
10.07.2026 à 11:01
3I/Atlas, une comète venue d’une autre étoile qui ne ressemble à rien de connu dans le Système solaire
Matthew Hopkins, Postdoctoral Fellow, University of Canterbury
Texte intégral (1827 mots)

Troisième objet interstellaire jamais détecté, 3I/Atlas ne ressemble à aucune comète du Système solaire. Sa composition et son âge exceptionnel en font un précieux témoin de la jeunesse de notre galaxie.
Des astronomes viennent de révéler de nouveaux détails sur la composition et l’âge d’une comète de passage, née autour d’une étoile lointaine. Ils concluent de leurs travaux que la composition de 3I/Atlas est radicalement différente de celle de tous les objets connus de notre Système solaire.
Trois études, publiées récemment et ici, apportent ainsi un nouvel éclairage sur les origines de cette comète hors du commun. 3I/Atlas semble s’être formée dans un environnement très froid, il y a environ 12 milliards d’années.
La comète est un objet interstellaire (interstellar object, ou ISO), c’est-à-dire un astéroïde ou une comète provenant de l’extérieur du Système solaire. Il s’agit du troisième objet de ce type jamais identifié, après 1I/ʻOumuamua et 2I/Borisov. Elle a été découverte il y a presque exactement un an, alors qu’elle arrivait de l’espace interstellaire sur une trajectoire traversant le Système solaire interne avant de s’en éloigner de nouveau.
Ces origines lointaines rendent les objets interstellaires particulièrement fascinants pour les astronomes, car ils constituent des fragments matériels d’autres systèmes planétaires, apportés jusqu’à nous par les courants gravitationnels de la galaxie et que nous pouvons étudier sans quitter le confort de notre propre Système solaire.
En tant que comète, 3I/Atlas contenait des glaces qui se sont sublimées, c’est-à-dire qu’elles sont passées directement de l’état solide à l’état gazeux. En se réchauffant sous l’effet du Soleil, ces gaz se sont échappés de la comète, donnant naissance à une spectaculaire chevelure (ou coma), l’enveloppe lumineuse qui entoure son noyau, ainsi qu’à une longue queue.
Une comète ne possède pas de source de lumière propre. La poussière présente dans sa chevelure réfléchit la lumière du Soleil, tandis que ses composés volatils (des substances qui se vaporisent ou se subliment facilement) émettent une fluorescence.
Mais il ne s’agit pas d’un simple spectacle lumineux : chaque molécule fluorescente laisse une empreinte spectrale dans la lumière qui parvient jusqu’à nos télescopes. Ces signatures permettent d’identifier les composés chimiques présents dans la comète.
Pour les révéler, les astronomes décomposent la lumière en ses différentes longueurs d’onde grâce à une technique appelée spectroscopie. Ils peuvent ainsi déterminer la composition chimique de la comète.
Un cocktail chimique inédit
Les observations ont révélé que 3I/Atlas renferme un mélange d’eau, de dioxyde et de monoxyde de carbone, de méthane, de cyanures, de sulfures, ainsi que d’atomes de fer et de nickel à l’état libre. Pris séparément, ces composés n’ont rien d’inhabituel : ils sont régulièrement détectés dans les comètes de notre propre Système solaire. En revanche, leurs proportions diffèrent nettement dans 3I/Atlas. Sa forte teneur en dioxyde de carbone (CO2) et sa faible abondance en ammoniac (NH3) trahissent son origine extérieure au Système solaire.
Les molécules constituées d’atomes appartenant à différents isotopes (des variantes d’un même élément chimique) présentent également des signatures spectrales légèrement différentes. Grâce à l’éclat de 3I/Atlas et à la puissance des plus grands télescopes, les astronomes ont pu distinguer ces signatures et mesurer les rapports isotopiques de la comète.
L’une des nouvelles études, publiée dans Nature, s’appuie sur les signatures spectrales de l’eau et du dioxyde de carbone mesurées par le télescope spatial James Webb pour déterminer le rapport entre les deux principaux isotopes du carbone, le 12C et le 13C, présents dans 3I/Atlas, ainsi que son rapport deutérium/hydrogène (D/H), le deutérium étant une forme lourde de l’hydrogène.
Ces résultats sont particulièrement enthousiasmants, car les rapports isotopiques d’un objet interstellaire comme 3I/Atlas sont censés refléter ceux du disque protoplanétaire dans lequel il s’est formé. Ils permettent donc de reconstituer avec une grande précision les conditions de sa formation, ainsi que les caractéristiques de l’étoile autour de laquelle il est né.
L’eau de 3I/Atlas présente un rapport deutérium/hydrogène (D/H) d’environ 1 %, soit une valeur nettement supérieure à celle mesurée dans toutes les comètes connues du Système solaire.
De telles concentrations en deutérium ne se rencontrent que dans des environnements extrêmement froids, où la température est inférieure à 30 kelvins (-243 °C). Dans ces conditions, les atomes d’hydrogène « ordinaires » sont progressivement remplacés par des atomes de deutérium, plus lourds, dans la glace d’eau qui recouvre de minuscules grains de poussière. Avec le temps, ces grains glacés s’agglomèrent pour former des comètes.
Une voyageuse venue des premiers âges de la galaxie
Le rapport 12C/13C de 3I/Atlas est lui aussi exceptionnel, bien supérieur à toutes les valeurs mesurées dans le Système solaire. Ce rapport isotopique fonctionne comme une véritable horloge cosmique. Au début de l’histoire de l’Univers, la première génération d’étoiles produisait un carbone très riche en 12C par rapport au 13C. Puis, au fil des cycles de naissance et de mort des étoiles, ce rapport a progressivement diminué. Si 3I/Atlas présente une valeur aussi élevée, c’est qu’elle s’est formée très tôt dans l’histoire de la Voie lactée, il y a environ 12 milliards d’années.
Des études menées peu après sa découverte avaient déjà suggéré que 3I/Atlas était probablement âgée d’au moins 7 milliards d’années, d’après sa vitesse. Son ancienneté est donc désormais étayée par plusieurs indices indépendants.
Si le ciel nocturne, au-delà des confins du Système solaire, peut sembler immuable, l’Univers comme notre galaxie évoluent bel et bien, à l’échelle de milliards d’années.

Lorsque 3I/Atlas s’est formée, l’Univers était encore dans sa prime jeunesse et la Voie lactée était encore en train de se construire, au gré de violentes collisions et fusions avec d’autres galaxies.
Si l’étoile autour de laquelle 3I/Atlas s’est formée avait une masse comparable à celle du Soleil, elle a probablement déjà achevé son existence. Les objets interstellaires qu’elle a éjectés peu après sa naissance, comme 3I/Atlas, lui ont ainsi survécu.
Au cours des dix prochaines années, de nouveaux télescopes de pointe dédiés à la découverte d’objets célestes, comme le NEO Surveyor de la NASA et l’observatoire Vera C. Rubin, au Chili, devraient multiplier par dix le nombre d’objets interstellaires connus. Cette moisson offrira aux astronomes une véritable archive fossile de l’évolution des systèmes planétaires tout au long de l’histoire de la Voie lactée.
Matthew Hopkins a reçu une bourse Elaine P. Snowden Fellow à l'université de Canterbury, en Nouvelle-Zélande.
10.07.2026 à 11:00
Les algues ne sont pas des plantes… et six autres faits surprenants sur la flore aquatique
Alexander Bowles, Glasstone Research Fellow, Plant Science, University of Oxford
Texte intégral (2748 mots)

Des plantes sans racines, d’autres carnivores, certaines capables de fleurir sous l’eau… Les plantes aquatiques ont développé des adaptations spectaculaires qui défient notre vision du monde végétal.
À l’abri des regards, sous la surface des eaux, se déploie un monde végétal d’une étonnante inventivité et parmi les plus importants sur le plan écologique.
Comme je le souligne dans une publication récente, les plantes aquatiques ont développé une extraordinaire diversité d’adaptations pour vivre sous l’eau. Certaines fleurissent sous la surface, d’autres capturent des animaux grâce à d’ingénieux pièges. Voici sept faits qui montrent à quel point ces organismes remarquables bousculent nos idées reçues sur ce qu’est une plante et sur les stratégies qu’elle déploie pour survivre.
1. Les plantes n’en finissent pas de retourner à l’eau
Quand on pense aux plantes, on imagine spontanément les forêts, les prairies ou les champs. Pourtant, au cours de leur histoire évolutive, les plantes sont retournées à de nombreuses reprises dans le milieu aquatique, là même où elles sont apparues. Il y a environ 500 millions d’années, elles ont conquis les terres émergées. Depuis, nombre d’entre elles ont fait le chemin inverse. Les scientifiques estiment que le mode de vie aquatique est apparu indépendamment plus de 100 fois au sein de différents groupes de plantes.
Les nénuphars font flotter leurs feuilles à la surface, les lentilles d’eau dérivent librement et les herbiers marins vivent entièrement immergés dans l’océan. Certains de ces groupes sont retournés à l’eau il y a plus de 100 millions d’années. Cette réapparition répétée des plantes aquatiques constitue l’un des exemples les plus spectaculaires de l’évolution convergente dans la nature.
2. Les plantes qui n’en sont pas
Parmi les organismes les plus visibles sous la surface de l’eau figurent les algues. Elles réalisent la photosynthèse et ressemblent souvent à des plantes sous-marines. Pourtant, malgré les apparences, les algues ne sont pas de véritables plantes.

Les algues marines appartiennent en réalité à plusieurs lignées d’algues distinctes dans l’arbre du vivant. Les laminaires géantes, qui forment de véritables forêts sous-marines, sont des algues brunes. Le nori et la dulse sont des algues rouges, tandis que la laitue de mer appartient aux algues vertes.
Contrairement aux plantes, elles ne possèdent ni véritables racines, ni tiges, ni feuilles, et ne produisent ni fleurs ni graines. Leur ressemblance avec les plantes rappelle toutefois que l’évolution peut conduire à des formes très similaires chez des organismes pourtant très éloignés, lorsqu’ils sont confrontés aux mêmes contraintes environnementales.
3. Des plantes qui vivent dans les profondeurs
Les plantes ont besoin de lumière pour réaliser la photosynthèse, ce qui les cantonne généralement aux milieux terrestres ou aux eaux peu profondes. Pourtant, certaines mousses aquatiques survivent à des profondeurs étonnantes. La faucillette courbée (Drepanocladus aduncus) a ainsi été observée à 140 mètres sous la surface dans les eaux exceptionnellement limpides de Crater Lake, dans l’État américain de l’Oregon. Il s’agit de la plante aquatique connue poussant aussi sur terre qui vit à la plus grande profondeur, environ la hauteur de la cathédrale de Strasbourg.
Des mousses de grande profondeur ont également été recensées dans des lacs de Nouvelle-Zélande, d’Antarctique et d’autres régions. Elles prospèrent dans des environnements si profonds qu’ils sont presque totalement privés de lumière et où très peu d’animaux peuvent survivre.
4. Des plantes sans racines
Les racines sont l’une des caractéristiques emblématiques des plantes. Elles les ancrent dans le sol et y puisent l’eau ainsi que les nutriments. Pourtant, de nombreuses plantes aquatiques ont considérablement réduit leur système racinaire, et certaines semblent même avoir complètement perdu leurs racines.

La vie sous l’eau change les règles du jeu. L’eau et les nutriments dissous entourent directement la plante, rendant les vastes systèmes racinaires beaucoup moins utiles que sur terre. De nombreuses espèces aquatiques absorbent ainsi les nutriments directement par leurs feuilles et leurs tiges.
Les lentilles d’eau en offrent l’un des exemples les plus extrêmes. Certaines espèces ne possèdent qu’une seule racine, contrairement à des parentes comme la grande lentille d’eau, qui en développe plusieurs. Quant aux espèces du genre Wolffia – les plus petites plantes à fleurs du monde –, elles n’ont plus aucune racine et flottent librement à la surface de l’eau. Un individu mesure à peine un millimètre de long et ses fleurs ne dépassent pas 0,3 millimètre.
5. Des plantes carnivores sous l’eau
Toutes les plantes aquatiques ne se contentent pas de la lumière du Soleil et des nutriments dissous dans l’eau. Certaines complètent leur alimentation en capturant et en digérant de petits animaux.
Les exemples les plus spectaculaires sont les utriculaires (Utricularia), un groupe de plantes aquatiques dépourvues de racines que l’on trouve dans les eaux douces du monde entier. Leurs feuilles se sont transformées en minuscules pièges en forme de vessie qui créent un vide en expulsant l’eau contenue dans leur cavité.

Lorsqu’un minuscule animal effleure les poils sensitifs situés à l’entrée du piège, une trappe s’ouvre brusquement et la proie est aspirée en moins d’une milliseconde. Les pièges des utriculaires figurent ainsi parmi les mouvements les plus rapides du règne végétal. S’ils capturent le plus souvent de petits invertébrés aquatiques, il leur arrive aussi de piéger des larves de poissons et des têtards.
Ce mode de vie carnivore permet aux utriculaires de prospérer dans des eaux pauvres en nutriments, où la plupart des autres plantes peinent à survivre.
6. Une pollinisation portée par les courants
Quand on pense à la pollinisation des plantes, on imagine volontiers des abeilles butinant de fleur en fleur par une belle journée ensoleillée. Mais sous l’eau, la pollinisation devient beaucoup plus compliquée. Au lieu de compter sur les insectes ou le vent, de nombreuses plantes aquatiques, comme les herbiers marins, utilisent directement les courants pour transporter leur pollen jusqu’à sa destination.
Sur terre, les plantes attirent leurs pollinisateurs en diffusant des parfums dans l’air. Sous l’eau, en revanche, ces signaux volatils sont inefficaces. Cette contrainte a conduit à un changement évolutif : les plantes entièrement aquatiques, comme les herbiers marins, ont perdu les gènes responsables de la production de ces composés odorants. Ne procurant plus d’avantage, ils ont progressivement disparu au cours de l’évolution.
7. Les herbiers marins et les mangroves, de puissants puits de carbone
Les herbiers marins et les mangroves capturent et stockent le carbone dans leurs tissus ainsi que dans les sédiments qui les entourent, ce qui les classe parmi les puits de carbone naturels les plus efficaces de la planète. Ensemble, ils emmagasinent ce que les scientifiques appellent le « carbone bleu » : le carbone piégé dans les écosystèmes côtiers, où il peut rester stocké pendant des siècles, voire des millénaires.

À l’échelle mondiale, ces écosystèmes – herbiers marins et mangroves – stockent 11,5 milliards de tonnes de carbone. Les mangroves représentent à elles seules le plus grand réservoir de carbone bleu, avec 6,5 milliards de tonnes.
Qu’elles capturent leurs proies en quelques fractions de milliseconde, poussent dans une quasi-obscurité ou stockent du carbone pendant des siècles, les plantes aquatiques témoignent de l’extraordinaire capacité du vivant à s’adapter.
Alexander Bowles a reçu une bourse « Glasstone Fellowship » à l'Université d'Oxford.
09.07.2026 à 17:26
Avec « The Mandalorian », comprendre les enjeux derrière les métaux rares
Olivier Pourret, Enseignant-chercheur en géochimie et responsable intégrité scientifique et science ouverte, UniLaSalle
Elodie Pourret-Saillet, Enseignante-chercheuse en géologie structurale, UniLaSalle
Texte intégral (2849 mots)

Armures étincelantes, forges ancestrales et batailles galactiques : dans l’univers de Star Wars, le « beskar » occupe une place à part. Ce métal légendaire, au cœur de l’identité mandalorienne, est réputé presque indestructible. Il résiste aux tirs de blaster et autres pistolasers, supporte des températures extrêmes et constitue un héritage transmis de génération en génération.
Avec la sortie en salle, le 20 mai dernier, de The Mandalorian and Grogu, premier film Star Wars à retrouver les écrans de cinéma depuis l’Ascension de Skywalker en 2019, le « beskar », matériau légendaire, revient au centre du récit. Présenté comme quasiment indestructible, capable de résister aux tirs de blaster et même aux sabres laser, le beskar appartient évidemment au domaine de la fiction.
Pourtant, derrière cette invention scénaristique se cache une réalité étonnamment familière : notre monde dépend lui aussi de matériaux rares, concentrés dans quelques régions du monde, convoités par les grandes puissances et devenus indispensables au fonctionnement des technologies modernes. La galaxie de Star Wars n’est peut-être pas aussi éloignée de nos préoccupations géologiques qu’elle en a l’air.
Un métal fictif qui ressemble à nos ressources stratégiques
Dans The Mandalorian, le beskar est bien davantage qu’un simple matériau. Il est rare, convoité, difficile à extraire et étroitement associé à une région unique de la galaxie : la planète Mandalore. Sa possession confère un avantage décisif, qu’il soit militaire, politique ou symbolique.
Cette situation n’est pas sans rappeler celle de certaines matières premières que géologues et économistes qualifient aujourd’hui de « critiques » ou de « stratégiques ». Ces ressources sont indispensables au fonctionnement de technologies essentielles, mais leur production demeure concentrée dans un nombre limité de pays, créant des dépendances parfois importantes.
Les terres rares en constituent sans doute l’exemple le plus connu. Derrière ce nom se cache un groupe de 17 éléments chimiques utilisés dans les aimants permanents des éoliennes, les moteurs de véhicules électriques, les smartphones ou encore certains équipements militaires. D’autres métaux, comme le cobalt, le gallium, le germanium ou l’indium, jouent également un rôle central dans les batteries, les semi-conducteurs ou les écrans tactiles.
Comme le beskar, ces ressources se distinguent moins par leur valeur marchande que par leur importance stratégique.
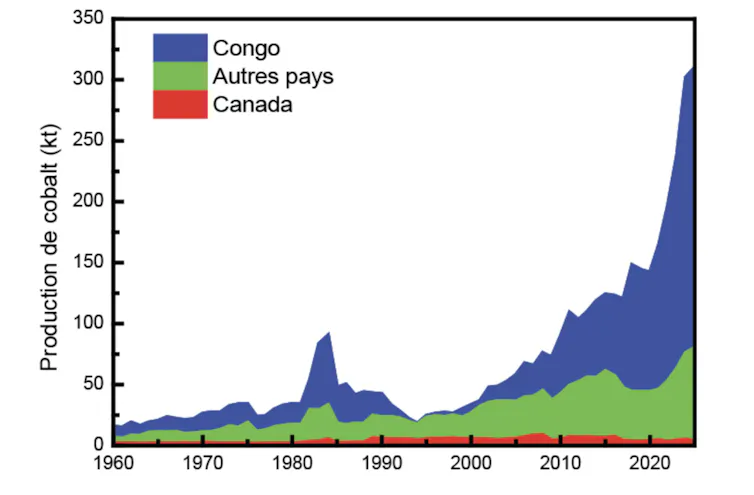
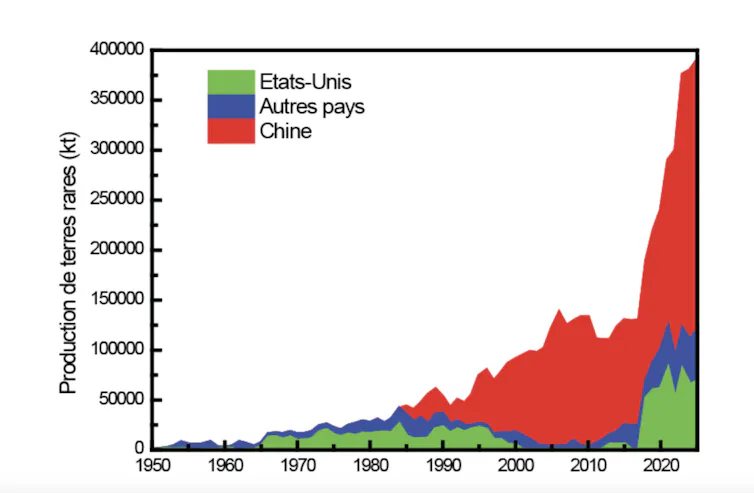
Leur répartition géographique est également très inégale. En 2025, la Chine assure près de 69 % de la production mondiale de terres rares et domine largement leur transformation industrielle. La République démocratique du Congo fournit quant à elle près des trois quarts du cobalt extrait dans le monde. Cette concentration crée une dépendance structurelle pour les grandes puissances industrielles, à l’image de celle que connaît la galaxie fictive de Star Wars vis-à-vis du beskar de Mandalore.
Quand la géologie rejoint la science-fiction
Les créateurs de Star Wars n’ont évidemment pas conçu le beskar comme un objet géologique. Pourtant, les propriétés qu’ils lui attribuent présentent une certaine cohérence avec ce que nous connaissons des matériaux les plus performants développés par l’industrie moderne.
Le beskar est présenté comme un alliage plutôt que comme un élément pur. Ce choix est particulièrement crédible. Dans le monde réel, les matériaux aux propriétés mécaniques exceptionnelles résultent presque toujours d’associations complexes entre plusieurs éléments chimiques.
L’acier inoxydable combine ainsi fer, chrome et nickel. Les alliages de titane utilisés dans l’aéronautique incorporent de l’aluminium et du vanadium. Les superalliages employés dans les turbines aéronautiques peuvent contenir une dizaine d’éléments différents afin de résister simultanément aux contraintes mécaniques, à l’oxydation et aux températures extrêmes.
La résistance thermique du beskar évoque également certains métaux réfractaires bien connus des géologues et des métallurgistes. Le tungstène, par exemple, possède la température de fusion la plus élevée parmi les métaux connus, atteignant 3 422 °C. Le rhénium, plus rare encore, est utilisé dans les composants soumis à des températures particulièrement élevées, notamment dans l’industrie aéronautique.

){kind=link}
Quant à sa capacité à absorber des impacts sans se rompre, elle rappelle les recherches menées depuis une vingtaine d’années sur les alliages à haute entropie. Ces matériaux de nouvelle génération associent plusieurs éléments en proportions voisines, produisant des combinaisons inédites de dureté, de résistance mécanique et de résistance à la corrosion.
Bien sûr, aucun de ces matériaux ne pourrait réellement arrêter un sabre laser. Mais la logique scientifique qui sous-tend le beskar apparaît moins fantaisiste qu’il n’y paraît au premier abord.
Des ressources au cœur des rapports de puissance
La comparaison devient encore plus frappante lorsqu’on s’intéresse à la géopolitique des ressources.
Dans l’univers du Mandalorian, le contrôle du beskar constitue un enjeu de pouvoir majeur. Les conflits qui entourent son extraction, sa circulation et sa réappropriation participent directement à l’équilibre politique de la galaxie. L’histoire récente fournit plusieurs exemples comparables.
En 2010, dans un contexte de tensions territoriales avec le Japon, la Chine a temporairement restreint ses exportations de terres rares. L’événement a provoqué une forte inquiétude parmi les industriels dépendants de ces matériaux et a accéléré les réflexions sur la diversification des approvisionnements.
Plus récemment, Pékin a instauré des restrictions à l’exportation concernant le gallium, le germanium, puis d’autres matériaux stratégiques utilisés dans les semi-conducteurs et les technologies de défense.
Ces épisodes rappellent que les matières premières critiques ne constituent pas seulement des ressources économiques. Elles représentent également des instruments d’influence et de souveraineté.
Face à ces enjeux, l’Union européenne a adopté en 2024 le Critical Raw Materials Act, destiné à renforcer la sécurité d’approvisionnement en matières premières critiques, à développer les capacités de recyclage et à diversifier les sources d’importation. Les États-Unis poursuivent des objectifs similaires à travers différents programmes de soutien à l’industrie minière et métallurgique.
Face à cette dépendance, deux grandes stratégies s’offrent aux pays importateurs : diversifier les sources d’extraction ou apprendre à récupérer ce que l’on a déjà consommé. C’est cette deuxième voie, celle du recyclage, que la série illustre, sans le savoir, avec une grande précision.
Le recyclage, ou l’art mandalorien appliqué à nos déchets
L’un des aspects les plus intéressants de la série réside peut-être dans la place accordée au recyclage du beskar. À plusieurs reprises, le personnage de l’armurière récupère d’anciens fragments de métal pour les fondre et leur donner une nouvelle forme. Dans la fiction, ce geste possède une dimension culturelle et spirituelle forte : il permet de préserver un héritage tout en l’adaptant aux besoins du présent.
Cette pratique fait écho à un défi bien réel. Aujourd’hui, moins de 1 % des terres rares contenues dans les produits en fin de vie sont effectivement recyclées. Les obstacles sont nombreux : faibles concentrations dans les objets, difficultés de démontage, coûts élevés des procédés de récupération ou encore insuffisance des filières de collecte.
Pourtant, les millions de véhicules électriques, d’éoliennes et d’équipements électroniques actuellement en circulation constituent déjà un immense gisement urbain de métaux stratégiques.
De nombreux programmes de recherche européens et asiatiques cherchent ainsi à développer de nouvelles méthodes permettant de récupérer le néodyme des aimants permanents ou le cobalt contenu dans les batteries. À leur manière, ces chercheurs pratiquent eux aussi une forme de forge moderne : ils transforment les déchets technologiques d’aujourd’hui en ressources stratégiques de demain.
Ce que le beskar révèle de notre monde
Au fond, The Mandalorian ne raconte pas une histoire de métallurgie. La série parle avant tout d’identité, de transmission, de mémoire collective et de résilience culturelle.
Mais si le beskar occupe une place aussi centrale dans cet univers, c’est précisément parce qu’il matérialise ces enjeux sous une forme immédiatement compréhensible. La rareté de la ressource, la dépendance qu’elle crée et les conflits qu’elle suscite donnent une profondeur supplémentaire aux thèmes explorés par la fiction.
Comme souvent, la science-fiction agit ici comme un miroir. Elle déplace les questions dans une galaxie imaginaire pour mieux éclairer celles qui traversent notre propre société.
Les terres rares, le cobalt ou le gallium ne bénéficient pas de l’aura mythique du beskar. Leurs noms sont moins évocateurs et leurs propriétés moins spectaculaires. Pourtant, ils jouent un rôle tout aussi déterminant dans les transformations technologiques, énergétiques et géopolitiques du XXIᵉ siècle.
La fiction n’invente donc pas tant qu’elle ne révèle. En imaginant un métal rare dont le contrôle influence le destin d’une galaxie entière, Star Wars nous invite à porter un regard nouveau sur les ressources dont dépend notre propre avenir.
Ignorer cette réalité, c’est avancer dans la galaxie sans armure : vulnérable, exposé, dépendant des autres.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.07.2026 à 10:00
Une découverte inattendue : des traces de séismes anciens dans le Bassin parisien
Stéphane Baize, Géologue des tremblements de terre, Directeur de Recherches, ASNR
Pierre Louis Antoine, Directeur de Recherche CNRS, géoloque et géomorphologue spécialiste des paléoenvironnements du Quaternaire, Centre national de la recherche scientifique (CNRS)
Texte intégral (1776 mots)
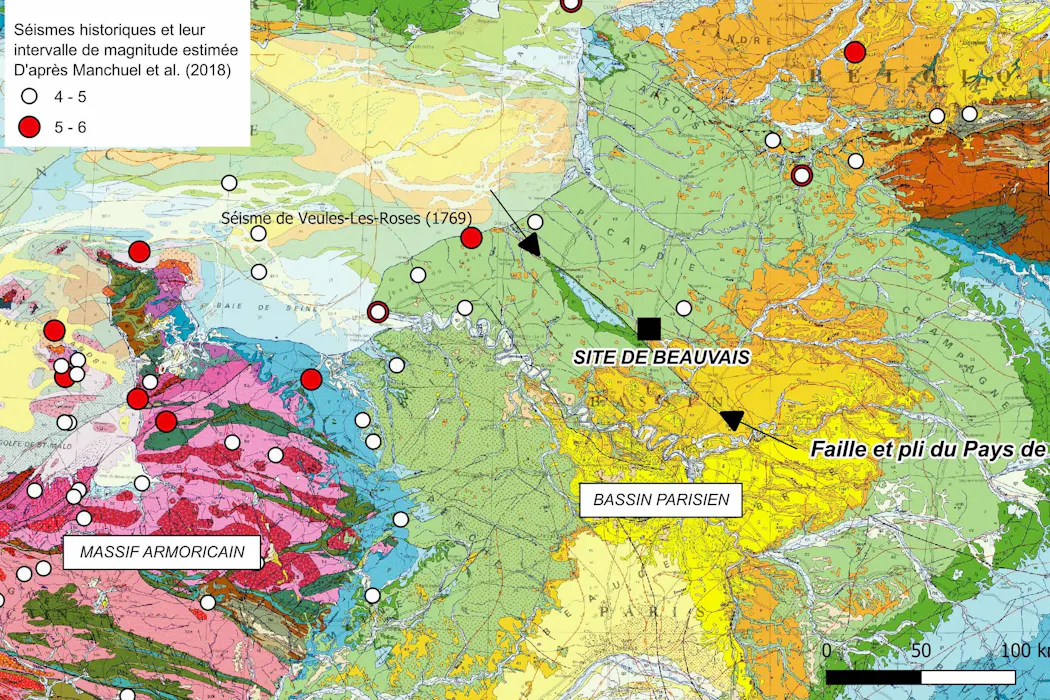
En 1993, lors de fouilles archéologiques préventives pour la construction d’une route à Beauvais, dans l’Oise, des géologues et des archéologues ont mis au jour un site paléolithique exceptionnel. Occupé par des néandertaliens il y a environ 60 000 ans, il révèle bien plus que des outils en silex ou des ossements d’animaux, de mammouths, de rennes et de rhinocéros laineux.
En effet, nous avons identifié un réseau de failles traversant les dépôts sédimentaires récents et les restes archéologiques associés ainsi que le substrat rocheux (ici, la craie). Dans notre étude publiée ce mois-ci dans les Comptes Rendus Géoscience, nous proposons une nouvelle interprétation à ces déformations : elles seraient d’origine sismique.
Les failles que nous observons présentent des décalages verticaux cumulés jusqu’à 25 centimètres (pour comparaison, c’est significativement plus grand que celles mesurées après le séisme de magnitude proche de 5 qui a secoué et endommagé les communes du Teil, de Viviers et Saint-Thomé en Ardèche, le 11 novembre 2019).
Ces failles ne peuvent pas être expliquées par des phénomènes comme l’effondrement liés à la dissolution de la craie (le « karst »), ni par le gel et le dégel de sols riches en glace (appelé « pergélisol », ni enfin par l’activité humaine…
C’est pourquoi l’hypothèse la plus plausible est une origine tectonique, c’est-à-dire que le déplacement soit lié aux mouvements de la croûte terrestre pendant un ou plusieurs séismes. Cette origine devra être confirmée par des études complémentaires, notamment par des explorations du sous-sol, ou la recherche d’autres indices similaires par d’autres fouilles dans la même zone.

Les structures que nous avons observées sont cohérentes avec l’expression superficielle de ruptures sismiques profondes, qui seraient liées au grand pli et à la faille du Pays de Bray, une des structures géologiques majeures du Bassin parisien, qui s’enracine à plusieurs kilomètres dans la croûte terrestre.
Si les failles observées à Beauvais sur le site du lieu-dit « La Justice » sont bien liées à un séisme ancien, leur taille et leur décalage suggèrent un événement d’une magnitude d’au moins 5,5.
Pourquoi cette découverte est-elle importante ?
Le Bassin parisien est traditionnellement considéré comme une région peu sismique, avec une activité tectonique quasi nulle depuis des millénaires. On n’y connaît guère que quelques séismes historiques, comme celui de Veules-les-Roses, dans l’actuelle Seine-Maritime, en 1769 (magnitude estimée proche de 5), qui a causé des dégâts localement.
La découverte de Beauvais modifie notre perception du « danger » sismique dans la zone. Elle suggère, par l’ampleur des déformations observées, qu’il n’est pas négligeable et que des séismes forts ont pu se produire sur des failles il y a seulement 50 000 à 60 000 ans, une période géologiquement récente.
Une autre conséquence est qu’on peut maintenant considérer la faille du Pays de Bray comme potentiellement active. Ce changement d’appréciation du degré d’activité de cette faille rejoint celui qui avait suivi l’occurrence du séisme du Teil en 2019, en Ardèche, sur une faille alors inconnue pour être active.
Ces deux exemples supportent le même constat : les failles « intraplaques » (situées à l’intérieur des continents, loin des limites de plaques tectoniques) peuvent produire des séismes forts avec ruptures en surface, même dans des régions réputées stables. C’est ce qu’ont connu, par exemple, le centre du continent australien en avril dernier et le nord-est des États-Unis en 2020.
Quelles suites pour ces recherches ?
Cette découverte soulève des questions cruciales : la faille du Pays de Bray, longue de près de 100 kilomètres, est-elle toujours active et capable de causer des séismes importants dans un futur proche ? Quelle est la probabilité de séismes futurs dans cette zone densément peuplée et industrialisée, et avec quelle magnitude peuvent-ils survenir ? Comment affiner les modèles d’aléa sismique en conséquence, pour cette région comme pour les zones intraplaques comparables ?
Pour répondre à ces interrogations, il faut poursuivre les investigations sur le terrain autour du site fouillé, notamment utiliser des méthodes géophysiques de haute résolution et non invasives, pour sonder et cartographier précisément les failles enterrées, à des profondeurs allant de quelques dizaines à plusieurs centaines de mètres. Il faudrait ensuite étendre les fouilles pour dater d’éventuelles traces de séismes passés et estimer leur fréquence (ce qu’on appelle l’analyse paléosismologique).
Un autre enjeu est de renforcer la collaboration interdisciplinaire : les traces de séismes passés dans les sols sont, dans le contexte français de tectonique lente, souvent masquées ou abîmées par l’érosion ou les activités humaines. Il est donc nécessaire de combiner les approches des archéologues, des géologues et des géophysiciens.
Au-delà des recherches proprement dites, l’objectif est de mettre à jour et de compléter la base de données des failles actives et des séismes préhistoriques connus, publiée il y a bientôt dix ans.
Enfin, ces résultats seront pris en compte dans l’évaluation des risques, qui est, par exemple, périodiquement mise à jour à l’échelle de l’Europe. Cette étude souligne que, même dans des zones réputées stables, le risque sismique ne doit pas être sous-estimé, même si les causes des séismes y restent encore débattues.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.07.2026 à 10:00
Avec ou sans synapses ? Le singulier système nerveux des cténophores, ou comment un débat scientifique vieux de 100 ans refait surface
David Stroebel, Ingénieur de recherche hors classe CNRS dans l'équipe Récepteurs du glutamate et synapses excitatrices, Institut de biologie, École normale supérieure (ENS) – PSL
Texte intégral (2359 mots)

Dans les livres de biologie, on apprend que le système nerveux se compose de neurones connectés par des synapses, indispensables à nos capacités de cognition. Jusqu’à très récemment, les synapses étaient un élément incontournable de tous les systèmes nerveux connus. Mais voilà que des chercheurs ont observé un système différent, sans synapses, chez d’intrigants animaux marins, les cténophores. Cette avancée suscite les débats chez les scientifiques.
Aux prémices de la neurobiologie moderne, au début du XXᵉ siècle, une rivalité d’anthologie opposa Camillo Golgi, médecin italien, pionnier et figure tutélaire de la microscopie cellulaire, et l’Espagnol Santiago Ramón y Cajal, génie de la neuroanatomie. L’Italien avançait que le système nerveux formait un réseau unique et continu : un syncytium. L’Espagnol y voyait plutôt un réseau discontinu, fait de cellules indépendantes se contactant par des synapses.

Cent vingt ans après l’attribution du même prix Nobel de physiologie aux deux scientifiques, le succès de Cajal apparaît total : les synapses constituent une pièce maîtresse de notre compréhension actuelle du fonctionnement du système nerveux. De fait, ces structures submicrométriques innombrables dans le cerveau (près d’un demi-million de milliards de synapses chez l’humain) forment le support des capacités de computation, d’apprentissage et de mémorisation.
Mais si, envers et contre l’histoire de la neurobiologie moderne, Golgi avait pu aussi avoir raison ? Et si le système nerveux d’un organisme pouvait également fonctionner en syncytium ?
C’est précisément ce que des chercheurs ont découvert en 2023, en imageant un cténophore par tomographie électronique. Les cténophores sont des créatures marines translucides, familières de presque tous les environnements marins, qui se distinguent par de délicates ondulations irisées à leur surface. Certains cténophores peuvent sembler, à première vue, être de proches cousins des méduses. Cependant, l’étude publiée en 2023, dans la revue Science, révèle que la partie centrale du réseau neural de cténophore est continu, un cas sans équivalent dans le monde vivant.
Le syncytium neural de Golgi se trouvait en fait… dans les mers.

Les cténophores n’en sont pas à leur première originalité
Contredisant leur apparente ressemblance, l’étude du génome des cténophores indiquait déjà en 2013 qu’ils sont plus éloignés des cnidaires (méduses) que ces dernières ne le sont de nous. Plusieurs études scientifiques placent désormais le groupe des cténophores comme ancêtres des animaux (on appelle le groupe des animaux les « Métazoaires »), avant même les éponges ! Mais ce classement reste encore aujourd’hui très débattu.
Pourquoi une telle querelle entre spécialistes ? Parce que l’ancestralité des cténophores chez les animaux (Métazoaires) complexifie le scénario d’émergence du système nerveux.
En effet, les classifications du vivant considéraient jusque-là que notre ancêtre commun, Eumétazaoire, a acquis un système nerveux après la séparation du groupe des éponges, qui, elles, seraient demeurées dépourvues de système nerveux. Le repositionnement des cténophores dans l’arbre du vivant bouscule complètement ce scénario : il impliquerait l’émergence multiple et séparée de systèmes nerveux potentiellement différents, couplée ou non à la disparition du système nerveux chez certaines espèces (par exemple, chez les éponges).
L’état actuel des recherches ne permet d’exclure aucun des deux scénarios. Le scénario initial a pour lui une grande simplicité (on parle de scénario « parcimonieux »), permettant aisément d’envisager un assemblage progressif de la complexité du système nerveux. Le scénario nouvellement remanié est porté par l’évolution exceptionnelle des données de séquençage de génome et des outils d’analyse bio-informatique. Ce nouveau scénario a le bénéfice et l’attrait de la nouveauté. Mais, pour convaincre, il lui reste encore à élaborer un mécanisme évolutif convaincant de formation du système nerveux.
C’est là qu’intervient la découverte de la singularité du système nerveux des cténophores, appuyant l’originalité biologique de ces discrets organismes marins parmi les animaux (Métazoaires). Si, à ce stade, elle ne permet pas formellement de trancher entre les deux théories, cette découverte offre un aperçu des possibilités insoupçonnées d’organisation du système nerveux dans le vivant. Par là même, elle ouvre les chemins des possibles évolutifs, ceux qui faisaient défaut aux scénarios complexes de co-émergence de systèmes nerveux.
Les cténophores déterrent le débat entre Golgi et Cajal
Mais revenons à l’autre débat, celui d’il y a plus de cent ans, entre Cajal et Golgi – ou, désormais transposé à la biologie marine, la distinction d’organisation neurobiologique entre cténophores et cnidaires. Que peut bien apporter une organisation neurale en syncytium par rapport à celle bien connue basée sur des synapses (et vice versa) ?
Pour l’instant, on ne sait encore presque rien du fonctionnement de ce syncytium neural des cténophores, seulement qu’il connecte les cellules excitables sensorielles et motrices de l’animal. En attendant les résultats de futures investigations, nous en sommes aujourd’hui juste réduits à spéculer sur ce qu’un tel réseau pourrait procurer : une économie d’énergie ? Un gain de rapidité de réponse ?
Le rôle des synapses, des méduses aux humains
Dans les organismes neuraux, les synapses constituent la base des capacités d’encodage complexe du signal au sein du réseau. L’importance de leur capacité d’adaptation (appelée aussi plasticité) et l’étendue de leur diversité constituent des champs d’investigation actifs de la neurobiologie actuelle. Plusieurs décennies de recherche intensive nous ont appris que, selon leur type et leur environnement cellulaire, les synapses modulent la force, la dynamique et même la nature des signaux transmis au neurone qu’elle contacte.
Ces propriétés sont vraisemblablement à l’origine des possibilités d’expansion et de complexification des réseaux neuronaux des organismes à synapses, comme chez nous autres Vertébrés. In fine, ce sont cette expansion et cette complexification qui ont permis de supporter le développement de comportements et d’apprentissages élaborés, jusqu’aux prouesses des transmissions culturelles humaines.
Embrasser la complexité du vivant
Alors, système à syncytium ou à synapses ?
Si juger (neurobiologiquement) de l’efficacité relative d’organisations si différentes n’a guère de sens, un regard sur les chiffres de population des espèces concernées révèle une profonde asymétrie. Seule une centaine d’espèces de cténophores est référencée alors qu’il existerait plus d’un million d’espèces d’animaux neuraux. Le succès évolutif des organismes à synapses – à la fois en termes de diversité que de biotopes occupés – est aussi incontestable que la postérité de Cajal.
Pourtant, après 600 millions d’années marquées par plusieurs extinctions massives, les cténophores continuent de cohabiter avec les autres espèces peuplant nos océans. La sélection naturelle n’a pas tranché entre système à syncytium et à synapses.
Et les cténophores, tels des clins d’yeux facétieux aux modèles de Golgi, persistent à tourner en dérision nos schémas simplistes, du fonctionnement neural au scénario de nos origines.
David Stroebel est un agent du CNRS, France. Il a reçu des financements de l'ANR (Agence Nationale pour la Recherche, France) ainsi que de la FRM (Fondation pour la recherche médicale).
08.07.2026 à 09:59
La respiration nous permet de communiquer avec nous-mêmes, avec les autres et avec les robots
Thomas Similowski, Professeur de pneumologie, directeur de l'unité de recherche UMRS1158 (Neurophysiologie Respiratoire Expérimentale et Clinique), spécialiste des interactions entre système respiratoire, système nerveux, et société, Sorbonne Université
Texte intégral (1852 mots)

La respiration n’a pas comme unique fonction de nous apporter de l’oxygène et d’éliminer du dioxyde de carbone. Loin de là. Elle sert aussi à communiquer de multiples manières : avec les autres explicitement ou implicitement ; avec soi-même ; et même avec des robots ou des œuvres d’art. Cette faculté est propre à la respiration : on ne communique avec son cœur ou ses tripes qu’au figuré.
Parmi les fonctions vitales, la respiration possède deux grandes particularités. La première est que nous pouvons en prendre temporairement le contrôle. Comment est-ce possible ? Parce que l’automatisme respiratoire ne vient pas des poumons eux-mêmes, comme c’est le cas pour les automatismes du cœur et de l’intestin, mais d’ailleurs : du système nerveux central. Pour respirer, il faut contracter des muscles « squelettiques » (qui font bouger des os), dont le plus connu est le diaphragme, la coupole musculaire qui sépare thorax et abdomen. Ces muscles respiratoires sont commandés par des neurones de la moelle épinière. Notre cortex cérébral y a accès pour en faire ce que nous voulons, en court-circuitant temporairement les structures automatiques qui assurent le rythme respiratoire (des oscillateurs neuronaux du tronc cérébral). Ce phénomène n’existe pour aucune autre fonction vitale.
Pour parler (ou chanter, ou siffler, ou jouer d’un instrument à vent), il faut pouvoir arrêter la respiration automatique, prendre une grande inspiration pour une voix forte ou une phrase longue, segmenter son souffle pour moduler sa prosodie. Une fois dit, cela paraît évident. Mais aviez-vous vraiment conscience que sans contrôle de la respiration, c’est le silence ?
Respirer, c’est communiquer
Deuxième particularité de la respiration : elle se voit et elle s’entend. Nous pouvons communiquer impatience, lassitude, colère, fatigue, soulagement, surprise, ou peur par des soupirs expressifs. Mais il y a plus subtil.
La respiration est branchée sur notre état physiologique (le sommeil ou l’effort), notre santé, nos émotions. Tous ces sentiments caricaturés explicitement par les soupirs appuyés, la respiration les traduit implicitement par des modifications de son amplitude et de sa fréquence, et des sons de notre « soufflet ».
Respiration lente, régulière et profonde de l’apaisé qui somnole. Respiration superficielle, rapide, monotone de la crise d’anxiété. Respiration saccadée, irrégulière de la joie et de l’excitation. Que nous en ayons conscience ou pas (plus souvent « pas », d’ailleurs), nous envoyons aux autres un flux continu d’information sur nous-mêmes par le simple fait de respirer. C’est d’ailleurs une source d’alliance : la synchronisation respiratoire, implicite ou explicite, peut créer un lien, favoriser la coopération. Nous avons même chacun notre signature motrice respiratoire : en effet, la façon dont notre poitrine se gonfle et se dégonfle nous est propre, comme l’est notre démarche.
Par ailleurs, notre cerveau est bombardé en permanence de milliers de messages qui proviennent de notre appareil respiratoire. Il se sert de ces messages comme d’un échafaudage pour coordonner des aires cérébrales impliquées dans de multiples fonctions cognitives : mémoriser ou décider, par exemple. Des recherches ont montré que nous enregistrons mieux une image si elle nous est présentée pendant l’inspiration que pendant l’expiration.
Ainsi, par la respiration, nous communiquons avec nous-mêmes. Et nous pouvons agir sur notre cerveau, en particulier l’apaiser, en changeant notre façon de respirer, une propriété largement mise à profit par la plupart des approches psychocorporelles.
Faire respirer les robots
Mais revenons à cette respiration qui se voit et qui s’entend, qui renseigne sur vous, qui dit en fait « Regarde, écoute, je suis vivant », et ce, dès notre tout premier cri, jusqu’à notre dernier souffle.
Pour savoir si quelque chose est vivant, les enfants utilisent trois indices : ça bouge ; ça respire ; ça grandit (mais celui-ci demande du temps). Donc pour savoir tout de suite si c’est vivant, même si cela ne bouge pas : est-ce que cela respire ?
Au laboratoire de physiopathologie respiratoire de l’unité de recherche UMRS 1158 Inserm-Sorbonne Université, et en collaboration avec l’Institut des systèmes intelligents et de robotique de Sorbonne Université, nous avons mobilisé ce concept pour l’appliquer à une problématique très spécifique, celle des interactions humains-robots.
Est-ce qu’un robot qui « respire » est plus « engageant » qu’un robot « normal » ? Ceci avait déjà été observé par d’autres chercheurs qui avaient animé un bras mécanique de mouvements cadencés ressemblant à une respiration. Les humains, qui travaillaient avec le robot sur une chaîne de coproduction humains-machines, avaient trouvé le « bras respirant » plus « vivant », plus « humain », plus « intelligent », plus « aimable » et plus « rassurant », selon un outil d’évaluation très utilisé en robotique (le questionnaire « Godspeed »). Mais notre question s’adressait davantage à ces robots humanoïdes qui seront peut-être nos compagnons, nos interlocuteurs de demain. Faire respirer un robot déjà très attractif par sa morphologie, est-ce mieux ? Ou au contraire, est-ce dérangeant ?
Pour tester cela, nous avons programmé deux robots « Pepper » (un petit humanoïde bourré de capteurs qui ressemble à un enfant d’une dizaine d’années) pour qu’ils puissent converser avec des humains. Nous en avons animé un de petits bruits et mouvements aléatoires que l’on injecte souvent dans le comportement des robots pour les rendre plus « vivants ». Nous avons animé l’autre d’un mouvement associant redressement du torse et rotation des épaules (comme ce qui se passe lorsque nous inspirons) ainsi que d’un discret souffle. Le résultat a été probant. Alors que la plupart des participants ne réalisaient pas consciemment que l’un des deux robots respirait, ils trouvaient celui-ci « plus vivant » et « plus intelligent ».
Surtout, l’interaction changeait : les participants passaient davantage de temps à regarder la tête et le visage du robot (« temps de regard ») et l’échange durait plus longtemps. Statistiquement, deux facteurs seulement étaient significativement associés au temps de regard : la respiration du robot d’une part et le niveau de sollicitude empathique de son interlocuteur de l’autre.
Un humain s’implique plus dans une interaction avec un robot si le robot « respire ». Donc, la respiration est un vecteur de communication même avec le « non-vivant ». Une piste si l’on souhaite humaniser toujours plus robots, intelligences artificielles et autres agents virtuels ?
Quand l’art respire

C’est selon ce principe d’animéité respiratoire que notre unité de recherche s’est intégrée à une équipe multidisciplinaire, réunie par Samuel Bianchini, artiste et enseignant-chercheur à l’École nationale supérieure des arts décoratifs, équipe dont les efforts ont convergé vers la création d’une œuvre d’art respirante.
Réespiration combine création artistique, robotique souple, ingénierie mécanique, intelligence artificielle, physiologie, design textile, design sonore, et bien d’autres choses encore, en une entité qui respire comme un humain (grâce à l’entraînement d’un algorithme spécialisé et qui peut synchroniser son rythme respiratoire à celui de son spectateur, voire l’influencer. Les réactions du public et les premières données de recherche montrent qu’en présence de Réespiration, les corps se détendent, les cerveaux s’apaisent. Ils vagabondent même, en chemin vers un état modifié de conscience.
Les robots respirants en général, et Réespiration en particulier, auront-ils des applications médicales ? Apaiseront-ils l’anxiété, aideront-ils à soulager la souffrance des patients atteints de maladies respiratoires chroniques ? C’est la prochaine question…
L’UMRS 1158 et le projet Réespiration sont soutenus par la Fondation du Souffle, www.lesouffle.org
08.07.2026 à 09:59
Les astronomes cherchent-ils vraiment des extraterrestres ? Oui, mais pas comme dans les films
Quentin Kral, Astrophysicien à l'observatoire de Paris-PSL, CNRS, Sorbonne Université, Université Paris Cité
Texte intégral (1999 mots)
La recherche de vie ailleurs que sur Terre n’est pas de la science-fiction, mais un domaine très sérieux de recherche : l’exobiologie. Découvrez les techniques qui pourraient permettre, un jour, une rencontre du troisième type.
Sommes-nous seuls dans l’Univers ? Pendant longtemps, cette question relevait surtout de la philosophie. Chacun pouvait avoir son intuition. Kant disait même qu’il parierait toute sa fortune sur l’existence d’une vie ailleurs dans l’Univers. Il ne prenait pourtant pas un très grand risque : à son époque, il était impossible de tester cette hypothèse.
Aujourd’hui, la situation a profondément changé. Grâce aux progrès de l’astronomie, de la biologie, de la chimie et de la géologie, la recherche de la vie extraterrestre est devenue une véritable discipline scientifique : l’exobiologie. Des milliers de chercheurs tentent désormais de répondre expérimentalement à une question qui semblait encore hors de portée il y a quelques décennies.
Plusieurs approches sont explorées. L’idée est d’apprendre ce que l’on peut du cas terrestre avant d’extrapoler à d’autres mondes. Ainsi, certaines équipes cherchent à comprendre comment la vie est apparue sur Terre afin d’identifier les ingrédients indispensables à son émergence. D’autres étudient son évolution vers des organismes plus complexes.
Les astronomes, eux, s’intéressent à une autre question : si la vie existe ailleurs, comment pourrions-nous la détecter ?
Deux grandes stratégies se dessinent. La première consiste à rechercher des biosignatures, c’est-à-dire des traces laissées par des organismes vivants. La seconde vise les technosignatures, des indices qui pourraient révéler l’existence d’une civilisation suffisamment avancée pour développer une technologie détectable.
Chercher la vie dans le système solaire
La façon de rechercher la vie dépend avant tout de la distance. Dans notre système solaire, nous pouvons envoyer des sondes pour analyser directement des roches, des glaces ou des océans cachés sous la surface. Autour d’autres étoiles, en revanche, nous sommes condamnés à observer les planètes à distance et à interpréter la faible lumière qui nous parvient.
Mars reste l’une des cibles les plus étudiées. Le rover Perseverance ne cherche pas à photographier d’éventuels organismes vivants, mais à identifier des biosignatures fossiles : des traces chimiques ou géologiques qui indiqueraient qu’une vie microbienne a existé lorsque Mars possédait des lacs et des rivières il y a plusieurs milliards d’années. Les échantillons qu’il collecte devraient être rapportés sur Terre dans les prochaines décennies – sûrement avec beaucoup de retard à cause de coupes budgétaires sévères de l’administration Trump – afin d’être analysés avec les instruments les plus performants.
D’autres mondes suscitent également beaucoup d’espoir. Les lunes glacées Europe, autour de Jupiter, et Encelade, autour de Saturne, abritent un océan d’eau liquide sous leur croûte de glace. Encelade projette même dans l’espace des panaches d’eau provenant de son océan, offrant une occasion unique d’en analyser directement la composition. Les missions Europa Clipper et Juice, actuellement en route, permettront de mieux comprendre si ces océans réunissent les conditions favorables à l’apparition de la vie.
Au-delà du système solaire, cette approche directe devient impossible. Les astronomes doivent alors rechercher les traces que la vie pourrait laisser dans l’atmosphère ou à la surface des exoplanètes.
Les biosignatures : rechercher les empreintes laissées par la vie
Sur Terre, les êtres vivants modifient profondément leur environnement. Certaines bactéries produisent de l’oxygène, d’autres du méthane. Les plantes absorbent certaines longueurs d’onde de la lumière pour réaliser la photosynthèse. Toutes ces activités laissent des signatures qui pourraient, en principe, être détectées à des dizaines d’années-lumière.
On pourrait croire qu’il suffit de détecter de l’oxygène dans l’atmosphère d’une exoplanète pour conclure à la présence de vie. Malheureusement, la nature sait produire de l’oxygène sans intervention biologique. Il existe de nombreux mécanismes dits abiotiques capables d’imiter certaines signatures du vivant.
On recherche donc des indices plus subtils : des déséquilibres chimiques. Sur Terre, par exemple, l’oxygène et le méthane coexistent alors qu’ils devraient rapidement réagir entre eux pour former du dioxyde de carbone. S’ils restent présents simultanément, c’est parce que les organismes vivants les renouvellent en permanence. Une telle combinaison constitue une biosignature beaucoup plus convaincante qu’une seule molécule prise isolément.
L’actualité récente illustre parfaitement cette difficulté. En 2025, des observations réalisées avec le télescope spatial James-Webb sur l’exoplanète K2-18 b ont révélé la présence possible de molécules comme le sulfure de diméthyle (DMS), un composé qui, sur Terre, est principalement produit par le phytoplancton marin. L’annonce a suscité un immense enthousiasme, mais aussi de nombreuses réserves : les données restent limitées et les conclusions ont sans doute été tirées un peu trop rapidement. De plus, il est possible que ces molécules puissent être produites par des processus non biologiques. Cette étude rappelle qu’aucune molécule, à elle seule, ne peut aujourd’hui être considérée comme une preuve de l’existence de la vie. Il faudra réunir plusieurs indices indépendants et convergents avant de pouvoir revendiquer une détection crédible.
Une autre approche consiste à observer directement la lumière réfléchie par une planète. Sur Terre, les végétaux absorbent fortement la lumière rouge pour alimenter la photosynthèse, puis réfléchissent très efficacement le proche infrarouge. Cette transition brutale, appelée le « bord rouge » de la végétation (vegetation red edge), est visible lorsqu’on observe notre planète depuis l’espace. Si une biosphère extraterrestre exploitait elle aussi l’énergie de son étoile grâce à un processus analogue, elle pourrait laisser une signature similaire, même si ses organismes étaient très différents des plantes terrestres.
Aucune de ces observations ne suffira, à elle seule, à démontrer l’existence de la vie. Les astronomes devront croiser plusieurs indices : la composition de l’atmosphère, la présence éventuelle d’eau liquide, la nature rocheuse de la planète, son champ magnétique ou encore les propriétés de son étoile. Comme dans une enquête policière, c’est l’accumulation de preuves indépendantes qui permettra de construire un scénario crédible.
Les technosignatures : rechercher des civilisations plutôt que des microbes
On pourrait penser que les astronomes devraient concentrer tous leurs efforts sur la recherche de vie microbienne, probablement beaucoup plus abondante que les civilisations technologiques. Pourtant, les deux approches sont complémentaires.
Les biosignatures sont sans doute plus fréquentes, mais souvent ambiguës. Les technosignatures, elles, seraient probablement beaucoup plus rares, mais aussi beaucoup plus difficiles à expliquer autrement. Si nous recevions un signal radio contenant les décimales du nombre π ou une suite de nombres premiers, le doute serait permis bien moins longtemps.
Depuis les années 1960, les recherches regroupées sous le nom de SETI (Search for Extraterrestrial Intelligence) scrutent le ciel à la recherche de signaux radio artificiels. L’idée est qu’une civilisation pourrait chercher à communiquer avec d’autres ou laisser s’échapper involontairement des émissions, comme nos propres transmissions radio et télévisées fuient dans l’espace depuis près d’un siècle.
À ce jour, aucune détection n’a été confirmée. Le célèbre « signal Wow ! », enregistré en 1977 par un radiotélescope de l’Ohio State University, est une émission radio de 72 secondes très intense et de bande étroite provenant de la constellation du Sagittaire. Son caractère inhabituel a suscité de nombreuses spéculations, mais son origine demeure inconnue. Surtout, l’absence de toute nouvelle détection similaire empêche d’y voir une preuve convaincante d’une civilisation extraterrestre.
Aujourd’hui, des chercheurs explorent un éventail beaucoup plus large de technosignatures. Une planète couverte d’éclairages artificiels pourrait produire une émission lumineuse inhabituelle. Une civilisation très avancée pourrait construire d’immenses infrastructures destinées à exploiter l’énergie de son étoile, comme les sphères de Dyson, un hypothétique immense ensemble de satellites collecteurs répartis autour de l’étoile pour en récupérer une grande partie de l’énergie. Il est également envisageable de rechercher des polluants industriels impossibles à produire naturellement, des faisceaux laser utilisés pour communiquer, voire des constellations de satellites semblables au réseau Starlink.
Une quête qui ne fait que commencer
Le télescope spatial James-Webb inaugure une nouvelle ère en permettant de sonder les atmosphères d’exoplanètes avec une précision jamais atteinte. Mais les instruments actuels restent encore limités.
La prochaine révolution viendra probablement de l’Extremely Large Telescope (ELT), actuellement en construction au Chili. Avec son miroir de 39 mètres de diamètre, il pourra analyser en détail l’atmosphère de petites planètes rocheuses situées autour d’étoiles proches. Les futurs observatoires spatiaux iront encore plus loin. Ensemble, ils permettront de tester des biosignatures toujours plus subtiles et d’éliminer progressivement les explications alternatives.
La découverte d’une vie extraterrestre ne prendra probablement pas la forme d’une photographie spectaculaire ou d’un unique signal mystérieux. Elle résultera plutôt d’une accumulation patiente d’indices, confrontés pendant des années à toutes les explications possibles.
Pour la première fois de l’histoire, la question « Sommes-nous seuls dans l’Univers ? » n’appartient plus seulement à la philosophie. Elle est devenue une question scientifique. Et les prochaines décennies pourraient enfin nous apporter les premiers éléments de réponse.
Pour en savoir plus sur cette quête de la vie extraterrestre, vous pouvez consulter le livre de Quentin Kral, Les Astronomes à la recherche de la vie extraterrestre, aux éditions Ellipses, 2025.
Quentin Kral est l'auteur de l'ouvrage : « Les astronomes à la recherche de la vie extraterrestre » aux éditions ellipses.
07.07.2026 à 15:53
Comment les constellations de satellites pourraient transformer la surveillance climatique
Mustapha Meftah, Chercheur au LATMOS/CNRS/UVSQ/SU et professeur à l'UVSQ, spécialisé en physique solaire, sciences de l'atmosphère, instrumentation spatiale et missions satellitaires, Sorbonne Université
Alain Sarkissian, 11 Boulevard d'Alembert, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Philippe Keckhut, vice-président innovation, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Texte intégral (2863 mots)
Pour détecter et réguler les émissions responsables du changement climatique, certains phénomènes doivent désormais être suivis en temps réel, ou presque. Une solution consiste à démultiplier les instruments d’observation grâce à des constellations de satellites. Mais comment faire en sorte que ces constellations à but scientifique ne provoquent pas plus de problèmes qu’elles ne contribuent à en résoudre ?
Les satellites sont devenus indispensables pour observer le changement climatique. Ils mesurent les gaz à effet de serre, surveillent les incendies, observent les nuages et suivent l’évolution des océans.
Mais certains phénomènes évoluent plus vite que le rythme des observations spatiales, ce qui rend leur observation plus difficile. Ainsi, un incendie, un épisode de pollution ou une fuite de méthane d’origine anthropique (provenant par exemple d’infrastructures pétrolières et gazières, de mines de charbon ou de centres d’enfouissement) peuvent évoluer plus rapidement que le temps nécessaire à un satellite pour observer à nouveau une même région. Des étapes clés de leur évolution peuvent alors être manquées, retardant leur détection, leur localisation et les interventions visant à en limiter les impacts.
C’est pour cela que la fréquence des observations satellitaires devient désormais presque aussi importante que leur précision. Une des pistes explorées consiste à déployer des constellations de satellites afin d’augmenter fortement la fréquence des mesures depuis l’espace. Dans cette approche, l’objectif n’est plus seulement d’utiliser quelques satellites très performants, mais également d’observer la Terre beaucoup plus fréquemment grâce à des constellations composées de dizaines, voire de centaines de satellites.
Être précis ou être rapide : le compromis des observations satellitaires actuelles
Ces nouvelles approches s’inscrivent dans la continuité des grandes missions spatiales d’observation du climat, telles que OCO-2, GOSAT ou la famille des satellites Sentinel du programme Copernicus, qui fournissent déjà des données essentielles pour suivre l’évolution de l’atmosphère et du cycle du carbone. La plupart de ces missions reposent sur un nombre limité de satellites.


{kind=link}
La mesure des gaz à effet de serre depuis l’espace est aujourd’hui considérée comme un enjeu majeur par les grandes organisations internationales de surveillance de la Terre, comme le Groupe d’observations de la Terre (en anglais, Group on Earth Observations, GEO) ou le Comité d’observation satellite de la Terre (Committee on Earth Observation Satellites, CEOS).
Pour répondre à ce besoin, plusieurs missions spatiales sont aujourd’hui en opération, telles que OCO-2, GOSAT ou Sentinel-5P, tandis que d’autres, comme CO2M, sont en préparation. Elles visent à mesurer les concentrations de gaz à effet de serre avec une précision toujours plus élevée. Certaines missions atteignent une précision de l’ordre de 1 partie par million (1 ppm) sur la concentration atmosphérique de CO₂, une performance nécessaire pour estimer les sources et les puits de carbone et mieux quantifier les échanges de CO₂ entre l’atmosphère, les océans et les continents.
Mais cette précision s’accompagne d’un compromis : pour obtenir des mesures très précises et une résolution spatiale élevée, les satellites observent généralement une bande de terrain de largeur limitée, ce qui augmente le temps nécessaire pour observer à nouveau une même région. C’est précisément cette limite que les constellations cherchent à dépasser en multipliant le nombre de satellites en orbite.
Le méthane réchauffe l’atmosphère bien plus rapidement que le CO₂, mais ses émissions évoluent trop vite pour les observations actuelles
Le méthane illustre particulièrement cette difficulté. Selon le Groupe d’experts intergouvernemental sur l’évolution du climat (Giec), le méthane réchauffe l’atmosphère environ 80 fois plus que le CO₂ sur une période de vingt ans. Réduire rapidement les émissions de méthane constitue donc un levier important pour limiter le réchauffement climatique à court terme. Le suivi du méthane repose sur la combinaison des observations satellitaires et des modèles de transport atmosphérique, qui permettent d’estimer la dispersion du méthane et l’évolution de ses émissions à l’échelle globale.

Les satellites permettent déjà de détecter certaines émissions depuis l’espace. Sentinel-5P/TROPOMI fournit par exemple une couverture quotidienne globale permettant d’identifier de grands « super-émetteurs » régionaux. D’autres instruments, comme Sentinel-2 ou certains imageurs hyperspectraux, permettent d’observer des émissions beaucoup plus localisées.
Mais certaines émissions restent intermittentes. Une fuite de méthane peut apparaître puis disparaître entre deux observations. Pour les agences environnementales comme pour les industriels, disposer de mesures plus fréquentes devient essentiel afin de localiser rapidement ces émissions et de répondre aux nouvelles exigences de surveillance et de déclaration des émissions de gaz à effet de serre (GES), dans le cadre notamment du CBAM européen.
La fréquence d’observation, grand intérêt scientifique des constellations de satellites
C’est précisément l’intérêt des constellations de satellites. Contrairement aux missions spatiales traditionnelles, qui reposent sur quelques plates-formes complexes, ces architectures utilisent plusieurs dizaines de satellites plus petits répartis sur plusieurs plans orbitaux, généralement à des altitudes comparables. L’objectif est moins de maximiser la performance de chaque satellite que de multiplier les observations au cours d’une même journée. Selon les caractéristiques des instruments embarqués, une constellation d’une vingtaine à quelques dizaines de satellites peut ainsi réduire le temps de revisite de plusieurs jours à quelques heures.
Les avancées dans la miniaturisation des satellites et des instruments rendent désormais possibles des capteurs scientifiques plus petits, plus légers et moins coûteux. Cette miniaturisation permet de développer des capteurs adaptés à des besoins d’observation ciblés, sans chercher systématiquement à maximiser les performances ni la complexité des instruments.
S’intégrer dans des constellations de télécommunications
Une autre évolution pourrait également transformer l’observation du climat : l’intégration de capteurs scientifiques miniaturisés à bord des satellites appartenant à des constellations de télécommunications. Cette approche est notamment étudiée dans le cadre des futures générations de satellites d’Eutelsat-OneWeb, qui pourraient accueillir des charges utiles auxiliaires.
Plutôt que de lancer une constellation scientifique entièrement dédiée, avec les enjeux associés en termes de débris spatiaux, d’occupation des orbites et de pollution lumineuse, il deviendrait possible d’embarquer de tels instruments à bord de ces satellites.
Ces infrastructures pourraient ainsi servir à la fois aux télécommunications et à l’observation du climat, en mutualisant les plates-formes et les lancements, ce qui pourrait réduire significativement les coûts par rapport à une constellation scientifique entièrement dédiée, tout en augmentant la fréquence des observations.
Ces nouvelles approches ne remplaceraient pas les grandes missions climatiques institutionnelles, indispensables pour garantir la stabilité et la qualité scientifique des mesures de référence. Elles pourraient en revanche compléter les infrastructures existantes grâce à des observations beaucoup plus fréquentes de la Terre.

La mission française UVSQ-SAT NG, développée par le laboratoire Atmosphères, observations spatiales (LATMOS), s’inscrit dans la continuité des missions UVSQ-SAT et INSPIRE-SAT 7, deux nanosatellites démonstrateurs dédiés à l’observation du bilan radiatif de la Terre.
UVSQ-SAT NG teste de nouvelles approches de miniaturisation pour l’observation du bilan radiatif terrestre et de certains gaz à effet de serre depuis une plateforme nanosatellite. Cette mission n’est pas intégrée à une constellation de télécommunications ; elle constitue un démonstrateur technologique destiné à préparer de futures architectures de constellations scientifiques. Les données de ces missions sont accessibles librement à la communauté scientifique et au public sur la plateforme NAHLA.
Mustapha Meftah a reçu des financements de l'Agence nationale de la recherche (ANR).
Alain Sarkissian a reçu des financements de l'Agence nationale de la recherche (ANR).
Philippe Keckhut a reçu des financements de l'ANR pour le projet Compétences et Métiers d'Avenir France2030; Académie Spatiale
06.07.2026 à 15:47
La sécurité des drones militaires, ou comment protéger ce qui compte (et ce n’est pas toujours le drone lui-même)
Serge Chaumette, Professeur des Universités en Informatique, chercheur au LaBRI (Laboratoire Bordelais de Recherche en Informatique) et responsable des activités drones de ce laboratoire, Université de Bordeaux
Damien Sauveron, Professeur des Universités en Informatique à la Faculté des Sciences et Techniques, Université de Limoges
Texte intégral (2420 mots)
Sur les théâtres d’opération militaire, les drones évoluent dans un environnement hostile où ils doivent avant tout protéger les troupes qu’ils accompagnent. Pour mener à bien cette mission, ils déploient des stratégies qui leur offrent une certaine résilience, le but n’étant finalement pas de les protéger pour eux-mêmes, mais de leur permettre d’accomplir leur tâche coûte que coûte. Leur propre protection n’est qu’un enjeu secondaire : on les dit sacrifiables.
Face aux vulnérabilités de ces nouveaux acteurs des conflits militaires, on se trouve devant un jeu du gendarme et du voleur où le gendarme court après de nouvelles solutions pour se protéger du voleur alors que le voleur cherche de nouvelles failles lui permettant de mettre à mal les stratégies développées par le gendarme.
La guerre en Ukraine a suscité un regain d’intérêt des forces armées pour les drones, en particulier de taille petite et moyenne, qu’ils soient unitaires ou en essaim. On le constate quotidiennement, ils sont partout sur le champ de bataille et constituent un atout majeur pour les forces : ils portent le feu pour elles vers les lignes ennemies, mais surtout ils les renseignent, leur évitent une exposition inutile, les protègent.
Mais comment assurer leur propre protection afin de garantir leur disponibilité face aux attaques de l’ennemi et à la « guerre électronique », qui sert parfois de prélude aux opérations cyber (opérations visant à mettre à mal, voire à pirater, leurs composants matériels ou logiciels) ? Des technologies et des stratégies existent, qui se construisent dans les laboratoires de recherche académiques, dans les start-up et les entreprises spécialisées et, pour certaines, au jour le jour sur le front (ukrainien, en particulier).
Mais tout d’abord, précisons qu’un drone est rarement isolé. Les drones sont la plupart du temps pilotés par un opérateur distant, généralement au sol. Le pilote et les équipements informatiques nécessaires à l’analyse des données collectées et au suivi de la mission sont hébergés, selon la terminologie militaire, dans un C2 (Command and Control), souvent un camion ou un bâtiment où se trouvent les équipements et les personnels nécessaires.
Pour en assurer la sécurité, il faut donc envisager les drones comme des systèmes à plusieurs composantes, au-delà de l’aéronef lui-même.
La résilience, un enjeu civil et militaire
Quand on parle de protection du drone, on parle avant tout de sa résilience, c’est-à-dire de la capacité du système à conserver un fonctionnement aussi nominal que possible face à un environnement ou à des événements hostiles. Cette hostilité peut être le fait de l’action volontaire d’un ennemi, qui va tout faire pour perturber leur fonctionnement en intervention ; mais elle peut également être liée à la nature même de certaines missions, par exemple la surveillance de zones forestières pour la lutte contre les incendies de forêt, qui peuvent conduire le drone à s’approcher ou à survoler des « zones interdites de fréquences » (terrains militaires, aéroports, centrales nucléaires, etc.). Dans ces zones, il est impossible ou interdit de communiquer en utilisant des ondes radio. Il faut être capable de s’adapter à cette contrainte, d’être résilient face à elle.
Il est toutefois plus ou moins critique qu’un système de drone soit résilient, selon les cas : un appareil suffisamment petit, peu coûteux, et que l’on sait produire en masse, peut être perdu sans grande conséquence.
Le premier objectif de la résilience est d’assurer à un drone la capacité à mener à bien sa mission. Certains drones, par exemple, jouent le rôle d’éclaireurs : le succès de leur mission conditionne le bon déroulement des opérations qui s’ensuivent. C’est le cas également dans un cadre civil, par exemple pour le transport de matières biologiques ou d’organes nécessaires à des greffes.
Il faut parfois également respecter certaines contraintes, par exemple conserver la confidentialité des données transportées, qu’elles soient collectées pendant la mission ou nécessaires à la mission elle-même. Par exemple, le plan de vol (c’est-à-dire les différents points GPS que le drone doit atteindre successivement) peut être une information sensible, dont il est nécessaire d’assurer la confidentialité, la disponibilité et/ou le retour en fin de mission, même en cas de perte ou de dégradation de certains composants matériels ou logiciels du système.
Comme nous l’avons vu, les drones et leur environnement constituent un système complexe et donc fragile par définition. Ces fragilités se situent à tous les niveaux : interne, externe et au niveau des interconnexions entre les éléments du système (drone, opérateur, C2, etc.).
Les fragilités internes
Les fragilités internes concernent aussi bien l’électronique que le logiciel embarqué. Par exemple, l’électronique peut être victime d’attaques par des « fusils électromagnétiques », qui utilisent des micro-ondes pour détruire certains circuits. Des approches à base de laser se développent aussi. Ces attaques peuvent conduire à la perte totale d’un appareil et peuvent aussi provoquer des failles propices à une attaque cyber (qui peut être effectuée en vol, mais plus aisément au sol après capture de l’appareil) : modifier des données en mémoire grâce à un rayonnement peut aider à faire apparaître une faille logicielle qui sera exploitée par la suite.
Les drones, comme tout autre système, ne sont pas exempts de bugs logiciels ou de sécurités défaillantes par construction. Une conséquence qui peut s’avérer fatale est, par exemple, la survenue d’un flyaway : le drone part vers une destination non prévue. Ce type de bug peut aussi avoir une composante matérielle. De manière plus globale, la perte de contrôle d’un appareil représente 36 % des accidents, toutes causes confondues.
Les attaques externes, un enjeu majeur
Les attaques externes consistent pour un ennemi à cibler les interactions entre le système et le monde extérieur, par exemple le système de navigation par satellite (souvent dénommé abusivement GPS – Global Positioning System, qui est le système américain – au lieu de GNSS pour Global Navigation Satellite System) ou la radio (que le drone utilise pour communiquer avec une station au sol).
Le GPS peut être brouillé – auquel cas le signal reçu n’est plus exploitable : le drone n’est alors plus en mesure de connaître sa position effective. Il devient inutilisable : on parle d’environnement « GNSS denied », c’est-à-dire d’environnement dans lequel le GNSS ne peut pas être utilisé. Cela peut par exemple conduire à sa capture : les forces armées iraniennes, en 2011, ont capturé un drone américain RQ-170 Sentinel de cette façon. En Ukraine, nombreuses sont les zones dans lesquelles le signal GPS est soit inexistant, soit brouillé et devient donc inutilisable pour naviguer.
Ce phénomène a également été observé sur des événements de type show lumineux, à Shanghai par exemple, où des dizaines de drones sont allés se poser de manière inopinée sur des bateaux situés à proximité.
Les attaques d’interconnexion
Les attaques d’interconnexion portent sur l’interface du drone avec les autres éléments du système, typiquement sur ses échanges avec la station sol, et donc sur le lien radio.
Elles peuvent par exemple consister à envoyer des ordres contrefaits ou à transmettre des données erronées vers la station au sol. Le composant cible croit échanger avec un autre composant légitime alors qu’il échange avec un attaquant. Il devient ainsi possible d’exploiter les captations vidéo d’un drone pour déterminer la localisation de sa base de lancement, puis de la prendre pour cible.
Les solutions : un puzzle de stratégies
Tout d’abord, pour ce qui concerne les problématiques clés, il existe de nombreux travaux de recherche fondamentale.
Aujourd’hui, les spécialistes travaillent en particulier sur la capacité à poursuivre la navigation en environnement GNSS denied et sur la sécurisation des liens de communication drone sol-sol drone. En effet il est indispensable que les appareils disposent de solutions de repli en environnement GNSS denied. Des approches algorithmiques reposant sur une analyse fine et un filtrage des signaux reçus, des antennes spécifiques et même des approches de type IA permettent de traiter certaines attaques.
En cas d’échec de ces stratégies de remédiation, l’utilisation d’amers (terme de navigation faisant référence à des points de repère fixes) permet de se repérer en s’accrochant visuellement à des points au sol. C’est souvent une combinaison de plusieurs de ces techniques qui permet en cas de perte de la disponibilité de l’une d’entre elles d’assurer la résilience du système.
Pour ce qui est de la radio, qui en plus d’être inutilisable (neutralisée ou interdite), peut être exploitée pour localiser un C2, des stratégies sont étudiées ou déjà mises en œuvre. Par exemple, des fibres optiques reliant un télépilote à son appareil pour communiquer en lieu et place de la radio ont été expérimentées en Ukraine. À plus long terme, des approches quantiques permettront de sécuriser ces communications de manière efficace.
Pour d’autres problématiques, des stratégies existent déjà, et peuvent être exploitées. Leur coût en revanche peut ne pas être négligeable. Un compromis coût/capacité de résilience est donc à trouver.
De manière plus méthodologique, il existe des processus de certification permettant de valider la conformité à la réglementation en vigueur, laquelle intègre par nature une notion de résilience. Les enjeux sont différents dans le domaine militaire : ceux-ci n’échappent évidemment pas à toute réglementation, mais la résilience est plus focalisée sur le succès de la mission que sur la sécurité de l’environnement dans lequel elle se déroule, comme discuté dans cet article.
Il s’agit dans ce cas de développer des solutions au plus vite, de les tester, de les valider et de les déployer.
La première étape consiste à valider chaque sous-système et à mesurer son TRL (Technology Readiness Level – niveau de maturité de la technologie). On évalue ensuite la capacité de chaque sous-système à s’intégrer avec d’autres, son IRL (Intégration Readiness Level – niveau de maturité d’intégration) ; puis on intègre le système et on évalue son SRL (System Readiness Level – niveau de maturité du système global). Ces mesures sont loin d’apporter des garanties universelles, mais elles permettent déjà d’assurer une qualité significative du produit final.
Rappelons, enfin, que les drones de petite et moyenne taille, objets technologiques pourtant anciens, n’ont révélé tout leur potentiel militaire que récemment. Il faut donc garder en tête qu’il ne faudra pas ralentir les efforts de recherche et les expérimentations quand les conflits actuels seront derrière nous.
Il en va de la capacité de ces systèmes à réaliser leurs missions, qui visent, redisons-le, à nous protéger lors d’éventuels futurs conflits.
Serge Chaumette a reçu des financements de l'ANR, de BPI, de l'AID, de l'EDA, des ARL (Army Research Labs), de l'ORNL (Office of Naval Research). Il est Professeur et Chercheur à l'Université de Bordeaux et conseille et détient des parts dans la société IcarusSwamrs.ai dont il est Directeur Scientifique. Il est membre du Comité Stratégique Drones et Nouveaux Usages du Pôle de Compétitivité Mondial Aerospace Valley et co-animateur du groupe Drones et Systèmes Autonomes du GIS Albatros (Groupement d'Intérêt Scientifique entre Thales et l'Université de Bordeaux). Enfin, il collabore ou pilote de nombreux projets avec des partenaires académiques, industriels et institutionnels dans le monde du drone.
Damien Sauveron a reçu des financements de l'ANR (notamment pour le projet PANDRONE dédié à la sécurité des flottes de drones), du CNRS (PEPS TRUSTED), de la Région Nouvelle-Aquitaine et de la fédération de recherche MIRES. Dans le cadre de ses collaborations industrielles passées, ses travaux sur les flottes de drones ont également été soutenus par Thales (projet NetCod). Il est Professeur des Universités en Informatique à l'Université de Limoges et chercheur au laboratoire XLIM (UMR CNRS 7252), dont il est Doyen Honoraire de la Faculté des Sciences et Techniques. Ses recherches portent sur la cybersécurité, les systèmes embarqués et la souveraineté des architectures autonomes. Enfin, il intervient comme expert auprès de la Commission Européenne.
05.07.2026 à 11:35
Sommes-nous prêts à faire confiance à l’IA pour organiser nos vacances ?
VO-THANH Tan, Full Professor, EMLV Business School, Pôle Léonard de Vinci, Pôle Léonard de Vinci
Texte intégral (1550 mots)
« Je vais passer une semaine à Rome en amoureux, trouve-moi cinq hôtels romantiques en centre-ville. » Faites-vous confiance aux IA génératives pour vous aider à organiser vos vacances ? Une nouvelle étude montre les points de résistance à l’utilisation de ces nouvelles technologies.
Les outils d’intelligence artificielle (IA) générative comme ChatGPT peuvent être considérés comme des compagnons de voyage et aident désormais les voyageurs à concevoir leurs itinéraires, à rechercher des destinations, à réserver des prestations touristiques et à résoudre leurs problèmes en temps réel.
Pourtant, malgré l’engouement, un nombre important de voyageurs reste profondément hésitants à les utiliser. Concrètement, une récente enquête de Longwoods International a révélé que seulement 33 % des voyageurs américains étaient disposés à utiliser ChatGPT pour planifier leurs voyages. Des hésitations similaires ont été constatées sur d’autres marchés comme la Corée du Sud, notamment là où la confiance numérique, les attentes culturelles et les pratiques de planification divergent des normes occidentales.
Alors que les défenseurs de la technologie se concentrent sur « l’adoption », notre étude récente explore l’envers du décor : pourquoi tant d’entre nous résistent-ils aux conseils de voyage générés par l’IA ? Cette étude utilise une approche qualitative pour explorer comment les voyageurs résistent aux conseils de voyage générés par l’IA. Elle permet de montrer comment les gens appréhendent, jugent et réagissent aux outils d’IA dans leurs contextes sociaux et culturels.
Une nouvelle étude menée en Iran
Elle a été menée en Iran, un pays en développement dont le tourisme représente une source de revenu important. Un échantillonnage raisonné (une méthode de sélection des participants dans laquelle le chercheur choisit délibérément les personnes les plus pertinentes pour répondre à la question de recherche, plutôt que de les sélectionner au hasard) a été utilisé pour recruter des voyageurs ayant effectué au moins quatre voyages internationaux au cours des trois dernières années. Ce critère garantissait que les participants étaient activement impliqués dans la planification de leurs voyages et avaient probablement déjà rencontré des recommandations générées par l’IA.
Les participants ont été recrutés via deux canaux : trois agences de voyages spécialisées dans les voyages à l’étranger permettant d’accéder à des clients réguliers, et des comptes Instagram publics présentant du contenu de voyage généré par les utilisateurs. Pour élargir l’échantillon, l’échantillonnage en boule de neige (une méthode de sélection des participants dans laquelle les premiers participants recrutés recommandent d’autres personnes qui répondent aux critères de l’étude) a également été utilisé.
Le guide d’entretien semi-structuré (une méthode de collecte de données, principalement utilisée dans les recherches qualitatives, où le chercheur suit un guide d’entretien composé de questions préparées à l’avance, tout en restant libre d’adapter l’ordre des questions et d’en poser de nouvelles selon les réponses du participant) a été élaboré à partir d’une analyse des recherches antérieures sur la résistance à la technologie, l’adoption de l’IA et le comportement des consommateurs dans le tourisme et d’autres domaines connexes. La collecte de données s’est poursuivie jusqu’à l’obtention de la saturation théorique (atteinte lorsque les nouvelles données ne permettent plus d’enrichir la théorie ou les catégories d’analyse que le chercheur développe) après 22 entretiens. Ce nombre est conforme aux normes de la recherche qualitative, qui privilégient le sens et la profondeur thématique plutôt que la couverture statistique.
Une résistance complexe
La résistance à l’utilisation de l’IA pour la planification de voyages n’est pas seulement une question d’être « en retard sur son temps ». Il s’agit plutôt d’une réaction complexe façonnée par des frustrations pratiques, des valeurs culturelles et même notre sentiment d’identité.
Plus qu’un simple problème technique, pour beaucoup, la résistance commence par des barrières fonctionnelles. Bien que l’IA puisse agréger des données rapidement, elle échoue souvent au « dernier kilomètre » de la planification de voyage.
On note différentes barrières :
la barrière d’usage : Les utilisateurs trouvent souvent les interfaces d’IA encombrantes ou déconnectées. Par exemple, si ChatGPT peut suggérer un vol, il ne peut pas le réserver, forçant les utilisateurs à basculer entre plusieurs plates-formes ;
la barrière de valeur : De nombreux voyageurs trouvent les suggestions de l’IA redondantes ou se limitant à des listes génériques de type « top 10 » qui n’offrent pas plus de valeur qu’une simple recherche Google ;
la barrière de risque : L’obstacle le plus important est sans doute celui des « hallucinations de l’IA » – où les systèmes fournissent avec assurance de fausses informations, comme fournir des informations imprécises sur les sites de visite ou suggérer des hôtels inexistants ou des règles de visa obsolètes. Un participant a partagé : « … Je l’ai testé en demandant les sites classés par l’Unesco à proximité, et il s’est trompé… Il a donné plusieurs mauvaises réponses, alors que ce sont des informations de base qu’on trouve facilement en ligne… S’il n’arrive pas à trouver ça, comment puis-je faire confiance à tout le reste qu’il suggère ? » Un autre participant a expliqué : « … Ses informations ne sont pas à jour, donc je ne m’y fie pas pour des informations importantes concernant les voyages, comme les règles relatives aux frontières ou aux visas. Ces règles changent souvent, et une erreur à ce sujet peut gâcher un voyage. »
Dans le monde à enjeux élevés des voyages internationaux, ces erreurs pourraient transformer des vacances de rêve en cauchemar.
La menace pour notre identité de voyageur
Au-delà des défauts techniques, il existe des barrières psychologiques plus profondes. Pour beaucoup, planifier un voyage n’est pas seulement une corvée à automatiser ; c’est un rituel précieux et une source de fierté personnelle. Certains voyageurs voient l’IA comme une menace pour leur autonomie. Utiliser une machine pour planifier un voyage donne l’impression de « déléguer » un processus créatif, rendant le voyage final moins personnel.
De plus, la tradition joue un rôle majeur. Dans la culture iranienne, les conseils de voyage reposent sur une confiance relationnelle – demander à un proche qui y est « réellement allé ». L’IA, en revanche, semble froide et impersonnelle, manquant de l’authenticité émotionnelle d’une recommandation humaine.
Notre recherche identifie finalement trois types distincts de « résistants » :
les opposants : ils considèrent la planification de voyage comme un acte personnel et relationnel et voient l’IA comme une menace pour leur autonomie ;
les temporisateurs : ce groupe n’est pas « anti-IA » mais attend que la technologie fasse ses preuves et nécessite des témoignages de réussite avant de s’engager ;
les leaders d’opinion : les résistants les plus actifs. Ils s’engagent de manière critique avec l’IA et expriment souvent leur opposition, considérant ces outils comme des systèmes « biaisés par l’Occident » ou culturellement déphasés qui ne comprennent pas les réalités locales.
Les développeurs devraient se concentrer sur des modèles hybrides qui soutiennent, plutôt que de supplanter, l’agence humaine. Le voyage est une expérience profondément humaine, ancrée dans l’interaction sociale. Tant que l’IA ne respectera pas ces nuances culturelles et émotionnelles, beaucoup préféreront encore discuter avec un ami plutôt que de rédiger une commande pour un robot.
VO-THANH Tan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:34
Percer les secrets de la stratosphère grâce à un ballon qui surfe sur différentes couches de vent
François Vacher, Chargé de projets "Ballons stratosphériques", Centre national d’études spatiales (CNES)
Laurent Tessariol, Chef de service Opérations Ballons et Chef de Centre Aire Sur l'Adour, Centre national d’études spatiales (CNES)
Texte intégral (3846 mots)

Et si les clés de notre climat se trouvaient à plusieurs dizaines de kilomètres au-dessus de nos têtes ? La stratosphère, parfois considérée comme une simple couche de l’atmosphère, a un impact décisif sur nos vies : elle nous protège des rayonnements ultraviolets, elle peut déclencher de grandes vagues de froid polaire et même bouleverser les saisons lorsqu’elle se charge d’aérosols. Il s’agit d’un véritable laboratoire naturel pour les chercheurs. Comprendre son fonctionnement, c’est mieux comprendre les mécanismes qui façonnent notre climat.
Pour percer les secrets de la stratosphère, les scientifiques disposeront bientôt d’un nouvel outil : le ballon manœuvrant. Véritable voilier des hautes couches de l’atmosphère, cet engin permet d’explorer cette région fascinante de manière inédite.
La stratosphère s’étend entre 18 et 50 kilomètres d’altitude. Située au-dessus de la troposphère, où se déroule l’essentiel de la météorologie, elle occupe une région singulière de l’atmosphère terrestre. À ces altitudes, l’air est trop raréfié pour permettre aux avions conventionnels de voler, mais demeure trop dense pour qu’un satellite puisse s’y maintenir en orbite. La stratosphère constitue ainsi une zone intermédiaire, longtemps restée difficile d’accès.
Cette inaccessibilité n’en fait pas moins un territoire d’un grand intérêt scientifique et stratégique. Les chercheurs y réalisent des mesures directes afin de mieux comprendre, par exemple, le climat. Dans le même temps, la très haute altitude suscite l’intérêt des acteurs de la défense, qui y voient un domaine propice au déploiement de plates-formes capables d’effectuer des missions de surveillance ou de communication tout en restant difficiles à détecter et à intercepter.

Une technologie aussi simple qu’ingénieuse permet pourtant d’accéder à la stratosphère : le ballon. Popularisé dès le XIXᵉ siècle par les récits de Jules Verne, ce moyen de transport aérien n’a cessé d’évoluer. Ainsi, les ballons modernes se distinguent désormais par leurs capacités de manœuvre : en modifiant leur altitude, ils exploitent les différentes couches de vent pour se déplacer et suivre des trajectoires choisies. Une élégante façon de naviguer dans les hautes couches de l’atmosphère, à la manière d’un voilier porté par les courants marins.
Léger comme un ballon
Parmi les différents engins capables de s’élever dans l’atmosphère – avions, hélicoptères ou fusées – les ballons occupent une place à part. Contrairement aux autres aéronefs, ils ne s’appuient ni sur la portance des ailes ni sur la poussée d’un moteur : ils utilisent la poussée d’Archimède pour se maintenir en altitude. Pour cela, leur enveloppe contient un gaz plus léger que l’air, généralement de l’hélium ou de l’hydrogène.
À mesure que l’on s’élève, l’air devient de moins en moins dense. Ainsi, à 18 kilomètres d’altitude, sa densité est divisée par dix par rapport à celle observée au niveau du sol. Cette diminution modifie directement la force d’Archimède, puisque celle-ci dépend de la masse d’air déplacée.
En ajustant soigneusement la quantité de gaz embarquée, le volume de l’enveloppe et la masse de la charge utile, il est possible d’atteindre une altitude d’équilibre dans la stratosphère. Le ballon peut alors demeurer pendant plusieurs semaines, voire plusieurs mois, à une altitude quasi constante.
Dans cette situation, deux forces s’équilibrent parfaitement : la poussée d’Archimède, dirigée vers le haut, et le poids du ballon, dû à la gravité terrestre, dirigé vers le bas. Le ballon « flotte » alors dans l’atmosphère, comme un navire à la surface de l’océan.
Histoire des ballons stratosphériques
Les ballons stratosphériques modernes sont fabriqués à partir de films de polyéthylène, un matériau léger, résistant et peu coûteux. Leur développement a véritablement pris son essor dans les années 1950, à mesure que la production industrielle de ces films plastiques se généralisait. Cette innovation a permis la réalisation de ballons de très grande taille, capables d’atteindre les hautes couches de l’atmosphère.
Dès 1960, les ballons stratosphériques suscitent l’intérêt des agences spatiales naissantes. En effet, ils offrent une plateforme idéale pour tester de nouvelles technologies et préparer les futures missions satellitaires. Plus simples à mettre en œuvre et beaucoup moins coûteux qu’un lancement orbital, ils permettent de valider des instruments dans un environnement proche de celui de l’espace.
Ainsi, dès sa création en 1961, le Centre national d’études spatiales (CNES) développe des programmes de ballons stratosphériques destinés à la recherche scientifique et à la préparation des technologies spatiales. Au fil des décennies, les progrès de l’électronique, des télécommunications et de l’informatique embarquée ont considérablement renforcé les capacités de ces plates-formes.

Les ballons stratosphériques ont ainsi contribué à l’étude de plusieurs enjeux scientifiques majeurs. Dans les années 1980 et 1990, ils ont participé à la compréhension de l’appauvrissement de la couche d’ozone au-dessus des régions polaires. Plus récemment, ils sont devenus des outils précieux pour l’observation du climat. Aujourd’hui, ils continuent de fournir des mesures uniques, indispensables à la compréhension de notre atmosphère et de son évolution.
Les ballons présentent également un atout remarquable : leur grande capacité à changer d’échelle. Il est possible de concevoir aussi bien des ballons d’une vingtaine de mètres de diamètre que des géants dépassant les 100 mètres. Les plus grands peuvent emporter près d’une tonne d’instruments scientifiques jusqu’à 40 kilomètres d’altitude.
Cette flexibilité est une des raisons du succès des ballons. Toutefois, ils sont confrontés à une limitation fondamentale. Contrairement à un avion ou à un satellite, un ballon ne dispose pas de moyen de propulsion lui permettant de modifier sa trajectoire. Une fois en vol, il est entraîné par les courants atmosphériques et dérive au gré des vents, ce qui limite fortement sa capacité à rejoindre ou à maintenir une position donnée.
Un voyage en ballon
Pour dépasser les limites des ballons traditionnels, les ingénieurs du CNES développent une nouvelle génération d’aéronefs stratosphériques : les ballons manœuvrants. Leur particularité réside dans leur capacité à modifier leur altitude en cours de vol. À l’image d’un voilier qui ajuste sa route en recherchant les vents les plus favorables, ces ballons exploitent les différentes couches de l’atmosphère pour se déplacer vers une destination choisie.
Cette capacité repose sur une architecture originale à double enveloppe. Le gaz porteur, généralement de l’hélium, est contenu dans une enveloppe interne. Autour de celle-ci se trouve une seconde enveloppe dans laquelle il est possible d’ajouter ou de retirer de l’air grâce à un dispositif spécialement conçu pour les conditions stratosphériques. En augmentant la quantité d’air embarquée, le ballon devient plus lourd et descend. À l’inverse, lorsque cet air est évacué, il retrouve de la flottabilité et remonte.

Le pilotage s’appuie ensuite sur les vents présents à différentes altitudes. Les ballons manœuvrants évoluent notamment autour de 20 kilomètres d’altitude, à la limite inférieure de la stratosphère, où les courants atmosphériques peuvent présenter des directions très différentes selon la hauteur. En choisissant soigneusement l’altitude la plus favorable, il devient possible d’orienter progressivement la trajectoire du ballon et de le guider vers sa zone d’observation.
Cette approche transforme le ballon en un véritable « voilier de la stratosphère », capable de parcourir de longues distances en utilisant uniquement l’énergie des vents, sans moteur ni consommation importante d’énergie.
Le concept de ballon manœuvrant n’est pas entièrement nouveau. Il a été développé à grande échelle au cours des années 2010 par l’entreprise états-unienne Google dans le cadre de son projet Loon. L’objectif était ambitieux : déployer une flotte de ballons stratosphériques capables d’apporter un accès à Internet dans les régions les plus isolées du globe, à l’image des constellations de satellites de télécommunication qui se développent aujourd’hui. Bien que le projet ait été arrêté en 2021 pour des raisons économiques, il a démontré la faisabilité et l’efficacité de la navigation stratosphérique par changement d’altitude.
Cette technologie a depuis trouvé de nouveaux débouchés. Aux États-Unis, l’entreprise Aerostar exploite des ballons manœuvrants capables de séjourner durablement dans la stratosphère. Ces plates-formes sont utilisées aussi bien pour des missions scientifiques que pour des applications liées à la surveillance et à la défense.
Consciente du potentiel stratégique et scientifique de ces véhicules, la France a engagé ses propres développements dans ce domaine. Depuis 2021, le CNES travaille à l’adaptation et à la maîtrise de cette technologie en partenariat avec Hemeria, acteur historique français du ballon stratosphérique.
L’objectif est de doter la France et l’Europe d’une capacité autonome de présence prolongée dans la stratosphère, au service de la recherche, de l’observation de l’environnement et des futures applications opérationnelles.
Des premiers tests de lâchers aux premiers tests en conditions réelles
Après plusieurs années de développement, le moment est venu de confronter notre ballon manœuvrant (Balman) à la réalité du terrain. Au printemps 2024, sur le site du CNES d’Aire-sur-l’Adour, dans les Landes, les équipes ont réalisé les premiers essais de lâcher de ce nouvel aéronef stratosphérique. Les opérations ont été menées à l’aube, quand les conditions météorologiques sont généralement plus calmes, limitant les rafales de vent susceptibles de compliquer les délicates opérations de décollage.

Mais réussir un lâcher de ballon ne constitue que la première étape. Pour valider pleinement le concept, il est indispensable de tester le véhicule dans son environnement opérationnel : la stratosphère. Ces essais doivent être réalisés en tenant compte de nombreuses contraintes, notamment l’insertion du ballon dans l’espace aérien et la maîtrise des risques liés au survol des populations. En effet, même si les vols sont soigneusement préparés, la retombée d’un équipement depuis plusieurs dizaines de kilomètres d’altitude nécessite des mesures de sécurité particulièrement rigoureuses.
Pour conduire ces essais dans les meilleures conditions, le CNES bénéficie d’un atout exceptionnel : le Centre spatial guyanais. Situé entre l’océan Atlantique et la forêt amazonienne, ce vaste territoire faiblement peuplé offre un environnement idéal pour les expérimentations aéronautiques et spatiales. C’est depuis cette base, mondialement connue pour les lancements d’Ariane-6, que les premiers vols du ballon manœuvrant ont été réalisés.
Ces campagnes d’essais ont permis de franchir plusieurs étapes majeures. Lors du premier vol, le ballon a démontré sa capacité à décoller, rejoindre la stratosphère puis revenir au sol en toute sécurité. Le second vol a marqué une avancée supplémentaire avec la première utilisation en conditions réelles du système de gestion d’air permettant de modifier l’altitude du ballon – une étape essentielle pour transformer ce simple ballon stratosphérique en véritable voilier capable de naviguer dans les vents de la haute atmosphère.
Le futur du Balman, le ballon manœuvrant
L’aventure Balman ne fait que commencer. Après les premiers vols d’essai, le programme poursuit sa qualification technologique. L’objectif est désormais d’accumuler de l’expérience en vol et d’enrichir progressivement le véhicule avec de nouvelles fonctionnalités. Parmi les prochaines évolutions figure notamment l’intégration d’un système de parachute, dont les premiers essais sont prévus à l’hiver 2026.
À mesure que sa maturité technologique augmentera, Balman ouvrira la voie à de nouvelles applications scientifiques. L’une des premières pourrait être sa contribution à la succession du projet Strateole-2, une future flotte de ballons longue durée développée conjointement par le CNES et le CNRS à l’horizon 2030. Grâce à leur capacité à séjourner plusieurs mois dans la stratosphère, ces ballons constitueront un outil unique pour observer et mieux comprendre les échanges entre les différentes couches de l’atmosphère.
L’étude du climat et de l’atmosphère repose aujourd’hui sur la complémentarité de plusieurs moyens d’observation. Les satellites offrent une vision globale de notre planète, tandis que les mesures réalisées directement dans l’atmosphère permettent d’analyser avec précision les phénomènes locaux et les mécanismes physiques à l’œuvre. En apportant sa capacité de manœuvre à ces futures missions, Balman permettra d’orienter les observations vers les zones les plus intéressantes et d’optimiser le déploiement des instruments scientifiques.
À plusieurs dizaines de kilomètres au-dessus de nos têtes, une nouvelle génération de ballons est ainsi en train d’émerger. Capables de naviguer dans les vents de la stratosphère comme des voiliers sur l’océan, ils pourraient bientôt devenir des outils essentiels pour mieux comprendre notre atmosphère et les changements qui l’affectent.
Francois VACHER ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son poste au CNES.
Laurent Tessariol ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.07.2026 à 23:55
Les tours Saint-Jacques, un prodige d’équilibre au cœur des Alpes
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (3003 mots)

Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. L’itinéraire de la 17ᵉ étape, le 23 juillet, entre Chambéry en Savoie et Voiron dans l’Isère, fait passer les coureurs par les tours Saint-Jacques, dans le massif des Bauges, en Haute-Savoie. Une curiosité géologique locale à la légende pour le moins insolite.
Pour leur 17ᵉ étape, le 23 juillet, les coureurs du Tour de France entreront dans le massif des Bauges (Haute-Savoie) par une trouée : la vallée du Chéran.
Les paysages de montagnes provoquent souvent une émotion par leur simple esthétique. Lorsque leur compréhension atteste en outre d’un phénomène rare et extraordinaire, l’émerveillement en est décuplé.

Les tours Saint-Jacques font partie de ces lieux : sur le flanc sud-ouest du massif du Semnoz dans les Bauges, dominant le village d’Allèves (Haute-Savoie), ces pitons rocheux baptisés d’après la chapelle d’un ancien prieuré attirent l’attention. Autrefois surnommés les « aiguilles de Racheroche », ces trois monolithes calcaires dont le plus grand mesure 70 mètres de hauteur et culmine à 991 mètres d’altitude, intriguent. De loin, ils évoquent les ruines d’anciennes tours.
Une histoire d’aigle, de loup et d’agneau
Comme beaucoup de lieux inhabituels, ces majestueuses aiguilles ont leur légende locale.

{kind=link}
Il est dit que, un jour, un aigle emporta un agneau menacé par un loup afin de lui éviter d’être dévoré. L’agnelet, un peu gros et un peu trop lourd pour être emmené au loin par le volatile aurait été déposé sur l’un des trois pitons, hors d’atteinte du loup. Des années plus tard, un alpiniste y aurait découvert un bélier. Les Aléviens, émerveillés par ce geste inattendu, y auraient vu un signe divin.
L’aigle et l’agneau sont alors devenus symboles de paix et de protection du bourg. Les tours ont ainsi offert, à partir de cette histoire, son identité à Allèves.
À lire aussi : Tour de France : marbre en serpentinite et traces d’un océan en haut des montagnes
Des sculptures naturelles

Le phénomène géologique de « paquet tassé », par lequel les roches glissent vers l’aval en ne perdant pas entièrement leur structure, est bien visible à travers les tours Saint-Jacques.
En réalité, de tels reliefs sont connus dans les Alpes en différents endroits et généralement appelés des « cheminées de fées ». Les « demoiselles coiffées » de Pontis, à l’est du lac de Serre-Ponçon (Alpes-de-Haute-Provence) sont les plus célèbres. Ces reliefs résultent d’une érosion différentielle qui décape des sédiments tendres (marnes, argiles sableuses, cendres…) sous un chapeau de roche plus résistante (bloc calcaire, bombe volcanique…)

{kind=link}
Les tours qui dominent Allèves sont le fruit d’un processus bien plus complexe. La pente d’où s’élèvent ces tours constitue le flanc sud du massif du Semnoz, dont le sommet est composé de calcaires d’âge crétacé (Valanginien, de -140 millions à -136 millions d’années), dits « calcaires de Fontanil » ou encore « marbre bâtard ». Ce massif forme une voûte (un anticlinal) dont la pente plonge vers le sud-ouest.
Cette épaisse couche de calcaires repose sur des marnes et des calcaires marneux un peu plus anciens (Berriasien, de -145 millions à -140 millions d’années). Les marnes, bien plus plastiques que le calcaire, peuvent former une sorte de couche « savon » sur laquelle des blocs détachés de la falaise du haut, tels des icebergs au front d’un glacier, peuvent glisser vers la rivière du Chéran.

Mais certaines inconnues demeurent.
Trois théories à l’épreuve
Trois propositions sont actuellement avancées pour expliquer la situation actuelle.

La première tiendrait à un simple phénomène érosif. Comme nous sommes sur la retombée d’un bombement, les couches sont inclinées vers le bas, vers la vallée. Elle sont parallèles – ou presque – à la pente. Soumises à l’érosion, des parties disparaissent, mais certains blocs résistent mieux et glissent plus bas. Elles constitueraient ainsi des buttes-témoins : les tours Saint-Jacques.
La deuxième postule un glissement de terrain en masse. Au front de la dalle calcaire, des blocs peuvent se détacher, un peu à l’image des icebergs qui se séparent de la banquise. Comme la dalle est inclinée, certains éléments reposant sur une couche plastique (les marnes du Berriasien) se mettent à glisser lentement tout en conservant leur position verticale.
La troisième explication fait appel à une logique plus complexe, associant séparation et glissement. La dalle calcaire du haut se serait fracturée en nombreux panneaux de tailles différentes. Ces éléments se seraient mis à glisser. Certains auraient basculé, d’autres se sont effondrés, auraient été érodés, en bref, certains seraient devenus invisibles dans la topographie au cours du temps. D’autres auraient résisté un peu mieux, se seraient fracturés en sous-blocs, continuant toutefois de glisser sans s’effondrer : les tours Saint-Jacques actuelles.
La deuxième théorie est, à l’heure actuelle, celle qui est privilégiée pour expliquer l’origine de ces structures. C’est aussi la mieux documentée. Les éléments n’auraient pas basculé en s’effondrant, mais en glissant tout doucement le long de la pente. Ils sont maintenant éloignés de plusieurs centaines de mètres de leur « port d’attache », de 700 mètres pour la plus haute et de 960 mètres pour la plus basse et la plus fine.
Et surtout, ils continuent à descendre, à une vitesse variable selon les éléments : de 2,1 cm/an pour la plus haute, de 1,8 cm/an pour le bloc du milieu et jusque 4,6 cm/an pour le plus fin, le plus bas, le plus rapide.
À lire aussi : Tour de France : entre Bourgogne et Quercy, grands crus et grenouilles momifiées
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
02.07.2026 à 17:11
La Sagrada Familia, ou quand les microfossiles inspirent l’architecture
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (3859 mots)

Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. La toute première étape de son édition 2026, le samedi 4 juillet, met Barcelone à l’honneur. La ville espagnole est connue pour sa fameuse basilique la Sagrada Familia, conçue par l’architecte Antoni Gaudi. Celui-ci s’est notamment inspiré, au plan esthétique, de la géologie et du vivant, et en particulier des microfossiles.
La toute première étape du Tour de France fait un détour par l’Espagne, plus précisément par Barcelone. La ville abrite l’emblématique Sagrada Familia, conçue par l’architecte espagnol Antoni Gaudi.
L’occasion de revenir sur les liens entre architecture, vivant et géologie, très présents dans l’Art nouveau, qui ont beaucoup inspiré Antoni Gaudi. Ces influences qui se retrouvent, comme on va le voir, dans le chef-d’œuvre de l’architecte.
Quand la nature inspire l’Art nouveau

{kind=link}
L’Art nouveau, mouvement artistique né à la fin du XIXᵉ siècle, s’appuie sur l’esthétique (des lignes, des couleurs, des ornementations) de la nature et de ses structures. Prendre la nature comme référence, c’est alors réagir contre le rationalisme du début de l’ère industrielle.
Pour le biologiste allemand Ernst Haeckel (1834-1919), la nature est apparentée à l’art. Il fut notamment marqué par la symétrie des microorganismes tels les radiolaires. Ses dessins d’organismes du plancton, obtinrent une grande célébrité, en particulier ses ouvrages Kunstformen der Natur (Formes artistiques de la nature), parus de 1899 à 1904 sous la forme de nombreux cahiers.
Ses représentations de micro et de macroorganismes ont considérablement influencé l’art du début du XXᵉ siècle. Les meilleurs exemples de cette fusion sont visibles au Musée océanographique de Monaco, dont le lustre méduse de Constant Roux, mais aussi les quatre lampes « radiolarium » et les fresques réalisées à partir des dessins d’Ernst Haeckel.
Les radiolaires de l’exposition universelle et l’essor du fonctionnalisme
Il en est de même pour la porte monumentale, à l’exposition universelle de Paris en 1900, de l’architecte français René Binet (1866-1911). La publication par Binet d’Esquisses décoratives, inspirée de Haeckel, fut une des bases de l’Art nouveau.

Les formes naturelles résultent de leur aptitude à une fonction et de règles morphologiques. Tout cela inspire considérablement les architectes de l’époque.
L’architecte français Eugène Viollet-le-Duc (1814-1879) a écrit qu’il fallait « chercher la raison de toute forme car toute forme a sa raison » dans sa préface des Entretiens sur l’architecture. Ce courant de pensée culmine avec la publication, en 1917, de l’ouvrage de D’Arcy Wentworth Thompson (1860-1948) Forme et Croissance, qui connaît un immense succès auprès des architectes.
Pour les fonctionnalistes (du courant fonctionnaliste en architecture), la forme et l’apparence d’un bâtiment devraient découler de sa fonction. En 1923, le biologiste autro-hongrois Raoul Francé (1874-1943) écrit :
« La nécessité prescrit certaines formes pour certaines qualités. (…) Dans la nature, toute forme (…) est une création de la nécessité. »
Ces parallèles avec l’architecture sont repris par l’architecte français Le Corbusier (1887-1965), qui déclare :
« La biologie est désormais le maître mot en architecture et urbanisme. »
Les influences géologiques de Montserrat à Barcelone
En France, Eugène Viollet-le-Duc sera l’inspirateur de nombreux architectes de l’Art nouveau, qui triomphe à l’Exposition universelle de Paris en 1900. Barcelone aussi s’illustre par des monuments Art nouveau, parmi lesquels ceux de l’architecte Antoni Gaudí, avec la basilique de la Sagrada Familia commencée en 1882. Pour lui :
« L’architecture du futur construira en imitant la nature, parce que c’est la plus rationnelle, durable et économique des méthodes. »
Alors qu’il était étudiant, Antoni Gaudi avait travaillé à l’abbaye de Montserrat (Catalogne) dont le paysage l’a marqué à tel point que l’on considère parfois que les tours de la Sagrada Familia sont une ode à Montserrat.

Ses tours, semblables à des aiguilles de pierre, reproduisent la verticalité des pics de Montserrat, tandis que les façades, sculptées comme par l’érosion, rappellent les parois rocheuses. Ces falaises sont constituées d’un conglomérat qui résulte de l’érosion des Pyrénées.
Ce même type de roche donne des reliefs similaires ailleurs, eux aussi accueillant parfois également des hommes d’Église, comme dans les monastères des Météores, en Grèce.

{kind=link}
Le biomimétisme en architecture, des radiolaires aux diatomées
Revenons-en aux radiolaires, et plus particulièrement à leurs microfossiles. Le squelette est le seul élément d’étude du micropaléontologue.
Or, la géométrie du squelette des radiolaires répond aux mêmes lois de physique fondamentale que celles qui régissent les interfaces entre fluides ou entre fluides et solides. Il existe aussi une similitude frappante de formes entre une association de bulles de savon et certains squelettes de ces organismes.
Une expérience permet de bien comprendre le processus lié aux volumes créés par des tensions superficielles moindres en plongeant des structures rigides en fil de fer dans un bain d’eau savonneuse. On observe alors des structures similaires, parce que les forces physiques jouent de la même façon.

Les structures de la nature résultent, elles, de centaines de millions d’années d’essais et d’erreurs, qui tiennent par exemple à la résistance mécanique ou aux économies de moyens, notamment en matière d’énergie nécessaire pour déposer le matériau (siliceux ou calcaire…). Les formes qui en sont issues répondent à des nécessités physiques et chimiques. Il n’est guère surprenant qu’elles inspirent les architectes et qu’elles invitent à établir un pont entre art et science à travers le biomimétisme.
Au-delà de l’Art nouveau, ce monde microscopique a continué d’influencer les architectes de structures monumentales telles la Géode du parc de la Cité des sciences, porte de la Villette à Paris, inaugurée en 1985, ou encore la Biosphère du pavillon des États-Unis à l’Exposition universelle de Montréal en 1967.
On retrouve des structures semblables dans les œuvres de l’allemand Frei Otto pour le toit du parc olympique de Munich pour les Jeux olympiques de 1972 ou de Jörg Gribl avec le bâtiment des hippopotames du zoo de Berlin.
{kind=link}

{kind=link}
Plus curieux encore, car il ne s’agit pas de copie cette fois, mais d’une ressemblance fortuite : il est tout à fait extraordinaire de constater que la structure du dôme de Sainte-Sophie à Istanbul, évoque celle d’une diatomée alors même qu’à l’époque de sa construction (VIᵉ siècle) on ne connaissait pas encore la forme des diatomées ! Or, ce dôme est justement construit avec de la diatomite, seule roche suffisamment légère, pour une telle taille. Ou quand la science rejoint, des siècles plus tard, l’imagination des architectes.

{kind=link}
Une précédente version de ce texte a été publiée le 8 juin 2026 sur le site_ Planet Terre _de l’ENS Lyon.
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
02.07.2026 à 10:12
Ce que l’on sait des récents séismes au Venezuela, et des risques qui subsistent
Sylvain Barbot, Professor of Earth Sciences, USC Dornsife College of Letters, Arts and Sciences
Texte intégral (2482 mots)
Le Venezuela et sa capitale, Caracas, ont été frappés par deux puissantes secousses sismiques le 24 juin 2026, à seulement quelques secondes d’intervalle. Les deux séismes, de magnitude 7,2 et 7,5, ont provoqué l’effondrement de bâtiments dans plusieurs villes du nord du pays, faisant plus de 2 200 morts et piégeant de nombreuses autres personnes, selon les autorités.
Le géophysicien Sylvain Barbot explique ce que l’on sait à ce stade de cette double secousse et les risques qui subsistent. Chercheur à l’Université de Californie du Sud, il dresse également un parallèle avec la faille de San Andreas, aux États-Unis.
Les séismes sont des phénomènes naturels qui se produisent généralement aux limites des plaques tectoniques de la Terre. Ces plaques, qui constituent la croûte terrestre, ont une épaisseur de plusieurs dizaines de kilomètres et portent les océans comme les continents. Elles sont en mouvement permanent, mais pas de manière fluide ni régulière.
Le Venezuela se situe à la frontière entre deux de ces plaques : la plaque sud-américaine et la plaque caraïbe. En glissant l’une contre l’autre, elles peuvent se bloquer, accumulant des contraintes jusqu’à ce qu’elles cèdent brutalement, provoquant un séisme.

Le 24 juin 2026, deux fortes secousses sismiques se sont produites à 39 secondes d’intervalle, toutes deux d’une magnitude supérieure à 7. Il pourrait s’agir de deux séismes distincts ou d’un seul séisme comportant deux phases de rupture. Les scientifiques ne le savent pas encore, car les données sont toujours en cours d’analyse.
L’hypothèse de deux séismes distincts est tout à fait plausible. En 2023, la Turquie a connu un « doublet » sismique, avec deux séismes de magnitude supérieure à 7 survenus à huit heures d’intervalle. Dans ce cas, il s’agissait clairement de deux événements distincts.
À lire aussi : Pourquoi il y a des séismes en cascade en Turquie et en Syrie
Au Venezuela, les deux secousses n’étaient espacées que de quelques secondes. Par le passé, de très longues failles ont subi des déplacements sur différents segments lors de séismes de cette ampleur, donnant l’impression qu’il s’agissait de deux séismes distincts alors qu’ils correspondaient en réalité à deux ruptures d’un même événement sismique.
Qu’est-ce qui déclenche des séismes aussi destructeurs ?
Les séismes sont déterminés par la manière dont les roches résistent aux contraintes de cisaillement et de pression. Ces contraintes peuvent s’accumuler pendant des années, voire des décennies, jusqu’à dépasser la résistance des roches, qui finissent alors par se rompre. À partir de ce moment, la contrainte se propage et la rupture s’étend.
Il ne s’agit pas d’un mouvement progressif. En quelques secondes, les plaques se déplacent brutalement, provoquant un séisme. Ce phénomène se produit à plusieurs kilomètres sous la surface, où la température et la pression sont très élevées.
Ce phénomène est difficile à reproduire en laboratoire et met en jeu de nombreux processus, relevant aussi bien de la mécanique que de la chimie ou de la circulation des fluides. Son résultat est toutefois simple : une rupture se produit, au cours de laquelle des masses rocheuses glissent les unes contre les autres, créant une fracture qui brise tout sur son passage et provoque d’importants dégâts.
Le système de failles du Venezuela est-il comparable à celui de la faille de San Andreas, en Californie ?
Les failles impliquées dans le séisme au Venezuela et la faille de San Andreas, en Californie, sont très similaires. Il s’agit de failles transformantes, où les plaques glissent horizontalement l’une par rapport à l’autre selon un mouvement en décrochement.
Même les vitesses de déplacement sont assez proches. Au Venezuela, les deux plaques glissent l’une par rapport à l’autre à une vitesse moyenne d’environ 20 millimètres par an. Le long de la faille de San Andreas, ce mouvement est légèrement plus rapide, de l’ordre de 30 millimètres par an.
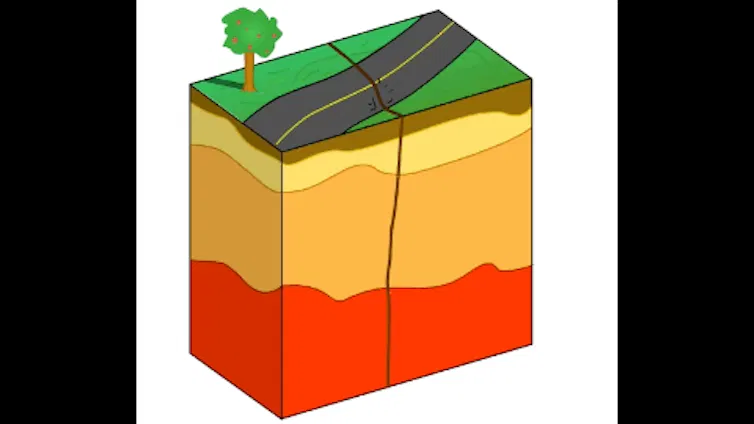
Ces failles produisent également des séismes de forte magnitude à des fréquences comparables. Sur la faille de San Andreas, les scientifiques estiment qu’un séisme de magnitude 7 ou plus se produit en moyenne tous les 170 ans environ, même si cet intervalle varie selon les segments de la faille. Il ne s’agit toutefois pas d’un mécanisme d’horlogerie : ces séismes peuvent survenir beaucoup plus fréquemment… ou beaucoup plus rarement.
Le dernier « Big One » du sud de la Californie remonte au séisme de Fort Tejon, en 1857, un puissant tremblement de terre de magnitude 7,9. Une étude récente suggère que les contraintes accumulées le long de la partie sud de la faille de San Andreas sont aujourd’hui plus importantes qu’à n’importe quel moment au cours des mille dernières années. Si les hypothèses de cette étude sont correctes, la faille pourrait être proche de rompre. Mais la fréquence des grands séismes est très variable : le prochain pourrait survenir dans cent ans… ou demain. Personne ne peut le prédire.
Ces failles ont déjà produit de nombreux séismes par le passé. C’est à lui seul un argument en faveur de normes parasismiques strictes pour les bâtiments et les infrastructures, comme les ponts ou les hôpitaux, ainsi que de plans de préparation aux situations d’urgence.
Les scientifiques ont-ils identifié des signes annonciateurs permettant de prévoir un séisme imminent ?
Les scientifiques cherchent activement à identifier des précurseurs fiables qui permettraient d’alerter avant une rupture sismique, mais aucun signal suffisamment fiable n’a encore été mis en évidence.
Il existe des cas anecdotiques où des essaims de petits séismes ont précédé une rupture majeure et qui, rétrospectivement, auraient pu constituer des indices précoces d’un grand séisme à venir. Mais ce n’est pas systématique.
L’apprentissage automatique a permis de mettre en évidence des modifications régulières de la microsismicité précédant les ruptures majeures, et certaines études sur la physique des séismes ont commencé à expliquer pourquoi ce phénomène se produit.
À lire aussi : Une IA pour détecter les signes avant-coureurs des séismes lents
Il y a donc de bonnes raisons d’espérer qu’à l’avenir, nous serons capables de relier ces différents indices et de mieux comprendre les mécanismes en jeu. Mais nous n’en sommes pas encore là.
En revanche, il est possible d’émettre des alertes à très court terme. Lorsqu’un séisme débute, il génère plusieurs types d’ondes sismiques qui se propagent à des vitesses différentes. Les plus rapides arrivent en premier et peuvent être détectées, ce qui permet aux scientifiques de prévoir l’arrivée des deuxième et troisième trains d’ondes, plus lents et généralement plus destructeurs.
Après les premières ondes, appelées ondes P, arrivent les ondes S, ou ondes de cisaillement, qui sont un peu plus puissantes. Viennent ensuite les ondes de surface. Les premières ondes P peuvent déclencher les systèmes d’alerte précoce, offrant seulement quelques secondes de réaction, mais cela suffit pour interrompre le trafic, fermer les gazoducs, arrêter les trains à grande vitesse et sécuriser les infrastructures sensibles aux secousses. Cela peut également laisser juste assez de temps pour se mettre à l’abri et éviter d’être tué par l’effondrement d’un bâtiment, au bureau comme à la maison.
Quels sont désormais les risques pour le Venezuela ?
Les géologues connaissent bien la tectonique de cette région, car ils cartographient ces failles et étudient leur comportement depuis des décennies. Mais pour comprendre précisément cet événement, les scientifiques doivent se rendre sur le terrain afin d’évaluer l’ampleur des dégâts et de mesurer l’étendue de la rupture.
Par ailleurs, les séismes entraînent d’autres risques. Après les secousses, la région reste pendant plusieurs mois, voire plusieurs années, plus exposée aux glissements de terrain, car les roches ont été déstabilisées.
Cela signifie que les prochaines fortes pluies risquent de déclencher des glissements de terrain. Le Venezuela doit donc s’attendre à de nouveaux dégâts, à d’autres dangers et, malheureusement, à de nouvelles pertes humaines.
Sylvain Barbot ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
02.07.2026 à 08:23
Que deviennent les fûts de déchets radioactifs immergés dans l’Atlantique dans les années 1970 et 1980 ? Les débuts de réponse d’une expédition scientifique
Javier Escartin, Directeur de recherche CNRS en géologie marine, École normale supérieure (ENS) – PSL
Patrick Chardon, Ingénieur en métrologie nucléaire au Laboratoire de Physique de Clermont Auvergne, coresponsable de la mission NODSSUM, Université Clermont Auvergne (UCA)
Texte intégral (2243 mots)

Entre 1971 et 1982, plus de 200 000 fûts de déchets radioactifs furent immergés par plusieurs pays européens dans l’Atlantique Nord-Est, à des profondeurs atteignant plus de 4 700 mètres. La localisation exacte de ces barils et surtout leurs impacts possibles sur l’environnement des grands fonds restaient à ce jour largement inconnus depuis des études des années 1980.
Les campagnes à la mer NODSSUM 2025 et 2026, portées par le CNRS et réalisées avec les moyens de la Flotte océanographique française, ont permis d’identifier plusieurs milliers de ces barils.
À l’aide du sous-marin Nautile, nous avons inspecté visuellement plusieurs dizaines de ces fûts, documenté leur degré avancé de dégradation et observé des containers particulièrement corrodés.
Le contenu de certains d’entre eux se répand sur le fond marin environnant. Ces fûts sont colonisés par différents organismes, notamment des anémones, des éponges et des crabes.

Sur cinq sites d’étude retenus, à proximité immédiate et au contact des fûts, le Nautile a réalisé des prélèvements détaillés de sédiments, d’eau, d’organismes et de communautés microbiennes. Les habitats rocheux voisins ont également été explorés par le sous-marin, afin de les comparer avec les écosystèmes présents sur et autour des fûts.
Des instruments de mesure de radioactivité de terrain embarqués ont détecté des signaux significatifs de radionucléides spécifiquement liés à ces déchets, le cobalt 60 et le niobium 94, en plus du césium 137 et de l’américium 241 (ces derniers sont également des marqueurs des essais aériens d’armes et accidents nucléaires, mais présents ici dans des quantités bien supérieures à ce marquage classique).
Ces mesures et contrôles radiologiques ont permis de confirmer l’absence de contamination des instruments déployés (y compris le Nautile) et de s’assurer que les niveaux d’activité n’induisaient pas de problèmes majeurs de radioprotection pour les scientifiques de la campagne à la mer.
Comment ces observations ont-elles été réalisées ?
La zone de déversement couvre une surface d’environ 14 500 kilomètres carrés. Pour identifier les fûts et définir les cibles de notre étude, le robot autonome Ulyx de la Flotte océanographique française a été déployé lors de la campagne 2025.
Capable de plonger jusqu’à 6 000 mètres et survolant les fonds marins d’environ 70 mètres, il acquiert des données sonar haute résolution avec une précision de 5 centimètres. Ulyx a permis de cartographier environ 165 kilomètres carrés, soit moins de 2 % de toute la zone de déversement. Plus de 3 500 fûts ont été localisés, alignés selon les trajectoires des navires ayant effectué les déversements.

Ulyx a également pu s’approcher et survoler le plafond océanique à environ 8-10 mètres au-dessus du fond marin pour se procurer des images. Nous avons prospecté cinq zones et photographié environ 50 fûts, montrant l’épanchement de matière hors des fûts. Ces données ont été combinées à un échantillonnage de sédiments réalisé en 2025 à distance des fûts depuis le navire, dont l’analyse a révélé la présence de radionucléides artificiels probablement associés à ce déversement, supérieure à celle attendue dans les grands fonds.
Les images de fûts dégradés prises par Ulyx, associées aux analyses de sédiments montrant les niveaux d’activité les plus élevés, ont fourni les cibles des plongées du Nautile lors de la campagne 2026.
Pourquoi est-ce important ?
Tout d’abord, ce site constitue un laboratoire unique pour comprendre le devenir des radionucléides dans les grands fonds et leurs interactions avec les écosystèmes de l’océan profond.
Les fûts modifient l’environnement en offrant un substrat dur qui se trouve colonisé, facilitant potentiellement ces transferts de radionucléides vers les organismes vivants, avec des conséquences encore inconnues, qui vont être évaluées par le projet NODSSUM. Les résultats de l’analyse des échantillons fourniront, dans les mois à venir, des indices sur l’impact de ces écosystèmes, y compris les microorganismes, ainsi que sur leur rôle dans le transfert et la mobilisation de ces radionucléides, permettant d’évaluer leurs impacts.
Enfin, il s’agit de l’une des premières études radioécologiques en grands fonds marins, ayant nécessité la mise en place et le développement de nouvelles procédures et méthodologies allant de la définition de la stratégie d’échantillonnage jusqu’à la radioprotection à bord.
Quelles vont être les suites ?
Les campagnes de 2025 et de 2026 ont permis de collecter un ensemble riche et vaste de données et d’échantillons : cartes sonar, images de fûts et des zones adjacentes, des centaines d’échantillons de sédiments, plusieurs dizaines de poissons, des milliers de litres d’eau filtrés et de nombreux organismes, dont des anémones et des concombres de mer.

Les images seront analysées afin de caractériser la composition et la structure des écosystèmes associés aux fûts et de ceux des zones avoisinantes. Les échantillons (sédiments, eau, faune) seront analysés dans les mois à venir par un groupe français et international de chercheurs (Norvège, Allemagne, Espagne) afin d’identifier et de quantifier différents radionucléides artificiels et d’étudier leur dispersion depuis les fûts vers l’environnement des grands fonds.
L’ensemble de ces données constituera l’une des études radioécologiques des grands fonds les plus complètes à ce jour et permettra de mieux comprendre le cycle biogéochimique des radionucléides dans ces environnements.
Pour aller plus loin et suivre l’actualité du projet NODSSUM, retrouvez-le sur Bluesky et LinkedIn, #NODSSUM.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Javier Escartin a reçu des financements de l'ANR pour autres projets et sans lien a la campagne NODSSUM.
Patrick Chardon a reçu des financements de ANR sans lien avec le projet NODSSUM
01.07.2026 à 17:25
Décapitaliser le savoir scientifique et le rendre accessible à tous : des solutions existent
Frédéric Schmidt, Professeur, Planétologie, Université Paris-Saclay
Camille Thomas, Chercheur en géologie, University of Bern
Romain Vaucher, Senior Lecturer in Sedimentology, James Cook University
Texte intégral (2742 mots)

Publier et accéder à des articles scientifiques coûte très cher aux organismes de recherche. L’accès ouvert est-il la solution parfaite ? Découvrez des exemples concrets de publications qui allient gratuité, exigence et rigueur.
L’édition scientifique est une industrie particulièrement rentable. Les estimations les plus récentes suggèrent qu’elle génère environ 19 milliards de dollars US (soit 16,67 milliards d’euros) de chiffre d’affaires par an, avec des marges qui avoisinent les 40 %. Ces chiffres vertigineux reflètent en grande partie le fait que des maisons d’édition privées, telles qu’Elsevier, Springer Nature, Wiley, Taylor & Francis ou SAGE, capitalisent sur un travail largement financé par des fonds publics.
Cette monétisation se fait soit conditionnant l’accès à un article scientifique au paiement d’un droit ou d’un abonnement, soit en faisant payer les auteurs pour publier en libre accès pour le lecteur. Pourtant, la majeure partie du travail nécessaire à la publication, notamment la rédaction, l’évaluation par les pairs et une grande partie du travail éditorial, est fournie gratuitement par les chercheurs. La conséquence directe est que la richesse d’un institut ou d’un pays dicte encore en partie l’accès au savoir scientifique.
Les barrières payantes
Pendant des décennies, la vaste majorité de la recherche a été publiée derrière des barrières payantes (paywalls). Cela signifie que les scientifiques, leurs institutions et le grand public doivent payer pour accéder aux découvertes scientifiques. Une personne peut acheter l’accès à un article spécifique pour quelques dizaines ou parfois une centaine d’euros. Les instituts de recherche, quant à eux, paient des abonnements qui se chiffrent souvent en millions d’euros à des milliers de revues scientifiques afin que leurs chercheurs puissent accéder à ces articles.
Rétrospectivement, avant l’avènement d’Internet et la diffusion massive de revues au format électronique, il était compréhensible que la production d’articles scientifiques engendre des coûts très importants, notamment en raison de l’impression et de la distribution physique des revues dans les bibliothèques universitaires. Aujourd’hui, cette justification n’est plus fondée.
Alors même que les coûts de production ont fortement diminué grâce à la diffusion numérique des articles, les frais de publication ont drastiquement augmenté. En réponse à cette privatisation du savoir, Aaron Swartz a publié en 2008 le Guerilla Open Access Manifesto, qui a eu pour but d’alerter et d’insister sur le manque d’accès pour les pays du Sud global.
Dans ce contexte, Alexandra Elbakyan a créé Sci-Hub en 2011, une plateforme, qui permet de donner accès à un grand nombre de publications scientifiques, devenue l’une des plus grandes fuites de connaissances scientifiques de notre époque. Bien que cette initiative repose sur une revendication éthique d’accès universel au savoir, elle demeure illégale et condamnée dans de nombreux pays, et ne saurait être une solution pérenne au problème de l’accès à la connaissance scientifique.
L’accès ouvert est-il une solution ?
Face à la frustration croissante suscitée par le verrouillage des résultats de la recherche derrière des barrières payantes, et aux fortes inégalités d’accès à la science qui en découlent, l’Open Access (OA), ou accès ouvert, est de plus en plus souvent exigé par les agences de financement de la recherche, et parfois par les gouvernements eux-mêmes. L’objectif est simple : faire en sorte que la recherche, en particulier lorsqu’elle est financée par des fonds publics, soit accessible comme un bien commun.

Aujourd’hui, si l’Open Access est devenu la norme, plusieurs modèles coexistent et ne répondent pas tous au problème de la même manière. Les trois principales voies sont l’OA verte, l’OA dorée et l’OA diamant.
L’OA verte consiste à publier dans une revue classique, souvent commerciale, puis à déposer une version acceptée mais non formatée du manuscrit dans une archive ouverte ou un dépôt institutionnel. L’OA dorée rend l’article final immédiatement accessible à tous, mais repose sur des frais de publication s’élevant à plusieurs milliers d’euros, payés par les auteurs ou leurs institutions. L’OA diamant, enfin, permet une publication gratuite pour les auteurs et une lecture gratuite pour les lecteurs, grâce à des revues portées par des communautés scientifiques, des bibliothèques universitaires ou des institutions sans but lucratif.
Les modèles d’OA verte et dorée restent dépendants des éditeurs commerciaux et entraînent souvent des coûts cachés pour les chercheurs, les institutions ou les financeurs. À l’inverse, l’OA diamant est porté par la communauté, gratuit à la fois pour les auteurs et pour les lecteurs, et maintient la recherche comme un bien public plutôt qu’une source de profit privé. Si l’OA verte améliore l’accès à court terme, elle peut aussi retarder des changements structurels plus profonds en préservant le système existant.
Des exemples d’accès diamant
Grâce aux avancées techniques récentes, il est facile de partager du code informatique, et la communauté scientifique, soutenue par les financeurs publics, s’est organisée pour créer Open Journal System, qui est un logiciel clé en main permettant de gérer l’ensemble du processus éditorial d’une revue scientifique (de la soumission des manuscrits à l’évaluation par les pairs, l’édition, la publication et la diffusion).
Aujourd’hui le système est utilisé dans 148 pays dans le monde et permet la gestion éditoriale gratuite de journaux par les scientifiques eux-mêmes. Parmi ces journaux, Sedimentologika, créé en novembre 2022, qui va bientôt publier son cinquantième article dans le domaine de la sédimentologie, ou Planetary Research, qui va publier son premier article dans le domaine de la planétologie en juillet 2026, sont deux revues que nous avons contribué à fonder.
D’autres initiatives, structurées en plateforme, comme Sci|Post, historiquement ancré dans le domaine de la physique, ou Episciences, proposent désormais des modèles étendus à l’ensemble des domaines de la science, y compris les sciences humaines et sociales. À l’échelle plus locale des établissements et universités, de nouveaux projets de presse académique émergent, tel que POPS à l’Université Paris-Saclay.
Les scientifiques ont aussi proposé d’autres façons de publier, s’affranchissant des codes de conduites les plus courants. Par exemple, la publication dans arXiv de l’Université Cornell, un gigantesque dépôt gratuit de 2,4 millions d’articles, ou sur son équivalent français HAL, permettent le partage de manuscrit sans validation par les pairs (article de type « preprint »). Le seul critère d’accès est que le déposant doit avoir un e-mail institutionnel ou être coopté par ses pairs (critère récent, nécessaire pour filtrer les faux articles créés par intelligence artificielle). La garantie de qualité scientifique y reste donc relativement limitée, mais l’avantage réside dans l’immédiateté de la diffusion à tous. De nombreux travaux très influents et largement cités, par exemple dans le domaine de l’intelligence artificielle, sont ainsi accessibles sans n’avoir jamais été évalués par les pairs. Cependant, la plupart des articles déposés sur arXiv sont également publiés par la suite dans des revues scientifiques après processus d’évaluation. Dans ce cas, arXiv sert principalement de plateforme de diffusion rapide et d’échange scientifique venant compléter plutôt que remplacer le processus éditorial traditionnel.
Certaines sociétés savantes proposent depuis longtemps des revues en accès diamant, comme les Comptes Rendus de l’Académie des sciences ou certaines communications de la Société américaine de mathématique. Malheureusement, le modèle économique en accès diamant est parfois difficile à établir, mais des solutions innovantes sont proposées. Par exemple, le Bulletin de la Société mathématique de France propose un modèle d’inscription-pour-ouverture (Subscribe-to-Open, S2O). Il s’agit ici chaque année de payer un abonnement pour la lecture, mais lorsque le seuil de rentabilité est atteint, tous les articles publiés dans cette revue deviennent accessibles librement ad vitam aeternam. Chaque année, le compteur est remis à zéro.
Une autre façon de publier consiste à proposer une discussion libre à propos de l’article après publication. Ce type de solution a l’avantage d’évaluer l’article, mais, pour l’instant, aucune solution pérenne et de grande ampleur n’a émergé. Il existe néanmoins des solutions intéressantes. Par exemple, Peer Community In comporte aujourd’hui 21 journaux thématiques avec relecture, publie gratuitement à la fin de l’évaluation et laisse le choix aux auteurs de soumettre de nouveau dans un journal traditionnel ou non.
Des dangers futurs, mais aussi des opportunités
L’édition scientifique est, aujourd’hui, mise en péril par les logiques capitalistes des grands éditeurs privés, qui s’enrichissent grâce à une aura et une respectabilité pourtant produite par les scientifiques eux-mêmes. Briser ce système reste difficile, car les scientifiques les plus réputés sont sollicités par les journaux les plus en vue, contribuant à reproduire ce modèle. D’autre part, les grands groupes éditoriaux contrôlent une part importante des outils de recherche, d’indexation et de mise en relation des articles scientifiques, renforçant encore la visibilité de leurs propres revues.
Par ailleurs, ces acteurs participent activement à la production d’une pseudoscience scientométrique, en proposant des évaluations quantitatives, comme les nombres de citations, les facteurs d’impacts, etc. Bien que les limites et les dérives de ces métriques aient été largement documentées, et malgré l’existence d’initiatives, comme DORA, appelant à une réforme de l’évaluation de la recherche, de nombreuses politiques publiques restent cantonnées à ces indicateurs pour évaluer la science (on privilégie la quantité d’articles à la qualité). Les carrières des chercheurs restent ainsi largement évaluées à travers le prestige supposé des revues dans lesquelles ils publient.
À l’heure où les grandes puissances mondiales sont tentées par des virages autoritaires et la promotion des faits « alternatifs », la science doit plus que jamais préserver son indépendance et maintenir la confiance du grand public. Dans un contexte de disette budgétaire, reprendre collectivement la maîtrise des infrastructures de publication scientifique de manière plus efficiente, moins onéreuse et plus durable apparaît comme un enjeu majeur pour la communauté scientifique.
Au-delà du monde académique, l’ouverture des connaissances bénéficie également au grand public, aux enseignants, aux associations, aux décideurs et au secteur privé, en facilitant l’accès aux avancées scientifiques les plus récentes. Enfin, rendre la science plus accessible ne signifie pas seulement diffuser davantage de savoirs : cela contribue aussi à renforcer la transparence, l’esprit critique et la capacité collective à débattre et à répondre aux défis actuels de manière informée et raisonnée.
Frédéric Schmidt est Professeur à l'Université Paris-Saclay, membre de l'Institut Universitaire de France (IUF). Il a obtenu divers financements publics (Université Paris-Saclay, CNRS, CNES, ANR, UE, ESA, France 2030) ainsi que des financements privés (Airbus) pour ses recherches. Il est éditeur scientifique du journal Planetary Research et membre fondateur de l'association Planetary Research Cooperative, l'association loi 1901 qui détient le journal.
Camille Thomas est co-fondateur et membre du comité de direction de Sedimentologika. Il a reçu des financements du fonds pour la recherche scientifique Suisse. Il travaille bénévolement comme manager éditorial pour Sedimentologika et est co-président de l'association loi 1901 qui détient le journal.
Romain Vaucher est co-fondateur et membre du comité de direction de Sedimentologika. Il travaille bénévolement comme manager éditorial pour Sedimentologika et est vice-président de l'association loi 1901 qui détient le journal.
30.06.2026 à 17:38
Intelligence artificielle générative et recherche académique : comment préserver éthique et intégrité scientifique
Nathalie Guichard, Professeur des Universités, Université Paris-Saclay
Agnès Helme-Guizon, Professeure des Universités, Marketing social, Grenoble IAE Graduate School of Management; Université Grenoble Alpes (UGA)
Anne-Sophie Cases, Professeur, laboratoire MRM Université de Montpellier, Université de Montpellier
Christelle Aubert Hassouni, Lecturer and researcher, specialist in consumer privacy issues, ESCP Business School
Jean-François Toti, Maître de conférences Sciences de Gestion - Marketing, Université de Lille
Texte intégral (1587 mots)
Pour les scientifiques, l’intelligence artificielle générative peut apparaître comme une option pour gagner du temps et augmenter leur productivité, mais ce n’est pas sans risques.
Lors de la pandémie de Covid-19, le refus de se faire vacciner résultait notamment du manque de confiance dans l’efficacité et la non-dangerosité du vaccin. Les climatosceptiques (32 % en France) continuent de nier la responsabilité des activités humaines dans le changement climatique. Ces deux exemples ont en commun la remise en question des apports de la science, menant au « scientoscepticisme ».
L’intégration de l’intelligence artificielle à tous les niveaux de la production scientifique pourrait venir renforcer ce sentiment dans la population. Une recherche intègre, éthique et responsable est une condition indispensable au maintien de la confiance des citoyens. Face aux bouleversements induits par l’intelligence artificielle générative (IAG) et en l’absence de règles clairement diffusées au sein de la communauté scientifique, les chercheurs en sciences humaines et sociales (SHS) s’interrogent sur l’évolution et l’éthique de leurs pratiques.
Dans un contexte très concurrentiel où la carrière des chercheurs dépend en grande partie de leur production scientifique, le recours à des outils d’IAG peut apparaître comme une option – pour un coût supposément minime (la plupart des outils sont gratuits et leur utilisation en apparence aisée) – pour augmenter leur propre productivité en s’appuyant sur les capacités de synthèse de vastes ensembles de données et d’écriture des IAG. Cette délégation peut sembler séduisante, mais comporte des risques importants.
Un double questionnement pour les chercheurs
La qualité de la production scientifique repose sur un système d’évaluation par des pairs (peer-review), le plus souvent anonyme. Dans un processus de publication, les chercheurs sont soit auteurs, soit évaluateurs, avec des problématiques quelque peu différentes.
Pour les auteurs, l’IAG est susceptible d’être mobilisée à différentes étapes du processus de la recherche (revue de littérature, collecte et analyse de données, rédaction…), ce qui interroge la notion même de propriété intellectuelle. Dans les SHS, où le processus de recherche est souvent itératif, interprétatif et sensible au contexte (en raison de son objet – la société et les relations entre les humains – et pour lequel des méthodologies qualitatives sont souvent mobilisées ; par exemple une analyse de discours de patients au fur et à mesure de l’adoption d’une solution en e-santé), le recours à l’IAG peut ainsi transformer en profondeur les pratiques de recherche. S’il peut aider les chercheurs, il soulève également une question centrale : à partir de quel moment ce soutien devient-il une délégation de l’acte scientifique lui-même ? Or, il est un principe de base, quelle que soit l’intervention de l’IAG dans la rédaction d’un article scientifique, seul le ou les auteurs humains seront in fine responsables du contenu produit. Dès lors, il devient urgent d’élaborer des directives explicites partagées, sur la façon de l’intégrer de manière responsable et de déclarer son usage de façon transparente.
Pour les évaluateurs, l’IAG peut être intégrée dans leur propre processus d’évaluation d’un article (peer-review). En effet, les évaluateurs peuvent être tentés d’y recourir pour produire leur évaluation (décrire/synthétiser l’article, identifier ses points forts ou faibles, rédiger certaines parties de leur rapport). L’IAG peut aussi avoir été utilisée par les auteurs de l’article, et c’est alors aux évaluateurs de le détecter et d’apprécier si cette utilisation respecte l’intégrité scientifique exigée par la revue scientifique.
Le recours à l’outil Problematic Paper Screener (PPS), créé par Guillaume Cabanac, a permis de détecter, à ce jour, 25 000 articles utilisant des « expressions torturées » laissant à penser à un usage d’algorithme pour leur rédaction, sans discernement ni relecture humaine.
Or, si de nombreuses revues ont aujourd’hui fixé des règles, les principes éthiques restent flous et les pratiques hétérogènes laissant les chercheurs dans l’incertitude.
Aussi, apparaît-il clairement dans les discours et débats des sociétés savantes, un réel besoin de dialoguer sur ces questions mais aussi une absence d’unanimité sur les options envisageables avec des perceptions éthiques divergentes.
Vers un appauvrissement de la pensée ?
Une étude récente publiée dans la revue Science montre que l’adoption des grands modèles de langage (LLM) par les chercheurs (toutes disciplines confondues) accroît leur productivité (plus de 89 %) et ouvre de nouvelles opportunités (simulation de populations virtuelles lorsque celles-ci sont difficilement accessibles ; synthèse rapide d’une somme d’articles de recherche) mais qu’elle diminue aussi la qualité de leurs travaux en raison de ses capacités limitées à appréhender des tâches complexes.
De plus, le recours à l’IAG pour acquérir des connaissances et rédiger fait courir un risque d’uniformisation de la pensée et des connaissances : son recours ayant tendance à cantonner les chercheurs aux champs déjà bien établis, réduisant par le fait même l’exploration scientifique « en dehors des sentiers battus ». Le chercheur, conscient de ces limites, peut tirer parti de l’utilisation d’une IAG en l’interrogeant de manière précise et pointue, sans se contenter de la première réponse et en vérifiant systématiquement les contenus produits.
L’utilisation de l’IAG pour l’évaluation des articles : un risque majeur pour la fiabilité de la recherche et son utilité pour la société ?
L’IAG représente un problème majeur en ce que les textes qu’elle génère sont, pour le moment, impossibles à différencier automatiquement de ceux produits par les humains. Aussi, à ce stade, deux principes doivent permettre de s’affranchir de cette limite.
Le chercheur doit être le seul garant de la qualité scientifique de la recherche : les chercheurs sont sollicités pour évaluer des articles précisément parce qu’ils sont experts du domaine scientifique considéré. Leur analyse doit donc théoriquement émaner de leur propre jugement, sans délégation à une IAG. C’est d’ailleurs ce que précisent les chartes éthiques ou les consignes de certains éditeurs de revues académiques (à l’instar d’Elsevier ou Sage) qui, à ce stade, interdisent aux évaluateurs de téléverser un article dans un outil d’IAG. Toutefois, si l’IAG devient un outil de support, quelles seront les limites à poser pour son utilisation ?
La confidentialité des données de la recherche devient un gage de la qualité des recherches futures : utiliser une IAG hébergée dans un cloud pour évaluer un article revient à prendre le risque d’exposer à tous des données confidentielles et potentiellement sensibles, ce qui est problématique, notamment, dans le cadre de l’évaluation d’un article scientifique. Il pourrait être envisagé d’utiliser une IAG installée en local non seulement pour préserver la confidentialité des données de recherche mais aussi pour éviter de nourrir l’IA avec des documents non validés scientifiquement. Il en va de la crédibilité des résultats de recherche et de la confiance du grand public dans le discours scientifique.
Le développement rapide des IAG dans la rédaction et l’évaluation d’articles scientifiques oblige d’une part à repenser notre rapport à la connaissance et à sa construction et, d’autre part, à réfléchir en profondeur à la façon de préserver les fondements éthiques de la production et de l’évaluation du savoir. Malgré de premières initiatives pertinentes, une réflexion collective, sociétale, interdisciplinaire et internationale apparaît indispensable pour articuler innovation technologique et responsabilité scientifique.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
28.06.2026 à 15:30
Clean beauty : comment une notion aussi floue est-elle devenue incontournable ?
Véronique Sadtler, Professeure, Université de Lorraine
Texte intégral (1663 mots)
Dans les rayons de cosmétiques, les promesses se multiplient : « naturel », « sans sulfate », « sans paraben », « 0 % silicone », « 95 % d’origine naturelle ». Ces mentions aujourd’hui omniprésentes sont devenues pour beaucoup de consommateurs des repères simples et rassurants face à des formulations souvent difficiles à décrypter. Mais que signifient-elles réellement ? Et comment une notion aussi floue que la « clean beauty » est-elle devenue en quelques années un argument majeur de l’industrie cosmétique ?
La question de l’exposition aux substances chimiques présentes dans les produits du quotidien fait régulièrement l’objet de travaux scientifiques. Une récente étude de l’Inserm a ainsi montré qu’une réduction temporaire de l’utilisation de certains produits cosmétiques et d’hygiène courants (shampooings, déodorants, dentifrices ou maquillage) pouvait entraîner une baisse mesurable de plusieurs polluants chimiques et perturbateurs endocriniens comme le bisphénol A.
Plus largement, les travaux consacrés aux perturbateurs endocriniens contribuent à alimenter les interrogations de la population sur les substances présentes dans les cosmétiques utilisés chaque jour. Les controverses régulièrement relayées dans les médias autour de certaines substances chimiques, ainsi que plusieurs procédures judiciaires récentes impliquant de grands groupes du secteur, entretiennent également ces débats dans l’espace public. Dans ce contexte, il n’est pas surprenant que la composition des produits soit devenue un critère de choix pour une part croissante des consommateurs.
C’est dans ce climat qu’a émergé la clean beauty. Apparue aux États-Unis dans les années 1990-2000 dans un contexte réglementaire beaucoup moins strict qu’en Europe, elle s’est progressivement diffusée à l’échelle mondiale. Les marques se sont à leur tour emparées de ces attentes, faisant de la clean beauty un argument central de communication. Cette tendance influence à présent l’ensemble du secteur cosmétique. Elle est souvent présentée comme l’une des grandes évolutions de l’industrie de la beauté au cours de la dernière décennie.
Cela témoigne d’un changement plus profond du rapport des consommateurs aux articles de soin et d’hygiène : au-delà de l’efficacité attendue, ils cherchent davantage à comprendre ce qu’ils utilisent au quotidien. Le succès de la clean beauty traduit ainsi un besoin croissant de réassurance. Face à des formulations complexes, beaucoup recherchent des repères plus simples pour guider leurs choix.
Une notion floue dans un secteur pourtant très réglementé
Mais derrière ce succès se cache un paradoxe. Contrairement aux labels ou certifications, la clean beauty ne repose sur aucune définition réglementaire harmonisée. Aucun texte européen ne définit ce qu’est une cosmétique « clean ». Chaque marque peut ainsi proposer sa propre interprétation : exclusion de certaines substances, limitation du nombre d’ingrédients, priorité donnée aux ingrédients d’origine naturelle ou encore mise en avant de procédés de fabrication particuliers.
Cette absence de définition contraste avec le niveau élevé de réglementation du secteur cosmétique européen. Les produits commercialisés en Europe font l’objet d’une évaluation de sécurité avant leur mise sur le marché. Plus de 1 300 substances y sont interdites et de nombreuses autres soumises à restriction.
On pourrait donc penser que ce cadre réglementaire répond déjà aux attentes d’un grand nombre de consommateurs. Malgré cela, les interrogations persistent. Les débats autour des perturbateurs endocriniens, des PFAS [13] ou de certaines substances classées CMR (cancérogènes, mutagènes ou toxiques pour la reproduction)) continuent d’alimenter les préoccupations de la population. Cette tension entre réglementation, perception du risque et attentes des utilisateurs apparaît également dans les débats récents autour du projet européen dit « Omnibus VI ». Présenté comme une simplification réglementaire, ce texte a suscité des inquiétudes chez plusieurs associations de consommateurs et organisations environnementales qui craignent un allongement des délais d’interdiction de certaines substances classées.
Quand la transparence ne suffit plus
On pourrait alors imaginer que la solution réside dans davantage d’informations. Après tout, la réglementation impose déjà une transparence importante. Tous les produits doivent afficher la liste complète de leurs ingrédients selon la nomenclature internationale INCI (International Nomenclature of Cosmetic Ingredients). La Direction générale de la concurrence, de la consommation et de la répression des fraudes (DGCCRF) rappelle régulièrement l’importance de lire l’étiquetage complet des cosmétiques et souligne que les allégations doivent être vérifiables.
Cependant, transparence ne signifie pas nécessairement compréhension. Paradoxalement, les utilisateurs n’ont probablement jamais eu autant d’informations à leur disposition. Toutefois, entre les listes INCI, les allégations marketing, les labels et les différentes définitions de la naturalité, il reste souvent difficile de s’y retrouver.
Pour répondre à cette difficulté, certaines marques complètent désormais la liste INCI par des explications simplifiées indiquant l’origine ou la fonction des ingrédients (« agent nettoyant », « conservateur », « issu d’huiles végétales », etc.). Malgré cette abondance d’informations, de nombreux consommateurs peinent encore à interpréter des termes comme « clean », « naturel » ou « sans… », faute de définition harmonisée.
De plus, la liste INCI renseigne sur l’identité des ingrédients mais rarement sur leur origine ou leur mode d’obtention. Ainsi, certains composés parfumants, comme la vanilline, peuvent être obtenus par extraction végétale, biotechnologie ou synthèse chimique, sans que cette origine apparaisse dans leur nom. La notion de naturalité elle-même peut prêter à confusion : certains tensioactifs utilisés dans les shampooings et gels douche, comme les glucosides, sont fabriqués à partir de sucres et d’huiles végétales mais nécessitent plusieurs étapes de transformation chimique avant d’être incorporés dans une formule. Autrement dit, « naturel » ne signifie pas nécessairement « non transformé ».
Face à cette complexité, les applications, les labels et les mentions « sans… » jouent un rôle de simplification. Certaines bases de données et associations de consommateurs recensent désormais plusieurs milliers de cosmétiques contenant des ingrédients considérés comme indésirables ou controversés, contribuant à renforcer la vigilance du public vis-à-vis de la composition de ce qu’ils utilisent. Le « clean » devient alors autant un signal de confiance et de lisibilité qu’une caractéristique objective du produit lui-même.
Une promesse de simplicité face à la réalité des formulations
Reste une question essentielle : cette recherche de simplicité se traduit-elle réellement par des formulations plus simples ? Le shampooing illustre bien cette évolution, où les mentions « sans sulfates » ou « sans silicone » se sont largement diffusées ces dernières années. Or, concevoir un shampooing suppose de concilier nettoyage, stabilité, conservation, texture, mousse et sensorialité. La suppression d’un ingrédient nécessite de rééquilibrer l’ensemble de la formule et parfois de reprendre une partie du développement. La longueur d’une liste d’ingrédients ne constitue donc pas, à elle seule, un indicateur pertinent de qualité.
Au fond, les consommateurs ne recherchent pas uniquement des produits jugés plus naturels ou plus sûrs. Ils cherchent aussi à mieux comprendre ce qu’ils utilisent. C’est sans doute ce qui explique le succès de la clean beauty auprès d’un public confronté à des formulations de plus en plus complexes à décrypter.
Pourtant, derrière une liste d’ingrédients raccourcie ou une promesse de naturalité se cache souvent la même réalité : un cosmétique doit continuer à remplir les fonctions attendues par l’utilisateur. La clean beauty apparaît ainsi moins comme une catégorie scientifique clairement définie que comme une réponse à une demande de lisibilité, de transparence et de réassurance.
Véronique Sadtler ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
27.06.2026 à 16:51
« Disclosure Day » : pourquoi la (potentielle) découverte d’une vie extraterrestre ne sera pas un blockbuster hollywoodien
Hervé Cottin, Astrochimiste, Professeur au Laboratoire Interuniversitaire des Systèmes Atmosphériques (LISA), Université Paris-Est Créteil Val de Marne (UPEC)
Texte intégral (3113 mots)

À moins qu’une soucoupe volante se pose devant la Maison-Blanche ou au pied de la tour Eiffel, il n’y aura pas de « jour de la révélation » hollywoodien proclamant la découverte d’une vie extraterrestre… Ce n’est pas ainsi que marche la science, et c’est tant mieux.
Dans son dernier film Disclosure Day, le réalisateur Steven Spielberg renoue avec une thématique qui lui est chère : la découverte de la vie extraterrestre. En règle générale, la vie extraterrestre décrite par Steven Spielberg est plutôt pacifique et curieuse à l’égard des humains. Rencontres du troisième type (1977) évoque la longue préparation à ce premier contact et l’invention d’un langage commun pour communiquer. Dans E.T. l’extraterrestre (1982), Spielberg inverse la dynamique de la menace avec un alien botaniste traqué par les humains – à rebours de l’archétype de l’envahisseur prédateur, présent par exemple dans la saga Alien inaugurée en 1979 par Ridley Scott.
Disclosure Day traite du « grand jour de la révélation, celui où nous apprenons que nous ne sommes pas seuls dans l’Univers ». Si, dans le film, l’existence d’extraterrestres est présentée comme un potentiel salut pour une humanité qui s’autodétruit, cette fiction est en phase avec une actualité bien réelle aux États-Unis, où le Congrès multiplie depuis 2022 les auditions officielles sur les phénomènes aérospatiaux non identifiés (PAN, le nouvel acronyme remplaçant celui d’ovni), tandis que le Pentagone alimente un site consacré aux photos, vidéos et témoignages d’observations de PAN. Ces documents, qui me semblent peu convaincants et ne constituent pas de preuve formelle, semblent avoir transformé la perception de Steven Spielberg, qui affirme croire aux témoignages sur la vie extraterrestre.
Avec ce film, la formidable machinerie hollywoodienne ranime un vieux fantasme collectif : celui de la révélation soudaine, globale et définitive de l’existence d’une vie extraterrestre.

{kind=link}
Pour quiconque pratique l’exobiologie, un domaine interdisciplinaire qui cherche à comprendre comment la vie est apparue sur Terre afin de mieux orienter notre stratégie pour la rechercher ailleurs, ce scénario d’une révélation soudaine et absolue relève de la pure commodité narrative. Il ne s’agit évidemment pas ici de faire une critique du film, que j’ai beaucoup apprécié à titre personnel, mais de rappeler que, dans la réalité scientifique, il n’y aura probablement pas de « Disclosure Day » : pas de consensus immédiat, pas de conférence de presse pour mettre un point final à l’angoisse de la solitude cosmique.
La quête du vivant ailleurs dans l’Univers est un chemin de patience extrême, qui est pavé de mesures d’anomalies et de controverses acharnées, et le restera.
Le mirage des « grands soirs » : de la météorite ALH 84001 à la phosphine vénusienne
L’histoire récente regorge déjà d’annonces où la communication institutionnelle a tenté de brûler les étapes.
Souvenons-nous de l’été 1996, lorsque le président des États-Unis Bill Clinton prit la parole pour annoncer que la météorite martienne ALH 84001 recelait de possibles traces de vie fossile. Le message était évidemment prudemment ciselé, ponctué d’appels à la prudence, mais l’impact médiatique fut planétaire. Puis, loin des caméras et des médias, au gré de contre-expertises et de publications contradictoires, les structures géochimiques observées furent expliquées par des processus ne nécessitant aucune activité biologique. L’annonce ne fut pas réfutée en un jour : elle s’est lentement dissoute dans le temps long d’un travail scientifique de longue haleine.
Un scénario relativement proche s’est reproduit en septembre 2020 avec l’affaire de la phosphine, une petite molécule de formule chimique PH₃, prétendument détectée dans l’atmosphère de Vénus. Une équipe annonçait, avec l’appui d’une publication scientifique, avoir mesuré la présence de ce gaz dans les nuages vénusiens à un niveau d’abondance inexplicable par les mécanismes géochimiques ou photochimiques connus, suggérant une possible activité biologique. Accompagnée d’un communiqué de presse titré « Indices de vie sur Vénus » et saluée par un tweet enthousiaste de l’administrateur de la Nasa de l’époque évoquant « la plus grande découverte » liée à la vie extraterrestre, la nouvelle a enflammé les médias. Dans la foulée, des financements privés ont même été annoncés pour lancer l’étude d’une mission spatiale spécifique.
Quelques années plus tard, que reste-t-il de cette annonce fracassante ? Des bases singulièrement fragiles : deux études indépendantes démontraient rapidement que la bande spectrale utilisée dans le domaine des ondes radio pour la détection n’était pas significative statistiquement, tandis que des observations complémentaires dans une autre gamme de longueur d’onde (infrarouge) ne confirmaient aucunement la présence de la molécule et abaissaient la limite supérieure de détection à un niveau 100 fois inférieur à ce qui avait été avancé. Le grand public, lui, est resté sur l’émerveillement du premier jour, ignorant que la controverse avait balayé l’hypothèse fantasmée d’une preuve de vie vénusienne.
Il n’est pas question ici de reprocher à une équipe scientifique de publier un résultat qu’elle estimait, en toute bonne foi, probablement pertinent. C’est d’ailleurs le principe de toute progression scientifique : un résultat nouveau, si surprenant soit-il, à partir du moment où il est étayé, reproductible, ou si les mêmes données peuvent être expertisées indépendamment (ce qui était le cas pour cet épisode vénusien), a vocation à être présenté à la communauté scientifique pour qu’il puisse être passé au crible des avis d’autres experts indépendants. Le communiqué de presse qui a été à l’origine de l’emballement médiatique était, par contre, probablement de trop…
L’« exobiowashing » et la tentation du « bling-bling » scientifique
Plus récemment encore, c’est l’exoplanète K2-18b qui a suscité beaucoup de bruit médiatique. En 2023, puis en 2026, une équipe scientifique, interprétant des mesures de composition atmosphérique de cette exoplanète par les télescopes spatiaux Hubble et James-Webb, a évoqué la présence de diméthylsulfure (DMS), une molécule qui, sur Terre, est fortement associée au vivant.
Les deux publications scientifiques sont à chaque fois légitimes, publiées dans des revues à comité de lecture, et soumises au débat contradictoire légitime quant à la validité ou non de la détection elle-même. À nouveau, la détection du DMS ne semble pas tenir la distance face à des contre-expertises indépendantes. De plus, quand bien même la molécule serait bel et bien détectée, d’autres processus que le vivant pourraient très bien en être à l’origine.

{kind=link}
Cependant, à chaque fois, le mécanisme est identique : ces publications sont accompagnées d’un communiqué de presse, parfois de vidéos autopromotionnelles pour le moins étonnantes. On assiste aujourd’hui à l’émergence de ce que l’on pourrait appeler l’« exobiowashing », un pendant spatial exobiologique du greenwashing. De même que l’écoblanchiment environnemental sert à valoriser l’image de marque d’une entité et à détourner l’attention de ses pratiques polluantes, l’exobiowashing utilise le vernis de la vie extraterrestre pour doper artificiellement l’attractivité d’une recherche.
L’idée derrière ce terme est que, dans un contexte académique hautement compétitif, ajouter une phrase ou deux suggérant que telle ou telle détection moléculaire fait progresser la quête de la vie extraterrestre est une assurance presque absolue de voir un projet de communiqué de presse accepté. Cela garantit une grande visibilité personnelle et institutionnelle, génère des titres accrocheurs et des clics sur les écrans de nos smartphones.
Cette stratégie pose un dilemme déontologique. La fin justifie-t-elle les moyens ? La science ne devrait-elle pas demeurer fermement ancrée dans les faits avérés, plutôt que dans la spéculation marketing ?
Le choc des temporalités : la science avance par le doute, et non par le sensationnel
Le véritable danger de cette accumulation d’annonces sensationnalistes réside dans le décalage abyssal entre la temporalité des médias et celle de la recherche.
Le public (dont je fais moi-même partie pour tout ce qui concerne les sujets extérieurs à mes domaines de recherche) consomme souvent l’actualité en scrollant rapidement, l’esprit traduisant rapidement le terme « habitable » par « habité ». On peut aussi confondre si facilement « matière organique » et « organisme vivant », tout comme on glisse sur une flaque d’eau liquide hypothétique à la surface d’une exoplanète lointaine pour l’associer à la promesse d’une forme de vie extraterrestre.
Le « Disclosure Day » aurait-il déjà eu lieu, infusé lentement à travers une succession de microfeux d’artifice médiatiques où rêves, fiction et science s’entremêlent dans une chasse au clic effrénée ? Si, dans l’esprit d’un grand nombre, la question de la vie extraterrestre est déjà réglée du fait de cette profusion d’annonces exagérées, comment pourrons-nous convaincre ce même public de la légitimité des dépenses futures indispensables pour construire les télescopes de nouvelle génération – ceux-là mêmes qui devront caractériser de manière rigoureuse la composition atmosphérique d’une exoplanète – ? Ou financer un retour d’échantillons martiens sur Terre (qui sera probablement indispensable pour savoir si la vie a un jour émergé sur notre voisine) ?
Pourtant, la communauté scientifique sait aussi faire preuve de retenue
Début 2022, la mesure par le rover de la Nasa Curiosity d’un déséquilibre isotopique intriguant du carbone 13 par rapport au carbone 12 dans le sol martien n’a donné lieu à aucune conférence de presse grandiloquente, alors que sur Terre des mesures équivalentes sont classiquement associées à la photosynthèse (c’est-à-dire la vie). Les doutes et les incertitudes de la recherche ont été partagés en bonne intelligence avec les médias. C’est cette rigueur qui s’était déjà imposée après les espoirs déçus des missions Viking dans les années 1970, dont les promesses de détection immédiate avaient fini par mettre en sommeil les programmes martiens pendant près de vingt ans.
L’exobiologie avancera, mais à son rythme. Elle s’appuie sur un postulat communément accepté mais non démontré : la vie pourrait surgir là où l’eau liquide, la matière organique et l’énergie coexistent. Démontrer, nuancer ou infirmer ce socle exige de croiser les expertises de géochimistes, géologues, chimistes, microbiologistes et d’astronomes… Une preuve de vie en dehors de la Terre ne prendra probablement jamais la forme d’un flash spécial d’information avec un signal indubitable. Elle se présentera sous la forme d’un faisceau d’indices ténus, d’une raie d’absorption contestée sur un spectre, d’une anomalie chimique que des analyses contradictoires mettront peut-être des décennies à valider ou à balayer.
À moins qu’une soucoupe volante se pose devant la Maison-Blanche, la tour Eiffel, la Cité interdite ou la pyramide de Gizeh, il n’y aura pas de « Disclosure Day » hollywoodien pour une annonce de découverte de vie extraterrestre, et c’est tant mieux. Le dialogue scientifique, avec ses disputes fécondes, ses doutes et ses réfutations, est infiniment plus passionnant que n’importe quel secret d’État éventé.
Sans renoncer à l’émerveillement des histoires extraordinaires sur grand écran, nous devons aussi apprendre à savourer le goût de la nuance scientifique plutôt que les illusions de la communication. C’est à ce prix que la science préservera sa crédibilité et que l’exploration de notre place dans l’univers restera une authentique aventure scientifique.
Pour en savoir plus sur l’exobiologie, Hervé Cottin a dirigé avec Muriel Gargaud la publication du Grand Livre de l’exobiologie, édité chez Belin Éducation (2025), et contribué à un site web pédagogique sur le sujet, avec d’autres spécialistes : AstrobioEducation.
Hervé Cottin est membre de la Société Française d'Exobiologie et préside la commission d'exobiologie de l'Union Astronomique Internationale. Ses recherches sont financées par le Centre national d'études spatiales (CNES), le CNRS, l'Agence nationale de la recherche (ANR), la région Île-de-France, la BPI ainsi que l'UPEC.
26.06.2026 à 14:53
Si l’IA générative favorise l’addiction, qui doit rendre des comptes ?
Bernd Stahl, Professor of Critical Research in Technology, School of Computer Science, University of Nottingham
Texte intégral (1657 mots)
Les appels à la modération individuelle ne suffiront peut-être pas. Face aux risques d’usage compulsif de l’IA générative, chercheurs, régulateurs, entreprises et société civile pourraient devoir agir de concert.
Lorsque je discute avec mon fils, élève ingénieur, et qu’une question ou un désaccord surgit, son premier réflexe est de se tourner vers ChatGPT pour obtenir une information ou confirmer ce qu’il pense.
Il est loin d’être le seul. L’usage des outils d’IA générative s’est généralisé dans de nombreux groupes de population. Pour beaucoup, ces outils sont divertissants, instructifs et utiles. Mais ils ont aussi leur face sombre.
À ce jour, l’IA générative n’est pas officiellement reconnue comme une addiction : les preuves médicales sont encore en cours d’évaluation. Mais un nombre important d’études montre qu’un usage intensif des chatbots et d’autres systèmes capables de produire du texte, des images ou des vidéos entraîne des modifications de l’activité cérébrale et des comportements associés aux mécanismes de l’addiction.
À la lumière de la condamnation récente de Meta et de YouTube dans un procès historique portant sur l’addiction aux réseaux sociaux, il est légitime de se demander si un raisonnement similaire ne devrait pas s’appliquer à l’IA générative – et comment y répondre. La première étape consiste à déterminer qui porte la responsabilité de son usage excessif.
Le débat scientifique est loin d’être tranché et certains appellent à la prudence avant d’employer le terme d’« addiction ». Ils préfèrent parler d’« usage problématique ». Toutefois, dans un récent article scientifique, notre équipe de recherche montre que de nombreux éléments indiquent que l’IA générative possède des propriétés susceptibles de favoriser des comportements addictifs.
Parmi les exemples les plus souvent cités figurent la dépendance affective envers des compagnons conversationnels, l’engagement compulsif dans les échanges avec ces outils, ainsi que l’affaiblissement des relations et des amitiés dans le monde réel.
Un élément essentiel est que, comme pour toute addiction, ce comportement entraîne des conséquences négatives pour la personne concernée, susceptibles d’affecter aussi bien sa vie personnelle que sa vie professionnelle.
Si l’on considère que l’IA générative est susceptible de provoquer des comportements addictifs, il faut alors s’interroger sur les responsabilités. Face à un phénomène préjudiciable, les sociétés cherchent généralement à identifier les personnes ou les organisations chargées d’y répondre. Les acteurs susceptibles d’être tenus responsables sont notamment les législateurs, les autorités de régulation, les entreprises du secteur et les systèmes de santé.
Des précédents historiques
Des précédents historiques, comme celui du tabagisme, peuvent éclairer la manière dont la question de l’addiction à l’IA générative pourrait évoluer.
Les lecteurs les plus âgés se souviennent peut-être de l’époque où le cow-boy Marlboro apparaissait à l’écran avant les séances de cinéma. On a fini par découvrir que non seulement le tabac était addictif et nocif pour la santé, mais aussi que les fabricants de cigarettes en avaient connaissance. Pourtant, ils l’ont publiquement nié.
Cette situation a donné lieu à des procédures judiciaires longues et très médiatisées, qui se sont soldées par d’importantes indemnisations financières ainsi que par de profondes réformes du secteur. Parmi elles figurent l’introduction des paquets de cigarettes neutres et l’apposition de messages d’avertissement particulièrement explicites sur les produits du tabac.
Les jeux d’argent semblent aujourd’hui suivre une trajectoire comparable. Quant aux réseaux sociaux, ils pourraient être en train d’entrer, eux aussi, dans une phase similaire.
Une question centrale est de savoir si les fabricants d’un produit (qu’il s’agisse du tabac, des jeux d’argent ou des réseaux sociaux) ont connaissance de son potentiel addictif. Une autre interrogation importante est de déterminer si certaines entreprises exploitent délibérément les propriétés potentiellement addictives de leurs produits pour en tirer un avantage commercial. L’IA n’est évidemment pas le tabac, mais ces précédents offrent des parallèles qui méritent d’être étudiés.
Dans nos travaux, nous avons identifié quatre catégories d’acteurs aujourd’hui appelées à répondre aux défis que pose la possibilité d’une addiction à l’IA générative. Le premier groupe est celui des gouvernements et des autorités de régulation. Ils ont un rôle essentiel à jouer pour mettre en lumière les problèmes, définir les règles du jeu et créer des incitations afin que les autres acteurs s’emparent eux aussi de cette question.
Ils disposent pour cela de nombreux leviers : imposer un étiquetage, encadrer la publicité, engager la responsabilité juridique des entreprises, financer la recherche, ainsi que de nombreuses autres mesures. Mais les acteurs les plus déterminants pour répondre aux comportements potentiellement addictifs liés à l’IA générative sont sans doute les grandes entreprises technologiques qui développent et possèdent ces technologies – et qui en tirent des bénéfices financiers.
Ces entreprises détiennent et ont accès aux données des utilisateurs, indispensables pour identifier les fonctionnalités qui favorisent ou, au contraire, limitent les comportements addictifs. Ce sont également elles qui peuvent tirer un avantage financier d’une éventuelle addiction, en augmentant le nombre d’utilisateurs et le temps qu’ils consacrent à leurs services, deux ressources essentielles de l’économie numérique.
Aux côtés de ces deux premiers groupes, les chercheurs ont un rôle crucial à jouer. Ils sont chargés de recueillir et d’interpréter les données, ainsi que de produire les preuves scientifiques nécessaires pour identifier les phénomènes d’addiction et les caractéristiques qui les favorisent, afin d’alimenter un débat politique et juridique fondé sur des éléments factuels.
Enfin, les organisations de la société civile, comme les associations d’usagers ou de patients, peuvent contribuer en apportant un soutien aux personnes concernées, en défendant leurs intérêts et en mettant en place des dispositifs d’alerte précoce. L’enjeu est que nul ne peut relever ce défi seul. Tous ces acteurs devront travailler ensemble.
Le problème, c’est toujours celui des autres
Aujourd’hui, l’un des principaux obstacles est l’absence d’un véritable débat structuré sur les responsabilités : chacun considère que le problème relève de quelqu’un d’autre. Pourtant, de nombreux précédents montrent qu’il est possible d’obtenir une mobilisation plus forte de l’ensemble des acteurs concernés.
Dans le cas du tabac, l’Organisation mondiale de la santé (OMS) a mis en place la Convention-cadre pour la lutte antitabac, un traité international réunissant gouvernements, autorités de santé publique, chercheurs et organisations de la société civile afin d’évaluer les preuves scientifiques et d’élaborer des règles communes. De la même manière, l’International AI Safety Report montre que des initiatives internationales visant à construire un consensus existent déjà sur d’autres enjeux liés à l’IA.
Une part de responsabilité incombe également aux utilisateurs de l’IA, qui doivent s’efforcer d’éviter ou de maîtriser les comportements susceptibles de leur être préjudiciables. Mais l’expérience acquise avec d’autres formes d’addiction montre que les appels à la modération ou à la vigilance individuelle ne suffisent pas.
Si les effets nocifs du tabac ou de l’abus d’alcool sont aujourd’hui bien connus, nos sociétés continuent de s’appuyer sur des limites d’âge, des règles d’étiquetage et des restrictions publicitaires. L’IA générative est en train de s’intégrer au tissu même de notre quotidien. Les décisions que nous prenons aujourd’hui façonneront ce qui sera considéré comme un usage acceptable pour les années à venir.
Bernd Stahl ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.06.2026 à 14:28
Feux de forêt, mégafeux : comment mieux prévoir leur propagation et limiter les risques ?
Marcos Rodrigues Mimbrero, Profesor Titular en Análisis Geográfico Regional, Universidad de Zaragoza; AXA Research Fund
Jorge Félez Bernal, Assistant researcher, Universidad de Concepción
Texte intégral (2058 mots)

L’ampleur des dégâts causés par les feux de forêt ne cesse de s’aggraver à l’échelle mondiale. Les incendies dangereux sont plus intenses et plus fréquents, alimentés à la fois par le changement climatique et par l’empreinte humaine sur les paysages – dont on parle moins, mais qui est également très importante.
Pour prévenir les dégâts, il faut pouvoir évaluer précisément les risques, notamment les trajectoires et l’évolution des mégafeux.
Les données mettent en évidence une tendance claire : nous sommes confrontés à des feux de forêt de plus en plus dévastateurs qui provoquent des catastrophes d’une ampleur jusqu’alors inconnue. Selon l’Agence européenne pour l’environnement, 3 770 kilomètres carrés de terres brûlent en moyenne en Europe, chaque année, et 45 000 personnes ont été déplacées à cause des feux de forêt entre 2008 et 2023. Ceci entraîne des pertes annuelles estimées à 2,5 milliards d’euros dans l’Union européenne.
Au cours de l’été 2025, l’Europe a connu les incendies de forêt les plus violents de ces deux dernières décennies en termes de superficie brûlée. Des incendies violents sur la péninsule ibérique ont ravagé 6 720 kilomètres carrés de terres, faisant le triste bilan de huit victimes.
À lire aussi : Mégafeux : Sommes-nous entrés dans une nouvelle ère ?
À l’autre bout du globe, le Chili a également connu des incendies stupéfiants, qui ont entraîné des catastrophes particulièrement douloureuses. En février 2024, l’incendie de Valparaíso-Viña del Mar a coûté la vie à 136 personnes et détruit près de 7 000 habitations. De même, en janvier dernier, à Concepción–Penco, un autre incendie a tué 21 personnes et rasé plus de 2 000 habitations.
La « pyrogéographie », où comprendre le comportement des feux à différentes échelles spatiales et temporelles
Il est essentiel de comprendre le potentiel de ces incendies à dévaster les communautés et les écosystèmes. Par conséquent, les recherches récentes en pyrogéographie se concentrent sur l’analyse du comportement du feu à différentes échelles spatiales et temporelles.
Dans ce contexte, deux approches technologiques sont particulièrement efficaces pour évaluer les impacts des incendies. En premier lieu, la télédétection (imagerie satellite, capteurs thermiques, plateformes aériennes), qui est essentielle pour reconstituer les impacts passés, pour la détection précoce et la surveillance en temps réel des feux en cours. Ensuite, les outils de simulation et de prévision, qui nous permettent d’identifier les configurations du paysage favorisant l’embrasement et la propagation du feu, et de comprendre la complexité des feux de forêt.
L’idée est d’utiliser ces connaissances pour participer à l’aménagement du territoire, afin de faire face aux risques croissants de feux de forêt et de mégafeux qui menacent nos communautés.
La télédétection pour cartographier les traces laissées par les feux de forêt passés
Pour quantifier l’ampleur de ces événements, nous exploitons l’imagerie satellite et des outils analytiques avancés afin d’évaluer deux variables principales : l’intensité et la sévérité des mégafeux.
L’intensité mesure la puissance du feu, c’est-à-dire le taux de libération d’énergie pendant la combustion, et aide à localiser les points chauds thermiques.
La sévérité évalue les conséquences : les dégâts matériels laissés dans le sillage de l’incendie.
En analysant des bandes spectrales spécifiques, nous pouvons par exemple quantifier la chute drastique de la productivité végétale, mesurant ainsi efficacement les difficultés de l’écosystème à se régénérer.
Les récents incendies de Barroca Grande (Portugal, août 2025) et des Trinitarias (Chili, janvier 2026) sont de bons exemples.
En combinant les données thermiques FIRMS de la Nasa et les images Copernicus Sentinel-3 de l’Agence spatiale européenne (ESA), nous pouvons visualiser la crise des incendies à la fois dans l’espace et dans le temps. Ces images révèlent une réalité stupéfiante : des panaches de fumée s’étendant sur des centaines de kilomètres dans l’atmosphère.
Les données d’intensité révèlent que plus de 95 % de la superficie totale finalement touchée a brûlé en une seule journée au Chili, le 18 janvier. C’est la définition même d’un « comportement explosif du feu » : des événements si rapides qu’ils dépassent les capacités des efforts traditionnels de lutte contre les incendies.
Au-delà de la chaleur immédiate, notre analyse de la sévérité fournit des indicateurs essentiels aux efforts de reconstruction. Au Portugal, 57 782 hectares ont été calcinés.
En recoupant ces niveaux de dégâts avec les types de combustibles, les conditions météorologiques locales et la topographie, nous pouvons concevoir des plans de restauration écologique précis et aider le secteur agricole à se reconstruire d’une manière qui, espérons-le, sera plus résiliente face aux futurs incendies.
Modélisation du comportement du feu et évaluation des risques
Dans le domaine de l’évaluation et de la gestion des risques d’incendie, deux stratégies prédominent.
La plus courante repose sur des évaluations à court terme : les indices quotidiens de risque d’incendie que l’on voit aux informations combinent les dangers météorologiques actuels et la vulnérabilité locale. C’est, par exemple, le principe de base du Système européen d’information sur les incendies de forêt (EFFIS).
À lire aussi : Un méga-incendie en Méditerranée, est-ce possible ?
À l’autre extrémité du spectre se trouve un outil plus stratégique appelé « simulation quantitative ». Plutôt que de se concentrer sur ce qui pourrait se passer demain (ou ce qui se passe actuellement), cette approche utilise des techniques de modélisation avancées pour orienter la planification à long terme et l’atténuation des risques.
Pour anticiper les effets possibles de saisons plus chaudes et plus sèches, ainsi que ceux de la transformation des paysages (par exemple, l’abandon des terres), nous évaluons l’exposition aux mégafeux en combinant la modélisation empirique (qui tire les leçons des feux qui se sont réellement produits dans l’histoire et de leur comportement) et la modélisation stochastique (qui utilise des algorithmes complexes pour simuler des milliers de scénarios hypothétiques).
Concrètement, nous étudions les incendies passés pour évaluer dans quelle mesure un paysage est susceptible de favoriser ou de freiner de futurs incendies, et déterminer dans quelle mesure nous y sommes potentiellement exposés, ou à quel point nous sommes menacés par ceux-ci. Pour quantifier cette exposition, nous identifions d’abord les facteurs spécifiques à l’origine des départs de feu : d’origine humaine ou naturelle. Ensuite, nous déclenchons des milliers d’incendies théoriques sur un « jumeau numérique » du paysage.
Nous exécutons ces simulations sous divers scénarios climatiques afin de générer des schémas réalistes d’exposition aux incendies. Il en résulte un ensemble d’indicateurs clairs et exploitables, qui nous indiquent non seulement où un incendie est susceptible de se déclarer, mais aussi quelle sera sa virulence.
Cette transition d’une approche réactive à une approche proactive nous permet de mettre en œuvre des stratégies plus efficaces. Qu’il s’agisse de réorganiser les combustibles forestiers, de mettre à jour les codes de construction urbains ou de concevoir des quartiers résistants au feu, ces décisions s’appuient sur des données.
En quoi cela aide-t-il en cas d’urgence ?
Le véritable test de ces technologies a lieu lors d’une situation d’urgence. Dans un contexte opérationnel, la modélisation de la propagation des incendies passe d’une planification stratégique à une course contre la montre.
Le programme WIFIRE de l’Université de Californie à San Diego, par exemple, fournit des informations en temps réel aux équipes d’intervention en cas d’incendie de forêt.
En intégrant des données satellitaires en temps quasi réel à des prévisions météorologiques de haute résolution, les chercheurs peuvent générer des projections qui prédisent la trajectoire d’un incendie dans les heures à venir.
L’un des outils les plus efficaces dans le cadre d’une évacuation opérationnelle est l’utilisation d’« isochrones » – des courbes de niveau sur une carte qui représentent l’heure d’arrivée prévue du feu (par exemple, 30, 60 ou 90 minutes à partir de la position actuelle).
La superposition de ces courbes de niveau sur des points de déclenchement (crêtes, routes ou repères spécifiques) permet aux responsables des services d’urgence d’automatiser le processus décisionnel.
Le mécénat scientifique d’AXA fait désormais partie du Fonds Axa pour le progrès humain, qui regroupe les engagements philanthropiques du Groupe et des mutuelles d’assurance Axa dans les domaines de la science, de la nature, de la solidarité et de la culture. Avant 2025, ce mécénat scientifique global était assuré par le Fonds Axa pour la recherche, qui a soutenu plus de 750 projets à travers le monde depuis sa création en 2007. Pour en savoir plus, rendez-vous sur Fonds Axa pour le progrès humain.
Marcos Rodrigues Mimbrero a reçu des financements du Ministerio de Ciencia, Innovación y Univesidades, de l'Agencia Estatal de Investigación et du Fonds Axa pour le progrès humain.
Jorge Félez Bernal a reçu des financements du Fonds Axa pour le progrès humain.
24.06.2026 à 11:23
Vous perdez vos mots ? C’est tout à fait normal !
Monica Baciu, Professeur Neurosciences Cognitives, Université Grenoble Alpes (UGA)
Clément Guichet, Chercheur postdoctoral, Université Grenoble Alpes (UGA)
Texte intégral (1589 mots)
« Comment ça s’appelle déjà ? » Le mot est là. On le sent à notre portée, presque accessible, « sur le bout de la langue », mais impossible de le prononcer immédiatement. Alors on contourne, on reformule, on attend quelques secondes. Puis, souvent, le mot revient. Ce phénomène, très courant à partir du milieu de la vie, est généralement perçu comme un signe inquiétant du vieillissement. Pourtant, nos recherches en neurosciences cognitives racontent une histoire bien plus nuancée, et surtout bien moins pessimiste.
Depuis plusieurs années, nos travaux étudient la manière dont le cerveau vieillit et réorganise ses fonctions de langage. Les résultats obtenus depuis 2021 montrent que les difficultés à retrouver ses mots ne traduisent pas nécessairement un déclin global de la mémoire ou de l’intelligence. Elles reflètent surtout une transformation progressive des stratégies utilisées par le cerveau pour accéder au langage.
Contrairement aux idées reçues, les mots ne disparaissent pas de notre mémoire avec l’âge. Les connaissances restent globalement très solides, et le vocabulaire continue même souvent de s’enrichir grâce à l’expérience accumulée au fil des années. Ce qui change davantage, c’est la rapidité avec laquelle le cerveau accède à ces connaissances.
Retrouvez notre vidéo basée sur cet article
Parler est une action extrêmement sophistiquée
Pour comprendre ce phénomène, il faut rappeler que parler est une opération extrêmement sophistiquée. Lorsque nous produisons un mot, le cerveau doit d’abord activer son sens, par exemple l’idée d’un objet, d’une personne ou d’une action, puis retrouver sa forme sonore avant de préparer son articulation.
Dans nos travaux récents sur le vieillissement du langage, nous distinguons notamment deux dimensions essentielles. La première est la dimension sémantique, c’est-à-dire le sens des mots, les connaissances et les associations construites par l’expérience. La seconde est la dimension phonologique, qui correspond aux sons permettant de prononcer les mots. Par exemple, lorsque vous prononcez le mot « chat », vous récupérez d’abord sa représentation mentale en mémoire, puis vous transformez cette représentation en une série de sons qui rend possible son articulation.
Avec l’âge, les systèmes liés au sens restent particulièrement robustes. En revanche, l’accès à la forme sonore exacte des mots devient parfois moins fluide, car plus vulnérable aux effets de l’âge. En somme, le cerveau retrouve bien l’idée du mot, mais sa récupération phonologique nécessite une mobilisation accrue des ressources cognitives. C’est précisément ce qui produit l’impression du « mot sur le bout de la langue ».
De nouvelles stratégies
Nos recherches menées depuis 2021 montrent cependant que le cerveau ne subit pas passivement ces changements. Il développe au contraire de nouvelles stratégies d’adaptation.
À mesure que les traitements rapides fondés sur les sons des mots deviennent moins efficaces, le cerveau s’appuie davantage sur les connaissances sémantiques, le contexte et l’expérience accumulée. Les mécanismes phonologiques et sémantiques ne sont pas mutuellement exclusifs et continuent de fonctionner en interaction. Toutefois, les modifications cérébrales associées au vieillissement sain semblent progressivement accroître la contribution des systèmes sémantiques, qui participent alors à la compensation des fragilités phonologiques.
Autrement dit, lorsque l’accès direct à un mot devient plus difficile, le cerveau compense en mobilisant davantage le sens et les associations d’idées. Cette réorganisation s’accompagne également d’une implication plus importante de systèmes liés à l’attention et aux organes de sens qui aident à sélectionner l’information pertinente.
Nos travaux plus récents montrent que ces adaptations ne concernent pas uniquement le langage lui-même. Elles reflètent une réorganisation plus interactive du fonctionnement cérébral au cours du vieillissement qui impacte notamment la mémoire et l’attention.
À partir d’environ 55 ans, nous observons des modifications progressives dans les réseaux cérébraux impliqués dans le langage et la communication. Cette réorganisation se manifeste également à l’échelle des réseaux cérébraux. Des travaux récents en magnétoencéphalographie (MEG) suggèrent notamment qu’il tend à regrouper davantage les représentations sémantiques en unités plus larges et plus stables en les associant à des représentations visuelles ou motrices. Pour reprendre notre exemple, le traitement du mot « chat », de sa récupération en mémoire à son articulation, serait davantage médié par l’image, le son ou le mouvement, pour faciliter le langage.
Nos recherches, menées ces trois dernières années, suggèrent également que ces changements répondent à une logique énergétique plus générale du cerveau. Avec le vieillissement, certaines connexions cérébrales longues et coûteuses, comme celles du système phonologique, deviennent plus vulnérables. En réponse, le cerveau tend à privilégier des circuits plus locaux, plus économes en énergie, des critères auxquels semblent répondre les systèmes liés au sens et à l’expérience.
Le vieillissement cérébral apparaît ainsi moins comme une dégradation brutale que comme une recherche permanente d’équilibre entre efficacité de traitement et économie d’énergie.
La réserve cognitive
Il est également important de souligner que cette évolution varie fortement d’un individu à l’autre. Certaines personnes conservent une grande fluidité verbale très tard dans la vie, tandis que d’autres présentent des difficultés plus précoces. Une partie de ces différences est liée à ce que les neurosciences appellent la réserve cognitive.
La réserve cognitive correspond à la capacité du cerveau à s’adapter aux changements et à mobiliser des stratégies alternatives. Elle est influencée par de nombreux facteurs comme le niveau d’éducation, les activités intellectuelles, les interactions sociales, l’activité physique ou encore le multilinguisme. Plus cette réserve est importante, plus le cerveau semble capable de compenser les effets du vieillissement.
C’est précisément cette diversité de trajectoires individuelles que nous étudions aujourd’hui afin de mieux comprendre pourquoi certains cerveaux restent particulièrement adaptatifs avec l’âge et d’identifier plus précocement les trajectoires de vulnérabilité grâce à l’intelligence artificielle et à l’analyse des réseaux cérébraux.
Ces travaux participent à une transformation plus large de la manière d’aborder la santé cérébrale. Aujourd’hui, les recherches visent de plus en plus à détecter les premiers signes de fragilité avant l’apparition de troubles cognitifs plus importants. Par exemple, l’augmentation des sensations de « mot sur le bout de la langue » précède des difficultés cognitives mesurables dans d’autres domaines cognitifs. C’est dans ce contexte qu’émergent les centres de santé du cerveau, qui développent des approches de prévention fondées sur l’identification précoce des individus qui pourraient ressentir des ralentissements de leurs compétences cognitives, mais sans que les mesures objectives montrent de déficit de ces fonctions.
En conclusion, lors du vieillissement cognitif sain, le mot finit presque toujours par revenir. Et lorsqu’il tarde un peu, cela ne signifie pas forcément que le cerveau perd ses capacités. Cela peut simplement indiquer qu’il est en train de modifier ses stratégies pour continuer à fonctionner autrement.
Monica Baciu a reçu des financements de l'ANR et du CNRS (programmes Défi 80|PRIME 2022).
Clément Guichet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
24.06.2026 à 11:23
La Chine, épicentre industriel et scientifique de l’énergie solaire
Laëtitia Guilhot, Maître de conférences HDR en sciences économiques, Université Grenoble Alpes (UGA)
André Meunié, Enseignant-chercheur en économie du développement et de l'environnement, Université de Bordeaux
Guillaume Wantz, Professeur des Universités, Université de Bordeaux
Marina Flamand, Chercheuse en économie de l'innovation, Université de Bordeaux
Pierre Berthaud, Maître de conférences HDR en économie, Université Grenoble Alpes (UGA)
Texte intégral (2353 mots)
Il n’y a pas si longtemps, la Chine était vue comme l’« usine du monde », le pays où les industries européennes étaient délocalisées. Petit à petit, son statut change. Un des secteurs emblématiques est celui de l’énergie solaire photovoltaïque, où l’étape du rattrapage industriel est révolue. Aujourd’hui, la Chine est aussi une usine à innovations.
En 2024, la Chine s’est imposée comme le premier investisseur mondial en recherche et développement (R&D), avec 27,4 % des dépenses totales contre seulement 4 % en 2000. Cette dynamique lui permet de consolider sa position de leader mondial dans un nombre croissant de « technologies critiques », en particulier dans le secteur des panneaux solaires photovoltaïques, où elle atteint 80 % de la production mondiale.
Grâce à une stratégie évolutive et une implication forte et efficace de l’État, la Chine a largement dépassé le stade d’« usine du monde » pour devenir à la fois le leader industriel, technologique et scientifique dans le secteur du solaire photovoltaïque (PV).
À lire aussi : La politique spatiale de la Chine déjoue-t-elle le narratif imposé par les Etats-Unis ? Une conversation avec Isabelle Sourbès-Verger
L’enjeu pour l’Europe et les États-Unis est dorénavant de ne pas accumuler un retard irrattrapable dans la course à l’innovation, dans ce secteur clé pour la décarbonation de nos économies.
Une domination mondiale de la production
Il n’a pas fallu plus de dix ans à la Chine pour littéralement évincer du marché des panneaux solaires les trois puissances de la fin du XXᵉ siècle : Europe, États-Unis, Japon. En 2002, les parts de marché globales de ces trois puissances étaient d’environ 80 % et celle de la Chine marginale. En 2012, la tendance était déjà inversée, avec 70 % pour la Chine et moins de 10 % pour les trois anciennes puissances solaires.
Depuis, les positions chinoises se sont encore renforcées dans l’ensemble des segments de la chaîne de valeur.
Dotée d’un savoir-faire indiscutable en matière de production de masse, elle s’est concentrée durant la décennie 2000 sur le développement de ses capacités industrielles dans les segments à fort potentiel (wafer, cellules et modules) ; puis, dans les années 2010, sur celui du silicium où sa dépendance extérieure était initialement la plus forte, en facilitant les transferts de technologies étrangères et en recourant à un soutien public massif.
Ainsi, la percée des entreprises chinoises se manifeste aujourd’hui sur les cinq segments de la chaîne de valeur : silicium, lingot, wafer, cellules et panneaux.

Cette position industrielle lui a permis de cibler d’abord la demande occidentale, mais la baisse des subventions sur ces marchés après 2010 a poussé le gouvernement chinois à renforcer la croissance de la demande intérieure, en s’appuyant sur des interventions publiques fortes et ciblées notamment à travers son système de planification et, à partir de 2015, une réforme du marché de l’électricité très favorable aux énergies renouvelables.
Au milieu des années 2010, cependant, des surcapacités de production importantes amènent les autorités publiques chinoises à inciter les firmes nationales à élargir leurs débouchés internationaux en direction des pays en développement, en particulier vers les marchés émergents, notamment le continent africain. Il faut bien noter que cette nouvelle stratégie s’est avérée pertinente grâce à une baisse drastique des coûts du kilowatt-heure photovoltaïque.
En rendant accessible cette énergie aux pays en développement pour répondre à leurs immenses besoins en énergie, la Chine a renforcé son image de puissance responsable.
Par sa capacité à satisfaire la demande nationale et mondiale de panneaux solaires, la Chine contribue ainsi à la transition énergétique et à la décarbonation de l’électricité. En 2024, la puissance du parc installé en Chine a atteint 1 048,5 gigawatts-crête, soit 46,7 % de l’ensemble des capacités installées dans le monde (le watt-crête désigne la puissance nominale d’une installation photovoltaïque dans des conditions optimales d’ensoleillement et de température).
À lire aussi : TW, kWh, mAh… Quelle est la différence entre énergie et puissance ?
Cependant, on peut toujours s’interroger sur la capacité de la Chine à devenir leader sur des technologies de pointe. Est-elle encore l’atelier du monde dans le photovoltaïque comme ailleurs ou bien a-t-elle, aujourd’hui, généré une capacité à se placer à l’avant-garde de la recherche et de l’innovation ?
La Chine a acquis le leadership technologique
Quatre catégories de technologies solaires photovoltaïques se distinguent, suivant les matériaux utilisés :
le silicium cristallin, qui compte à lui seul pour plus de 97 % du marché total en 2024, avec un rendement de conversion énergétique dépassant les 20 % pour les modules solaires industriels ;
les couches minces – principalement à base de tellurure de cadmium (CdTe), de cuivre, indium, gallium et sélénium (CIGS) ou de silicium amorphe –, qui couvrent 2,2 % du marché total en 2024, avec un rendement plus faible et des usages plus spécifiques ouvrant la voie vers des modules solaires flexibles, légers et performants sous faible éclairement ;
les cellules « émergentes » à colorants, à base de pérovskite hybride et les cellules organiques : aucune n’est encore présente en masse sur le marché ; mais elles sont néanmoins porteuses de promesses en matière de réduction de l’impact environnemental de la production solaire ;
les multijonctions, très performantes, mais encore très coûteuses sont souvent réservées aux applications militaires et spatiales.
Pour ces quatre catégories, la Chine domine quantitativement et qualitativement sur les dépôts de demandes de brevets. Ainsi, entre 1990 et 2022, 40 % des inventions brevetées sont chinoises, sur 57 000 au total. L’effort d’innovation se concentre, en Chine comme ailleurs, sur les cellules émergentes (un peu plus de 28 000 brevets, dont environ 40 % pour la Chine), puis sur la cellule solaire conventionnelle en silicium cristallin de première génération, ou c-Si (près de 20 000, dont environ 50 % pour la Chine).
De plus, la Chine est en tête des citations de brevets pour les cellules c-Si et émergentes : à la fois dans le top 10 % (le seuil caractérisant des inventions « majeures ») et dans le top 1 % (seuil des innovations « de rupture »).
Cette progression rapide et durable de la Chine sur les brevets touchant aux technologies déjà exploitées industriellement permet de conclure que le learning by doing a été le principal moteur de la construction de la prééminence chinoise.
Le photovoltaïque est en effet un secteur où le taux d’apprentissage (baisse du coût pour chaque doublement de la capacité à technologie donnée) est reconnu parmi les plus élevés (de 20 à 30 %, selon une estimation de l’Agence internationale de l’énergie, 2020) et donc parmi les plus propices aux gains d’échelle et de compétitivité pour les firmes et les pays se positionnant sur des technologies bien maîtrisées.
La domination de la Chine se confirme aussi pour les technologies émergentes
La Chine s’impose ainsi comme le premier pôle scientifique mondial dans la recherche sur le solaire de prochaine génération.
Une analyse bibliométrique de la production scientifique dans des revues à comité de lecture sur les segments les plus en pointe – à savoir les cellules solaires émergentes – offre un aperçu de l’effectivité et de la pérennité de la puissance scientifique chinoise. En effet, ces technologies ont le potentiel de briser le quasi-monopole actuel du silicium cristallin, en raison de leurs promesses d’efficacité énergétique, de coûts de production et d’impacts environnementaux plus faibles grâce à des procédés de dépôts peu énergivores et par impression grande surface.
Ainsi, la Chine a réalisé en 2023 plus de 50 % de la production scientifique sur les pérovskites hybrides (la technologie émergente la plus dynamique depuis 2012) et 55 % pour le photovoltaïque organique. Les cellules solaires à colorant connaissent un déclin relatif depuis 2014. La Chine y avait atteint un pic de publications, avant d’être dépassée par l’Inde en 2021 – un recul qui s’explique principalement par le report des efforts de recherche vers les pérovskites hybrides.
Dans le domaine du photovoltaïque, comme dans d’autres, il n’est pas incongru de parler d’un « choc chinois ».
En 2018, l’administration américaine a adopté la China Initiative, dont l’objectif affiché était de lutter contre l’espionnage scientifique et industriel en restreignant les collaborations scientifiques avec des chercheurs chinois. Mais l’effet principal de cette tentative d’isolement de la recherche chinoise a été un redéploiement des collaborations vers les partenaires alternatifs aux Américains, en particulier la Corée du Sud et l’Allemagne permettant la croissance continue de la production scientifique chinoise contrairement à celle des États-Unis, qui décline depuis cette date.
Qui plus est, une proportion croissante des publications les plus citées dans les journaux les plus prestigieux est désormais réalisée par des équipes uniquement chinoises, hors collaborations internationales, ce qui confirme son autonomie scientifique grandissante.
Le projet Transition énergétique en Chine : Nouvelles orientations économiques et politiques – TEChNOPE (ANR-18-CE05-0011) est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Laëtitia Guilhot a reçu des financements de l'Agence Nationale de la Recherche (ANR)
Guillaume Wantz a reçu des financements de l'Agence Nationale de la Recherche (ANR).
Pierre Berthaud a reçu des financements de l'Agence Nationale de la Recherche
André Meunié et Marina Flamand ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
23.06.2026 à 16:18
Comment peut-on faire de la science avec et pour la société ? Ce que révèle une enquête au cœur des collectifs
Max Bouyssières, Chargé de projet Observatoire Science Avec et Pour la Société (SAPS), Université Fédérale Toulouse Midi-Pyrénées
Anne-Claire Jolivet, Directrice opérationnelle Recherche Valorisation Science avec et pour la société, Université Fédérale Toulouse Midi-Pyrénées
Bertrand Jouve, Mathématicien, Directeur de Recherche CNRS, Université Fédérale Toulouse Midi-Pyrénées
Charlène Rivière, Chargée de programme Science et Société - TIRIS, Université Fédérale Toulouse Midi-Pyrénées
Nicolas Dietrich, Professeur des universités en génie des procédés, INSA Toulouse
Philippe Terral, Sociologue - CreSco - Vice-Président Science Avec et Pour la Société, Université de Toulouse
Texte intégral (2719 mots)

Associer scientifiques et citoyens pour produire des connaissances : l’idée séduit, voire enthousiasme. Mais comment ces collectifs fonctionnent-ils réellement ? Une enquête, menée en Occitanie, lève le voile.
Les recherches menées avec la société sont-elles l’affaire de tous ? Que disent réellement les faits ? Notre enquête, portant sur des projets de recherche menés avec des structures diverses – principalement des associations, des entreprises et des collectivités –, montre que les femmes scientifiques y sont très majoritairement engagées. Les collectifs observés sont en outre largement construits à partir de liens interpersonnels préexistants. Si une part importante du travail de recherche est souvent menée en commun, tous ces acteurs ne prennent pas en charge les mêmes tâches. L’enquête révèle en effet que, bien que les orientations soient souvent discutées collectivement, l’analyse des données recueillies demeure par exemple largement assurée par les scientifiques. Pourtant, ces formes de production de connaissance sont diverses et il serait probablement vain de tenter de les enfermer dans un cadre unique.
Alors, pourquoi et comment s’organise un tel partage ? Pour répondre à cette question, nous avons étudié la façon dont ces collectifs fonctionnent, et dans quelles conditions.
Faire de la science « avec et pour » la société : de quoi parle-t-on ?
Les sciences et les recherches participatives remontent bien au-delà de l’époque contemporaine, et correspondent à l’engagement d’acteurs non scientifiques de métier dans la production de connaissances. Au Japon, par exemple, les dates de floraison des cerisiers – sakura – sont consignées depuis plus de mille ans par des habitants et des érudits. Aujourd’hui, ces démarches prennent des formes variées, allant de la collecte citoyenne de données à la participation à d’autres étapes de la recherche.
Par exemple, Vigie-Nature mobilise des volontaires pour suivre la biodiversité à l’échelle internationale ; Galaxy Zoo permet à des internautes de classer des galaxies à partir d’images astronomiques ; en France, le projet La Grande Synchr’EAU mobilise également des citoyens pour mesurer simultanément la qualité de l’eau et produire des données scientifiques à grande échelle.
Nous sommes confrontés à une grande diversité de pratiques, allant du simple recueil de données jusqu’à la définition conjointe des questions de recherche, des méthodes, de l’analyse des résultats et de leur valorisation. Elles interrogent le partage qui a pu être établi entre « sachant » et « non sachant », « théoriciens » et « praticiens », dans la période contemporaine, qui a vu fortement se développer l’activité scientifique sous la forme de disciplines très diverses et de plus en plus spécialisées.
Ouvrir la « boîte noire » des collectifs producteurs de connaissances
Notre enquête, conduite à Toulouse, repose sur l’analyse de 21 réponses recueillies par questionnaire auprès des 53 (co)porteurs et référents de 29 projets de corecherche menés très largement en Occitanie. Elle dresse un panorama des pratiques et des ressentis de ces acteurs. Leurs projets mobilisent 54 organisations non académiques et 34 laboratoires de recherche.

Ces projets abordent 7 grandes thématiques : « Agroécologie, alimentation et pratiques alimentaires », « Santé, corps et contexte », « Participation, gouvernance et aide à la décision », « Apprentissages, transmission et appropriation des savoirs », « Habiter, territoires et transitions locales », « Humanités, imaginaires et récits contemporains » et « Milieux naturels et dynamiques écologiques ».
Deux premiers constats émergent de l’enquête :
Des collectifs issus de relations antérieures : la moitié des répondants indiquent que leurs collectifs de co-recherche se sont formés à partir de liens interpersonnels préexistants, très souvent entre femmes : des liens professionnels datant d’au moins un an.
Une présence féminine importante : environ deux tiers des enquêtés sont des femmes, un pourcentage qui nécessite une analyse plus approfondie pour en évaluer la significativité car il pourrait seulement s’agir d’une représentativité disciplinaire et institutionnelle due au pourcentage élevé de Maîtres de Conférences qui sont des femmes dans le domaine des Sciences Humaines et Sociales.
Comment les rôles sont-ils répartis ?
Dans la lignée du rapport de recherche sur le projet Initiatives de recherches collaboratives Toulouse – porté par la Maison des sciences humaines et sociales de Toulouse de 2018 à 2022 et visant à recenser et mieux comprendre les collaborations entre sciences et « société civile non marchande » en Occitanie-Ouest –, l’enquête met en lumière une collaboration effective, mais asymétrique selon les étapes de la démarche de production de connaissances.
Quatre étapes sur cinq ont vocation à être partagées entre scientifiques et partenaires : la définition des problèmes, le choix des terrains et/ou de la population d’étude, la collecte des données et la diffusion. Dans les faits, la collecte et l’analyse des données restent principalement l’apanage des scientifiques, tandis que l’accès aux terrains ou aux populations d’étude est souvent initié et facilité par les acteurs de la société.
Pour que des acteurs aux cultures professionnelles différentes puissent se comprendre, s’organiser et se coordonner, des méthodes d’accompagnement, souvent regroupées sous le terme « intermédiation », sont évoquées comme utiles, voire nécessaires. Pourtant, dans notre enquête, cette fonction – et le panel de compétences qu’elle requiert – repose presque toujours sur une seule personne, le porteur de projet « principal », rarement formé à ce rôle. Former à l’intermédiation pour mieux accompagner des collaborations hybrides semble donc constituer un levier majeur pour un bon déploiement des projets.
Comment peut-on faire de la science avec et pour la société ?
L’enquête montre que les activités des collectifs de corecherche étudiés ne relèvent ni d’un effet d’affichage ni d’un simple engouement passager. Dans la grande majorité des cas, les relations entre scientifiques et partenaires sont jugées fréquentes et complémentaires. Les projets favorisent des apprentissages réciproques et un enrichissement intellectuel en lien avec un climat de confiance : « Le travail collaboratif avec les scientifiques permet d’affiner le regard sur le sujet complexe de la corecherche et de tenter de partager la démarche avec les habitants concernés » selon un partenaire extra-académique, référent du projet. La qualité des savoirs et celle des relations semblent aller de pair :
« La corecherche impose un rythme plus lent, mais nécessaire, pour permettre l’émergence de relations de confiance et de véritables échanges. Le respect des temporalités de chacun […] est un facteur clé de réussite », selon un chercheur, porteur de projet.
Mais ces dynamiques ne vont pas de soi. L’ambition affichée d’une symétrie d’engagement, avec des compétences différentes, dans la plupart des étapes de production des connaissances ne résiste pas aux descriptions issues de notre enquête. La diversité des formes de collaborations est une richesse qui reconnaît la diversité des compétences et des savoirs des « non-scientifiques ». Observer cette pluralité permet d’interroger les partages que notre société a établis entre « sachant » et « non-sachant », entre « théorie » et « pratique ».
La diversité observée est aussi celle du caractère « situé » et « ancré » dans des contextes et des territoires de connaissances collectivement produites. Que l’on parle de la co-élaboration de questions de recherche ou de la co-interprétation des données collectées, l’enjeu principal de ces partenariats est la production de connaissances utiles pour éclairer, voire résoudre, un problème concret.
Par exemple, coconstruire une solution biomimétique s’inspirant des castors pour ralentir l’assèchement prématuré de cours d’eau nécessite une symbiose entre les savoirs symboliques des scientifiques et les savoirs pratiques des personnes concernées – locaux, militants, etc. –, ainsi qu’une volonté d’agir commune. L’apport des partenaires « non scientifiques » est alors décisif aux côtés du travail des scientifiques, habitués à produire des connaissances généralisables, mais qui s’éloignent ainsi parfois d’un ajustement à la spécificité de l’écosystème. En ce sens, les discussions, échanges, voire confrontations, entre ces acteurs aux profils divers procèdent souvent par tâtonnements et ajustements progressifs, nécessitant une capacité d’adaptation des scientifiques et des non-scientifiques. Les compétences spécialisées de chacun peuvent être davantage exploitées, notamment : d’une part, la connaissance du contexte des partenaires et, d’autre part, les capacités de formalisation et d’écriture des scientifiques, habitués à publier et à communiquer.
Pour autant, cette diversité révèle aussi des situations d’expérimentation, souvent menées en dehors des sentiers battus de nos institutions, confrontées à d’importantes contraintes et incertitudes. Ces collaborations reposent sur des disponibilités construites dans le cadre d’autres activités, qu’elles soient professionnelles ou personnelles. Car les moyens humains – compétences et personnels pour animer les échanges, gérer administrativement les projets, etc. – et matériels – ressources financières pour les besoins d’enquête, de formalisation et de diffusion des résultats, pour assurer la disponibilité des participants tout au long du processus, etc. – permettant de se consacrer pleinement au déploiement de ces collaborations hybrides font souvent défaut.
Les chercheurs, comme les partenaires, ne sont pas forcément formés, prêts et suffisamment disponibles pour vivre ces collaborations et en assurer le maintien dans la durée. Et ce, d’autant plus que leurs activités sont marquées par des modes de fonctionnement, des objectifs, et des temporalités différentes. Est également pointée la question de la reconnaissance de ces activités par les institutions, notamment dans les carrières professionnelles, que l’on parle des scientifiques ou de leurs partenaires.
Faire de la science avec et pour la société est possible et fécond, tant pour faire avancer la connaissance en elle-même que pour contribuer à résoudre des problèmes rencontrés. Toutefois, cette démarche nécessite des compétences qui ne sont pas aujourd’hui usuelles dans la production de connaissances. Notre enquête montre qu’il n’y a pas qu’une façon de faire collectif, ni une seule méthode ou démarche qui doit s’imposer. Étudier de près la diversité de ces modes de collaboration, en suivant leur déploiement dans leurs conditions concrètes d’organisation et de partage, nous semble essentiel pour mieux accompagner ces collectifs et bénéficier de connaissances complémentaires à celles produites par les canaux plus habituels de la sphère académique.
Les auteurs remercient les membres du comité de ressources de l’Observatoire, ainsi que les cochercheurs ayant participé à l’enquête, sans qui celle-ci n’aurait pas été possible. L’enquête sociologique, exploratoire et compréhensive, menée par l’observatoire Science avec et pour la société (SAPS) de la Communauté d’universités et établissements de Toulouse, dont fait état cet article, est issue de l’analyse des 21 réponses à un questionnaire destiné aux 53 (co)porteurs et référents des 29 projets de recherche participative sélectionnés et accompagnés dans le cadre des deux dispositifs 2024 du comité de programme « Science et société » du projet Toulouse Initiative for Research’s Impact on Society (TIRIS) : l’appel à projets « Co-recherche avec la société » et l’appel à manifestation d’intérêt de sa Boutique des sciences.
Max Bouyssières est chargé du projet Observatoire Science Avec et Pour la Société (SAPS), un dispositif financé par TIRIS, au sein de la COMUE (Communauté d'universités et établissements) de Toulouse. TIRIS est un projet cofinancé par l’ANR au titre de France 2030 (ANR-22-EXES-0015), par la région Occitanie et par le Fonds Européen de Développement Régional.
Jolivet Anne-Claire est directrice opérationnelle Recherche, Doctorat, Valorisation et responsable du service Science avec et pour la Société à la Comue de Toulouse.
Bertrand Jouve est le Responsable Scientifique et Technique de TIRIS, un projet cofinancé par l’ANR au titre de France 2030 (ANR-22-EXES-0015), par la région Occitanie, et par le Fonds Européen de Développement Régional.
Charlène Riviere est chargée du programme "Science-Société" de TIRIS, au sein de la COMUE (Communauté d'universités et établissements) de Toulouse. TIRIS est un projet cofinancé par l’ANR au titre de France 2030 (ANR-22-EXES-0015), par la région Occitanie et par le Fonds Européen de Développement Régional.
Nicolas Dietrich est président du comité de programme « Science et société » de TIRIS, un projet cofinancé par l’ANR au titre de France 2030 (ANR-22-EXES-0015), par la région Occitanie et par le Fonds Européen de Développement Régional.
Philippe Terral est Vice-Président Science Avec et Pour la Société (SAPS) de la COMUE (Communauté d'universités et établissements) de Toulouse
22.06.2026 à 16:45
Les chercheurs ont divisé par deux leurs vols professionnels sans y être contraints
Tamara Ben Ari, Chercheuse en sciences de l'environnement, Inrae
Léa Marquet, Doctorante en sciences de l'environnement, Inrae
Philippe-e. Roche, Checheur en physique, Centre national de la recherche scientifique (CNRS)
Texte intégral (1150 mots)

Alors que le trafic aérien mondial a retrouvé, voire dépassé, ses niveaux d’avant-Covid, les personnels de la recherche français auxquels nous sous sommes intéressés font exception : leurs déplacements en avion ont été divisés par deux par rapport à 2019, et cette baisse se maintient dans le temps.
Nos récentes analyses montrent que ces scientifiques, toutes disciplines confondues, se déplacent aux mêmes endroits et pour les mêmes raisons, mais deux fois moins qu’auparavant. Résultat : les émissions de gaz à effet de serre (GES) liées aux déplacements professionnels ont, elles aussi, été divisées par deux, sans qu’aucune contrainte réglementaire ne l’ai imposé.
Comment ces résultats ont-ils été obtenus ?
Nous avons analysé la plus grande base de données existante sur l’empreinte carbone de la recherche, construite par le groupement de recherche (GDR) Labos 1point5 grâce à l’outil libre et open source GES 1point5.
La base de données ainsi constituée regroupe près d’un million de déplacements professionnels réalisés entre 2019 et 2024 dans environ un tiers des laboratoires de recherche français. Cette base, construite grâce au travail collaboratif de centaines de laboratoires de recherche volontaires, permet de suivre l’évolution du nombre de déplacements, des distances parcourues, des modes de transport utilisés (avion, train) et des émissions de gaz à effet de serre associées. Elle est basée sur les listings de voyages financés par les laboratoires. Le nombre de déplacements, vérifiés et corrigés ligne à ligne peut enfin être normalisé par le nombre de personnels du laboratoire.
Nous avons « décomposé » les émissions de GES annuelles de façon à répondre à trois questions simples :
• Voyage-t-on moins souvent ?
• Voyage-t-on moins loin ?
• Utilise-t-on des modes de transport moins carbonés ?
Nous montrons que la diminution de la fréquence des déplacements, tous modes confondus, explique à elle seule environ la moitié de la réduction totale des émissions observée depuis 2019. Ensuite, la distance moyenne parcourue par déplacement diminue d’environ 17 %, et l’intensité carbone moyenne par kilomètre parcouru diminue d’environ 20 %. Cette évolution de la baisse de l’intensité carbone tient avant tout à la montée en proportion du ferroviaire, nettement moins émetteur que l’aérien.
En quoi est-ce important ?
Les déplacements professionnels représentent une part importante de l’empreinte carbone de la recherche (environ 25 % en 2019). Montrer qu’il est possible de diviser ces émissions par deux remet en cause l’idée selon laquelle la mobilité aérienne serait incompressible dans les métiers compétitifs, collaboratifs ou fortement internationalisés.
Le contraste entre la recherche et d’autres secteurs professionnels, où le trafic aérien semble repartir à la hausse, malgré des informations fragmentaires, suggère que cette transformation est à relier à une certaine autonomie organisationnelle du champ scientifique ainsi, éventuellement, au consensus scientifique autour des enjeux climatiques.
Cette réduction drastique des émissions de GES invite à nuancer l’idée que l’absence de régulation contraignante généralisée – qu’elle soit imposée par le haut au niveau national ou par le bas dans les laboratoires – signifie une incapacité à dépasser la seule quantification des émissions de GES. Nos résultats suggèrent au contraire que des transformations importantes ont eu lieu, en l’absence de politiques climatiques ambitieuses. L’appropriation de la question climatique au sein des laboratoires, accompagnée par des initiatives dédiées telles que Labos 1point5, a pu y contribuer.
Nos résultats plaident enfin pour un « verrouillage vertueux », qui permettrait d’éviter un retour progressif aux niveaux d’émissions de gaz à effet de serre antérieur au Covid.
Quelles suites à cette recherche ?
Il reste à comprendre plus finement pourquoi cette transformation s’est maintenue dans le temps, et si elle est parfaitement représentative de l’ensemble de l’enseignement supérieur et de la recherche. Plusieurs facteurs peuvent être en jeu pour expliquer nos observations : les effets durables de la pandémie sur l’offre et la demande en déplacements, la généralisation et la diversification des usages de la visioconférence, la hausse du prix des billets d’avion et de train, mais aussi la diffusion progressive de nouvelles normes de sobriété dans le monde académique.
La question devient alors celle d’une possible écologisation du monde académique : assiste-t-on à une redéfinition progressive de ce qui est considéré comme une mobilité légitime ou nécessaire dans la recherche ? Répondre à cette question est crucial pour comprendre si les évolutions observées sont conjoncturelles ou le signe d’une transformation plus profonde du secteur, ainsi que leur possible diffusion à d’autres secteurs. Des études similaires conduites dans d’autres pays seront nécessaires pour mieux comprendre les déterminants et la stabilité des changements observés en France.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui les ont menées, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Tamara Ben Ari est co-fondatrice de Labos 1point5
Léa Marquet et Philippe-e. Roche ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview