
08.07.2026 à 09:59
Les astronomes cherchent-ils vraiment des extraterrestres ? Oui, mais pas comme dans les films
Quentin Kral, Astrophysicien à l'observatoire de Paris-PSL, CNRS, Sorbonne Université, Université Paris Cité
Texte intégral (1999 mots)
La recherche de vie ailleurs que sur Terre n’est pas de la science-fiction, mais un domaine très sérieux de recherche : l’exobiologie. Découvrez les techniques qui pourraient permettre, un jour, une rencontre du troisième type.
Sommes-nous seuls dans l’Univers ? Pendant longtemps, cette question relevait surtout de la philosophie. Chacun pouvait avoir son intuition. Kant disait même qu’il parierait toute sa fortune sur l’existence d’une vie ailleurs dans l’Univers. Il ne prenait pourtant pas un très grand risque : à son époque, il était impossible de tester cette hypothèse.
Aujourd’hui, la situation a profondément changé. Grâce aux progrès de l’astronomie, de la biologie, de la chimie et de la géologie, la recherche de la vie extraterrestre est devenue une véritable discipline scientifique : l’exobiologie. Des milliers de chercheurs tentent désormais de répondre expérimentalement à une question qui semblait encore hors de portée il y a quelques décennies.
Plusieurs approches sont explorées. L’idée est d’apprendre ce que l’on peut du cas terrestre avant d’extrapoler à d’autres mondes. Ainsi, certaines équipes cherchent à comprendre comment la vie est apparue sur Terre afin d’identifier les ingrédients indispensables à son émergence. D’autres étudient son évolution vers des organismes plus complexes.
Les astronomes, eux, s’intéressent à une autre question : si la vie existe ailleurs, comment pourrions-nous la détecter ?
Deux grandes stratégies se dessinent. La première consiste à rechercher des biosignatures, c’est-à-dire des traces laissées par des organismes vivants. La seconde vise les technosignatures, des indices qui pourraient révéler l’existence d’une civilisation suffisamment avancée pour développer une technologie détectable.
Chercher la vie dans le système solaire
La façon de rechercher la vie dépend avant tout de la distance. Dans notre système solaire, nous pouvons envoyer des sondes pour analyser directement des roches, des glaces ou des océans cachés sous la surface. Autour d’autres étoiles, en revanche, nous sommes condamnés à observer les planètes à distance et à interpréter la faible lumière qui nous parvient.
Mars reste l’une des cibles les plus étudiées. Le rover Perseverance ne cherche pas à photographier d’éventuels organismes vivants, mais à identifier des biosignatures fossiles : des traces chimiques ou géologiques qui indiqueraient qu’une vie microbienne a existé lorsque Mars possédait des lacs et des rivières il y a plusieurs milliards d’années. Les échantillons qu’il collecte devraient être rapportés sur Terre dans les prochaines décennies – sûrement avec beaucoup de retard à cause de coupes budgétaires sévères de l’administration Trump – afin d’être analysés avec les instruments les plus performants.
D’autres mondes suscitent également beaucoup d’espoir. Les lunes glacées Europe, autour de Jupiter, et Encelade, autour de Saturne, abritent un océan d’eau liquide sous leur croûte de glace. Encelade projette même dans l’espace des panaches d’eau provenant de son océan, offrant une occasion unique d’en analyser directement la composition. Les missions Europa Clipper et Juice, actuellement en route, permettront de mieux comprendre si ces océans réunissent les conditions favorables à l’apparition de la vie.
Au-delà du système solaire, cette approche directe devient impossible. Les astronomes doivent alors rechercher les traces que la vie pourrait laisser dans l’atmosphère ou à la surface des exoplanètes.
Les biosignatures : rechercher les empreintes laissées par la vie
Sur Terre, les êtres vivants modifient profondément leur environnement. Certaines bactéries produisent de l’oxygène, d’autres du méthane. Les plantes absorbent certaines longueurs d’onde de la lumière pour réaliser la photosynthèse. Toutes ces activités laissent des signatures qui pourraient, en principe, être détectées à des dizaines d’années-lumière.
On pourrait croire qu’il suffit de détecter de l’oxygène dans l’atmosphère d’une exoplanète pour conclure à la présence de vie. Malheureusement, la nature sait produire de l’oxygène sans intervention biologique. Il existe de nombreux mécanismes dits abiotiques capables d’imiter certaines signatures du vivant.
On recherche donc des indices plus subtils : des déséquilibres chimiques. Sur Terre, par exemple, l’oxygène et le méthane coexistent alors qu’ils devraient rapidement réagir entre eux pour former du dioxyde de carbone. S’ils restent présents simultanément, c’est parce que les organismes vivants les renouvellent en permanence. Une telle combinaison constitue une biosignature beaucoup plus convaincante qu’une seule molécule prise isolément.
L’actualité récente illustre parfaitement cette difficulté. En 2025, des observations réalisées avec le télescope spatial James-Webb sur l’exoplanète K2-18 b ont révélé la présence possible de molécules comme le sulfure de diméthyle (DMS), un composé qui, sur Terre, est principalement produit par le phytoplancton marin. L’annonce a suscité un immense enthousiasme, mais aussi de nombreuses réserves : les données restent limitées et les conclusions ont sans doute été tirées un peu trop rapidement. De plus, il est possible que ces molécules puissent être produites par des processus non biologiques. Cette étude rappelle qu’aucune molécule, à elle seule, ne peut aujourd’hui être considérée comme une preuve de l’existence de la vie. Il faudra réunir plusieurs indices indépendants et convergents avant de pouvoir revendiquer une détection crédible.
Une autre approche consiste à observer directement la lumière réfléchie par une planète. Sur Terre, les végétaux absorbent fortement la lumière rouge pour alimenter la photosynthèse, puis réfléchissent très efficacement le proche infrarouge. Cette transition brutale, appelée le « bord rouge » de la végétation (vegetation red edge), est visible lorsqu’on observe notre planète depuis l’espace. Si une biosphère extraterrestre exploitait elle aussi l’énergie de son étoile grâce à un processus analogue, elle pourrait laisser une signature similaire, même si ses organismes étaient très différents des plantes terrestres.
Aucune de ces observations ne suffira, à elle seule, à démontrer l’existence de la vie. Les astronomes devront croiser plusieurs indices : la composition de l’atmosphère, la présence éventuelle d’eau liquide, la nature rocheuse de la planète, son champ magnétique ou encore les propriétés de son étoile. Comme dans une enquête policière, c’est l’accumulation de preuves indépendantes qui permettra de construire un scénario crédible.
Les technosignatures : rechercher des civilisations plutôt que des microbes
On pourrait penser que les astronomes devraient concentrer tous leurs efforts sur la recherche de vie microbienne, probablement beaucoup plus abondante que les civilisations technologiques. Pourtant, les deux approches sont complémentaires.
Les biosignatures sont sans doute plus fréquentes, mais souvent ambiguës. Les technosignatures, elles, seraient probablement beaucoup plus rares, mais aussi beaucoup plus difficiles à expliquer autrement. Si nous recevions un signal radio contenant les décimales du nombre π ou une suite de nombres premiers, le doute serait permis bien moins longtemps.
Depuis les années 1960, les recherches regroupées sous le nom de SETI (Search for Extraterrestrial Intelligence) scrutent le ciel à la recherche de signaux radio artificiels. L’idée est qu’une civilisation pourrait chercher à communiquer avec d’autres ou laisser s’échapper involontairement des émissions, comme nos propres transmissions radio et télévisées fuient dans l’espace depuis près d’un siècle.
À ce jour, aucune détection n’a été confirmée. Le célèbre « signal Wow ! », enregistré en 1977 par un radiotélescope de l’Ohio State University, est une émission radio de 72 secondes très intense et de bande étroite provenant de la constellation du Sagittaire. Son caractère inhabituel a suscité de nombreuses spéculations, mais son origine demeure inconnue. Surtout, l’absence de toute nouvelle détection similaire empêche d’y voir une preuve convaincante d’une civilisation extraterrestre.
Aujourd’hui, des chercheurs explorent un éventail beaucoup plus large de technosignatures. Une planète couverte d’éclairages artificiels pourrait produire une émission lumineuse inhabituelle. Une civilisation très avancée pourrait construire d’immenses infrastructures destinées à exploiter l’énergie de son étoile, comme les sphères de Dyson, un hypothétique immense ensemble de satellites collecteurs répartis autour de l’étoile pour en récupérer une grande partie de l’énergie. Il est également envisageable de rechercher des polluants industriels impossibles à produire naturellement, des faisceaux laser utilisés pour communiquer, voire des constellations de satellites semblables au réseau Starlink.
Une quête qui ne fait que commencer
Le télescope spatial James-Webb inaugure une nouvelle ère en permettant de sonder les atmosphères d’exoplanètes avec une précision jamais atteinte. Mais les instruments actuels restent encore limités.
La prochaine révolution viendra probablement de l’Extremely Large Telescope (ELT), actuellement en construction au Chili. Avec son miroir de 39 mètres de diamètre, il pourra analyser en détail l’atmosphère de petites planètes rocheuses situées autour d’étoiles proches. Les futurs observatoires spatiaux iront encore plus loin. Ensemble, ils permettront de tester des biosignatures toujours plus subtiles et d’éliminer progressivement les explications alternatives.
La découverte d’une vie extraterrestre ne prendra probablement pas la forme d’une photographie spectaculaire ou d’un unique signal mystérieux. Elle résultera plutôt d’une accumulation patiente d’indices, confrontés pendant des années à toutes les explications possibles.
Pour la première fois de l’histoire, la question « Sommes-nous seuls dans l’Univers ? » n’appartient plus seulement à la philosophie. Elle est devenue une question scientifique. Et les prochaines décennies pourraient enfin nous apporter les premiers éléments de réponse.
Pour en savoir plus sur cette quête de la vie extraterrestre, vous pouvez consulter le livre de Quentin Kral, Les Astronomes à la recherche de la vie extraterrestre, aux éditions Ellipses, 2025.
Quentin Kral est l'auteur de l'ouvrage : « Les astronomes à la recherche de la vie extraterrestre » aux éditions ellipses.
07.07.2026 à 15:53
Comment les constellations de satellites pourraient transformer la surveillance climatique
Mustapha Meftah, Chercheur au LATMOS/CNRS/UVSQ/SU et professeur à l'UVSQ, spécialisé en physique solaire, sciences de l'atmosphère, instrumentation spatiale et missions satellitaires, Sorbonne Université
Alain Sarkissian, 11 Boulevard d'Alembert, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Philippe Keckhut, vice-président innovation, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Texte intégral (2863 mots)
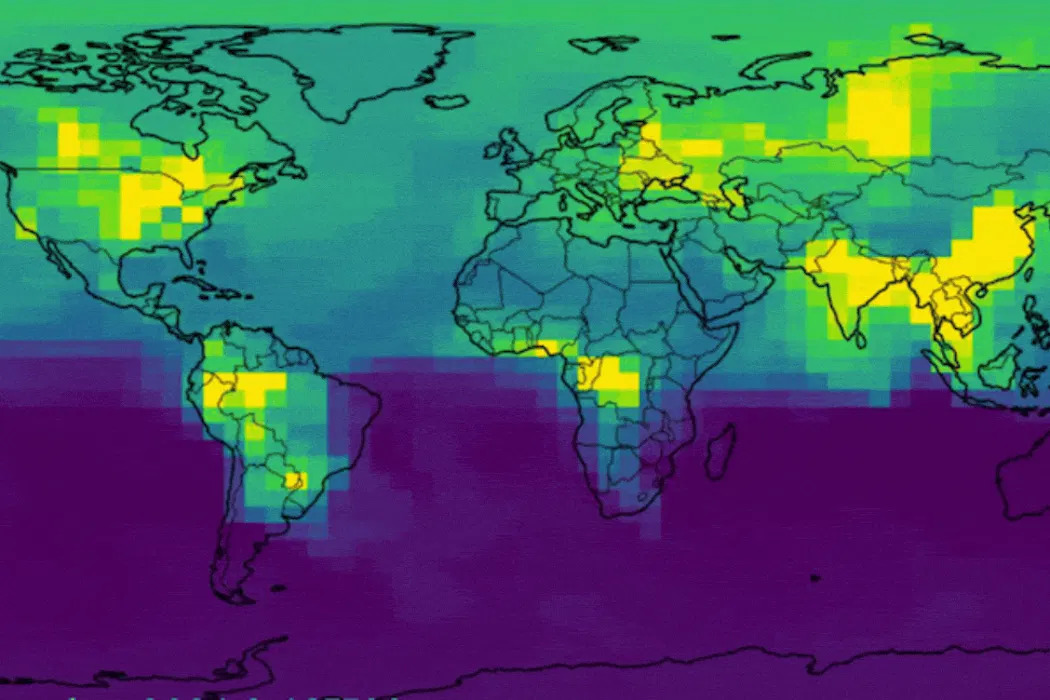
Pour détecter et réguler les émissions responsables du changement climatique, certains phénomènes doivent désormais être suivis en temps réel, ou presque. Une solution consiste à démultiplier les instruments d’observation grâce à des constellations de satellites. Mais comment faire en sorte que ces constellations à but scientifique ne provoquent pas plus de problèmes qu’elles ne contribuent à en résoudre ?
Les satellites sont devenus indispensables pour observer le changement climatique. Ils mesurent les gaz à effet de serre, surveillent les incendies, observent les nuages et suivent l’évolution des océans.
Mais certains phénomènes évoluent plus vite que le rythme des observations spatiales, ce qui rend leur observation plus difficile. Ainsi, un incendie, un épisode de pollution ou une fuite de méthane d’origine anthropique (provenant par exemple d’infrastructures pétrolières et gazières, de mines de charbon ou de centres d’enfouissement) peuvent évoluer plus rapidement que le temps nécessaire à un satellite pour observer à nouveau une même région. Des étapes clés de leur évolution peuvent alors être manquées, retardant leur détection, leur localisation et les interventions visant à en limiter les impacts.
C’est pour cela que la fréquence des observations satellitaires devient désormais presque aussi importante que leur précision. Une des pistes explorées consiste à déployer des constellations de satellites afin d’augmenter fortement la fréquence des mesures depuis l’espace. Dans cette approche, l’objectif n’est plus seulement d’utiliser quelques satellites très performants, mais également d’observer la Terre beaucoup plus fréquemment grâce à des constellations composées de dizaines, voire de centaines de satellites.
Être précis ou être rapide : le compromis des observations satellitaires actuelles
Ces nouvelles approches s’inscrivent dans la continuité des grandes missions spatiales d’observation du climat, telles que OCO-2, GOSAT ou la famille des satellites Sentinel du programme Copernicus, qui fournissent déjà des données essentielles pour suivre l’évolution de l’atmosphère et du cycle du carbone. La plupart de ces missions reposent sur un nombre limité de satellites.


{kind=link}
La mesure des gaz à effet de serre depuis l’espace est aujourd’hui considérée comme un enjeu majeur par les grandes organisations internationales de surveillance de la Terre, comme le Groupe d’observations de la Terre (en anglais, Group on Earth Observations, GEO) ou le Comité d’observation satellite de la Terre (Committee on Earth Observation Satellites, CEOS).
Pour répondre à ce besoin, plusieurs missions spatiales sont aujourd’hui en opération, telles que OCO-2, GOSAT ou Sentinel-5P, tandis que d’autres, comme CO2M, sont en préparation. Elles visent à mesurer les concentrations de gaz à effet de serre avec une précision toujours plus élevée. Certaines missions atteignent une précision de l’ordre de 1 partie par million (1 ppm) sur la concentration atmosphérique de CO₂, une performance nécessaire pour estimer les sources et les puits de carbone et mieux quantifier les échanges de CO₂ entre l’atmosphère, les océans et les continents.
Mais cette précision s’accompagne d’un compromis : pour obtenir des mesures très précises et une résolution spatiale élevée, les satellites observent généralement une bande de terrain de largeur limitée, ce qui augmente le temps nécessaire pour observer à nouveau une même région. C’est précisément cette limite que les constellations cherchent à dépasser en multipliant le nombre de satellites en orbite.
Le méthane réchauffe l’atmosphère bien plus rapidement que le CO₂, mais ses émissions évoluent trop vite pour les observations actuelles
Le méthane illustre particulièrement cette difficulté. Selon le Groupe d’experts intergouvernemental sur l’évolution du climat (Giec), le méthane réchauffe l’atmosphère environ 80 fois plus que le CO₂ sur une période de vingt ans. Réduire rapidement les émissions de méthane constitue donc un levier important pour limiter le réchauffement climatique à court terme. Le suivi du méthane repose sur la combinaison des observations satellitaires et des modèles de transport atmosphérique, qui permettent d’estimer la dispersion du méthane et l’évolution de ses émissions à l’échelle globale.

Les satellites permettent déjà de détecter certaines émissions depuis l’espace. Sentinel-5P/TROPOMI fournit par exemple une couverture quotidienne globale permettant d’identifier de grands « super-émetteurs » régionaux. D’autres instruments, comme Sentinel-2 ou certains imageurs hyperspectraux, permettent d’observer des émissions beaucoup plus localisées.
Mais certaines émissions restent intermittentes. Une fuite de méthane peut apparaître puis disparaître entre deux observations. Pour les agences environnementales comme pour les industriels, disposer de mesures plus fréquentes devient essentiel afin de localiser rapidement ces émissions et de répondre aux nouvelles exigences de surveillance et de déclaration des émissions de gaz à effet de serre (GES), dans le cadre notamment du CBAM européen.
La fréquence d’observation, grand intérêt scientifique des constellations de satellites
C’est précisément l’intérêt des constellations de satellites. Contrairement aux missions spatiales traditionnelles, qui reposent sur quelques plates-formes complexes, ces architectures utilisent plusieurs dizaines de satellites plus petits répartis sur plusieurs plans orbitaux, généralement à des altitudes comparables. L’objectif est moins de maximiser la performance de chaque satellite que de multiplier les observations au cours d’une même journée. Selon les caractéristiques des instruments embarqués, une constellation d’une vingtaine à quelques dizaines de satellites peut ainsi réduire le temps de revisite de plusieurs jours à quelques heures.
Les avancées dans la miniaturisation des satellites et des instruments rendent désormais possibles des capteurs scientifiques plus petits, plus légers et moins coûteux. Cette miniaturisation permet de développer des capteurs adaptés à des besoins d’observation ciblés, sans chercher systématiquement à maximiser les performances ni la complexité des instruments.
S’intégrer dans des constellations de télécommunications
Une autre évolution pourrait également transformer l’observation du climat : l’intégration de capteurs scientifiques miniaturisés à bord des satellites appartenant à des constellations de télécommunications. Cette approche est notamment étudiée dans le cadre des futures générations de satellites d’Eutelsat-OneWeb, qui pourraient accueillir des charges utiles auxiliaires.
Plutôt que de lancer une constellation scientifique entièrement dédiée, avec les enjeux associés en termes de débris spatiaux, d’occupation des orbites et de pollution lumineuse, il deviendrait possible d’embarquer de tels instruments à bord de ces satellites.
Ces infrastructures pourraient ainsi servir à la fois aux télécommunications et à l’observation du climat, en mutualisant les plates-formes et les lancements, ce qui pourrait réduire significativement les coûts par rapport à une constellation scientifique entièrement dédiée, tout en augmentant la fréquence des observations.
Ces nouvelles approches ne remplaceraient pas les grandes missions climatiques institutionnelles, indispensables pour garantir la stabilité et la qualité scientifique des mesures de référence. Elles pourraient en revanche compléter les infrastructures existantes grâce à des observations beaucoup plus fréquentes de la Terre.

La mission française UVSQ-SAT NG, développée par le laboratoire Atmosphères, observations spatiales (LATMOS), s’inscrit dans la continuité des missions UVSQ-SAT et INSPIRE-SAT 7, deux nanosatellites démonstrateurs dédiés à l’observation du bilan radiatif de la Terre.
UVSQ-SAT NG teste de nouvelles approches de miniaturisation pour l’observation du bilan radiatif terrestre et de certains gaz à effet de serre depuis une plateforme nanosatellite. Cette mission n’est pas intégrée à une constellation de télécommunications ; elle constitue un démonstrateur technologique destiné à préparer de futures architectures de constellations scientifiques. Les données de ces missions sont accessibles librement à la communauté scientifique et au public sur la plateforme NAHLA.
Mustapha Meftah a reçu des financements de l'Agence nationale de la recherche (ANR).
Alain Sarkissian a reçu des financements de l'Agence nationale de la recherche (ANR).
Philippe Keckhut a reçu des financements de l'ANR pour le projet Compétences et Métiers d'Avenir France2030; Académie Spatiale
06.07.2026 à 15:47
La sécurité des drones militaires, ou comment protéger ce qui compte (et ce n’est pas toujours le drone lui-même)
Serge Chaumette, Professeur des Universités en Informatique, chercheur au LaBRI (Laboratoire Bordelais de Recherche en Informatique) et responsable des activités drones de ce laboratoire, Université de Bordeaux
Damien Sauveron, Professeur des Universités en Informatique à la Faculté des Sciences et Techniques, Université de Limoges
Texte intégral (2420 mots)
Sur les théâtres d’opération militaire, les drones évoluent dans un environnement hostile où ils doivent avant tout protéger les troupes qu’ils accompagnent. Pour mener à bien cette mission, ils déploient des stratégies qui leur offrent une certaine résilience, le but n’étant finalement pas de les protéger pour eux-mêmes, mais de leur permettre d’accomplir leur tâche coûte que coûte. Leur propre protection n’est qu’un enjeu secondaire : on les dit sacrifiables.
Face aux vulnérabilités de ces nouveaux acteurs des conflits militaires, on se trouve devant un jeu du gendarme et du voleur où le gendarme court après de nouvelles solutions pour se protéger du voleur alors que le voleur cherche de nouvelles failles lui permettant de mettre à mal les stratégies développées par le gendarme.
La guerre en Ukraine a suscité un regain d’intérêt des forces armées pour les drones, en particulier de taille petite et moyenne, qu’ils soient unitaires ou en essaim. On le constate quotidiennement, ils sont partout sur le champ de bataille et constituent un atout majeur pour les forces : ils portent le feu pour elles vers les lignes ennemies, mais surtout ils les renseignent, leur évitent une exposition inutile, les protègent.
Mais comment assurer leur propre protection afin de garantir leur disponibilité face aux attaques de l’ennemi et à la « guerre électronique », qui sert parfois de prélude aux opérations cyber (opérations visant à mettre à mal, voire à pirater, leurs composants matériels ou logiciels) ? Des technologies et des stratégies existent, qui se construisent dans les laboratoires de recherche académiques, dans les start-up et les entreprises spécialisées et, pour certaines, au jour le jour sur le front (ukrainien, en particulier).
Mais tout d’abord, précisons qu’un drone est rarement isolé. Les drones sont la plupart du temps pilotés par un opérateur distant, généralement au sol. Le pilote et les équipements informatiques nécessaires à l’analyse des données collectées et au suivi de la mission sont hébergés, selon la terminologie militaire, dans un C2 (Command and Control), souvent un camion ou un bâtiment où se trouvent les équipements et les personnels nécessaires.
Pour en assurer la sécurité, il faut donc envisager les drones comme des systèmes à plusieurs composantes, au-delà de l’aéronef lui-même.
La résilience, un enjeu civil et militaire
Quand on parle de protection du drone, on parle avant tout de sa résilience, c’est-à-dire de la capacité du système à conserver un fonctionnement aussi nominal que possible face à un environnement ou à des événements hostiles. Cette hostilité peut être le fait de l’action volontaire d’un ennemi, qui va tout faire pour perturber leur fonctionnement en intervention ; mais elle peut également être liée à la nature même de certaines missions, par exemple la surveillance de zones forestières pour la lutte contre les incendies de forêt, qui peuvent conduire le drone à s’approcher ou à survoler des « zones interdites de fréquences » (terrains militaires, aéroports, centrales nucléaires, etc.). Dans ces zones, il est impossible ou interdit de communiquer en utilisant des ondes radio. Il faut être capable de s’adapter à cette contrainte, d’être résilient face à elle.
Il est toutefois plus ou moins critique qu’un système de drone soit résilient, selon les cas : un appareil suffisamment petit, peu coûteux, et que l’on sait produire en masse, peut être perdu sans grande conséquence.
Le premier objectif de la résilience est d’assurer à un drone la capacité à mener à bien sa mission. Certains drones, par exemple, jouent le rôle d’éclaireurs : le succès de leur mission conditionne le bon déroulement des opérations qui s’ensuivent. C’est le cas également dans un cadre civil, par exemple pour le transport de matières biologiques ou d’organes nécessaires à des greffes.
Il faut parfois également respecter certaines contraintes, par exemple conserver la confidentialité des données transportées, qu’elles soient collectées pendant la mission ou nécessaires à la mission elle-même. Par exemple, le plan de vol (c’est-à-dire les différents points GPS que le drone doit atteindre successivement) peut être une information sensible, dont il est nécessaire d’assurer la confidentialité, la disponibilité et/ou le retour en fin de mission, même en cas de perte ou de dégradation de certains composants matériels ou logiciels du système.
Comme nous l’avons vu, les drones et leur environnement constituent un système complexe et donc fragile par définition. Ces fragilités se situent à tous les niveaux : interne, externe et au niveau des interconnexions entre les éléments du système (drone, opérateur, C2, etc.).
Les fragilités internes
Les fragilités internes concernent aussi bien l’électronique que le logiciel embarqué. Par exemple, l’électronique peut être victime d’attaques par des « fusils électromagnétiques », qui utilisent des micro-ondes pour détruire certains circuits. Des approches à base de laser se développent aussi. Ces attaques peuvent conduire à la perte totale d’un appareil et peuvent aussi provoquer des failles propices à une attaque cyber (qui peut être effectuée en vol, mais plus aisément au sol après capture de l’appareil) : modifier des données en mémoire grâce à un rayonnement peut aider à faire apparaître une faille logicielle qui sera exploitée par la suite.
Les drones, comme tout autre système, ne sont pas exempts de bugs logiciels ou de sécurités défaillantes par construction. Une conséquence qui peut s’avérer fatale est, par exemple, la survenue d’un flyaway : le drone part vers une destination non prévue. Ce type de bug peut aussi avoir une composante matérielle. De manière plus globale, la perte de contrôle d’un appareil représente 36 % des accidents, toutes causes confondues.
Les attaques externes, un enjeu majeur
Les attaques externes consistent pour un ennemi à cibler les interactions entre le système et le monde extérieur, par exemple le système de navigation par satellite (souvent dénommé abusivement GPS – Global Positioning System, qui est le système américain – au lieu de GNSS pour Global Navigation Satellite System) ou la radio (que le drone utilise pour communiquer avec une station au sol).
Le GPS peut être brouillé – auquel cas le signal reçu n’est plus exploitable : le drone n’est alors plus en mesure de connaître sa position effective. Il devient inutilisable : on parle d’environnement « GNSS denied », c’est-à-dire d’environnement dans lequel le GNSS ne peut pas être utilisé. Cela peut par exemple conduire à sa capture : les forces armées iraniennes, en 2011, ont capturé un drone américain RQ-170 Sentinel de cette façon. En Ukraine, nombreuses sont les zones dans lesquelles le signal GPS est soit inexistant, soit brouillé et devient donc inutilisable pour naviguer.
Ce phénomène a également été observé sur des événements de type show lumineux, à Shanghai par exemple, où des dizaines de drones sont allés se poser de manière inopinée sur des bateaux situés à proximité.
Les attaques d’interconnexion
Les attaques d’interconnexion portent sur l’interface du drone avec les autres éléments du système, typiquement sur ses échanges avec la station sol, et donc sur le lien radio.
Elles peuvent par exemple consister à envoyer des ordres contrefaits ou à transmettre des données erronées vers la station au sol. Le composant cible croit échanger avec un autre composant légitime alors qu’il échange avec un attaquant. Il devient ainsi possible d’exploiter les captations vidéo d’un drone pour déterminer la localisation de sa base de lancement, puis de la prendre pour cible.
Les solutions : un puzzle de stratégies
Tout d’abord, pour ce qui concerne les problématiques clés, il existe de nombreux travaux de recherche fondamentale.
Aujourd’hui, les spécialistes travaillent en particulier sur la capacité à poursuivre la navigation en environnement GNSS denied et sur la sécurisation des liens de communication drone sol-sol drone. En effet il est indispensable que les appareils disposent de solutions de repli en environnement GNSS denied. Des approches algorithmiques reposant sur une analyse fine et un filtrage des signaux reçus, des antennes spécifiques et même des approches de type IA permettent de traiter certaines attaques.
En cas d’échec de ces stratégies de remédiation, l’utilisation d’amers (terme de navigation faisant référence à des points de repère fixes) permet de se repérer en s’accrochant visuellement à des points au sol. C’est souvent une combinaison de plusieurs de ces techniques qui permet en cas de perte de la disponibilité de l’une d’entre elles d’assurer la résilience du système.
Pour ce qui est de la radio, qui en plus d’être inutilisable (neutralisée ou interdite), peut être exploitée pour localiser un C2, des stratégies sont étudiées ou déjà mises en œuvre. Par exemple, des fibres optiques reliant un télépilote à son appareil pour communiquer en lieu et place de la radio ont été expérimentées en Ukraine. À plus long terme, des approches quantiques permettront de sécuriser ces communications de manière efficace.
Pour d’autres problématiques, des stratégies existent déjà, et peuvent être exploitées. Leur coût en revanche peut ne pas être négligeable. Un compromis coût/capacité de résilience est donc à trouver.
De manière plus méthodologique, il existe des processus de certification permettant de valider la conformité à la réglementation en vigueur, laquelle intègre par nature une notion de résilience. Les enjeux sont différents dans le domaine militaire : ceux-ci n’échappent évidemment pas à toute réglementation, mais la résilience est plus focalisée sur le succès de la mission que sur la sécurité de l’environnement dans lequel elle se déroule, comme discuté dans cet article.
Il s’agit dans ce cas de développer des solutions au plus vite, de les tester, de les valider et de les déployer.
La première étape consiste à valider chaque sous-système et à mesurer son TRL (Technology Readiness Level – niveau de maturité de la technologie). On évalue ensuite la capacité de chaque sous-système à s’intégrer avec d’autres, son IRL (Intégration Readiness Level – niveau de maturité d’intégration) ; puis on intègre le système et on évalue son SRL (System Readiness Level – niveau de maturité du système global). Ces mesures sont loin d’apporter des garanties universelles, mais elles permettent déjà d’assurer une qualité significative du produit final.
Rappelons, enfin, que les drones de petite et moyenne taille, objets technologiques pourtant anciens, n’ont révélé tout leur potentiel militaire que récemment. Il faut donc garder en tête qu’il ne faudra pas ralentir les efforts de recherche et les expérimentations quand les conflits actuels seront derrière nous.
Il en va de la capacité de ces systèmes à réaliser leurs missions, qui visent, redisons-le, à nous protéger lors d’éventuels futurs conflits.
Serge Chaumette a reçu des financements de l'ANR, de BPI, de l'AID, de l'EDA, des ARL (Army Research Labs), de l'ORNL (Office of Naval Research). Il est Professeur et Chercheur à l'Université de Bordeaux et conseille et détient des parts dans la société IcarusSwamrs.ai dont il est Directeur Scientifique. Il est membre du Comité Stratégique Drones et Nouveaux Usages du Pôle de Compétitivité Mondial Aerospace Valley et co-animateur du groupe Drones et Systèmes Autonomes du GIS Albatros (Groupement d'Intérêt Scientifique entre Thales et l'Université de Bordeaux). Enfin, il collabore ou pilote de nombreux projets avec des partenaires académiques, industriels et institutionnels dans le monde du drone.
Damien Sauveron a reçu des financements de l'ANR (notamment pour le projet PANDRONE dédié à la sécurité des flottes de drones), du CNRS (PEPS TRUSTED), de la Région Nouvelle-Aquitaine et de la fédération de recherche MIRES. Dans le cadre de ses collaborations industrielles passées, ses travaux sur les flottes de drones ont également été soutenus par Thales (projet NetCod). Il est Professeur des Universités en Informatique à l'Université de Limoges et chercheur au laboratoire XLIM (UMR CNRS 7252), dont il est Doyen Honoraire de la Faculté des Sciences et Techniques. Ses recherches portent sur la cybersécurité, les systèmes embarqués et la souveraineté des architectures autonomes. Enfin, il intervient comme expert auprès de la Commission Européenne.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview