11.07.2026 à 11:34
La stratégie Ender de l’IA : le monde comme délégation et comme simulation.
Olivier Ertzscheid
Texte intégral (7351 mots)
Le (Large) langage (Model) de la guerre.
« Il faut désarmer l’IA » écrit le pape Léon XIV dans sa première encyclique, « Magnifica Humanitas« , publiée le lundi 25 Mai 2026. De fait et à l’occasion des récents conflits, de l’Ukraine à l’Iran en passant par Gaza, les technologies d’IA sont des puissances d’armement.
En première intention et sous les feux de la rampe autant que de ceux de la guerre, on a beaucoup parlé, ces derniers mois, de l’injonction faite par le gouvernement Trump aux grandes sociétés d’intelligence artificielle (IA) de se soumettre et d’accepter que leurs technologies soient utilisées dans le cadre de programmes militaires. Rien de vraiment nouveau car toutes les technologies et la plupart des industries (automobile par exemple) ont toujours été utilisées et mobilisées dans le cadre de guerres déclarées, ou en anticipation de celles pouvant l’être, y compris les fondements d’internet qui fut pour partie un projet de la DARPA.
Là où un changement de paradigme s’opère c’est qu’il s’agit cette fois de se plier (pour Anthropic et les autres) à l’utilisation de leur technologie d’IA, y compris pour la décision non-supervisée d’offensives et de ciblages à dimension létales, donc en clair pour tuer des gens de manière automatisée sur la base de choix dans lesquels la décision humaine n’est plus qu’un cadre de raisonnement parmi d’autres, ni déterminant ni déterministe, une variable d’ajustement de moins en moins requise, et de plus en plus systématiquement exclue de toute action ou réaction « en temps réel ».
Le patron d’Anthropic (Dario Amodei) a refusé de se plier à l’injonction qui lui était faite (refusant à la fois le cadre d’une utilisation létale et celui d’une surveillance de masse des populations). Trump l’a donc banni et mis sur liste noire, le privant notamment de juteux et décisifs financements étatiques. Dario Amodei a probablement vécu son moment « San Bernardino », à la manière dont Tim Cook (patron d’Apple) avait en 2015 refusé de baisser le niveau de sécurité de l’iPhone pour permettre au FBI d’accéder aux données du meurtrier de la tuerie de San Bernardino (à l’époque, il y a donc 10 ans, c’est pas rien à l’échelle des sujets dont on parle, j’avais pris un positionnement un peu … dissonant en posant la question suivante « un terroriste est-il un client Apple comme les autres ?« )
Dans une enquête de Bloomberg notamment relayée par une journaliste de la RTS sur X, on apprenait plus précisément ceci (je souligne) :
« L’image publique d’Anthropic repose sur une IA conçue pour servir l’humanité. L’entreprise refuse de franchir certaines lignes rouges, notamment celles des armes entièrement autonomes et de la surveillance de masse. Mais au début de l’année 2026, alors qu’Anthropic engageait un bras de fer avec le Département de la Défense sur les principes de son contrat en cours à 200 millions de dollars, l’entreprise soumettait une proposition pour remporter un concours du Pentagone doté de 100 millions de dollars.
L’objectif du programme était de produire une technologie permettant de superviser, par la voix, des essaims de drones létaux. Claude devait comprendre l’ordre vocal d’un opérateur humain et le convertir en instructions numériques pour coordonner la flotte de drones. Dans ce cas, l’humain donne une instruction globale. Une fois l’ordre transmis, les drones, grâce à leur propre intelligence artificielle en réseau, calculent leurs trajectoires d’approche et se répartissent les cibles sans intervention humaine.
Selon les sources internes citées par Bloomberg, la direction d’Anthropic estimait que cette utilisation respectait ses conditions d’utilisation car l’IA de ciblage létal est embarquée dans les drones eux-mêmes, pas dans Claude. Par conséquent, tant que l’opérateur conserve le pouvoir théorique d’interrompre le système, l’entreprise considère que l’arme n’est pas « entièrement autonome ».
Mais sur le terrain opérationnel, cette distinction relève davantage de la philosophie que de la balistique. Même si l’opérateur conserve la supervision et le pouvoir d’interrompre le système, il est techniquement impossible pour un humain de traiter assez d’informations pour l’utiliser à temps, face à la rapidité de calcul d’un essaim de drones propulsés par une intelligence artificielle en réseau. Le temps que l’opérateur comprenne que l’essaim a fait une erreur d’identification, la cible est déjà détruite. Dans l’imaginaire collectif, une armée de robots tueurs se représente souvent sous la forme d’androïdes humanoïdes lourdement armés, marchant au pas sur un champ de bataille. Or, le Pentagone ne cherche pas à reproduire le soldat humain, mais à le dépasser par la logique de l’essaim. (…) Il faut imaginer des centaines de petits drones, furtifs et peu coûteux. Animés par un modèle d’IA, ils communiquent entre eux en temps réel. Ils fonctionnent en réseau et se comportent comme une ruche. Si des drones sont abattus par l’ennemi, l’essaim recalcule instantanément sa géométrie et poursuit sa mission.
Leur objectif tactique est de saturer la cible. Ils sont conçus pour submerger les radars, épuiser les défenses anti-aériennes, traquer une cible sous une multitude d’angles simultanés et frapper de façon synchronisée.Cette stratégie s’inscrit dans le programme Replicator, annoncé en 2023 avec une promesse opérationnelle pour août 2025. Son objectif est de contrer l’avantage du nombre de l’armée chinoise en produisant des milliers de systèmes autonomes coordonnés par intelligence artificielle, sacrifiables et peu coûteux. C’est pour devenir le cerveau de ce type de chorégraphie qu’Anthropic avait proposé Claude.
Comme les sources de Bloomberg le rapportent, Anthropic n’était donc fondamentalement pas opposée au développement de systèmes autonomes, tant que la définition de l’autonomie s’alignait sur ses propres standards. L’impasse est survenue lorsque la direction d’Anthropic a exigé de maintenir l’humain dans la boucle de décision d’élimination de la cible, tout en refusant d’accorder au Pentagone un accès complet et sans restriction au modèle. Or, le Pentagone n’achète pas de boîtes noires. Perdant patience face à une entreprise qui plaçait sa gouvernance au-dessus des impératifs étatiques, le Secrétaire à la Défense Pete Hegseth a ordonné l’interdiction pour les sous-traitants du Pentagone de mener toute activité commerciale avec Anthropic, la classant de facto comme un risque pour la chaîne d’approvisionnement.
C’est une condamnation à mort commerciale qui excommunie la firme de tout l’écosystème de défense : désormais, aucun sous-traitant de l’armée n’a le droit d’interfacer ses systèmes avec Claude. Y compris Palantir. Anthropic a parié que ses capacités de raisonnement la rendraient indispensable. C’était une erreur d’appréciation. Pour l’armée américaine, un modèle capable à 95 % qui obéit est infiniment plus précieux qu’un modèle à 99 % qui discute les ordres.
Le Pentagone a immédiatement redistribué les cartes. Toujours selon Bloomberg, pour faire avancer son projet d’essaims de drones autonomes, l’armée s’est tournée vers une coalition de remplaçants incluant SpaceX, xAI, et des firmes de technologie de défense partenaires d’OpenAI.
D’autres, comme Sam Altman le patron d’OpenAI, se sont rapidement mis en mode carpette et plié à l’ensemble des demandes de l’administration Trump (avant de récemment rétro-pédaler partiellement sur la question de la surveillance de masse). Pourtant de fait et malgré la position de son patron, l’IA Claude d’Anthropic a largement été utilisée pour l’offensive actuelle contre l’Iran, un délai de 6 mois étant nécessaire avant son bannissement « effectif » et que l’entreprise est pour l’instant liée par contrat à l’administration US.
Toujours dans le cadre de la guerre en Iran, on apprenait dans The Independant que Grok avait été mobilisé pour une opération de lancement de plus de 2000 missiles :
« Selon un haut responsable de la Défense, l’administration de Donald Trump aurait fait appel au chatbot Grok d’Elon Musk pour lancer des milliers de missiles en Iran. Dans une déclaration sous serment visant à défendre le « trillionaire » contre un procès alléguant que les centres de données de xAI polluent illégalement les communautés noires, le responsable de l’intelligence artificielle au Pentagone a déclaré que le maintien en service du chatbot était « une question de sécurité nationale primordiale » — et qu’il avait été utilisé pour tirer plus de « 2 000 missiles sur 2 000 cibles distinctes en 96 heures ».
Grok, un chatbot d’intelligence artificielle générative développé par xAI, fait partie des quatre modèles d’IA « actuellement capables de prendre en charge des applications liées à la sécurité nationale », selon Cameron Stanley, directeur du numérique et de l’intelligence artificielle au Pentagone. »
War (is not a) Game.
Dans cette affaire et par-delà les singularités de la gouvernance actuelle des USA, c’est, dans le champ social le retour d’une imagerie de l’IA agissant en Terminator avec la crainte d’un soulèvement des machines. Certes les IA et les « machines » ne déclarent pas encore la guerre, mais sur les terrains de guerre, l’automatisation de décisions leur appartenant désormais entièrement peut engager de nouvelles forces, de nouveaux déterminismes du conflit, y compris dans son extension possible. Ce scénario – d’un soulèvement des machines – est aujourd’hui une médiane paradoxale dans le champ de la prospective : il n’est en effet ni pleinement ni actuellement crédible sur le plan technologique, mais il n’est pas non plus totalement exclu sur un plan politique (qui serait celui d’un emballement, une « furie épique » par exemple …). Ce paradoxe s’explique principalement par le fait que les IA « générales » ou « autonomes » n’existent pas mais qu’une autonomie de décision peut en revanche parfaitement leur être confiée, accordée ou déléguée et qu’à ce stade là, plus personne n’est actuellement en capacité de tracer les décisions qui seront alors prises : c’est le scénario de l’IA battant les meilleurs joueurs d’échec puis les meilleurs joueurs de Go. Dans ces derniers cas, la rapidité de calcul peut-être mise exactement sur le même plan que la capacité de décision puisqu’elle n’aura d’autre inférence, quoi qu’il advienne, que celles circonscrites au plateau de jeu et à détermination de la fin de partie. Sauf qu’on ne parle plus ici d’une activité récréative mais de terrains de guerres. Et sur des terrains de guerre (mais également sur des terrains médicaux, éducatifs, juridiques, etc.), la rapidité de calcul des machines entre en concurrence directe avec la capacité de décision humaine. Or prétendre déléguer aux machines une capacité décisionnelle au motif qu’elles calculent plus vite que nous est à la fois imbécile et dangereux. On m’objectera que les terrains de guerre moderne impliquent la prise de décisions à la milliseconde tout comme les terrains spéculatifs modernes (nos bourses) ont vu l’arrivée du High-Frequency Trading (trading à haute fréquence). Relire Virilio à ce stade n’est plus une option mais une impérieuse nécessité.

Image extraite du film War Games.
D’autres accélérations surviennent. En à peine 30 ans nous avons connu la première guerre entièrement télévisée, en Irak. En Irak encore les drones de combat (Predator) après l’attentat sur les tours jumelles. Hier toujours, la guerre par écran interposé. Aujourd’hui donc les frappes assistées par IA (notamment après le 7 Octobre). Et sous nos yeux la première guerre assistée par des LLM (notamment pour cibler des populations et des individus mais aussi pour permettre à des drones de se coordonner avec une autonomie décisionnelle alignée sur un objectif militaire).
Je reprends ici ce qu’Olivier Tesquet écrivait sur LinkedIn (et je souligne) :
« Je lis dans The Wall Street Journal que l’armée américaine aurait – encore – utilisé Claude pour frapper l’Iran. Puisque ces informations sont classifiées, impossible de savoir à ce stade comment les États-Unis se servent précisément des IA génératives dans le cadre d’opérations militaires. Mais ça m’inspire quelques réflexions générales à chaud.
Tout d’abord, peut-être que le conflit de cette semaine entre Anthropic et le Pentagone – avec cet ultimatum très serré lancé par Hegseth – était lié à des considérations beaucoup plus opérationnelles que ce qu’on imaginait.
Ensuite, quand je travaillais spécifiquement sur les questions de surveillance, j’étais hanté par cette phrase de Michael Hayden, ancien patron de la NSA et de la CIA, évoquant les « assassinats ciblés » par drone : « Nous tuons les gens sur la base de métadonnées ». C’était il y a plus de dix ans.
Désormais, la guerre à Gaza l’a cruellement mis en lumière, l’armée utilise des LLM pour profiler la population (palestinienne) et des systèmes d’IA pour automatiser ses bombardements. Le continuum répressif est évident. Il faut lire à ce sujet le travail capital de +972 Magazine.
Dans les deux cas, on tue en se basant sur des inférences probabilistes, qui prédisent des comportements. On prend la vie de quelqu’un qui ressemble statistiquement à une menace, pas quelqu’un dont on a établi la culpabilité. Les dommages collatéraux ? Les civils tués ? Des variables d’ajustement.
Mais avec l’IA, on franchit un seuil supplémentaire : celui de l’intelligibilité. On ne peut plus retracer le chemin logique qui mène du signal à la décision.
Conséquence : tout principe de responsabilité – y compris pénale – disparaît. Et c’est peut-être ce qui attire tant le pouvoir américain. »
Au milieu de tout cela, ne jamais oublier que comme tant d’autres, cette guerre en Iran, « du signal à la décision« , a commencé par un tir sur une école. « Du signal à la décision« . Une école primaire. L’école primaire Shajareh Tayyebeh à Minab, dans le sud de l’Iran.
Et qu’en plus de tout cela, nous nous éloignons toujours davantage de ce qu’écrivaient Bostrom et Yudowsky (deux théoriciens de l’intelligence artificielle) dont je cite souvent ici l’article de 2011, « The Ethics of Artificial Intelligence » :
« Les algorithmes de plus en plus complexes de prise de décision sont à la fois souhaitables et inévitables, tant qu’ils restent transparents à l’inspection, prévisibles pour ceux qu’ils gouvernent, et robustes contre toute manipulation. »
L’infanterie des données.
Si l’IA (et les LLM) sont la nouvelle artillerie des guerres modernes, alors les données (et métadonnées) sont leur nouvelle infanterie. Or ces données sont des armes de contact à la volatilité extrême. Capables de se retourner contre l’assaillant autant que vers l’assailli. On ne peut en effet que constater aujourd’hui avec autant d’inquiétude que d’effarement la multiplication, la massification et la récurrence des leaks, piratages et autres immenses fuites et vols de données : personnelles, fiscales, médicales, depuis des sources privées, des institutions publiques ou des ministères régaliens, pas une semaine, pas un jour parfois sans un nouveau scandale. A un point que cela en devient presque une sorte de routine et donne naissance à des arnaques de plus en plus nombreuses mais surtout de plus en plus efficaces.
Parmi les plkus récentes rendues publiques on notera celles de l’ANTS (11,7 millions d’usagers), de Almeris (15 millions de patients concernés et autant de données critiques dans le domaine médical), celle de la Banque Postale (11 millions d’usagers), celle de l’opticien Atol (5,9 millions de clients) ou de la chaîne Pierre & Vacances (4,5 millions de clients), sans oublier jusqu’à la DGFIP (direction générale des finances publiques) où les données de plus d’1,2 millions de comptes fiscaux ont été volées.
Ces fuites, ces leaks, ces vols, ces actes de cyber-piraterie ou de cyber-guerre sont aussi bien menés par des pirates agissant en collectifs « autonomes » que par des corsaires au service d’états voyous ou de puissances impériales. Et là encore, le scénario d’un effondrement oscille entre celui de l’impact d’un Armageddon planétaire et le ressenti d’une patate de forain en sortie de boîte de nuit à Arma-sur -Guédon dans la Creuse.
La stratégie Ender.
Dans ce roman de science-fiction, après des années à l’entraîner via de gigantesques simulations, on présente à un humain (Ender) un acte de commandement en temps de guerre et pour une bataille décisive, comme celui d’une énième « simple » simulation alors qu’il s’agit en fait de la réalité et qu’il est vraiment en train de commander des armées sur un terrain tout à fait réel. Nous vivons aujourd’hui une stratégie Ender en miroir. Des IA prennent des décisions en temps de guerre dont certaines s’apparentent à du commandement, et elles le font sans en avoir de quelconque « conscience » tout comme Ender, persuadé d’être dans une simulation, n’éprouvait un quelconque sentiment de responsabilité sur des pertes humaines y compris lorsque celles-ci deviennent critiques. Et nous, nous les humains spectateurs de ces guerres, avons à la fois l’impression terrible d’observer une grande simulation qui nous échappe, tout en mesurant l’atrocité de ce qui s’y joue en temps réel, mais en la mesurant de si loin et via des images si artefactuelles et calquées sur la culture populaire (super-héros et autres reprises de codes de la pop-culture) que la frontière entre le réel et la simulation n’est désormais plus qu’un vague continuum.
Plus rien n’appartient au réel qui ne puisse être simulé et donc simulacre. Et plus aucune simulation ou aucun simulacre ne nécessite d’être ramené au réel pour être éprouvé en tant que tel.
Depuis le début de la guerre faite par les USA et Israël à l’Iran, le compte de la Maison Blanche multiplie les publications qui mêlent images de films (Top Gun, Predator, Mission Impossible …) et images réelles de missiles frappant des cibles ; et quand il ne s’agit pas de films, ce sont les codes des jeux vidéos familiaux (les sports de la Wii U récemment) qui sont associés à ces mêmes images hyper-réalistes de frappes aériennes ou maritimes. De son côté le régime iranien des Mollahs répondait avec les vidéos du sacre de leur nouvel ayatollah où ce sont des personnages Lego qui sont filmés en stop motion (voir l’excellent Dessous des images consécré à « La guerre en Lego »). L’idée n’est pas de vendre une guerre « pop » : l’idée c’est d’anecdotiser complètement l’existence même de la guerre à l’échelle de certains espaces médiatiques.
Après que la guerre a été éloignée des médias à l’exception d’images et de discours qui n’étaient que de propagande, après qu’elle a été filmée au plus près et télévisée en temps réel, après que les témoignages et images qui la constituent se sont réfugiés dans les réseaux sociaux en en empruntant les codes (comme ce fut le cas souvenez-vous en Ukraine ou les témoignages sous les bombes adoptaient le codes des comptes Tiktok de l’âge des premières victimes), aujourd’hui ce qui se joue dans l’économie médiatique de la guerre c’est l’écartèlement permanent entre le réalisme de la disponibilité d’images et de témoignages insoutenables d’un côté, et la réalisation d’images et de récits totalement irréalistes et fantasmés de l’autre côté. Le tout arbitré en visibilité par des algorithmes relais de pouvoir et totalement inféodées à la volonté de leurs maîtres.
Et il ne s’agit pas pour nous de choisir mais d’accepter de prendre tout cela ensemble, car l’architecture de circulation de ces discours est en forme d’arène dans laquelle ces spectacularisations s’enchaînent et se répondent sans cesse et sans que nous puissions ne serait-ce que dire que nous aimerions choisir.
Stratégie Ender (suite) : Attrapez-les tous !
Certains peut-être se souviennent du phénoménal engouement autour du jeu Pokémon Go décliné en réalité augmentée. Il s’agissait de chasser les Pokémon un peu partout dans le monde réel, en passant par une application de réalité augmentée qui « superposait » sur notre géographie classique l’environnement ludique du jeu. Je m’étais de mon côté interrogé sur ces nouvelles affordances et j’avais publié plusieurs articles sur le sujet que vous retrouverez par ici. Dans le premier de ces articles, je proposais même le concept de « schizo-haptie » que je définissais comme suit :
Quand nombre d’entre nous sont aujourd’hui incapables de se passer de leurs smartphones, de « lâcher » cet objet, quand et surtout comment serons-nous demain capables de s’affranchir de nos corps-interfaces pour revenir à plus naturelles synesthésies qui risquent de nous apparaître comme « dégradées » puisque non-augmentées ? Le hold-up du haptique sur tout autre mode d’interfaçage avec le monde et les objets techniques pourrait également donner naissance à de passionnantes études sur l’interface … des faux-mouvements. Aux pathologies actuelles du numérique, à la nomophobie, à la FOMO, à l’algorithmophobia, faudra-t-il rajouter une nouvelle forme de schizophrénie (du grec « schizein = fendre » et « phrên = esprit ») dénommée « schizo-haptie », une schizophrénie du mouvement et de l’ensemble de la panoplie des « gestes-contrôle » ? »
Nous étions alors en 2016. Dix ans plus tard, nous venons d’apprendre, dans un article du MIT repris notamment dans Le Devoir, que derrière cette ludification se tramait en parallèle (et sans un quelconque consentement de notre part), un entraînement pour permettre … de créer une carte du monde en réalité augmentée. Laquelle carte est notamment utilisée pour permettre à des robots de livrer des pizzas. La préméditation n’est pas établie mais le fait est que la société Niantic (qui développait le jeu) dispose aujourd’hui d’une nouvelle branche baptisé Niantic Spatial et dont l’objectif est – je reprends leur slogan – « de construire un LGM (Large Geospatial Model), un modèle vivant du monde auquel les êtres humains et les machines pourront s’adresser » (« Niantic Spatial is building a Large Geospatial Model, a living model of the world that people and machines can talk to« ).
Or y compris avec la localisation GPS et notamment dans de grands centres urbains, on manque de précision au mètre près pour opérer un certain nombre de transactions et autres livraisons. Parce que la distribution sur le dernier kilomètre représentait il y a 10 ans de cela la logistique la plus complexe, Amazon avait lancé en 2015 le service « Flex », pour « uberiser » ce dernier bastion, cette dernière proximité, et nous permettre de récupérer des colis et de les livrer sur le trajet nous (r)amenant chez nous ou à notre travail. Dix ans plus tard, c’est la conquête des derniers mètres qui est devenue la grande bataille logistique. Et il ne s’agit plus d’embaucher des humains mais de permettre à des robots autonomes d’effectuer ces derniers mètres avec la plus grande précision possible. Comme l’explique très bien Camille Coirault sur Presse-Citron :
« Ce qui distingue ce système de tout ce qui existait avant, c’est sa nature : un GPS fonctionne grâce à des coordonnées mathématiques abstraites : une latitude, une longitude et une altitude. Pour les entreprises clientes, l’intérêt est de remplacer le calcul de probabilité du signal satellite par une identification visuelle instantanée des environnements réels.«
Du côté des usages civils, on a donc cette technologie du dernier mètre qui est mise à disposition de robots livreurs de pizzas : des glacières sur roues de la société « Coco Delivery ».

Cette glacière autonome sur roues peut contenir 8 pizzas (y compris à l’ananas) et se déplace à 8 km/h.
On vit une époque formidable. Pour les pizzas.
Jamais à l’abri d’un excès, dans l’article du MIT qui a révélé l’utilisation des données Pokemon Go pour ce nouvel usage, le patron de Niantic Spatial, John Hanke, parle carrément d’une « nouvelle explosion Cambrienne dans le domaine de la robotique. » Pour celles et ceux qui comme moi auraient séché les cours de paléontologie au lycée, l’explosion Cambrienne c’est lorsque (merci Wikipédia) :
Les sédiments cambriens révèlent l’extension de mers peu profondes recouvrant des plates-formes continentales, et une brusque multiplication de nouveaux groupes animaux (animaux à parties dures notamment). Cette « explosion cambrienne » n’a pas encore d’explication. Elle peut avoir plusieurs causes : des modifications climatiques, l’activité accrue de prédateurs ou encore les sels marins favorisant l’absorption de substances chimiques et le dépôt de couches dures sur la peau. Le développement de squelettes externes (exosquelettes) peut avoir été une réaction adaptative à l’apparition de nouvelles niches écologiques. Il pourrait également s’agir d’organismes des grandes profondeurs nouvellement acclimatés aux habitats de surface ou inversement, mais aussi d’une évolution vers des espèces capables d’exploiter des ressources alimentaires nouvelles.
Alors pas sûr que les glacières sur roues soient une nouvelle branche de l’évolution des espèces robotiques, mais la métaphore réussit à nous interpeller. Et comme souvent dans le secteur de la tech et du numérique, il faut lire ces usages métaphoriques pour ce qu’ils sont : la nécessité d’installer rapidement un imaginaire favorable à la naissance ou au maintient de nouvelles rentes économiques (par ailleurs souvent sur fonds publics). Si chacun peut voir dans cette supposée explosion cambrienne robotique des éléments de réel (oui il y a de plus en plus de robots et de dispositifs autonomes, mais non il n’y a aucune logique évolutive derrière), l’enjeu est de convaincre des financeurs, des industriels et des responsables de politiques publiques que cette explosion est en train d’advenir et qu’il serait de bon ton de ne pas se laisser dépasser.
Du côté des usages militaires, car oui Pokemon Go avait également été utilisé par des militaires engagés sur des terrains de guerre et cela avait fait immensément débat, je vous laisse imaginer ce qui peut-être fait de cette maîtrise des derniers mètres. Et s’il faut parler un peu de géopolitique et de terrains de guerre, Le Devoir rappelle qu’en mars 2025, « le jeu a été vendu à Scopely, une entreprise détenue par le fonds d’investissement saoudien contrôlé par le prince héritier Mohammed ben Salmane. La transaction incluait toutes les données des utilisateurs. »
Il y a quelques jours (19 Mai 2026), Google annonçait le lancement de « Gemini Omni », une IA multimodale capable de manipuler nativement le texte, l’audio et la vidéo avec des résultats une fois de plus tout à fait sidérants de vraisemblance. La génération de ces vidéos peut notamment s’appuyer sur les données captées depuis des années par Google Earth, Google Maps et Google Street View permettant par exemple de générer le film hyperréaliste d’un personnage marchant, courant, volant, roulant ou naviguant dans à peu près n’importe quel endroit de la planète.
Le problème de disposer d’une carte à l’échelle du territoire est entièrement résolu. Nous sommes complètement sortis de l’âge où comme l’écrivait en 1931 le mathématicien et philosophe Alfred Korzybski, « la carte n’est pas le territoire », et où il il existait une différence entre la réalité et la représentation que l’on s’en faisait. Le problème est que l’alignement, la superposition au réel ne peut-être résolu ou « exercé » sans recours à une simulation qui, dès lors, prend le pas sur le réel lui-même.
Par-delà tout un ensemble d’autres sujets connexes, la multiplication de ces outils d’IA génératives, leur « fluidité » et leur disponibilité immédiate, s’accompagne aussi d’un retour en grâce (ou d’une nouvelle offensive marketing en tout cas) pour nous réimposer des appareillages sensoriels installant la prééminence de réalités simulées ou virtuelles, Google annonçant ainsi le retour de ses lunettes connectées. Face à des artefacts génératifs désormais presque tous capables de simulations multimodales, s’aligne la conception d’une humanité sensoriellement appareillée non pour s’augmenter mais pour s’aligner avec la carte que dessinent ces Béhémots calculatoires plutôt qu’avec le territoire que nous arpentons chacune et chacun avec nos propres focales.
Apostille.
Si Ender remporte sa guerre, c’est parce qu’il n’a jamais conscience d’être ailleurs que dans une simulation ; c’est parce que les choix qu’il met en oeuvre se subordonnent entièrement à la conscience – en réalité une croyance – qu’il a d’évoluer dans une réalité simulée. La « stratégie Ender » c’est le pari immensément risqué d’un groupe d’adultes face à une guerre d’extermination imminente et qui vont faire le choix de confier l’avenir d’une civilisation à l’habilité et à la ruse d’un enfant habitué à ne prendre de décisions vitales que dans le cadre de simulations virtuelles. Par-delà même les guerres qui traversent aujourd’hui directement nos vies ou nos voisinages, il n’est pas totalement vain de s’interroger sur la stratégie Ender dans laquelle entrent actuellement l’essentiel de nos modes de conflits et de nos modes d’existence.
Et s’il faut trouver un dessein à cette stratégie Ender, il est à coup sûr dans la mise en fragilité ou en effondrement de l’ensemble de nos formes collectives de gouvernance. C’est en tout cas ce qui m’est apparu comme une évidence à la lecture d’un article: « Comment l’IA détruit les institutions. »
IA : Institutions Apocryphes.
Cet article traite de la percolation des technologies d’IA dans l’ensemble de nos institutions au sens régalien comme symbolique. Et du mal que cela leur fait. En d’autres termes la manière dont l’IA détruit nos institutions.
Depuis que je m’intéresse à ces sujets et notamment à l’IA générative, par-delà l’enthousiasme légitime que l’on peut avoir pour des usages grégaires, par-delà l’inquiétude tout aussi légitime qui nous oblige à repenser presque totalement nos heuristiques de preuve, je cherchais ce qui dans ces artefacts génératifs était le point nodal des risques qu’ils font peser aujourd’hui sur nos sociétés. Et ce point est circonscrit et formidablement argumenté sous la plume de deux collègues juristes, Woodrow Hartzog et Jessica M. Silbey de la faculté de droit de l’université de Boston, dans leur article : « How AI Destroys Institutions« , article dont voici le résumé (je souligne et traduis avec l’aide partielle de Deepl) :
Les institutions civiques – l’État de droit, les universités et la liberté de la presse – constituent l’épine dorsale de la vie démocratique. Elles sont les mécanismes par lesquels les sociétés complexes encouragent la coopération et la stabilité, tout en s’adaptant à l’évolution des circonstances. La véritable superpuissance des institutions réside dans leur capacité à évoluer et à s’adapter au sein d’une hiérarchie d’autorité et d’un cadre de rôles et de règles, tout en conservant leur légitimité dans les connaissances produites et les actions entreprises. Les institutions axées sur des objectifs et fondées sur la transparence, la coopération et la responsabilité permettent aux individus de prendre des risques intellectuels et de remettre en question le statu quo. Cela se produit grâce aux mécanismes des relations interpersonnelles au sein de ces institutions, qui élargissent les perspectives et renforcent l’engagement commun envers les objectifs civiques.
Malheureusement, les affordances des systèmes d’IA anéantissent ces caractéristiques institutionnelles à chaque tournant. Dans cet essai, nous avançons un argument simple : les systèmes d’IA sont conçus pour fonctionner d’une manière qui dégrade et risque de détruire nos institutions civiques essentielles. Les affordances des systèmes d’IA ont pour effet d’éroder l’expertise, de court-circuiter la prise de décision et d’isoler les individus les uns des autres. Ces systèmes sont contraires à l’évolution, à la transparence, à la coopération et à la responsabilité qui donnent leur raison d’être et leur durabilité aux institutions vitales. En bref, les systèmes d’IA actuels sont une condamnation à mort pour les institutions civiques, et nous devons les traiter comme tels.
De mon côté je souligne depuis longtemps à quel point ces outils d’IA excellent dans 2 domaines : primo la simulation d’expertise (en se présentant comme des systèmes experts en capacité de nous leurrer sur la base de notre propre ignorance tout en favorisant par ailleurs des effets Dunning-Kruger de plus en plus problématiques), et deuxio la dissimulation d’expertise (notamment en opacifiant et en dissimulant d’une part la valeur ajoutée des travailleurs de l’ombre, et d’autre part l’ensemble des sources couvertes par le droit d’auteur qui sont captées de manière extractiviste et prédatrice sans égard ni considération).
L’autre point qui m’a frappé dans l’approche des auteurs de l’article « Comment l’IA détruit nos institutions » c’est la question des affordances qu’ils posent à l’échelle de ces systèmes anthropo-techniques que sont les IA, notamment génératives. L’affordance c’est le titre éponyme de mon blog depuis près d’un quart de siècle, et c’est aussi le projet que j’entretiens de documenter les affordances des systèmes numériques que nous utilisons pour mieux comprendre comment ils modifient nos propres comportements et habitus informationnels, cognitifs, relationnels, etc.
Autre extrait de leur article :
« Les premiers théoriciens, comme Émile Durkheim, considéraient les institutions — telles que la famille, la religion et l’éducation — comme des « représentations collectives » qui
soutiennent les normes sociales et assurent la cohésion dans des sociétés de plus en plus complexes. Max Weber s’est intéressé au développement des institutions bureaucratiques, telles que les systèmes judiciaires, qu’il considérait comme fondamentales pour les États-nations modernes. Les spécialistes du « nouvel institutionnalisme » de la seconde moitié du XXe siècle mettent l’accent sur les dimensions culturelles, cognitives et historiques des institutions, y compris leur dynamisme institutionnel par opposition à leur immobilisme. Ces théoriciens expliquent que les institutions sont des constructions sociales et acquièrent leur légitimité en s’ancrant dans les pratiques sociales et en étant façonnées par le comportement humain, reproduisant et maintenant les normes institutionnelles à travers les interactions quotidiennes. En conséquence, la légitimité institutionnelle n’est pas simplement imposée aux individus, mais découle du comportement humain et des interactions »
Et c’est tout cela que viennent miner les IA telles qu’elles se déploient en tout cas majoritairement aujourd’hui.
Tout cela se noue dans une matrice au sein de laquelle les développements technologiques dans leur logique de massification, ont toujours eu pour principal objet une « économie de l’attention » au sein de laquelle il nous faut toujours davantage faire l’économie de notre propre attention aux choses et aux êtres, c’est à dire fonctionner à coût cognitif nul. Sans friction. La marche d’après, lorsqu’il n’est plus d’économie possible car l’essentiel de nos interactions sont déjà réduites à des activités de pousse-bouton ou de défilement infini, la marche d’après consiste à progressivement et entièrement déléguer un ensemble de tâches à la machine et aux technologies. C’est à dire à nous faire entrer dans des phases de déprise à la fois opérationnelles et symboliques, à la fois rationnelles et affectives. Et à ce titre l’essor des artefacts conversationnels fonctionne comme un paradigme téléologique. Et une nouvelle forme de stratégie Ender.
========================================
Cet article a été rédigé fin mai 2026, dans une actualité où les débats autour du positionnement de Dario Amodei et de l’encyclique du Pape occupaient le devant de la scène.
Il devait initialement paraître sur un autre média que ce blog. .
20.06.2026 à 12:08
L’heure de l’IA au lycée. Buvez des données et mangez des tokens.
Olivier Ertzscheid
Texte intégral (1751 mots)
Le 1er Ministre Lecornu vient d’annoncer, au coeur des épreuves du bac et de la canicule, que tous les lycéens bénéficieraient à la rentrée prochaine, en classe de 2nde, d’une heure d’enseignement par semaine sur l’IA.
Le même gouvernement qui a aussi annoncé l’interdiction des téléphones portables au lycée dès la rentrée prochaine.
Le même gouvernement qui veut interdire les réseaux sociaux aux moins de 15 ans.
Le même gouvernement qui veut faire pousser des Data Center partout en mode « Viva Tech et Balek ».
En pleine canicule. Ne cherchez pas la cohérence vous n’en trouverez pas. Mais eux, bah oui :
Le chef du gouvernement souligne que «former à l’IA» et «réduire l’exposition aux écrans», comme avec le projet d’interdire les réseaux sociaux aux jeunes de moins de 15 ans, «participent d’une même ambition : faire de nos élèves des citoyens libres, autonomes. Condition de notre souveraineté collective».
« Participent d’une même ambition » … Alors comment te dire, Seb. Y’a rien qui va. Rien. Ces trois éléments pris successivement peuvent à la rigueur faire illusion de cohérence à la manière dont trois chansons de Michel Sardou font illusion de patriotisme mais franchement … « Les écrans », « l’IA », « les réseaux sociaux ». Rien que ça déjà. Qui partagent autant de points communs que le taboulé, la mayonnaise et le nutella.
Prétendre tout aligner pour faire oublier que l’on a tout mélangé. Là où l’immensité des enjeux et des urgences nécessite une approche systémique, c’est à dire articulée au plus près des conditions d’enseignement (y compris et surtout pratiques et matérielles) et des modalités de ce qu’est l’expérience lycéenne de l’apprentissage singulier et collectif, on a une bouillie de mesures à effet médaille, c’est à dire qui ont pour principale vocation de décorer le torse des egos qui auront été les premiers à les brandir. Le lycée (surtout) est devenu un immense fourre tout d’opportunismes politiques dans lequel chaque ministre se rêve en Derrida de chez Wish confondant la déconstruction et la reconstruction. Ce qui se déconstruit ce sont les collectifs, enseignants comme lycéens. Ce qui se déconstruit ce sont les espaces de classes et de groupe. Ce qui se déconstruit ce sont les choix que l’on multiplie de manière totalement artificielle et de plus en plus tôt pour mieux masquer les impasses et complexifier les rares lisibilités de futurs envisageables.
Toutes les enseignantes et tous les enseignants vous le diront : cette idée de mettre une heure par semaine sur l’IA en classe de 2nde qui sort comme ça pif paf pouf sans concertation à quelques jours des vacances d’été, on appelle ça une mesure fantôme (qui s’ajoute aux précédentes, EVARS, pix, e3d, etc). Ce n’est pas financé, ça sort de nulle part, on ne sait même pas qui va faire les cours et quel en sera le contenu et on a un mois et demi (de vacances) pour être prêts à la rentrée et tout doit être prêt pour la rentrée 2027 alors même que les prochains au pouvoir déferont à leur tour probablement l’essentiel de ce qui aura été fait. Ce qui compte ce n’est pas la temporalité de la mesure, ce qui compte c’est la temporalité de l’annonce de la mesure. Viva Tech et Balek. Si le foutage de gueule était un doctorat, ces gens là seraient tous Honoris Causa.
Oui bien sûr il faut former à l’IA. Bien sûr. Mais là et dans les conditions exposées ci-dessus, on ne construit pas : on sabote, on dynamite, on vaporise. C’est la méthode des vieux pubards : « Spray and Pray ». Vaporisez et priez. Mettez-en partout et attendez que ça prenne. Et si ça ne prend pas bah au moins vous en aurez foutu un peu partout.
Franchement ? Ce serait presque rigolo. Si le contexte n’était pas ce qu’il est, notamment depuis la mise à sac des réformes Blanquer qui est à l’éducation nationale ce que Patrick Bruel est à la lutte contre les violences faites aux femmes ; si une génération n’était pas en train d’étouffer sous la canicule avec en face d’elles une dynastie d’immacescibles tanches qui s’interrogent encore pour savoir si mettre des épreuves que le matin ce serait pas une bonne idée ; si la place des mathématiques n’avait pas changé tous les ans sur le cycle lycée depuis (au moins) 5 ans en dépit de toute forme de bon sens et en débit de toute forme de rationalité ; si toutes ces conditions et quelques autres n’étaient pas réunies, alors oui ce serait presque risible mais ça ne l’est pas. Et c’est un fait acquis que Lecornu, à l’instar de tous ceux qui, osera tout.
Je me permets donc de lui suggérer de pousser un cran plus loin. Une heure de cours sur l’IA par semaine en 2nde ? D’accord mais on regroupe tous ces cours sur le mois de Juin. De toute façon en Juin à part mourir en stage, les élèves de 2nde ils ne branlent rien. Et on hydrate les lycéennes et lycéens en leur faisant boire de l’eau issue de Data Centers. Et on leur fait bouffer des tokens.

Comme ça on est bien. Vous vous souvenez de Chirac et de son « mangez des pommes » ? Bah on on garde la même DA mais on va la glow up niveau expert et on leur dira : « Buvez des Datas et mangez des tokens ». Parce que c’est notre projet.
<Mise à jour du 21 Juin> Suite à la publication de cet article, pas mal de réactions donc je précise un peu. Non il ne faut pas à tout prix « former à l’IA », par contre il est vital de former à la culture numérique et de former de manière politique à la culture numérique (donc en gros et pour faire simple, travailler autour de tout le catalogue sur ce sujet de C&F Editions 
L’autre point sur lequel il y a débat c’est sur l’idée de cette supposée « même ambition« , de ce point commun in abstentia entre réseaux sociaux, écrans et IA. Là encore je maintiens ce que j’écrivais et je précise. « Les écrans » c’est avant tout une question sociale, une question d’organisation sociale, de la manière dont nos sociétés, nos vies et nos rythmes (familiaux, professionnels, amicaux) créent ou empêchent des temporalités dans lesquelles le recours aux écrans devient une clé comme l’était hier le recours à la télé ou à l’ordinateur familial du salon. « Les réseaux sociaux » c’est une question médiatique et éditoriale, et ce n’est que cela. Enfin, « l’IA » c’est une question technologique, et oui bien sûr toute technologie est politique surtout quand elle met à mal l’une des ressources actuellement les plus rivales entre un accélérationnisme industriel et notre propre survie, c’est à dire la ressource en eau.
Ce qu’il nous manque et ce que les annonces de Macron n’ont jamais permis de penser et d’installer depuis qu’il s’est fantasmé en président de la start-up nation, ce qu’il nous manque c’est une pensée politique capable d’articuler la question des temporalités et des rythmes sociaux avec celle des instances médiatiques qui les donnent à voir dans des prismes toujours plus ambivalents et des régimes de vérités désormais structurellement mouvants, et avec ce que chaque nouvelle technologie peut changer ou prendre comme place dans l’accélération ou la dilatation de ces temps et dans les choix de politiques publiques qui les mettent à leur service ou qui nous y asservissent.
28.05.2026 à 10:02
Entre la lame et la flamme. Chronique d’un « record »
Olivier Ertzscheid
Texte intégral (1225 mots)
« Record ». « Record ». « Record ». « Record ». « Record ». Des mots il y en a d’autres. Mais celui-là est le plus chaud, le plus saillant, le plus repris. Nous en franchissons. Nous en battons. Nous en dépassons de précédents. Des records. De chaleur donc. Et donc comment dire autre chose de « record ».
D’autres mots s’alignent derrière : « jamais vu« , « historique« , « inédit » … Mais toujours celui-là qui revient : « record. » Alors on y va au record, au rapport. Dire et redire le record de chaleur pour ,ne pas dire le record de souffrance, le record d’épuisement, le record de sensation d’étouffement, le record d’irrespirabilité, le record de malaises, etc.
Dire et répéter sans cesse ce « record » c’est installer narrativement une dimension qui est celle du sport, du dépassement, de la médaille, bref, des valeurs presque toujours associées à quelque chose de positif dans notre imaginaire. Alors dire sans cesse ces records, est-ce franchir une limite ou s’affranchir des dernières supportables restantes ?
Dire et répéter sans cesse ce record c’est aussi marquer le moment d’un souvenir, s’inscrire donc dans une histoire, un record c’est un témoignage. Record nous dit le dictionnaire de l’académie c’est : « Emprunté de l’anglais record, ‘procès verbal, témoignage consigné’, déverbal de to record, ‘enregistrer’, lui-même emprunté du français recorder. » Alors on enregistre. La hausse des températures, les images de plage, de glaces, d’eau, d’espaces et de lieux et ressources qui aujourd’hui sont enregistrés comme ceux qui rafraîchissent, mais que l’on enregistre aussi comme ceux qui seront demain impraticables, inaccessibles, épuisés.
Et puis il y a les autres records, les autres enregistrements, les autres mémoires collectives qui se construisent et se fixent.
J’enregistre. Il faut aller à l’école, en cours. Il faut passer des examens, des épreuves. Bacheliers professionnels à l’épreuve d’un baccalauréat que le ministre ne voit aucune raison de décaler, de déplacer, d’aménager. Pourtant il n’y a pas si longtemps on avait déplacé, décalé, aménagé le brevet des collèges mais là ce sont des bacheliers professionnels. Alors il faut les habituer à la peine. Il faut les tordre.
Plus rien n’est adapté. Voilà des décennies que nous avons construit (et construisons encore contre toute logique) des bâtiments faits pour dire que nous aspirions à la chaleur : larges fenêtres, baies vitrées immenses, orientations plein sud. Let The Sun Shine In. Laissons entrer le soleil.

Et nous avons des villes entières, des gares, des lotissements, des écoles, des collèges, des lycées, des immeubles tout entiers tournés vers le soleil qui désormais écrase.
Parmi les images les plus fortes d’une littérature qui m’accompagne, il y a celle du tout début du roman de Kim Stanley Robinson, « Le ministère du futur« , la description d’une humanité écrasée d’une chaleur insoutenable, qui à la nuit se réfugie en quête de fraîcheur dans un lac lui-même déjà trop chaud mais pourtant seul supportable, et d’une partie de cette humanité qui y crève littéralement, et du narrateur qui s’y réveille à peine vivant au milieu de cadavres. Ce roman est une vraie claque. D’autres sciences et d’autres fictions bien sûr racontent l’inexorable qui vient.
Nous avons maintenant juste besoin de politique. Et des formes les plus abouties de radicalité, de redirection écologique, de de planification, appelez cela comme vous voulez mais puisqu’il est déjà trop tard, non pas tant pour nous que pour nos gosses, il faudra de la politique, et de la dure.
Il y a cette certitude sourde que deux choses ne nous sauverons pas : l’innovation et l’adaptation. Oui nous innoverons et oui certains trouveront encore à s’adapter, bien sûr qu’il le faudra. Mais ni l’innovation ni l’adaptation ne nous sauverons si nous considérons qu’elles deux seules peuvent encore nous sauver.
L’innovation ne nous sauvera pas. Elle ne fera que retarder certains pans d’un inéluctable dont la capacité mortifère est d’ores et déjà irréductible.
Notre capacité d’adaptation ne nous sauvera plus. Nous ne pourrons pas, nous ne pourrons plus (nous ne le pouvons presque déjà plus), ni à l’échelle de nos corps ni à l’échelle de nos lieux, de nos corporéités et de nos habitabilités, nous ne pourrons pas nous adapter davantage, ni en creusant plus bas sous terre, ni en avançant plus loin ou plus profond dans l’océan, ni en montant plus haut dans nos villes comme dans nos géographies ou dans nos conquêtes de l’espace.
Nous sommes depuis déjà trop longtemps entrés dans un cycle où les innovations et les adaptations effondrent les cohésions, les sociabilités, les cohabitations qu’elles soient de voisinage ou de destin. Entre ceux qui ont la clim et ceux qui ne l’ont pas. Entre ceux qui vivent là et ceux qui vivent ailleurs. Entre ceux qui peuvent financer leur adaptation et ceux qui ne le peuvent pas.
C’est à la fois enthousiasmant et désespérant mais il ne nous reste plus que du politique pour nous sauver la peau et que nos gosses et les gosses de nos gosses ne soient pas les accablés nomades de nos errances ou les assignés à résidence punitive de nos tardives repentances.
D’un record, l’autre. C’est désormais la seule et l’unique question, dont toutes les autres dépendent : nous visons dans un monde dont la géographie, l’espace, l’habitat, la circulation, ne sont plus du tout adaptés au climat que nous traversons et traverserons. Alors nous attendons. Nous attendons la lame, celle qui viendra de l’océan. Nous attendons la flamme, celle qui viendra de nos forêts. Entre la lame et la flamme. Juste du politique.
20.05.2026 à 18:27
Le cauchemar de Lessig. If « Code Is Law », what da fuck is « Vibe Coding » ?
Olivier Ertzscheid
Texte intégral (2149 mots)
Rapidement quelques réflexions construites en préparant mon intervention lors d’une journée autour de l’IAG organisée par l’APDEN de Poitiers. Merci à toute l’équipe pour l’invitation et l’organisation.

Ecrire du code.
Arthur Mensch est Le PDG de Mistral AI, entreprise spécialisée dans l’IA et « licorne » française. Il vient d’être auditionné par l’assemblée nationale. Si vous vous intéressez au sujet, l’entretien est assez intéressant même s’il faut très souvent faire la part de ce qui relève de la réalité de cette firme (et qui peut être étendu à d’autres semblables) et la dimension très prégnante de l’opportunité de lobbying qui lui est ainsi offerte (mais c’est le jeu, il fait son taff, et il le fait plutôt très bien).

Deux séquences, ou plus exactement deux phrases m’ont beaucoup frappé dans cette intervention de presque une heure trente.
« Aujourd’hui les ingénieurs chez Mistral n’écrivent plus de ligne de code. » Je répète et souligne : « Aujourd’hui les ingénieurs chez Mistral n’écrivent plus de ligne de code. »
Et il poursuit : « Aujourd’hui vous n’êtes plus un artisan, vous êtes un manager, donc vous demandez à des agents (IA) d’écrire le code pour vous. Vous donnez les spécifications ; vous êtes un donneur d’ordre. » (la séquence est accessible à partir de 1h 8 min et 41 sec.
Et là quand j’entends ça j’ai plein de questions.
Première question : est-ce que c’est vrai ? Alors disons oui et non. Pour en avoir échangé avec des collègues informaticien.ne.s dont certain.e.s ont également travaillé dans ces grands groupes (Google et Facebook), disons que oui c’est vrai il existe des ingénieurs / développeurs qui n’écrivent plus de ligne de code, mais il existe aussi toujours quand même qui codent les agents IA qui à leur tour vont coder à la place d’autres ingénieurs et/ou développeurs. Il y a d’ailleurs une expression dédiée, on appelle cela du « Vibe Coding » qui consiste à créer du code informatique (par des initiés ou des non-initiés) en utilisant du langage naturel grâce à l’IA.
Deuxième question : est-ce que c’est grave ? Je n’ai pas la réponse à court terme mais à moyen terme j’ai l’absolue certitude que cela l’est. Et que cela l’est éminemment.
Troisième question : est-ce que c’est une bonne nouvelle ? Pour répondre, je vous propose de transposer la situation du PDG d’une boite d’IA expliquant que ses ingénieurs n’écrivent plus de ligne de code pour … coder, à la situation, par exemple, d’un ou d’une responsable de formation, d’un ou d’une enseignante, qui dirait : « je n’ai plus aucun étudiant / élève qui ait besoin de comprendre les concepts et notions que je manipule pour leur transmettre un savoir et qu’ils soient en capacité d’en produire de nouveaux à leur tour. Et là c’est, convenez-en, tout à fait vertigineux. Alors oui bien sûr, comparaison n’est pas raison, les ingénieurs d’Arthur Mensch ne sont pas les élèves ou étudiants dans nos classes et nos amphis, et oui bien sûr le code est un langage mais on pourrait philosopher quelques heures (en relisant Saussure, Chomsky, Wittgenstein et quelques autres) sur le fait qu’il est ou non une langue. Mais vous voyez l’idée.
Quatrième question. Si l’on s’accorde sur le fait que le code est une langue ou à tout le moins un langage, quand vous n’écrivez ou ne parlez plus une langue, au bout de combien de temps cessez-vous de la comprendre et de la maîtriser ? Arthur Mensch le dit lui-même, il est de cette génération « d’artisans du code » (il a 33 ans), il a appris cet artisanat et il dit aussi que cela lui a plu. Mais une autre génération arrive, qui n’aura plus la nécessité d’apprendre, ou d’apprendre autant. Alors que feront-ils ? Et s’ils n’écrivent plus une ligne de code mais doivent continuer de fabriquer des applications, alors que feront-ils … sans code ? Autre vertige.
Alors oui je sais, entre ce que dit Arthur Mensch, et le contexte et la place depuis lesquels il dit cela, il y a tout de même une série de nuances à apporter. Pour autant, dans le champ scientifique qui est le mien (les sciences de l’information et de la communication), il nous appartient précisément de prendre des énoncés pour ce qu’ils disent dans l’instant, autant que pour ce qu’ils installent aussi en terme de narration sociale plus ou moins implicite. Et Arthur Mensch « incarnant » et portant le discours technophile, accélérationniste et dérégulateur autour de l’IA, ce qu’il dit (même si cela n’est que 2 minutes dans une vidéo d’une heure trente) est en soi un énoncé particulièrement performatif auprès de celles et ceux qui l’écoutent. Et ce que dit Arthur Mensch c’est que « aujourd’hui les ingénieurs chez Mistral n’écrivent plus de ligne de code. » Comprenez et entendez que donc tous les ingénieurs dans toutes les entreprises d’IA qui sont ou se rêvent en futures licornes, n’écrivent et n’écriront plus une ligne de code ou en tout cas n’ont et n’auront plus vocation à le faire. Juste du Vibe Coding.
Le cauchemar de Lessig.
« Code Is Law. » (traduit en français par Framasoft). « Le code c’est la loi. » C’est un livre (paru en 1999, « Code And Other Laws of Cyberspace« ) et un article (paru en 2000). C’est l’un des textes fondateurs de la culture numérique. Publié au début des années 2000, absolument fondamental et totalement visionnaire, Lawrence Lessig (professeur de droit, spécialiste de propriété intellectuelle, inventeur des licences Creative Commons, etc.), Lawrence Lessig y explique notamment que le code est un régulateur, que le code décide et que le code :
« définit la manière dont nous vivons le cyberespace. Il détermine s’il est facile ou non de protéger sa vie privée, ou de censurer la parole. Il détermine si l’accès à l’information est global ou sectorisé. Il a un impact sur qui peut voir quoi, ou sur ce qui est surveillé. Lorsqu’on commence à comprendre la nature de ce code, on se rend compte que, d’une myriade de manières, le code du cyberespace régule. »
Et il poursuit en expliquant que :
Des gens choisissent la manière dont le code effectue tout cela. Des gens écrivent ce code. Dès lors le choix n’est pas de savoir si les gens pourront choisir la manière de réguler le cyberespace. D’autres gens – les codeurs – le feront. Le seul choix est de savoir si nous jouerons collectivement un rôle dans leurs choix – et si nous pourrons alors déterminer la manière dont ces valeurs se régulent – ou si nous autoriserons collectivement ces codeurs à décider de ces valeurs à notre place.
D’où ma dernière question : if « Code Is Law », then what da fuck is Vibe Coding ?
Le « Vibe Coding », un monde dans lequel les entreprises les plus puissantes en IA n’auraient que des ingénieurs et des développeurs n’écrivant plus de ligne de code, ce monde c’est le cauchemar de Lawrence Lessig et notre cauchemar à toutes et tous. Car si les codeurs eux-mêmes sont à distance du langage ou de la langue par laquelle ils installent des valeurs dans le code, s’ils ne parlent ou n’entendent plus cette langue et s’ils se réduisent à des fonctions de « managers d’agents IA – faussement – autonomes », alors comment elles et eux en première ligne, et surtout comment nous toutes et tous en première cible, comment serons-nous encore capables de jouer collectivement un rôle dans la circulation et l’établissement de ces valeurs, de ces agendas politiques, économiques, idéologiques, que le code véhicule et qui n’ont jamais été aussi puissants et déterminants, et dans le même temps jamais à ce point été inféodés à des intérêts presqu’uniquement marchands, mafieux et singuliers ?
Si le code se passe de développeurs autres que des agents non-humains, alors la question de la maîtrise des valeurs que le code véhicule devient une non-question, un inquestionnable.
« Un algorithme c’est la décision de quelqu’un d’autre » me faisait l’honneur d’écrire Antonio Casilli dans la préface à l’un de mes tout premiers ouvrages. Et ce quelqu’un n’était pas extrêmement compliqué à trouver, à isoler, et à questionner. Mais un algorithme « vibe codé » c’est la décision de … qui ?
« Les limites de mon langage signifient les limites de mon propre monde » écrivait Wittgenstein.
L’intelligence c’est de l’énergie (et la connerie c’est de l’énergie moins chère).
Arthur Mensch dit aussi plein d’autres trucs qui installent des narratifs extrêmement clairs et puissants dans leur fonction d’agenda. Par exemple à plusieurs reprises il répète qu’il faut réfléchir ou considérer l’intelligence comme on réfléchit à l’énergie, à l’électricité. Alors bien sûr il parle de l’intelligence artificielle. Mais il ne dit pas « intelligence artificielle », il dit juste « intelligence ». Et ce n’est pas « juste » une omission ou un raccourci. C’est l’endroit d’où il parle, celui d’où il est situé, c’est l’énoncé de son futur probable et de son futur désiré, d’un futur qui répond à « son » agenda propre. Un mode dans lequel en effet l’intelligence se capte, se stocke, se transmet et se calcule comme l’énergie, comme l’électricité. D’ailleurs et c’est aussi extrêmement frappant, à plusieurs reprises et sur plusieurs questions, il commence toujours par répondre en nombre de kilowatts ou de mégawatts. C’est son unité de mesure, son mètre étalon et ce sur presque l’ensemble des questions qui lui sont posées et adressées. Tout se calcule en kilowatts ou mégawatts. Tout est là. Toutes les réponses sont là. Un mètre étalon. Qui est aussi son plus grand talon d’Achille (à lui et à l’ensemble de l’industrie extractiviste de l’IA).
10.05.2026 à 14:44
L’overview effect de l’IA.
Olivier Ertzscheid
Texte intégral (2119 mots)
Et si notre terre était notre langue ?
Et si les IA conversationnelles étaient nos vaisseaux ?
Et si nous étions des astronautes sociaux ?
L’Overview Effect ou « effet de vue d’ensemble » c’est « un choc cognitif, une prise de conscience dont témoignent certains astronautes lors d’un vol spatial qui se produit lorsque ceux-ci observent la Terre depuis l’orbite terrestre ou la Lune. Cet effet se produit par la mise en perspective directe de la situation de la Terre dans l’espace : la planète est perçue comme une sphère fragile, un point bleu pâle « suspendu dans le vide », protégé par une fine atmosphère. »

L’Overview Effect conduit donc à prendre conscience de la fragilité d’un écosystème en l’observant d’un point, d’une position qui ne nous est ni naturelle ni facilement accessible et qui introduit une grande distance impliquant un renversement de perspective.
Et bien – me semble-t-il en tout cas – c’est très caractéristique de ce qu’ont produit les premiers systèmes d’IA conversationnels, ces artefacts génératifs. Et de ce qu’ils continuent de produire actuellement. En même temps que ces « agencements machiniques informationnels » ont déplacé la question du langage, ces IA conversationnelles et leur insincères maïeutiques nous ont mis dans une situation d’observation tout sauf naturelle de processus discursifs en temps réel qu’ils effectuent, processus discursifs pour autant (essentiellement) crédibles et « satisfaisants » (en tout cas satisfaisants aux principaux codes d’un échange conversationnel entre deux êtres humains).
Voir des machines parler était déjà étonnant mais fut longtemps cantonné au seul imaginaire de science-fiction ; puis parler à des machines (via les interfaces vocales du World Wide Voice) devînt une forme de routine mais demeurait, quelque part, toujours une forme d’étonnement ; aujourd’hui, voir des machines avoir avec nous des conversations rationnelles en temps réel, produit un effet de décalage qui fait que c’est « notre » intelligence, « notre » capacité dialogique et rationnelle qui est vue comme immensément fragile et qui, par contraste, donne à ces machines et à ces artefacts, dans l’interaction que nous avons avec elles, une place différente de ce qu’elle devrait être. Un renversement de perspective.
Nous sommes dans la position de l’astronaute qui observe non pas la terre mais la capacité de langage et d’intellection (et parfois aussi d’imagination), et qui l’observe pour la première fois depuis la médiation artificielle et artefactuelle qu’en propose l’IA générative. Et si la distance de la terre à la station spatiale qui permet de l’observer est considérable et se mesure en kilomètres (autour de 400 pour être précis), la distance entre notre « engagement langagier » et l’écho conversationnel médié par les IA est tout aussi vertigineuse à ceci près qu’elle ne se mesure plus en kilomètres mais plutôt en dépliant l’ensemble des règles algorithmiques, corpus d’entraînement, processus de « fine-tuning » mais aussi infrastructures techniques (data centers) et autres opérations qui permettent aux machines de faire à la fois illusion de langage et leurre de conversation.
Soit la langue est fragile, soit c’est nous qui le sommes.
Et si la langue est aux machines …
Cette position tout sauf naturelle (au même titre que celle de l’astronaute Sophie Adenot ci-dessus) nous conduit, en partie au moins, à regarder et à mieux mesurer et prendre en compte toute la fragilité du langage et des interactions humaines qu’il permet et conditionne. Mais cette situation d’observation inédite produit également deux effets différents : certains cherchent à protéger ou à sanctuariser la nature ou à tout le moins la fonction du langage, et à ne pas entièrement et systématiquement les soumettre aux systèmes techno-politiques qui produisent et façonnent ces IA ; d’autres au contraire font de cette fragilité évidente l’occasion d’un renoncement sur l’autel de l’efficience ou de la rationalité économique, prétextant se démultiplier via des IA agentiques qui sont le Taylorisme d’une langue véhicule. Et puis bien sûr il y a les enjeux même de l’écriture et de la création, que décrit un récent et admirable texte de Gregory Chatonsky sur AOC : « Ce qui (me) permet d’écrire est ce qui (vous) empêche de lire. »
Dans les deux types de réaction possible à cet Overview Effect de l’IA sur le langage, certains initialement en garderont donc surtout un sentiment accru de connexion avec une entité non-humaine, là où d’autres n’y verront que l’instanciation de formes toujours plus abouties d’isolement et de solitude. Tout comme la littérature scientifique autour de l’Overview Effect (qui date des premiers vols à haute altitude dans les années 1950), documentait aussi bien « l’appréciation et la perception de la beauté, une émotion inattendue, voire bouleversante, et un sentiment accru de connexion avec les autres » (Wikipedia) qu’un effet paradoxal de « rupture » ; les aviateurs traversaient en effet un phénomène décrit comme un sentiment de séparation physique de la terre occasionnant des réactions individuelles allant qui pouvait soit les plonger dans un sentiment « d’exaltation ou du sentiment de se sentir plus proche de Dieu » tout comme à des formes élevées d’anxiété, de peur ou de solitude (Wikipedia). Ce phénomène dit de « break-off » cessa d’être étudié en tant que tel au début des années 1970.
Dans l’histoire des technologies numériques, qu’il s’agisse du Cloud, des réseaux sociaux, ou désormais de l’IA, les effets de proximité sont presque toujours paradoxaux et ne font que masquer une distance de plus en plus grande. Le « Cloud Computing » permet une disponibilité immédiate de documents qui n’ont jamais été stockés physiquement aussi loin de nous ; les réseaux sociaux ont historiquement fait proximité (puis promiscuité) avec des individus géographiquement toujours plus éloignés. Sans toujours le mesurer ou l’éprouver, nous avons donc déjà traversé d’autres « Overview Effects » : celui de l’éloignement et d’une distension de nos mémoires documentaires, celui de l’éloignement et d’une distension de nos relations sociales, et désormais donc, celui de l’éloignement et d’une distension là encore paradoxale de notre rapport au langage.
Voilà pourquoi, aussi, la question des heuristiques de preuve, celle de savoir comment à l’échelle d’une société nous serons – ou non – encore capables de définir la valeur de vérité d’un énoncé ou d’un fait et que cette valeur soit partagée parce que démontrable, documentable, voilà pourquoi la question des heuristiques de preuve est devenue aussi essentielle : non pas seulement par l’industrialisation de la production du faux, non pas uniquement par la vitesse même à laquelle ce faux est créé et se diffuse mais parce que nous sommes placés à une distance lointaine, inédite, comme en « décrochage » de notre capacité à faire langage. Parce que pour filer cette métaphore au moins visuelle de l’Overview Effect, c’est un autre type de vaisseau que l’ISS qui nous mène à si grande distance d’un biotope (la langue) qui nous est habituellement si proche et qui à mesure qu’elle se rapproche des machines semble aussi comme proportionnellement s’éloigner de nous. Les IA, ou plus précisément leur cadre de déploiement technique (les LLM) et infrastructurel (Data Centers et processeurs), sont un vaisseau comme un vecteur de mise à distance, d’éloignement de ce qui fait la langue.
Nous arrivons aujourd’hui à un moment charnière dans lequel nous verrons si la massification de l’usage des IA (pour autant qu’elle continue d’augmenter de manière constante et ne soit pas soumise à divers aléas d’un modèle économique pour l’instant reposant sur la dynamique d’un gigantisme de l’épuisement – toujours plus de ressources et de consommation), nous verrons, disais-je, si la massification de l’usage des IA nous emmène plutôt vers la conscientisation de la fragilité de la langue ou s’il faut plutôt se résoudre, après sa marchandisation dans un capitalisme linguistique (Frédéric Kaplan), à sa presque totale servicialisation dans un cadre où ce que l’on appelait la novlangue et le néo-parler, seront l’essentiel de la langue collective circulante quand d’autres régimes discursifs et linguistiques, jusqu’ici principalement vecteurs de socialisations affectives fines, seront de plus en plus cantonnés aux seuls échanges entre humains et machines.
Je ne crois pas trop à l’avènement à moyen terme d’une société du silence qu’extrapole par exemple un éditorial du WSJ reposant sur un article scientifique qui montre que nous utilisons en moyenne chaque année, 300 mots de moins par jour. Un recul de la parole qui touche toutes les classes d’âge et que les chercheurs comptabilisent en indiquant que notre volume de parole a diminué de 28% en moins de 15 ans.
Je crois par contre que depuis l’avènement des médiations numériques, l’inflation de paroles et de discours directement monétisables d’une part (capitalisme linguistique), et en parallèle et d’autre part, l’artificialisation soutenue de formes discursives indigentes au seul renfort d’une nécessité d’interaction rendant la langue soluble dans sa fonction phatique, je crois que oui, tout cela fait qu’encore une fois la question du langage s’est déplacée et qu’elle continue de le faire toujours davantage, les IA conversationnelles augmentant la distance entre elle et nous à des échelles stratosphériques jusqu’ici jamais atteintes.
One More Thing.
Dans une interview au magazine Usbek & Rika à propos de son dernier livre, la question était posée à Nicholas Carr de savoir quelle serait sa première décision s’il était nommé à la tête d’un puissant ministère de la technologie et du numérique par un gouvernement éclairé. Et il répondait ceci : « Détruire tous les centres de données. »
Or que sont ces centres de données fondamentalement dans la perspective qui nous occupe ? Ce sont des centres d’accumulation de paroles et de discours ; de paroles et de discours retenus, en permanence recalculés, archivés non pas par vertu de conservation mais par nécessité de manipulation. Détruire tous les centres de données pourrait alors, en effet, redonner une chance à la parole d’exister, et que chaque occasion nouvelle de discourir soit aussi une occasion nouvelle de découvrir. Ce qui fût un temps l’essentiel de l’intérêt de ce que nous appelions le Web.
24.04.2026 à 18:17
Parcoursup saison 8 : faites l’armée plutôt que l’université.
Olivier Ertzscheid
Texte intégral (1286 mots)
Parcoursup est l’outil dont rêvait l’institution disciplinaire décrite par Foucault. Fondamentalement. Et chaque année davantage depuis déjà 8 ans que cette saloperie existe. Je vous ai déjà à de nombreuses reprises expliqué tout le mal que je pensais de cette plateforme (en 2020, en 2021, en 2025, en 2026 …) que j’ai vécu et expérimenté personnellement à trois reprises en tant que parent de 3 enfants et que je pratique également donc depuis 8 ans en tant que responsable de formation.
Presque chaque année c’est une nouvelle contrainte imbécile qui tombe ou s’impose dans cette plateforme sans que jamais il ne soit possible de la discuter ou de la remettre en cause. Et cette année j’avoue que lorsque j’ai appris qu’à terme les lettres de motivation allaient totalement disparaître et que si on voulait les garder c’était à chaque responsable de formation de fournir un argumentaire pour se justifier, j’ai vraiment eu envie de coller une grande soupe de phalange dans le cimetière à magret de mon ami Mister T. Mais j’étais très loin du climax de mon courroux (coucou) car je n’avais pas encore reçu le message ci-dessous.
Donc il y a quelques jours, alors que sur les 1600 dossiers que nous recevons pour 60 places je venais de finir de traiter les 200 qui me reviennent, j’ai eu la surprise de recevoir un petit mail de Parcoursup qui disait ceci :
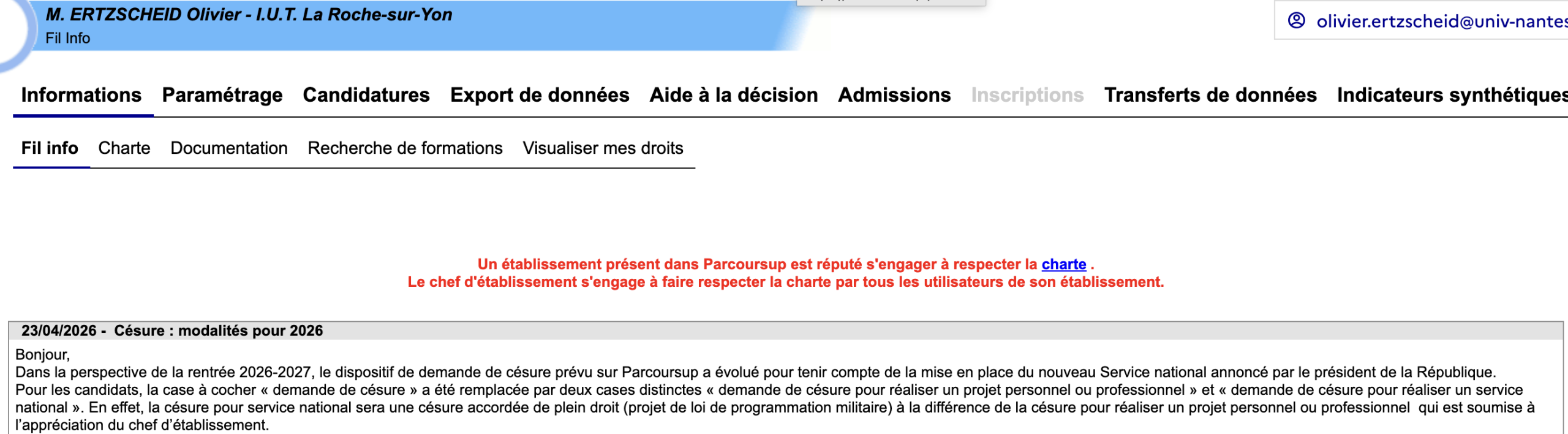
Je vous remets le texte directement :
Dans la perspective de la rentrée 2026-2027, le dispositif de demande de césure prévu sur Parcoursup a évolué pour tenir compte de la mise en place du nouveau Service national annoncé par le président de la République.
Pour les candidats, la case à cocher « demande de césure » a été remplacée par deux cases distinctes « demande de césure pour réaliser un projet personnel ou professionnel » et « demande de césure pour réaliser un service national ». En effet, la césure pour service national sera une césure accordée de plein droit (projet de loi de programmation militaire) à la différence de la césure pour réaliser un projet personnel ou professionnel qui est soumise à l’appréciation du chef d’établissement.
J’espère que tout cela est clair. Après la mise sous coupe algorithmique réglée de l’ensemble d’une classe d’âge, après l’empilement de réformes toutes plus débiles les unes que les autres à l’échelle du lycée et du baccalauréat, après la mise à sac programmatique de l’université publique, après les refus répétés en mode allegro obstinato de tenir compte de l’ensemble des retours des utilisateurs de cette p**** de plateforme qui chaque année expliquent que tout cela irait beaucoup plus vite et serait beaucoup moins stressant pour les lycéens et lycéennes s’ils et elles pouvaient classer leurs voeux dès le départ, voilà donc maintenant que Parcoursup se met au service d’un agenda politique national guerrier. Et voici Emmanuel Macron, le plutôt cadre ploutocrate enquillant son 2ème mandat à l’abri de toute mandale, qui d’une main nous incite à la chair du « réarmement démographique » et de l’autre anticipe le sort funeste de cette même chair.
Cette année on nous annonce donc que les demandes de césure pour faire son service militaire doivent être obligatoirement accordées. Et on nous l’annonce en plein milieu de la procédure et sans aucune concertation parce qu’il s’agit bien sûr aussi de nous discipliner.
Vu la situation et le contexte international, je ne suis pas le seul à nourrir d’immenses craintes pour ce que Parcoursup deviendra l’année prochaine et les suivantes. L’institution disciplinaire doit être vue, lue et comprise comme un continuum. Je rappelle que certains avaient déjà envisagé que celles et ceux qui avaient effectué le débilitant SNU puissent bénéficier de points supplémentaires dans Parcoursup. Une énième idée à la con qui avait heureusement été promptement identifiée comme telle mais qui avait aussi et surtout permis de préparer les esprits à ce qui adviendra inévitablement à l’horizon de quelques années.
Sans parler de la guerre, on observe cette année une augmentation très forte (et qui me semble inquiétante) de dossiers qui nous reviennent après avoir effectué une première année (en vérité quelques mois) dans une toute autre formation, preuve supplémentaire que la première orientation et la première expérience de la plateforme Parcoursup sont de plus en plus à côté de la plaque. Entendons-nous bien, on a bien sûr le droit de se réorienter et rien n’est dramatique, loin s’en faut, lorsque l’on est néo-bachelier. Ce qui est par contre inquiétant ce sont les choix qui semblent effectués en dépit de tout bon sens de la part de lycéens et lycéennes et de familles totalement égarés dans une offre surabondante et opaque, livrés au mieux à eux-mêmes et à la bonne volonté de professeurs principaux qui sont beaucoup de choses mais certainement pas des conseillers d’orientation ; lycéens, lycéennes et leurs familles qui sont surtout soumis, dès la fin du collège et durant toutes leurs années lycées, à une pression totalement inédite au regard des contraintes que l’on fait peser sur elles et eux.
Disciplinés très tôt par l’empilement de réformes aux temporalités imbéciles et sans aucune cohérence pédagogique ne serait-ce qu’interne, réformes totalement étanches aux rythmes de travail et de vie de nos sociétés et aux assignations parentales qui en découlent, ce ne sont pas les quelques ajustements cosmétiques annuels de l’interface Parcoursup qui permettront de régler le problème d’une plateforme qui semble n’avoir jamais été pensée ou même réfléchie pour accompagner des trajectoires mais qui donne hélas sa pleine mesure dès lors qu’il s’agit de sanctionner des parcours.
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Thomas BEAUFILS
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Scientifiques en Rebellion
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD