
03.08.2026 à 16:08
Climate-related ‘silent adaptation’ coping strategies are going beyond official directives
Guillaume Simonet-Umaña, enseignant chercheur en adaptation aux changements climatiques, Université de Pau et des pays de l’Adour (UPPA)
Texte intégral (1495 mots)
Scientific reports, political directives and national plans follow one after another, urging regions to adapt to new climate realities. Yet, one question remains: how do adaptation initiatives among local communities and businesses actually unfold on the ground. While announcements of public or government-backed projects or regulatory frameworks often take centre stage, other, far more discreet grassroots forms of action or reorganisation are at work, which can be grouped under the term “silent adaptation”.
Behind this term lie numerous individual, corporate or collective initiatives, which, while not specifically designated or labelled as “adaptation”, are nevertheless gradually transforming organisations and regions. Taking these dynamics into account and gaining a better understanding of their nature could prove crucial in ensuring that public policies do not overlook aspects of the reality experienced on the ground by local communities and businesses.
Adaptation: a concept still seeking meaning in its practical application
Faced with a steady decline in his harvests, which are suffering from persistent mildew caused by erratic weather patterns, a winegrower based in France’s Aude department has been benefiting since 2021 from data collected by local weather stations. This, thanks to a technician working for the departmental Chamber of Agriculture. This valuable data enables him to anticipate adverse weather conditions as effectively as possible while awaiting INRAE’s (the National Research Institute for Agriculture, Food and the Environment, a public scientific agency) approval of new grape varieties that are more disease-resistant, which are being tested as part of a collaborative project.
Yet at no point does this winegrower refer to these measures as ‘actions for adapting to climate change’, even though they are helping his vineyard cope and keep up with the accelerating pace of new climate realities.
Long regarded as the “poor relation” of international and national climate policy agendas, adaptation to climate change is now becoming one of the most prominent terms. This is evidenced by the proliferation of national climate change adaptation plans, adaptation awards and the boom in scientific and media publications on the subject.
However, despite its stated priority in public climate policies, adaptation still faces several challenges when it comes to its operational implementation, not least of which is being recognised as such. For example, an artisan chocolatier who has no choice but to diversify and find new sources of cocoa following disastrous harvests affecting their usual supplier in Côte d’Ivoire is unlikely to describe their approach as adapting to climate change.
For many professionals working in the emerging field of climate change resilience, adaptation is often nothing more than an update to “Risk Management 3.0”, bolstered by new technical tools for forecasting, which are gradually being supplemented by regenerative AI. Colour-coded maps featuring statistical data derived from increasingly sophisticated climate models are then presented as the basis for the client to develop an action plan.
However, this “top-down” approach was questioned as early as 2004 by researchers
Suraje Dessai and Mike Hulme regarding its relevance in terms of operationalising adaptation. Consequently, despite the stated paradox of “transformation”, the objective is clear: to increase the resilience of ways of life that have been established over several generations in order to cope with a France that is 4°C warmer by around 2100.
But at local level, a different story is unfolding amongst communities who are increasingly facing severe weather events. For instance, at a French clinic in the Grand Est region (France), a circular confirmed that working hours could be adjusted during now-recurring heatwaves to protect staff and patients. At the same time, discussions are taking place at management level to assess the possibility of providing more suitable uniforms for care staff.
These are all measures that embody new practices, though the term “adaptation” is not used when speaking to those involved. The fact is that, in order to ensure the continuity of their services and long-term business viability, local authorities and businesses have very little room for manoeuvre: in practical terms, this means, above all, having to improvise in the face of mounting financial, technical or administrative constraints. Many local stakeholders are thus working quietly, off the radar of the administrative bodies that track, recognise or highlight the “top performers” in the field of adaptation.
Silent adaptation: standing apart from official guidelines
To describe the phenomenon that has regularly emerged from interviews and observations carried out over the last two decades with practitioners in the field, I have chosen the term “silent adaptation”, drawing on the work of the French philosopher François Jullien. To describe the continuous changes that lie at the heart of life – such as ageing or the evolution of feelings – François Jullien used the term “silent transformations” as early as 2009, a term he also applies to climate change: “what is climate change if not silent transformations, arising from an indefinite interplay of factors occurring infinitesimally and continuously on a global scale?”.
In turn, when viewed as a silent transformation, adaptation can thus be perceived as a process of continuous reorganisation through which system restructure themselves in response to climate change in order to ensure their viability.
Linking “adaptation” with “silent” also highlights a reality: many stakeholders make little use – whether intentionally or not – of the vocabulary associated with adaptation measures advocated in policy directives. Here, people do not communicate using terms such as “vulnerability assessments”, “exposures to hazards” or sensitivity factors". They monitor the weather on a day-to-day basis and take action according to the resources at hand by changing sowing dates, postponing construction work or clearing the banks of the nearby river.
The aim is then to operate within a time frame that will allow the activity to continue, maintain a good relationship with clients or mitigate the impact of the impending rainfall. The temporal horizon ranges from the day before to the day after right up to “next time”. The spatial horizon, meanwhile, is on the scale of 120m2 of the north wall of the 14th-century church, which is suffering from severe clay shrinkage and swelling; the scale of the four municipal staff members tasked with clearing the undergrowth on the western outskirts of the village. This string of successive initiatives put in place “to cope with such erratic weather” is unfolding across the area and forms part of the adaptation process.
In practical terms, these overlooked reorganisation efforts are all processes not explicitly designated as adaptations to climate change, which reveal themselves through practice rather than decree: fearing another summer “like last year’s”, the estate agents’ office is trialling new opening hours during the summer months to ensure staff are offered thermal comfort.
For researchers surveying the field, these forms of action are more widespread than one might think. They differ from public action across several characteristics, including the absence of any official designation, maximum decentralisation and the optimisation of step-by-step learning: unable to reach the weekly market due to flooded roads, the mobile butcher for instance, makes enquiries about other markets by calling on his network to draw up a new annual schedule that takes recurring weather-related obstacles into account.
Adapting also means listening to what is taking shape quietly, often behind the scenes.
The illusion lies in believing that the tangibility of high-profile adaptation offers a sense of security. Yet silence also has the potential to build on our resilience to inhabit the world and this is gradually happening each day before our very eyes. In its pursuit of efficiency, public policy could gain a great deal from ceasing to regard local actors as passive recipients of master plans they have devised for them.
Guillaume Simonet-Umaña is a coordinator of the Reconnexion - Expertise Climat Occitanie association.
03.08.2026 à 16:07
La souveraineté énergétique passe-t-elle forcément par l’électrification ? L’exemple du solaire thermique, mieux développé dans d’autres pays pas forcément plus ensoleillés
Olivès Régis, Professeur en énergétique, Université de Perpignan Via Domitia
Texte intégral (1908 mots)
La guerre en Iran et le blocage du détroit d’Ormuz ont poussé le gouvernement Lecornu à accélérer la mise en œuvre de mesures inscrites dans la programmation pluriannuelle de l’énergie, dite PPE3. D’un objectif environnemental de réduction des émissions de CO₂, il est passé à un enjeu de souveraineté énergétique, « électrifier pour moins dépendre des énergies fossiles ».
Dans le secteur du bâtiment, ces mesures sont actuellement très en faveur des pompes à chaleur pour le chauffage et l’eau chaude sanitaire. Mais ce ne sont pas les seules solutions, comme le montre un regard sur quelques-uns de nos voisins européens, bénéficiant pourtant de moins d’ensoleillement, qui ont recours au solaire thermique – plus simple que le solaire photovoltaïque.
En France, l’eau chaude sanitaire, c’est-à-dire l’eau que nous consommons pour la douche essentiellement et la vaisselle éventuellement, consomme une énergie de 75 térawatts-heures (75 milliards de kilowatts-heures). Pour donner une idée, cette énergie correspond à l’électricité produite par un cinquième du parc nucléaire français. C’est le troisième poste de consommation d’énergie après le chauffage et l’électricité dans le secteur résidentiel. Ce poste occupe 10 à 20 % du budget énergie d’un ménage.
Alors que les efforts liés à la réglementation ont conduit à la réduction de la consommation d’énergie pour le chauffage, la part de l’eau chaude sanitaire subit plutôt une tendance à la hausse. Décarboner l’énergie dans le secteur du bâtiment nécessite donc de se pencher sérieusement sur les systèmes de production d’eau chaude sanitaire. Ceci nous amène à privilégier les systèmes électriques pour chauffer l’eau et à délaisser, forcément, les chaudières à gaz. Parmi ces systèmes électriques, on trouve les chauffe-eaux électriques, les plus répandus, et les chauffe-eaux thermodynamiques, beaucoup moins répandus mais deux à trois fois plus performants. Ces derniers ont actuellement le vent en poupe, car ils s’inscrivent très bien dans la Stratégie nationale bas carbone : le secteur du bâtiment y trouve donc une réponse intéressante à la question de souveraineté énergétique tout en respectant les impératifs écologiques.
Néanmoins, si l’électrification des usages est indispensable à la transition énergétique, elle ne doit pas faire oublier que d’autres types d’énergies renouvelables sont disponibles et exploitables pour fournir de la chaleur – elles pourraient permettre d’accroître notre souveraineté énergétique, de diversifier nos sources énergétiques pour ne pas dépendre d’un seul type d’infrastructure et de réduire nettement nos émissions de gaz à effet de serre.
La souveraineté passe-t-elle uniquement par l’électrification ?
Un chauffe-eau thermodynamique est une pompe à chaleur couplée à un ballon d’eau chaude. Grâce à son compresseur, la pompe à chaleur puise la chaleur dans l’air environnant et élève son niveau de température à environ 60 °C, température requise pour l’eau chaude sanitaire. Le rapport entre la chaleur nécessaire pour chauffer l’eau et l’électricité consommée est le coefficient de performance (COP). Pour un chauffe-eau électrique, le coefficient de performance est très proche de 1. Pour un chauffe-eau thermodynamique, le coefficient de performance dépend de la température de l’air extérieur. Généralement, les constructeurs affichent un coefficient de performance de 3. Cependant, on constate que lors des périodes froides à températures négatives, la résistance électrique prend le relais et le coefficient de performance se rapproche alors de 1. En conditions réelles, il est donc plutôt compris entre 2 et 3.
Ainsi, remplacer une chaudière au gaz ou un chauffe-eau électrique par un chauffe-eau thermodynamique apparaît comme un moyen efficace pour réduire la consommation d’énergie et s’extraire des inconvénients de l’énergie fossile : pollution, émissions de CO₂, dépendance aux pays producteurs, augmentation des coûts…
Des énergies renouvelables permettent également de chauffer l’eau et de diversifier nos ressources.
Dans le cas de la géothermie, au lieu de puiser la chaleur dans l’air extérieur, on exploite le fait que la température est stable dans le sous-sol et donc de la chaleur géothermique. Un chauffe-eau thermodynamique couplé à un forage géothermique peut avoir un coefficient de performance supérieur à 5. Beaucoup plus efficace, ce système requiert néanmoins un investissement plus élevé du fait du forage. Ce type de système reste tout de même intéressant dans l’habitat collectif, ou quand il permet de produire à la fois le chauffage et l’eau chaude sanitaire : on parle alors de « système combiné ».
Au-delà de la géothermie, le soleil aussi peut chauffer l’eau.
Comment marche un chauffe-eau solaire thermique ?
La technologie fait appel à des capteurs solaires thermiques : du cuivre pour les tubes, du verre à l’avant pour éviter le refroidissement tout en laissant passer les rayons du soleil, un isolant thermique à l’arrière, une armature en aluminium pour tenir le tout. Cette technologie simple, mature et efficace, peut être fabriquée localement. Elle est très différente du solaire photovoltaïque, qui génère de l’électricité mais nécessite des matériaux bien plus complexes et des cellules produites majoritairement en Asie.
Aux capteurs solaires thermiques, on ajoute un ballon de stockage, une petite pompe servant de circulateur et un boîtier électronique commandant la pompe selon la différence de température entre le ballon et la sortie du capteur.
Ainsi, la chaleur collectée par les capteurs solaires est transmise à un fluide caloporteur. Ce fluide, généralement de l’eau glycolée, cède sa chaleur à l’eau contenue dans le ballon avant de retourner dans les capteurs. Dans les régions qui ne subissent que quelques jours de gel dans l’année, il est même possible de se passer d’eau glycolée et d’utiliser directement l’eau du réseau.
Le ballon est muni d’une résistance électrique qui sert d’appoint pour pallier les journées sans soleil. Une installation typique est constituée de 4 mètres carrés de capteurs solaires et d’un ballon de 200 à 300 litres.
Un potentiel important mais sous-exploité
Résultat : un chauffe-eau solaire à Lille permet de couvrir près de 65 % des besoins en eau chaude sanitaire, à Besançon 71 %, à Orléans 72,5 %, à Bordeaux 76 % et à Nice 85 % (soit une moyenne nationale de 75 %). Ce système possède ainsi un coefficient de performance dépendant certes de l’ensoleillement, mais toujours compris entre 3 et 8, et donc supérieur à celui d’un chauffe-eau thermodynamique.
En 2024, la surface de capteurs en France hexagonale était de 2,457 millions de mètres carrés, utilisés essentiellement pour des chauffe-eau solaires individuels. Avec une moyenne de 4 mètres carrés installés, cela conduit à environ 600 000 installations – ceci correspond à moins de 2 % de l’ensemble des systèmes de chauffe-eaux.
En d’autres termes, le solaire thermique est peu déployé, alors que la ressource solaire disponible est suffisante pour assurer de 65 à 85 % des besoins en eau chaude sanitaire. Malheureusement, comme les énergies renouvelables thermiques sont très facilement et trop souvent oubliées (nous privilégions en France des technologies plus complexes et énergivores), le marché du solaire thermique est plutôt moribond.
Pour illustrer ce propos, comparons avec le scénario établi en 2029 par RTE (Réseau de transport d’électricité). Dans ce scénario, il s’agissait de remplacer de 9,5 millions de chauffe-eaux électriques et de chaudières à gaz par des chauffe-eaux thermodynamiques, afin d’aboutir à une économie d’énergie annuelle de 3 térawatts-heures et une réduction des émissions de CO₂ annuelles de 800 000 tonnes.
Par comparaison, nous estimons qu’installer 9,5 millions de chauffe-eaux solaires aboutirait à 16 térawatts-heures d’économies d’énergie annuelles et près de 5 millions de tonnes de CO₂ évitées par an. Les gains seraient très nettement supérieurs au scénario proposé par RTE.
Une solution rentable économiquement et déployée dans des pays moins ensoleillés
Mais est-il possible – et raisonnable – d’installer 9,5 millions de chauffe-eaux solaires ? Ceci correspondrait à 30 % des foyers (il y a 31 millions de ménages en France).
Ce n’est pas si éloigné de ce qui est fait en Autriche, où environ 27,5 % des foyers auraient installé des chauffe-eaux solaires (1,15 million d’installations pour 4,18 millions de ménages). En effet, n’étant pas dotée de centrale nucléaire, l’Autriche souhaite décarboner son énergie mais sans forcément passer par l’électricité. Elle a choisi de privilégier les technologies les mieux adaptées aux usages et en particulier à la production de chaleur à 60 °C, qui convient très bien au solaire thermique. Ce n’est donc pas étonnant que le plus grand fabricant de capteurs solaires thermiques soit autrichien !
Notons qu’en termes d’ensoleillement, les Autrichiens ne sont pas mieux dotés que les Français – c’est même plutôt l’inverse. Les Autrichiens reçoivent entre 1 000 et 1 200 kilowatts-heures d’énergie solaire par mètres carrés et par an, alors que les Français en reçoivent entre 1 000 et 1 800 kilowatts-heures par mètres carrés et par an.
Le solaire thermique intéresse plus globalement de plus en plus de nos voisins européens, Allemagne et Danemark en tête. On constate une augmentation du nombre de réseaux de chaleur urbains, de centres aquatiques et d’industries alimentés par des capteurs solaires thermiques.
La stabilité du coût de la chaleur ainsi produite explique cet intérêt grandissant : il ne dépend que des investissements et de la ressource solaire.
Les mesures gouvernementales françaises pourraient davantage favoriser ces technologies, qui répondent véritablement aux enjeux environnementaux, économiques et de souveraineté énergétique.
Olivès Régis a reçu des financements de l'ANR.
03.08.2026 à 16:05
Redessiner le monde pour mieux le comprendre : le pouvoir politique des contre-cartes
Patty Heyda, Professor of Urban Design and Architecture, Washington University in St. Louis
Texte intégral (2979 mots)
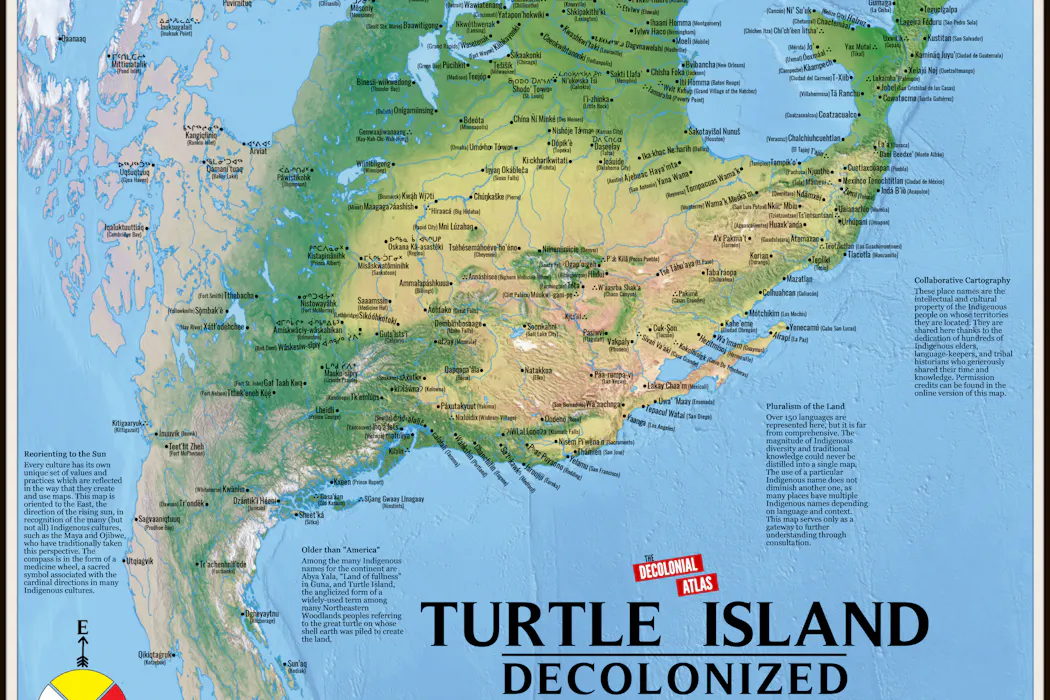
Les cartes ne se contentent pas de représenter le monde : elles contribuent à le façonner. Longtemps utilisées pour asseoir le pouvoir politique, économique ou colonial, elles peuvent aussi, en réintroduisant les informations omises et en croisant des données rarement associées, révéler les inégalités, les exclusions et les rapports de force invisibles qui structurent nos territoires.
À travers l’histoire, les cartes ont été des outils précieux pour les puissants, leur permettant d’affirmer leur emprise sur des territoires et des marchés. Les responsables politiques engagent des batailles de redécoupage électoral à l’échelle nationale afin de garantir le contrôle de leur camp, affaiblissant ainsi le pouvoir des électeurs. Les postures géopolitiques de l’administration Trump à propos du Groenland s’inscrivent dans une longue histoire de l’impérialisme appuyé par les cartes. Et dans la Rome antique, la table de Peutinger représentait une vision immense de l’Empire en plaçant Rome au centre du monde.
Mais les cartes peuvent aussi raconter des histoires cachées sur la politique et le pouvoir, permettant aux populations de se réapproprier leurs espaces et leur avenir. C’est notamment le cas des contre-cartes – c’est-à-dire des cartes qui remettent en question les présupposés existants – en élargissant les récits dominants sur un lieu pour y intégrer des points de vue jusque-là exclus.
Comme urbaniste, architecte, cartographe et chercheuse en politique de l’espace, j’ai pu constater de quelle manière les cartes façonnent les espaces urbains et les récits que l’on construit à leur sujet. J’ai également vu comment elles peuvent remettre en question ces récits et faire émerger d’autres significations d’un lieu, portées par les habitants et les travailleurs qui l’occupent au quotidien.
Bien plus que de simples outils numériques d’orientation, les cartes sont des instruments stratégiques de construction du monde. Elles montrent que certaines idées ou frontières que l’on croit immuables peuvent en réalité être rendues flexibles. Chacun peut créer une carte et, parce qu’elles sont des outils de narration spatiale, les possibilités qu’elles révèlent sur les lieux sont pratiquement infinies.
Qui fabrique les cartes ?
Le géographe Mark Monmonier est célèbre pour avoir expliqué comment mentir avec les cartes. Il soulignait que les producteurs de cartes disposant d’un pouvoir important, qu’il s’agisse des gouvernements ou des entreprises, recourent à une sélection des informations afin de promouvoir des objectifs particuliers ou de diffuser une image de marque.
Les cartes routières de Shell Oil des années 1950 constituent un exemple révélateur de l’utilisation des cartes comme outil marketing. Arborant un grand logo en couverture et la rose des vents aux couleurs de Shell à l’intérieur, ces cartes étaient distribuées gratuitement dans les stations-service à travers le pays. Elles faisaient la promotion de la marque tout en facilitant les déplacements en automobile grâce à la représentation des routes et des principaux points de repère. Au verso figuraient également des tableaux de kilométrage permettant aux automobilistes de planifier leurs arrêts pour faire le plein. En revanche, ces cartes passaient sous silence les réseaux de transport concurrents, comme les lignes d’autobus.

Les institutions publiques et les organismes nés de partenariats public-privé utilisent également des cartes pour promouvoir certains agendas politiques. Ainsi les cartes de redlining (une pratique consistant à exclure certains quartiers de l’accès au crédit immobilier) de la Home Owners’ Loan Corporation des années 1930 montrent de manière particulièrement explicite comment les pouvoirs publics et le secteur immobilier se sont servis des cartes pour exclure certaines communautés. Réalisées pour la quasi-totalité des grandes villes américaines, elles identifiaient comme risqués pour les prêteurs les quartiers où vivaient les Afro-Américains, les excluant de fait de l’accès à la propriété.
Aujourd’hui encore, les opérations de redécoupage électoral partisan menées dans des États, comme le Texas ou la Floride, permettent de voir comment les cartes sont utilisées pour contrôler l’accès aux leviers de la démocratie. Ces redécoupages ont été réalisés en dehors du calendrier habituel du recensement afin de maximiser les chances d’obtenir davantage de sièges au Congrès lors des élections de 2026.
Recartographier les coulisses
Si les cartes servent à écarter systématiquement les quartiers minoritaires des marchés immobiliers, alors le fait de recartographier ces systèmes permet de mettre au jour les mécanismes par lesquels les pouvoirs publics et les acteurs privés organisent cette exclusion, ainsi que les bénéficiaires de celle-ci.
Dans mon livre, Radical Atlas of Ferguson, USA, je propose une nouvelle cartographie de cette ville américaine afin de montrer ce qui se joue en coulisses dans la planification régionale et municipale. Cette approche révèle pourquoi des inégalités aussi marquées continuent d’y perdurer.
La banlieue de Ferguson, située dans le nord du comté de St. Louis, s’est retrouvée sous les projecteurs en 2014 lorsqu’un policier blanc a abattu Michael Brown Jr, un adolescent noir non armé. La mobilisation suscitée par cette injustice a contribué à donner un nouvel élan au mouvement Black Lives Matter.
Dans les cartes réunies dans ce livre, j’ai superposé de nouveaux récits afin de mettre en lumière le contexte politique et économique complexe qui sous-tend la situation de Ferguson. Ainsi, l’historien Walter Johnson souligne que plusieurs grandes entreprises figurant au classement Fortune 500 sont implantées à quelques pâtés de maisons seulement de l’endroit où Michael Brown a été tué. Alors que ces entreprises bénéficient d’importantes exonérations fiscales et d’aides publiques destinées à soutenir leur développement immobilier, les dépenses municipales consacrées à des besoins essentiels, comme les écoles publiques ou les trottoirs, demeurent insuffisamment financées. En mettant en évidence ces différentes dimensions du territoire, les cartes peuvent révéler qui influence réellement la vision des urbanistes et des responsables politiques.

La recartographie aide les décideurs à mieux prendre conscience des biais présents dans les données qu’ils utilisent pour évaluer les quartiers et produire les cartes municipales. Les cartes présentant des données de criminalité apparemment objectives, par exemple, tendent souvent à renforcer les représentations du risque associées aux quartiers minoritaires. Mais lorsque les délits contre les biens recensés dans le nord du comté de St. Louis, où vit une majorité de résidents noirs, sont mis en regard des fraudes hypothécaires commises par des acteurs de la finance lors de la crise de 2008 – un jeu de données généralement absent des catalogues municipaux –, il apparaît clairement que cette zone a été spécifiquement ciblée par les prêteurs spécialisés dans les crédits hypothécaires (subprimes). Élargir la manière dont nous évaluons les données et leurs sources permet ainsi de déplacer l’attention vers les forces sous-jacentes qui produisent ces statistiques.
Le remapping (ou recartographie) permet également de croiser des couches d’information qui semblent, à première vue, sans rapport, afin de faire émerger de nouvelles connexions spatiales. Pourquoi, par exemple, la participation électorale est-elle si faible dans le quartier où Michael Brown a été tué ? Une carte combinant la répartition raciale de la population et l’emplacement des bureaux de vote révèle non seulement l’absence de bureau de vote dans le quartier majoritairement afro-américain, mais aussi l’existence de barrières physiques, notamment une voie ferrée surélevée et un corridor fluvial, qui compliquent l’accès des habitants à l’hôtel de ville et aux autres bureaux de vote.

Des cartes au service du public
À mesure que les détenteurs du pouvoir continuent de politiser les cartes, la pratique du remapping peut servir l’intérêt général en rendant ces systèmes de pouvoir plus visibles pour tous. Les contre-cartes ont inspiré de nombreux militants à réintroduire dans les récits dominants des informations qui en avaient été exclues.
Le cartographe Andrew Middleton m’a ainsi fait découvrir un exemple parlant : une relecture pétrofuturiste des cartes routières de Shell Oil. Ces contre-cartes représentent les routes figurant sur les cartes de Shell comme étant submergées en fonction des projections d’élévation du niveau de la mer liées au changement climatique – un phénomène principalement causé par la combustion des énergies fossiles produites par des entreprises telles que Shell.
Les cartes sont des représentations géographiques à échelle réduite, conçues pour être lisibles et utiles. Elles sont comprises par des personnes de tous âges. Elles communiquent visuellement au-delà des langues et sont faciles à transporter. Lorsque les cartes et les contre-cartes mettent au jour et superposent des relations autrement invisibles qui façonnent un lieu, elles contribuent à faire émerger de nouvelles formes de mémoire collective et proposent des conceptions plus riches et plus significatives de l’autorité publique.
Patty Heyda ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Goodtech.info
- Libre à lire (April)
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview