune de ces réponses est pertinente, on peut toutefois regretter qu’elles ne soient pas citées par un plus grand nombre d’élèves…
L’avis des parents compte
Pour les jeunes adolescents interrogés, les parents demeurent un repère. Durant notre enquête, ils constituaient la principale source d’information vis-à-vis des dangers à l’océan, citée par 57 % des répondants, devant la télévision ou la radio (citées par 20 % des enquêtés), à égale position avec Internet et les réseaux sociaux (20 % de citations). L’école arrivait ensuite (avec 17 %). Les amis n’ont été mentionnés que par 8 % des répondants.
L’influence des parents se fait également sentir au travers des scénarios hypothétiques auxquels les collégiens ont été soumis. Ainsi, la probabilité de se baigner (hors d’une zone surveillée, rappelons-le) s’est révélée plus élevée – et le danger perçu, plus faible – lorsque nous indiquions que les parents étaient présents à la plage, par rapport à la situation où ils ne l’auraient pas été.
Cette influence des parents diminue au fur et à mesure que l’âge des répondants augmente. On constate par ailleurs que la propension à entrer dans l’eau est plus élevée chez les garçons.
Ces relations sont significatives sur un plan statistique, même si les raisons d’un tel résultat sont naturellement sujettes à discussions. Pour les adolescents, la présence des parents a pu être interprétée comme une autorisation de fait (« si les parents sont là, alors j’ai le droit d’y aller »).
En outre, au cours de nos précédentes études menées en Nouvelle-Aquitaine, une majorité d’adultes déclarait se baigner hors des zones ou des périodes surveillées. Il n’est donc pas impossible que les enfants aient eux aussi été influencés par ces comportements, s’ils accompagnaient leurs parents à ces occasions.
La sécurité, l’affaire de tous
Dans notre échantillon, une très large proportion de collégiens (66 %) ont déclaré avoir pris des cours de natation en dehors de l’école. Si l’acquisition de telles compétences est hautement recommandable, elle ne doit pas être perçue comme une assurance.
Une étude menée aux États-Unis a en effet mis en évidence que la vigilance des parents avait tendance à baisser dès lors qu’ils estimaient que leurs enfants savaient nager. Or, il faut bien comprendre que, dans le milieu naturel, la natation n’a plus vraiment de point commun avec ce qu’on l’on apprend en piscine. Le vent, les courants, les vagues ou l’absence de repères changent radicalement la donne.
En outre, si la confiance que les enfants ont en leurs parents est parfaitement légitime, d’autres travaux menés en Australie ont montré qu’au moins un quart des adultes présents sur la plage avaient leur attention monopolisée par autre chose que la surveillance des enfants.
Autre point essentiel : sauver quelqu’un de la noyade ne s’improvise pas. Chaque année, de nombreuses personnes décèdent en tentant d’en secourir une autre.
Pour cette raison, il reste impératif de se baigner dans des zones surveillées par des professionnels du sauvetage, y compris lorsque l’on est à la plage avec ses parents. La mise en place de ces zones en des lieux où la fréquentation est avérée est une mesure de santé publique, car interdire de se baigner est souvent vain.
Enfin, notre étude montre également que la sensibilisation aux risques de baignade ne doit pas se cantonner aux espaces côtiers : elle doit se déployer sur l’ensemble du territoire national. Il est important que la communication touche toute la sphère familiale, y compris les adultes.
L’environnement aquatique est une source immense de bien-être et de bienfaits pour tous, y compris les plus jeunes. Il est primordial de fournir aux adolescents d’aujourd’hui les meilleures clefs de compréhension pour en profiter en toute sécurité, afin que demain, ils se comportent en adultes responsables.
Les auteurs remercient Jean-François Téchené, enseignant et nageur-sauveteur, pour son soutien lors de la mise en place et la diffusion de l’enquête.
Jeoffrey Dehez est membre du groupe de recherche sur la sécurité de la baignade de l'Université de Nouvelles Galles du Sud, en Australie (University of New South Wales Beach Safety Research Group). Il a reçu des financements de la région Nouvelle Aquitaine.
Bruno Castelle et Sandrine Lyser ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
28.06.2026 à 15:29
Affaire Lyhanna : un ministre n’est-il pas responsable des fautes de son administration ?
Jeremy Martinez, Maître de conférences, droit public, Université Paris Dauphine – PSL
Texte intégral (2051 mots)
Le ministre de la justice Gérald Darmanin a refusé de démissionner après le meurtre de la jeune Lyhanna, malgré les dysfonctionnements graves relevés au niveau des magistrats du parquet. Le choix du garde des Sceaux s’inscrit dans la logique de la Vᵉ République, qui n’a eu de cesse de marginaliser la responsabilité des ministres, pourtant chefs de service de leur administration.
Rapidement après l’annonce du décès de la jeune Lyhanna dans des conditions terribles, les médias ont évoqué de nombreux dysfonctionnements de la chaîne pénale, policière comme judiciaire, qui ont incité les ministres de la justice, de l’intérieur et de l’éducation nationale à lancer une enquête administrative dont une première publication est intervenue le mardi 22 juin.
Ce « pré-rapport d’inspection de fonctionnement » conclut à un traitement défaillant de la part du parquet d’Auch et de la compagnie de gendarmerie de Condom. Les ministres de l’intérieur et de la justice ont pris des mesures conservatoires avant même la mise en œuvre d’une procédure contradictoire susceptible de mener à la révocation des fonctionnaires.
Le premier ministre Sébastien Lecornu a affirmé que la « puissance publique ne se défaussera pas » en faisant référence à la possibilité d’adopter des sanctions disciplinaires ainsi que plusieurs mesures législatives afin de mieux prévenir ces drames.
La position du Gouvernement repose donc sur un équilibre précaire : condamner individuellement des fonctionnaires négligents, tout en rejetant la responsabilité politique sur les ministres. Interrogé sur son avenir politique à la chancellerie, Gérald Darmanin a présenté des excuses en tant que garde des Sceaux, mais a refusé de démissionner, estimant que sa responsabilité politique n’était pas engagée.
Sans entrer dans l’opportunité politique d’un tel refus, une analyse constitutionnelle permet de comprendre le contexte de ce choix qui s’inscrit dans la logique du régime de la Vᵉ République, qui n’a eu de cesse de marginaliser la responsabilité politique individuelle des ministres. Nous pourrons alors mieux comprendre l’enjeu, ainsi que la difficulté soulevée par ces refus de démissionner.
Le contexte : un cadre constitutionnel lacunaire sur la responsabilité individuelle des ministres
La Constitution ne prévoit pas explicitement la démission individuelle des ministres. L’article 8 prévoit formellement que la cessation des fonctions d’un ministre n’intervient que lorsque le président de la République, sur proposition du premier ministre, l’a décidée.
Bien sûr, ce cadre juridique n’a pas empêché les ministres qui le souhaitaient de démissionner. Même si, en l’absence d’un cadre juridique clair, les motifs de départ sont très variés, il est possible de distinguer deux catégories principales de démissions individuelles depuis le début de la Vᵉ République.
La première concerne un désaccord politique. Par exemple, Aurélien Rousseau, ministre de la santé, a présenté sa démission en raison de son opposition à la loi sur l’immigration de 2023. La seconde concerne les ministres qui présentent leur démission en raison d’une affaire judiciaire.
Cependant, comme le rappelle l’affaire Lyhanna, il existe un motif de démission politique que les ministres tendent à exclure. Il concerne le refus d’un ministre d’assumer la responsabilité d’un dysfonctionnement grave au sein de son administration.
Le refus de démissionner du ministre en tant que chef de service
En effet, le garde des Sceaux Gérald Darmanin a écarté l’hypothèse d’une démission pour ce motif. Le ministre ne s’estime pas tenu pour responsable des défaillances administratives, dès lors que ses services auraient agi en contradiction avec les circulaires et les instructions qu’il avait données. En outre, Gérald Darmanin affirme que « le ministre de la justice ne peut rien faire », en raison de l’indépendance des magistrats, notamment du siège. On remarquera toutefois que, s’agissant de l’affaire Lyhanna, ce sont les magistrats du parquet, agissant sous l’autorité du ministre de la justice, qui sont principalement concernés. Gérald Darmanin évoque à cet égard l’impossibilité de donner des instructions individuelles, en vertu d’une loi de 2013 dite « loi Taubira ».
Le garde des Sceaux n’est pas le premier à s’être appuyé sur l’indépendance de son administration pour justifier une irresponsabilité politique. Le ministre de l’économie Bruno Le Maire a affirmé que certains services de Bercy (Direction générale du Trésor) étaient indépendants pour établir les prévisions de recettes fiscales qui déterminent l’équilibre budgétaire, et que, par conséquent, une erreur de leur part ne devait pas lui être imputable. Cette argumentation visant à écarter l’engagement d’une responsabilité politique est ancienne, car elle avait été énoncée par le premier ministre Lionel Jospin en 1999 à l’occasion de l’affaire des paillotes corses.
On peine à trouver un exemple de démission de ministres sous la Vᵉ République endossant les fautes de leurs services, à l’exception de celle, souvent citée, de Charles Hernu, ministre de l’intérieur en 1985, lors de l’affaire du Rainbow Warrior, qui a démissionné parce que des responsables de son ministère lui « [avaient] caché la vérité » (Le Monde, du 23 septembre 1985).
Ces refus successifs d’assumer une responsabilité ministérielle, en présence d’un grave dysfonctionnement des services, reposent sur une confusion entre responsabilité personnelle et responsabilité politique. En vertu de celle-ci, le ministre est responsable de l’action gouvernementale dans le champ de son ministère puisqu’il est le chef de service de son administration. Il peut donc être conduit à répondre des erreurs ou des dysfonctionnements de son administration, même lorsqu’il n’en est pas personnellement à l’origine, dès lors qu’il est l’autorité politique chargée d’exercer, dans ce domaine, le pouvoir de l’État. Encore plus, dans un régime parlementaire où, selon la formule de Georges Vedel, « le ministre fait écran entre le Parlement et les fonctionnaires » : il lui revient donc d’assumer politiquement les défaillances de son administration.
Ne pas confondre responsabilité politique et responsabilité pénale
Depuis longtemps maintenant, une large partie de la doctrine constitutionnelle s’alarme d’un défaut de responsabilité politique des ministres, car cette lacune semble avoir été compensée par ce qu’Olivier Beaud a qualifié de « criminalisation de la responsabilité des gouvernants », faisant référence au processus par lequel, à défaut de procédure de responsabilité politique, la voie pénale est mobilisée pour contester en creux des choix politiques.
De nombreux juristes ont dénoncé un risque de confusion entre les responsabilités politiques et pénales, et distingué des « erreurs politiques [qui] ne sauraient être assimilées à des fautes pénales ». Une faute pénale est, en principe, personnelle et intentionnelle, tandis qu’une erreur politique peut être générale et collective.
Depuis l’affaire du sang contaminé (O. Beaud, Le Sang contaminé. Essai critique sur la criminalisation de la responsabilité des gouvernants, 1999), on constate une augmentation de certaines plaintes déposées à l’encontre de ministres pour dénoncer l’adoption ou l’absence de décisions politiques sur le fondement d’une infraction pénale, par exemple, la mise en danger de la vie d’autrui (article 223-1 du Code pénal), ce qui peut poser une question brutale : « mal gouverner est-il un crime ? ». Les plaintes déposées contre plusieurs ministres de la santé pendant la crise du Covid en constituent une illustration significative.
Dans l’affaire Lyhanna, l’avocat de la partie civile a annoncé le dépôt de plusieurs plaintes sur ce fondement, non seulement contre le ministre de la justice devant la Cour de justice de la République, mais aussi contre les différents acteurs de la chaîne pénale, à savoir les enquêteurs et les magistrats devant une juridiction de droit commun.
La mise en cause personnelle des agents publics, ici des magistrats et des gendarmes, nous semble pouvoir être présentée comme une conséquence de la lente érosion de la responsabilité politique. Cette érosion tend à transférer la critique d’un dysfonctionnement institutionnel sur des responsabilités individuelles, en suggérant parfois une forme de partialité politique ou une défaillance personnelle des fonctionnaires concernés. Or, ces derniers agissent au nom de l’État et dans l’intérêt général, dans le cadre de fonctions qui dépassent leur seule personne.
Les décisions prises par ces fonctionnaires le sont en tant que magistrats ou gendarmes, et non en tant que personnes. Ce sont des administrateurs qui commettent d’abord des fautes de service, des actes impersonnels, et non des individus avec leurs « faiblesses, leurs passions, leurs imprudences » (Laferrière), même si, bien sûr, des fautes personnelles peuvent intervenir. Les magistrats et les gendarmes ont-ils eu l’intention de protéger Jérôme B. ? Doivent-ils être mis en cause pour des manquements professionnels ou personnels ?
En plaçant les projecteurs sur des défaillances personnelles, le refus d’un ministre d’engager sa responsabilité politique en présence d’un dysfonctionnement grave de son administration est susceptible de mettre en cause, au fond, l’équilibre même des institutions de l’État. Les répercussions de l’affaire Lyhanna replacent ainsi au cœur du débat public une question essentielle : celle de la responsabilité des gouvernants chargés de garantir le bon fonctionnement des services publics et la continuité des institutions de l’État.
Jeremy Martinez ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
28.06.2026 à 11:00
Derrière la mignonnerie du panda, une diplomatie d’influence chinoise de l’émotion en ligne
Zhao Alexandre Huang, Maître de conférences HDR en Sciences de l’Information et de la Communication, Laboratoire DICEN, Université Gustave Eiffel
Texte intégral (2403 mots)

Animal tardivement découvert par l’Occident, le panda géant est devenu au fil des décennies un symbole savamment construit par Pékin, bien plus politique que culturel. La séquence diplomatique de fin 2025 — marquée par le départ des pandas de Beauval et la visite présidentielle en Chine — a rappelé au grand public l’importance de cette mascotte. Sur les réseaux sociaux, la Chine utilise la puissance émotionnelle du panda pour tisser des liens affectifs avec l’audience mondiale. Une opération de charme numérique dont l’efficacité tient à un ressort psychologique universel, celui de l’attendrissement face aux traits juvéniles.
À la fin de l’année 2025, des pandas se sont imposés, contre toute attente, comme l’un des sujets visibles de la vie médiatique et diplomatique française. Cette attention est d’abord liée au départ du couple de Huan Huan et Yuan Zi, les deux pandas géants qui avaient vécu treize ans au ZooParc de Beauval avant de regagner la Chine le 25 novembre 2025. Motivé notamment par l’état de santé de Huan Huan, leur retour à Chengdu a suscité une forte émotion : cérémonies d’adieu, reportages nostalgiques, vidéos de fans et messages affectueux sur les réseaux sociaux ont rappelé que ces animaux étaient devenus de vraies célébrités en France et des symboles de la relation franco-chinoise.
Quelques jours plus tard, la visite d’État d’Emmanuel Macron en Chine, du 3 au 5 décembre, a replacé les pandas au centre du récit diplomatique. À Chengdu, Brigitte Macron a retrouvé Yuan Meng, premier panda né en France en 2019, et dont elle est la marraine. Parallèlement, la Chine annonçait un nouveau cycle de coopération avec la France autour du panda géant, avec l’arrivée prévue d’un nouveau couple à Beauval en 2027.
Derrière cette séquence apparemment attendrissante se pose pourtant une question centrale de communication internationale : comment un animal simplement perçu comme mignon, inoffensif et universellement aimable peut-il devenir une ressource stratégique de diplomatie publique et d’influence, notamment numérique ?
Un symbole politique réinventé par l’histoire
Contrairement à une idée largement répandue aujourd’hui, le panda géant n’a pas toujours occupé une place centrale dans l’imaginaire politique chinois. Les références à cet animal demeurent relativement rares dans les registres historiques et littéraires chinois, et sa découverte par le monde occidental ne remonte qu’à 1869, lorsque le missionnaire français Armand David en propose la première description scientifique.
Ce n’est qu’au XXe siècle que le panda acquiert une visibilité internationale croissante, avant d’être progressivement investi d’une fonction politique et diplomatique. Les premières utilisations diplomatiques du panda remontent à la République de Chine durant la Seconde Guerre mondiale. Un épisode fondateur se produit en 1941, lorsque le régime nationaliste dirigé par le Kuomintang souhaite remercier le gouvernement américain pour son soutien à la Chine dans la guerre de résistance contre l’invasion japonaise. Madame Chiang Kai-shek organise alors l’envoi aux États-Unis de deux pandas géants, Pan Dee et Pan Dah. Le choix de ces animaux comme présents diplomatiques s’explique notamment par la popularité qu’ils avaient déjà acquise auprès du public américain à la suite de leur introduction en Occident par Harkness et Tangier-Smith dans les années 1930 et 1940.
La République populaire de Chine, instaurée en 1949, reprendra cet héritage en l’inscrivant dans un projet idéologique plus large.
Dans les années 1950, les recherches zoologiques et paléontologiques consacrées au panda furent mobilisées pour illustrer les principes du « matérialisme dialectique », promouvoir une conception socialiste de la science et contribuer à la construction de symboles nationaux enracinés dans le territoire chinois. Le panda apparaît ainsi moins comme un symbole culturel immémorial que comme une construction politique relativement récente, associée à la légitimation scientifique, nationale et diplomatique du régime.
Depuis les années 1950, la diplomatie du panda — qui s’inscrit dans la stratégie maoïste de la diplomatie du peuple — est petit à petit mise en pratique par Pékin. Originalement, cette diplomatie animalière chinoise vise à offrir ou louer des pandas géants à des pays partenaires pour symboliser l’amitié et la coopération. La diplomatie du panda est devenue populaire après la visite du président Richard Nixon en Chine en 1972 : le gouvernement de Mao Zedong envoya alors un couple de pandas comme cadeaux d’État aux États-Unis pour symboliser le dégel des relations sino-américaines.
Les pandas géants sont très rapidement devenus des stars médiatiques du fait de leur apparence attendrissante de peluches et de leur comportement maladroit. Dès lors, la diplomatie du panda s’est progressivement transformée en une pratique représentative de la diplomatie publique à la chinoise.
À partir des années 2010, les autorités chinoises ont mis en place une politique invitant les entreprises à « sortir du territoire (zou chu qu, 走出去) », c’est-à-dire à chercher à s’étendre dans des pays étrangers. Dans ce cadre, les médias chinois ont reçu des subventions conséquentes pour internationaliser leurs pratiques journalistiques et communicationnelles.
La mise en pratique de cette politique a été largement facilitée par l’essor précoce de la numérisation de la diplomatie publique en Chine. Celle-ci a rapidement fait du panda un animal médiatique emblématique. Symbole de bienveillance par excellence, le panda incarne l’image apaisée et amicale que Pékin entend projeter sur la scène internationale, en particulier à travers les réseaux sociaux.
La néoténie, ressort biologique d’une stratégie d’influence
La réussite du panda comme star de la diplomatie publique chinoise n’est pas seulement due à sa rareté en tant que trésor national de la Chine ; elle émane surtout de son image. En effet, les caractéristiques physiques du panda correspondent à ce que l’on décrit des traits considérés comme mignons. Selon l’éthologiste Konrad Lorenz, ces traits mignons correspondent à une néotonie (kindchenschema), terme qui désigne un ensemble de caractéristiques physiques juvéniles qui déclenchent chez l’humain une réaction émotionnelle positive face à ce qui est perçu comme mignon ou attendrissant.
Ce schéma de néotonie se manifeste par des caractéristiques physiques telles qu’un front haut et bombé, une tête disproportionnellement grande, un visage arrondi, de grands yeux, des joues pleines, ainsi que des membres courts ou épais. Quand ces éléments sont mobilisés, ces déclencheurs qualifiés de supra-naturels pourraient activer, entretenir et renforcer un sentiment d’attendrissement et de tendresse chez l’humain.
Enfin, cette néotonie favoriserait aussi le déclenchement de mécanismes innés, comme ceux consistant à exprimer ses émotions et, chez les adultes, à protéger les êtres jugés faibles et juvéniles. Dans ce cadre, bien que potentiellement dangereux, le panda incarne une figure hautement attachante : son visage rond, les cercles noirs entourant ses yeux, son allure pataude et ses mouvements maladroits contribuent à façonner une image attendrissante et inoffensive.
Le panda, visage bienveillant de la Chine
Dans ce contexte, une série d’enquêtes sur la diplomatie numérique du panda est menée depuis 2019 (voir ici, ici, ici ou encore ici. L’objectif est d’étudier la façon dont les autorités de Pékin utilisent les comptes Twitter (actuellement X) de leurs médias nationaux, dont l’agence de presse Xinhua, le journal Le Quotidien du Peuple ou encore la chaîne de télévision CGTN pour mettre en scène la diplomatie du panda.
Cette série d’enquêtes empiriques conduit à une conclusion éclairante. Loin d’être anodin et innocent, le contenu publié par Pékin sur Twitter sur le thème du panda revêt une dimension profondément politisée dans le cadre de la diplomatie numérique chinoise. À partir d’une analyse fine du discours et du contenu visuel de tous les tweets collectés, nous avons mis en évidence un double objectif stratégique de ces contenus sur le panda, d’apparence purement ludique et anodine.
Tout d’abord, ils se mettent au service de la diffusion du discours officiel chinois sur la scène internationale de manière subtile. Chaque fois qu’un événement diplomatique impliquant un panda se produit — par exemple la naissance d’un bébé panda dans un zoo étranger ou la célébration de l’anniversaire d’un panda loué à l’étranger, etc. —, les médias chinois en profitent pour rappeler les messages politiques de Pékin. Il s’agit soit de l’amitié sino-étrangère et de la coopération gagnant-gagnant, soit du rôle de la Chine comme puissance bienveillante et défendant la paix. Un tweet typique de ce type de message politisé est d’associer une photo attendrissante de panda à un commentaire qui souligne les bonnes relations entre la Chine et tel pays, ou à une déclaration d’un dirigeant chinois sur la coopération internationale.
Ensuite, ces tweets au sujet de pandas visent à accumuler du capital sympathie pour la Chine. Grâce à son attrait universel, le panda est devenu un vecteur d’émotion positive particulièrement efficace. Les médias chinois exploitent à fond ce filon en publiant massivement sur Twitter des photos attendrissantes, des vidéos amusantes, ou encore des images mouvantes (gifs) animées de pandas joueurs. Ces contenus visuels permettent d’accroître l’attractivité de la Chine par un placement stratégique d’images accompagnées d’un récit présentant le pays de façon positive (par exemple, « Les pandas géants enchantent les visiteurs du monde entier dans la base de Chengdu »). Autrement dit, grâce à cette mascotte vivante, la Chine cherche à mettre en œuvre une stratégie de nation branding ludique.
Comme nous l’avons formulé ailleurs, « l’image universelle du panda aide Pékin à surmonter les énormes difficultés de langue, de politique et de culture » dans [sa communication internationale]. Même sans comprendre le chinois ni avoir d’affinités particulières avec la Chine, les internautes peuvent être touchés par une vidéo ou une image attendrissante de panda et, inconsciemment, associer ce sentiment positif à l’image de la Chine elle-même. C’est une manière douce et « apolitique » d’influencer les perceptions.
Ce travail a été réalisé dans le cadre du projet PubDiplo, cofinancé par l’Agence nationale de la recherche (ANR) et le Research Grants Council (RGC) de Hongkong (Références : ANR-25-CE41-4061/RGC-A-HKBU203/25).
Ce travail a été réalisé dans le cadre du projet PubDiplo, cofinancé par l’Agence nationale de la recherche (ANR) et le Research Grants Council (RGC) de Hong Kong (références : ANR-25-CE41-4061 / RGC-A-HKBU203/25).
28.06.2026 à 11:00
Quelles mesures sont les plus efficaces contre la dermatose nodulaire ? Ce que disent les modèles épidémiologiques
Clara Delecroix, Epidémiologiste spécialisée dans la modélisation mathématique des maladies infectieuses, Inrae
Gaël Beaunée, Chercheur en épidémiologie spécialisé dans la modélisation mathématique des maladies infectieuses, Inrae
Stéphane Bertagnoli, Professeur spécialisé en pathologie infectieuse-virologie à l'Ecole Nationale Vétérinaire de Toulouse - UMR INRAE-ENVT 1225 IHAP, École Nationale Vétérinaire de Toulouse
Timothée Vergne, Épidémiologiste et maitre de conférences en santé publique vétérinaire à l'école Nationale Vétérinaire de Toulouse, UMR ENVT-INRAE « Interactions Hôtes-agents pathogènes », Inrae
Texte intégral (2924 mots)
En 2025, de nombreux cas de dermatose nodulaire contagieuse, ou DNC, bovine ont déferlé sur les élevages français. Pour y faire face, les autorités ont alors misé sur la vaccination d’urgence et l’abattage total des cheptels touchés. Aurait-on pu gérer différemment cette épizootie, par exemple en n’abattant que les animaux malades ? Les modèles épidémiologiques permettent de répondre à cette question.
Alors que la dermatose nodulaire contagieuse (DNC) bovine continue de s’étendre au sud de l’Europe, par exemple en Sardaigne, aucun nouveau cas n’a été détecté en France depuis le 2 janvier 2026. Une accalmie qui fait suite à des mesures sanitaires combinant vaccination en urgence et abattage des troupeaux contaminés.
Les premiers cas de DNC en France ont été été décelés en juin 2025 dans des élevages de bovins localisés en Savoie, puis dans la région Auvergne-Rhône-Alpes. Dès octobre 2025, les cas ont gagné d’autres régions (Bourgogne-Franche-Comté et Occitanie), faisant craindre une épizootie de grande ampleur.
Cette maladie, qui a provoqué une grave crise sanitaire dans sept pays des Balkans entre 2015 et 2017, n’avait alors encore jamais été détectée en France. Elle fait partie des cinq maladies bovines les plus graves classées catégorie A par l’Union européenne (UE) – c’est-à-dire, maladie habituellement absente de l’UE contre laquelle des mesures d’éradication immédiate doivent être prises.

{kind=link}
La DNC est causée par un virus transmis entre bovins par l’intermédiaire d’une mouche piqueuse présente en grand nombre dans les étables, Stomoxys calcitrans. Du fait de l’interruption de leur repas sanguin par les bovins gênés par les piqûres, ces mouches peuvent piquer plusieurs bovins successivement et transmettre le virus d’un animal à l’autre. La propagation du virus au sein d’un élevage est donc très rapide et difficilement maîtrisable.
Face à cette situation, le gouvernement a mis en œuvre une stratégie de gestion combinant abattage total des troupeaux infectés (dépeuplement) et vaccination d’urgence autour des foyers. Bien qu’efficace pour maîtriser l’épizootie en quelques mois, cette approche a suscité une forte contestation du monde agricole.
Une des alternatives proposées par cette contestation consistait à réaliser un dépistage régulier de l’ensemble des bovins d’un élevage infecté, suivi de l’euthanasie des seuls animaux identifiés comme infectés.
Mais cette alternative, appelée « dépeuplement sélectif », est-elle vraiment réaliste ? Permet-elle de maîtriser efficacement la propagation du virus au sein d’un élevage ainsi qu’aux élevages voisins ? Nous avons mené des travaux de modélisation épidémiologique qui permettent de répondre à cette question.
Modéliser la transmission dans un élevage
Nous avons tout d’abord élaboré un modèle dit « mécaniste » de transmission du virus dans un troupeau de 100 bovins. Un modèle mécaniste est un modèle mathématique qui reproduit les mécanismes de transmission en les décomposant en processus élémentaires, qui sont ensuite transcrits sous forme mathématique afin de simuler la transmission de la maladie dans différentes situations.

Grâce à différents échanges avec des spécialistes de la maladie, nous avons pu mettre au point un modèle mathématique de la propagation de la DNC. Nous avons ainsi retenu les éléments suivants :
la transmission ne peut se faire que par l’intermédiaire des mouches piqueuses ;
une mouche qui pique un bovin infecté a 22 % de chances de se contaminer si le bovin est symptomatique et 0,6 % s’il est asymptomatique ;
l’infection d’un bovin survient pour environ 5 % des piqûres par des mouches contaminées ;
environ la moitié des bovins infectés finissent par développer des signes cliniques ;
enfin, les mouches peuvent piquer jusqu’à 20 bovins par jour.
La plupart de ces hypothèses sont tirées de données issues d’expériences de laboratoire reproduisant les conditions de transmission de manière contrôlée.
Les simulations réalisées à partir de ce modèle ont montré qu’une vache infectée en infectera en moyenne 19 autres, par l’intermédiaire des piqûres de mouches qui se sont nourries sur elle. Cela correspond à un « nombre de reproduction de base » (R0) de 19, soit une transmission initiale très rapide. Pour comparaison, le R0 de la Covid-19 était estimé entre 1,4 et 6,5 selon les souches.
Sans intervention, un troupeau de 100 bovins a donc 91 % de probabilité de se retrouver entièrement infecté sous environ 51 jours. Ces estimations sont cohérentes avec les quelques observations de terrain rapportées dans la littérature scientifique.
Aurait-il fallu privilégier le dépeuplement sélectif ?
Que dit ce modèle de l’efficacité des stratégies de lutte contre le virus mises en place dans les élevages ? Celles-ci ont été au cœur de la controverse : des rumeurs selon lesquelles l’abattage partiel aurait été préférable à l’abattage total mis en œuvre par les autorités se sont rapidement diffusées. Est-ce vraiment le cas ?
Afin de pouvoir conclure, nous avons ajouté à notre modèle de transmission de la DNC une stratégie de dépeuplement sélectif des animaux infectés. L’enjeu : comprendre si elle permet ou non de réduire la transmission au sein du troupeau.
Nous avons considéré que ce dépeuplement était mis en place à partir du moment où le premier animal infecté symptomatique apparaissait, ce qui, d’après les simulations du modèle, prend en moyenne 13 jours, avec une grande variabilité selon que le premier infecté du troupeau finisse par présenter des signes cliniques ou non.

Au moment de l’apparition du premier cas symptomatique, le modèle prédit qu’entre une (au minimum) et sept (au maximum) vaches sont déjà infectées et qu’entre 0 et 74 mouches sont déjà contaminées.
Le modèle a ensuite permis de simuler la mise en œuvre d’un dépistage de l’ensemble du troupeau tous les deux jours. On considère que, lors de ce dépistage, les animaux testés positifs sont immédiatement euthanasiés et retirés du troupeau. Les tests diagnostiques étant imparfaits, le modèle suppose par ailleurs qu’un animal infecté mais asymptomatique n’a qu’une probabilité de 30 % d’être détecté positif lors d’un test.
Outre les contraintes logistiques et budgétaires qu’une telle stratégie engendrerait, nos simulations suggèrent que le troupeau finirait par être intégralement infecté malgré tout. Ceci tient au délai séparant l’introduction du virus de la détection du premier cas, à la présence d’animaux asymptomatiques non détectés qui continuent à contaminer des mouches et d’un très grand nombre de mouches qui restent contaminées malgré l’abattage des bovins testés positifs.
Ces résultats ne s’appliquent toutefois qu’aux troupeaux non vaccinés contre le virus de la DNC. Dans un contexte vaccinal, la transmission du virus est réduite si les animaux ont eu le temps de développer leur immunité. Le dépeuplement sélectif pourrait-il être pertinent dans ce nouveau contexte vaccinal ?
Des travaux de modélisation sont en cours pour déterminer dans quels scénarios le dépeuplement sélectif, conjugué à la vaccination, sera suffisamment efficace pour contenir la propagation du virus. En effet, le modèle doit être complexifié pour prendre en compte de nouveaux paramètres : combien d’animaux ont été vaccinés dans le troupeau (couverture vaccinale), quelle proportion est réellement protégée (efficacité vaccinale) et combien de temps il faut pour qu’un animal vacciné soit effectivement protégé.
À lire aussi : Dermatose nodulaire contagieuse : les vétérinaires victimes d’une épidémie de désinformation
De l’intérêt des modèles pour l’aide à la prise de décision en santé animale
Cette démonstration rappelle l’intérêt des modèles épidémiologiques pour évaluer l’efficacité attendue de différentes stratégies de gestion envisagées par les autorités, dans un contexte où il n’est pas possible de tester expérimentalement chacune d’elles.
À ce titre, ils constituent un outil d’aide à la décision précieux, qui permet de simuler les conséquences probables des différentes options. Il faut toutefois garder en tête qu’ils ne proposent que des approximations de ce qui se passera en réalité, et qu’ils ne sont utiles que dans la mesure où les hypothèses qui les ont construits sont fiables.
Il est donc crucial de s’appuyer sur une collaboration entre acteurs de terrain (vétérinaires, éleveurs, administrations locales), chercheurs et laboratoires pour intégrer les principaux mécanismes de transmission du virus et reproduire le plus finement possible dans les simulations les dynamiques observées sur le terrain. C’est cette démarche qui permet d’évaluer l’impact de scénarios alternatifs de gestion de l’épizootie.
Il n’existe toutefois pas de stratégie optimale de façon universelle : le choix des mesures à mettre en œuvre dépendra à la fois des objectifs poursuivis et du contexte dans lequel l’épizootie survient.
Les objectifs peuvent consister à retrouver le plus rapidement possible le statut de pays indemne afin de rétablir les exportations, à limiter les pertes économiques ou encore à réduire le nombre d’animaux abattus. L’efficacité et la pertinence des mesures dépendront également des caractéristiques locales, telles que le type d’élevage, l’organisation de la filière ou encore les conditions environnementales, qui influencent la transmission de la maladie et les possibilités de mise en œuvre des mesures de contrôle.
À la suite des mesures mises en place, aucun nouveau cas de dermatose nodulaire contagieuse n’a été détecté en France depuis le 2 janvier 2026. En cas de réémergence, il faudra désormais tenir compte d’un nouveau contexte, marqué par une population bovine partiellement vaccinée.
À lire aussi : Dermatose nodulaire : comment faire évoluer les dispositifs de gestion sanitaire ?
Clara Delecroix a reçu des financements de l'Agence nationale de la recherche (ANR).
Gaël Beaunée a reçu des financements de l'Agence nationale de la recherche (ANR).
Stéphane Bertagnoli a reçu des financements de l'Agence nationale de la recherche (ANR).
Timothée Vergne a reçu des financements de l'Agence nationale de la recherche (ANR).
28.06.2026 à 10:59
Robin des Bois était bien plus violent que la légende ne le raconte
Alex Brown, Associate Professor of Medieval History, Durham University
Texte intégral (1939 mots)

Bien avant Hollywood, les légendes anglaises mettaient en scène des hors-la-loi capables des exploits les plus héroïques… et des violences les plus extrêmes. Pourquoi Robin des Bois est-il le seul à être entré dans la mémoire collective ?
Deux événements liés à Robin des Bois ont récemment remis le célèbre hors-la-loi médiéval sous les projecteurs : la sortie le 1er juillet de On l’appelait Robin des Bois (The Death of Robin Hood en VO), avec Hugh Jackman dans le rôle-titre, et l'annonce de la disparition du « Major Oak », le chêne emblématique de la forêt de Sherwood que la légende présente comme l'une des cachettes du célèbre bandit.
Mais pourquoi Robin des Bois est-il connu dans le monde entier, alors que les noms des autres hors-la-loi du Moyen Âge sont, pour la plupart, tombés dans l'oubli ?
La première mort littéraire de Robin des Bois survient de manière assez expéditive dans A Gest of Robyn Hode, un récit de la fin du XVe siècle, lorsque la prieure de Kirklees le tue à la suite d'une tentative de saignée qui tourne mal. Cette fin a en partie inspiré la vision plus sombre du héros proposée par le réalisateur Michael Sarnoski dans On l’appelait Robin des Bois.
Si les premiers récits consacrés à Robin des Bois n'associent pas explicitement le hors-la-loi au « Major Oak » de la forêt de Sherwood, ils montrent en revanche Robin et ses compagnons se retrouvant régulièrement sous un « trystle », c'est-à-dire un arbre servant de lieu de rendez-vous. Il est facile d'imaginer comment ces légendes ont fini par se cristalliser autour d'un arbre aussi remarquable que le chêne de Sherwood.
Bien loin du Robin des Bois de Disney
Les compagnons d'infortune médiévaux de Robin des Bois sont aujourd'hui largement tombés dans l'oubli. Qui connaît encore les exploits de Fulk FitzWarin, de Hereward the Wake, d’Eustace le Moine, de Gamelyn, ou encore d’Adam Bell, Clim of the Clough et William Cloudesley ?
Si Robin des Bois a traversé les siècles, c'est en partie parce que chacun pouvait voir en lui le héros qu'il souhaitait., séduisant des publics très variés au sein de la société médiévale. Sa légende a toujours été malléable, y compris dans ses premières versions, et le héros a été réinventé à chaque nouvelle adaptation.

{kind=link}
Le Robin des Bois des premiers récits qui nous sont parvenus diffère sensiblement de celui des adaptations modernes. On n'y trouve notamment aucune histoire d'amour avec Marianne. Le hors-la-loi est au contraire profondément dévoué à la Vierge Marie. Par amour pour elle, il refusait de faire du mal aux femmes.
Robin récompense l'honnêteté et combat la corruption, mais sans s'inscrire dans une opposition de classes aussi nette qu'on pourrait l'imaginer. Bien qu'il soit dit qu'il faisait « beaucoup de bien aux pauvres », il ne distribue pas d'aumônes aux paysans. Il prête plutôt de l'argent à un chevalier honnête mais ruiné par le mauvais sort.
Robin des Bois est aussi capable d'une violence surprenante. Si les scènes de violence des premiers récits sont souvent traitées sur un mode comique, certaines histoires révèlent une facette bien plus sombre du personnage. Après avoir affronté Guy de Gisborne, par exemple, Robin le décapite, plante sa tête au bout de son bâton d'arc et mutile son visage afin que personne ne puisse l'identifier. C'est cette version plus brutale et tourmentée de Robin des Bois que le personnage incarné par Hugh Jackman entend faire revivre.
Les hors-la-loi médiévaux tombés dans l'oubli
Il est difficile de faire l'éloge des véritables hors-la-loi de l'Angleterre médiévale, tant leur existence fut marquée par une violence qui heurte les sensibilités contemporaines. Les véritables bandes de hors-la-loi, comme les Coterels et les Folvilles du début du XIVᵉ siècle, se rendaient coupables de nombreux vols, meurtres et enlèvements, tout en pratiquant le racket et l'extorsion. La réputation des Folvilles était telle que leur forme expéditive de justice est devenue connue en Angleterre sous le nom de « loi des Folville ».
Pourtant, d'autres récits mettant en scène des hors-la-loi légendaires circulaient dans l'Angleterre médiévale. L'un d'eux, Adam Bell, Clim of the Clough and William Cloudesley, raconte les aventures de trois hors-la-loi de la forêt d'Inglewood, dans le nord-ouest de l'Angleterre. Les trois héros sont mis hors la loi pour avoir braconné, un crime qui suscitait probablement la sympathie d'une grande partie des classes populaires.
Après avoir été déclaré hors-la-loi, William Cloudesley se faufile dans la ville de Carlisle pour retrouver sa femme et leurs trois jeunes enfants. Trahi puis assiégé, il est défendu par Alice, sa « fidèle épouse légitime », qui saisit une hache pour protéger la porte d'entrée pendant que William décoche ses flèches sur les hommes du shérif venus l'arrêter. Le shérif finit par incendier leur maison, mais William parvient à retenir ses assaillants suffisamment longtemps pour permettre à sa famille de s'enfuir par une fenêtre.
Lorsque la corde de son arc est détruite par les flammes, William est finalement capturé et condamné à la pendaison, tandis que la ville de Carlisle est placée sous haute surveillance. C'est alors qu'intervient le porcher de la ville, un jeune garçon qui parvient à s'échapper pour prévenir les deux autres hors-la-loi, Adam et Clim, de la capture de William. Ceux-ci organisent un spectaculaire sauvetage au pied de la potence, digne d'une scène de Robin des Bois, prince des voleurs. Au cours de leur fuite, ils tuent ensuite 300 représentants de l'autorité.
En quête d'une grâce royale, William démontre alors son incroyable talent d'archer en décochant une flèche qui atteint une pomme posée sur la tête de son fils de sept ans, dans un final qui rappelle la légende de Guillaume Tell.
C'est donc en William Cloudesley que s'exprime le plus pleinement la fierté des archers du « Nord de l'Angleterre ». C'est à travers Alice que se dévoile le destin difficile de l'épouse d'un hors-la-loi. C'est dans le personnage du jeune porcher que s'incarnent les liens de solidarité propres au banditisme social. Et c'est enfin dans la relation entre les trois compagnons que se manifeste l'idéal d'une camaraderie héroïque, lorsque, encerclé de toutes parts par les hommes du shérif de Carlisle, William lance à ses frères d'armes : « En ce jour, vivons et mourons ensemble. »
Ces scènes sont depuis longtemps devenues indissociables de la légende de Robin des Bois. Pourtant, beaucoup d'entre elles n'y trouvent pas leur origine. Elles sont apparues pour la première fois dans les aventures de trois hors-la-loi aujourd'hui largement oubliés de la forêt d'Inglewood.
Il est peut-être temps de les sortir de l'immense ombre de Robin des Bois et, ce faisant, de redécouvrir la richesse et la diversité des récits consacrés aux hors-la-loi de l'Angleterre médiévale.
Alex Brown a reçu des financements du Leverhulme Trust dans le cadre du projet de recherche « Modelling the Black Death and Social Connectivity in Medieval England » (« Modéliser la peste noire et les réseaux sociaux dans l'Angleterre médiévale »).
28.06.2026 à 10:59
Comment une dent de chèvre éclaire enfin les secrets de l’élevage dans la Grèce antique
Flint Dibble, Marie-Sklowdowska Curie Research Fellow, School of History, Archaeology and Religion, Cardiff University
Texte intégral (2845 mots)

{kind=link}
En analysant les restes de 50 moutons et chèvres découverts en Crète, des archéologues montrent que l’élevage de la Grèce antique était bien plus complexe qu’on ne le pensait. Une découverte qui éclaire le fonctionnement économique et politique des premières cités grecques.
**
L’agriculture était le moteur de la prospérité de la Grèce antique. La nourriture occupait une place centrale dans la vie sociale, qu’il s’agisse des symposiums où quelques convives partageaient du vin ou des immenses festins sacrificiels réunissant toute une communauté. Dans l’Odyssée, le poème épique de la Grèce antique, le fils d’Ulysse participe à l’un de ces banquets hors normes : un gigantesque barbecue collectif où une centaine de bovins sont sacrifiés.
Les chercheurs savent depuis longtemps que l’alimentation jouait un rôle central dans l’économie, la politique et la vie sociale de la Grèce antique. Mais une question fondamentale restait sans réponse : comment les animaux étaient-ils réellement élevés pour nourrir cette société ?
Depuis près d’un siècle, les chercheurs sont engagés dans un débat sur l’organisation de l’élevage dans la Grèce antique. Deux modèles s’opposent. Selon le premier, de grands troupeaux semi-nomades parcouraient le territoire au gré des saisons à la recherche de pâturages. Selon le second, les animaux étaient élevés en petits troupeaux intégrés aux exploitations agricoles, où ils se nourrissaient des ressources locales et des résidus des cultures. En d’autres termes, l’élevage reposait-il sur un système pastoral mobile ou sur des fermes associant étroitement cultures et bétail ?
Avec une équipe pluridisciplinaire réunissant archéologues et scientifiques, j’ai analysé l’un des plus importants ensembles de restes animaux jamais mis au jour dans le monde grec antique, sur le site d’Azoria, en Crète, afin d’apporter de nouveaux éléments à ce débat. Nous avons publié nos résultats dans un article récent.
Lorsque les premiers historiens se sont penchés sur la manière dont les animaux étaient élevés et les cultures pratiquées dans la Grèce antique, le paysage grec était encore marqué par la présence de grands troupeaux de moutons et de chèvres conduits par des groupes semi-nomades. Ces troupeaux migraient des pâturages d’altitude en été vers les plaines en hiver, à la recherche de ressources saisonnières.
Dans son ouvrage The Geography of the Mediterranean Region : Its Relation to Ancient History (« La géographie de la région méditerranéenne : ses liens avec l’histoire antique », non traduit), la géographe américaine Ellen Churchill Semple fut la première à avancer que ce mode d’élevage saisonnier existait déjà dans la Grèce antique.

Une autre école de pensée défend toutefois un modèle très différent de l’économie agricole. S’appuyant sur des entretiens menés auprès de bergers et d’agriculteurs âgés, l’archéologue Paul Halstead soutient, dans plusieurs articles ainsi que dans son livre de 2014, Two Oxen Ahead. Pre-Mechanized Farming in the Mediterranean (« Deux bœufs en tête : l’agriculture méditerranéenne avant la mécanisation », non traduit), que les animaux étaient principalement élevés en petits troupeaux rattachés aux exploitations agricoles. Ils paissaient surtout sur les jachères ou les pâturages voisins, ou étaient nourris avec des cultures fourragères spécialement produites à leur intention. Dans ce modèle, cultures et élevage formaient un système étroitement intégré.
Au fil des décennies, les chercheurs se sont rangés dans l’un ou l’autre camp de ce débat. Mais jusqu’à récemment, il était impossible de mesurer directement le régime alimentaire et la mobilité des animaux de la Grèce antique, et donc de trancher la question.
Quand la science éclaire l’histoire
Le recours à l’analyse des isotopes stables – une technique qui mesure différentes formes d’un même élément chimique, appelées isotopes, dont la masse varie légèrement – offre pour la première fois aux chercheurs la possibilité de départager ces deux hypothèses à partir des restes d’animaux découverts sur des sites de la Grèce antique.
En analysant le mélange d’isotopes conservé dans les os et les dents anciens, les scientifiques peuvent reconstituer le régime alimentaire d’un animal ou d’un être humain, mais aussi obtenir des indices sur les lieux où il a vécu. En effet, les aliments et l’eau laissent des signatures chimiques qui s’enregistrent progressivement dans les tissus de l’organisme.
Les atomes d’un même élément peuvent exister sous plusieurs isotopes, qui se distinguent par leur masse en raison d’un nombre différent de neutrons. En analysant les proportions de ces différents isotopes dans les vestiges archéologiques, l’analyse des isotopes stables permet d’identifier les sources – alimentation, eau ou air – qui ont contribué à la composition chimique d’un animal (ou d’un être humain).

Les rapports entre les isotopes du carbone et de l’azote renseignent sur le type d’alimentation des animaux de l’antiquité. Ceux des isotopes stables de l’oxygène révèlent, quant à eux, les variations saisonnières enregistrées lors de la formation de l’émail des dents. En combinant ces différentes analyses isotopiques, les chercheurs peuvent s’attaquer directement au débat sur l’agropastoralisme et reconstituer le régime alimentaire saisonnier des animaux.
Les premières applications de ces techniques aux animaux de la Grèce antique n’ont toutefois fait que compliquer le tableau. En raison du coût des analyses et du nombre limité d’échantillons disponibles, seuls quelques animaux ont pu être étudiés sur des sites tels que Cnossos, en Crète, ou Argilos, dans le nord de la Grèce. Les résultats n’ont pas confirmé un modèle unique, mais mis en évidence une diversité de pratiques d’élevage. La faible taille des échantillons ne permettait cependant pas de tirer des conclusions solides, si ce n’est que les animaux de la Grèce antique étaient élevés selon une combinaison de différentes méthodes agricoles. Restait à comprendre comment cette diversité s’inscrivait dans le fonctionnement global de l’économie antique.
Notre étude, menée sur le site d’Azoria, en Crète, est la première à avoir été conçue spécifiquement pour départager ces deux hypothèses concurrentes, grâce à l’analyse isotopique des restes de 50 moutons et chèvres. ([azoria.unc.edu][1])
Mettre les hypothèses à l’épreuve
À bien des égards, Azoria constitue le site idéal pour étudier l’économie qui a accompagné les débuts des cités-États grecques. La ville a été brusquement abandonnée au tout début du Ve siècle av. J.-C., juste avant l’entrée dans la période classique (510-323 av. J.-C.). Cet abandon soudain a figé un instantané de la vie quotidienne : les habitants ont laissé derrière eux leurs déchets – notamment d’abondants restes animaux et végétaux – ainsi que leur vaisselle en céramique, trop encombrante pour être emportée. Ces ensembles de céramiques, exceptionnellement bien conservés, nous ont permis de déterminer la fonction des différents bâtiments et des pièces qui les composaient.
Au sommet de la colline se trouvent plusieurs bâtiments publics, dont un édifice destiné aux repas communautaires. C’est là que les citoyens se réunissaient régulièrement pour festoyer et débattre des affaires de la cité. Plus bas, sur les terrasses, s’élevaient les demeures des élites.
Grâce à mon analyse de plus de 200 000 restes animaux provenant de ces différents espaces, il est possible de comparer, avec un niveau de détail inédit, les repas pris dans les maisons et les grands banquets publics. J’ai constaté que les mêmes espèces d’animaux, abattus au même âge, étaient consommées aussi bien dans les habitations que dans le bâtiment des repas communautaires : principalement des chèvres, puis des moutons, des porcs et des bovins.
Plus intéressante encore, la préparation de la viande différait selon qu’il s’agissait d’un banquet public ou d’un repas domestique. Lors des festins, des bouchers professionnels – probablement des prêtres chargés des sacrifices – découpaient les carcasses à l’aide de couperets. À la maison, en revanche, la viande était simplement tranchée au couteau.
On pourrait en conclure que les mêmes animaux étaient servis dans les deux contextes. Pourtant, les analyses isotopiques racontent une autre histoire. Les valeurs des isotopes du carbone relevées sur les animaux consommés dans les foyers correspondent aux variations des isotopes de l’oxygène mesurées à différents endroits d’une même dent, lesquelles reflètent les changements de saison. Cela indique que ces animaux étaient principalement élevés à proximité des exploitations agricoles locales et se nourrissaient de plantes dont la composition variait au fil des saisons.
En revanche, les animaux consommés lors des banquets publics présentent un profil très différent. Leurs valeurs isotopiques du carbone ne suivent plus les variations des isotopes de l’oxygène, mais évoluent en sens inverse. Ce schéma est caractéristique d’une transhumance entre les pâturages d’altitude en été et les plaines en hiver. D’autres animaux affichent, au contraire, des valeurs de carbone remarquablement stables tout au long de l’année, signe probable qu’ils étaient nourris avec des cultures fourragères produites spécialement à leur intention.
Ces résultats montrent que l’économie alimentaire de la Grèce antique était bien plus complexe que ne le supposaient les chercheurs. Les deux modèles d’élevage coexistaient : certains animaux étaient intégrés aux exploitations agricoles, tandis que d’autres appartenaient à des troupeaux gérés de manière plus spécialisée et mobile. Il semble même que la cohésion politique des cités-États ait reposé, en partie, sur ces grands sacrifices publics qui fournissaient de la viande à l’ensemble des citoyens, rendus possibles par la gestion collective et spécialisée de vastes troupeaux.
Ces conclusions offrent un regard nouveau sur les communautés qui ont donné naissance aux cités-États de la Grèce antique. Elles montrent que leurs membres coopéraient pour produire leur nourriture, se nourrir mutuellement et créer les conditions matérielles des banquets comme de la vie politique. Après tout, nous sommes définis non seulement par ce que nous mangeons, mais aussi par les personnes avec qui nous partageons nos repas… et, bien sûr, par ce que notre nourriture a elle-même mangé.
Flint Dibble a reçu un financement pour les analyses isotopiques dans le cadre d'une bourse individuelle des actions Marie Skłodowska-Curie de la Commission européenne (convention de subvention n° 101026314), au titre du projet de recherche ZOOCRETE.
27.06.2026 à 16:51
« Disclosure Day » : pourquoi la (potentielle) découverte d’une vie extraterrestre ne sera pas un blockbuster hollywoodien
Hervé Cottin, Astrochimiste, Professeur au Laboratoire Interuniversitaire des Systèmes Atmosphériques (LISA), Université Paris-Est Créteil Val de Marne (UPEC)
Texte intégral (3110 mots)

À moins qu’une soucoupe volante se pose devant la Maison-Blanche ou au pied de la tour Eiffel, il n’y aura pas de « jour de la révélation » hollywoodien proclamant la découverte d’une vie extraterrestre… Ce n’est pas ainsi que marche la science, et c’est tant mieux.
Dans son dernier film Disclosure Day, le réalisateur Steven Spielberg renoue avec une thématique qui lui est chère : la découverte de la vie extraterrestre. En règle générale, la vie extraterrestre décrite par Steven Spielberg est plutôt pacifique et curieuse à l’égard des humains. Rencontres du troisième type (1977) évoque la longue préparation à ce premier contact et l’invention d’un langage commun pour communiquer. Dans E.T. l’extraterrestre (1982), Spielberg inverse la dynamique de la menace avec un alien botaniste traqué par les humains – à rebours de l’archétype de l’envahisseur prédateur, présent par exemple dans la saga Alien inaugurée en 1979 par Ridley Scott.
Disclosure Day traite du « grand jour de la révélation, celui où nous apprenons que nous ne sommes pas seuls dans l’Univers ». Si, dans le film, l’existence d’extraterrestres est présentée comme un potentiel salut pour une humanité qui s’autodétruit, cette fiction est en phase avec une actualité bien réelle aux États-Unis, où le Congrès multiplie depuis 2022 les auditions officielles sur les phénomènes aérospatiaux non identifiés (PAN, le nouvel acronyme remplaçant celui d’ovni), tandis que le Pentagone alimente un site consacré aux photos, vidéos et témoignages d’observations de PAN. Ces documents, qui me semblent peu convaincants et ne constituent pas de preuve formelle, semblent avoir transformé la perception de Steven Spielberg, qui affirme croire aux témoignages sur la vie extraterrestre.
Avec ce film, la formidable machinerie hollywoodienne ranime un vieux fantasme collectif : celui de la révélation soudaine, globale et définitive de l’existence d’une vie extraterrestre.

{kind=link}
Pour quiconque pratique l’exobiologie, un domaine interdisciplinaire qui cherche à comprendre comment la vie est apparue sur Terre afin de mieux orienter notre stratégie pour la rechercher ailleurs, ce scénario d’une révélation soudaine et absolue relève de la pure commodité narrative. Il ne s’agit évidemment pas ici de faire une critique du film, que j’ai beaucoup apprécié à titre personnel, mais de rappeler que, dans la réalité scientifique, il n’y aura probablement pas de « Disclosure Day » : pas de consensus immédiat, pas de conférence de presse pour mettre un point final à l’angoisse de la solitude cosmique.
La quête du vivant ailleurs dans l’Univers est un chemin de patience extrême, qui est pavé de mesures d’anomalies et de controverses acharnées, et le restera.
Le mirage des « grands soirs » : de la météorite ALH 84001 à la phosphine vénusienne
L’histoire récente regorge déjà d’annonces où la communication institutionnelle a tenté de brûler les étapes.
Souvenons-nous de l’été 1996, lorsque le président des États-Unis Bill Clinton prit la parole pour annoncer que la météorite martienne ALH 84001 recelait de possibles traces de vie fossile. Le message était évidemment prudemment ciselé, ponctué d’appels à la prudence, mais l’impact médiatique fut planétaire. Puis, loin des caméras et des médias, au gré de contre-expertises et de publications contradictoires, les structures géochimiques observées furent expliquées par des processus ne nécessitant aucune activité biologique. L’annonce ne fut pas réfutée en un jour : elle s’est lentement dissoute dans le temps long d’un travail scientifique de longue haleine.
Un scénario relativement proche s’est reproduit en septembre 2020 avec l’affaire de la phosphine, une petite molécule de formule chimique PH₃, prétendument détectée dans l’atmosphère de Vénus. Une équipe annonçait, avec l’appui d’une publication scientifique, avoir mesuré la présence de ce gaz dans les nuages vénusiens à un niveau d’abondance inexplicable par les mécanismes géochimiques ou photochimiques connus, suggérant une possible activité biologique. Accompagnée d’un communiqué de presse titré « Indices de vie sur Vénus » et saluée par un tweet enthousiaste de l’administrateur de la Nasa de l’époque évoquant « la plus grande découverte » liée à la vie extraterrestre, la nouvelle a enflammé les médias. Dans la foulée, des financements privés ont même été annoncés pour lancer l’étude d’une mission spatiale spécifique.
Quelques années plus tard, que reste-t-il de cette annonce fracassante ? Des bases singulièrement fragiles : deux études indépendantes démontraient rapidement que la bande spectrale utilisée dans le domaine des ondes radio pour la détection n’était pas significative statistiquement, tandis que des observations complémentaires dans une autre gamme de longueur d’onde (infrarouge) ne confirmaient aucunement la présence de la molécule et abaissaient la limite supérieure de détection à un niveau 100 fois inférieur à ce qui avait été avancé. Le grand public, lui, est resté sur l’émerveillement du premier jour, ignorant que la controverse avait balayé l’hypothèse fantasmée d’une preuve de vie vénusienne.
Il n’est pas question ici de reprocher à une équipe scientifique de publier un résultat qu’elle estimait, en toute bonne foi, probablement pertinent. C’est d’ailleurs le principe de toute progression scientifique : un résultat nouveau, si surprenant soit-il, à partir du moment où il est étayé, reproductible, ou si les mêmes données peuvent être expertisées indépendamment (ce qui était le cas pour cet épisode vénusien), a vocation à être présenté à la communauté scientifique pour qu’il puisse être passé au crible des avis d’autres experts indépendants. Le communiqué de presse qui a été à l’origine de l’emballement médiatique était, par contre, probablement de trop…
L’« exobiowashing » et la tentation du « bling-bling » scientifique
Plus récemment encore, c’est l’exoplanète K2-18b qui a suscité beaucoup de bruit médiatique. En 2023, puis en 2026, une équipe scientifique, interprétant des mesures de composition atmosphérique de cette exoplanète par les télescopes spatiaux Hubble et James-Webb, a évoqué la présence de diméthylsulfure (DMS), une molécule qui, sur Terre, est fortement associée au vivant.
Les deux publications scientifiques sont à chaque fois légitimes, publiées dans des revues à comité de lecture, et soumises au débat contradictoire légitime quant à la validité ou non de la détection elle-même. À nouveau, la détection du DMS ne semble pas tenir la distance face à des contre-expertises indépendantes. De plus, quand bien même la molécule serait bel et bien détectée, d’autres processus que le vivant pourraient très bien en être à l’origine.

{kind=link}
Cependant, à chaque fois, le mécanisme est identique : ces publications sont accompagnées d’un communiqué de presse, parfois de vidéos autopromotionnelles pour le moins étonnantes. On assiste aujourd’hui à l’émergence de ce que l’on pourrait appeler l’« exobiowashing », un pendant spatial exobiologique du greenwashing. De même que l’écoblanchiment environnemental sert à valoriser l’image de marque d’une entité et à détourner l’attention de ses pratiques polluantes, l’exobiowashing utilise le vernis de la vie extraterrestre pour doper artificiellement l’attractivité d’une recherche.
L’idée derrière ce terme est que, dans un contexte académique hautement compétitif, ajouter une phrase ou deux suggérant que telle ou telle détection moléculaire fait progresser la quête de la vie extraterrestre est une assurance presque absolue de voir un projet de communiqué de presse accepté. Cela garantit une grande visibilité personnelle et institutionnelle, génère des titres accrocheurs et des clics sur les écrans de nos smartphones.
Cette stratégie pose un dilemme déontologique. La fin justifie-t-elle les moyens ? La science ne devrait-elle pas demeurer fermement ancrée dans les faits avérés, plutôt que dans la spéculation marketing ?
Le choc des temporalités : la science avance par le doute, et non par le sensationnel
Le véritable danger de cette accumulation d’annonces sensationnalistes réside dans le décalage abyssal entre la temporalité des médias et celle de la recherche.
Le public (dont je fais moi-même partie pour tout ce qui concerne les sujets extérieurs à mes domaines de recherche) consomme souvent l’actualité en scrollant rapidement, l’esprit traduisant rapidement le terme « habitable » par « habité ». On peut aussi confondre si facilement « matière organique » et « organisme vivant », tout comme on glisse sur une flaque d’eau liquide hypothétique à la surface d’une exoplanète lointaine pour l’associer à la promesse d’une forme de vie extraterrestre.
Le « Disclosure Day » aurait-il déjà eu lieu, infusé lentement à travers une succession de microfeux d’artifice médiatiques où rêves, fiction et science s’entremêlent dans une chasse au clic effrénée ? Si, dans l’esprit d’un grand nombre, la question de la vie extraterrestre est déjà réglée du fait de cette profusion d’annonces exagérées, comment pourrons-nous convaincre ce même public de la légitimité des dépenses futures indispensables pour construire les télescopes de nouvelle génération – ceux-là mêmes qui devront caractériser de manière rigoureuse la composition atmosphérique d’une exoplanète – ? Ou financer un retour d’échantillons martiens sur Terre (qui sera probablement indispensable pour savoir si la vie a un jour émergé sur notre voisine) ?
Pourtant, la communauté scientifique sait aussi faire preuve de retenue
Début 2022, la mesure par le rover de la Nasa Curiosity d’un déséquilibre isotopique intriguant du carbone 13 par rapport au carbone 12 dans le sol martien n’a donné lieu à aucune conférence de presse grandiloquente, alors que sur Terre des mesures équivalentes sont classiquement associées à la photosynthèse (c’est-à-dire la vie). Les doutes et les incertitudes de la recherche ont été partagés en bonne intelligence avec les médias. C’est cette rigueur qui s’était déjà imposée après les espoirs déçus des missions Viking dans les années 1970, dont les promesses de détection immédiate avaient fini par mettre en sommeil les programmes martiens pendant près de vingt ans.
L’exobiologie avancera, mais à son rythme. Elle s’appuie sur un postulat communément accepté mais non démontré : la vie pourrait surgir là où l’eau liquide, la matière organique et l’énergie coexistent. Démontrer, nuancer ou infirmer ce socle exige de croiser les expertises de géochimistes, géologues, chimistes, microbiologistes et d’astronomes… Une preuve de vie en dehors de la Terre ne prendra probablement jamais la forme d’un flash spécial d’information avec un signal indubitable. Elle se présentera sous la forme d’un faisceau d’indices ténus, d’une raie d’absorption contestée sur un spectre, d’une anomalie chimique que des analyses contradictoires mettront peut-être des décennies à valider ou à balayer.
À moins qu’une soucoupe volante se pose devant la Maison-Blanche, la tour Eiffel, la Cité interdite ou la pyramide de Gizeh, il n’y aura pas de « Disclosure Day » hollywoodien pour une annonce de découverte de vie extraterrestre, et c’est tant mieux. Le dialogue scientifique, avec ses disputes fécondes, ses doutes et ses réfutations, est infiniment plus passionnant que n’importe quel secret d’État éventé.
Sans renoncer à l’émerveillement des histoires extraordinaires sur grand écran, nous devons aussi apprendre à savourer le goût de la nuance scientifique plutôt que les illusions de la communication. C’est à ce prix que la science préservera sa crédibilité et que l’exploration de notre place dans l’univers restera une authentique aventure scientifique.
Pour en savoir plus sur l’exobiologie, Hervé Cottin a dirigé avec Muriel Gargaud la publication du Grand Livre de l’exobiologie, édité chez Belin Éducation (2025), et contribué à un site web pédagogique sur le sujet, avec d’autres spécialistes : AstrobioEducation.
Hervé Cottin est membre de la Société Française d'Exobiologie et préside la commission d'exobiologie de l'Union Astronomique Internationale. Ses recherches sont financées par le Centre national d'études spatiales (CNES), le CNRS, l'Agence nationale de la recherche (ANR), la région Île-de-France, la BPI ainsi que l'UPEC.
27.06.2026 à 16:46
Chercheuse, mère et précaire : une équation impossible
Marie Janot Caminade, Docteure en science politique, chercheuse à l'Institut des sciences sociales du politique (ISP), Université Paris Nanterre
Texte intégral (1737 mots)
Accéder à un poste de titulaire dans l’enseignement supérieur et la recherche, c’est un parcours d’obstacles. Pour les femmes qui deviennent mères avant d’y parvenir, la route se complique encore plus. Certaines tentent de devenir des chercheuses totales, cumulant tous les rôles, mais à quel prix et pour combien de temps ?
Comment encourager les femmes à se tourner vers des carrières scientifiques ? Ces dernières années, un certain nombre d’initiatives de mentorat ou d’information ont été mises en place pour inciter lycéennes et étudiantes à étudier les maths, la physique ou encore les sciences de l’ingénieur, alors qu’elles restent sous-représentées dans ces filières. L’une des dernières actions de grande ampleur est le plan Filles et maths, lancé en 2025, incluant notamment un travail sur les biais de genre, la mise en place de « rôles modèles » ou des classes à horaires aménagés.
Ce plan suscite néanmoins des critiques : si les femmes restent sous-représentées dans certaines disciplines, elles demeurent aussi minoritaires aux postes les plus élevés de l’ensemble du monde académique, des mathématiques aux sciences sociales.
Les inégalités de genre ne se limitent donc pas à l’accès aux études scientifiques : elles traversent l’ensemble des carrières universitaires et conduisent de nombreuses femmes à quitter l’enseignement supérieur et la recherche (ESR) avant leur titularisation. Cette fuite s’explique par plusieurs facteurs parmi lesquels la maternité occupe une place importante. Une enquête menée au Danemark montre ainsi qu’une femme sur trois abandonne sa carrière scientifique après la naissance de son premier enfant, contrairement aux hommes.
L’enquête que je mène auprès de doctorantes et de docteures en sciences sociales met en lumière les difficultés rencontrées par les femmes devenues mères avant leur titularisation. Depuis les années 1980, les exigences de recrutement se renforcent : il faut rédiger une bonne thèse, publier régulièrement, participer à des événements scientifiques et s’investir dans la vie des laboratoires. Une grande partie de ce travail relève du hope labour, c’est-à-dire d’un travail non rémunéré effectué dans l’espoir d’une embauche future.
À lire aussi : Apprentissage, service civique, stages… Les politiques d’insertion des jeunes, entre promesses d’embauche et faux espoirs
Dans ce contexte, se dessine ce que l’on pourrait appeler le mythe de la « chercheuse totale ». Celui-ci repose sur une double injonction : être une scientifique productive (sans forcément percevoir de rémunération) tout en incarnant l’idéal de « la femme », à la fois professionnelle efficace, compagne dévouée et mère investie.
Or, cet idéal de la « chercheuse totale » se heurte aux conditions concrètes du travail scientifique et à celles de la maternité.
Tout concilier mais à quel prix ?
Pour devenir des chercheuses totales, les mères non titulaires réorganisent leur vie. Certaines cumulent plusieurs journées de travail en une : emploi alimentaire, enseignements en vacation, travail scientifique gratuit et charges parentales. Ce rythme contraint souvent les femmes à travailler dans l’urgence, parfois au détriment de la quantité et de la qualité de leurs travaux scientifiques.
D’autres femmes choisissent le chômage ou le congé parental et lient ainsi leur carrière à celle de leur conjoint quand il dispose de revenus suffisants. Si cette stratégie de linked career est favorable à la production scientifique quand on a un enfant, elle crée aussi une dépendance matérielle susceptible d’aboutir à des violences sexistes et sexuelles au sein du couple. Jeanne, docteure et mère d’une petite fille, témoigne ainsi :
« Je me sens parfois obligée [d’avoir des rapports sexuels]. Je me dis “Je le lui dois bien” et lui me le fait entendre aussi. »
Dans un contexte professionnel, où chaque moment doit être rentabilisé, les congés maternité, parentaux ou pour enfant malade deviennent eux-mêmes des temps de travail scientifique.
Rebecca raconte, par exemple, avoir continué la rédaction de sa thèse pendant l’hospitalisation de son fils en urgence. Cette situation nourrit un sentiment de double culpabilité : les enquêtées estiment n’être jamais à la hauteur, ni comme mères ni comme chercheuses. Joana explique :
« J’ai pris un congé parental pour bosser, mais je m’en veux de travailler quand je vois mon fils à côté de moi. »
À l’inverse, certains pères non titulaires bénéficient d’un bonus académique de paternité. La répartition genrée des tâches domestiques et parentales ainsi que l’usage des congés paternité leur permettent parfois de consacrer davantage de temps à leurs recherches. Marion rapporte à cet égard les propos de son conjoint, docteur en histoire : « J’ai bouclé près de deux articles en un mois de congé paternité ! »
Le discours du « rite initiatique »
Même lorsqu’elles réorganisent leur vie pour assurer leur activité scientifique, les mères non titulaires se heurtent à des mécanismes de disqualification de la part de leurs pairs.
Certaines remarques formulées sous couvert de bienveillance les renvoient à leur maternité : « Tu devrais passer plus de temps avec tes enfants », « Tu dois leur manquer » ou encore « Il est où ton enfant ? »
D’autres collègues, souvent des femmes titulaires, normalisent les difficultés que les mères non titulaires rencontrent pour concilier maternité et travail scientifique, en les présentant comme des épreuves inévitables. Comme le rapporte Louise, une collègue lui a expliqué :
« Ce que tu vis est normal, c’est le parcours du combattant. On est toutes passées par là. »
À travers ces discours qui se veulent réconfortants, les contraintes liées à la maternité apparaissent comme un rite initiatique obligatoire pour devenir une chercheuse totale.
Des contraintes maternelles transformées en défauts
Du fait de la concurrence croissante dans l’ESR, la maternité de certaines devient le prétexte de leur mise à l’écart par d’autres. Certaines enquêtées racontent avoir été écartées d’événements scientifiques au prétexte qu’elles avaient désormais « mieux à faire » avec leurs enfants.
Quand elles prennent la parole au cours de réunion entre précaires, leurs difficultés à concilier travail scientifique et maternité sont disqualifiées au motif qu’elles « savaient » ce qu’impliquait le fait d’avoir un enfant avant la titularisation.
Les contraintes liées à la maternité sont enfin invisibilisées derrière des critiques portant sur un prétendu manque de productivité scientifique. Celles-ci apparaissent dès la grossesse, à travers des remarques sur l’apparence physique des femmes non titulaires et sur leur supposée mauvaise gestion du stress lors d’échéances importantes pour leur carrière.
Anouk raconte qu’après une audition pour un poste de maîtresse de conférences, qu’elle a passée alors qu’elle était enceinte, une membre du jury qui disait vouloir l’aider, lui a « rappelé » que les comités recherchaient des gens « sympas avec qui discuter à la machine à café », avant de lui prodiguer le conseil suivant :
« Vous êtes enceinte ? Vous étiez pâle. Il faudrait mettre du rouge aux joues la prochaine fois pour ne pas faire mauvaise impression. »
Les reproches portent également sur les trajectoires académiques : l’absence à certains congrès organisés pendant les vacances scolaires des enfants, l’exercice d’emplois alimentaires ou le fait de ne pas développer d’autres objets de recherche que celui de la thèse sont fréquemment associés à un manque d’engagement scientifique, occultant alors les contraintes économiques et familiales auxquelles ces femmes sont confrontées.
Condamnées comme Sisyphe ?
Face à l’impossibilité d’atteindre l’idéal de la chercheuse totale, de nombreuses enquêtées finissent par intérioriser leurs difficultés comme des échecs individuels et abandonnent progressivement le milieu universitaire.
Cet éloignement résulte en réalité de contraintes structurelles qui rendent difficile la conciliation entre maternité et carrière académique. Élodie exprime à cet égard un sentiment d’épuisement :
« Je suis comme Sisyphe ! Je suis condamnée à faire un travail qui ne sera jamais reconnu, qui ne débouchera jamais sur rien parce que j’ai eu un enfant à la fin de la thèse. »
Dans ce contexte, dans l’enseignement supérieur et la recherche, ce ne sont pas des plans comme le plan Filles et maths qui suffiront à réduire les inégalités. C’est, plus largement, l’ensemble des critères de titularisation qu’il faudrait repenser.
Les exigences actuelles favorisent celles et ceux qui disposent de ressources matérielles et d’un temps suffisants, au détriment des personnes confrontées à des contraintes familiales, sociales ou économiques. Cette mise à l’écart n’est pas seulement inégalitaire : elle est néfaste pour la recherche elle-même. En se privant de certains talents, on se prive aussi de certains savoirs.
Marie Janot Caminade ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
27.06.2026 à 11:50
Pourquoi le CO₂ des vols influence si peu nos choix (et comment y remédier)
Benjamin Boeuf, Professeur en marketing, IESEG School of Management et LEM-CNRS 9221, IÉSEG School of Management
Céline Flipo, Assistant Professor, Human Resources Management, IÉSEG School of Management
Texte intégral (1151 mots)
Pour qu’une information ait un impact sur le comportement d’un consommateur, il ne suffit pas de la lui donner. Encore faut-il que l’information soit communiquée de façon compréhensible pour pouvoir être facilement transformée en action. Illustration avec le choix d’un vol en fonction du nombre de kilogrammes de CO₂ consommés par ce trajet.
Vous cherchez un vol sur Internet. Deux options s’offrent à vous : l’une est légèrement moins chère, l’autre un peu plus rapide. À côté du prix et de la durée : les émissions de CO₂ du trajet, exprimées en kilogrammes. Vous hésitez, puis vous choisissez… le vol le plus polluant.
Depuis quelques années, des plateformes, comme Google Flights ou Skyscanner, affichent l’empreinte carbone des vols. L’objectif est clair : inciter les voyageurs à intégrer l’impact environnemental dans leurs décisions. Sur le papier, tout est là pour orienter les choix vers les vols les moins polluants.
Pourtant, dans les faits, cela change peu de choses. Pourquoi ? Parce que pour qu’une information environnementale influence une décision, encore faut-il qu’elle soit comprise, interprétée et jugée pertinente au moment du choix. Or, la plupart du temps, ce n’est pas le cas.
À lire aussi : Impact du transport aérien sur le climat : pourquoi il faut refaire les calculs
Le pouvoir discret des interfaces
Les sites de réservation en ligne comme Google Flights ne se contentent pas d’afficher des informations ; ils organisent les décisions. En hiérarchisant les résultats, en mettant en avant certains critères et en en reléguant d’autres, ces plateformes construisent ce que les économistes comportementaux appellent une « architecture des choix ».
Dans ce contexte, la manière dont l’impact environnemental est présenté devient déterminante. Une information visible mais difficile à interpréter peut rester sans effet. Autrement dit, il ne suffit pas de rendre l’information disponible. Il faut la rendre actionnable.
Des kilogrammes qui pèsent peu
Aujourd’hui, les émissions sont généralement affichées en kilogrammes de CO₂ par passager. Cette unité est précise, mais elle reste largement abstraite. Que représentent 800 kg de CO₂ pour un trajet long-courrier ? Est-ce beaucoup ? Est-ce peu ? Comment comparer deux ordres de grandeur proches ?
Faute de repères, cette information peine à s’imposer face à des critères plus familiers comme le prix ou la durée du vol. Elle reste en périphérie de la décision, sans réellement peser sur le choix final. Ce phénomène est bien documenté : une information trop technique ou trop éloignée de l’expérience quotidienne a peu de chances d’être intégrée dans un arbitrage rapide.
Rendre l’impact concret change les arbitrages
C’est précisément ce point que nous avons exploré dans une recherche récente. À partir de deux expériences, nous avons comparé l’effet de différentes présentations de l’information carbone lors d’un choix de vol. Dans certains cas, les émissions étaient simplement indiquées en kilogrammes de CO₂. Dans d’autres, elles étaient accompagnées d’équivalents concrets, par exemple en termes d’absorption par des arbres ou de consommation de carburant.
Le résultat est clair. Lorsque l’information est présentée de manière standard, elle n’a pas d’effet significatif sur les intentions de choix. En revanche, lorsqu’elle est rendue plus concrète, les individus sont moins enclins à sélectionner les vols les plus polluants.
Quand l’information devient saillante
Cette différence s’explique par un mécanisme simple : la saillance. Une information saillante est une information qui attire l’attention et qui est perçue comme importante dans la décision. Les équivalents concrets permettent précisément cela, puisqu’ils traduisent une donnée abstraite en une représentation plus familière, plus immédiatement compréhensible.
Dire qu’un vol correspond à « ce que X arbres absorbent en un an » ou à « X litres de carburant consommés » facilite la projection mentale. L’impact environnemental devient plus tangible, et donc plus difficile à ignorer. À l’inverse, une information exprimée uniquement en kilogrammes reste souvent trop distante pour influencer un arbitrage rapide.
Ces résultats montrent plus largement que l’effet de l’information environnementale dépend fortement de la manière dont elle est présentée. À ce titre, ils éclairent les débats actuels sur la réduction de l’empreinte climatique des transports, qu’il s’agisse de taxation, de quotas ou de dispositifs comme les « passeports carbone ».
Une question de forme
Ce constat ne se limite pas aux vols. Dans de nombreux secteurs, l’information environnementale est communiquée sous des formes techniques (grammes de CO₂, kilowattheures…) et est difficile à comprendre pour les individus. Dans l’automobile ou l’énergie, par exemple, les débats autour de l’affichage environnemental portent précisément sur la difficulté à rendre ces données compréhensibles pour les consommateurs.
Dans tous ces cas, l’efficacité de l’information repose moins sur sa présence que sur sa forme. Rendre les émissions tangibles constitue, de ce point de vue, un levier simple et peu coûteux. Sans contraindre les choix, cela modifie la manière dont ils sont perçus. C’est précisément le principe des nudges, ces incitations douces qui orientent les comportements sans les restreindre.
L’enjeu n’est donc pas seulement de mesurer l’impact environnemental des activités, mais de le rendre intelligible et pertinent au moment de la décision. Tant que le CO₂ restera une abstraction, il continuera à peser peu dans nos arbitrages.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
27.06.2026 à 11:49
Comment Grenoble pourrait tirer parti des JO 2030 sans être une ville hôte
Michel Polski, Professeur de Marketing, GEM
Texte intégral (2116 mots)

C’est officiel, la « capitale des Alpes françaises » n’accueillera pas de sites des prochains Jeux olympiques et paralympiques d’hiver en 2030. N’a-t-elle pas d’autres cartes à jouer que la construction de nouvelles infrastructures ? Au final, ne sera-t-elle pas la grande gagnante parmi les villes françaises bénéficiant de cet évènement sportif planétaire ?
C’est officiel, le vendredi 29 juin, la carte des sites des Jeux olympiques et paralympiques d’hiver 2030 est présentée au grand public. Sans surprise, il n’y a pas la ville de Grenoble, dans l’Isère.
Les Jeux olympiques d’hiver de Milan-Cortina se sont achevés et le drapeau olympique a été transmis à Albertville, déjà ville olympique en 1992, en vue des Jeux de 2030. Dans le même temps, l’organisation des Jeux « Alpes françaises 2030 » suscite déjà débats et interrogations, car elle a été principalement initiée et portée par des responsables politiques, qui l’ont d’abord présentée comme un levier d’investissement et de modernisation pour les territoires de montagne.
L’argument n’est pas nouveau. En 1968 déjà, les Jeux de Grenoble étaient présentés comme un accélérateur de modernisation pour la ville. Cette fois-ci, la « capitale des Alpes » ne participera pas aux Jeux d’hiver de 2030 ; Albertville n’y sera associé qu’avec son centre média pour les Alpes du Nord.
Ce paradoxe conduit à poser une question rarement abordée : comment un territoire peut-il tirer parti d’un méga-événement auquel il ne participe pas ?
La question est d’autant plus d’actualité que les Jeux Alpes françaises 2030 ne sont pas présentés comme un levier de transformation pour une seule ville, mais comme un instrument d’aménagement d’une mosaïque de territoires partagée entre différentes régions hétéroclites.
S’approprier les valeurs de l’olympisme
Un territoire peut construire une stratégie de différenciation en se réappropriant les valeurs fondatrices de l’olympisme, non comme un discours institutionnel figé, mais comme un levier d’action.
Cette idée prolonge nos travaux relatifs à la portée éducative de ces valeurs, mises en tension avec la réalité contemporaine des Jeux olympiques, et marquées par des enjeux économiques et politiques.
Plutôt que de chercher à capter les retombées des Jeux olympiques ou à s’y opposer, certains territoires utilisent l’attention médiatique qu’ils suscitent pour rappeler les principes qui ont historiquement fondé le mouvement olympique. Dans la charte olympique, l’olympisme est défini comme une philosophie de vie reposant sur trois valeurs centrales : l’excellence, l’amitié et le respect. L’objectif initial n’était pas seulement d’organiser un spectacle sportif mondial, mais de promouvoir l’éducation, la rencontre entre les peuples et un développement harmonieux des sociétés par le sport.
Les « JO sans les JO »
Lausanne illustre bien cette stratégie. Sans avoir jamais accueilli les Jeux, la ville est devenue le siège du CIO en 1915, puis a construit son identité autour de l’olympisme : fédérations sportives internationales, musée olympique, événements culturels et éducatifs. Le titre de « capitale olympique », attribué par le CIO en 1994, consacre ainsi une ville associée aux valeurs olympiques plutôt qu’à l’organisation des Jeux.

Grenoble pourrait profiter des Jeux de 2030 pour reparler des valeurs de l’olympisme : l’éducation, la culture, le respect de l’environnement et le lien entre les peuples. Le Conservatoire observatoire laboratoire des Jeux olympiques de Grenoble (Coljog) en donne un bon exemple. Cette association fait vivre la mémoire des Jeux de 1968 grâce à des expositions, des archives, des conférences et des actions culturelles.
Elle montre qu’un héritage olympique peut continuer à exister même sans accueillir de nouvelles épreuves. L’idée n’est pas de regretter les Jeux du passé, mais de s’en servir pour réfléchir à l’avenir. La ville de Grenoble pourrait, par exemple, organiser un grand forum sur la montagne avec moins de neige, des parcours dans la ville sur l’histoire olympique et les transitions alpines, ou encore des rencontres entre chercheurs, professionnels du tourisme, sportifs et habitants. Ce serait une façon concrète de faire des « JO sans les JO » : ne pas accueillir les compétitions, mais produire des idées utiles pour les territoires de montagne.
Il existe d’autres stratégies plus classiques pour tirer parti d’un tel événement. La première consiste à adopter un positionnement pro-Jeux olympiques en organisant à l’avance les conditions permettant de profiter des retombées, ce que le spécialiste du sport et du tourisme Laurence H. Chalip a théorisé sous le nom de leveraging, puis que le professeur en management public Jean-Loup Chappelet a contribué à diffuser en Europe.
La seconde stratégie consiste au contraire à prendre ses distances avec les Jeux, en assumant un positionnement alternatif, voire contestataire, face au dispositif olympique.
Tirer parti de l’évènement
La stratégie de leveraging consiste à tenter de capter les retombées indirectes de l’évènement. Ce phénomène est souvent décrit comme un « effet de halo ». Même sans accueillir d’épreuves, un territoire peut bénéficier de la visibilité générée par l’événement, à condition de mettre en place des stratégies pour en capter les effets.
Par exemple, avant les Jeux olympiques de Londres en 2012, de nombreux territoires britanniques ont accueilli des délégations dans des camps d’entraînement pré-olympiques ou participé à l’Olympiade culturelle, organisée à l’échelle du Royaume-Uni.
De même, pour les Jeux olympiques de Paris 2024, le label Terre de Jeux et les campagnes touristiques d’Atout France visaient explicitement à associer des collectivités non hôtes et à diffuser l’attractivité des Jeux à l’échelle du pays.
Les Jeux d’hiver de Milan-Cortina 2026 s’inscrivent dans cette logique territoriale. Des initiatives comme le programme Italia dei Giochi ou les campagnes de promotion touristique de l’Agence nationale italienne du tourisme (Agenzia Nazionale del Turismo) visent à associer des villes italiennes non hôtes et à diffuser les retombées de l’événement à l’échelle nationale.
À lire aussi : JO Milan-Cortina 2026 et Alpes 2030 : qui sont les « éléphants blancs » ?
Bien que l’efficacité de cette stratégie de halo n’ait jamais été totalement prouvée, il semble qu’un certain consensus se dégage pour dire que les retombées ne résultent pas automatiquement de l’événement lui-même. Elles dépendent avant tout des dispositifs d’accompagnement capables d’organiser en amont la visibilité internationale.
La réactivation d’un récit territorial
Certains territoires préfèrent au contraire construire leur positionnement en opposition au projet olympique. Les opposants dénoncent notamment les coûts publics, l’impact environnemental et les transformations de leur territoire. Plusieurs villes européennes ont montré qu’un refus des Jeux ne signifiait pas un renoncement au développement. Les villes de Hambourg, Oslo ou Stockholm ont abandonné leur candidature aux Jeux olympiques et paralympiques, tout en poursuivant avec succès leur développement urbain de façon volontariste et positive. Le positionnement « No JO » ne crée pas forcément un modèle alternatif, mais révèle d’autres priorités territoriales : qualité de vie, maîtrise des coûts, gouvernance et distance vis-à-vis du gigantisme événementiel.
Si cette stratégie par contraste peut donner une certaine visibilité médiatique grâce aux controverses qu’elle suscite, elle reste délicate à assumer pour une collectivité. Elle peut la placer en porte-à-faux avec les acteurs régionaux ou nationaux engagés dans le projet olympique, notamment la communauté sportive.
C’est pourquoi une troisième voie consiste à ne pas se positionner contre les Jeux, mais à s’appuyer sur leur puissance symbolique pour réactiver un récit territorial différenciant.
Les Jeux olympiques de 1968 ont accéléré la modernisation de Grenoble, sans l’enfermer durablement dans une identité strictement olympique : recherche scientifique, innovation, transition environnementale… À l’heure où les Jeux de 2030 se présentent comme un projet pour l’ensemble des Alpes françaises, Grenoble peut rappeler qu’un territoire peut hériter des Jeux olympiques, s’en inspirer, mais aussi construire son avenir au-delà d’eux.
Michel Polski ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
27.06.2026 à 11:49
Pourquoi la négation à la sauce IA – « Ce n’est pas X, c’est Y » – est à la fois agaçante et inefficace
Joshua Gonzales, PhD, Management, Lang School of Business and Economics, University of Guelph
Texte intégral (1281 mots)
Vous avez sans doute déjà vu cette formulation sur LinkedIn : « Ce n’est pas un métier, c’est une vocation », « Ce n’est pas du marketing, c’est un mouvement » ou encore « Ce n’est pas un outil, c’est un changement de paradigme ». Mais si, au premier abord, cette tournure typique de l’IA générative peut sembler percutante, notre cerveau a du mal à la traiter.
Ce type de formulation envahit les publications sur la plateforme. C’est devenu l’un des schémas les plus reconnaissables du texte généré par IA : « Ce n’est pas X, c’est Y. »
Si vous êtes comme moi, vous trouvez cela agaçant et vous passez votre chemin dès que vous le lisez. Votre exaspération est justifiée. La négation peut être un puissant procédé littéraire lorsqu’elle est utilisée à bon escient, mais dans le cas contraire, elle sonne creux.
C’est exactement ce que fait le « slop IA » – ce contenu numérique de mauvaise qualité généré par l’intelligence artificielle, souvent avec peu ou pas de supervision humaine : il transforme des repères autrefois utiles en charabia.
À la lecture, il suffit généralement d’ignorer les tics de langage de l’IA générative. La forme négative de la « bouillie IA », cependant, n’est pas seulement agaçante : elle fausse la manière dont les gens traitent et mémorisent l’information. Avant même d’avoir eu le temps d’assimiler quelque chose de significatif, votre attention est déjà accaparée par ce qui ne l’est pas.
Comment le cerveau traite la négation
Si cette structure semble bizarre, il y a une explication. Les psychologues cognitifs savent depuis des décennies que la négation ne fonctionne pas comme le souhaitent les locuteurs. Quand quelqu’un vous dit ce que quelque chose « n’est pas », votre cerveau ne passe pas directement à l’alternative. Il traite d’abord le concept nié.
C’est ce qu’a démontré une étude de 2003. Après avoir lu une information négative, les modèles mentaux des lecteurs conservaient toujours le concept nié, même à des intervalles de traitement courts. La négation ne fonctionnait pas comme une gomme. Au contraire, le concept s’imprimait dans l’esprit du lecteur, et ce n’est qu’avec un temps de traitement supplémentaire et un soutien contextuel que celui-ci pouvait le dépasser.
Chaque fois que vous lisez « Ce n’est pas du marketing », par exemple, vous traitez le concept de marketing avant de pouvoir accéder à ce que l’auteur affirme être la réalité alternative.
Si cela n’arrive qu’une seule fois dans un texte, ça reste gérable, mais cette charge cognitive s’accumule avec la répétition.
« Ne pensez pas à l’ours blanc »
Dans une expérience classique de 1987, le psychologue Daniel Wegner a demandé aux participants de ne pas penser à un ours blanc. Ils n’y sont pas parvenus.
Ceux à qui l’on avait demandé de refouler cette idée en parlaient plus d’une fois par minute. Pis encore, les participants qui avaient d’abord tenté de refouler cette pensée ont ensuite montré un effet rebond, pensant aux ours blancs nettement plus souvent que ceux qui avaient été libres d’y penser dès le départ.
L’effort déployé pour repousser une idée ne faisait que la rendre encore plus tenace.
Lorsque votre fil d’actualité LinkedIn vous propose des dizaines de publications reposant sur la même structure de négation et de recadrage, chacune d’entre elles constitue ainsi une nouvelle consigne de ne pas penser à ce que l’auteur voulait vous faire oublier.
Les conséquences vont au-delà du simple agacement. Dans une étude de psychologie sociale de 2004 examinant la manière dont les gens encodent les informations négatives, les chercheurs ont expliqué pourquoi certaines négations échouent davantage que d’autres.
Lorsqu’une phrase négative comporte une alternative évidente et couramment déduite, les lecteurs la remplacent mentalement. Par exemple, ils peuvent substituer « non coupable » à « innocent » ou « pas froid » à « chaud ». En l’absence d’alternative, le concept d’origine reste actif, assorti d’une étiquette de négation, à l’image d’un post-it mental sur lequel serait écrit « pas ça ».
Ce post-it peut se décoller assez facilement. Dans l’étude, les participants l’ont perdu dans plus d’un tiers des cas pour les concepts ne présentant pas d’alternative claire, se souvenant à la place de la version affirmative.
Réfléchissez à ce que cela signifie pour « Ce n’est pas du marketing, c’est un mouvement ». Le marketing n’a pas de substitut tout prêt que notre esprit puisse envisager. Ce que les lecteurs retiennent, c’est « marketing » avec une étiquette qui peut ou non survivre à leur défilement vers le post suivant.
L’échelle d’un problème cognitif
Le problème, c’est l’échelle. Une étude de 2024 sur l’IA générative menée par des chercheurs en économie et en stratégie a révélé que lorsque les gens écrivent avec l’aide de l’IA, leurs productions convergent. Les textes individuels peuvent être plus soignés, mais l’ensemble des écrits devient plus homogène. Les textes rédigés avec l’aide de l’IA se sont avérés environ 10 % plus similaires que ceux écrits uniquement par des humains.
Leur étude portait sur la fiction créative, mais les résultats ont des implications évidentes pour d’autres formes d’écriture. Lorsqu’une formule rhétorique sature toute une plateforme, elle cesse d’être l’habitude stylistique d’une seule personne et devient un cadre par défaut à travers lequel les idées entrent dans le débat public.
À l’heure actuelle, ce cadre part souvent d’un déficit. Il met l’accent sur ce qu’une chose n’est pas plutôt que sur ce qu’elle offre.
L’alternative est simple. Dites ce que c’est. Dites ce que vous avez construit, ce en quoi vous croyez, ce que vous offrez. C’est une meilleure stratégie cognitive. Les lecteurs qui tombent sur « Je suis un bâtisseur de mouvement » retiennent « bâtisseur de mouvement ». Ceux qui tombent sur « Ce n’est pas du marketing » retiennent « marketing » avec un post-it qui se décolle déjà.
L’une de ces formulations donne aux gens quelque chose à retenir. L’autre leur donne quelque chose à oublier, et la psychologie suggère que cela ne fonctionne pas.
Joshua Gonzales ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
27.06.2026 à 08:39
Autour des bois, quelques arbres peuvent faire une grande différence pour la biodiversité
Anderson Saldanha Bueno, Professor, Instituto Federal Farroupilha (IFFar)
Carlos A. Peres, Professor of Tropical Conservation Ecology, University of East Anglia
Chase Mendenhall, Conservation Scientist
Texte intégral (1937 mots)

Une étude menée dans 17 pays montre que de petits fragments forestiers peuvent abriter bien plus d’espèces d’oiseaux que leur taille ne le laisse penser lorsque leur environnement est favorable.
« Les grandes surfaces abritent davantage d’espèces. » Il s’agit de l’une des lois les plus solidement établies de l’écologie, qui explique pourquoi les grands espaces naturels bénéficient généralement d’une plus forte attention dans les stratégies de conservation. Dans les paysages fragmentés, cette logique a également conduit à considérer les petits fragments forestiers comme des milieux de moindre valeur pour la biodiversité.
Mais est-il possible d’augmenter le nombre d’espèces présentes dans un fragment forestier sans en accroître la superficie ? C’est ce qu’établit notre étude, publiée dans la revue Proceedings of the National Academy of Sciences. Lorsque l’environnement qui les entoure est favorable, de petits fragments forestiers peuvent abriter bien davantage d’espèces d’oiseaux que ce que leur seule superficie laisserait prévoir.
Des paysages forestiers fragmentés
Les paysages forestiers transformés par les activités humaines sont composés de fragments forestiers de tailles variées, entourés d’autres types de milieux, regroupés sous le terme de matrice. Cette matrice peut être terrestre, comme les pâturages, les cultures agricoles ou les zones urbaines, ou aquatique, comme les réservoirs des barrages hydroélectriques.
Outre cette matrice, l’environnement des fragments peut également comprendre de la végétation arborée, notamment des arbres dispersés, des forêts riveraines ou d’autres fragments forestiers situés à proximité. Ensemble, la matrice et cette végétation arborée constituent l’environnement des fragments forestiers.

L’apport de l’environnement
Pour comprendre le rôle de cet environnement, nous avons rassemblé des données portant sur près de 2 000 espèces d’oiseaux recensées dans plus d’un millier de vestiges forestiers tropicaux et subtropicaux, répartis dans 50 paysages de 17 pays d’Amérique, d’Afrique et d’Asie. L’étude a comparé des fragments forestiers entourés de matrices terrestres modifiées par l’élevage, l’agriculture ou l’urbanisation à des îles forestières créées par des réservoirs hydroélectriques.
Les îles de réservoirs constituent un cas extrême de fragmentation en raison de l’hostilité écologique de la matrice qui les entoure. En les comparant à des fragments forestiers entourés de matrices terrestres, nous avons pu mesurer dans quelle mesure le remplacement d’une matrice aquatique par une matrice terrestre peut accroître le nombre d’espèces d’oiseaux dans des forêts de même superficie.
À l’aide d’images satellitaires, nous avons également mesuré la quantité de végétation arborée présente autour des vestiges forestiers à différentes distances, allant de 50 à 2 000 mètres. Cette approche nous a permis de déterminer jusqu’à quelle distance de la forêt l’augmentation de la couverture arborée exerce l’effet le plus important sur la richesse en espèces d’oiseaux.
Améliorer l’environnement augmente le nombre d’espèces
Les fragments forestiers entourés de matrices terrestres abritaient davantage d’espèces que les îles de réservoirs. Cet écart augmente à mesure que la superficie du fragment diminue. Ainsi, un fragment forestier d’un hectare peut accueillir plus de deux fois plus d’espèces qu’une île de même taille.
La quantité de végétation arborée entourant les vestiges forestiers est également déterminante. Dans les fragments comme sur les îles, une plus grande présence d’arbres dans le paysage environnant – en particulier dans un rayon de 300 mètres – se traduit par un nombre moindre d’extinctions locales. Cet effet est encore plus marqué chez les oiseaux dépendant des milieux forestiers, qui sont les plus sensibles à la fragmentation des forêts.
Comment les espèces perçoivent leur environnement
Les oiseaux qui vivent dans des fragments forestiers ne sont pas nécessairement confinés à l’intérieur de ceux-ci. Plus la matrice est accueillante et plus la végétation arborée est abondante dans les environs, plus les espèces sont susceptibles de se déplacer entre les fragments et d’exploiter les ressources disponibles dans la matrice, comme les insectes ou le nectar des fleurs.
La capacité de voler ne garantit pas aux oiseaux une libre circulation à travers la matrice ou entre les zones forestières. Certaines espèces adaptées aux sous-bois ombragés de la forêt ont tendance à éviter les milieux ouverts. De plus, de nombreuses espèces se déplacent principalement à l’intérieur de la forêt, sans avoir besoin d’effectuer de longs vols. C’est pourquoi même de simples pistes en terre peuvent limiter les déplacements des oiseaux entre des fragments voisins.
Cette mobilité est pourtant essentielle à l’échelle du paysage. Des fragments forestiers où certaines espèces ont disparu localement peuvent être recolonisés par des individus provenant d’autres fragments. Pour que ce processus de recolonisation soit possible, deux conditions doivent être réunies : les espèces doivent pouvoir traverser la matrice et disposer de fragments forestiers proches ou d’éléments arborés servant de relais le long de leur trajet, comme des arbres isolés ou des forêts riveraines, qui facilitent les déplacements entre des fragments plus éloignés.
L’environnement compte davantage pour les petits fragments
Dans les grands fragments forestiers, les espèces trouvent généralement suffisamment de nourriture, d’abris et d’espace pour se maintenir. Dans les petits fragments, en revanche, l’espace et les ressources disponibles peuvent être insuffisants pour soutenir de nombreuses populations d’oiseaux. Mais lorsque les oiseaux parviennent à exploiter des ressources situées en dehors du fragment et à rejoindre d’autres zones forestières, ils utilisent en réalité un territoire plus vaste que celui délimité par le fragment lui-même. C’est pourquoi les petits fragments bénéficiant d’un environnement favorable peuvent accueillir davantage d’espèces.
Or, la plupart des fragments forestiers sont de petite taille. Dans les régions tropicales et subtropicales, les paysages forestiers fragmentés sont constitués, dans leur immense majorité, de petits fragments. Dans la forêt atlantique d’Amérique du Sud, 80 % des fragments forestiers couvrent moins de cinq hectares. Autrement dit, la survie de la biodiversité dans les forêts résiduelles dépend largement de la qualité de leur environnement immédiat.
Des implications pour la conservation
De modestes augmentations de la couverture arborée dans un rayon de 300 mètres autour des fragments forestiers peuvent réduire de manière significative la perte d’espèces. Cela signifie que des actions locales peuvent produire des bénéfices réels pour la biodiversité : planter des arbres, restaurer les forêts riveraines, réhabiliter les zones dégradées ou développer les systèmes agroforestiers – comme les plantations de café et de cacao – peut rendre les paysages productifs plus favorables à la faune sauvage.
Dans un monde où les habitats naturels continuent de se réduire, ce constat porte un message d’espoir.
La protection des forêts et des autres habitats naturels reste, et restera, la stratégie centrale de conservation de la biodiversité. Mais notre étude montre que les efforts de conservation ne doivent pas s’arrêter aux limites de la forêt. En combinant la protection des milieux forestiers avec l’amélioration de leur environnement immédiat, il est possible d’accroître la valeur de conservation des fragments forestiers, en particulier des plus petits, qui sont les plus fréquents dans les paysages transformés par les activités humaines.
La taille est un facteur crucial, mais elle ne fait pas tout : ce qui se trouve à l’extérieur du fragment forestier contribue aussi à déterminer le nombre d’espèces qu’il peut abriter.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
26.06.2026 à 14:53
Quand les religieuses prêtaient de l’argent : l’influence méconnue des couvents sur l’économie viennoise
Anna Molnár, Leverhulme Early Career Research Fellow, Late Medieval Financial History of Central Europe, University of Reading
Texte intégral (1990 mots)

Les religieuses n’étaient pas seulement des figures spirituelles. À la fin du Moyen Âge, les couvents de Vienne géraient d’importants capitaux et finançaient ménages, artisans et institutions à travers toute la ville.
Préparer sa retraite n’a rien d’une invention moderne. Bien avant les fonds de pension et les produits d’épargne, les habitants de l’Europe médiévale échangeaient déjà des capitaux contre des revenus réguliers. À Vienne, à la fin du Moyen Âge, ce système de rentes constituait même l’un des piliers de l’économie urbaine.
Et contrairement à ce que l’on pourrait imaginer, les principaux acteurs de cette finance d’avant les banques n’étaient pas seulement des marchands ou de riches notables. Des communautés de religieuses jouaient elles aussi un rôle central, au point de devenir parmi les gestionnaires financiers les plus fiables et les plus influents de la ville.
Les rentes existaient sous plusieurs formes, adaptées à des besoins différents. Leur principe était simple : une personne versait une somme d’argent importante en échange d’un revenu régulier, généralement garanti par un bien immobilier ou par des recettes urbaines.
Dans la Vienne médiévale – qui constitue mon domaine de recherche –, la formule la plus répandue était la rente perpétuelle. Ce type de contrat assurait un revenu annuel fixe sans date d’échéance prédéfinie et pouvait être revendu ou transmis à un tiers.
À côté de ces rentes perpétuelles existaient les rentes viagères, qui garantissaient un revenu à leur bénéficiaire jusqu’à sa mort. Elles offraient une forme de sécurité pour la vieillesse tout en facilitant la gestion des héritages. Les autorités municipales émettaient également des rentes publiques, permettant à la ville de lever des fonds en échange de versements réguliers garantis par ses recettes.
Ces différents types de rentes répondaient à une grande variété de besoins financiers. Les ménages y recouraient pour obtenir rapidement des liquidités, les investisseurs pour s’assurer des revenus prévisibles, et les institutions pour gérer leurs actifs sur le long terme. Dans des villes comme Vienne, ce système constituait l’épine dorsale de la finance urbaine. En l’absence de véritables établissements bancaires, il permettait de financer durablement l’activité économique et de faire circuler les capitaux au sein de la cité.
Des femmes au centre du système
Les recherches que j’ai menées à partir des archives municipales de Vienne offrent un aperçu exceptionnellement détaillé de ce système. Une base de données regroupant plus de 2 000 contrats de rente enregistrés dans les Grundbücher, les registres fonciers de la ville, entre environ 1360 et 1450, permet d’identifier les acteurs de ce marché et de suivre l’évolution de leurs pratiques au fil du temps.
Les femmes y apparaissent de manière particulièrement visible, aussi bien comme emprunteuses que comme prêteuses. Les épouses participaient à la gestion financière du foyer aux côtés de leur mari, les veuves administraient et réinvestissaient leur patrimoine, tandis que certaines femmes agissaient comme de véritables agentes économiques indépendantes. Loin d’être marginales, les femmes étaient pleinement intégrées au fonctionnement quotidien des marchés du crédit à la fin du Moyen Âge.
Au cours du XVe siècle, toutefois, cette situation commence à évoluer. Les femmes apparaissent de moins en moins souvent dans les transactions de rentes à titre individuel. À leur place émerge progressivement une autre figure féminine de l’activité économique : la religieuse.

{kind=link}
L’âge et la situation familiale influençaient la manière dont les femmes participaient au marché du crédit dans le cadre juridique viennois. Les règlements de la ville définissaient les moments où elles pouvaient disposer de leurs biens, notamment lors d’un veuvage, d’une entrée au couvent ou lorsqu’elles atteignaient un âge reconnu comme celui de la maturité économique.
Les femmes apparaissent ainsi dans les archives des rentes à différents moments de leur existence. Elles interviennent parfois seules, parfois avec leur époux ou des membres de leur famille. Dans le même temps, des transformations institutionnelles plus larges modifient les circuits du crédit au sein de la ville. Les femmes demeurent une composante essentielle de ce système, même si les modalités de leur participation évoluent progressivement.
L’une des évolutions les plus marquantes de cette période est la montée en puissance des couvents féminins comme prêteurs. À mesure que les femmes apparaissent moins fréquemment dans les transactions de rentes à titre individuel, les communautés religieuses deviennent des acteurs de plus en plus actifs du crédit. Ce basculement devient particulièrement visible après 1420, lorsque la communauté juive de Vienne – longtemps l’une des principales sources de crédit de la ville – est expulsée. La contraction de ces circuits de financement ouvre alors de nouvelles opportunités. Les couvents investissent cet espace, développent leurs activités de prêt et s’imposent progressivement comme des fournisseurs essentiels de crédit urbain.
Les couvents, nouveaux acteurs du crédit
Les couvents accumulaient des ressources grâce aux dots, aux dons et aux revenus de rentes, constituant derrière leurs murs d’importantes réserves de capitaux. Ils réinvestissaient ensuite cette richesse à travers des contrats de rente, souvent sur de longues périodes, en répartissant les risques entre un large éventail d’emprunteurs.
Les responsables des couvents suivaient les paiements, négociaient les contrats et entretenaient leur réputation de fiabilité. Dans un monde où la confiance était au cœur des échanges financiers, les religieuses étaient reconnues comme des créancières sûres et fiables.
_(1610)_-_Foto_Giovanni_Dall%27Orto,_6-Dec-2007.jpg){kind=link}
Toutes sortes d’emprunteurs venaient à elles. Les registres viennois des rentes privées montrent ainsi que des ménages, des artisans, des élites locales et des institutions se tournaient tous vers les couvents pour obtenir du crédit. Ces prêts servaient à financer des transactions immobilières, à restructurer des dettes existantes, à répondre aux besoins des foyers ou encore à réaliser des investissements. L’activité de prêt des couvents faisait alors partie intégrante du fonctionnement quotidien de l’économie viennoise.
L’étude de ces archives invite également à revoir notre compréhension de l’histoire économique des femmes. Si les femmes sont moins présentes à titre individuel dans les systèmes financiers, leur participation se déplace vers des formes plus collectives et institutionnelles. Elles continuent d’influencer la vie économique, souvent à travers des structures capables d’organiser et de renforcer les ressources dont elles disposent.
À l’heure où les questions d’inclusion financière et de stabilité économique restent au cœur des débats, l’exemple de Vienne offre plusieurs enseignements. La confiance, la capacité d’adaptation et la diversité des acteurs sont des éléments essentiels au bon fonctionnement d’un système financier. Lorsque les sources traditionnelles de crédit se transforment ou disparaissent, de nouveaux acteurs peuvent émerger pour prendre le relais et maintenir la circulation des capitaux.
Dans le cas de Vienne, ce rôle a été assumé par les communautés religieuses féminines, qui ont contribué de manière décisive à la résilience économique de la ville.
Anna Molnár a reçu des financements du Leverhulme Trust.
26.06.2026 à 14:53
Si l’IA générative favorise l’addiction, qui doit rendre des comptes ?
Bernd Stahl, Professor of Critical Research in Technology, School of Computer Science, University of Nottingham
Texte intégral (1657 mots)
Les appels à la modération individuelle ne suffiront peut-être pas. Face aux risques d’usage compulsif de l’IA générative, chercheurs, régulateurs, entreprises et société civile pourraient devoir agir de concert.
Lorsque je discute avec mon fils, élève ingénieur, et qu’une question ou un désaccord surgit, son premier réflexe est de se tourner vers ChatGPT pour obtenir une information ou confirmer ce qu’il pense.
Il est loin d’être le seul. L’usage des outils d’IA générative s’est généralisé dans de nombreux groupes de population. Pour beaucoup, ces outils sont divertissants, instructifs et utiles. Mais ils ont aussi leur face sombre.
À ce jour, l’IA générative n’est pas officiellement reconnue comme une addiction : les preuves médicales sont encore en cours d’évaluation. Mais un nombre important d’études montre qu’un usage intensif des chatbots et d’autres systèmes capables de produire du texte, des images ou des vidéos entraîne des modifications de l’activité cérébrale et des comportements associés aux mécanismes de l’addiction.
À la lumière de la condamnation récente de Meta et de YouTube dans un procès historique portant sur l’addiction aux réseaux sociaux, il est légitime de se demander si un raisonnement similaire ne devrait pas s’appliquer à l’IA générative – et comment y répondre. La première étape consiste à déterminer qui porte la responsabilité de son usage excessif.
Le débat scientifique est loin d’être tranché et certains appellent à la prudence avant d’employer le terme d’« addiction ». Ils préfèrent parler d’« usage problématique ». Toutefois, dans un récent article scientifique, notre équipe de recherche montre que de nombreux éléments indiquent que l’IA générative possède des propriétés susceptibles de favoriser des comportements addictifs.
Parmi les exemples les plus souvent cités figurent la dépendance affective envers des compagnons conversationnels, l’engagement compulsif dans les échanges avec ces outils, ainsi que l’affaiblissement des relations et des amitiés dans le monde réel.
Un élément essentiel est que, comme pour toute addiction, ce comportement entraîne des conséquences négatives pour la personne concernée, susceptibles d’affecter aussi bien sa vie personnelle que sa vie professionnelle.
Si l’on considère que l’IA générative est susceptible de provoquer des comportements addictifs, il faut alors s’interroger sur les responsabilités. Face à un phénomène préjudiciable, les sociétés cherchent généralement à identifier les personnes ou les organisations chargées d’y répondre. Les acteurs susceptibles d’être tenus responsables sont notamment les législateurs, les autorités de régulation, les entreprises du secteur et les systèmes de santé.
Des précédents historiques
Des précédents historiques, comme celui du tabagisme, peuvent éclairer la manière dont la question de l’addiction à l’IA générative pourrait évoluer.
Les lecteurs les plus âgés se souviennent peut-être de l’époque où le cow-boy Marlboro apparaissait à l’écran avant les séances de cinéma. On a fini par découvrir que non seulement le tabac était addictif et nocif pour la santé, mais aussi que les fabricants de cigarettes en avaient connaissance. Pourtant, ils l’ont publiquement nié.
Cette situation a donné lieu à des procédures judiciaires longues et très médiatisées, qui se sont soldées par d’importantes indemnisations financières ainsi que par de profondes réformes du secteur. Parmi elles figurent l’introduction des paquets de cigarettes neutres et l’apposition de messages d’avertissement particulièrement explicites sur les produits du tabac.
Les jeux d’argent semblent aujourd’hui suivre une trajectoire comparable. Quant aux réseaux sociaux, ils pourraient être en train d’entrer, eux aussi, dans une phase similaire.
Une question centrale est de savoir si les fabricants d’un produit (qu’il s’agisse du tabac, des jeux d’argent ou des réseaux sociaux) ont connaissance de son potentiel addictif. Une autre interrogation importante est de déterminer si certaines entreprises exploitent délibérément les propriétés potentiellement addictives de leurs produits pour en tirer un avantage commercial. L’IA n’est évidemment pas le tabac, mais ces précédents offrent des parallèles qui méritent d’être étudiés.
Dans nos travaux, nous avons identifié quatre catégories d’acteurs aujourd’hui appelées à répondre aux défis que pose la possibilité d’une addiction à l’IA générative. Le premier groupe est celui des gouvernements et des autorités de régulation. Ils ont un rôle essentiel à jouer pour mettre en lumière les problèmes, définir les règles du jeu et créer des incitations afin que les autres acteurs s’emparent eux aussi de cette question.
Ils disposent pour cela de nombreux leviers : imposer un étiquetage, encadrer la publicité, engager la responsabilité juridique des entreprises, financer la recherche, ainsi que de nombreuses autres mesures. Mais les acteurs les plus déterminants pour répondre aux comportements potentiellement addictifs liés à l’IA générative sont sans doute les grandes entreprises technologiques qui développent et possèdent ces technologies – et qui en tirent des bénéfices financiers.
Ces entreprises détiennent et ont accès aux données des utilisateurs, indispensables pour identifier les fonctionnalités qui favorisent ou, au contraire, limitent les comportements addictifs. Ce sont également elles qui peuvent tirer un avantage financier d’une éventuelle addiction, en augmentant le nombre d’utilisateurs et le temps qu’ils consacrent à leurs services, deux ressources essentielles de l’économie numérique.
Aux côtés de ces deux premiers groupes, les chercheurs ont un rôle crucial à jouer. Ils sont chargés de recueillir et d’interpréter les données, ainsi que de produire les preuves scientifiques nécessaires pour identifier les phénomènes d’addiction et les caractéristiques qui les favorisent, afin d’alimenter un débat politique et juridique fondé sur des éléments factuels.
Enfin, les organisations de la société civile, comme les associations d’usagers ou de patients, peuvent contribuer en apportant un soutien aux personnes concernées, en défendant leurs intérêts et en mettant en place des dispositifs d’alerte précoce. L’enjeu est que nul ne peut relever ce défi seul. Tous ces acteurs devront travailler ensemble.
Le problème, c’est toujours celui des autres
Aujourd’hui, l’un des principaux obstacles est l’absence d’un véritable débat structuré sur les responsabilités : chacun considère que le problème relève de quelqu’un d’autre. Pourtant, de nombreux précédents montrent qu’il est possible d’obtenir une mobilisation plus forte de l’ensemble des acteurs concernés.
Dans le cas du tabac, l’Organisation mondiale de la santé (OMS) a mis en place la Convention-cadre pour la lutte antitabac, un traité international réunissant gouvernements, autorités de santé publique, chercheurs et organisations de la société civile afin d’évaluer les preuves scientifiques et d’élaborer des règles communes. De la même manière, l’International AI Safety Report montre que des initiatives internationales visant à construire un consensus existent déjà sur d’autres enjeux liés à l’IA.
Une part de responsabilité incombe également aux utilisateurs de l’IA, qui doivent s’efforcer d’éviter ou de maîtriser les comportements susceptibles de leur être préjudiciables. Mais l’expérience acquise avec d’autres formes d’addiction montre que les appels à la modération ou à la vigilance individuelle ne suffisent pas.
Si les effets nocifs du tabac ou de l’abus d’alcool sont aujourd’hui bien connus, nos sociétés continuent de s’appuyer sur des limites d’âge, des règles d’étiquetage et des restrictions publicitaires. L’IA générative est en train de s’intégrer au tissu même de notre quotidien. Les décisions que nous prenons aujourd’hui façonneront ce qui sera considéré comme un usage acceptable pour les années à venir.
Bernd Stahl ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
26.06.2026 à 14:51
Un portrait de Pocahontas daté de 1616 révèle le regard des colons anglais sur les peuples autochtones américains
Peter C. Mancall, Distinguished Professor and Professor of the Humanities, USC Dornsife College of Letters, Arts and Sciences
Texte intégral (2755 mots)

.png){kind=link}
En représentant Pocahontas comme une dame anglaise, les colons voulaient démontrer que les peuples autochtones étaient appelés à adopter rapidement leur culture. L'histoire leur donnera tort.
Grâce à Disney, Pocahontas est sans doute l'Amérindienne du XVIIe siècle la plus célèbre au monde. Le film d'animation consacré à son enfance la montre conversant avec un saule, se liant d'amitié avec des animaux, chantant « Les couleurs du vent » et vivant une romance impossible avec le capitaine John Smith.
Le film de 1995 a façonné une image durable de Pocahontas. Il reprend certains éléments issus des sources historiques, mais relève aussi largement de la fiction. John Smith était bien l'un des colons anglais arrivés à Jamestown, en Virginie, peu après la fondation de la colonie en 1607. Le père de Pocahontas, Wahunsonacock (que les colons, puis Disney, ont appelé Powhatan) était le chef suprême de la confédération powhatan, dont les communautés vivaient le long de la baie de Chesapeake et de ses affluents.
Il n'existe qu'un seul portrait de Pocahontas réalisé de son vivant, très loin de l'image popularisée par Disney. Et ce portrait en dit long sur la manière dont les Anglais concevaient la colonisation.
Une famille puissante
Comme je l'explique dans mon livre publié en 2026, Contested Continent: The Struggle for North America, c. 1000 to 1680 (« Continent disputé : la lutte pour l'Amérique du Nord, de l'an 1000 à 1680 », non traduit en franças), Wahunsonacock fut la figure politique la plus importante de la Virginie des débuts de la colonisation, un territoire que les Powhatans appelaient Tsenacommacah. Grâce à un réseau d'alliances personnelles et à une remarquable habileté politique, il exerçait son autorité sur une trentaine de communautés établies le long des rives de la baie de Chesapeake et de ses affluents.

{kind=link}
Pocahontas, également connue sous les noms de Matoaka et Amonute, avait probablement dix ou onze ans lorsqu'elle rencontra John Smith à la fin de l'année 1607. À ce moment-là, celui-ci était prisonnier de son père qui, selon le récit qu'il fera plus tard, s'apprêtait à le faire exécuter. Les historiens estiment toutefois que Wahunsonacock soumettait plus vraisemblablement Smith à un rituel d'adoption. Le colon anglais, lui, affirma que Pocahontas lui avait sauvé la vie.
En 1613, les Anglais capturèrent Pocahontas au cours d'un conflit connu sous le nom de première guerre anglo-powhatan. Après avoir obtenu la libération de sa fille en 1614, Wahunsonacock approuva son mariage avec John Rolfe, acteur majeur de l'économie du tabac de la colonie, et elle se convertit au christianisme. Entre 1615 et 1617, elle donna naissance à leur fils, Thomas.
Pocahontas en Angleterre
Deux ans après leur mariage, Pocahontas et John Rolfe se rendirent en Angleterre, où elle joua un rôle central dans la mission diplomatique menée au nom de son père.
Au cours de son séjour à Londres, qui lui permit notamment de rencontrer le roi Jacques Ier, Pocahontas posa pour un portrait réalisé par l'artiste Simon van de Passe. Sa tenue et sa posture reprennent les codes des portraits des femmes de l'élite anglaise de l'époque. L'image met en valeur son haut chapeau cylindrique, son large col de dentelle, sa robe richement brodée ou en brocart, ainsi qu'une boucle d'oreille en perle suspendue à son oreille gauche.

Outre sa tenue anglaise, Pocahontas tient dans la main soit un éventail en plumes, accessoire courant chez les femmes de la haute société de l'époque, soit une plume à écrire. Les Européens considérant alors la maîtrise de l'écriture comme un marqueur essentiel de la civilisation, l'un comme l'autre de ces objets illustrent l'espoir des Anglais de voir les peuples autochtones adopter rapidement la culture des colons.
Le pouvoir des images
La gravure de Pocahontas n'est pas la première représentation des peuples autochtones de la côte médio-atlantique à avoir circulé en Angleterre. Les illustrations d'un ouvrage largement réédité jouèrent de leur côté un rôle déterminant pour convaincre les Anglais de fonder des colonies en Amérique du Nord.
À la fin du XVIe siècle, les promoteurs de la colonisation anglaise avaient compris que les descriptions de l'Amérique du Nord pouvaient rendre ces territoires lointains plus attractifs aux yeux des futurs colons. Ils cherchaient à persuader les hommes et les femmes d'Angleterre qu'il était possible d'y bâtir une économie prospère tout en coexistant avec les peuples autochtones.

{kind=link}
Certains promoteurs de la colonisation comprirent que les aquarelles réalisées en 1585 par l'artiste John White, représentant les Algonquiens de Caroline vivant dans les Outer Banks, pouvaient susciter l'intérêt – et attirer des investisseurs. Ces promoteurs, proches des principaux cercles de la cour d'Angleterre et du monde de l'imprimerie, virent également l'intérêt de publier l'étude approfondie de la région réalisée par le jeune mathématicien et écrivain anglais Thomas Harriot, intitulée “A Briefe and True Report of the Newfound Land of Virginia”. En 1590, ils s'associèrent à l'imprimeur flamand Theodor de Bry pour en publier une édition illustrée, contenant des gravures inspirées des peintures de John White.
L'ouvrage décrivait les modes de vie des Algonquiens de Caroline et recensait les ressources susceptibles d'être exploitées à des fins lucratives. Certains des autochtones représentés dans ses pages ne portent qu'un pagne en peau de daim. Certaines femmes portent une jupe, mais aucun vêtement sur le haut du corps.
Pour les Européens, élevés dans l'idée que couvrir entièrement son corps était un signe de civilisation, cette apparence revêtait une forte portée symbolique. Les peuples que les colonisateurs considéraient comme des « sauvages » étaient souvent représentés nus, comme les Taïnos rencontrés par Christophe Colomb un siècle plus tôt. En revanche, les Anglais qui lisaient cet ouvrage sur les Algonquiens y voyaient un peuple qui, avec l'encadrement approprié, pouvait adopter les usages anglais, y compris le christianisme protestant.
« Ils ont déjà une certaine religion », écrivait Harriot dans “A Briefe and True Report, « qui, bien qu'éloignée de la vérité, laisse espérer qu'elle pourra être réformée plus facilement et plus rapidement. »
Pour illustrer l'idée que les peuples autochtones pouvaient être convertis à la culture européenne, les graveurs ajoutèrent des représentations des anciens Bretons, prétendument inspirées d'une ancienne chronique. Trois de ces images montrent des Pictes nus, couverts de tatouages plus nombreux encore que les Algonquiens. Ces personnages sont également dépeints comme plus violents : un homme picte tient une tête fraîchement tranchée, tandis qu'une autre gît à ses pieds ; une femme picte, elle, brandit des lances et une épée large.
{kind=link}
{kind=link}
Un retour à la réalité
Lorsque Pocahontas posa pour Simon van de Passe, son portrait fit bien plus que reproduire les traits de cette jeune femme, qui mourut l'année suivante, peu après avoir quitté Londres, emportée soit par une maladie, soit, selon la tradition orale d'une tribu de Virginie, empoisonnée.
À l'image des gravures popularisées par le livre de Harriot, ce portrait suggérait que les peuples autochtones adopteraient bientôt les usages anglais. Comme le rappelle l'inscription figurant sur la gravure, Pocahontas était devenue Rebecca Rolfe après son mariage. Dans ses écrits, son mari célébrait sa conversion à la foi anglicane. Le portrait semblait ainsi offrir une preuve éclatante de ce modèle de conversion culturelle.
Le père de Pocahontas mourut en 1618. Quatre ans plus tard, les Powhatans se soulevèrent contre les colons anglais. Le 22 mars 1622, sous le commandement du chef de guerre Opechancanough, ils tuèrent environ un quart des colons installés en Virginie. Les Anglais qualifièrent cette attaque de « massacre barbare » et déclenchèrent une guerre de représailles, qui culmina notamment avec l'empoisonnement massif de Powhatans en 1623 – une action que les Anglais de l'époque savaient pourtant contraire aux principes émergents du droit de la guerre.
En voyant Pocahontas représentée assise avec élégance, coiffée d'un chapeau raffiné et tenant une plume à écrire, les Anglais avaient cru que les peuples autochtones adopteraient naturellement les usages des colons. Les événements de mars 1622 leur prouvèrent le contraire.
Peter C. Mancall a reçu des financements de the National Endowment for the Humanities, the Huntington Library, and the Mellon Foundation.
26.06.2026 à 10:28
Provinciales 2026 : les paradoxes d’une élection censée sortir la Nouvelle-Calédonie de l’impasse
Pierre-Christophe Pantz, Enseignant vacataire et chercheur associé à l'Université de la Nouvelle-Calédonie (UNC), Université de la Nouvelle-Calédonie
Texte intégral (1875 mots)
Deux ans après la date initialement prévue, les élections provinciales se tiennent enfin, ce dimanche 28 juin 2026, en Nouvelle-Calédonie. Reportées trois fois pour favoriser un accord sur l’avenir institutionnel, elles interviennent finalement après l’échec des négociations et l’abandon des accords de Bougival et d’Élysée-Oudinot. Ce scrutin met en lumière plusieurs paradoxes qui illustrent les blocages politiques actuels de l’Archipel océanien.
Le 28 juin 2026, les électeurs calédoniens renouvellent les assemblées des trois provinces ainsi que, indirectement, la composition du Congrès et du gouvernement collégial de la Nouvelle-Calédonie. Dans un territoire bipolarisé, elles constituent également un baromètre du rapport de force entre les camps indépendantiste et non indépendantiste.
Initialement prévues en mai 2024, ces élections ont été repoussées pour laisser du temps aux négociations sur l’avenir institutionnel du territoire, puis la mise en œuvre des accords de Bougival et d’Élysée-Oudinot (BEO). Inévitablement, ces reports exceptionnels ont progressivement nourri les débats sur la légitimité d’élus dont le mandat a finalement été prolongé de 40 %. Les détracteurs de ces accords ont d’ailleurs contesté la légitimité de leurs signataires, transformant ce rendez-vous électoral en séquence politique où se mêlent fatigue démocratique, incertitude institutionnelle et recomposition des rapports de force.
À première vue, ces élections pourraient apparaître comme une solution au blocage politique. Pourtant, elles révèlent surtout les difficultés qu’elles sont censées résoudre. L’élection apparaît moins comme l’aboutissement d’un compromis que comme la conséquence de l’impossibilité de faire émerger un accord suffisamment consensuel.
Le paradoxe d’élections reportées pour favoriser un accord… qui n’a jamais été trouvé
Les différents reports des provinciales ont été justifiés par la volonté de laisser du temps aux partenaires politiques pour parvenir à un compromis sur l’après-accord de Nouméa.
Or, les accords conclus à Bougival (12 juillet 2025) puis à l’Élysée-Oudinot (19 janvier 2026) n’ont finalement pas permis de faire émerger le consensus politique nécessaire à leur application. Malgré deux années de discussions après les émeutes de mai 2024, les Calédoniens votent dans un contexte d’incertitude institutionnelle largement inchangé.
Plus encore, les futurs élus auront probablement pour principale mission de participer à de nouvelles négociations dont les contours restent largement à définir. Cette situation entretient l’idée d’un processus suspendu, où l’élection ne clôt pas une phase politique, mais vient combler l’absence d’accord.
Le paradoxe d’une collectivité autonome dont l’issue dépend encore de Paris
Depuis l’accord de Nouméa signée en 1998, la Nouvelle-Calédonie est engagée dans un processus de décolonisation original au sein de la République française. Si les trois référendums (en 2018, en 2020 et en 2021 ; le troisième est contesté par le camp indépendantiste) n’ont pas réussi à refermer cette séquence, l’accord trouvé entre les partenaires à Bougival laissait entrevoir un consensus entre les acteurs locaux pour une sortie de crise. Mais c’est finalement à Paris que l’avenir institutionnel du territoire s’est joué, au gré des équilibres politiques nationaux. Les débats autour des accords proposés ces derniers mois ont montré à quel point les rapports de force à l’Assemblée nationale pesaient sur le dossier calédonien, limitant l’autonomie effective du processus local.
Dans cette configuration, le scrutin provincial agit aussi comme un signal adressé au niveau national, à l’approche des échéances électorales de 2027. Pendant la campagne, certains candidats semblent privilégier une stratégie d’attente, pariant sur les échéances nationales plutôt que sur un compromis immédiat. Cette forme de « présidentialisation » tend à suspendre les arbitrages locaux dans l’attente de l’élection présidentielle, replaçant une partie du destin institutionnel calédonien dans le calendrier politique national.
Le paradoxe d’un besoin de renouvellement… sans garantie de renouvellement
Ces élections étaient attendues comme un moyen de restaurer une légitimité politique fragilisée par l’allongement exceptionnel de la mandature (sept ans au lieu de cinq ans).
Pour autant, rien ne garantit un renouvellement significatif de la représentation politique. Le mode de scrutin provincial – scrutin de liste proportionnelle à la plus forte moyenne, combiné au seuil de 5 % des inscrits nécessaire pour obtenir des élus – favorise les formations historiques les plus unies, tout en pénalisant l’éparpillement des voix et l’émergence d’une troisième voie.
Dans ce cadre, le renouvellement politique attendu par une partie des électeurs se heurte à des mécanismes institutionnels qui tendent à reproduire les équilibres existants.
Le paradoxe d’une offre politique plus diversifiée que jamais mais une fragmentation à l’issue incertaine
À l’instar de 2019, la campagne de 2026 se caractérise par une fragmentation, particulièrement en province Sud, qui cristallise les principaux enjeux de ce scrutin.
Quatre listes se réclament d’un espace central cherchant à dépasser l’opposition traditionnelle entre indépendantistes et non-indépendantistes. Elles privilégient les enjeux économiques, sociaux et de gouvernance, reléguant souvent la question institutionnelle au second plan.
Cette diversification traduit des attentes nouvelles, mais elle se heurte à un risque structurel : voir plusieurs de ces listes échouer à franchir le seuil d’éligibilité et transformer une part des suffrages en voix non représentées.
Dans le même temps, le camp indépendantiste connaît une division inédite en province Sud. Après plus de vingt ans de listes communes, l’UNI-Palika et le FLNKS se présentent séparément, accentuant une fragmentation qui ravive le souvenir de 2004, lorsque, en l’absence d’unité, aucun élu indépendantiste n’avait été désigné en province Sud. En face, le camp non indépendantiste, malgré une union majoritaire autour des loyalistes et du Rassemblement, doit composer avec l’émergence de deux listes concurrentes situées à sa droite.
Le paradoxe d’un scrutin local aux conséquences institutionnelles majeures
Enfin, ces élections illustrent une singularité calédonienne : bien que juridiquement provinciales, leurs effets dépassent le cadre local.
Pourtant, ce sont les équilibres issus du scrutin qui détermineront la composition du Congrès, la formation du gouvernement et le rapport de force dans les futures négociations avec l’État. Le scrutin agit ainsi moins comme une élection de gestion locale que comme un baromètre institutionnel.
De manière asymétrique, la bataille décisive se joue donc en province Sud, où se concentre l’essentiel du poids électoral du territoire.
Une participation sous surveillance
Alors que les provinciales pourraient constituer un moment de clarification démocratique, une abstention élevée prolongerait en réalité une tendance déjà ancienne. Depuis 2004, la baisse de la participation se vérifie scrutin après scrutin, s’inscrit dans la durée et ne se limite ni aux contextes de crise ni aux seules séquences électorales récentes. Elle traduit une forme de rejet progressif de la population vis-à-vis des partis, des élus et, plus largement, du fonctionnement institutionnel.
Ce phénomène s’accompagne d’un brouillage des repères politiques et d’un éloignement des enjeux institutionnels du quotidien. Des initiatives de démocratie participative ont émergé au Congrès, traduisant une recherche de nouvelles formes de légitimité. Mais cette dynamique reste fragile face à une tendance de fond plus large de défiance politique, désormais installée dans la durée.
« Le pari de la confiance »
Au fond, même si le nouveau rapport de force politique issu des urnes aura une importance capitale pour la reprise des négociations, l’enjeu du 28 juin ne se limite pas à la désignation des vainqueurs. Dans un paysage politique particulièrement fragmenté, marqué par l’émergence d’un espace central susceptible de jouer un rôle d’arbitre, la question est aussi celle de la capacité des institutions à dégager une majorité politique suffisamment légitime pour relancer le dialogue sur l’avenir du pays.
Le principal enseignement ne résidera peut-être pas dans la seule configuration des assemblées provinciales, du Congrès et du gouvernement, mais dans la capacité des nouveaux élus à restaurer une confiance effritée. Ce n’est sans doute pas un hasard si l’accord de Bougival avait été sous-titré « Le pari de la confiance ».
Car le dernier paradoxe de ces provinciales est peut-être le plus déterminant : une élection organisée pour contribuer à sortir d’une impasse politique pourrait aussi en révéler toute la profondeur.
Pierre-Christophe Pantz ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 15:29
Quand l’IA s’invite dans nos relations, la véritable intimité tend à disparaître
Luke Brunning, Lecturer in Applied Ethics, University of Leeds
Texte intégral (1662 mots)

À l’heure où les outils d’IA générative sont à portée de clic, il est tentant de les interroger autour de petits et grands problèmes de la vie. Mais les solliciter comme des coachs pour nos interactions sociales et amoureuses est-il sans risques ? Ce qui relève de l’intime ne nécessite-t-il pas justement de la curiosité et du lâcher-prise ?
Le PDG de l’application de rencontres Hinge a récemment laissé entendre que la génération Z, qui « peine à trouver la confiance nécessaire pour se mettre en avant », utilise des outils d’intelligence artificielle (IA) pour l’aider à trouver l’amour. Elle a expliqué que les suggestions de conversation générées par l'IA de Hinge visent à aider les utilisateurs à exprimer qui ils sont.
De l’essor fascinant des applications de rencontre basées sur l’IA et de leur impact social incertain jusqu’au battage médiatique autour des entreprises d’applications de rencontre promettant une révolution dans le domaine des rencontres en ligne, partout où l’intimité peut être encouragée par l’IA, il existe une entreprise qui encourage les gens à en tirer parti.
Des applications d’IA tierces sont utilisées pour rendre nos conversations plus drôles ou nos profils plus séduisants. Les gens utilisent des outils d’IA spécialement conçus pour les entraîner à mieux communiquer avec les autres, ou se contentent d’utiliser des chatbots existants comme ChatGPT pour gérer les conflits dans leurs relations ou gérer leur vie sociale.
Préjugés et failles de confidentialité
Comprendre comment l’IA façonne la vie intime fait partie de mon travail en tant que chercheur spécialiste de l’amour et des relations. Ce qui a commencé comme un exercice théorique, explorant la signification morale d’une utilisation possible de l’IA, a rapidement trouvé un prolongement dans une salle de classe.
Un étudiant en commerce m’a raconté un jour comment il avait utilisé un modèle d’IA pour l’aider à résoudre un désaccord avec sa petite amie. « C’était comme un ami », m’a-t-il dit, « et ça m’a aidé à mieux comprendre le point de vue de ma petite amie ». L’IA l’a aidé à exprimer ses propres sentiments avec plus de clarté et à s’entraîner à mener une conversation difficile. Qui ne serait pas tenté d’utiliser ces outils pour bénéficier d’un soutien lorsqu’il s’agit de sortir avec quelqu’un, de se faire des amis, de gérer des tensions familiales ou de prendre soin de sa santé mentale ?
Il existe des raisons évidentes d’inviter à la prudence face à ces tentations, du moins jusqu’à ce que nous ayons une meilleure compréhension de leurs effets à long terme. Les experts s’inquiètent de la précision de l’IA lorsqu’elle émet des conseils, ainsi que du fait que ces outils et modèles sont entraînés sur des données qui reflètent toute une série de préjugés sur les êtres humains, leurs interactions et ce à quoi ressemble une bonne intimité. Il existe également des préoccupations de longue date en matière de confidentialité concernant les risques liés au partage de nos vies les plus intimes avec des entreprises technologiques.
Une compréhension simpliste de l’intimité
Il existe des raisons moins évidentes, mais d’autant plus importantes, d’être prudent. Celles-ci sont liées à la nature même de l’intimité.
La normalisation du recours à l’IA pour servir d’intermédiaire et façonner l’intimité sape la curiosité de soi. Les tentatives visant à anticiper la vie intime, à modeler et à affiner les interactions, ainsi qu’à éviter les désaccords ou les frictions émotionnelles, risquent de remplacer le désir de découvrir ce que nous pensons, ressentons et voulons sur le moment.
L’attrait du contrôle prend le pas sur les bienfaits et le plaisir de la curiosité. Des recherches empiriques suggèrent que les personnes curieuses sont apparemment moins hostiles, plus ouvertes à l’inconnu et plus disposées à laisser les autres s’exprimer, et que la curiosité nous aide à éviter les excès liés aux déséquilibres de pouvoir – autant de facteurs importants dans l’intimité.
La facilité d’accès aux outils d’IA destinés à favoriser l’intimité peut conduire à se laisser tenter par une compréhension simpliste de la vie intime elle-même. Les rencontres amoureuses, par exemple, risquent d’être perçues comme un défi à relever, la conversation comme un domaine dans lequel il faut exceller, et les disputes comme des batailles à gagner. L’intimité est bien plus qu’un jeu dans lequel on échange des propos jusqu’à atteindre une satisfaction mutuelle. L’intimité est désordonnée, dynamique, incarnée et imprévisible. La véritable intimité, c’est l’improvisation, pas un récit scénarisé.
Lâcher prise et prendre des risques
Certains peuvent avancer que les outils d’IA nous aident à acquérir les compétences nécessaires pour tirer son épingle du jeu dans cette improvisation chaotique. Mais, de mon point de vue, c’est plutôt faux. Tout comme il a été démontré que l’IA pouvait nous appauvrir en compétences professionnelles, ou rendre les gens moins aptes à raisonner de manière critique, nous devrions craindre qu’elle n’entraîne une déqualification intime : l’érosion des capacités nécessaires pour imaginer, rechercher et entretenir l’intimité que nous désirons.
Ces compétences – que j’appelle « l’autonomie amoureuse » – se développent et se maintiennent dans la pratique. Aucun conseil ni aucun modèle de phrases de drague ne peuvent remplacer le pouvoir d’action que nous procure le fait de nous découvrir, en situation, en menant des conversations difficiles, en prenant des risques, en faisant le premier pas et en exprimant nos sentiments.
Il y a là aussi des considérations esthétiques. Voulons-nous vraiment que notre vie intime prenne ce ton homogène, fade et dépourvu de nuances culturelles que privilégie l’IA générative ? Les choses sont meilleures et plus riches lorsque nous embrassons ce que le philosophe libéral John Stuart Mill appelait les « expériences de vie ». L’exploration, l’incohérence, l’esprit ludique et le plaisir de s’exprimer doivent être célébrés. L’humanité et l’attention se manifestent autant dans la manière dont nous communiquons que dans ce que nous communiquons.
Les entreprises qui cherchent à s’immiscer dans notre vie intime à l’aide de leurs outils d’IA nous promettent de nous rendre plus performants et de nous aider à réussir sur le « marché des rencontres ». Mais nous devrions refuser ce discours. On a un jour demandé à Daniel Arnold, photographe de rue influent, pourquoi il préférait encore photographier sur pellicule plutôt que d’utiliser des appareils numériques, plus faciles et plus immédiats. Sa réponse : « La photographie numérique est un dialogue avec le succès, tandis que la photographie argentique est un dialogue avec l’échec. » Photographier en argentique signifie ne pas « être précieux, calculateur », mais vivre l’instant présent, agir et voir comment les choses se déroulent.
C’est pour cette même raison que nous devrions embrasser l’intimité « à l’ancienne », sans l’intervention de l’IA. C’est en lâchant prise et en renonçant à la possibilité de s’entraîner, d’ajuster et de peaufiner notre approche avant d’aller vers quelqu’un que la véritable aventure de l’intimité peut commencer.
Luke Brunning ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 15:28
De Southampton à Belfast : comment Nigel Farage fait entrer les thèmes de l’extrême droite dans le débat public britannique
Karine Tournier-Sol, Professeur de civilisation britannique contemporaine, Université de Toulon
Texte intégral (2609 mots)
Les émeutes racistes de Southampton, en Angleterre, et de Belfast, en Irlande du Nord, début juin 2026, illustrent la manière dont certains faits divers impliquant des immigrés sont mobilisés par Nigel Farage et les autres forces britanniques d’extrême droite pour alimenter les débats sur l’immigration et dénoncer un supposé traitement discriminatoire des Britanniques blancs. En durcissant son discours autour d’un « racisme anti-Blancs » et du slogan White Lives Matter, Farage, qui fait la course en tête dans les sondages conduits en vue d’éventuelles législatives anticipées, contribue à normaliser des thèmes auparavant cantonnés aux marges de l’extrême droite.
Les récents événements survenus à Southampton puis à Belfast ont fourni à Nigel Farage une nouvelle occasion de relancer le débat sur l’immigration, thème central du projet politique porté par Reform UK. Dans les deux cas, un crime particulièrement choquant commis par une personne issue de l’immigration a servi de déclencheur. Le leader de Reform UK s’en est emparé pour dénoncer les conséquences de ce qu’il qualifie d’immigration de masse et ce qu’il présente comme un traitement injuste des Britanniques blancs par les autorités.
Ces épisodes s’inscrivent dans une dynamique observable depuis les émeutes de Southport à l’été 2024, où certains faits divers sont récupérés à des fins politiques. Ce phénomène ne se limite pas à Nigel Farage : il mobilise plus largement l’ensemble de l’écosystème d’extrême droite britannique. Farage y joue toutefois un rôle singulier, en contribuant à faire entrer dans le débat public des thèmes longtemps restés cantonnés aux marges de l’extrême droite.
Southampton : de l’émotion à la récupération politique
À Southampton d’abord, dans le sud de l’Angleterre, les violences ont suivi la diffusion, le 1er juin, d’une vidéo de l’arrestation d’Henry Nowak. Ce jeune étudiant de 18 ans avait été poignardé, le 3 décembre dernier, par Vickrum Digwa, membre de la communauté sikh. Alertés par le frère de Digwa, qui avait signalé une prétendue agression raciste contre ce dernier, les policiers arrivés sur les lieux traitent Digwa comme la victime et Nowak comme le suspect. Sur les images enregistrées par les caméras embarquées des policiers, on les voit procéder à l’arrestation de Nowak et le menotter alors qu’il gît au sol, mortellement blessé. On l’entend répéter aux policiers qu’il a été poignardé et qu’il ne peut plus respirer – « I can’t breathe », les mêmes mots que George Floyd avant sa mort en 2020 – mais ceux-ci ne le croient pas. Il perd connaissance avant de succomber à ses blessures.
La diffusion de ces images a suscité une vive émotion dans le pays. Alors que le père de Nowak avait demandé à ce que la mort de son fils ne soit pas exploitée pour attiser les tensions et la haine, c’est précisément l’inverse qui s’est produit.
Nigel Farage a été prompt à s’emparer de ce fait divers tragique. Dans une vidéo publiée sur les réseaux sociaux, il a établi le parallèle avec George Floyd et le mouvement Black Lives Matter, mais en inversant la lecture : il a dénoncé une « société à deux vitesses » dans laquelle « les droits et les privilèges des Blancs comptent moins que ceux des minorités ethniques » ; il a appelé à mettre fin aux « préjugés anti-Blancs », ajoutant que « les vies des Blancs comptent autant que celles des Noirs » (« White Lives Matter just as much as Black Lives ») ; il a également remis en cause les politiques destinées à lutter contre les discriminations et à améliorer la représentation des minorités. Enfin, il a encouragé les Britanniques à réagir avec une « rage pure et froide » à l’assassinat de Henry Nowak.
Dans le même temps, l’ensemble de la mouvance d’extrême droite s’est rapidement mobilisée. Le 2 juin au soir, une manifestation organisée devant le commissariat de Southampton a dégénéré en affrontements avec la police. Au sein d’une foule mêlant habitants locaux bouleversés par la tragédie et militants venus porter un message politique, l’activiste d’extrême droite Tommy Robinson, de son vrai nom Stephen Yaxley-Lennon, a appelé à obtenir « justice pour Henry », dénonçant une « police raciste » et affirmant que « les Blancs sont traités comme des citoyens de seconde zone par le gouvernement ». À ses côtés se trouvaient plusieurs figures de l’extrême droite britannique.
Belfast : une mécanique similaire
Une semaine plus tard, l’agression au couteau de Stephen Ogilvie à Belfast (Irlande du Nord) par un réfugié soudanais a une nouvelle fois servi de déclencheur, reproduisant la même mécanique : amplification sur les réseaux sociaux, récupération politique et mobilisation de militants d’extrême droite sur le terrain. Grièvement blessé lors de l’attaque, Ogilvie a survécu mais a perdu un œil.
Les images de l’agression ont rapidement circulé sur les réseaux sociaux et ont été relayées par l’ensemble de l’écosystème d’extrême droite britannique, de Reform UK à Tommy Robinson, en passant par Restore Britain, nouveau parti fondé par Rupert Lowe après sa rupture avec Reform UK. Robinson a notamment relayé les lieux des rassemblements prévus, une publication ensuite partagée par Elon Musk.
Malgré les appels au calme des responsables politiques nord-irlandais et de la police, une nuit de violence a suivi, pendant laquelle des dizaines de militants d’extrême droite, souvent vêtus de noir et masqués, ont incendié des véhicules, des commerces et des logements dans ce qui s’apparente à une véritable chasse aux étrangers. Ces violences ont été qualifiées de « pogroms racistes » par plusieurs médias.
Un schéma désormais récurrent
La séquence de Southampton et Belfast n’est pas nouvelle. Il s’agit là d’un schéma désormais récurrent, qui s’observe régulièrement au Royaume-Uni depuis les émeutes qui ont suivi le meurtre de trois fillettes à Southport (Angleterre) en juillet 2024. À l’époque déjà, une campagne de désinformation sur les réseaux sociaux avait présenté à tort l’auteur de l’attaque comme un demandeur d’asile musulman récemment arrivé dans le pays. L’information s’était propagée rapidement, alimentant des manifestations largement investies par l’extrême droite qui avaient dégénéré en violences dans plusieurs villes britanniques.
Nigel Farage, fraîchement élu à Westminster, s’était alors retrouvé au cœur de la controverse. C’est à cette occasion qu’il avait repris à son compte l’expression de « police à deux vitesses » (two-tier policing), contribuant à faire entrer dans le débat public un thème jusque-là largement cantonné aux marges de l’extrême droite britannique. Il établissait déjà un parallèle avec les manifestations Black Lives Matter de 2020, affirmant que les personnes y ayant participé avaient bénéficié d’un traitement plus favorable de la part de la police.
Le même phénomène s’est reproduit à l’été 2025 à Epping (Angleterre), après l’agression sexuelle d’une adolescente par un demandeur d’asile. Partie d’une émotion bien réelle au sein de la population locale, la mobilisation a rapidement été investie par l’extrême droite et a débouché sur une vague de manifestations à travers le pays devant des hôtels hébergeant des demandeurs d’asile. Certaines de ces mobilisations ont dégénéré et plusieurs établissements ont été pris pour cible.
Tous les faits divers ne suscitent pas une telle mobilisation. Ceux qui sont mis en avant par l’extrême droite sont ceux qui peuvent être reliés à la question migratoire. Le fait divers devient alors la preuve supposée d’un problème plus général lié à l’immigration de masse. Les réseaux sociaux jouent un rôle essentiel dans cette dynamique, permettant à la fois la circulation rapide d’informations –et de désinformation – et la coordination des mobilisations.
Quand les thèmes des marges gagnent le centre
On l’a vu, Nigel Farage n’est pas le seul acteur à s’emparer de ces faits divers. Mais ce qui distingue Farage est sa capacité à récupérer des éléments de langage issus des marges de l’extrême droite et à les placer au cœur du débat public.
Les scandales liés aux grooming gangs, ces réseaux d’exploitation sexuelle de jeunes filles dans lesquels des hommes d’origine pakistanaise étaient surreprésentés, illustrent bien cette dynamique. Farage a contribué très tôt à politiser cette affaire. Mais d’autres figures de l’extrême droite, comme Tommy Robinson et Rupert Lowe, s’en sont également emparées.
Les événements de Southampton et de Belfast marquent une nouvelle étape. Jusqu’à présent, Farage dénonçait principalement les conséquences de l’immigration, l’échec des politiques migratoires ou encore ce qu’il qualifie de « police à deux vitesses ». Avec les références aux « préjugés anti-Blancs », au « racisme anti-Blancs » ou encore au slogan « White Lives Matter », il franchit désormais un nouveau cap.
L’ensemble de ces thèmes repose sur une même idée : celle selon laquelle les Britanniques blancs seraient aujourd’hui victimes d’un traitement injuste ou discriminatoire. En reprenant à son compte ces éléments de langage, Farage participe à diffuser bien au-delà des marges de l’extrême droite des thèmes qui y circulaient déjà depuis plusieurs années, contribuant ainsi à leur normalisation.
Cette évolution témoigne d’une nouvelle radicalisation discursive. Alors que Farage et ses partis successifs s’étaient jusqu’à présent inscrits dans un nationalisme civique, les références aux « Blancs » et au « racisme anti-Blancs » introduisent une dimension plus explicitement raciale.
Pourquoi Farage durcit son discours
Cela peut sembler paradoxal. Nigel Farage s’est toujours efforcé de tracer une ligne de démarcation claire avec les partis d’extrême droite, et en particulier avec la figure de Tommy Robinson. Cette stratégie lui a permis de se présenter comme une alternative plus respectable tout en défendant des positions très fermes sur l’immigration. Le chercheur Aurélien Mondon parle à cet égard de « légitimation par contraste » : en se distinguant de figures plus extrêmes, Farage apparaît plus modéré. Le curseur de ce qui est acceptable dans le débat public est déplacé vers la droite, et on assiste à une normalisation des idées et du discours anti-immigration.
Aujourd’hui pourtant, alors que Reform UK fait la course en tête dans les sondages depuis plus d’un an et tente de se présenter comme un parti de gouvernement crédible, la radicalisation récente du discours de Farage, mais aussi de la politique migratoire prônée par Reform UK, peut sembler contre-intuitive.
Elle peut se lire comme une stratégie pour tenter de contrer la pression exercée sur sa droite : Robinson jouit d’une popularité importante parmi les membres de Reform UK (61 % ont une opinion favorable de lui). Sa manifestation Unite the Kingdom, qui a rassemblé 150 000 personnes à Londres en septembre 2025, témoigne également de sa capacité de mobilisation.
À cette concurrence s’ajoute désormais celle de Rupert Lowe. Depuis sa rupture avec Reform UK et la création de Restore Britain, il cherche à incarner une option alternative plus radicale à Farage. Les enquêtes montrent qu’il bénéficie lui aussi d’une image positive auprès d’une large partie des membres de Reform UK, et l’élection partielle de Makerfield (très suivie dans l’ensemble du pays, car elle s’est soldée par l’élection du travailliste Andy Burnham, qui peut désormais briguer le poste de premier ministre laissé vacant par Keir Starmer) a montré sa capacité à capter une partie de l’électorat de Reform UK : la candidate de Restore Britain Rebecca Shepherd a glané quelque 7 % des suffrages, dont une grande partie seraient sans doute allés, si elle ne s’était pas présentée, au représentant de Reform UK Robert Kenyon (34,7 %).
Cela agace visiblement Nigel Farage, qui s’efforce publiquement de minimiser la portée de cette menace, mais on peut penser que sa radicalisation supplémentaire est une tactique pour tenter de la désamorcer.
Il y a d’ailleurs une certaine ironie à cette situation. Farage accuse aujourd’hui Lowe d’entraver les perspectives de Reform en scindant le vote de droite. Or c’est précisément ce qu’il a lui-même fait pendant des années au parti conservateur avec ses partis successifs, du UKIP à Reform UK. L’arroseur est, aujourd’hui, arrosé.
Les événements de Southampton et de Belfast illustrent un phénomène qui dépasse largement ces deux affaires. En reprenant des thèmes et des éléments de langage longtemps associés aux marges de l’extrême droite, Nigel Farage contribue à les installer au cœur du débat politique britannique. Plus encore que ses succès électoraux, c’est peut-être là que réside aujourd’hui son influence la plus durable.
Karine Tournier-Sol ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 15:27
Comment la « nouvelle norme » de l’été 2026 met à l’épreuve la résilience climatique de l’Europe
Júlia de Freitas Sampaio, Postdoctoral researcher, University of Luxembourg
Texte intégral (1772 mots)
Alors que les populations d’une large partie de l’Europe suffoquent sous une vague chaleur sans précédent, l’urgence est d’adopter enfin des mesures coordonnées au plus haut niveau pour faire face à ces températures extrêmes.
Nous ne sommes qu’en juin, mais l’Europe subit déjà sa deuxième vague de chaleur extrême en deux mois. Les températures ont dépassé les 44 °C dans plusieurs régions du continent. Des alertes canicule sont désormais en vigueur dans plusieurs pays, dont six au niveau rouge, le plus extrême.
La France a placé 72 de ses 96 départements en alerte rouge. Au moins 40 personnes se sont noyées en tentant d’échapper à la chaleur.
En Espagne, les températures ont atteint un pic de 45,1 °C, avec 101 décès liés à la chaleur recensés rien qu’au mois de mai, soit le chiffre le plus élevé jamais enregistré pour ce mois.
Le Royaume-Uni a battu son record historique de température pour le mois de juin. Les villes ferment les écoles, les réseaux électriques sont mis à rude épreuve et les hôpitaux signalent une forte augmentation des urgences liées à la chaleur.
Mais rien de tout cela n’aurait dû être une surprise.
L’Europe est le continent qui se réchauffe le plus rapidement sur Terre, à un rythme environ deux fois supérieur à la moyenne mondiale, et les scientifiques alertent depuis des décennies sur le fait que le changement climatique d’origine humaine allait rendre les vagues de chaleur plus fréquentes et plus intenses. Les projections actuelles prévoient que les cinq prochaines années battront encore davantage de records, faisant de ce phénomène une « nouvelle norme ».
Les étés que les Européens ont connus dans leur enfance n’existent plus. Les vagues de chaleur extrême ne constituent plus une anomalie, mais la nouvelle référence. Autrement dit, la question n’est plus de savoir si ces vagues de chaleur reviendront, mais si les villes européennes seront capables d’y résister.
Une catastrophe climatique qui n’est pas traitée comme telle
Les vagues de chaleur extrêmes font plus de victimes en Europe que tout autre phénomène climatique.
Selon l’Organisation mondiale de la santé (OMS), plus de 175 000 personnes meurent chaque année à cause de la chaleur sur l’ensemble du continent européen.
Malgré ces chiffres, les températures extrêmes n’ont pas été traitées avec la même urgence que d’autres catastrophes, telles que les tempêtes, les feux de forêt ou les inondations. La plupart des gouvernements continuent d’improviser sans réponse coordonnée face aux vagues de chaleur extrême, celles-ci étant encore trop souvent considérées comme un simple désagrément météorologique plutôt que comme un danger mortel.
Ce cadrage commence toutefois à évoluer. Lors de la COP30, le Bureau des Nations unies pour la réduction des risques de catastrophe (NDRR) a lancé un nouveau cadre de gouvernance des risques liés aux vagues de chaleur extrême. Il a officiellement reconnu la canicule comme l’une des menaces climatiques les plus meurtrières et les moins bien gérées à l’heure actuelle.
Bien que ce cadre constitue un pas en avant, des décennies de politiques fragmentées, une réflexion axée sur les crises à court terme et un sous-investissement chronique dans les services publics ont laissé l’Europe dangereusement exposée.
En conséquence, chaque été qui s’écoule sans progrès significatifs est un été de plus qui coûtera des vies humaines.
L’Europe n’est pas construite pour ça
Un rapport récent de la Commission britannique sur le changement climatique a fait valoir que le pays a été conçu pour un climat qui n’existe plus, avertissant que les températures dépassant les 40 °C deviennent de plus en plus courantes. On pourrait en dire autant de pratiquement tous les pays européens.
Les villes ont été conçues pour une autre époque, avec des routes, des trottoirs et des bâtiments en béton qui absorbent et retiennent la chaleur plutôt que de la réfléchir, transformant les zones urbaines en véritables fournaises dont la température est supérieure de quatre à six degrés par rapport à leur environnement.
Plusieurs villes européennes ont déjà pris des mesures. Par exemple, Paris s’est engagée à planter 170 000 arbres dans les espaces publics, et Marseille procède au débitumage de places historiques et cartographie les itinéraires piétonniers ombragés.
Certains pays prennent des mesures en remplaçant les revêtements routiers classiques par des surfaces rafraîchissantes et de la peinture routière réfléchissante, en repensant les codes de construction et les espaces publics dans une optique de refroidissement passif.
Mais aucune de ces mesures ne s’attaque au problème sous-jacent. L’Europe continue d’être largement alimentée par les énergies fossiles, et ses systèmes alimentaires, son parc immobilier et ses réseaux de transport ont tous un lourd bilan carbone.
L’empreinte carbone de l’Union européenne (UE) s’élève à environ 9 tonnes équivalent CO₂ par personne et par an, ce qui est bien supérieur à la moyenne mondiale, qui est d’environ 5 tonnes.
Des progrès sont certes en cours, mais leur rythme n’est pas assez rapide.
Voyager en train reste plus cher que l’avion sur de nombreux itinéraires. Les normes de construction autorisent encore celle de bâtiments qui deviendront bientôt inhabitables. Les « îlots de fraîcheur » urbains, les cheminements ombragés dans l’espace public et les actions de proximité proactives auprès des personnes âgées vivant seules restent l’exception plutôt que la règle.
À lire aussi : « Refuges climatiques » : pourquoi l’Espagne est déjà une référence mondiale en matière de lutte contre les chaleurs extrêmes
Des plans d’action en cas de canicule existent dans certaines villes, mais peu d’entre eux sont juridiquement contraignants. Encore moins de localités disposent des budgets nécessaires pour concrétiser leurs ambitions.
Les actions individuelles ont leur importance – manger moins de viande ou prendre moins l’avion font certes une différence à grande échelle, mais le compte à rebours continuera tant que les émissions ne seront pas réduites à la source.
Les actions individuelles ne peuvent se substituer à des changements systémiques que seuls les gouvernements et les institutions sont en mesure de mettre en œuvre.
En matière de changement climatique, l’adaptation et l’atténuation doivent aller de pair. Aucun de ces deux volets ne saurait attendre.
La fenêtre d’action se rétrécit
L’UE prépare une stratégie de résilience climatique qui devrait être présentée fin 2026 et introduire des règles juridiquement contraignantes et des outils de suivi afin de coordonner les actions entre les États membres. C’est un pas dans la bonne direction.
Mais, comme le montre clairement la vague de chaleur de cette semaine, le fossé entre ce qui est prévu et ce qui se passe déjà sur le terrain ne cesse de se creuser rapidement.
La question n’est pas seulement de savoir comment faire face à la prochaine vague de chaleur, mais surtout de savoir comment gouverner, financer et reconstruire un continent qui vit déjà dans un futur différent.
Júlia de Freitas Sampaio ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 15:26
Pourquoi l’Europe a besoin d’une Bourse unique et transparente
Angelo Riva, Economist, Professor at the INSEEC Grande Ecole, Affiliate Researcher at the Paris School of Economics, Academic Fellow at the Institut Louis Bachelier, INSEEC Grande École
Texte intégral (1899 mots)
En promouvant un marché pour les marchés financiers, l’Union européenne stimule une forme de concurrence. À qui profite vraiment cette dernière ? Aux grandes entreprises ? Aux PME ? Aux investisseurs privés ? Reste qu’un marché financier unique – la Bourse européenne – aurait des avantages nombreux. Quels sont-ils ? Comment y parvenir ?
Dans le sillage des rapports Letta (2024) et Draghi (2025), la question d’une bourse européenne unique est revenue d’actualité. Le chancelier allemand Friedrich Merz a appelé à créer un marché des capitaux suffisamment large et profond pour que les entreprises européennes se financent plus facilement. Christine Lagarde, présidente de la BCE, a formulé le même diagnostic : l’Europe souffre d’une fragmentation excessive des marchés financiers.
En effet, l’Union européenne compte 295 plateformes de trading, 14 chambres de compensation et 32 dépositaires centraux. Pour Lagarde et Merz, cette dispersion draine la liquidité, affaiblit les introductions en Bourse et pousse les entreprises à chercher des capitaux ailleurs. Faut-il laisser les échanges se disperser entre des centaines de plateformes, souvent opaques, ou les concentrer sur un marché unique et transparent ?
L’Union européenne a fait le choix de la dispersion avec la directive Market in Financial Instruments Regulation (MiFIR, 2007), en organisant un « marché pour les marchés » où de nombreuses plateformes se concurrencent pour attirer les ordres. Cette concurrence peut réduire les commissions payées par les investisseurs pour négocier sur un marché et améliorer la liquidité, surtout pour les grandes entreprises dont les titres sont arbitrés, souvent à haute fréquence, entre plusieurs places.
À lire aussi : Les nouvelles technologies bouleversent le secteur de la finance
Un impact sur la qualité des marchés
Toutefois, ses effets sont plus incertains pour les petites et moyennes entreprises. Surtout, lorsque des plateformes opaques concurrencent des marchés transparents, la plupart des travaux soulignent une dégradation de la qualité de marché : les grandes institutions financières, mieux informées et capables d’intervenir sur plusieurs plateformes, en tirent avantage, au détriment des autres investisseurs.
La Bourse est une institution qui transforme l’épargne en investissement. Lorsqu’une entreprise veut se développer, elle peut émettre et vendre ses titres sur le marché primaire auprès d’investisseurs. Mais ceux-ci n’acceptent de les acheter que s’ils sont assurés de pouvoir les revendre rapidement, à un prix « sincère », selon l’expression utilisée dans la France du XIXᵉ siècle, c’est-à-dire un prix qui reflète fidèlement la rencontre entre l’offre et la demande.
Liquide et transparent
La qualité du marché secondaire, celui où les titres déjà émis s’échangent, est donc essentielle. Plus un marché est liquide, plus il est facile d’acheter ou de vendre rapidement sans faire varier fortement le prix. Plus il est transparent, plus les investisseurs peuvent observer les prix et les volumes, moins ils craignent d’être désavantagés face aux grandes institutions financières.
C’est ici qu’une bourse unique et transparente présente de grands avantages. Si les ordres sont concentrés sur un même marché transparent, ils se rencontrent plus facilement. Les prix reflètent mieux l’information disponible. L’épargne est alors mieux orientée : les entreprises solides peuvent se financer à moindre coût, tandis que les investisseurs disposent de signaux de prix plus fiables.
L’histoire financière montre que ces effets ne dépendent pas d’une conjoncture spécifique ni d’un contexte macroéconomique ou institutionnel particulier. Le déclin du marché obligataire du New York Stock Exchange (NYSE) et son déplacement vers les marchés de gré à gré (marchés Over-the-Counter, ou OTC) en offrent une illustration éclairante. Jusqu’à la fin des années 1920 pour les obligations municipales et au milieu des années 1940 pour les obligations d’entreprises, le NYSE proposait en effet un marché transparent, où les coûts de transaction étaient nettement inférieurs à ceux observés sur les marchés OTC fragmentés du début du XXIᵉ siècle.
Cette transparente prénégociation favorisait les investisseurs particuliers. Progressivement, les grandes institutions financières ont déplacé la négociation obligataire vers les marchés OTC qui répondaient davantage à leurs intérêts, en leur offrant flexibilité, commissions négociables et opportunités de rentes informationnelles. Une fois la liquidité déplacée vers le marché de gré à gré, les externalités de réseau ont verrouillé ce nouvel équilibre.
Une alternance de régimes
Dans un autre contexte, au tournant du XXᵉ siècle, la Bourse de Paris détenait un monopole légal sur les titres cotés, contesté par « la Coulisse », marché de gré à gré très actif. Des réformes très rapprochées ont fait alterner trois régimes : concurrence illégale avant 1893, concurrence libre jusqu’en 1898, puis rétablissement du monopole. Dans les années 1890, la Coulisse dominait en volume, mais cette concurrence a dégradé la qualité du marché.
En effet, après la violente crise de 1895, qui avait son épicentre en Coulisse, le retour au monopole et l’imposition de règles de transparence à la Coulisse ont permis de recentrer les échanges sur la Bourse, tandis que la Coulisse se spécialisait sur des titres plus jeunes et risqués. La qualité globale du marché parisien s’en est trouvée nettement améliorée.
À lire aussi : Le grand bond en arrière de Donald Trump sur la Fed, la Réserve fédérale des États-Unis
Autre exemple : entre 1890 et 1913, les bourses de Milan et de Gênes, pourtant soumises à une législation commune, ont développé des organisations très différentes. À Gênes un marché opaque, animé par un grand nombre d’intermédiaires et fortement influencé par les grandes banques, capables d’exploiter leur avantage informationnel. À Milan, au contraire, un marché plus restreint et organisé, fondé sur la criée, assurait une plus grande transparence. Malgré des volumes plus élevés à Gênes jusqu’en 1907, la qualité du marché y était inférieure, et cette opacité a contribué à fragiliser le système, faisant de la place génoise l’épicentre de la crise de 1907. Les autorités ont alors imposé un alignement sur le modèle milanais, entraînant une centralisation des échanges et une amélioration durable de la qualité de marché.
Au-delà de la concurrence ?
La leçon est claire : la concurrence n’est pas la panacée. Lorsque les transactions se dispersent et, notamment, se déplacent vers des lieux où les ordres ne sont pas visibles, le prix public devient moins représentatif. Les investisseurs qui restent sur le marché transparent voient une partie de la liquidité leur échapper. En pratique, la qualité de marché se détériore, surtout pour les moins puissants : petits investisseurs et entreprises.
Un marché européen unique et transparent ne résoudrait pas tout, mais il répondrait à une faiblesse structurelle. Il renforcerait la compétitivité de l’Europe face aux grandes places états-uniennes, aux marchés intégrés par un réseau informatique unique, le consolidated tape. Les Européens, quand ils investissent et entreprennent, alimentent trop souvent avec leur épargne et leurs entreprises les places américaines. En 2024, la capitalisation boursière des places européennes représentait environ 73 % du PIB de l’Union européenne, contre 270 % du PIB aux États-Unis.
Un obstacle essentiellement politique
Comme l’illustrent les prises de position de Merz et de Lagarde, ces faiblesses et ces risques apparaissent désormais de plus en plus clairement. Pourtant, l’obstacle principal à la consolidation en Europe est politique. La formation d’un marché européen unifié se heurte à la tension entre Paris et Francfort. Euronext, qui regroupe notamment Paris, Amsterdam, Bruxelles, Lisbonne, Dublin, Oslo et Milan, se présente comme le candidat naturel à la consolidation. Mais Deutsche Börse, l’opérateur de Francfort, est plus grand, plus diversifié, et contrôle des infrastructures majeures, comme Eurex et Clearstream.
Derrière cette rivalité industrielle se jouent des enjeux de souveraineté financière : qui contrôlerait la formation des prix ? Où seraient localisées les infrastructures stratégiques ? Quel superviseur aurait le dernier mot ? Les résistances institutionnelles sont fortes, car une Bourse européenne déplacerait du pouvoir économique entre États. Cette difficulté n’est pas nouvelle. Des tentatives de rapprochement entre Euronext et Deutsche Börse ont déjà échoué. L’histoire financière offre ici un nouvel enseignement : la rivalité intense entre les places de Montréal et de Toronto a freiné le développement du marché financier canadien au XIXᵉ siècle, conduisant entreprises et investisseurs à se tourner vers les États-Unis.
Si l’Europe veut transformer son épargne abondante en investissement productif, elle doit construire un marché plus profond, transparent et intégré. L’histoire enseigne que lorsqu’elle fragmente l’information et la liquidité, la concurrence affaiblit le marché qu’elle prétend dynamiser.
Angelo Riva ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 15:25
Céline Dion, la superstar qui rapproche le Québec et la France
Adeline Vasquez-Parra, Maître de conférences, Université Lumière Lyon 2
Texte intégral (1782 mots)
La fête nationale du Québec, célébrée le 24 juin, offre l’occasion de revenir sur l’un des évènements québécois de l’année : les dix concerts parisiens de Céline Dion. À chaque nouvelle tournée de la chanteuse québécoise, le même phénomène se produit : files d’attente interminables, billets épuisés en quelques minutes. Au-delà de la « starification », que révèle son parcours entre le Québec et la France ?
Née en 1968, Céline Dion appartient à un Québec que l’on pourrait aujourd’hui qualifier de « disparu ». Dernière d’une fratrie de 14 enfants, elle grandit au sein d’une société canadienne-française rurale encore marquée par la tradition : familles nombreuses et forte empreinte catholique.
Sa naissance coïncide toutefois avec l’entrée du Québec dans la modernité car Céline Dion est d’abord une enfant de « la révolution tranquille », cette période de mutations sociales et économiques qui voit l’État québécois se moderniser sous l’impulsion du gouvernement de Jean Lesage (1960-1966). L’éducation et la santé passent sous le contrôle de l’État provincial retirant à l’Église catholique sa tutelle historique. La langue française s’affirme comme langue de l’espace public et de l’activité économique.
À partir de la révolution tranquille, il ne s’agit plus seulement d’assurer la survie d’une minorité francophone mais de bâtir une société moderne capable de se prendre en main par le biais de l’État provincial.
Cette double appartenance explique en partie la place singulière de Céline Dion dans l’imaginaire collectif québécois. Comme l’a montré le chercheur Frédéric Demers, elle occupe une position centrale dans le panthéon québécois précisément parce qu’elle sert de « pont entre continuités et mutations ». Son parcours a réconcilié le Québec avec les valeurs entrepreneuriales et celles du succès professionnel, longtemps taboues, et les a exportées à l’international. C’est de cette conversion (non dénuée de sarcasme) que traite, en partie, le film de Valérie Lemercier Aline, sorti en 2020 en France.
Rapprochement France-Québec
La fin des années 1960 témoigne aussi d’un rapprochement inédit entre la France et le Québec. L’Exposition universelle de Montréal de 1967 offre au Québec une visibilité internationale sans précédent tout comme le célèbre « vive le Québec libre ! » lancé par le général de Gaulle depuis le balcon de l’hôtel de ville de Montréal. Sans résumer les relations franco-québécoises à cet épisode, celui-ci contribue à renforcer les échanges institutionnels entre les deux sociétés.
L’un des aspects les plus complexes du parcours de Céline Dion réside pourtant dans son rapport à l’identité québécoise puisqu’elle a toujours évité les prises de position politiques explicites. Lors des référendums sur la souveraineté du Québec de 1980 et de 1995, elle demeure prudente. Cette neutralité contraste avec toute une génération d’artistes québécois connus en France dans les années 1960 et 1970, tels Gilles Vigneault ou Félix Leclerc, pour qui la chanson constituait un instrument d’émancipation nationale.
La première superstar québécoise
Car l’intérêt historique de Céline Dion dans l’étude des relations France-Québec tient aussi à sa trajectoire exceptionnelle dans un contexte de mondialisation accélérée où son image puise à la fois dans l’américanité et la francophonie. Au cours des années 1980 et surtout 1990, la libéralisation des marchés et la multiplication des chaînes de télévision permettent l’essor des industries du divertissement et démocratisent l’accès aux productions culturelles.
La carrière musicale de Céline Dion accompagne plusieurs moments emblématiques de cette mondialisation culturelle principalement associée au triomphe des industries culturelles américaines. Sa présence à la cérémonie de gala du président Bill Clinton en 1994, puis sa participation à l’ouverture des Jeux olympiques d’Atlanta en 1996 et le succès planétaire de My Heart Will Go On pour la bande-son du film Titanic en 1998 la consacrent comme une diva nord-américaine.
La journaliste Denise Bombardier observera rétrospectivement dans son Dictionnaire amoureux du Québec qu’il a fallu « attendre que les États-Unis la décrètent mégastar pour qu’enfin la France, dédouanée par les Américains en quelque sorte, l’adopte et la consacre à son tour ».
Céline Dion est peut-être la première chanteuse québécoise massivement adoptée par les Français parce qu’elle incarne d’abord une forme de modernité nord-américaine.
Ainsi, « les années Céline », du début des années 1990 à la fin des années 2000, correspondent à un nouveau rapport entre les Français et le Québec. Ce dernier y importe des codes très en vogue de la culture nord-américaine. Les humoristes Anthony Kavanagh ou Stéphane Rousseau connaissent un certain succès avec leur one-man show, la présentatrice Julie Snyder importe le rythme rapide des talk-shows à l’américaine avec son émission, « Vendredi, c’est Julie », diffusée sur France 2.
La Québécoise : un symbole
La grande nouveauté qu’a introduit Céline Dion en France tient peut-être au fait qu’elle soit une Québécoise. Pendant longtemps, les représentations françaises du Canada historique ont été dominées par des figures masculines héritées de la relation coloniale originelle où explorateurs, coureurs de bois, aventuriers et bûcherons, répondant à des codes précis de virilité, incarnaient une certaine représentation française de l’Amérique du Nord. Jusqu’au XXᵉ siècle, les grandes personnalités québécoises connues en France demeurent des hommes que l’on pense à Robert Charlebois, ou encore Marcel Béliveau.
Certes, la France avait déjà découvert Ginette Reno ou Diane Dufresne avant Céline Dion, mais aucune n’avait occupé une place aussi centrale dans l’imaginaire populaire. Alors qu’elle tient une place d’héroïne nationale au Québec, comme l’indique la chercheuse en musique populaire Line Grenier, sa réception en France semble opérer un même déplacement. Ni totalement étrangère ni véritablement française, mais tout aussi « héroïque » et « nationale ».
Un paysage mémoriel sonore partagé
Céline Dion emprunte à une mémoire musicale commune. Le projet de Maison de la chanson et de la musique du Québec dont l’ouverture est prévue à Montréal en 2028 repose sur une intuition particulièrement innovante : et si ce qui reliait le Québec au monde était avant tout une mémoire sonore partagée ?
Depuis la création des Francofolies de La Rochelle en 1985, puis des FrancoFolies de Montréal en 1989, les échanges musicaux entre les deux rives de l’Atlantique n’ont cessé de croître. Ces festivals ont beaucoup contribué à faire circuler les artistes francophones et à intégrer la chanson québécoise à un espace culturel transnational.
Le succès de Céline Dion ne doit toutefois pas masquer la diversité de cette production musicale. Des artistes comme Les Cowboys Fringants ou plus récemment Angine de Poitrine ont développé d’autres manières d’incarner le Québec sur la scène française. Plus récemment, les voix autochtones comme Elisapie contribuent à faire entendre des rapports plus complexes à la langue française et à l’identité québécoise.
Malgré leur reconnaissance critique et leur popularité, peu de ces artistes ont cependant réussi à fédérer un public aussi vaste et bigarré que celui de Céline Dion.
Adeline Vasquez-Parra ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 14:28
Feux de forêt, mégafeux : comment mieux prévoir leur propagation et limiter les risques ?
Marcos Rodrigues Mimbrero, Profesor Titular en Análisis Geográfico Regional, Universidad de Zaragoza; AXA Research Fund
Jorge Félez Bernal, Assistant researcher, Universidad de Concepción
Texte intégral (2058 mots)

L’ampleur des dégâts causés par les feux de forêt ne cesse de s’aggraver à l’échelle mondiale. Les incendies dangereux sont plus intenses et plus fréquents, alimentés à la fois par le changement climatique et par l’empreinte humaine sur les paysages – dont on parle moins, mais qui est également très importante.
Pour prévenir les dégâts, il faut pouvoir évaluer précisément les risques, notamment les trajectoires et l’évolution des mégafeux.
Les données mettent en évidence une tendance claire : nous sommes confrontés à des feux de forêt de plus en plus dévastateurs qui provoquent des catastrophes d’une ampleur jusqu’alors inconnue. Selon l’Agence européenne pour l’environnement, 3 770 kilomètres carrés de terres brûlent en moyenne en Europe, chaque année, et 45 000 personnes ont été déplacées à cause des feux de forêt entre 2008 et 2023. Ceci entraîne des pertes annuelles estimées à 2,5 milliards d’euros dans l’Union européenne.
Au cours de l’été 2025, l’Europe a connu les incendies de forêt les plus violents de ces deux dernières décennies en termes de superficie brûlée. Des incendies violents sur la péninsule ibérique ont ravagé 6 720 kilomètres carrés de terres, faisant le triste bilan de huit victimes.
À lire aussi : Mégafeux : Sommes-nous entrés dans une nouvelle ère ?
À l’autre bout du globe, le Chili a également connu des incendies stupéfiants, qui ont entraîné des catastrophes particulièrement douloureuses. En février 2024, l’incendie de Valparaíso-Viña del Mar a coûté la vie à 136 personnes et détruit près de 7 000 habitations. De même, en janvier dernier, à Concepción–Penco, un autre incendie a tué 21 personnes et rasé plus de 2 000 habitations.
La « pyrogéographie », où comprendre le comportement des feux à différentes échelles spatiales et temporelles
Il est essentiel de comprendre le potentiel de ces incendies à dévaster les communautés et les écosystèmes. Par conséquent, les recherches récentes en pyrogéographie se concentrent sur l’analyse du comportement du feu à différentes échelles spatiales et temporelles.
Dans ce contexte, deux approches technologiques sont particulièrement efficaces pour évaluer les impacts des incendies. En premier lieu, la télédétection (imagerie satellite, capteurs thermiques, plateformes aériennes), qui est essentielle pour reconstituer les impacts passés, pour la détection précoce et la surveillance en temps réel des feux en cours. Ensuite, les outils de simulation et de prévision, qui nous permettent d’identifier les configurations du paysage favorisant l’embrasement et la propagation du feu, et de comprendre la complexité des feux de forêt.
L’idée est d’utiliser ces connaissances pour participer à l’aménagement du territoire, afin de faire face aux risques croissants de feux de forêt et de mégafeux qui menacent nos communautés.
La télédétection pour cartographier les traces laissées par les feux de forêt passés
Pour quantifier l’ampleur de ces événements, nous exploitons l’imagerie satellite et des outils analytiques avancés afin d’évaluer deux variables principales : l’intensité et la sévérité des mégafeux.
L’intensité mesure la puissance du feu, c’est-à-dire le taux de libération d’énergie pendant la combustion, et aide à localiser les points chauds thermiques.
La sévérité évalue les conséquences : les dégâts matériels laissés dans le sillage de l’incendie.
En analysant des bandes spectrales spécifiques, nous pouvons par exemple quantifier la chute drastique de la productivité végétale, mesurant ainsi efficacement les difficultés de l’écosystème à se régénérer.
Les récents incendies de Barroca Grande (Portugal, août 2025) et des Trinitarias (Chili, janvier 2026) sont de bons exemples.
En combinant les données thermiques FIRMS de la Nasa et les images Copernicus Sentinel-3 de l’Agence spatiale européenne (ESA), nous pouvons visualiser la crise des incendies à la fois dans l’espace et dans le temps. Ces images révèlent une réalité stupéfiante : des panaches de fumée s’étendant sur des centaines de kilomètres dans l’atmosphère.
Les données d’intensité révèlent que plus de 95 % de la superficie totale finalement touchée a brûlé en une seule journée au Chili, le 18 janvier. C’est la définition même d’un « comportement explosif du feu » : des événements si rapides qu’ils dépassent les capacités des efforts traditionnels de lutte contre les incendies.
Au-delà de la chaleur immédiate, notre analyse de la sévérité fournit des indicateurs essentiels aux efforts de reconstruction. Au Portugal, 57 782 hectares ont été calcinés.
En recoupant ces niveaux de dégâts avec les types de combustibles, les conditions météorologiques locales et la topographie, nous pouvons concevoir des plans de restauration écologique précis et aider le secteur agricole à se reconstruire d’une manière qui, espérons-le, sera plus résiliente face aux futurs incendies.
Modélisation du comportement du feu et évaluation des risques
Dans le domaine de l’évaluation et de la gestion des risques d’incendie, deux stratégies prédominent.
La plus courante repose sur des évaluations à court terme : les indices quotidiens de risque d’incendie que l’on voit aux informations combinent les dangers météorologiques actuels et la vulnérabilité locale. C’est, par exemple, le principe de base du Système européen d’information sur les incendies de forêt (EFFIS).
À lire aussi : Un méga-incendie en Méditerranée, est-ce possible ?
À l’autre extrémité du spectre se trouve un outil plus stratégique appelé « simulation quantitative ». Plutôt que de se concentrer sur ce qui pourrait se passer demain (ou ce qui se passe actuellement), cette approche utilise des techniques de modélisation avancées pour orienter la planification à long terme et l’atténuation des risques.
Pour anticiper les effets possibles de saisons plus chaudes et plus sèches, ainsi que ceux de la transformation des paysages (par exemple, l’abandon des terres), nous évaluons l’exposition aux mégafeux en combinant la modélisation empirique (qui tire les leçons des feux qui se sont réellement produits dans l’histoire et de leur comportement) et la modélisation stochastique (qui utilise des algorithmes complexes pour simuler des milliers de scénarios hypothétiques).
Concrètement, nous étudions les incendies passés pour évaluer dans quelle mesure un paysage est susceptible de favoriser ou de freiner de futurs incendies, et déterminer dans quelle mesure nous y sommes potentiellement exposés, ou à quel point nous sommes menacés par ceux-ci. Pour quantifier cette exposition, nous identifions d’abord les facteurs spécifiques à l’origine des départs de feu : d’origine humaine ou naturelle. Ensuite, nous déclenchons des milliers d’incendies théoriques sur un « jumeau numérique » du paysage.
Nous exécutons ces simulations sous divers scénarios climatiques afin de générer des schémas réalistes d’exposition aux incendies. Il en résulte un ensemble d’indicateurs clairs et exploitables, qui nous indiquent non seulement où un incendie est susceptible de se déclarer, mais aussi quelle sera sa virulence.
Cette transition d’une approche réactive à une approche proactive nous permet de mettre en œuvre des stratégies plus efficaces. Qu’il s’agisse de réorganiser les combustibles forestiers, de mettre à jour les codes de construction urbains ou de concevoir des quartiers résistants au feu, ces décisions s’appuient sur des données.
En quoi cela aide-t-il en cas d’urgence ?
Le véritable test de ces technologies a lieu lors d’une situation d’urgence. Dans un contexte opérationnel, la modélisation de la propagation des incendies passe d’une planification stratégique à une course contre la montre.
Le programme WIFIRE de l’Université de Californie à San Diego, par exemple, fournit des informations en temps réel aux équipes d’intervention en cas d’incendie de forêt.
En intégrant des données satellitaires en temps quasi réel à des prévisions météorologiques de haute résolution, les chercheurs peuvent générer des projections qui prédisent la trajectoire d’un incendie dans les heures à venir.
L’un des outils les plus efficaces dans le cadre d’une évacuation opérationnelle est l’utilisation d’« isochrones » – des courbes de niveau sur une carte qui représentent l’heure d’arrivée prévue du feu (par exemple, 30, 60 ou 90 minutes à partir de la position actuelle).
La superposition de ces courbes de niveau sur des points de déclenchement (crêtes, routes ou repères spécifiques) permet aux responsables des services d’urgence d’automatiser le processus décisionnel.
Le mécénat scientifique d’AXA fait désormais partie du Fonds Axa pour le progrès humain, qui regroupe les engagements philanthropiques du Groupe et des mutuelles d’assurance Axa dans les domaines de la science, de la nature, de la solidarité et de la culture. Avant 2025, ce mécénat scientifique global était assuré par le Fonds Axa pour la recherche, qui a soutenu plus de 750 projets à travers le monde depuis sa création en 2007. Pour en savoir plus, rendez-vous sur Fonds Axa pour le progrès humain.
Marcos Rodrigues Mimbrero a reçu des financements du Ministerio de Ciencia, Innovación y Univesidades, de l'Agencia Estatal de Investigación et du Fonds Axa pour le progrès humain.
Jorge Félez Bernal a reçu des financements du Fonds Axa pour le progrès humain.
25.06.2026 à 10:41
Summer’s new normal is a hazard that’s testing Europe’s climate resilience
Júlia de Freitas Sampaio, Postdoctoral researcher, University of Luxembourg
Texte intégral (1603 mots)
It is only June, and Europe is already baking through its second extreme heatwave in two months. Temperatures have topped 44 degrees Celsius in parts of the continent. Heat alerts are now in place for several countries, with six at the most severe red level.
France placed 72 of its 96 departments under red alert, and at least 40 people have drowned trying to escape the heat.
In Spain, temperatures peaked at 45.1°C, with 101 heat-related deaths in May alone, the highest ever recorded for the month.
The UK broke its all-time June temperature record. Cities are closing schools, power grids are buckling, and hospitals are reporting a surge in heat-related emergencies.
None of this should have been a surprise. Europe is the fastest-warming continent on Earth, heating at roughly twice the global average, and scientists have been warning for decades that human-made climate change would make extreme heat more frequent and more severe. Current projections expect the next five years to shatter even more records, making this the “new normal”.
The summers European residents grew up with no longer exist, and extreme heat is no longer an anomaly, but the new baseline. This means the question now is no longer whether extreme heat will return, but whether European cities can survive it.
A climate disaster that isn’t treated like one
Extreme heat kills more Europeans than any other climate hazard.
According to the World Health Organisation (WHO), over 175,000 people die every year from heat-related causes across the continent.
Despite the numbers, extreme temperatures have not been treated with the same urgency as other disasters, such as storms, wildfires, or floods. Most governments are still improvising, and there is no coordinated response to extreme heat, as it is still treated as a weather inconvenience rather than a life-threatening hazard.
However, this framing is starting to shift. At COP30, the United Nations office for Disaster Risk Reduction (NDRR) launched a new Extreme Heat Risk Governance Framework. It formally recognised extreme heat as one of the most deadly and least managed climate threats. Although this framework is a step forward, decades of fragmented policies, short-term crisis thinking, and chronic underinvestment in public services have left Europe dangerously exposed.
As a result, every summer that passes without meaningful progress is another summer that will cost lives.
Europe is not built for this
A recent report by the UK’s Climate Change Committee argued that the country is built for a climate that no longer exists, warning that temperatures exceeding 40°C are becoming increasingly common. The same could be said of virtually every European country. Cities were designed for a different era with concrete roads, pavements, and buildings that absorb and trap heat rather than deflect it, turning urban areas into furnaces that run four to six degrees warmer than their surroundings.
Some cities are already responding. For instance, Paris has pledged to plant 170,000 trees in public spaces, and Marseille is depaving historic plazas and mapping shaded walking routes.
Other countries are also taking action by replacing standard pavement with cool surfaces and reflective road paint, rethinking building codes, and redesigning public spaces with passive cooling in mind. However, none of it touches the underlying problem. Europe is still largely powered by fossil fuels, and its food systems, housing and transport networks all carry a heavy carbon cost.
The EU’s greenhouse gas footprint amounts to around 9 tonnes of CO₂ equivalent per person per year, well above the global average of roughly 5 tonnes.
Progress is being made, but not fast enough. Train travel is still more expensive than flying on many routes, building codes still allow new construction that will soon be uninhabitable, and cooling centres, shaded public corridors, and proactive outreach to elderly people living alone remain the exception rather than the rule.
Heat action plans exist in some cities, but few are legally binding, and fewer still have the budgets to match their ambitions.
Individual action matters, but it cannot substitute for the systemic changes that only governments and institutions can deliver. Eating less meat or flying less makes a difference at scale, but the clock will not stop running unless emissions are cut at the source.
Adaptation and mitigation need to happen together, and neither can wait.
The window is narrowing
The EU is preparing a climate resilience strategy due at the end of 2026, which is expected to introduce legally binding rules and monitoring tools to coordinate action across member states. It is a step in the right direction. But as this week’s heatwave has made clear, the gap between what is being planned and what is already happening on the ground is widening fast.
The question is not just how to respond to the next heatwave, but how to govern, finance, and rebuild for a continent that is already living in a different future.

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Júlia de Freitas Sampaio ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 10:10
Tony Mazzocchi, le syndicaliste oublié qui pensa la transition juste
Yanis Rihi, Doctorant en économie politique du développement, Université Paris-Saclay
Texte intégral (4794 mots)

Qui se souvient de Tony Mazzocchi ? En refusant d’opposer emplois et exigences environnementales, ce syndicaliste new-yorkais conceptualisa l’idée de transition juste abondamment reprise aujourd’hui, même à la COP30, par exemple. Dans ses actions, le militant syndical a lié étroitement les combats environnementaux aux enjeux sociaux et sanitaires, mais également aux luttes contre le racisme et le sexisme.
L’idée de « transition juste » est désormais omniprésente. On la retrouve dans les négociations climatiques, le Pacte vert européen ou encore les partenariats énergétiques entre des pays européens et des États des Suds.
Pourtant, l’homme à l’origine de ce concept reste quelque peu méconnu : Tony Mazzocchi, un syndicaliste américain qui cherchait, dès les années 1970, à résoudre une question toujours d’actualité : comment protéger l’environnement sans sacrifier les travailleurs de certains secteurs ?
Un fils de Brooklyn au cœur de l’Amérique industrielle
Né en 1926 à Brooklyn (New York) dans une famille italo-américaine modeste et militante syndicale, Tony Mazzocchi est très tôt confronté aux inégalités sociales. Marqué par la Grande Dépression durant son enfance, puis par son engagement dans la marine américaine durant la Seconde Guerre mondiale, il appartient à une génération qui a connu à la fois les grandes crises économiques du XXᵉ siècle et l’essor industriel de l’après-guerre.
Sa trajectoire syndicale débute en 1950 dans une usine de cosmétiques du Queens. Rapidement élu délégué syndical, puis président à seulement 26 ans, du Local 149 de l’United Gas, Coke, and Chemical Workers Union, il transforme cette section syndicale en une actrice influente dans la région new-yorkaise. Le syndicat étend dès lors sa présence jusqu’à représenter les salariés d’une vingtaine d’entreprises.
Outre les revendications salariales, Mazzocchi défend une conception plus large de l’action syndicale. Le Local 149 mène, par exemple, des campagnes en faveur de l’égalité salariale entre hommes et femmes, participe à d’importantes campagnes de syndicalisation et contribue à la mise en place de l’un des premiers régimes d’assurance dentaire du pays.
Il gravit ensuite les échelons de l’Oil, Chemical and Atomic Workers (OCAW), le principal syndicat des raffineries américaines de l’époque – directeur des affaires législatives, puis de la santé et de la sécurité et enfin vice-président. Une position qui lui permettra d’influencer les orientations du syndicat à l’échelle nationale. Convaincu que l’émancipation ouvrière passe aussi par l’éducation populaire, il organise des clubs de lecture où les discussions portent aussi bien sur les conditions de travail que sur l’histoire ou la philosophie.
Les risques cachés d’une puissance industrielle
Lorsque Mazzocchi entame sa carrière, le mouvement syndical américain constitue déjà une force politique majeure. Les syndicats représentent alors plusieurs millions de travailleurs et participent activement aux grands débats de leur temps.
Sous l’impulsion de dirigeants comme Walter Reuther, l’United Auto Workers (UAW) soutient, par exemple, le mouvement des droits civiques et contribue à l’organisation de la Marche sur Washington pour l’emploi et la liberté de 1963.
C’est d’ailleurs une période fortement marquée par l’émergence de nouveaux mouvements sociaux qui contestent les effets sociaux, raciaux et environnementaux du modèle de développement américain d’après-guerre. C’est effectivement à partir des années 1960 que les préoccupations environnementales gagnent en visibilité à mesure que s’accumulent les preuves des effets sanitaires et écologiques de l’industrialisation. La publication de Silent Spring par la biologiste et militante écologiste états-unienne Rachel Carson, en 1962, contribue d’ailleurs à sensibiliser l’opinion publique aux effets des pesticides sur l’environnement et la santé humaine ainsi qu’à l’interdiction du DDT, dix ans plus tard.
Dans le même temps, des communautés afro-américaines marginalisées dénoncent leur exposition disproportionnée à la pollution industrielle et aux déchets toxiques. À Houston, au Texas, des habitants contestent ainsi, dès la fin des années 1960, la concentration de décharges et d’infrastructures polluantes dans leurs quartiers. Tout cela fera émerger les premières critiques des inégalités environnementales et posera les bases de ce qui deviendra le mouvement pour la justice environnementale.
Alors vice-président de l’OCAW, Mazzochi représente les travailleurs des secteurs les plus stratégiques de l’économie américaine : le pétrole, la pétrochimie, la chimie et l’industrie nucléaire. Car si les États-Unis sont souvent associés à leur industrie pétrolière, ils constituaient aussi, durant la guerre froide, l’un des principaux centres mondiaux du nucléaire, tant civil que militaire.

L’OCAW regroupe ainsi à cette époque une part importante de la main-d’œuvre des raffineries, des usines chimiques et des installations nucléaires du pays, secteurs les plus dangereux de l’époque. Les travailleurs sont quotidiennement exposés à des substances dont les effets sanitaires sont méconnus ou minimisés, faute de connaissances scientifiques et d’une réglementation insuffisante. Les entreprises contrôlent d’ailleurs en grande partie la production des savoirs relatifs aux risques professionnels. Comme le résumera plus tard le militant syndical et compagnon de route de Mazzocchi, Les Leopold :
« les entreprises régnaient comme des monarchies absolues sur la production chimique, l’exposition aux substances dangereuses et leur réglementation. »
Travailleurs et environnement : même combat
Chez Mazzochi, les travailleurs deviennent le premier point de rencontre entre les enjeux de santé publique et les préoccupations environnementales. Là où de nombreux responsables syndicaux voient dans les réglementations environnementales une menace pour l’emploi, Mazzocchi refuse d’opposer conditions de travail et protection de l’environnement, affirmant :
« Malheureusement, une telle position défensive n’offre aucune garantie d’emploi. Toutes les réglementations environnementales actuellement en vigueur pourraient être abrogées, et des millions de travailleurs – dont beaucoup de nos syndiqués – seraient toujours menacés de se réveiller un jour sans emploi. »
Pour lui, s’opposer aux réglementations environnementales au nom de l’emploi revient à combattre le mauvais adversaire. Les travailleurs sont souvent les premières victimes de la pollution industrielle : avant même que les émissions toxiques n’affectent les populations voisines, elles touchent quotidiennement ceux qui manipulent des produits chimiques ou inhalent des poussières dangereuses.
Entre 1969 et 1970, Mazzocchi organise une série d’auditions publiques réunissant des travailleurs et des spécialistes de la santé au travail afin de documenter publiquement les effets de nombreuses substances toxiques, telles que l’amiante, utilisée comme isolant industriel, le benzène, présent dans les solvants, et le plomb, employé dans de nombreux procédés manufacturiers.
Ces témoignages contribuent à médiatiser la question et à renforcer les pressions en faveur d’une législation fédérale en matière de santé au travail. De la sorte, il contribue à ce que l’on appellera le labor environmentalism, c’est-à-dire la convergence, longtemps jugée improbable, entre revendications ouvrières et écologie.

{kind=link}
Tandis que les syndicats se concentrent principalement sur les accidents du travail visibles et immédiats, Mazzocchi attire l’attention sur des maladies qui apparaissent parfois des années après l’exposition, telles que le cancer du poumon ou le mésothéliome. Un engagement qui n’est d’ailleurs pas sans risque.
En 1974, Karen Silkwood, membre de l’OCAW impliquée dans une campagne sur la sécurité au sein d’une usine de traitement du plutonium, meurt dans des circonstances controversées alors qu’elle s’apprêtait à révéler des dysfonctionnements au sein de son entreprise au New York Times.
Au sujet de sa mort, Tony Mazzocchi affirmera :
« Nous devons nous souvenir de son histoire parce qu’elle symbolise les efforts collectifs et le courage des millions de syndicalistes qui ont lutté – et continuent de lutter – pour défendre la santé, la sécurité et la protection de leurs collègues. »

Figure de proue donc de ces luttes, Mazzocchi contribue à rassembler les syndicats, les scientifiques, les acteurs de la santé publique et les organisations environnementales autour d’une cause commune. Il compte parmi les figures syndicales les plus influentes des campagnes ayant conduit à l’adoption de l’Occupational Safety and Health Act de 1970, la première grande législation fédérale états-unienne consacrée à la santé et à la sécurité au travail. Un texte qui ouvrira la voie à de nouvelles normes visant à limiter l’exposition à des substances particulièrement dangereuses, telles que l’amiante, l’arsenic, le benzène et le plomb.
Au-delà de cette victoire, son approche contribue à transformer la manière dont les syndicats appréhendent les risques industriels. L’enjeu n’est plus seulement d’éviter les accidents, mais aussi de prévenir les maladies invisibles résultant d’une exposition prolongée à des substances toxiques. Cette évolution est telle que son collègue et biographe Les Leopold le décrira plus tard comme l’équivalent syndical de Rachel Carson.
« La première étape était de faire comprendre aux travailleurs que ce qu’ils vivaient n’était pas un incident isolé, mais une réalité partagée dans tout le pays. La seconde consistait à les mobiliser pour défendre des droits fondamentaux, notamment le droit à l’information sur les risques auxquels ils étaient exposés, une bataille que nous n’avons pas encore remportée. »
1995 : quand « transition juste » entre dans le vocabulaire
Au cours des années 1970, l’OCAW met donc en pratique cette stratégie proactive fondée sur les alliances multipartites. En 1973, le syndicat mène, par exemple, une grève nationale de quatre mois contre Shell Oil, portant sur les questions de santé et de sécurité au travail. Face à la puissance des grandes compagnies pétrolières, les militants de l’OCAW s’appuient sur le soutien d’organisations environnementales pour dénoncer les risques professionnels auxquels les travailleurs sont exposés.
Ce type de revendications contribue à remettre en cause l’opposition traditionnellement entretenue entre la protection de l’emploi et celle de l’environnement. Car, à mesure que les réglementations environnementales se renforcent dans les années 1970 et 1980, Mazzocchi se heurte de plein fouet à une question qui demeure au cœur des débats actuels sur la transition écologique : comment protéger l’environnement sans faire peser l’essentiel des coûts de cette transformation sur les travailleurs et les territoires dépendants des industries polluantes ?
Mazzocchi prend ce dilemme à bras-le-corps et développe, au début des années 1990, une proposition baptisée « Superfund for Workers », en référence au programme fédéral Superfund, créé en 1980 pour financer la dépollution de milliers de sites industriels contaminés. L’idée est simple : ceux qui paient pour réparer les territoires pollués devraient donc également contribuer à réparer les dommages sociaux qui en découlent. Cette conviction l’amène à formuler ce qui deviendra le cœur de sa réflexion sur la transition juste :
« La seule façon de sortir du dilemme entre l’emploi et l’environnement est de prévoir un accompagnement pour les travailleurs qui perdent leur emploi à la suite des opérations de dépollution indispensables, ou qui sont affectés par les restructurations économiques, les réductions des dépenses militaires ou les délocalisations industrielles. »
Le Superfund for Workers prévoit alors le maintien des revenus et des avantages sociaux, la prise en charge de formations, des aides à la reconversion ainsi que des dispositifs de relocalisation. L’objectif n’est donc pas seulement de compenser une perte d’emploi, mais bien de garantir aux travailleurs des perspectives comparables à celles dont ils auraient bénéficié sans la fermeture ou la transformation de leur activité.
On ne parle pas encore de « transition juste », car le véritable changement sémantique s’opère en 1995, lorsque Les Leopold présente publiquement cette proposition sous l’appellation, cette fois-ci, de « Just Transition Fund ». C’est la première occurrence connue de l’expression, pour désigner des mécanismes destinés à accompagner les travailleurs confrontés aux transformations environnementales et économiques.
Deux ans plus tard, l’OCAW contribue à la création de la Just Transition Alliance, qui rassemble des syndicats, des organisations environnementales et des mouvements de justice sociale autour d’un objectif commun : éviter que les coûts des transformations industrielles ne soient supportés par les populations les plus vulnérables.
Toujours active aujourd’hui, l’organisation continue de promouvoir les principes de justice environnementale et de transition juste auprès des travailleurs et des communautés affectées par les transformations écologiques.

Pourquoi Tony Mazzocchi reste actuel
Dès les années 1970, la question était donc de savoir comment organiser collectivement une transformation nécessaire sans abandonner ceux qui en supportent les coûts immédiats. Mais plus de trente ans après la formulation du Just Transition Fund, cette interrogation demeure au cœur des débats sur la transition écologique.
Le premier enseignement que l’on peut tirer du parcours de Mazzocchi est sans doute que les avancées environnementales reposent rarement sur un seul type d’acteurs. Les succès obtenus par son syndicat résultent indubitablement de coalitions inédites réunissant des travailleurs, des scientifiques, des médecins, des associations citoyennes et des organisations environnementales. À l’heure où les politiques climatiques suscitent parfois méfiance ou polarisation, cette capacité à rassembler des acteurs aux intérêts en apparence divergents reste une condition de leur succès.
Le second consiste à prendre conscience que les travailleurs ne sont pas nécessairement opposés aux politiques environnementales. Bien avant que la transition juste ne s’impose dans les débats climatiques, Mazzocchi contestait déjà l’idée d’une opposition entre emploi et environnement.
À lire aussi : L’écologie, un problème de riches ? L’histoire environnementale nous dit plutôt le contraire
Il avait compris que les résistances naissent moins des objectifs poursuivis que de la manière dont leurs coûts sont répartis. Lorsque les bénéfices sont collectifs mais que les pertes se concentrent sur certains secteurs ou territoires, les conflits deviennent presque inévitables. Plus de cinquante ans plus tard, ce « dilemme emploi-environnement » continue pourtant de structurer une partie des débats sur le climat.
Enfin, l’héritage de Mazzocchi rappelle que la transition juste ne se résume pas uniquement à un objectif de décarbonation. Pour lui, cette approche devait s’accompagner de garanties concrètes pour les populations concernées, autrement dit la justice et la protection sociale (maintien des revenus, formation, reconversion professionnelle). Si l’expression est aujourd’hui largement mobilisée, les moyens alloués à ces dimensions sociales demeurent souvent en décalage avec les ambitions affichées.

Tandis que les idées de Mazzocchi se sont largement diffusées ces dernières décennies, nombre de dispositifs qu’il défendait n’ont jamais été mis en œuvre à l’échelle qu’il envisageait. Convaincu que les travailleurs avaient dès lors besoin d’une représentation politique indépendante, il participe, dans les années 1990, à la création du Labor Party, pensé comme une alternative aux deux grands partis, porteuse des intérêts de la classe ouvrière. Mais en dépit du soutien de plusieurs organisations syndicales et des ambitions importantes, le projet ne parvint jamais à s’imposer durablement dans le paysage politique américain.
Un échec qui illustre bien l’une des tensions au cœur de son héritage. Alors que les restructurations industrielles, les délocalisations et l’affaiblissement du syndicalisme des dernières décennies ont sensiblement réduit la capacité des organisations ouvrières à peser sur les décisions, les idées défendues par Mazzocchi continuaient de se diffuser. En ce sens, il a peut-être davantage remporté une bataille intellectuelle qu’une bataille politique. La transition juste est effectivement devenue aujourd’hui un langage largement partagé pour débattre des politiques climatiques.
Des régions charbonnières européennes aux pays des Suds engagés dans des partenariats de transition énergétique, les mêmes interrogations demeurent : qui finance les transformations, qui en bénéficie et qui en supporte les coûts ? Les débats portent désormais autant sur les travailleurs que sur les territoires, les communautés locales et même les pays appelés à concilier la décarbonation et le développement.
Enfin, à l’heure où la transition écologique est souvent présentée comme une nécessité et un défi principalement technique, le parcours de Tony Mazzocchi rappelle qu’elle demeure, fondamentalement, une question politique et sociale. Plus de cinquante ans après ses premiers combats, la question qu’il posait reste entière : comment transformer l’économie sans abandonner ceux qui supportent les coûts du changement, notamment les travailleurs des secteurs les plus polluants ? C’est sans doute ce qui explique que sa pensée continue d’alimenter les débats contemporains sur la transition juste.
Yanis Rihi ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
24.06.2026 à 14:53
Désinformation en santé : pourquoi les IA conversationnelles doivent entrer dans le débat
Karen Nuvoli, Maître de conférences en Sciences de l'Information et de la Communication à l'Université de Lorraine | Centre de Recherche sur les Médiations (Crem, UR 3476), Université de Lorraine
Gilbert Faure, PU-PH. Professeur des Universités Emérite
Texte intégral (2123 mots)
L’essentiel
- La désinformation en santé n’est pas un phénomène nouveau, mais les crises sanitaires successives, de l’affaire du sang contaminé à la pandémie de Covid-19, ont contribué à en accroître la visibilité.
- Les réseaux sociaux ont amplifié la circulation de la désinformation en santé tandis que les IA conversationnelles redéfinissent les pratiques d’accès à l’information.
- Le gouvernement français a émis des recommandations pour former les citoyens à démêler le vrai du faux dans ce nouvel écosystème informationnel complexe.
À l’heure où les fausses informations circulent plus vite que les savoirs établis, le dialogue entre science et société semble fragilisé. Méfiance envers les experts, controverses amplifiées par les réseaux sociaux, brouillage des repères… comment rétablir une discussion constructive fondée sur les faits, sans nier les doutes et les questionnements citoyens ?
Loin d’être cantonnée aux sphères politiques, la désinformation se répand largement dans le domaine de la santé. Informations erronées sur les vaccins, thérapies alternatives ou régimes miracles prolifèrent dans un espace numérique où les frontières entre savoirs légitimes et opinions infondées sont floues.
À lire aussi : Désinformation : sommes-nous tous manipulés ?
Plusieurs facteurs s’entrecroisent pour expliquer cette vulnérabilité. À cet égard, nous pouvons rappeler :
la charge émotionnelle liée aux sujets sanitaires ;
la centralité médiatique de la santé ;
l’histoire des crises sanitaires : l’affaire du sang contaminé (1991), la crise de la vache folle (1996) ou la pandémie de Covid (2019) ont altéré la confiance envers les institutions et les experts, ancrant un sentiment de défiance structurelle.
Cette défiance s’inscrit dans les fractures sociales et politiques contemporaines où les divisions sociales, politiques et économiques sont prononcées. Dans une société fragmentée, la désinformation trouve un public particulièrement réceptif au sein de groupes déjà enclins à se méfier des institutions.
Défiance et information en santé à l’ère numérique
Les travaux de la Fondation Descartes montrent que les personnes qui s’informent surtout par l’intermédiaire d’Internet et des réseaux sociaux ont un niveau de connaissances en santé plus faible, une confiance moindre envers la science, la médecine et les institutions, et une sensibilité plus forte aux croyances, aux thérapies alternatives et à l’ésotérisme.
Ce contexte constitue un véritable écosystème informationnel de défiance, au sein duquel les fausses informations circulent plus facilement et peuvent encourager des comportements à risque. La désinformation en santé est même devenue récemment une démarche politique aux États-Unis dans le cadre du mouvement MAHA (pour Make America Healthy Again, en français « Que l’Amérique soit de nouveau en bonne santé ») qui bourgeonne également en Europe.
Ainsi, la désinformation en santé n’est pas seulement un problème de communication, mais aussi un enjeu de gouvernance démocratique. Une démocratie repose, en effet, sur la capacité des citoyens à prendre des décisions éclairées. Or, une information biaisée ou mensongère altère cette rationalité collective.
Une nouvelle étape dans la lutte contre la désinformation en santé
Le gouvernement français a fait de la lutte contre la désinformation médicale une priorité politique. Dans ce sens, la Stratégie nationale de lutte contre la désinformation en santé, présentée en janvier 2026 par la ministre de la santé, fixe quatre axes d’actions dans le prolongement du rapport Molimard.
Le premier concerne l’écoute et la participation citoyenne. Le rapport des assises citoyennes numériques en santé, tout juste publié, dresse le constat d’une mésinformation massive et rappelle que, en matière de santé, protéger l’information, c’est protéger les Français. Il recommande de rendre l’information visible, lisible, pertinente et accessible au bon moment pour les bonnes personnes, et de faire évoluer en conséquence le cadre réglementaire. À ce propos, des sanctions vis-à-vis des désinformateurs existent déjà. Mais leur application semble difficile.
Le deuxième axe concerne la création d’un observatoire de la désinformation en santé qui devra assurer veille, analyse et alerte en lien avec le troisième axe du dispositif, l’« info-vigilance ».
Le dernier axe du plan, « bâtir un socle de confiance propice à l’information en santé », vise à responsabiliser les plateformes numériques et à renforcer l’éducation critique à la santé dès l’école, notamment au moyen des kits pédagogiques conçus avec le Centre pour l’éducation aux médias et à l’information (Clemi).
Pour réussir, la stratégie devra sortir des formats institutionnels traditionnels et trouver des relais crédibles auprès des communautés sceptiques, sans tomber dans une posture moralisatrice qui aggraverait encore la fracture. Le succès du plan dépendra de sa capacité à restaurer la confiance et à toucher tous les publics. La stratégie française s’inscrit à la fois dans la perspective européenne, en continuité du rapport sur la santé publique à l’âge de la mésinformation, et dans le cadre des recommandations internationales.
Dans ce contexte l’Organisation mondiale de la santé (OMS) insiste d’ailleurs depuis plusieurs années sur la nécessité de développer la littératie en santé, c’est-à-dire la capacité des individus à comprendre, évaluer et utiliser l’information médicale pour faire des choix éclairés.
Un point tout aussi important concerne l’accès aux soins. La désinformation et le recours aux thérapies alternatives touchent davantage les « déserts médicaux », où il est difficile de consulter un médecin traitant – pourtant considéré parmi les sources les plus crédibles.
À lire aussi : Médecins spécialistes et déserts médicaux : leur présence sur un territoire ne suffit pas à garantir l’accès aux soins
Cette approche met en lumière une idée clé : lutter contre la désinformation, ce n’est pas seulement corriger les fausses nouvelles. Il s’agit aussi d’outiller intellectuellement les citoyens pour qu’ils puissent s’orienter dans un écosystème informationnel complexe.
L’angle mort : les IA conversationnelles et les usages citoyens
Le rapport du ministère mérite d’être salué, notamment pour sa volonté de renforcer la confiance collective. Mais une question se pose : quelle place accorder aux IA conversationnelles en santé, d’autant que les outils et les usages se multiplient à l’international comme en France ?
Le rapport prévoit des formations à l’IA générative pour les journalistes et son intégration sur Sante.fr, mais passe à côté des citoyens – pourtant les principaux concernés – et des professionnels de santé. Ce choix surprend d’autant plus que l’usage de ces outils et la confiance qu’ils suscitent semblent déjà bien ancrés.
Ainsi, 62 % des médecins généralistes auraient recours ponctuellement à ChatGPT dans leur pratique et 45 % des Français seraient en accord avec cet usage. Mais ces estimations sont à prendre avec prudence puisqu’elles émanent d’acteurs eux-mêmes investis dans l’IA.
Cette question est néanmoins pertinente dans un contexte où les IA dans le domaine de la santé ne cessent d’évoluer. ChatGPT Santé a été lancé aux États-unis, le 7 janvier 2026, rapidement suivi par Claude for Healthcare, l’IA d’Anthropic, qui peut se connecter à des données individuelles de santé via iOS et Android.
Le premier se concentre sur une assistance conversationnelle personnalisée pour accompagner les individus dans la compréhension de leurs données de santé, leurs résultats d’examen et la préparation de consultations. Anthropic mise, quant à lui, sur l’intégration des outils dans les écosystèmes professionnels et de recherche. Tous les géants du Web proposent déjà des solutions, sans oublier les licornes françaises, comme Mistral et Doctolib. Quelle sera leur acceptabilité respective dans l’avenir ?
L’usage de ces outils par le grand public apparaît en effet souvent désordonné, faute de comparaison claire des mécanismes de fonctionnement. Si les usages techniques en imagerie (radiologie, pathologie) sont prometteurs, les applications en diagnostic médical individuel sont plus problématiques.
Les risques à l’usage sont nombreux et les publications se multiplient. Pour ne citer que les plus récentes : erreurs d’interprétation des situations cliniques (en particulier en conditions d’urgence), biais vers des diagnostics rares, difficultés des patients à établir un dialogue performant avec les LLM actuels (les LLM ou grands modèles de langages sont les systèmes d’intelligence artificielle type ChatGPT, ndlr), problèmes éthiques concernant l’utilisation des données personnelles, ou encore risque de piratage des données de santé individuelles.
Cette situation soulève donc plusieurs interrogations majeures vis-à-vis d’un accès responsable à l’information médicale et en santé : comment les utilisateurs vont-ils s’approprier les outils ? Jusqu’où un assistant conversationnel peut‑il accompagner les patients dans le diagnostic médical ? Quelles formations pour les médecins ?
Intégrer ce type de réflexion dans la stratégie nationale permettrait d’orienter les citoyens vers des usages plus responsables de ces outils.
Karen Nuvoli est membre du SFSIC (Société Française des Sciences de l’Information & de la Communication).
Gilbert Faure est fondateur et animateur du réseau HESIVAXs.
24.06.2026 à 14:53
Le boycott académique contre Israël est minoritaire et traduit l’émergence de nouvelles normes académiques
Éric Muraille, Biologiste, Immunologiste. Directeur de recherches au FNRS, Université Libre de Bruxelles (ULB)
Joël Kotek, Politiste, Université Libre de Bruxelles (ULB)
Texte intégral (2461 mots)
En rompant leurs liens avec les universités israéliennes, plusieurs universités européennes revendiquent une responsabilité morale face à la guerre à Gaza. Une évolution qui interroge les principes traditionnels de liberté académique et de neutralité institutionnelle.
À la suite de l’intensification du conflit israélo-palestinien, les militants propalestiniens ont organisé en 2024 de vastes manifestations dans les universités américaines. Ils dénonçaient un génocide commis à Gaza et exigeaient que les institutions académiques rompent leurs liens avec Israël.
Ce mouvement a gagné l’Europe. En réponse, les autorités académiques de certaines universités ont imposé un boycott institutionnel des universités israéliennes. Cet article tente de mettre en évidence l’ampleur de ce boycott en Europe ainsi que les arguments avancés par les autorités académiques pour le justifier.
Histoire des boycotts académiques
L’appel au boycott d’universités d’un pays pour les punir ou exercer une pression sur leur gouvernement n’est pas nouveau. Après la Première Guerre mondiale, les scientifiques allemands et autrichiens furent interdits de participer aux conférences et aux agences scientifiques internationales. Ce boycott punitif ne prit fin qu’en 1926, lorsque l’Allemagne fut invitée à rejoindre la Société des Nations.
Selon l’historien Michael D. Gordin, ce boycott, comme ceux contre l’Allemagne nazie ou contre l’URSS en représailles à l’invasion de l’Afghanistan, étaient partiels et se sont avérés inefficaces. Le seul boycott réputé pour avoir eu un impact sur une communauté scientifique et un régime politique serait le boycott contre le régime d’apartheid en Afrique du Sud entre 1960 et 1990.
L’efficacité de ce boycott peut s’expliquer par sa longue durée, par le consensus sur sa nécessité en raison du racisme du régime politique de l’Afrique du Sud et par la petite taille de la communauté scientifique sud-africaine. Toutefois, conclure qu’il aurait joué un rôle décisif dans la chute du régime d’apartheid semble exagéré. En effet, ce boycott était associé à de sévères sanctions économiques américaines ainsi qu’à une profonde crise structurelle interne du système socioéconomique de l’Afrique du Sud.
Au début des années 2000, des figures scientifiques défendant la cause palestinienne ont appelé à un boycott académique d’Israël. Cette demande s’est intensifiée lorsque des associations palestiniennes se sont unies dans le mouvement « Boycott, Désinvestissement et Sanctions » (BDS). En réaction, l’American Association of University Professors (AAUP) a exprimé son opposition à tout boycott systématique d’une institution universitaire. Ce refus a également été défendu par certains journaux scientifiques, comme le British Medical Journal.
Le principe du boycott académique viole les normes académiques traditionnelles et les droits fondamentaux
La liberté académique, telle que formulée par l’AAUP en 1915, protège les activités d’enseignement et de recherche des professeurs. La neutralité institutionnelle de l’université, le fait qu’elle s’abstienne de prendre position sur des sujets controversés ou qu’elle s’érige en acteur politique, est considérée comme une condition nécessaire à la liberté académique. Cette dernière est elle-même vue comme indispensable à la progression des connaissances scientifiques.
La liberté académique ne protège pas explicitement le droit des chercheurs à choisir librement leurs collaborateurs. Toutefois, la recherche scientifique repose sur un niveau d’organisation autonome impliquant des réseaux de collaboration universitaires internationaux. Il est également documenté qu’une réduction de la coopération scientifique internationale peut entraîner un déclin de la production scientifique. Ainsi, l’International Science Council, qui compte 135 organisations scientifiques, défend l’universalité de la science et « s’oppose à la discrimination fondée sur des facteurs tels que le sexe, l’origine ethnique, la citoyenneté, et l’opinion politique ». Du point de vue du droit international, le principe du boycott des scientifiques d’un pays contredit également le « droit à la science » garanti par la Déclaration universelle des droits de l’homme de 1948.
Sur ces bases, les chercheurs Blakemore, Dawkins, Noble et Yudkin considèrent qu’un boycott académique ne devrait être utilisé qu’en tout dernier recours et uniquement si les conditions suivantes sont remplies :
il existe de bonnes raisons de croire qu’un boycott aiderait à changer le comportement inacceptable d’un régime ;
la répulsion envers le régime doit être largement partagée …
le boycott fait partie d’un programme plus large de mesures, qui inclut des mesures diplomatiques, des sanctions économiques et culturelles.
Le boycott académique institutionnel contre Israël est minoritaire
Ces conditions n’étant pas remplies, il n’est pas surprenant de constater que, en août 2025, seuls 48 établissements d’enseignement supérieur en Europe avaient officiellement adopté un boycott partiel ou total des institutions israéliennes. Ce qui représente moins de 6 % des quelque 900 établissements reconnus par l’Association européenne des universités.

Les pays avec la plus forte proportion d’universités ayant déclaré un boycott académique officiel d’Israël sont la Belgique (100 %), les Pays-Bas (50 %), la Norvège (36,3 %) et l’Espagne (23,6 %). L’exceptionnalité belge est confirmée par le rapport du Samuel Neaman Institute qui classe la Belgique comme le pays européen présentant le plus haut taux d’incident de boycott en 2024.
Il est à noter qu’un « boycott caché » envers les chercheurs israéliens a également été documenté. Celui-ci, de par sa nature, est difficilement quantifiable.
L’émergence de nouvelles normes académiques inspirée par les luttes du Sud global
Dans leur communication commune, les recteurs des universités belges affirment que le choix de boycotter Israël est un « choix moralement responsable » et que « tenir Israël responsable des violations persistantes des droits de l’homme n’est pas une position idéologique, mais un impératif moral et juridique ». La rhétorique des recteurs belges reflète donc clairement un appel à la « responsabilité morale », qu’ils placent au-dessus des normes académiques traditionnelles proscrivant les boycotts.
Ce positionnement traduit l’influence en Europe de la Campagne palestinienne pour le boycott académique et culturel d’Israël (PACBI) reprise par le mouvement BDS. Dans son appel, PACBI affirme qu’Israël exerce une domination coloniale sur les Palestiniens et soutient que les universités participent activement au maintien de ce système. Dès lors, la communauté scientifique internationale aurait une responsabilité morale de boycotter les institutions académiques israéliennes. Cet argumentaire entre en tension avec la conception traditionnelle de la liberté académique où les chercheurs sont supposés être autonomes vis-à-vis des gouvernements et ne peuvent être tenus responsables des politiques étatiques.
Le positionnement des recteurs belges s’inscrit également dans l’ordre international construit après 1945 autour des droits humains universels. Le principe de la « responsabilité de protéger » (R2P), approuvé par l’Assemblée générale des Nations unies en 2005, a renforcé l’idée qu’il existe une obligation collective de s’opposer aux formes graves d’oppression et aux crimes contre l’humanité. Cette obligation légale est cependant celle des États et non celle des individus ou des universités.
Ainsi, le débat autour des boycotts académiques oppose deux conceptions très différentes de la liberté académique et ne peut se réduire à une simple opposition entre partisans et opposants à Israël.
Les dangers d’une transformation des universités en acteurs politiques
Les nouvelles normes académiques incluant une responsabilité morale pourraient encourager les autorités académiques à adopter des positions officielles sur chaque conflit international. Dans un monde de plus en plus marqué par des différends territoriaux, les boycotts académiques pourraient se banaliser et entraîner la résurgence de mouvements scientifiques nationalistes là où ils avaient disparu, un résultat qui représenterait une profonde régression.
Les boycotts ont un coût direct pour les universités. Par exemple, la Floride a inscrit des universités belges sur une liste noire pour avoir boycotté Israël. La rectrice de l’Université de Gent Petra De Sutter a admis que son université a perdu de nombreux partenariats et évoque la diminution du nombre de projets de recherche, des financements alloués à la recherche et du nombre de doctorats.
La politisation croissante des universités pourrait changer la perception publique et gouvernementale des institutions et de l’expertise académiques. Les universités pourraient devenir des cibles politiques, ce qui affecterait leur financement. La confiance envers les diplômés pourrait s’éroder, alimentant le ressentiment populaire envers les élites et contribuant à la montée du populisme.
Plus important, si l’expertise académique et scientifique devenait perçue comme politiquement orientée, sa crédibilité en tant que fondement objectif des délibérations publiques serait gravement compromise. Les conséquences à long terme de l’abandon de la neutralité institutionnelle par les universités au profit de l’activisme politique justifient donc un examen approfondi et soutenu.
Face à ces menaces, plus de 160 universités américaines, dont Columbia, Cornell, Harvard, Princeton et Stanford, ont officiellement adopté en 2024 et en 2025 des politiques de neutralité ou de retenue institutionnelle. En France, Luis Vassy, directeur de Sciences Po Paris, a imposé en 2025 un principe de « réserve institutionnelle » afin de préserver la pluralité d’opinion et l’organisation de débats pluralistes sur le campus. Certains auteurs dénoncent ces choix comme étant une « stratégie fondée sur la peur » servant un agenda politique conservateur et un « mécanisme pour échapper à la responsabilité, masquer le pouvoir et perpétuer l’inégalité ».
Les débats sur la neutralité institutionnelle et les boycotts académiques sont donc loin d’être clos. Ils dépassent le cadre du conflit israélo-palestinien et ont pour enjeu la redéfinition des missions des universités.
Eric Muraille a reçu des financements de FRS-FNRS (Belgium)
Joël Kotek ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
24.06.2026 à 14:52
La démocratie en recul face à la poussée des autoritarismes
Pierre-Yves Hénin, Professeur émérite en économie, Université Paris 1 Panthéon-Sorbonne
Texte intégral (1769 mots)
Alors que les relations internationales traversent une phase de turbulences et de redéfinitions, plusieurs grandes puissances semblent converger vers des modèles de gouvernance mêlant fermeture nationale, interventionnisme économique et concentration des pouvoirs. Dans Trump, Poutine et Xi Jinping. Le national capitalisme autoritaire, modèle pour un nouvel ordre mondial, Pierre-Yves Hénin, professeur émérite à l’Université Paris 1 Panthéon-Sorbonne, propose un cadre d’analyse pour penser ces évolutions et poursuit sa réflexion sur le concept de « national capitalisme autoritaire » (NaCA) déjà entamée dans un ouvrage précédent.
Joe Biden a révélé que, le soir de son élection à la Maison-Blanche en 2020, le président chinois, tout en le félicitant, lui a déclaré que « les démocraties ne peuvent perdurer au XXIᵉ siècle, ce sont les autocraties qui dirigeront le monde. Pourquoi ? Les choses changent si rapidement. Les démocraties exigent un consensus, et cela prend du temps, et vous n’avez pas le temps ».
Effectivement, les historiens de demain considéreront le mouvement quasi général de recul de la démocratie dans les décennies 2010 et 2020 comme le plus grand changement politique intervenu depuis le milieu du XXᵉ siècle, plus important même que l’effondrement du communisme au début des années 1990, un changement conforté par la réélection de Donald Trump en novembre 2024 avec un programme radicalisé.
L’affirmation de Xi Jinping apparaît en phase avec la montée des mouvements et des pays autoritaires dont la crise financière globale de 2007-2008 a été un accélérateur. Depuis cette crise, on constate un recul général de la démocratie dans le monde. L’autocratisation est devenue le nouveau défi planétaire.
Actualisé d’année en année, l’état des lieux dressé par l’institut V-Dem, parmi d’autres organismes spécialisés, documente la marée montante des autoritarismes. Faisant suite à des constats déjà alarmants pour 2023 et 2024, le rapport du V-Dem pour l’année 2025, publié en mars 2026, s’ouvre sur une interrogation préoccupante : « L’ère démocratique touche-t-elle à sa fin ? », tandis que le rapport de Freedom House s’ouvre sur le constat de « l’ombre grandissante de l’autocratie ».
Le monde comporte plus d’autocraties (92) que de démocraties (87). 74 % de la population mondiale vit dans des régimes autoritaires et le poids économique des démocraties est à son plus bas niveau depuis cinquante ans. Le basculement engagé aux États-Unis aggravera encore ce bilan.
Une vague mondiale d’autocratisation
La montée des autoritarismes se manifeste par un recul des libertés fondamentales. En 2025, ces libertés avaient décliné pour la vingtième année consécutive dans le monde.
La promotion de la non-démocratie n’est pas maintenant le fait de dictateurs marginaux mais bien de Xi Jinping, le dirigeant de la deuxième puissance économique de la planète avant que Donald Trump, dirigeant de la première, ne lui emboîte le pas. Le constat selon lequel authoritarianism goes global s’est maintenant imposé.
Dans nombre de pays, l’exercice du pouvoir politique devient plus arbitraire et répressif. L’espace de contestation publique plus restreint réduit ainsi les possibilités d’une alternance même si les élections relativement libres sont formellement maintenues. La remise en cause des acquis de la démocratie par des interventions militaires, par la manipulation du processus électoral, par la mise sous tutelle de la justice et des médias s’accompagne aussi du recul de l’attractivité et de l’effectivité du modèle de capitalisme libéral, fragilisé par ses propres dérapages. Ce recul, qui est manifeste au niveau international, est aussi présent dans la sphère occidentale où l’on constate dans la plupart des pays la montée des mouvements politiques autoritaires ou populistes nationalistes, certains d’entre eux accédant au pouvoir ou sur le point d’y accéder.
L’attaque de l’Ukraine par la Russie et la guerre entre Israël et Hamas dans la bande de Gaza ont accéléré cet affaiblissement, dans une grande partie du monde, du tropisme du modèle occidental et des valeurs universelles dont il est le promoteur. Par ailleurs, la vague de démocratisation des années 1990 s’accompagnait de l’idée selon laquelle les principales caractéristiques institutionnelles des pays développés pouvaient être reproduites à l’échelle mondiale dans un avenir proche.
Thomas Carothers diagnostiquait pourtant la fin du paradigme de transition et remettait en cause l’approche de democracy-promotion community parce que ce type d’approche, trop dépendant d’un tropisme occidental, se focalisait principalement sur le processus et les institutions politiques en méconnaissant l’importance des questions socioculturelles et économiques dans le processus de démocratisation. Cette croyance dans la capacité de promouvoir, voire d’imposer, la démocratie devait servir de prétexte, à côté d’autres facteurs politico-économiques, à la guerre menée en 2003 par les États-Unis contre l’Irak de Saddam Hussein, aux effets particulièrement destructeurs, favorisant une nouvelle vague d’autocratisation.
Fukuyama et la fin d’un monde unipolaire
Faut-il en conclure à un échec complet de la prophétie de Fukuyama annonçant la fin de l’histoire par la victoire définitive de la démocratie et du capitalisme ? Pas totalement. Si l’annonce de la victoire définitive et universelle de la démocratie s’est avérée fausse, en revanche le capitalisme n’a pas connu sur le plan international une remise en cause significative, bien au contraire.
À la différence de la période de la Guerre froide où s’opposaient le bloc capitaliste démocratique et un bloc communiste à économie planifiée, le nouvel affrontement oppose deux capitalismes qui sont parties prenantes d’un capitalisme global. Ainsi, tandis que l’affrontement géopolitique et systémique des années 1945-1991 divisait le monde en deux pôles respectifs, capitaliste et communiste, le capitalisme global de la nouvelle guerre froide tend à se structurer en un monde multipolaire, mettant fin au « long moment unipolaire ».

Ce recul de la démocratie et du système occidental a fait l’objet de multiples travaux. Le projet de ce livre n’est pas d’y ajouter un nième ouvrage. Il est plutôt de caractériser le modèle alternatif qui bénéficie de ce recul. La confrontation en cours ne se poursuit pas seulement entre les démocraties et les autocraties, elle se manifeste aussi par une crise du « capitalisme démocratique », largement vécue comme telle dans le monde occidental. À partir de ce constat, notre objectif est de proposer les moyens de compréhension d’un monde bouleversé, d’identifier les principaux sujets de tensions et les régimes alternatifs qui surgissent ou se renforcent face au déclin que connaît le modèle de capitalisme qualifié de démocratique et libéral.
Ceci exige nécessairement une approche pluridisciplinaire, associant la science politique et l’économie, et sollicitant les regards historiques ou géopolitiques. L’idée défendue dans ce livre est que le modèle de démocratie occidentale, au-delà des divergences et des rivalités géopolitiques, économiques et culturelles qui le traversent, se trouve confronté à un système combinant autoritarisme et nationalisme avec un capitalisme adapté à ce contexte sociopolitique. La Chine et la Russie représentent aujourd’hui, chacune sous des modalités différentes, les formes paradigmatiques de ce modèle.
Pierre-Yves Hénin ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview