
08.07.2026 à 10:00
Une découverte inattendue : des traces de séismes anciens dans le Bassin parisien
Stéphane Baize, Géologue des tremblements de terre, Directeur de Recherches, ASNR
Pierre Louis Antoine, Directeur de Recherche CNRS, géoloque et géomorphologue spécialiste des paléoenvironnements du Quaternaire, Centre national de la recherche scientifique (CNRS)
Texte intégral (1776 mots)
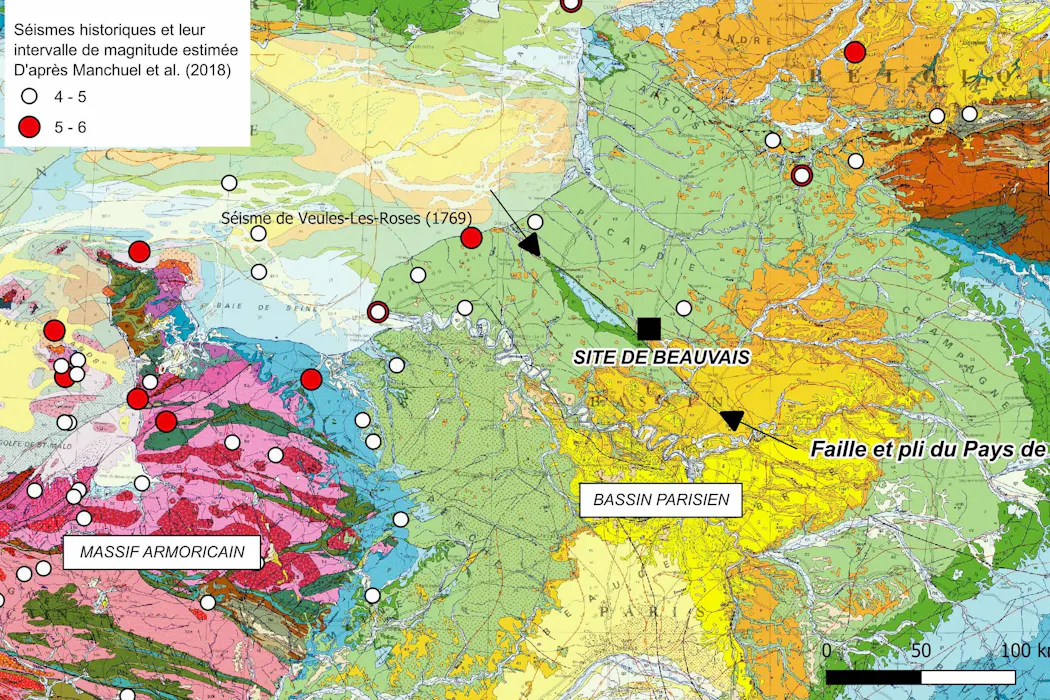
En 1993, lors de fouilles archéologiques préventives pour la construction d’une route à Beauvais, dans l’Oise, des géologues et des archéologues ont mis au jour un site paléolithique exceptionnel. Occupé par des néandertaliens il y a environ 60 000 ans, il révèle bien plus que des outils en silex ou des ossements d’animaux, de mammouths, de rennes et de rhinocéros laineux.
En effet, nous avons identifié un réseau de failles traversant les dépôts sédimentaires récents et les restes archéologiques associés ainsi que le substrat rocheux (ici, la craie). Dans notre étude publiée ce mois-ci dans les Comptes Rendus Géoscience, nous proposons une nouvelle interprétation à ces déformations : elles seraient d’origine sismique.
Les failles que nous observons présentent des décalages verticaux cumulés jusqu’à 25 centimètres (pour comparaison, c’est significativement plus grand que celles mesurées après le séisme de magnitude proche de 5 qui a secoué et endommagé les communes du Teil, de Viviers et Saint-Thomé en Ardèche, le 11 novembre 2019).
Ces failles ne peuvent pas être expliquées par des phénomènes comme l’effondrement liés à la dissolution de la craie (le « karst »), ni par le gel et le dégel de sols riches en glace (appelé « pergélisol », ni enfin par l’activité humaine…
C’est pourquoi l’hypothèse la plus plausible est une origine tectonique, c’est-à-dire que le déplacement soit lié aux mouvements de la croûte terrestre pendant un ou plusieurs séismes. Cette origine devra être confirmée par des études complémentaires, notamment par des explorations du sous-sol, ou la recherche d’autres indices similaires par d’autres fouilles dans la même zone.

Les structures que nous avons observées sont cohérentes avec l’expression superficielle de ruptures sismiques profondes, qui seraient liées au grand pli et à la faille du Pays de Bray, une des structures géologiques majeures du Bassin parisien, qui s’enracine à plusieurs kilomètres dans la croûte terrestre.
Si les failles observées à Beauvais sur le site du lieu-dit « La Justice » sont bien liées à un séisme ancien, leur taille et leur décalage suggèrent un événement d’une magnitude d’au moins 5,5.
Pourquoi cette découverte est-elle importante ?
Le Bassin parisien est traditionnellement considéré comme une région peu sismique, avec une activité tectonique quasi nulle depuis des millénaires. On n’y connaît guère que quelques séismes historiques, comme celui de Veules-les-Roses, dans l’actuelle Seine-Maritime, en 1769 (magnitude estimée proche de 5), qui a causé des dégâts localement.
La découverte de Beauvais modifie notre perception du « danger » sismique dans la zone. Elle suggère, par l’ampleur des déformations observées, qu’il n’est pas négligeable et que des séismes forts ont pu se produire sur des failles il y a seulement 50 000 à 60 000 ans, une période géologiquement récente.
Une autre conséquence est qu’on peut maintenant considérer la faille du Pays de Bray comme potentiellement active. Ce changement d’appréciation du degré d’activité de cette faille rejoint celui qui avait suivi l’occurrence du séisme du Teil en 2019, en Ardèche, sur une faille alors inconnue pour être active.
Ces deux exemples supportent le même constat : les failles « intraplaques » (situées à l’intérieur des continents, loin des limites de plaques tectoniques) peuvent produire des séismes forts avec ruptures en surface, même dans des régions réputées stables. C’est ce qu’ont connu, par exemple, le centre du continent australien en avril dernier et le nord-est des États-Unis en 2020.
Quelles suites pour ces recherches ?
Cette découverte soulève des questions cruciales : la faille du Pays de Bray, longue de près de 100 kilomètres, est-elle toujours active et capable de causer des séismes importants dans un futur proche ? Quelle est la probabilité de séismes futurs dans cette zone densément peuplée et industrialisée, et avec quelle magnitude peuvent-ils survenir ? Comment affiner les modèles d’aléa sismique en conséquence, pour cette région comme pour les zones intraplaques comparables ?
Pour répondre à ces interrogations, il faut poursuivre les investigations sur le terrain autour du site fouillé, notamment utiliser des méthodes géophysiques de haute résolution et non invasives, pour sonder et cartographier précisément les failles enterrées, à des profondeurs allant de quelques dizaines à plusieurs centaines de mètres. Il faudrait ensuite étendre les fouilles pour dater d’éventuelles traces de séismes passés et estimer leur fréquence (ce qu’on appelle l’analyse paléosismologique).
Un autre enjeu est de renforcer la collaboration interdisciplinaire : les traces de séismes passés dans les sols sont, dans le contexte français de tectonique lente, souvent masquées ou abîmées par l’érosion ou les activités humaines. Il est donc nécessaire de combiner les approches des archéologues, des géologues et des géophysiciens.
Au-delà des recherches proprement dites, l’objectif est de mettre à jour et de compléter la base de données des failles actives et des séismes préhistoriques connus, publiée il y a bientôt dix ans.
Enfin, ces résultats seront pris en compte dans l’évaluation des risques, qui est, par exemple, périodiquement mise à jour à l’échelle de l’Europe. Cette étude souligne que, même dans des zones réputées stables, le risque sismique ne doit pas être sous-estimé, même si les causes des séismes y restent encore débattues.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.07.2026 à 10:00
Avec ou sans synapses ? Le singulier système nerveux des cténophores, ou comment un débat scientifique vieux de 100 ans refait surface
David Stroebel, Ingénieur de recherche hors classe CNRS dans l'équipe Récepteurs du glutamate et synapses excitatrices, Institut de biologie, École normale supérieure (ENS) – PSL
Texte intégral (2359 mots)

Dans les livres de biologie, on apprend que le système nerveux se compose de neurones connectés par des synapses, indispensables à nos capacités de cognition. Jusqu’à très récemment, les synapses étaient un élément incontournable de tous les systèmes nerveux connus. Mais voilà que des chercheurs ont observé un système différent, sans synapses, chez d’intrigants animaux marins, les cténophores. Cette avancée suscite les débats chez les scientifiques.
Aux prémices de la neurobiologie moderne, au début du XXᵉ siècle, une rivalité d’anthologie opposa Camillo Golgi, médecin italien, pionnier et figure tutélaire de la microscopie cellulaire, et l’Espagnol Santiago Ramón y Cajal, génie de la neuroanatomie. L’Italien avançait que le système nerveux formait un réseau unique et continu : un syncytium. L’Espagnol y voyait plutôt un réseau discontinu, fait de cellules indépendantes se contactant par des synapses.

Cent vingt ans après l’attribution du même prix Nobel de physiologie aux deux scientifiques, le succès de Cajal apparaît total : les synapses constituent une pièce maîtresse de notre compréhension actuelle du fonctionnement du système nerveux. De fait, ces structures submicrométriques innombrables dans le cerveau (près d’un demi-million de milliards de synapses chez l’humain) forment le support des capacités de computation, d’apprentissage et de mémorisation.
Mais si, envers et contre l’histoire de la neurobiologie moderne, Golgi avait pu aussi avoir raison ? Et si le système nerveux d’un organisme pouvait également fonctionner en syncytium ?
C’est précisément ce que des chercheurs ont découvert en 2023, en imageant un cténophore par tomographie électronique. Les cténophores sont des créatures marines translucides, familières de presque tous les environnements marins, qui se distinguent par de délicates ondulations irisées à leur surface. Certains cténophores peuvent sembler, à première vue, être de proches cousins des méduses. Cependant, l’étude publiée en 2023, dans la revue Science, révèle que la partie centrale du réseau neural de cténophore est continu, un cas sans équivalent dans le monde vivant.
Le syncytium neural de Golgi se trouvait en fait… dans les mers.

Les cténophores n’en sont pas à leur première originalité
Contredisant leur apparente ressemblance, l’étude du génome des cténophores indiquait déjà en 2013 qu’ils sont plus éloignés des cnidaires (méduses) que ces dernières ne le sont de nous. Plusieurs études scientifiques placent désormais le groupe des cténophores comme ancêtres des animaux (on appelle le groupe des animaux les « Métazoaires »), avant même les éponges ! Mais ce classement reste encore aujourd’hui très débattu.
Pourquoi une telle querelle entre spécialistes ? Parce que l’ancestralité des cténophores chez les animaux (Métazoaires) complexifie le scénario d’émergence du système nerveux.
En effet, les classifications du vivant considéraient jusque-là que notre ancêtre commun, Eumétazaoire, a acquis un système nerveux après la séparation du groupe des éponges, qui, elles, seraient demeurées dépourvues de système nerveux. Le repositionnement des cténophores dans l’arbre du vivant bouscule complètement ce scénario : il impliquerait l’émergence multiple et séparée de systèmes nerveux potentiellement différents, couplée ou non à la disparition du système nerveux chez certaines espèces (par exemple, chez les éponges).
L’état actuel des recherches ne permet d’exclure aucun des deux scénarios. Le scénario initial a pour lui une grande simplicité (on parle de scénario « parcimonieux »), permettant aisément d’envisager un assemblage progressif de la complexité du système nerveux. Le scénario nouvellement remanié est porté par l’évolution exceptionnelle des données de séquençage de génome et des outils d’analyse bio-informatique. Ce nouveau scénario a le bénéfice et l’attrait de la nouveauté. Mais, pour convaincre, il lui reste encore à élaborer un mécanisme évolutif convaincant de formation du système nerveux.
C’est là qu’intervient la découverte de la singularité du système nerveux des cténophores, appuyant l’originalité biologique de ces discrets organismes marins parmi les animaux (Métazoaires). Si, à ce stade, elle ne permet pas formellement de trancher entre les deux théories, cette découverte offre un aperçu des possibilités insoupçonnées d’organisation du système nerveux dans le vivant. Par là même, elle ouvre les chemins des possibles évolutifs, ceux qui faisaient défaut aux scénarios complexes de co-émergence de systèmes nerveux.
Les cténophores déterrent le débat entre Golgi et Cajal
Mais revenons à l’autre débat, celui d’il y a plus de cent ans, entre Cajal et Golgi – ou, désormais transposé à la biologie marine, la distinction d’organisation neurobiologique entre cténophores et cnidaires. Que peut bien apporter une organisation neurale en syncytium par rapport à celle bien connue basée sur des synapses (et vice versa) ?
Pour l’instant, on ne sait encore presque rien du fonctionnement de ce syncytium neural des cténophores, seulement qu’il connecte les cellules excitables sensorielles et motrices de l’animal. En attendant les résultats de futures investigations, nous en sommes aujourd’hui juste réduits à spéculer sur ce qu’un tel réseau pourrait procurer : une économie d’énergie ? Un gain de rapidité de réponse ?
Le rôle des synapses, des méduses aux humains
Dans les organismes neuraux, les synapses constituent la base des capacités d’encodage complexe du signal au sein du réseau. L’importance de leur capacité d’adaptation (appelée aussi plasticité) et l’étendue de leur diversité constituent des champs d’investigation actifs de la neurobiologie actuelle. Plusieurs décennies de recherche intensive nous ont appris que, selon leur type et leur environnement cellulaire, les synapses modulent la force, la dynamique et même la nature des signaux transmis au neurone qu’elle contacte.
Ces propriétés sont vraisemblablement à l’origine des possibilités d’expansion et de complexification des réseaux neuronaux des organismes à synapses, comme chez nous autres Vertébrés. In fine, ce sont cette expansion et cette complexification qui ont permis de supporter le développement de comportements et d’apprentissages élaborés, jusqu’aux prouesses des transmissions culturelles humaines.
Embrasser la complexité du vivant
Alors, système à syncytium ou à synapses ?
Si juger (neurobiologiquement) de l’efficacité relative d’organisations si différentes n’a guère de sens, un regard sur les chiffres de population des espèces concernées révèle une profonde asymétrie. Seule une centaine d’espèces de cténophores est référencée alors qu’il existerait plus d’un million d’espèces d’animaux neuraux. Le succès évolutif des organismes à synapses – à la fois en termes de diversité que de biotopes occupés – est aussi incontestable que la postérité de Cajal.
Pourtant, après 600 millions d’années marquées par plusieurs extinctions massives, les cténophores continuent de cohabiter avec les autres espèces peuplant nos océans. La sélection naturelle n’a pas tranché entre système à syncytium et à synapses.
Et les cténophores, tels des clins d’yeux facétieux aux modèles de Golgi, persistent à tourner en dérision nos schémas simplistes, du fonctionnement neural au scénario de nos origines.
David Stroebel est un agent du CNRS, France. Il a reçu des financements de l'ANR (Agence Nationale pour la Recherche, France) ainsi que de la FRM (Fondation pour la recherche médicale).
08.07.2026 à 09:59
La respiration nous permet de communiquer avec nous-mêmes, avec les autres et avec les robots
Thomas Similowski, Professeur de pneumologie, directeur de l'unité de recherche UMRS1158 (Neurophysiologie Respiratoire Expérimentale et Clinique), spécialiste des interactions entre système respiratoire, système nerveux, et société, Sorbonne Université
Texte intégral (1852 mots)

La respiration n’a pas comme unique fonction de nous apporter de l’oxygène et d’éliminer du dioxyde de carbone. Loin de là. Elle sert aussi à communiquer de multiples manières : avec les autres explicitement ou implicitement ; avec soi-même ; et même avec des robots ou des œuvres d’art. Cette faculté est propre à la respiration : on ne communique avec son cœur ou ses tripes qu’au figuré.
Parmi les fonctions vitales, la respiration possède deux grandes particularités. La première est que nous pouvons en prendre temporairement le contrôle. Comment est-ce possible ? Parce que l’automatisme respiratoire ne vient pas des poumons eux-mêmes, comme c’est le cas pour les automatismes du cœur et de l’intestin, mais d’ailleurs : du système nerveux central. Pour respirer, il faut contracter des muscles « squelettiques » (qui font bouger des os), dont le plus connu est le diaphragme, la coupole musculaire qui sépare thorax et abdomen. Ces muscles respiratoires sont commandés par des neurones de la moelle épinière. Notre cortex cérébral y a accès pour en faire ce que nous voulons, en court-circuitant temporairement les structures automatiques qui assurent le rythme respiratoire (des oscillateurs neuronaux du tronc cérébral). Ce phénomène n’existe pour aucune autre fonction vitale.
Pour parler (ou chanter, ou siffler, ou jouer d’un instrument à vent), il faut pouvoir arrêter la respiration automatique, prendre une grande inspiration pour une voix forte ou une phrase longue, segmenter son souffle pour moduler sa prosodie. Une fois dit, cela paraît évident. Mais aviez-vous vraiment conscience que sans contrôle de la respiration, c’est le silence ?
Respirer, c’est communiquer
Deuxième particularité de la respiration : elle se voit et elle s’entend. Nous pouvons communiquer impatience, lassitude, colère, fatigue, soulagement, surprise, ou peur par des soupirs expressifs. Mais il y a plus subtil.
La respiration est branchée sur notre état physiologique (le sommeil ou l’effort), notre santé, nos émotions. Tous ces sentiments caricaturés explicitement par les soupirs appuyés, la respiration les traduit implicitement par des modifications de son amplitude et de sa fréquence, et des sons de notre « soufflet ».
Respiration lente, régulière et profonde de l’apaisé qui somnole. Respiration superficielle, rapide, monotone de la crise d’anxiété. Respiration saccadée, irrégulière de la joie et de l’excitation. Que nous en ayons conscience ou pas (plus souvent « pas », d’ailleurs), nous envoyons aux autres un flux continu d’information sur nous-mêmes par le simple fait de respirer. C’est d’ailleurs une source d’alliance : la synchronisation respiratoire, implicite ou explicite, peut créer un lien, favoriser la coopération. Nous avons même chacun notre signature motrice respiratoire : en effet, la façon dont notre poitrine se gonfle et se dégonfle nous est propre, comme l’est notre démarche.
Par ailleurs, notre cerveau est bombardé en permanence de milliers de messages qui proviennent de notre appareil respiratoire. Il se sert de ces messages comme d’un échafaudage pour coordonner des aires cérébrales impliquées dans de multiples fonctions cognitives : mémoriser ou décider, par exemple. Des recherches ont montré que nous enregistrons mieux une image si elle nous est présentée pendant l’inspiration que pendant l’expiration.
Ainsi, par la respiration, nous communiquons avec nous-mêmes. Et nous pouvons agir sur notre cerveau, en particulier l’apaiser, en changeant notre façon de respirer, une propriété largement mise à profit par la plupart des approches psychocorporelles.
Faire respirer les robots
Mais revenons à cette respiration qui se voit et qui s’entend, qui renseigne sur vous, qui dit en fait « Regarde, écoute, je suis vivant », et ce, dès notre tout premier cri, jusqu’à notre dernier souffle.
Pour savoir si quelque chose est vivant, les enfants utilisent trois indices : ça bouge ; ça respire ; ça grandit (mais celui-ci demande du temps). Donc pour savoir tout de suite si c’est vivant, même si cela ne bouge pas : est-ce que cela respire ?
Au laboratoire de physiopathologie respiratoire de l’unité de recherche UMRS 1158 Inserm-Sorbonne Université, et en collaboration avec l’Institut des systèmes intelligents et de robotique de Sorbonne Université, nous avons mobilisé ce concept pour l’appliquer à une problématique très spécifique, celle des interactions humains-robots.
Est-ce qu’un robot qui « respire » est plus « engageant » qu’un robot « normal » ? Ceci avait déjà été observé par d’autres chercheurs qui avaient animé un bras mécanique de mouvements cadencés ressemblant à une respiration. Les humains, qui travaillaient avec le robot sur une chaîne de coproduction humains-machines, avaient trouvé le « bras respirant » plus « vivant », plus « humain », plus « intelligent », plus « aimable » et plus « rassurant », selon un outil d’évaluation très utilisé en robotique (le questionnaire « Godspeed »). Mais notre question s’adressait davantage à ces robots humanoïdes qui seront peut-être nos compagnons, nos interlocuteurs de demain. Faire respirer un robot déjà très attractif par sa morphologie, est-ce mieux ? Ou au contraire, est-ce dérangeant ?
Pour tester cela, nous avons programmé deux robots « Pepper » (un petit humanoïde bourré de capteurs qui ressemble à un enfant d’une dizaine d’années) pour qu’ils puissent converser avec des humains. Nous en avons animé un de petits bruits et mouvements aléatoires que l’on injecte souvent dans le comportement des robots pour les rendre plus « vivants ». Nous avons animé l’autre d’un mouvement associant redressement du torse et rotation des épaules (comme ce qui se passe lorsque nous inspirons) ainsi que d’un discret souffle. Le résultat a été probant. Alors que la plupart des participants ne réalisaient pas consciemment que l’un des deux robots respirait, ils trouvaient celui-ci « plus vivant » et « plus intelligent ».
Surtout, l’interaction changeait : les participants passaient davantage de temps à regarder la tête et le visage du robot (« temps de regard ») et l’échange durait plus longtemps. Statistiquement, deux facteurs seulement étaient significativement associés au temps de regard : la respiration du robot d’une part et le niveau de sollicitude empathique de son interlocuteur de l’autre.
Un humain s’implique plus dans une interaction avec un robot si le robot « respire ». Donc, la respiration est un vecteur de communication même avec le « non-vivant ». Une piste si l’on souhaite humaniser toujours plus robots, intelligences artificielles et autres agents virtuels ?
Quand l’art respire

C’est selon ce principe d’animéité respiratoire que notre unité de recherche s’est intégrée à une équipe multidisciplinaire, réunie par Samuel Bianchini, artiste et enseignant-chercheur à l’École nationale supérieure des arts décoratifs, équipe dont les efforts ont convergé vers la création d’une œuvre d’art respirante.
Réespiration combine création artistique, robotique souple, ingénierie mécanique, intelligence artificielle, physiologie, design textile, design sonore, et bien d’autres choses encore, en une entité qui respire comme un humain (grâce à l’entraînement d’un algorithme spécialisé et qui peut synchroniser son rythme respiratoire à celui de son spectateur, voire l’influencer. Les réactions du public et les premières données de recherche montrent qu’en présence de Réespiration, les corps se détendent, les cerveaux s’apaisent. Ils vagabondent même, en chemin vers un état modifié de conscience.
Les robots respirants en général, et Réespiration en particulier, auront-ils des applications médicales ? Apaiseront-ils l’anxiété, aideront-ils à soulager la souffrance des patients atteints de maladies respiratoires chroniques ? C’est la prochaine question…
L’UMRS 1158 et le projet Réespiration sont soutenus par la Fondation du Souffle, www.lesouffle.org
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview